RoboGround 论文
一类中间表征是语言指令,但对于空间位置描述过于模糊(“把杯子放桌上”但不知道放桌上哪里);另一类是目标图像或点流,但是开销大;由此 GeoDEX 提出一种兼具二者的掩码。
相比于 GR-1,通过分割算法,提出了局部 Mask,以及相应的坐标,增强了空间理解。
现有的语言条件下的仿真数据集常常存在物体和环境多样性不足,或者缺乏广泛的指令和复杂场景,基于 RoboCasa 引入一种自动化数据生成流程。

数据集
在 Objaverse 中借助 GPT-4o,筛选并识别出1)适合桌面使用的物品;2)与厨房相关的物品;3)排除多件物品组合;再经过人工审核,挑选出 1017 个高质量桌面操作物体。
原有的语言条件数据集:指令格式固定——模型只需要学习指令到任务的映射,无需深入理解指令,导致泛化能力差。
- Appearance——从 4 个视角(正面、背面、左侧和右侧)渲染每个物体,由此组合成一张综合图像,再用 GPT-4 提取特征(颜色、材质、形状等),随机选取一个作为物体特征并过滤掉场景中包含该特征的其他物体。然后通过 CLIP 选择干扰物。(选取一组代表物,通过他们学习别的特征混合的物体)
- Spatial——指定物体以及位置坐标的指令。
- Commonsense——使用 GPT-4 为每个任务提供机器人的视角图像(左侧、右侧和手部视角),以及目标物体及其预期位置的详细信息。(传统:把红色的杯子从桌子上拿起来;常识:把杯子从桌子上拿起来)

定位视觉语言模型
-
y
t
=
L
(
f
v
(
C
L
I
P
(
x
v
)
)
,
x
t
)
y_t=L(f_v(CLIP(x_v)),x_t)
yt=L(fv(CLIP(xv)),xt) 模型通过一个提示来感知图像,提示的格式为:“The
<IMAGE>provides an overview of the picture”。其中<IMAGE>标记被替换为投影后的视觉特征,表示为256个标记的序列。 - 在定位头中,采用预训练的 SAM 编码器,解码器类似 SAM 解码器架构。在 LLM 的词汇表中引入
<SEG>提取与定位相关特征。由此生成二进制掩码: M = D ( f s ( F s e g , E ( x v ) ) ) M=D(f_s(F_{seg},E(x_v))) M=D(fs(Fseg,E(xv)))
其中 f v , f s f_v,f_s fv,fs 为投影器, F s e g F_{seg} Fseg 为<SEG>标记对应的最后一层嵌入。
采用 GR-1 架构。
掩码为机器人的策略提供了有用的空间引导。与其要求明确地将语义描述定位到具体物体上,策略网络可以专注于利用这种结构化信息来改进物体定位和动作执行。
视觉特征
Z
v
∈
R
197
×
D
v
Z_v \in \mathbb{R}^{197×D_v}
Zv∈R197×Dv :
Z
v
=
V
i
T
M
A
E
(
L
i
n
e
a
r
(
C
o
n
c
a
t
(
x
v
,
M
o
,
M
p
)
)
)
Z_v=ViTMAE(Linear(Concat(x_v,M_o,M_p)))
Zv=ViTMAE(Linear(Concat(xv,Mo,Mp))),
M
o
M_o
Mo 为目标物体掩码,
M
p
M_p
Mp 为放置区域掩码。同时
Z
v
Z_v
Zv 还包含 CLS 特征
Z
C
L
S
v
∈
R
1
×
D
v
Z_{CLS}^v\in R^{1×D_v}
ZCLSv∈R1×Dv ,一组局部 patch
Z
v
P
∈
R
196
×
D
Z_v^P \in R^{196×D}
ZvP∈R196×D。
语言输入通过 CLIP 编码为
Z
t
Z_t
Zt,机器人状态
x
t
x_t
xt 通过 MLP 投影为
Z
s
Z_s
Zs,以及一个可学习的动作标记
Z
a
c
t
Z_{act}
Zact。
在 GR-1 中,Perceiver 作为一个标记重组器,通过在一组可学习的查询标记和初始视觉特征之间进行迭代注意力层来减少从初始视觉特征中派生的特征数量。本文将注意力引导至掩码所在的区域,引入两组额外标记:
Q
o
Q_o
Qo 用于目标物体,
Q
p
Q_p
Qp 用于放置物体,在每个注意力层中,他们与
Z
v
P
Z_v^P
ZvP 相互作用,注意力通过掩码
M
o
M_o
Mo 和
M
p
M_p
Mp 引导。
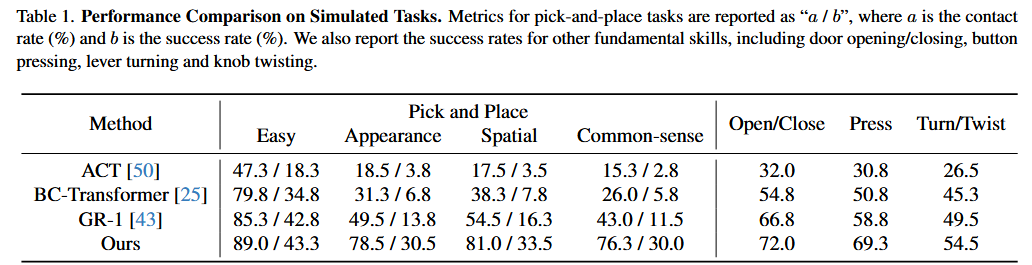
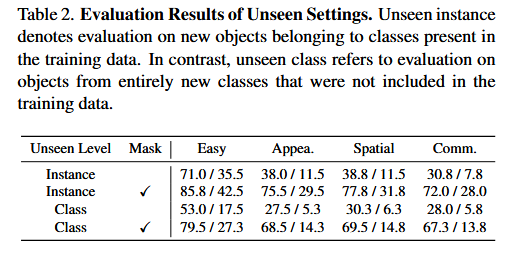
实验结果




![[Java实战]Spring Boot 整合 Freemarker (十一)](https://i-blog.csdnimg.cn/direct/fa803baa80044fb2a9d9cb5fa25ce96d.png#pic_center)