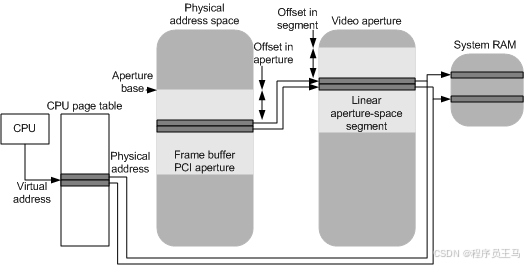
1、根据color分组统计销售数量
只执行聚合分组,不做复杂的聚合统计。在ES中最基础的聚合为terms,相当于
SQL中的count。
在ES中默认为分组数据做排序,使用的是doc_count数据执行降序排列。可以使用
_key元数据,根据分组后的字段数据执行不同的排序方案,也可以根据_count元数
据,根据分组后的统计值执行不同的排序方案。
1 GET /cars/_search
2 {
3 "aggs": {
4 "group_by_color": {
5 "terms": {
6 "field": "color",
7 "order": {
8 "_count": "desc"
9 }
10 }
11 }
12 }
13 }2、统计不同color车辆的平均价格
本案例先根据color执行聚合分组,在此分组的基础上,对组内数据执行聚合统
计,这个组内数据的聚合统计就是metric。同样可以执行排序,因为组内有聚合统
计,且对统计数据给予了命名avg_by_price,所以可以根据这个聚合统计数据字段名
执行排序逻辑。
1 GET /cars/_search
2 {
3 "aggs": {
4 "group_by_color": {
5 "terms": {
6 "field": "color",
7 "order": {
8 "avg_by_price": "asc"
9 }
10 },
11 "aggs": {
12 "avg_by_price": {
13 "avg": {
14 "field": "price"
15 }
16 }
17 }
18 }
19 }
20 }
size可以设置为0,表示不返回ES中的文档,只返回ES聚合之后的数据,提高查询速
度,当然如果你需要这些文档的话,也可以按照实际情况进行设置
1 GET /cars/_search
2 {
3 "size" : 0,
4 "aggs": {
5 "group_by_color": {
6 "terms": {
7 "field": "color"
8 },
9 "aggs": {
10 "group_by_brand" : {
11 "terms": {
12 "field": "brand",
13 "order": {
14 "avg_by_price": "desc"
15 }
16 },
17 "aggs": {
18 "avg_by_price": {
19 "avg": {
20 "field": "price"
21 }
22 }
23 }
24 }
25 }
26 }
27 }
28 }3、统计不同color不同brand中车辆的平均价格
先根据color聚合分组,在组内根据brand再次聚合分组,这种操作可以称为下钻
分析。
Aggs如果定义比较多,则会感觉语法格式混乱,aggs语法格式,有一个相对固定
的结构,简单定义:aggs可以嵌套定义,可以水平定义。
嵌套定义称为下钻分析。水平定义就是平铺多个分组方式。
1 GET /index_name/type_name/_search
2 {
3 "aggs" : {
4 "定义分组名称(最外层)": {
5 "分组策略如:terms、avg、sum" : {
6 "field" : "根据哪一个字段分组",
7 "其他参数" : ""
8 },
9 "aggs" : {
10 "分组名称1" : {},
11 "分组名称2" : {}
12 }
13 }
14 }
15 }
1 GET /cars/_search
2 {
3 "aggs": {
4 "group_by_color": {
5 "terms": {
6 "field": "color",
7 "order": {
8 "avg_by_price_color": "asc"
9 }
10 },
11 "aggs": {
12 "avg_by_price_color" : {
13 "avg": {
14 "field": "price"
15 }
16 },
17 "group_by_brand" : {
18 "terms": {
19 "field": "brand",
20 "order": {
21 "avg_by_price_brand": "desc"
22 }
23 },
24 "aggs": {
25 "avg_by_price_brand": {
26 "avg": {
27 "field": "price"
28 }
29 }
30 }
31 }
32 }
33 }
34 }
35 }4、统计不同color中的最大和最小价格、总价
1 GET /cars/_search
2 {
3 "aggs": {
4 "group_by_color": {
5 "terms": {
6 "field": "color"
7 },
8 "aggs": {
9 "max_price": {
10 "max": {
11 "field": "price"
12 }
13 },
14 "min_price" : {
15 "min": {
16 "field": "price"
17 }
18 },
19 "sum_price" : {
20 "sum": {
21 "field": "price"
22 }
23 }
24 }
25 }
26 }
27 }5、统计不同品牌汽车中价格排名最高的车型
在分组后,可能需要对组内的数据进行排序,并选择其中排名高的数据。那么可
以使用s来实现:top_top_hithits中的属性size代表取组内多少条数据(默认为
10);sort代表组内使用什么字段什么规则排序(默认使用_doc的asc规则排序);
_source代表结果中包含document中的那些字段(默认包含全部字段)。
1 GET cars/_search
2 {
3 "size" : 0,
4 "aggs": {
5 "group_by_brand": {
6 "terms": {
7 "field": "brand"
8 },
9 "aggs": {
10 "top_car": {
11 "top_hits": {
12 "size": 1,
13 "sort": [
14 {
15 "price": {
16 "order": "desc"
17 }
18 }
19 ],
20 "_source": {
21 "includes": ["model", "price"]
22 }
23 }
24 }
25 }
26 }
27 }
28 }6、histogram 区间统计
histogram类似terms,也是进行bucket分组操作的,是根据一个field,实现数据
区间分组。
如:以100万为一个范围,统计不同范围内车辆的销售量和平均价格。那么使用
histogram的聚合的时候,field指定价格字段price。区间范围是100万-interval :
1000000。这个时候ES会将price价格区间划分为: [0, 1000000), [1000000,
2000000), [2000000, 3000000)等,依次类推。在划分区间的同时,histogram会类似
terms进行数据数量的统计(count),可以通过嵌套aggs对聚合分组后的组内数据做
再次聚合分析。
1 GET /cars/_search
2 {
3 "aggs": {
4 "histogram_by_price": {
5 "histogram": {
6 "field": "price",
7 "interval": 1000000
8 },
9 "aggs": {
10 "avg_by_price": {
11 "avg": {
12 "field": "price"
13 }
14 }
15 }
16 }
17 }
18 }7、date_histogram区间分组
date_histogram可以对date类型的field执行区间聚合分组,如每月销量,每年销
量等。
如:以月为单位,统计不同月份汽车的销售数量及销售总金额。这个时候可以使
用date_histogram实现聚合分组,其中field来指定用于聚合分组的字段,interval指
定区间范围(可选值有:year、quarter、month、week、day、hour、minute、
second),format指定日期格式化,min_doc_count指定每个区间的最少document(如
果不指定,默认为0,当区间范围内没有document时,也会显示bucket分组),
extended_bounds指定起始时间和结束时间(如果不指定,默认使用字段中日期最小值
所在范围和最大值所在范围为起始和结束时间)。
1 ES7.x之前的语法
2 GET /cars/_search
3 {
4 "aggs": {
5 "histogram_by_date" : {
6 "date_histogram": {
7 "field": "sold_date",
8 "interval": "month",
9 "format": "yyyy‐MM‐dd",
10 "min_doc_count": 1,
11 "extended_bounds": {
12 "min": "2021‐01‐01",
13 "max": "2022‐12‐31"
14 }
15 },
16 "aggs": {
17 "sum_by_price": {
18 "sum": {
19 "field": "price"
20 }
21 }
22 }
23 }
24 }
25 }
26 执行后出现
27 #! Deprecation: [interval] on [date_histogram] is deprecated, use [fixed_inter
val] or [calendar_interval] in the future.
28
29 7.X之后
30 GET /cars/_search
31 {
32 "aggs": {
33 "histogram_by_date" : {
34 "date_histogram": {
35 "field": "sold_date",
36 "calendar_interval": "month",
37 "format": "yyyy‐MM‐dd",
38 "min_doc_count": 1,
39 "extended_bounds": {
40 "min": "2021‐01‐01",
41 "max": "2022‐12‐31"
42 }
43 },
44 "aggs": {
45 "sum_by_price": {
46 "sum": {
47 "field": "price"
48 }
49 }
50 }
51 }
52 }
53 }8、_global bucket
在聚合统计数据的时候,有些时候需要对比部分数据和总体数据。
如:统计某品牌车辆平均价格和所有车辆平均价格。global是用于定义一个全局
bucket,这个bucket会忽略query的条件,检索所有document进行对应的聚合统计。
GET /cars/_search
2 {
3 "size" : 0,
4 "query": {
5 "match": {
6 "brand": "大众"
7 }
8 },
9 "aggs": {
10 "volkswagen_of_avg_price": {
11 "avg": {
12 "field": "price"
13 }
14 },
15 "all_avg_price" : {
16 "global": {},
17 "aggs": {
18 "all_of_price": {
19 "avg": {
20 "field": "price"
21 }
22 }
23 }
24 }
25 }
26 }9、aggs+order
对聚合统计数据进行排序。
如:统计每个品牌的汽车销量和销售总额,按照销售总额的降序排列。
1 GET /cars/_search
2 {
3 "aggs": {
4 "group_of_brand": {
5 "terms": {
6 "field": "brand",
7 "order": {
8 "sum_of_price": "desc"
9 }
10 },
11 "aggs": {
12 "sum_of_price": {
13 "sum": {
14 "field": "price"
15 }
16 }
17 }
18 }
19 }
20 }
如果有多层aggs,执行下钻聚合的时候,也可以根据最内层聚合数据执行排序。
如:统计每个品牌中每种颜色车辆的销售总额,并根据销售总额降序排列。这就像
SQL中的分组排序一样,只能组内数据排序,而不能跨组实现排序。
1 GET /cars/_search
2 {
3 "aggs": {
4 "group_by_brand": {
5 "terms": {
6 "field": "brand"
7 },
8 "aggs": {
9 "group_by_color": {
10 "terms": {
11 "field": "color",
12 "order": {
13 "sum_of_price": "desc"
14 }
15 },
16 "aggs": {
17 "sum_of_price": {
18 "sum": {
19 "field": "price"
20 }
21 }
22 }
23 }
24 }
25 }
26 }
27 }10、search+aggs
聚合类似SQL中的group by子句,search类似SQL中的where子句。在ES中是完全可
以将search和aggregations整合起来,执行相对更复杂的搜索统计。
如:统计某品牌车辆每个季度的销量和销售额。
1 GET /cars/_search
2 {
3 "query": {
4 "match": {
5 "brand": "大众"
6 }
7 },
8 "aggs": {
9 "histogram_by_date": {
10 "date_histogram": {
11 "field": "sold_date",
12 "calendar_interval": "quarter",
13 "min_doc_count": 1
14 },
15 "aggs": {
16 "sum_by_price": {
17 "sum": {
18 "field": "price"
19 }
20 }
21 }
22 }
23 }
24 }11、filter+aggs
在ES中,filter也可以和aggs组合使用,实现相对复杂的过滤聚合分析。
如:统计10万~50万之间的车辆的平均价格。
1 GET /cars/_search
2 {
3 "query": {
4 "constant_score": {
5 "filter": {
6 "range": {
7 "price": {
8 "gte": 100000,
9 "lte": 500000
10 }
11 }
12 }
13 }
14 },
15 "aggs": {
16 "avg_by_price": {
17 "avg": {
18 "field": "price"
19 }
20 }
21 }
22 }12、聚合中使用filter
filter也可以使用在aggs句法中,filter的范围决定了其过滤的范围。
如:统计某品牌汽车最近一年的销售总额。将filter放在aggs内部,代表这个过滤器
只对query搜索得到的结果执行filter过滤。如果filter放在aggs外部,过滤器则会过
滤所有的数据。
12M/M 表示 12 个月。
1y/y 表示 1年。
d 表示天
1 GET /cars/_search
2 {
3 "query": {
4 "match": {
5 "brand": "大众"
6 }
7 },
8 "aggs": {
9 "count_last_year": {
10 "filter": {
11 "range": {
12 "sold_date": {
13 "gte": "now‐12M"
14 }
15 }
16 },
17 "aggs": {
18 "sum_of_price_last_year": {
19 "sum": {
20 "field": "price"
21 }
22 }
23 }
24 }
25 }
26 }