许多大模型具有推理参数,用于控制输出的“随机性”。常见的几个是 Top-K、Top-p,以及温度。
Top-p:
含义:Kernel sampling threshold. Used to determine the randomness of the results. The higher the value, the stronger the randomness. The higher the possibility of getting different answers to the same question.
核采样阈值。用于决定结果的随机性。值越高,随机性越强。对于同一个问题,得到不同答案的可能性越高。
温度:
含义:The probability threshold of the nucleus sampling method during the generation process. The larger the value is, the higher the randomness of generation will be. The smaller the value is, the higher the certainty of generation will be.
在生成过程中,核采样方法的概率阈值。值越大,生成的随机性越高。值越小,生成的确定性越高。
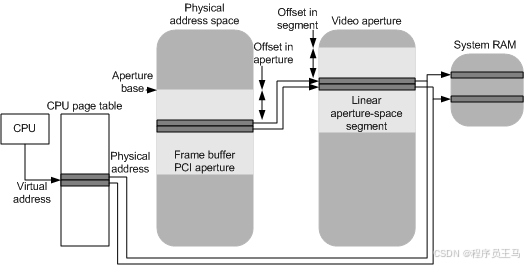
LLM 输出概率分布
LLM 通常对一系列 token 进行操作,这些token可以是单词、字母或子词单元。操作后得到的 token 集,称为 LLM 的词汇表。
LLM 接收一个输入的 token 序列,然后尝试预测下一个 token。它通过使用 Softmax函数作为网络的最后一层,为所有可能的 token 生成离散概率分布来实现此目的。这是 LLM 的原始输出。
例如,如果我们的词汇量为 5,则输出可能如下所示(大多数 LLMs 的词汇量显然要大得多):
t0→0.4
t1→0.2
t2→0.2
t3→0.15
t4→0.05
由于这是一个概率分布,因此所有值的总和为 1。一旦我们有了这个概率分布,我们就可以决定如何从中采样,这就是 Top-K 和 Top-p 的作用所在。
小记:Top-K 和 Top-p 是两种不同的采样方法。
Top-K 采样
Top-K 采样的工作原理如下:
按概率的降序排列token。
选择前 K 个 token 来创建新的分布。
从这些 token 中抽取样本。
例如,假设使用上述示例中的 Top-3 策略进行采样。排名前 3 的是:
t0→0.4
t1→0.2
t2→0.2
但是,概率加起来不再等于 1 ,所以必须用前 3 个 token 的总和来进行规一化。我们将每个概率除以 0.4+0.2+0.2=0.8,得到前 3 个 token 的新概率分布:
t0→0.5
t1→0.25
t2→0.25
现在可以通过从中采样来选择一个 token。
如果设置 K=1,那么会得到所谓的贪婪策略,因为总是选择最可能的token。
Top-p 采样
这种策略(也称为核采样,英文通常为 Nucleus sampling 或 Kernel sampling)与 Top-K 类似,但我们不是选择一定数量的 token,而是选择足够多的 token 来“覆盖”由参数 p 定义的一定概率,方式如下:
按概率的降序排列 token。
选择最少数量的顶级 token,使得它们的累积概率至少为 p。
从这些 token 中抽取样本。
例如,假设我们使用 p=0.5 和 top-p 策略进行采样,同样取自上述示例。该过程如下:
最上面的 token t0 被选中。它的概率是 0.4,我们的累积概率也是 0.4。
累积概率小于 p=0.5 ,因此我们选择下一个token。
下一个token t1 的概率为 0.2,现在我们的累积概率为 0.6。
累积概率至少为 p=0.5 的值,因此我们停止。
结果是只有前 2 个 token 被选中:
t0→0.4
t1→0.2
再次,我们必须通过除以总和 0.4+0.2=0.6 来对概率进行归一化,得到:
t0→0.67
t1→0.33
我们现在可以从该分布中采样,就像之前使用 Top-K 所做的那样。
再次理解核采样的定义
核采样只关注概率分布的核心部分,而忽略了尾部部分。因为它只关注概率分布的核心部分,而忽略了尾部部分。
例如,如果 p=0.9,那么我们只从累积概率达到 0.9 的最小单词集合中选择一个单词,而不考虑其他累积概率小于 0.9 的单词。 这样可以避免采样到一些不合适或不相关的单词,同时也可以保留一些有趣或有创意的单词。
Top-p 值通常设置为比较高的值(如0.75),目的是限制低概率 token 的长尾。
温度对采样的影响
温度会影响模型输出的“随机性”,其作用与前两个参数不同。虽然 Top-K 和 Top-p 直接作用于输出概率,但温度会影响 Softmax 函数本身,因此需要简要回顾一下其工作原理。
也即:温度影响的环节,更靠前一些。
Softmax 函数接收一个由 n 个实数组成的向量,然后将其标准化为这 n 个元素的离散概率分布,且概率的总和为 1。标准 Softmax 函数定义如下:
该函数应用于输入向量
中的每个元素,以生成相应的输出向量。即:
指数函数应用于元素
。
然后将结果值通过所有元素
的指数和进行归一化。这确保了结果值的总和为 1,从而使输出向量成为概率分布。
除了将输出转换为概率分布之外,Softmax还会改变每个元素之间的相对差异。Softmax函数的效果取决于输入元素的范围
:
如果被比较的两个输入元素都是
< 1,那么它们之间的差异就会缩小。
如果被比较的元素中至少有一个大于 1,那么它们之间的差异就会被放大。这可以使模型对预测更加“确定”。
这可以使模型对预测更加“确定”。这句话怎么理解呢?
简单理解就是:不同 token 之间的差异越大,那么模型输出时,总是倾向于选择头部 token,自然就表现得更为“确定”。
我们看看这个标准 Softmax函数的输入和输出值,看看相对差异是如何改变的。当输入值小于 1 时,输出值的相对差异会减小:
可见,温度 T 的值越小,输入值之间的差异就越大。相反,温度 T 的值越大,差异就越小。
还可以考虑极端情况下发生的情况,以更直观地了解温度如何影响输出:
如果是 T 趋近于 0,那么我们将处理极大的指数,因此具有最大值的
元素将占主导地位,即它的概率将接近 1,而所有其他元素的概率将接近 0。这相当于一种贪婪策略,其中始终选择顶部token,非常“确定”。
如果是 T 趋近无穷大 ∞,则指数全部变为
= 1,这会使输出变为均匀分布,即所有概率变为
。也就是说,所有token的概率都相等。当然,这显然不再是一个有用的模型。
本质上,温度会改变概率分布的形状。随着温度升高,概率差异会减小,从而导致模型输出更“随机”。这表现为 LLM 输出更具“创造性”。相反,较低的温度会使输出更具确定性。
顺便说一句,该参数之所以被称为“温度”,与热力学中的概念有关:在较高温度下,气体或流体的浓度会比在低温下扩散(扩散)得更快。
总结
Top-K、Top-p 和温度都是影响生成token方式的推理参数,它们都作用于大模型的输出概率分布。
Top-K 和 Top-p 均为采样策略。它们并非特定于 LLMs,甚至根本不特定于神经网络。它们只是从离散概率分布中采样的方法。
Top-K 将我们要考虑的特定token限制为一定数量(K)。
Top-p 将我们限制在特定的累积概率 ( p ) 内。
相比之下,温度的作用方式不同:
温度不是一种采样策略,而是网络最后一层的 Softmax 函数的一个参数。
温度影响概率分布的形状。
高温使 token 概率彼此接近,这使得输出更加随机、“有创意”。
低温通过放大概率差异,这使得输出更加确定。
文本生成场景
假设我们使用一个大语言模型(LLM)来续写句子“今天天气不错,我打算”。
低温情况(输出更确定):当温度设置得较低时,比如 0.2,模型会更倾向于选择概率最高的词来完成句子。由于模型经过大量训练,对于这种常见场景,有一些比较“主流”的后续表述概率会很高。所以可能输出“今天天气不错,我打算去公园散步”。这是因为在低温下,模型会优先选择那些在训练数据中与前文搭配最频繁、概率最大的表述,结果比较固定和可预测。
高温情况(输出更随机):当温度设置得较高,例如 1.5 时,模型输出的随机性就会大大增加。此时模型可能会输出“今天天气不错,我打算去外太空探险”。在正常的认知和常见表述中,“去外太空探险”和前文“今天天气不错”的搭配并不常见,但在高温下,模型有更大的可能性选择那些概率相对较低的词来组成句子,从而产生一些意想不到、更具创造性但可能不太符合常规逻辑的结果,表现得更加随机。
故事创作场景
让模型创作一个简短的童话故事开头,句子为“在一个神秘的森林里”。
低温设置:模型可能输出“在一个神秘的森林里,住着一只善良的小兔子,它每天都会去森林里采蘑菇”。这种输出遵循了常见的童话故事套路,因为低温使得模型选择了那些在训练数据中经常出现的、概率较大的元素来构建故事,结果比较常规和确定。
高温设置:模型或许会输出“在一个神秘的森林里,突然出现了一个会说话的仙人掌,它说自己来自另一个星球”。这种结果与常见的童话故事开头差异很大,高温让模型突破了常规的选择,增加了输出的随机性和创造性,可能会给人带来新奇的感觉,但同时也可能会偏离传统的故事逻辑。
对话回复场景
在一个对话中,用户问“你觉得周末怎么过比较好”。
低温状态:模型可能回复“周末可以选择在家休息,看看电影、读读书,或者约上朋友去外面吃顿饭”。这是比较常见、常规的周末安排建议,是模型基于大量对话数据中概率较高的回复内容生成的,比较确定。
高温状态:模型可能给出“周末可以去山顶上倒立看星星,说不定能看到外星人的飞船”。这种回复打破了常规的周末活动建议,是模型在高温下随机选择一些不太常见的元素组合而成的,具有很强的随机性和创造性,但可能不太符合实际的生活场景。
为了更直观地解释为什么温度高会导致语言生成变得更随机,我们可以从概率分布的角度来理解这个问题。让我们以一个简单的例子来说明。
假设我们有一个模型需要根据前面的上下文“我最喜欢的颜色是”来预测下一个词。在这个例子中,可能的选项有“红色”,“蓝色”,“绿色”,以及一些不太常见的颜色如“橙色”。模型会为每个词分配一个分数,然后通过Softmax函数将这些分数转换成概率。在没有温度参数的情况下(即温度T=1),假设得到的概率分布如下:
- 红色: 0.5
- 蓝色: 0.3
- 绿色: 0.15
- 橙色: 0.05
这意味着模型认为“红色”是最有可能的选择,“蓝色”次之,“绿色”再次之,“橙色”最不可能被选择。
温度的作用
当我们将温度参数引入时,这个概率分布会发生变化。具体来说,温度T会影响Softmax函数中的指数部分,从而改变最终的概率分布。
低温情况 (T < 1)
如果温度设置得很低,比如T=0.5,那么高概率的词(如“红色”)会变得更加突出,而低概率的词(如“橙色”)的概率会被进一步压缩。新的概率分布可能看起来像这样:
- 红色: 0.7
- 蓝色: 0.2
- 绿色: 0.08
- 橙色: 0.02
在这种情况下,模型几乎总是会选择“红色”,因为它的概率远高于其他选项。这使得输出更加确定和可预测。
高温情况 (T > 1)
相反,如果温度设置得较高,例如T=2,那么所有词的概率都会变得更加接近。新的概率分布可能变为:
- 红色: 0.4
- 蓝色: 0.3
- 绿色: 0.2
- 橙色: 0.1
现在,“红色”仍然是最有可能的选择,但“蓝色”、“绿色”甚至“橙色”都有了更高的机会被选中。这增加了输出的多样性,使模型的行为更加随机和不可预测。
极端情况
-
温度趋近于0:当温度非常低时,只有具有最高原始分数的词会被赋予接近1的概率,其余词的概率接近0。这相当于一种贪婪策略,模型总是选择当前看来最好的词。
-
温度趋近于无穷大:当温度非常高时,所有词的概率趋于相等,模型的选择变得完全随机,不再依赖于原始分数的差异。
总结来说,温度参数通过调整Softmax函数的输出,控制了模型生成文本时的确定性和随机性。较高的温度值会平滑概率分布,增加低概率词被选择的机会,从而使生成的文本更具多样性和创造性;而较低的温度值则会使模型倾向于选择高概率词,生成更保守、更可预测的文本。