摘要
本文主要介绍了数据治理系统的建设。数据治理对企业至关重要,其动因包括应对数据爆炸增长、提升内部管理效率、支撑复杂业务需求、加强风险防控与合规管理以及实现数字化转型战略。其核心目的是提升数据质量、统一数据标准、优化数据资产管理、支撑业务发展和提升系统效率与稳定性。数据治理的终极目标是实现数据资产化、数据驱动决策、数据价值变现和形成企业级数据中台。一个完整的数据治理方案通常包含组织与职责建设、数据标准体系建设等关键组成部分。
1. 数据治理背景
1.1. 数据治理背景
企业开展数据治理的动因包括:
- 应对数据爆炸增长的挑战:海量数据如果不治理,将变成负担;
- 提升内部管理效率:减少重复开发、提升协同效率;
- 支撑复杂业务需求:高质量、稳定、可复用的数据是现代业务创新的基础;
- 加强风险防控与合规管理:满足数据安全、隐私保护和行业监管要求;
- 实现数字化转型战略:数据治理是企业从“人治”走向“数治”的基础工程。
数据治理的核心目的在于:
- 提升数据质量:保证数据的准确性、一致性、完整性与可用性。
- 统一数据标准:规范命名、格式、分类、接口,消除“数据孤岛”。
- 优化数据资产管理:梳理数据资产目录,明确数据责任归属,实现可追溯、可共享。
- 支撑业务发展:通过治理构建高效数据服务体系,提升数据支撑决策与运营的能力。
- 提升系统效率与稳定性:降低重复建设、减少资源浪费、提高系统健壮性。
1.2. 数据治理终极目标
数据治理的终极目标是实现:
- 数据资产化:让数据像资产一样被管理、评估与使用;
- 数据驱动决策:增强数据对业务决策、运营优化与战略制定的支持;
- 数据价值变现:释放数据潜能,提升企业运营效率与创新能力;
- 形成企业级数据中台:支撑多业务系统数据共享与复用,提升系统整体灵活性与可扩展性。
1.3. 数据治理方案设计
一个完整的数据治理方案通常包含以下关键组成部分:
| 方案 | 措施 | 备注 |
| 组织与职责建设 | 建立数据治理委员会 | |
| 明确数据拥有者、管理员、使用者的职责边界 | ||
| 数据标准体系建设 | 定义元数据、主数据、参考数据等标准 | |
| 制定数据质量标准与指标体系 | ||
| 数据质量管理机制 | 建立数据质量监控、评估、预警与修复机制 | |
| 数据全生命周期管理 | 包括数据采集、处理、存储、使用、归档与销毁等环节 | |
| 数据资产目录与血缘分析 | 建立统一数据资产目录 | |
| 支持数据的溯源、依赖关系跟踪与影响分析 | ||
| 数据服务与共享平台 | 构建数据服务平台,实现数据可查、可管、可用、可控 |
2. 数据治理体系架构
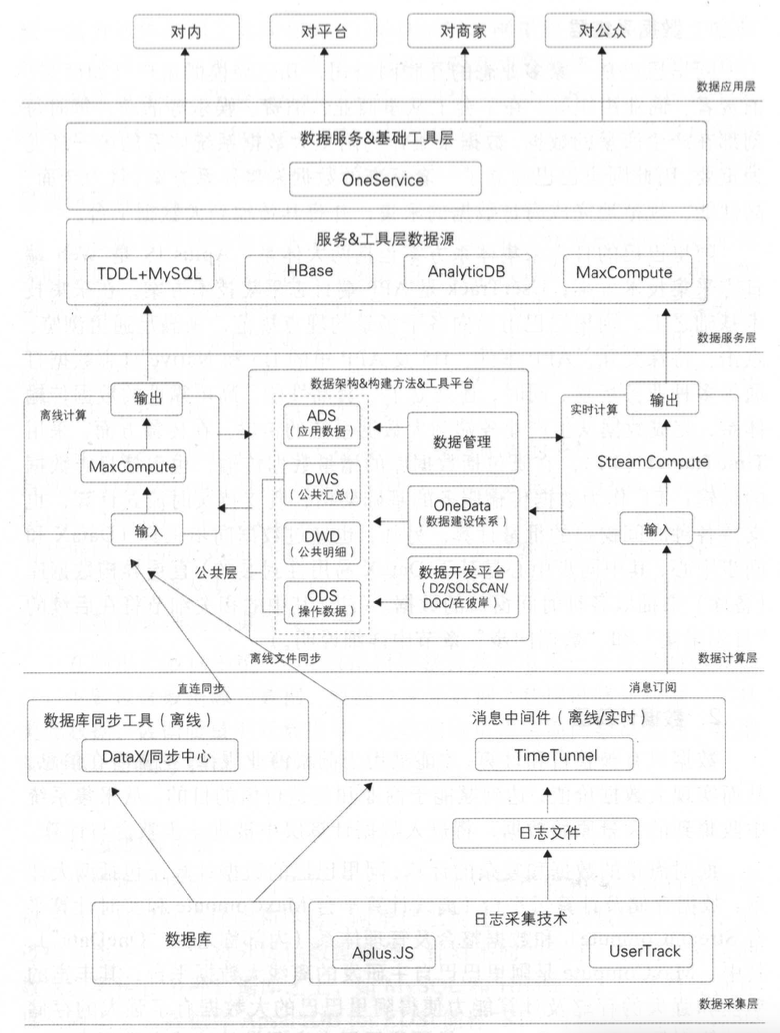
3. 数据治理体系设计
3.1. 数据采集层
在大数据体系中,数据采集层是数据治理的起点和基础。阿里作为一家业务多元、用户规模庞大的互联网企业,每时每刻都在处理来自电商、金融、内容、物流等多业务场景下的海量数据。为保障数据的全面性、及时性与准确性,阿里构建了一套高性能、标准化、覆盖全端的数据采集体系,以支持大数据平台的上层计算与治理需求。
3.1.1. 数据采集定义与作用
定位:位于系统架构的最底层,是数据流入系统的入口。
核心目标:将分散、异构的数据源(如传感器、日志、数据库、API等)中的原始数据,转换为标准化格式并输送到数据处理层。
重要性:直接影响数据质量、实时性及后续分析的准确性。
3.1.2. 数据源类型
结构化数据:关系型数据库(MySQL、Oracle)、ERP/CRM系统。
半结构化数据:日志文件(Nginx日志)、JSON/XML格式数据(API响应)。
非结构化数据:文本文件、图片、音视频、IoT传感器数据。
实时流数据:Kafka消息队列、MQTT协议设备数据。
第三方数据:公开API、合作伙伴数据接口。
3.1.3. 数据采集核心功能
数据抽取:通过主动查询(轮询)、事件驱动(推送)或日志监听(如Filebeat)获取数据。
数据标准化:清洗脏数据(去重、补全)、格式转换(时间戳统一、编码转换)。
数据传输:支持批量(如每日同步)或实时(如Kafka)传输,确保低延迟与高吞吐。
容错与重试:断点续传、失败任务重试机制,保障数据完整性。
3.1.4. 数据采集常用技术与工具
| 场景 | 工具示例 |
| 日志采集 | Filebeat、Flume、Logstash |
| 数据库同步 | Sqoop、Debezium(CDC)、Maxwell |
| IoT设备 | MQTT Broker、Apache NiFi |
| API/流数据 | Kafka Connect、Telegraf |
| 分布式采集 | Apache NiFi、Airbyte |
3.1.5. 数据采集关键挑战与解决方案
| 挑战 | 应对策略 |
| 高并发数据流 | 分布式采集架构(如Kafka分区分片) |
| 数据质量参差不齐 | 实时清洗(如Spark Streaming去噪) |
| 异构协议适配 | 开发多协议连接器(HTTP/SFTP/Modbus等) |
| 资源消耗优化 | 压缩传输(Snappy)、增量更新(CDC) |
3.1.6. 6. 数据采集典型应用场景
- 物联网(IoT):采集传感器数据(温度、GPS),用于智慧城市监控。
- 业务系统:同步订单数据(从MySQL到数据仓库)支持BI分析。
- 日志分析:实时收集Web服务器日志,用于异常检测(如ELK Stack)。
- 广告技术:聚合用户点击流数据,优化广告投放策略。
3.2. 数据计算层
数据计算层是数据处理架构中的核心组成部分,负责对原始数据进行加工、分析和计算,最终输出可用结果。以下从多个维度详细解析这一概念:
3.2.1. 数据计算定义与定位
位置:位于数据架构中层,连接数据存储层(如数据湖、数据仓库)与上层应用(如BI工具、业务系统)。
核心目标:将原始数据转化为业务价值,支撑实时分析、机器学习、报表生成等场景。
3.2.2. 数据计算核心功能
数据加工:清洗(去重、补全)、转换(格式标准化)、聚合(统计指标计算)。
复杂计算:机器学习模型训练、图计算、实时流处理。
资源调度:合理分配CPU、内存、GPU等资源,优化任务执行效率。
3.2.3. 数据计算技术方案
计算引擎
- 批处理:Apache Spark(内存计算)、Hadoop MapReduce(离线高吞吐)。
- 流处理:Apache Flink(低延迟)、Kafka Streams(实时管道)。
- 混合计算:Apache Beam(统一编程模型,支持批/流)。
任务调度
- 分布式调度:Airflow(DAG工作流)、DolphinScheduler(可视化编排)。
- 资源管理:YARN(Hadoop生态)、Kubernetes(容器化计算)。
数据接口
- SQL/API:支持标准SQL查询(Presto、ClickHouse),或通过REST API暴露计算结果。
3.2.4. 数据计算技术选型策略
| 场景 | 推荐技术 | 示例 |
| 离线批处理 | Spark、Flink(批模式) | 用户行为日志聚合分析 |
| 实时流处理 | Flink、Kafka + Flink CEP | 金融交易风控实时监测 |
| 机器学习训练 | TensorFlow、PyTorch + Horovod | 图像识别模型分布式训练 |
| Serverless轻量级计算 | AWS Lambda、Google Cloud Functions | 突发性小规模数据处理 |
3.2.5. 数据计算设计原则
扩展性:采用分布式架构(如K8s自动扩缩容),支持横向扩展。
容错性:检查点机制(Flink Savepoint)、任务重试策略。
性能优化:内存计算(Spark RDD)、向量化执行(Apache Arrow)。
成本控制:Spot实例(AWS)、存算分离(Snowflake架构)。
3.2.6. 数据计算典型应用场景
实时推荐系统:Flink实时处理用户点击流,更新推荐模型。
IoT数据分析:边缘节点预处理传感器数据,云端聚合分析。
基因测序:Spark分布式处理TB级基因序列数据。
3.2.7. 数据计算挑战与解决方案
数据倾斜:自定义分区策略、局部聚合(加盐处理)。
状态管理:使用RocksDB(Flink状态后端)处理超大状态。
延迟敏感场景:Flink窗口优化(增量聚合+会话窗口)。
3.3. 数据服务层
数据服务层是大数据系统架构中的核心环节,负责将底层存储与计算的数据资源转化为可被业务直接调用的标准化服务,同时解决数据易用性、稳定性、安全性等问题。以下是结合阿里巴巴实践的数据服务层核心要点:
3.3.1. 数据服务层核心目标
高效赋能业务:为内部员工、外部客户及合作伙伴提供统一、标准化的数据服务接口,降低数据使用门槛。
保障服务质量:确保数据服务的实时性、准确性、稳定性,支撑高并发业务场景(如双11实时数据披露)。
实现数据资产化:通过服务化将数据转化为可量化、可运营的资产,提升数据复用价值。
3.3.2. 数据服务架构设计要点
数据接入与整合
- 统一接入规范:制定标准化的数据接入协议,支持多源异构数据(日志、数据库、IoT设备等)的统一采集。
- 多源数据融合:整合离线(批处理)与实时(流处理)数据,构建全域数据视图。
数据处理与建模
- 分层数据模型:构建ODS(原始数据层)、DWD(明细数据层)、DWS(汇总数据层)、ADS(应用数据层)等分层体系,提升数据复用性。
- 实时与离线协同:通过Lambda或Kappa架构平衡实时计算(如Flink)与离线计算(如Hadoop)的协同效率。
服务化能力
- API网关管理:提供标准化API接口,支持SQL、RESTful等多种调用方式,实现数据服务的统一入口。
- 动态资源调度:基于容器化技术(如Kubernetes)弹性分配计算资源,应对突发流量(如双11支付峰值)。
安全与权限管控
- 精细化权限控制:基于RBAC(角色访问控制)模型,实现数据分级分类授权(如商家仅能访问自身数据)。
- 数据脱敏与加密:对敏感字段(如用户身份信息)进行动态脱敏,保障数据安全合规。
3.3.3. 数据服务关键技术挑战与解决方案
| 挑战 | 解决方案 |
| 高并发实时响应 | 使用内存计算技术(如Redis)、预计算(Cube)优化,实现PB级数据毫秒级响应。 |
| 数据一致性保障 | 通过分布式事务框架(如Seata)、数据校验规则引擎确保跨系统数据一致性。 |
| 服务性能瓶颈 | 引入缓存机制(如CDN、本地缓存)、异步处理(消息队列)提升吞吐量。 |
| 资源成本控制 | 动态资源调度(如弹性伸缩)、存储分层(热数据/冷数据分离)降低资源消耗。 |
3.3.4. 数据服务典型应用场景
内部赋能:
- 数据中台:为业务部门提供统一数据看板、BI工具,支持实时决策(如供应链优化)。
- 数据产品:开放“生意参谋”等数据产品,赋能商家运营分析。
外部开放:
- 数据市场:通过API或数据沙箱向合作伙伴提供脱敏数据,驱动生态协作(如广告投放优化)。
3.4. 数据应用层
数据应用层是大数据系统架构的“最后一公里”,直接面向业务场景和终端用户,将经过治理的数据转化为可感知、可操作的业务价值。其核心目标是通过数据驱动业务决策、优化运营效率、创新产品体验,是数据从“资源”转化为“生产力”的关键环节。以下是结合阿里巴巴实践的数据应用层核心内容:
3.4.1. 数据应用核心目标
业务赋能:将数据能力嵌入业务流程,支撑实时决策、精准营销、用户运营等场景。
体验升级:通过数据驱动产品智能化(如个性化推荐、智能客服),提升用户体验。
价值变现:对外输出数据服务(如数据市场、行业解决方案),实现数据商业化。
3.4.2. 数据应用主要功能与场景
业务决策支持
- 实时BI与可视化:通过数据看板(如阿里“数据大屏”)实时监控业务指标(如双11支付峰值、GMV)。支持多维度下钻分析,辅助管理层快速决策(如库存调配、流量分配)。
- 预测与预警:基于机器学习模型预测业务趋势(如销量预测、用户流失预警)。
用户端应用
- 个性化推荐:利用用户画像、协同过滤算法(如“猜你喜欢”)提升点击率与转化率。结合实时行为数据动态调整推荐策略(如淘宝“千人千面”)。
- 智能客服:基于NLP(自然语言处理)的智能问答(如阿里“小蜜”),降低人工客服成本。
商家端赋能
- 数据产品工具:提供“生意参谋”等数据产品,帮助商家分析市场趋势、优化商品运营。开放API接口,支持商家自主获取经营数据(如流量来源、转化漏斗)。
- 广告投放优化:基于RTB(实时竞价)模型,通过数据匹配实现精准广告投放(如阿里妈妈)。
生态协同应用
- 供应链优化:通过数据预测需求波动,优化库存与物流链路(如菜鸟网络智能分仓)。
- 智慧城市:城市交通流量预测、公共资源调度(如杭州“城市大脑”)。
3.4.3. 数据应用技术挑战与解决方案
| 挑战 | 解决方案 |
| 实时性要求高 | 流批一体架构(如Flink+Iceberg),实现秒级延迟的数据应用。 |
| 多源数据一致性 | 通过数据湖(Data Lake)统一存储,结合数据血缘追踪确保数据可信。 |
| 个性化与规模化矛盾 | 构建通用推荐框架(如X-DeepFM模型),支持大规模用户个性化需求。 |
| 隐私与合规风险 | 联邦学习(Federated Learning)实现数据“可用不可见”,满足GDPR等法规要求。 |
3.4.4. 数据应用典型应用案例
- 阿里巴巴内部:
-
- 双11大促:实时数据看板监控全球交易动态,动态调整服务器资源与营销策略。
- 聚划算:基于商品热度预测与用户兴趣匹配,实现活动商品的精准推荐。
- 外部合作:
-
- 数据市场:向企业提供脱敏后的行业趋势数据,辅助其战略规划。
- 金融风控:输出信用评估模型,助力金融机构降低坏账率。
4. 数据治理体系难点和重点
数据治理体系是企业在DT时代实现数据资产化、价值化的核心基础,但其建设面临复杂挑战,需平衡技术、管理与业务需求。以下是关键难点、重点及技术应用方向:
4.1. 数据治理体系的核心难点
数据规模与复杂性
- 挑战:EB级数据存储、千亿级实时记录、多源异构数据(日志、IoT、业务系统等)整合困难。
- 典型场景:阿里双11期间单日数据量超百亿级,需支持实时分析与历史回溯。
多源异构数据融合
- 挑战:数据来源分散(数据库、日志、第三方API),格式多样(结构化、半结构化、非结构化),语义不一致。
- 典型问题:同一实体(如用户)在不同系统中标识不一致,导致数据冗余与冲突。
实时性与一致性要求
- 挑战:高并发场景(如支付峰值)需毫秒级响应,同时保证跨系统数据一致性(如订单与库存同步)。
- 矛盾点:实时计算(流处理)与离线批处理的协同效率问题。
安全与隐私合规
- 挑战:数据泄露风险(如用户敏感信息)、GDPR/《数据安全法》等法规合规压力。
- 难点:如何在数据共享与隐私保护间平衡(如多方数据联合建模)。
技术与组织协同
- 挑战:技术架构复杂(分布式存储、微服务化),跨部门协作低效(如数据需求响应慢)。
- 典型矛盾:业务部门需求快速迭代 vs. 数据治理流程僵化。
4.2. 数据治理体系的核心重点
标准化与规范化
- 目标:建立统一数据模型、命名规范、质量标准,消除歧义。
- 实践:阿里数据中台的“OneData”体系,通过分层建模(ODS→DWD→DWS→ADS)实现全域数据标准化。
数据质量管控
- 目标:确保准确性、完整性、一致性、时效性。
- 方法:
-
- 规则引擎:定义数据质量规则(如字段非空、值域校验);
- 自动化检测:实时监控异常数据(如订单金额负值);
- 根因分析:通过血缘追踪定位问题源头(如上游ETL任务失败)。
安全与隐私保护
- 目标:实现数据“可用不可见”与合规使用。
- 技术:
-
- 动态脱敏:对敏感字段(如手机号)按角色动态掩码;
- 联邦学习:跨机构联合建模,避免原始数据出域;
- 区块链存证:记录数据操作日志,确保审计可追溯。
高效架构设计
- 目标:支持弹性扩展、高并发与低成本运维。
- 技术选型:
-
- 云原生架构:容器化(Kubernetes)+ 弹性伸缩(Auto Scaling)应对流量洪峰;
- 数据湖与湖仓一体:统一存储(如Hudi/Iceberg)支持批流一体,降低存储成本。
工具链与自动化
- 目标:降低人工干预,提升治理效率。
- 工具:
-
- 元数据管理平台:自动采集数据血缘、Schema变更;
- 数据开发IDE:一站式完成ETL开发、调试与部署;
- AI辅助治理:NLP自动生成数据字典,机器学习识别数据异常模式。
4.3. 数据治理技术上需重点
| 技术方向 | 核心作用 | 典型应用场景 |
| 实时计算引擎 | 支持低延迟、高吞吐的实时数据处理 | Flink处理双11支付峰值每秒12万笔交易实时统计 |
| 数据湖与湖仓一体 | 统一存储多源数据,支持批流协同分析 | 阿里云Data Lake Analytics实现PB级数据低成本存储与分析 |
| 数据血缘与图谱 | 追踪数据全生命周期,支持影响分析 | 阿里“数据血缘平台”自动解析表级/字段级依赖关系 |
| 自动化质量治理 | 减少人工巡检,提升数据可靠性 | 阿里“数据质量管家”自动拦截脏数据并触发告警 |
| 隐私计算技术 | 解决跨域数据协作中的隐私问题 | 蚂蚁链摩斯平台支持多方安全计算(MPC)建模 |
| AI驱动的智能运维 | 预测资源需求,优化集群性能 | 阿里云MaxCompute基于时序预测动态扩缩容 |
4.4. 数据治理技术落地的关键原则
- 业务驱动:治理目标需与业务场景强关联(如双11保障优先级高于日常治理)。
- 分层推进:从核心业务(如交易数据)切入,逐步扩展至全域数据。
- 技术组合:混合架构(如OLAP+OLTP)适配不同场景需求。
- 持续迭代:通过A/B测试验证治理效果,动态优化策略。
阿里巴巴实践启示:
- 数据中台:通过“OneEntity, OneID, OneService”实现数据资产化;
- 数据血缘平台:支持分钟级定位数据问题,降低运维成本30%+;
- 隐私计算:在金融风控领域实现数据“可用不可见”,坏账率下降15%。
核心结论:数据治理是技术、管理与业务的系统性工程,需以标准化为基础、智能化为手段、安全合规为底线,最终实现数据从“成本”到“资产”的跃迁。
博文参考
《阿里巴巴大数据实践》