一、引言
在大模型微调中,数据质量直接决定模型性能。LLaMA-Factory提供了完整的数据工程工具链,支持从数据格式规范到清洗增强、注册验证的全流程管理。本文结合结构图、实战代码和生产级经验,带您掌握构建高质量数据集的核心技术。
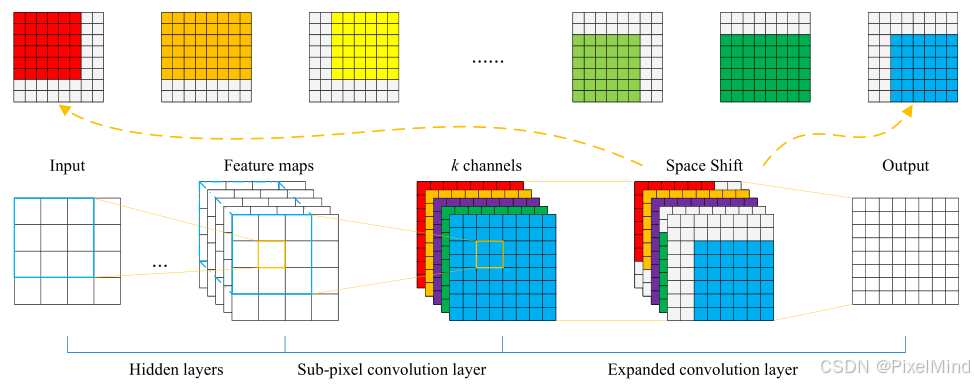
二、数据工程核心架构图
三、数据格式规范:定义微调数据的“通用语言”
1. 指令微调数据(Alpaca格式)
核心结构(三元组):
{
"instruction": "用户需求描述", // 任务指令(如“生成SQL查询”)
"input": "任务相关输入(可选)", // 上下文信息(如数据库表结构)
"output": "期望的模型输出" // 正确响应(如具体SQL语句)
}
代码示例(生成标准Alpaca数据):
from llamafactory.data.formatter import AlpacaFormatter
# 原始数据列表
raw_data = [
("生成Python代码", "计算斐波那契数列", "def fib(n): ..."),
("翻译英文", "Hello world", "你好,世界")
]
# 格式转换
formatter = AlpacaFormatter()
alpaca_data = formatter.convert(raw_data)
with open("alpaca_data.json", "w") as f:
f.write(json.dumps(alpaca_data, indent=2))
2. 多模态数据支持
图像-文本对格式:
{
"text": "描述图片中的物体", // 文本指令
"image": "path/to/image_001.jpg", // 图像文件路径(支持JPEG/PNG)
"output": "图片中有一只站立的金毛犬" // 多模态输出
}
音频-文本对格式:
{
"text": "将语音转换为文字", // 文本指令
"audio": "path/to/audio_clip.wav", // 音频文件路径(支持WAV/MP3)
"output": "欢迎使用LLaMA-Factory" // 语音识别结果
}
四、数据清洗与增强:打造高价值训练数据
1. 去重与过滤(提升数据纯净度)
① 基于相似度去重
from llamafactory.data.cleaner import Deduplicator
# 初始化去重器(阈值0.8,使用Sentence-BERT计算相似度)
deduplicator = Deduplicator(threshold=0.8, model_name="all-MiniLM-L6-v2")
# 加载原始数据
with open("raw_data.json", "r") as f:
data = json.load(f)
# 去重处理
clean_data = deduplicator.process(data)
print(f"去重后数据量:{len(clean_data)}(原始{len(data)}条)")
② 噪声过滤规则
# 定义过滤函数(移除包含敏感词或过短的样本)
def filter_function(sample):
if len(sample["output"]) < 10: return False # 输出长度小于10字符
if "禁止内容" in sample["instruction"]: return False # 包含敏感词
return True
# 应用过滤
filtered_data = [sample for sample in clean_data if filter_function(sample)]
2. 合成数据生成(解决数据稀缺问题)
使用GraphGen工具生成领域数据
# 安装GraphGen(知识图谱驱动的数据生成工具)
pip install graphgen-toolkit
from graphgen import GraphGenerator
# 初始化(加载金融领域知识图谱)
generator = GraphGenerator(knowledge_graph="financial_kg.json")
# 生成1000条财报分析数据
synthetic_data = generator.generate(
num_samples=1000,
template="分析{公司} {年份}财报中的{指标}趋势",
entities=["Apple", "2023", "营收"]
)
# 保存为Alpaca格式
with open("financial_synthetic.json", "w") as f:
f.write(json.dumps(synthetic_data, indent=2))
五、数据集注册与验证:确保数据可用合规
1. 数据集注册(配置文件定义)
在data/dataset_info.json中声明数据集:
{
"medical_qa": {
"file_path": "data/medical/qa.json", // 数据文件路径
"format": "alpaca", // 数据格式(alpaca/多模态/custom)
"columns": ["instruction", "input", "output"], // 字段列表
"description": "医学问答数据集(包含5万条样本)"
},
"multimodal_data": {
"file_path": "data/multimodal/data.json",
"format": "multimodal",
"columns": ["text", "image", "output"]
}
}
2. 数据验证(命令行工具)
① 格式校验
# 校验单个数据集
llamafactory-cli validate dataset --name medical_qa
# 校验多模态数据集(指定格式)
llamafactory-cli validate dataset --name multimodal_data --format multimodal
② 质量评估(统计指标)
# 生成数据质量报告
llamafactory-cli analyze dataset --name medical_qa --output report.html
③ 自动修复(可选)
from llamafactory.data.fixer import DataFixer
fixer = DataFixer(dataset_name="medical_qa")
fixed_data = fixer.autorepair() # 自动修复格式错误(如缺失字段补全)
六、生产级数据处理案例:医疗领域数据集构建
1. 数据处理流水线
- 原始数据:爬取PubMed论文(10万篇)+ 医院问诊记录(5万条)
- 格式转换:将非结构化文本转为Alpaca格式(使用正则表达式提取“问题-解答”对)
- 清洗步骤:
- 去除重复率>80%的样本(保留20万条)
- 过滤包含未标注疾病术语的样本(保留15万条)
- 增强操作:使用GraphGen合成5万条罕见病案例数据
- 注册验证:通过
dataset_info.json注册,命令行校验通过率100%
2. 关键命令汇总
# 格式转换(Python脚本)
python scripts/convert_medical_data.py --input pubmed_raw.json --output medical_alpaca.json
# 批量去重(命令行)
llamafactory-cli deduplicate --input medical_alpaca.json --output cleaned_medical.json --threshold 0.8
# 注册并验证
echo '{"medical_qa": {"file_path": "cleaned_medical.json", "format": "alpaca"}}' > data/dataset_info.json
llamafactory-cli validate dataset --name medical_qa
七、总结
数据工程是大模型微调的“地基”,LLaMA-Factory通过标准化格式、智能化清洗和自动化验证,大幅降低数据处理成本。本文重点实践:
- 格式规范:掌握Alpaca/多模态数据结构,支持复杂任务建模
- 清洗增强:利用相似度去重和GraphGen合成,解决数据质量与数量问题
- 注册验证:通过配置文件和命令行工具,确保数据可用合规
下一步建议:
- 从官方数据仓库获取各领域数据集模板
- 在Jupyter Notebook中交互式调试数据处理流程
- 结合Web UI进行数据可视化预览(后续教程详解)
通过高效的数据工程,开发者能为模型微调提供“优质燃料”,显著提升垂直领域任务性能。后续教程将深入模型微调核心技术,敬请关注!