🦌 DeerFlow
DeerFlow(Deep Exploration and Efficient Research Flow)是一个社区驱动的深度研究框架,它建立在开源社区的杰出工作基础之上。目标是将语言模型与专业工具(如网络搜索、爬虫和Python代码执行)相结合.。
0.1 特性
- 🤖 LLM集成
- 通过litellm支持集成大多数模型
- 支持开源模型如Qwen
- 兼容OpenAI的API接口
- 多层LLM系统适用于不同复杂度的任务
-
工具和MCP集成
-
🔍 搜索和检索
- 通过Tavily、Brave Search等进行网络搜索
- 使用Jina进行爬取
- 高级内容提取
-
🔗 MCP无缝集成
- 扩展私有域访问、知识图谱、网页浏览等能力
- 促进多样化研究工具和方法的集成
-
-
人机协作
-
🧠 人在环中
- 支持使用自然语言交互式修改研究计划
- 支持自动接受研究计划
-
📝 报告后期编辑
- 支持类Notion的块编辑
- 允许AI优化,包括AI辅助润色、句子缩短和扩展
- 由tiptap提供支持
-
-
内容创作
- 🎙️ 播客和演示文稿生成
- AI驱动的播客脚本生成和音频合成
- 自动创建简单的PowerPoint演示文稿
- 可定制模板以满足个性化内容需求
- 🎙️ 播客和演示文稿生成
0.2 架构
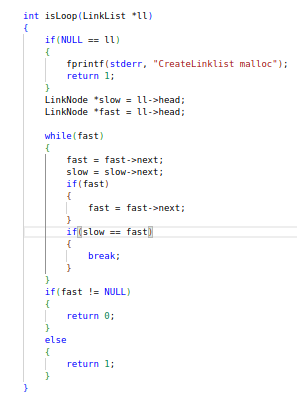
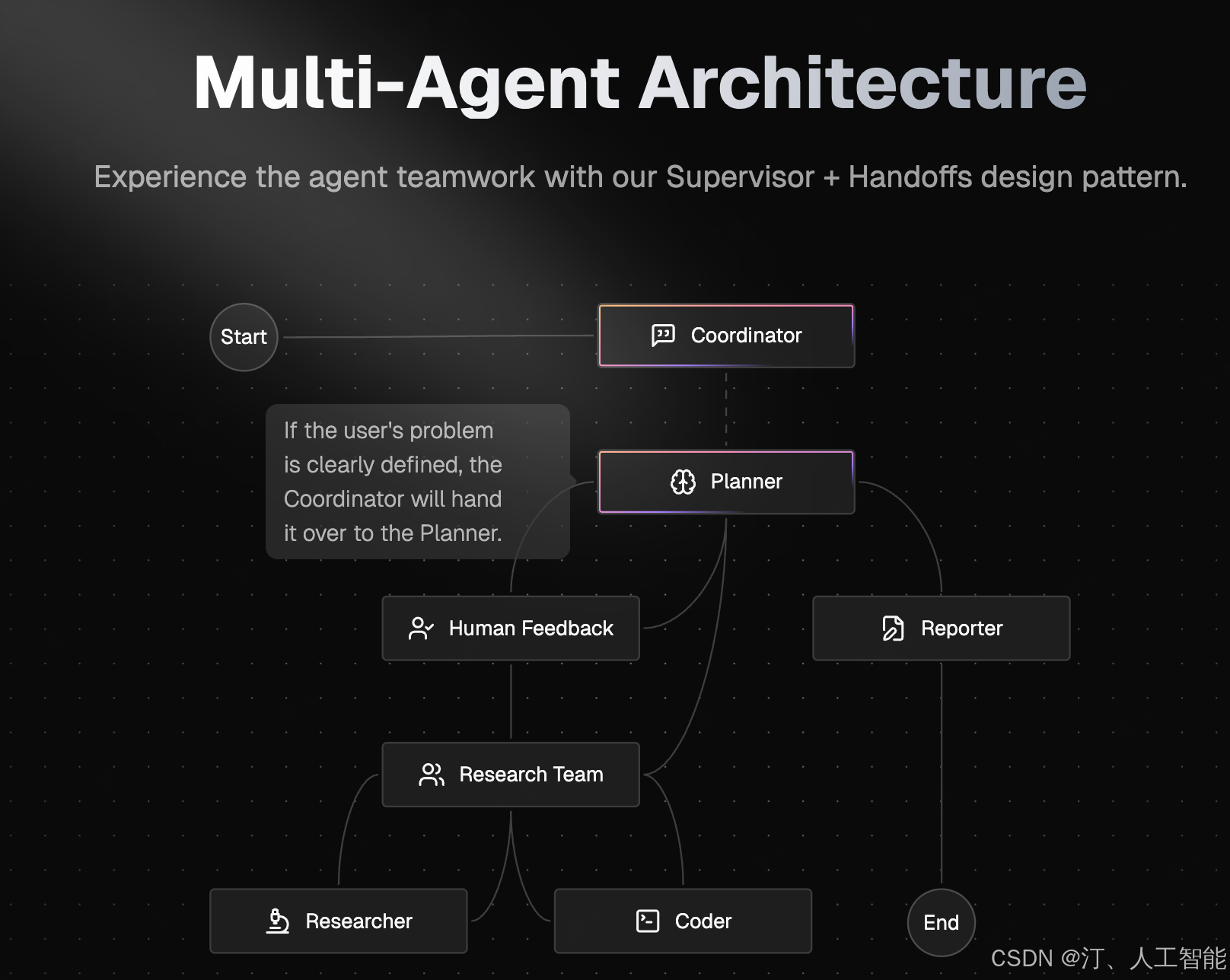
DeerFlow实现了一个模块化的多智能体系统架构,专为自动化研究和代码分析而设计。该系统基于LangGraph构建,实现了灵活的基于状态的工作流,其中组件通过定义良好的消息传递系统进行通信。

系统采用了精简的工作流程,包含以下组件:
-
协调器:管理工作流生命周期的入口点
- 根据用户输入启动研究过程
- 在适当时候将任务委派给规划器
- 作为用户和系统之间的主要接口
-
规划器:负责任务分解和规划的战略组件
- 分析研究目标并创建结构化执行计划
- 确定是否有足够的上下文或是否需要更多研究
- 管理研究流程并决定何时生成最终报告
-
研究团队:执行计划的专业智能体集合:
- 研究员:使用网络搜索引擎、爬虫甚至MCP服务等工具进行网络搜索和信息收集。
- 编码员:使用Python REPL工具处理代码分析、执行和技术任务。
每个智能体都可以访问针对其角色优化的特定工具,并在LangGraph框架内运行
-
报告员:研究输出的最终阶段处理器
- 汇总研究团队的发现
- 处理和组织收集的信息
- 生成全面的研究报告
1.快速开始
DeerFlow使用Python开发,并配有用Node.js编写的Web UI。为确保顺利的设置过程,我们推荐使用以下工具:
-
推荐工具
-
uv:
简化Python环境和依赖管理。uv会自动在根目录创建虚拟环境并为您安装所有必需的包—无需手动安装Python环境。 -
nvm:
轻松管理多个Node.js运行时版本。 -
pnpm:
安装和管理Node.js项目的依赖。
-
-
环境要求
确保您的系统满足以下最低要求:
- Python: 版本
3.12+ - Node.js: 版本
22+
1.1安装
# 克隆仓库
git clone https://github.com/bytedance/deer-flow.git
cd deer-flow
# 安装依赖,uv将负责Python解释器和虚拟环境的创建,并安装所需的包
uv sync
# 使用您的API密钥配置.env
# Tavily: https://app.tavily.com/home
# Brave_SEARCH: https://brave.com/search/api/
# 火山引擎TTS: 如果您有TTS凭证,请添加
cp .env.example .env
# 查看下方的"支持的搜索引擎"和"文本转语音集成"部分了解所有可用选项
# 为您的LLM模型和API密钥配置conf.yaml
# 请参阅'docs/configuration_guide.md'获取更多详情
cp conf.yaml.example conf.yaml
# 安装marp用于PPT生成
# https://github.com/marp-team/marp-cli?tab=readme-ov-file#use-package-manager
brew install marp-cli
可选,通过pnpm安装Web UI依赖:
cd deer-flow/web
pnpm install
- 控制台UI
运行项目的最快方法是使用控制台UI。
# 在类bash的shell中运行项目
uv run main.py
1.2 Web UI
本项目还包括一个Web UI,提供更加动态和引人入胜的交互体验。
[!注意]
您需要先安装Web UI的依赖。
# 在开发模式下同时运行后端和前端服务器
# 在macOS/Linux上
./bootstrap.sh -d
# 在Windows上
bootstrap.bat -d
打开浏览器并访问http://localhost:3000探索Web UI。
在web目录中探索更多详情。
1.3支持的搜索引擎
DeerFlow支持多种搜索引擎,可以在.env文件中通过SEARCH_API变量进行配置:
-
Tavily(默认):专为AI应用设计的专业搜索API
- 需要在
.env文件中设置TAVILY_API_KEY - 注册地址:https://app.tavily.com/home
- 需要在
-
DuckDuckGo:注重隐私的搜索引擎
- 无需API密钥
-
Brave Search:具有高级功能的注重隐私的搜索引擎
- 需要在
.env文件中设置BRAVE_SEARCH_API_KEY - 注册地址:https://brave.com/search/api/
- 需要在
-
Arxiv:用于学术研究的科学论文搜索
- 无需API密钥
- 专为科学和学术论文设计
要配置您首选的搜索引擎,请在.env文件中设置SEARCH_API变量:
# 选择一个:tavily, duckduckgo, brave_search, arxiv
SEARCH_API=tavily
1.4 文本转语音集成
DeerFlow现在包含一个文本转语音(TTS)功能,允许您将研究报告转换为语音。此功能使用火山引擎TTS API生成高质量的文本音频。速度、音量和音调等特性也可以自定义。
- 使用TTS API
您可以通过/api/tts端点访问TTS功能:
# 使用curl的API调用示例
curl --location 'http://localhost:8000/api/tts' \
--header 'Content-Type: application/json' \
--data '{
"text": "这是文本转语音功能的测试。",
"speed_ratio": 1.0,
"volume_ratio": 1.0,
"pitch_ratio": 1.0
}' \
--output speech.mp3
2.开发
2.1测试
运行测试套件:
# 运行所有测试
make test
# 运行特定测试文件
pytest tests/integration/test_workflow.py
# 运行覆盖率测试
make coverage
2.2 代码质量
# 运行代码检查
make lint
# 格式化代码
make format
使用LangGraph Studio进行调试
DeerFlow使用LangGraph作为其工作流架构。您可以使用LangGraph Studio实时调试和可视化工作流。
- 本地运行LangGraph Studio
DeerFlow包含一个langgraph.json配置文件,该文件定义了LangGraph Studio的图结构和依赖关系。该文件指向项目中定义的工作流图,并自动从.env文件加载环境变量。
- Mac
# 如果您没有uv包管理器,请安装它
curl -LsSf https://astral.sh/uv/install.sh | sh
# 安装依赖并启动LangGraph服务器
uvx --refresh --from "langgraph-cli[inmem]" --with-editable . --python 3.12 langgraph dev --allow-blocking
- Windows / Linux
# 安装依赖
pip install -e .
pip install -U "langgraph-cli[inmem]"
# 启动LangGraph服务器
langgraph dev
启动LangGraph服务器后,您将在终端中看到几个URL:
- API: http://127.0.0.1:2024
- Studio UI: https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024
- API文档: http://127.0.0.1:2024/docs
在浏览器中打开Studio UI链接以访问调试界面。
- 使用LangGraph Studio
在Studio UI中,您可以:
- 可视化工作流图并查看组件如何连接
- 实时跟踪执行情况,了解数据如何在系统中流动
- 检查工作流每个步骤的状态
- 通过检查每个组件的输入和输出来调试问题
- 在规划阶段提供反馈以完善研究计划
当您在Studio UI中提交研究主题时,您将能够看到整个工作流执行过程,包括:
- 创建研究计划的规划阶段
- 可以修改计划的反馈循环
- 每个部分的研究和写作阶段
- 最终报告生成
3. 示例展示
以下示例展示了DeerFlow的功能:
-
什么是MCP? - 对"MCP"一词在多个上下文中的全面分析
- 探讨AI中的Model Context Protocol、化学中的Monocalcium Phosphate和电子学中的Micro-channel Plate
- 查看完整报告
-
比特币价格波动 - 最近比特币价格走势分析
- 研究市场趋势、监管影响和技术指标
- 基于历史数据提供建议
- 查看完整报告
# 最近三个月比特币价格波动分析报告
## 执行摘要
本报告分析了过去三个月内比特币的价格波动情况,主要依据现有的搜索结果进行总结。分析内容涵盖市场情绪、监管影响、经济因素以及技术分析指标。由于无法直接获取和处理原始数据,本报告基于多个来源的汇总信息进行研究。
## 关键发现
- **特朗普政府政策影响**:2025年4月实施的关税政策导致比特币价格从109,000美元下跌至84,000美元。
- **经济不确定性**:整体经济环境的不确定性促使比特币价格跌破90,000美元。
- **市场情绪**:加密货币“恐惧与贪婪指数”反映了市场整体情绪,该指数会因新闻事件而波动。
- **技术分析**:关键支撑位约在80,400美元和74,000美元,阻力位则接近98,500美元和106,000美元。
## 详细分析
### 影响因素
#### 监管环境
特朗普政府对加密货币的监管态度以及美国证券交易委员会(SEC)的相关行动对比特币价格产生了显著影响。
#### 市场情绪
“加密货币恐惧与贪婪指数”是衡量市场情绪的重要指标。此外,来自雅虎财经(Yahoo Finance)和Investing.com的历史交易数据显示了过去三个月的比特币交易量变化。
#### 社交媒体情绪
Reddit的r/cryptocurrency板块及推特(X)上的讨论可提供市场情绪洞察。
#### GBTC持仓
Grayscale比特币信托(GBTC)的历史价格和持仓数据反映了机构投资者的态度。
#### 比特币期货
根据雅虎财经的数据,比特币期货(BTC=F)的历史走势提供了市场预期的参考。
#### Google趋势
Google Trends显示,“比特币”关键词的搜索热度随时间变化。近期文章指出,“比特币”及“比特币价格”相关搜索兴趣有所下降。
### 价格波动情况
- **关税政策影响**:受特朗普政府于2025年4月2日宣布的关税政策影响,比特币价格由109,000美元跌至84,000美元。
- **经济不确定性影响**:整体经济形势不明朗,导致比特币价格跌破90,000美元。
- **技术支撑与阻力位**:当前需关注的关键支撑位为80,400美元和74,000美元,阻力位分别为98,500美元和106,000美元。
## 结论与建议
### 结论
综合现有信息来看,过去三个月比特币价格波动主要受到监管政策、宏观经济状况以及市场情绪等多重因素的影响。
### 建议
1. **密切关注监管动向**:持续跟踪各国政府及监管机构的政策调整,评估其对加密货币市场的潜在影响。
2. **关注宏观经济指标**:密切留意全球经济增长、通胀数据等宏观指标,以判断其对投资者行为的影响。
3. **利用市场情绪工具**:结合“加密货币恐惧与贪婪指数”及社交媒体舆情分析,掌握市场心理变化。
4. **技术分析辅助决策**:运用技术分析工具识别关键支撑与阻力位,为投资策略提供参考依据。
### 局限性
本报告基于公开渠道的汇总信息撰写,缺乏对原始数据的深入分析。如需得出更精确的结论,建议进一步开展基于完整数据分析的深入研究。
- 如何使用Claude进行深度研究? - 在深度研究中使用Claude的最佳实践和工作流程
- 涵盖提示工程、数据分析和与其他工具的集成
- 查看完整报告
# 深度研究中使用 Claude:工作流程与最佳实践
## 执行摘要
本报告概述了将 **Claude** 有效整合进深度研究流程的最佳实践,涵盖数据收集、预处理、分析与综合等关键环节。此外,还探讨了其与其他工具的集成方式、结果验证方法、成本管理策略、协作机制、文档撰写规范及相关案例研究。Claude 可作为辅助工具支持学术写作与研究,但应始终服务于原创性思考,而非替代之。
## 关键发现
- **学术写作与研究支持**:Claude 能够辅助学术写作和研究,但应作为辅助工具,而非取代原创性思维。
- **项目功能(Project Feature)**:可上传相关文档以减少重复设置上下文信息的工作量。
- **数据分析能力**:内置的数据分析工具能够编写并运行 JavaScript 代码,对数据进行处理并提供洞察。
- **引用工具**:具备自动验证来源及规范引用格式的功能,有助于提升学术严谨性。
- **模型选择建议**:Haiku 是其智能等级中响应最快、性价比最高的模型。
- **虚拟团队成员角色**:Claude 可作为虚拟团队成员推动研究或产品开发进程。
- **协同创新**:分享由 Claude 协助生成的研究成果,有助于激发产品开发与科研中的创新。
- **技术文档撰写**:Claude 能高效生成技术文档,并保持内容一致性。
- **工具集成能力**:可与笔记、写作及参考文献管理工具无缝集成。
## 详细分析
### 工作流程与最佳实践
#### 明确研究问题
在初始提示中清晰定义研究问题和关注领域,确保 Claude 理解任务目标。
#### 结构化数据输入
提供结构化的数据信息,提高 Claude 的理解和处理效率。
#### 使用 Project 功能
利用 Claude 的“项目”功能上传相关文档,避免重复输入背景信息,提升工作效率。
[来源: https://support.anthropic.com/en/articles/9797557-usage-limit-best-practices]
#### 提示工程技巧
采用提示工程技巧,如加入“请逐步思考”,以提升输出质量。
[来源: https://aws.amazon.com/blogs/machine-learning/prompt-engineering-techniques-and-best-practices-learn-by-doing-with-anthropics-claude-3-on-amazon-bedrock/]
---
### 数据分析
#### 内置数据分析工具
Claude 提供内置数据分析工具,可通过执行 JavaScript 代码对数据进行处理并提取洞察。
[来源: https://www.anthropic.com/news/analysis-tool, https://support.anthropic.com/en/articles/10008684-enabling-and-using-the-analysis-tool]
#### CSV 文件分析
该工具也可用于分析上传的 CSV 数据文件,并实现可视化展示。
[来源: https://support.anthropic.com/en/articles/10008684-enabling-and-using-the-analysis-tool]
---
### 结果验证
#### 引用验证工具
使用 Claude 提供的引用工具来验证来源准确性,并确保符合学术引用规范。
[来源: https://www.yomu.ai/blog/claude-ai-in-academic-writing-and-research-essential-tips-for-optimal-results]
#### 提示词清洗与验证
注意 Anthropic API 对用户提示词会进行基本的清洗与验证处理。
[来源: https://docs.anthropic.com/en/api/prompt-validation]
---
### 成本管理
#### 模型选择
根据任务需求选择合适的模型,推荐在需要高性价比时使用 **Claude Haiku**,其在同级别智能模型中响应最快、成本最低。
[来源: https://www.anthropic.com/news/claude-3-family]
---
### 协作策略
#### 虚拟团队成员
将 Claude 视为虚拟团队成员,协助完成资料整理、初稿撰写、逻辑梳理等工作。
[来源: https://www.anthropic.com/team]
#### 共享共创成果
共享由 Claude 协助生成的内容,尤其适用于产品开发和科研协作,可促进团队内部创新。
[来源: https://www.anthropic.com/news/projects]
---
### 文档撰写
#### 技术文档生成
Claude 可快速生成高质量技术文档,并确保术语与风格的一致性。
[来源: https://beginswithai.com/how-to-use-claude-ai-to-create-technical-documentation/]
---
### 与其他工具集成
#### 笔记与写作工具
与 Evernote、OneNote、Google Docs 等笔记与写作工具集成,便于实时同步与协作。
[来源: https://beginswithai.com/using-claude-for-research/]
#### 参考文献管理工具
支持 Zotero、Mendeley 和 EndNote 等参考文献管理工具的集成。
[来源: https://beginswithai.com/using-claude-for-research/]
#### 平台集成
确保与 Anthropic API、Google Cloud Vertex AI 等平台的良好兼容性,提升整体研究效率。
[来源: https://www.yomu.ai/blog/claude-ai-in-academic-writing-and-research-essential-tips-for-optimal-results]
---
### 案例研究
#### 多领域成功应用
已有多个行业成功应用 Claude 的案例,包括鲸类保护、品牌管理、网络安全、招聘筛选、保险理赔、代码审查、客户服务和销售转化等领域。
[来源: https://www.anthropic.com/customers]
---
## 结论与建议
### 结论
Claude 是一款在深度研究中极具价值的人工智能助手,只要合理规划使用方式,即可显著提升研究效率与质量。通过明确研究问题、结构化数据输入、善用项目功能与数据分析工具,研究人员可以充分发挥其潜力。同时,借助引用工具与提示工程优化输出内容的准确性和逻辑性至关重要。Claude 还能增强团队协作能力,并通过与其他研究工具的集成优化整体工作流。从多个领域的实际案例来看,Claude 展现出广泛的应用前景与强大的适应能力。
### 建议
1. **明确研究目标**:在开始阶段就清晰定义研究问题与目标。
2. **结构化输入数据**:提供清晰、有组织的数据以提高处理效率。
3. **充分利用项目功能**:上传背景材料,节省反复解释时间。
4. **优化提示词设计**:采用分步引导、角色设定等方式提升输出质量。
5. **验证输出结果**:使用引用工具确保信息准确无误。
6. **控制成本支出**:根据任务复杂程度选择合适模型。
7. **加强团队协作**:鼓励团队共享与共创,推动知识沉淀与创新。
8. **完善文档记录**:利用 Claude 快速生成统一风格的技术文档。
9. **整合研究工具链**:打通与现有研究工具的数据与流程连接。
10. **学习成功案例**:借鉴其他行业的应用经验,探索更多可能性。
- 医疗保健中的AI采用:影响因素 - 影响医疗保健中AI采用的因素分析
- 讨论AI技术、数据质量、伦理考虑、经济评估、组织准备度和数字基础设施
- 查看完整报告
要运行这些示例或创建您自己的研究报告,您可以使用以下命令:
# 使用特定查询运行
uv run main.py "哪些因素正在影响医疗保健中的AI采用?"
# 使用自定义规划参数运行
uv run main.py --max_plan_iterations 3 "量子计算如何影响密码学?"
# 在交互模式下运行,带有内置问题
uv run main.py --interactive
# 或者使用基本交互提示运行
uv run main.py
# 查看所有可用选项
uv run main.py --help
- 交互模式
应用程序现在支持带有英文和中文内置问题的交互模式:
-
启动交互模式:
uv run main.py --interactive -
选择您偏好的语言(English或中文)
-
从内置问题列表中选择或选择提出您自己问题的选项
-
系统将处理您的问题并生成全面的研究报告
参考:
- 字节跳动开源了一款 Deep Research 项目