简要分析vLLM中PA的代码架构和v1与v2的区别
vLLM版本:0.8.4
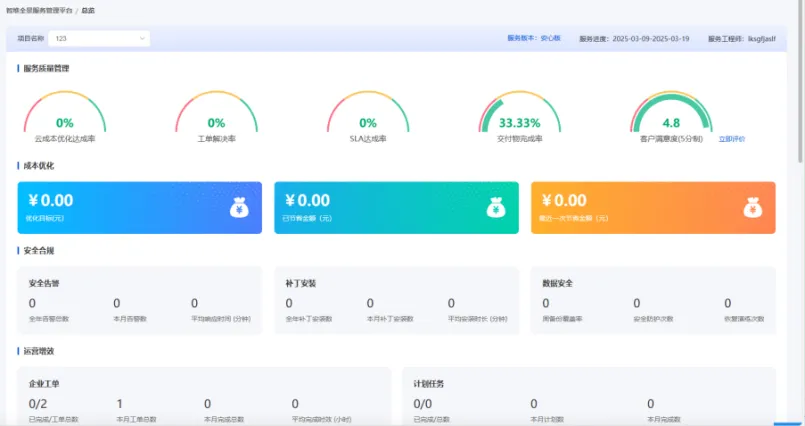
整体结构分析
首先从torch_bindings.cpp入手分析:
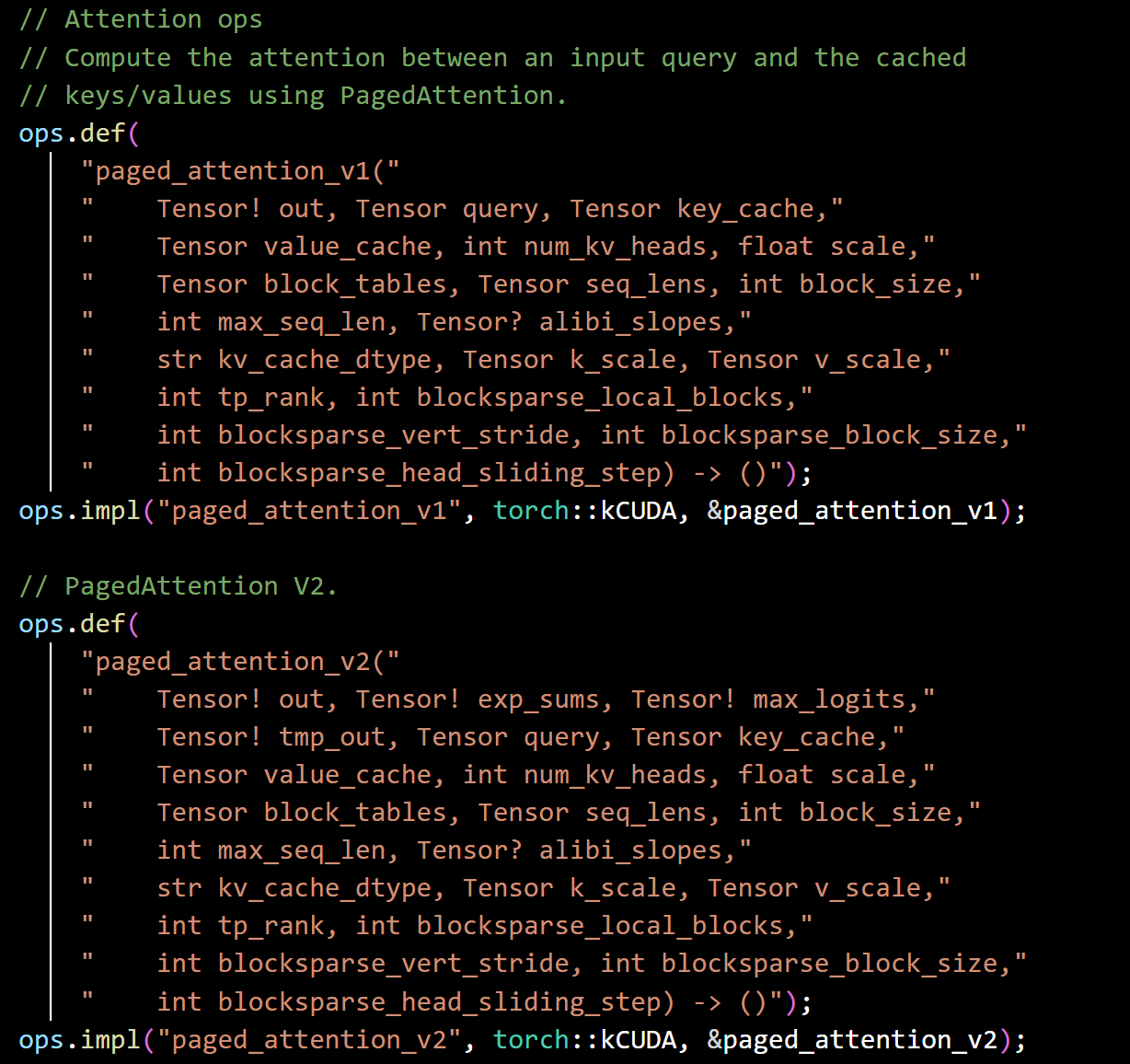
这里可以看到vLLM向pytorch中注册了两个PA算子:v1和v2
其中paged_attention_v1和paged_attention_v2分别实现在csrc/attention/paged_attention_v1.cu以及csrc/attention/paged_attention_v2.cu中:
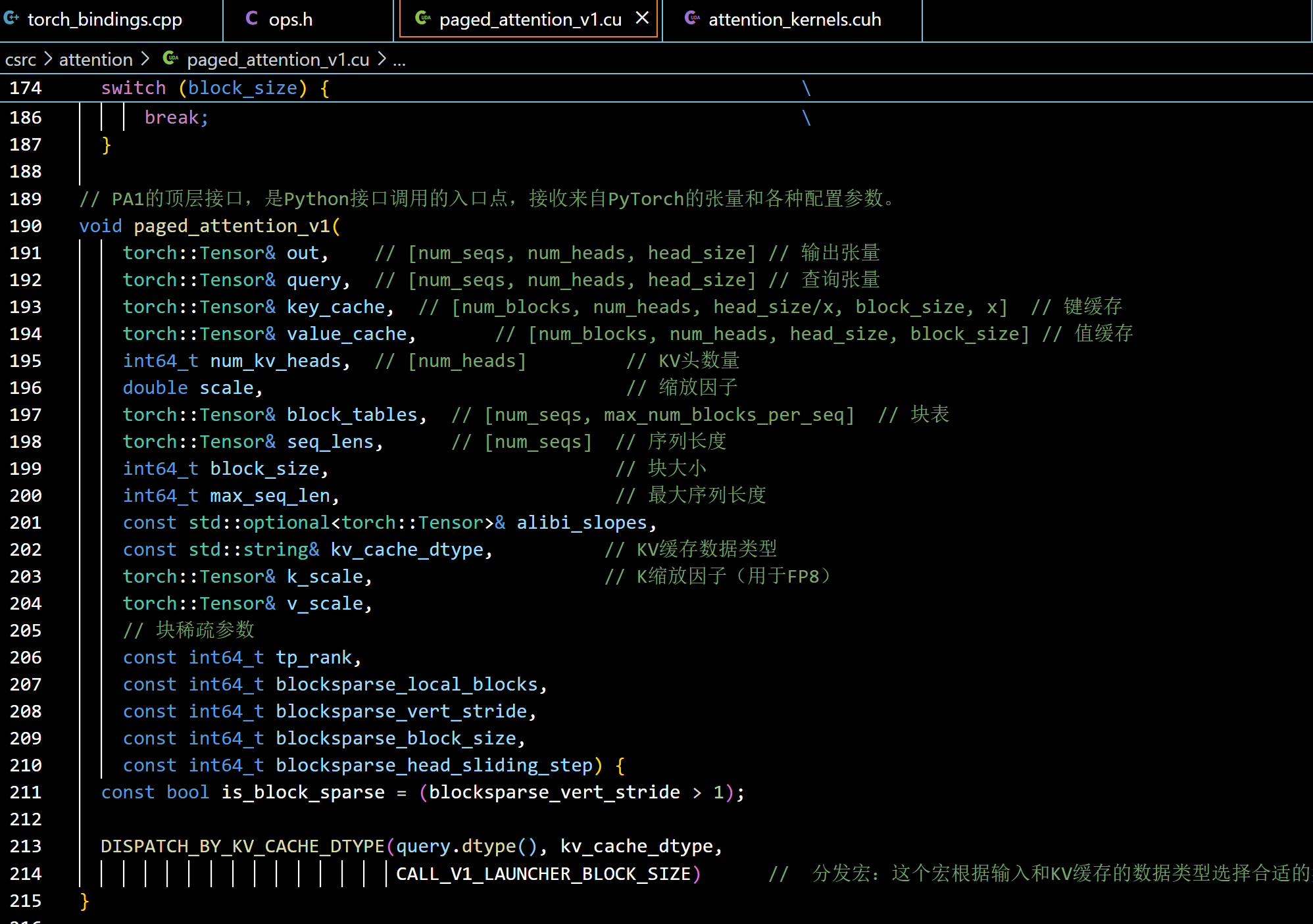
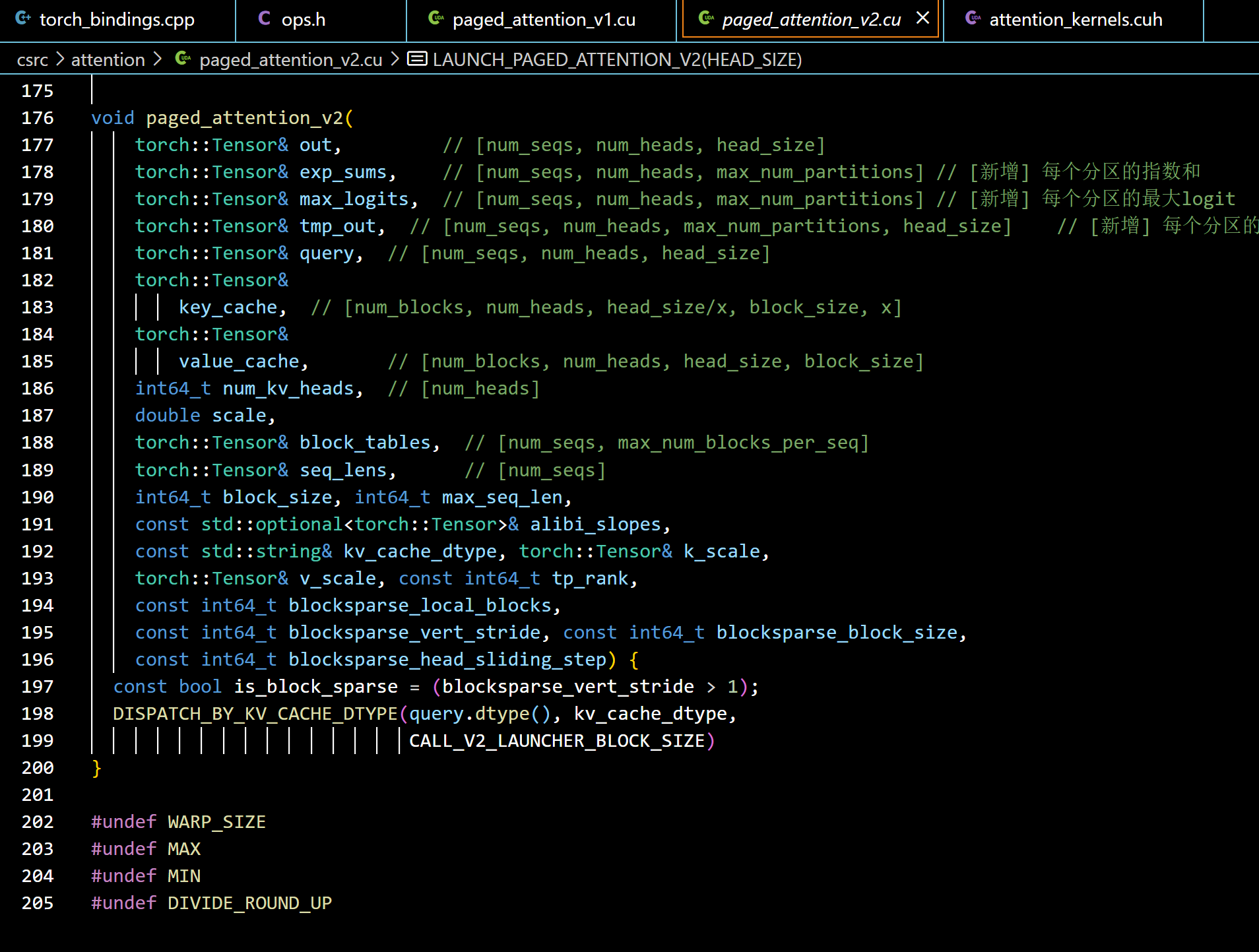
paged_attention_v1和paged_attention_v2都是PA实现的顶层接口,是Python接口调用的入口点,接收来自PyTorch的张量和各种配置参数。
根据csrc/attention/paged_attention_v1.cu中的代码逻辑,我们可以知道vLLM使用了多层分发机制来实现灵活的算子调用,以csrc/attention/paged_attention_v1.cu中的paged_attention_v1为例,分发层级为:
paged_attention_v1:
-> DISPATCH_BY_KV_CACHE_DTYPE
-> CALL_V1_LAUNCHER_BLOCK_SIZE
-> CALL_V1_LAUNCHER_SPARSITY
-> CALL_V1_LAUNCHER
-> paged_attention_v1_launcher
-> LAUNCH_PAGED_ATTENTION_V1
-> paged_attention_v1_kernel (csrc/attention/attention_kernels.cuh实现)
-> paged_attention_kernel(csrc/attention/attention_kernels.cuh实现)
可知paged_attention_kernel是具体的PA算子,csrc/attention/attention_kernels.cuh的代码主要包含以下几个函数:

paged_attention_v1_kernel和paged_attention_v2_kernel分别是v1和v2对paged_attention_kernel的封装,功能是类似的。
v1与v2的具体区别
总体上:
- v1版本提供了直接、无分区的注意力计算,适用于中短序列,实现简单,内核启动开销低。
- v2版本引入了分区计算和归约合并的两阶段处理,解决了长序列的共享内存限制问题,提高了GPU利用率。
函数参数
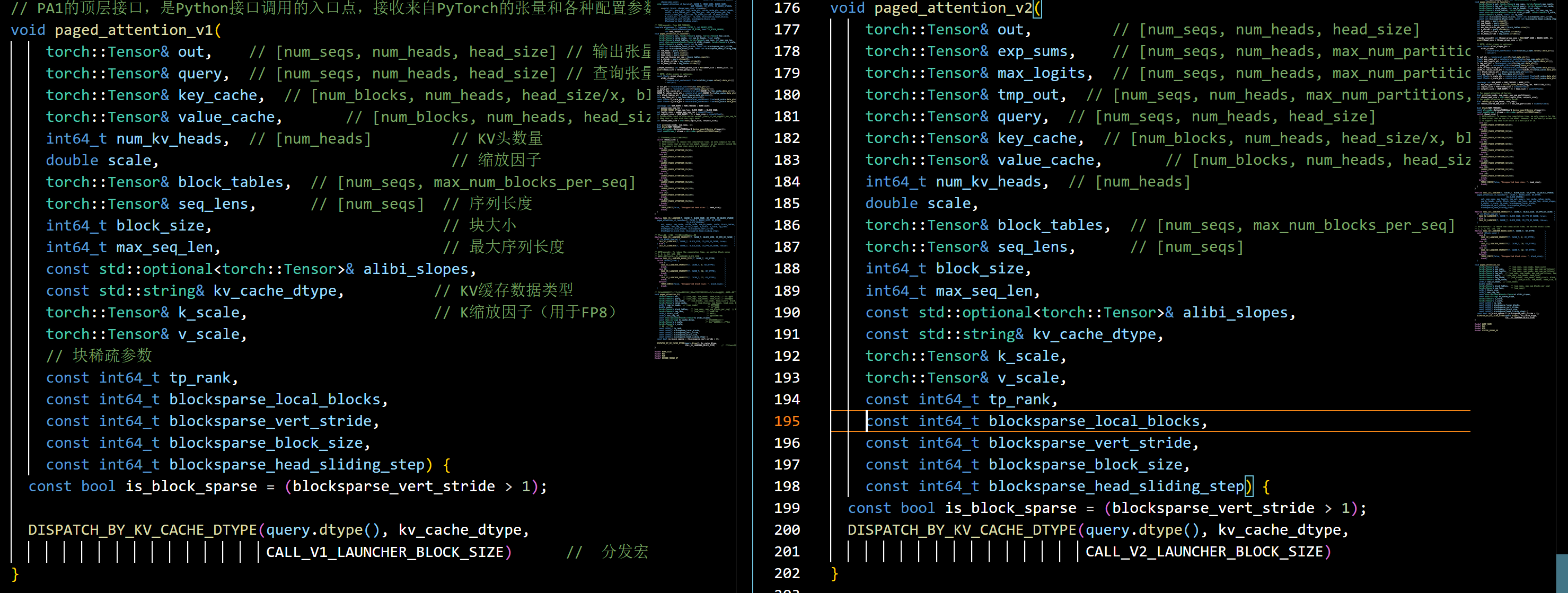
paged_attention_v1和paged_attention_v2参数对比可以发现,v2版本新增了三个参数:exp_sums,max_logits,tmp_out,他们是用于分区注意力计算。
这三个参数的维度包含了max_num_partitions,表示序列被划分的最大分区数。
分区计算策略
v2版本引入了固定大小的分区(默认512个token),将长序列分割成多个分区并行处理。
// v1版本 - 整体处理序列
dim3 grid(num_heads, num_seqs, 1); // 注意z维度为1
// v2版本 - 分区处理序列
int max_num_partitions = DIVIDE_ROUND_UP(max_seq_len, PARTITION_SIZE);// 默认分区大小PARTITION_SIZE = 512
dim3 grid(num_heads, num_seqs, max_num_partitions); // z维度为分区数
v2两阶段计算
#define LAUNCH_PAGED_ATTENTION_V2(HEAD_SIZE) \
vllm::paged_attention_v2_kernel<T, CACHE_T, HEAD_SIZE, BLOCK_SIZE, \
NUM_THREADS, KV_DTYPE, IS_BLOCK_SPARSE, \
PARTITION_SIZE> \
<<<grid, block, shared_mem_size, stream>>>( \
exp_sums_ptr, max_logits_ptr, tmp_out_ptr, query_ptr, key_cache_ptr, \
value_cache_ptr, num_kv_heads, scale, block_tables_ptr, \
seq_lens_ptr, max_num_blocks_per_seq, alibi_slopes_ptr, q_stride, \
kv_block_stride, kv_head_stride, k_scale_ptr, v_scale_ptr, tp_rank, \
blocksparse_local_blocks, blocksparse_vert_stride, \
blocksparse_block_size, blocksparse_head_sliding_step); \
vllm::paged_attention_v2_reduce_kernel<T, HEAD_SIZE, NUM_THREADS, \
PARTITION_SIZE> \
<<<reduce_grid, block, reduce_shared_mem_size, stream>>>( \
out_ptr, exp_sums_ptr, max_logits_ptr, tmp_out_ptr, seq_lens_ptr, \
max_num_partitions);
相对于v1,v2包含两阶段计算,分别是:
// 第一阶段:分区计算
vllm::paged_attention_v2_kernel<<< ... >>>(/* 参数 */);
// 第二阶段:合并结果
vllm::paged_attention_v2_reduce_kernel<<< ... >>>(/* 参数 */);
而v1版本只需一个核函数:
vllm::paged_attention_v1_kernel<<< ... >>>(/* 参数 */);
共享内存的使用上
// v1版本 - 需要为整个序列分配共享内存
int padded_max_seq_len = DIVIDE_ROUND_UP(max_seq_len, BLOCK_SIZE) * BLOCK_SIZE;
int logits_size = padded_max_seq_len * sizeof(float);
// v2版本 - 只需为一个分区分配共享内存
int logits_size = PARTITION_SIZE * sizeof(float);
v2版本显著减少了每个线程块需要的共享内存大小.
v2版本的规约
v2版本在paged_attention_v2_reduce_kernel中实现了复杂的跨分区归约。
// 计算全局最大logit
max_logit = fmaxf(max_logit, VLLM_SHFL_XOR_SYNC(max_logit, mask));
// 计算重新缩放的指数和
float rescaled_exp_sum = exp_sums_ptr[i] * expf(l - max_logit);
// 聚合分区结果
float acc = 0.0f;
for (int j = 0; j < num_partitions; ++j) {
acc += to_float(tmp_out_ptr[j * HEAD_SIZE + i]) * shared_exp_sums[j] * inv_global_exp_sum;
}
若有错误,欢迎指正!