文章目录
- TLDR;
- 量化分类
- 量化时机
- 量化粒度
- ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
- 细粒度硬件感知量化
- 低成本逐层知识蒸馏(Layer-by-layer Knowledge Distillation, LKD)
- LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
- SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
- 量化维度
- 激活平滑
- 量化效果
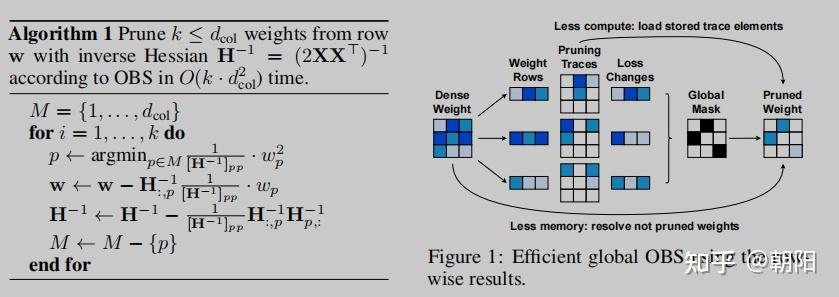
- OBS(Optimal Brain Surgeon)
- OBQ(Optimal Brain Quantization)
- 优化1:使用L2重建量化损失
- 优化2:行并行与递归求解 H − 1 H^{-1} H−1
- 算法实现
- GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
- 步骤1: 任意顺序量化(Arbitrary Order Insight)
- 步骤2: 批量量化(Lazy Batch-Updates)
- 步骤3: Cholesky矩阵分解(Cholesky Reformulation)
- 算法过程
- AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
- 保留1%重要性参数可提升量化性能
- 激活感知缩放保护重要权重
参考论文
- 2022.01 - ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
- 2022.08 - LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
- 2022-10 - GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
- 2022.11 - SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
- 2023.06 - AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
参考文章
- LLM 量化技术小结
- OBS: LLM模型量化世界观(上)
- 真的从头到尾弄懂量化之GPTQ
TLDR;
ZeroQuant 对权重使用group-wise量化,对激活采用dynamic per-token量化,并实现fusion kernel,加速量化。同时,设计了逐层知识蒸馏LKD,进一步提高量化精度。
LLM.int() 验证了尺寸大于6.7B模型激活值中的离群点对模型性能影响的显著性,它根据启发式规则(激活值较大并且存在于一定比例的网络层和序列中)找到离群特征,采用混合精度(离群FP16、其他INT8)量化。
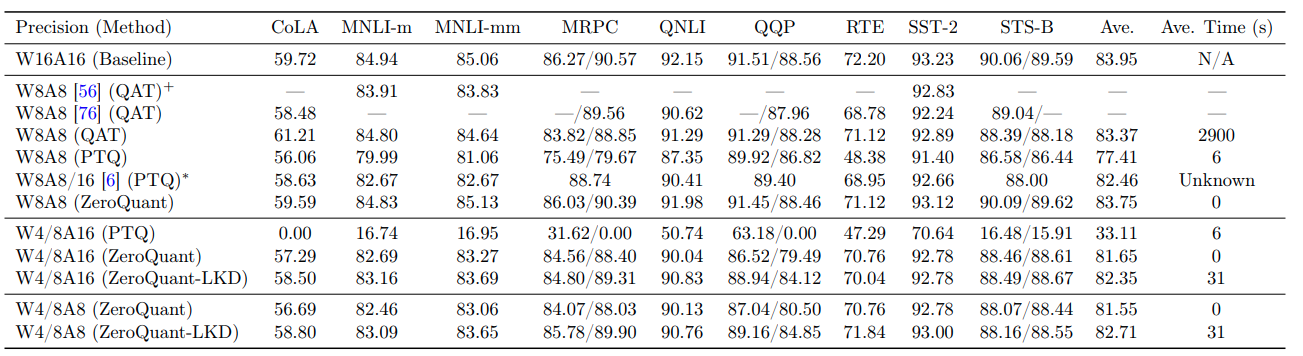
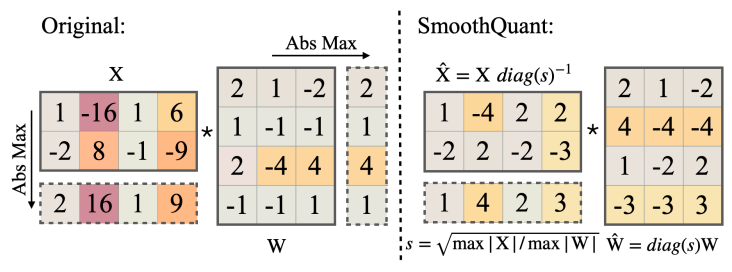
SmoothQuant发现激活中存在离群点,导致方差比较大,比权重难量化。发现离群特征在不同token之间的方差比较小,但由于硬件加速内核的限制,无法在矩阵运算内围进行缩放。使用数学变换 ( X diag ( s ) − 1 ) ⋅ ( diag ( s ) W ) (\mathbf X\text{diag}(\mathbf s)^{-1})\cdot(\text{diag}(\mathbf s)\mathbf W) (Xdiag(s)−1)⋅(diag(s)W),将激活的量化难度转移到权重,同时还能使用高效的GeMM内核。
OBS属于剪枝算法,利用二阶导数信息贪婪地一步一步移除剪枝损失最小的权重,剪枝损失约为 0.5 ∗ δ w ⊤ H δ w 0.5*\delta_w^\top H\delta_w 0.5∗δw⊤Hδw。每次移除一个权重后,更新其他未剪枝的权重,以补偿剪枝带来的损失。
OBQ将OBS应用到模型量化,将量化损失重构为量化激活的L2损失,损失近似为 0.5 ∗ ( quant ( w ) − w ) 2 / H q q − 1 0.5*{(\text{quant}(w) - w)^2}/{H_{qq}^{-1}} 0.5∗(quant(w)−w)2/Hqq−1,也就是说,优先选择量化后权重数值变化小、Hessian对角元素比较小(通常对应的逆比较大)的权重。同时使用迭代方式更新 H − 1 H^{-1} H−1,降低量化后更新Hessian逆矩阵的时间复杂度。
GPTQ不是RTN簇量化算法(缩放到紧邻整数,如LLM.int8()、SmoothQuant、AWQ等),它是对OBQ的改进,认为OBS、OBQ贪婪依次选择剪枝/量化误差比较小的权重和随机选择权重相比,最终的量化性能差异不大,可能的原因是OBQ中影响较大的权重都留在比较靠后的位置才量化,而此时能补偿量化误差的参数所剩无几,因此参数的量化顺序没那么重要。GPTQ采用从左到右分组的固定顺序量化,并对Hessian逆矩阵Cholesky分解,使得分步量化时不需要显示更新 H − 1 H^{-1} H−1,避免量化大模型时反复矩阵求逆带来的累积误差,并且相比OBQ时间复杂度下降一个数量级。
GPTQ代码实现中act-order参数是按照Hessian矩阵对角元素大小逆序排列,意味着优先量化Hessian矩阵对角元素比较大的特征。而Hessian对角元素值表示特征对损失的曲率,值越大对损失影响越大,这与OBQ优先选择量化损失最小的权重的观念相反。AWQ中给出的解释时,优先量化重要性权重,避免补偿重要性权重。
AWQ认为权重具有不同的重要性,量化时仅保留1%重要性权重为FP16,就可以达到很好的量化效果。量化之前对重要性权重进行一定程度的放大,可提高量化性能。为避免使用混合精度量化,采用激活感知搜索为不同通道的权重设置不同的缩放率,从而保护重要性权重,实现单精度INT3/INT4量化。
不同量化方法一览表
| 量化方法 | 量化类型 | 权重 | 激活 | Hessian矩阵 | 描述 |
|---|---|---|---|---|---|
| ZeroQuant | Any | group-wise | dynamic per-token | 否 | 小模型尚可,不能量化大模型 |
| LLM.int8() | W8A8 | per-channel | dynamic per-token | 否 | 混合精度分解,动态量化激活,不能硬件加速,速度比FP16慢约20%,但175B以下模型可达无损量化 ,bitsandbytes库有实现 |
| SmoothQuant-O3 | W8A8 | per-tensor | static per-tensor | 否 | 效果与LLM.int8()差不多,但是速度更快 |
| GPTQ | W4A16 | group-wise | / | 是 | |
| AWQ | W4A16 | group-wise | / | 否 |
量化分类
根据量化后的目标区间,量化(也称为离散化)可分为二值化、三值化、定点化(INT4, INT8)等,常用的是定点量化,就是把16位浮点数转化为低精度的8位或4位整数。
根据量化节点的分布,又可以把量化分为均匀量化和非均匀量化。非均匀量化是根据量化参数的概率分布分配量化节点,参数密集的区域分配更多的量化节点,其余部分少一些,这样量化精度较高,但计算复杂。
现在LLM主要采用的是均匀量化,它又可以分为对称量化和非对称量化。比较常见的FP => INT量化方式是minmax量化。令 x \bm x x表示原始值, s s s表示缩放比例, q m a x q_{max} qmax表示目标区间最大值(目标区间为 [ − 2 n , 2 n − 1 ] [-2^n,2^n-1] [−2n,2n−1]), n n n表示位数。对称性量化计算简单,非对称量化的量化区间利用率更高。
对称性量化(Symmetric Quantization/Absmax Quantization)
缩放比例为原始数值的最大绝对值映射到目标区间的最大值:
x
q
=
clamp
(
⌈
x
s
⌋
,
−
q
m
a
x
,
q
m
a
x
)
,
s
=
max
(
∣
x
∣
)
q
m
a
x
\bm x_q=\text{clamp}\Big(\Big\lceil\frac{\bm x}{s}\Big\rfloor,-q_{max}, q_{max} \Big), \quad s=\frac{\max(|\bm x|)}{q_{max}}
xq=clamp(⌈sx⌋,−qmax,qmax),s=qmaxmax(∣x∣)
非对称量化 (Asymmetric Quantization/Zeropoint Quantization)
缩放比例为原始数值区间缩放到目标数值区间:
x
q
=
clamp
(
⌈
x
s
⌋
+
z
,
−
q
m
a
x
,
q
m
a
x
)
,
s
=
x
m
a
x
−
x
m
i
n
q
m
a
x
−
q
m
i
n
,
z
=
q
m
i
n
−
x
m
i
n
s
\bm x_q=\text{clamp}\Big(\Big\lceil\frac{\bm x}{s}\Big\rfloor+z, -q_{max}, q_{max}\Big), \quad s=\frac{x_{max}-x_{min}}{q_{max}-q_{min}},\quad z=q_{min}-\frac{x_{min}}{s}
xq=clamp(⌈sx⌋+z,−qmax,qmax),s=qmax−qminxmax−xmin,z=qmin−sxmin
其中,
z
z
z表示零点,区间映射中的平移量。
区间映射
把数值区间[xmin, xmax]映射到[ymin, ymax]:
y = x − x m i n s + y m i n , s = x m a x − x m i n y m a x − y m i n y=\frac{x - x_{min}}{s} + y_{min},\quad s=\frac{x_{max}-x_{min}}{y_{max}-y_{min}} y=sx−xmin+ymin,s=ymax−yminxmax−xmin
如果 y m i n = 0 y_{min}=0 ymin=0,则
y = x − x m i n x m a x − x m i n ∗ y m a x y=\frac{x-x_{min}}{x_{max}-x_{min}}*y_{max} y=xmax−xminx−xmin∗ymax
量化时机
根据量化的时机,量化可分为量化感知训练和训练后量化。
量化感知训练(Quantization Aware Training, QAT) 是在训练过程中对权重和激活先量化再反量化,引入量化误差,在优化Training Loss时兼顾Quantization Error。方法虽好,但训练成本大大增加。
训练后量化(Post Training Quantization, PTQ) 是在训练结束后对权重和激活进行量化,是LLM主流量化方法。在推理前事先计算好权重量化的参数,但对于激活而言,由于取决于具体输入,量化比较复杂。激活量化又可以分为动态量化和静态量化。动态量化,on-the-fly方式,推理过程中,实时计算激活的量化系数。静态量化,推理前,利用校准集事先计算好激活的量化系数,推理时直接应用。
量化粒度
量化粒度是指计算量化缩放因子 s s s的数据范围。数据范围越小,量化误差越小;数据范围越大,更多的待量化参数共享一个缩放因子 s s s,误差越大,但额外占用显存越少、计算速度越快。
- per-tensor: 最简单、最大的量化粒度,单个张量(权重/激活值)中所有数据共享一个量化参数。
- per-token: 仅针对激活值,单独量化每个时间步的激活值。
- per-channel: 针对激活值的输出通道和权重矩阵的输入输出通道的向量,单独量化单个向量。比如对于矩阵乘 X @ W \mathbf X @\mathbf W X@W, X ∈ R T × h _ i n \mathbf X\in\R^{T\times h\_in} X∈RT×h_in, W ∈ R h _ i n × h _ o u t \mathbf W\in\R^{h\_in\times h\_out} W∈Rh_in×h_out,对 X X X的h_in和 W \mathbf W W的h_in和h_out维度的向量单独量化,但因硬件加速限制,不易对h_in维度向量单独量化。
- group-wise: 将tensor按照某一维按照group size划分组,每组单独量化,可提高计算效率。量化粒度位于per-tensor和vertor-wise之间,vector-wise是per-token和per-channel的统称。如GPTQ和AWQ中默认组大小是128,即每次处理128列。权重矩阵以row-major存储,shape是[out_features, in_features],权重分组是对输入特征分组。SmoothQuant也提到,激活在序列维度上高方差,在输入维度上低方差,因此按输入维度分组是合理的。在输入维度上分组,离群特征(重要特征)会保留精度,但舍弃了其他多数非重要特征的量化精度。
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
细粒度硬件感知量化
Group-wise Quantization for Weights
分组量化权重矩阵,考虑硬件加速。
Token-wise Quantization for Activations
大语言模型激活方差比较大,使用校准集事先获取量化因子,推理时静态量化,会导致性能下降。解决这一问题的自然想法就是,动态、细粒度地量化每一个token。
动态量化激活值,就是Zero名称的由来?
现有的深度学习框架使用per-token量化,会增加内存和GPU之间数据交换频率,增加量化和反量化开销。本文开发了kernel-fusion算子,将量化和LayerNorm等运算融合,将GeMM乘法和反量化融合,以缓解显存带宽瓶颈(硬件感知)。

反量化融合
量化模式下,输入(激活值)和权重执行INT8矩阵乘,为避免数值溢出,输出通过INT32累加器存储。反量化时,将INT32乘以两个量化尺度(激活和权重的缩放因子),再转回FP16。这期间涉及中间结果INT32的读写。
反量化融合就是一步到位:
FP16 = INT32 × S w × S a \text{FP16 = INT32 }\times S_w \times S_a FP16 = INT32 ×Sw×Sa
低成本逐层知识蒸馏(Layer-by-layer Knowledge Distillation, LKD)
知识蒸馏(Knowledge Distillation, KD)是缓解模型压缩后精度下降的重要方法。
传统KD的限制: 训练过程中,需要加载教室和学生模型,增加了存储和计算成本;KD通常需要从头训练学生模型,需要存储梯度、一/二阶动量副本; 需要训练教师模型的原始数据,对于私有模型,通常无法获取。
逐层知识蒸馏/逐层量化: 假定输入是
X
\mathbf X
X,需量化第
L
k
L_k
Lk层,量化版本是
L
^
k
\hat L_k
L^k,则该层的量化损失为
L
L
K
D
,
k
=
MSE
(
L
k
⋅
L
k
−
1
⋅
L
k
−
2
⋅
…
⋅
L
1
(
X
)
−
L
^
k
⋅
L
k
−
1
⋅
L
k
−
2
⋅
…
⋅
L
1
(
X
)
)
\mathcal{L}_{L K D, k}=\operatorname{MSE}\left(L_k \cdot L_{k-1} \cdot L_{k-2} \cdot \ldots \cdot L_1(\boldsymbol{X})-\widehat{L}_k \cdot L_{k-1} \cdot L_{k-2} \cdot \ldots \cdot L_1(\boldsymbol{X})\right)
LLKD,k=MSE(Lk⋅Lk−1⋅Lk−2⋅…⋅L1(X)−L
k⋅Lk−1⋅Lk−2⋅…⋅L1(X))
训练过程中每次只更新第 L k L_k Lk层参数,显存需求很少。
直通估计器(Straight-Through Estimator ,STE)
STE常用与量化感知训练(QAT),将量化操作视为恒等变换。前向过程执行量化(round、clamp等操作)得到离散张量,模拟模型量化推理。反向传播时,将round(x)的梯度近似为1,即恒等映射,保证梯度传播。
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
vector-wise可轻松应对参数两小于2.7B的模型,但当模型尺寸超过这一数值,受离群值影响,量化性能下降。
离群点的分布
对于超过6.7B的LLMs,推理时激活会出现离群点。其他值20x的离群点首次大概出现深度为25%的网络层,当模型大小逐渐增至6.7B,所有的网络层都有离群点,序列中75%的位置都受离群点影响。对于6.7B模型,离群点呈系统性分步(要么不出现,要么大多数层中出现),每个输入序列大致有150,000个离群点,它们仅分布在整个transformer的6个特征维度。
离群点的重要性
若将离群点设置0,会导致self-attn softmax的top-1概率下降20%,语言困惑度增加600%以上,尽管这些离群点仅占输入特征的0.1%。
随着模型尺寸增加,PPL逐渐降低,离群点显现,可以推测离群点对模型性能影响很重要。
如何找到离群点
规则:特征大于6、影响25%以上的网络层以及影响序列中6%以上的token。
具体地说,对于 L L L层网络和隐状态 X l ∈ R s × h \mathbf X_l\in\R^{s\times h} Xl∈Rs×h, h i h_i hi表示任意层的第 i i i个特征, 0 ≤ i ≤ h 0\le i\le h 0≤i≤h。如果 h i h_i hi是离群点,则至少25%的网络层和5%的token在位置 i i i的特征值大于6。
LLM.int8()的工作
- 混合精度分解,99.9%的矩阵乘中单独量化每对内积(vector-wise),0.1%离群点使用FP16矩阵乘。
- 在高达175B的模型上推理几乎没有损失。

LLM.int8()的步骤
- 给定16位的输入和权重,将其分解为离群值和其他值两个子矩阵。
- 常规输入矩阵的行向量和权重矩阵的列向量执行Absmax INT8量化(归一化),执行INT8矩阵乘,再乘以各自的缩放因子反量化回FP16。此处行列是相对的,如果矩阵乘是WX形式(图中所示),则对输入列和权重行分别执行INT8量化。
- 离群矩阵执行FP16矩阵乘。
- 两部分结果在FP16精度下合并。
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
当LLMs尺寸超过6.7B时,激活值会出现大量离群点,比小模型(BERT)更难量化。ZeroQuant使用per-token量化激活值,使用group-wise量化权重,在小模型(小于6B)上表现优异,但在175B大模型上性能严重下降。LLM.int8()使用混合精度分解(激活离群点使用FP16,其它使用INT8)解决了大模型量化准确率下降问题,但这种混合精度分解不能很好利用硬件加速。
大模型每个token的激活值因离群点的存在(其他多数激活值的100x),激活值离群点扩展了数据范围,增加了通道方差,导致其它多数激活值被分配到很窄的量化区间,增加了量化难度。观察发现这些离群点大多位于小部分固定通道,通道内部方差较小。权重值分步均匀、方差小,比激活容易量化。
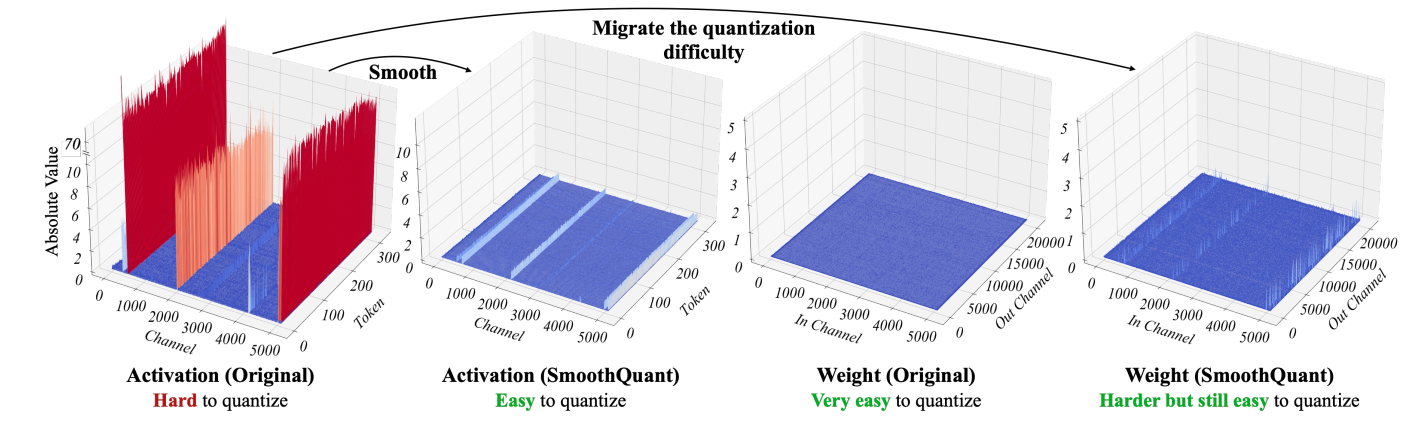
从单个token来看,若某个通道存在离群点,那其他token的这个通道也会是离群点,但各token在这个通道上的方差较小。因此,执行per-channel量化的预期效果会比per-tensor量化效果要好。
SmoothQuant的工作
- 使用校准集离线量化,通过数学变换将激活的量化难度迁移到权重,平滑了激活离群点,调整后的激活和权重都容易量化。
- 间接实现per-channel量化,并且能够GEMM内核,相比现有权重激活量化或仅权重量化,硬件利用效率更高。
- 支持对所有GEMMs大模型进行INT8的权重和激活量化,如OPT-175B、BLOOM-176B和GLM-130B等。
相比FP16,INT8对GPU显存需求减半,矩阵乘的吞吐量加倍。
量化维度
 |  |
|---|
上右图显示量化的不同细粒度:per-tensor、per-token和per-channel。per-tensor对整个tensor统一量化,per-token对输入的每个时间步( T T T维)单独量化,per-channel对权重的每个输出维度( C o C_{o} Co)单独量化。
为了利用硬件加速的GEMM内核,只能在矩阵乘的外围进行per-channel量化,比如输入矩阵的序列维度和权重矩阵的输出维度,不能对 C i C_i Ci维单独量化。现有方法多使用per-token量化线性层,无法解决各时间步激活方差大的问题,效果比per-tensor仅好一点点。

量化维度的限制
对于矩阵乘 X @ W X@W X@W, X ∈ R n × i n X\in \R^{n\times in} X∈Rn×in, W ∈ R i n × o u t W\in \R^{in\times out} W∈Rin×out, X X X的每一行和 W W W的每一行做内积。如果对 X X X执行per-channel量化,会导致 X X X的每一列都有独立的缩放因子,内积运算中每一项都需要做缩放,不能有效利用GEMM内核。
也就说,为了高效利用GEMM内核,只能在矩阵乘的外围(n维和out维)做缩放,不能在内围(in维)。缩放因子不能从in维提取。
激活平滑
由于per-channel量化不可行,我们将输入激活的每个channel各除以一个平滑因子,为保证数学等价性,需在反方向缩放权重矩阵。
Y
=
(
X
diag
(
s
)
−
1
)
⋅
(
diag
(
s
)
W
)
=
X
^
W
^
\mathbf Y=(\mathbf X\text{diag}(\mathbf s)^{-1})\cdot(\text{diag}(\mathbf s)\mathbf W)=\hat{\mathbf X}\hat{\mathbf W}
Y=(Xdiag(s)−1)⋅(diag(s)W)=X^W^
X有乘对角矩阵,列缩放;W左乘对角矩阵,行缩放。
当所有通道缩放之后的最大值相同,则总的量化效率最高。令
s
j
=
max
(
∣
X
j
∣
)
s_j=\max(|\mathbf X_j|)
sj=max(∣Xj∣),缩放后激活的各通道的最大值为1。激活的量化难度转移到权重矩阵,导致权重量化变难。因此,需要将量化难度均摊到激活和权重,公式如下:
s
j
=
max
(
∣
X
j
∣
)
α
/
max
(
∣
W
j
∣
)
1
−
α
s_j=\max(|\mathbf X_j|)^\alpha/\max(|\mathbf W_j|)^{1-\alpha}
sj=max(∣Xj∣)α/max(∣Wj∣)1−α
 |  |
|---|
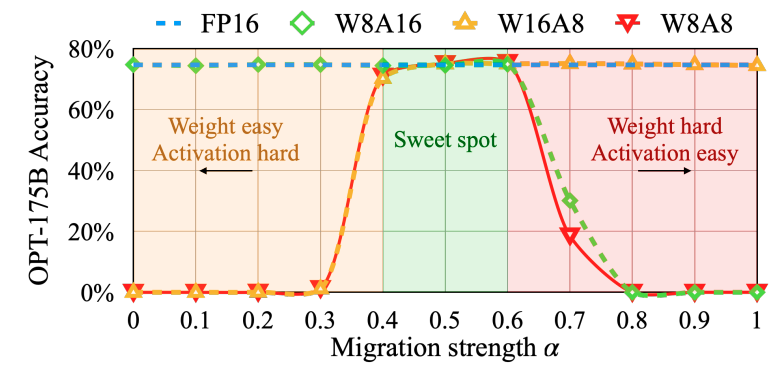
对于多数模型 α \alpha α取0.5表现良好, α \alpha α越大,权重的量化难度越大。论文中在Pile验证集进行了网格搜索。GLM130B激活比较难量化, α \alpha α选取0.75,其他模型则选取0.5。
Transformer Block的量化
Softmax和LayerNorm使用FP16运算,其他运算使用INT8。

量化效果
SmoothQuant-O1-3效率逐渐增加。



OBS(Optimal Brain Surgeon)
1992年发表,从数学角度推导如何对模型剪枝(参数置0)。
泰拉展开式
函数 f ( x ) f(x) f(x)在指定点 x 0 x_0 x0附近的展开式
f ( x ) = f ( x 0 ) 0 ! + f ′ ( x 0 ) 1 ! ( x − x 0 ) + f ′ ′ ( x 0 ) 2 ! ( x − x 0 ) 2 + ⋯ + f ( n ) ( x 0 ) n ! x n + R n ( x ) f(x)=\frac{f(x_0)}{0!}+\frac{f'(x_0)}{1!}(x-x_0)+\frac{f''(x_0)}{2!}(x-x_0)^2+\cdots +\frac{f^{(n)}(x_0)}{n!}x^n+R_n(x) f(x)=0!f(x0)+1!f′(x0)(x−x0)+2!f′′(x0)(x−x0)2+⋯+n!f(n)(x0)xn+Rn(x)
f ( x 0 + Δ x ) f(x_0+\Delta x) f(x0+Δx)在 x 0 x_0 x0处的二阶泰勒展开式
f ( x 0 + Δ x ) ≈ f ( x 0 ) + f ′ ( x 0 ) Δ x + f ′ ′ ( x 0 ) 2 ( Δ x ) 2 + O ( ∣ ∣ Δ w ∣ ∣ 3 ) f(x_0+\Delta x)\approx f(x_0)+f'(x_0)\Delta x+\frac{f''(x_0)}{2}(\Delta x)^2+O(||\Delta_w||^3) f(x0+Δx)≈f(x0)+f′(x0)Δx+2f′′(x0)(Δx)2+O(∣∣Δw∣∣3)
W
q
W_q
Wq可看作为
W
W
W加扰动,函数
E
(
W
q
)
E(W_q)
E(Wq)在
W
W
W处的二阶泰勒展开式为
E
(
W
q
)
=
E
(
W
+
Δ
W
)
≈
E
(
W
)
+
1
2
δ
w
⊤
H
δ
w
E(W_q)=E(W+\Delta W)\approx E(W)+\frac{1}{2}\delta_w^\top H\delta_w
E(Wq)=E(W+ΔW)≈E(W)+21δw⊤Hδw
训练好意味着参数 W W W位于局部极小值附近,也就是一阶导数为0。 H H H是Hessian矩阵。 Δ x \Delta x Δx和 δ w \delta_w δw表示扰动量/增量,只是记法不同。
因此,剪枝带来的损失为
L
=
Δ
E
≈
1
2
δ
w
⊤
H
δ
w
\mathcal L=\Delta E\approx \frac{1}{2}\delta_w^\top H\delta_w
L=ΔE≈21δw⊤Hδw
OBS的核心思想:对于参数向量 w = [ w 1 , ⋯ , w n ] w=[w_1,\cdots,w_n] w=[w1,⋯,wn],依次去除影响最小的分量 w q w_q wq,并修正其它分量 w i ( i ≠ q ) w_{i(i\ne q)} wi(i=q),以补偿去除分量 w q w_q wq带来的扰动,重复直到裁剪到目标大小。分步裁剪时, Δ w \Delta_w Δw中每次仅有一个元素非0。
对于量化则是依次量化影响最小的参数,并修正其它参数,直到所有参数完成量化。
如何找到剪枝影响最小的参数?
什么是剪枝?剪枝就是将某个参数置0,也就是参数增量是它的相反数,即
δ
w
q
+
w
q
=
0
\delta_{w_q}+w_q=0
δwq+wq=0,这里
q
q
q表示
w
w
w的第
q
q
q维元素。
怎么找到影响最小的 q q q?这属于约束极值问题,就是在 δ w q + w q = 0 \delta_{w_q}+w_q=0 δwq+wq=0的约束下,求 L \mathcal L L的极小值。更一般地,令 e q e_q eq表示除 q q q维为1,其他维均为0的列向量,则 δ w q = e q ⊤ δ w \delta_{w_q}=e_q^\top \delta_w δwq=eq⊤δw。
现在问题的约束变为
e
q
⊤
δ
w
+
w
q
=
0
e_q^\top \delta_w+w_q=0
eq⊤δw+wq=0,引入拉格朗日乘子将约束优化问题转为无约束优化:
L
=
1
2
δ
w
⊤
H
δ
w
+
λ
(
e
q
⊤
δ
w
+
w
q
)
\mathcal L=\frac{1}{2}\delta_w^\top H\delta_w + \lambda(e_q^\top \delta_w+w_q)
L=21δw⊤Hδw+λ(eq⊤δw+wq)
L
\mathcal L
L在极小值
δ
w
\delta_w
δw处的一阶导为0,可得
δ
w
=
−
λ
H
−
1
e
q
\delta_w=-\lambda H^{-1}e_q
δw=−λH−1eq。由于
e
q
e_q
eq是仅在维度
q
q
q为1的单位向量,带入约束可得
w
q
=
λ
e
q
⊤
H
−
1
e
q
,
λ
=
w
q
H
q
q
−
1
⟹
δ
w
=
−
w
q
H
q
q
−
1
H
−
1
e
q
w_q=\lambda e_q^\top H^{-1}e_q,\quad \lambda=\frac{w_q}{H_{qq}^{-1}} \implies \delta_w=-\frac{w_q}{H_{qq}^{-1}}H^{-1}e_q
wq=λeq⊤H−1eq,λ=Hqq−1wq⟹δw=−Hqq−1wqH−1eq
因此,剪枝损失可表示为
L
=
1
2
δ
w
⊤
H
δ
w
=
1
2
(
−
w
q
H
q
q
−
1
H
−
1
e
q
)
⊤
H
(
−
w
q
H
q
q
−
1
H
−
1
e
q
)
=
1
2
w
q
2
(
H
q
q
−
1
)
2
e
q
⊤
(
H
−
1
)
⊤
H
H
−
1
e
q
=
1
2
w
q
2
H
q
q
−
1
\begin{align*} \mathcal L &=\frac{1}{2}\delta_w^\top H\delta_w\\ &=\frac{1}{2}\Big(-\frac{w_q}{H_{qq}^{-1}}H^{-1}e_q\Big)^\top H\Big(-\frac{w_q}{H_{qq}^{-1}}H^{-1}e_q\Big)\\ &=\frac{1}{2}\frac{w_q^2}{(H_{qq}^{-1})^2}e_q^\top (H^{-1})^\top HH^{-1}e_q\\ &=\frac{1}{2}\frac{w_q^2}{H_{qq}^{-1}} \end{align*}
L=21δw⊤Hδw=21(−Hqq−1wqH−1eq)⊤H(−Hqq−1wqH−1eq)=21(Hqq−1)2wq2eq⊤(H−1)⊤HH−1eq=21Hqq−1wq2
更一般地,第 q q q维参数的量化损失为
L = ( quant ( w q ) − w q ) 2 2 H q q − 1 L=\frac{(\text{quant}(w_q)-w_q)^2}{2H_{qq}^{-1}} L=2Hqq−1(quant(wq)−wq)2
直观意义就是,每一项损失的增量大致与“该项平方除以Hessian逆矩阵对应位置对角线元素”相关。也就是说, H q q − 1 H_{qq}^{-1} Hqq−1越大, q q q维能容忍的变化越大,对损失的影响小,更适合量化/裁剪。
如何修正其它参数?
OBS在裁剪
q
q
q维元素后,同步地调整其它参数使裁剪后增加损失最小(损失补偿),第
i
i
i个非裁剪参数的调整幅度为
δ
w
i
=
−
w
q
(
H
−
1
)
q
q
(
H
−
1
)
i
q
\delta_{w_i} = -\frac{w_q}{(H^{-1})_{qq}} (H^{-1})_{iq}
δwi=−(H−1)qqwq(H−1)iq
总结

OBS没有一次性对所有参数进行裁剪,而是逐步调整,逐步裁剪影响最小参数,并修正其它参数。
OBS需要计算 H − 1 H^{-1} H−1,时间复杂度是 O ( d 3 ) O(d^3) O(d3),分步裁剪/量化每一维,复杂度是 O ( d ) O(d) O(d),总时间复杂度是 O ( d 4 ) O(d^4) O(d4)。
对于参数矩阵W,这里的维度d应该是行数✖列数。
OBQ(Optimal Brain Quantization)
将OBS应用到模型量化,逐行量化、递归求解 H − 1 H^{-1} H−1,降低OBS时间复杂度。
每行单独计算剪枝顺序,再综合所有行确定最终裁剪行列。OBS算法每剪枝一个权重,需要重新计算 H − 1 H^{-1} H−1,OBQ提出递归式求解法(行列消除法),时间复杂度为 O ( d col 2 ) O(d_\text{col}^2) O(dcol2)。
优化1:使用L2重建量化损失
对于线性层权重矩阵
W
W
W,剪枝/量化的权重矩阵为
W
^
\hat W
W^,目标是尽量降低激活的差异:
W
^
=
arg min
∣
∣
W
^
X
−
W
X
∣
∣
2
2
\hat W =\argmin||\hat WX - WX||^2_2
W^=argmin∣∣W^X−WX∣∣22
X X X使用小批量估计。
采用激活值的平方误差作为量化损失
L
=
1
2
∣
∣
W
^
X
−
W
X
∣
∣
2
2
,
∇
W
2
L
=
H
=
2
X
X
⊤
\mathcal L=\frac{1}{2}||\hat W X - WX||_2^2,\quad \nabla_W^2 \mathcal L=H=2XX^\top
L=21∣∣W^X−WX∣∣22,∇W2L=H=2XX⊤
采用分行量化时,每一行权重 W i W_i Wi独立量化,Hessian(线性层的平方损失对权重的二阶导数)近似为块对角矩阵,每个块 H i H_i Hi对应与第 i i i行权重的Hessian,即 H i = 2 X X ⊤ H_i=2XX^\top Hi=2XX⊤,大小为 d col × d col d_\text{col}\times d_\text{col} dcol×dcol。

对于线性层网络,每行参数的输入相同,初始Hessian相同。
优化2:行并行与递归求解 H − 1 H^{-1} H−1
每行独立量化,每次贪婪地选择最小损失参数
w
q
w_q
wq去量化,并使用
δ
F
\delta_F
δF修正未量化的参数:
w
q
=
argmin
w
q
(
quant
(
w
q
)
−
w
q
)
2
[
H
F
−
1
]
q
q
,
δ
F
=
−
w
q
−
quant
(
w
q
)
[
H
F
−
1
]
q
q
⋅
(
H
F
−
1
)
:
,
q
.
(2)
w_q = \text{argmin}_{w_q} \frac{(\text{quant}(w_q) - w_q)^2}{[\mathbf{H}_F^{-1}]_{qq}}, \quad \delta_F = -\frac{w_q - \text{quant}(w_q)}{[\mathbf{H}_F^{-1}]_{qq}} \cdot (\mathbf{H}_F^{-1})_{:,q}. \tag{2}
wq=argminwq[HF−1]qq(quant(wq)−wq)2,δF=−[HF−1]qqwq−quant(wq)⋅(HF−1):,q.(2)
使用上面两个公式迭代量化所有参数。为避免重新计算
H
−
1
\mathbf H^{-1}
H−1,通过以下公式更新Hessian:
H
−
q
−
1
=
(
H
−
1
−
1
[
H
−
1
]
q
q
H
:
,
q
−
1
H
q
,
:
−
1
)
−
p
(3)
\mathbf{H}_{-q}^{-1} = \left( \mathbf{H}^{-1} - \frac{1}{[\mathbf{H}^{-1}]_{qq}} \mathbf{H}_{:,q}^{-1} \mathbf{H}_{q,:}^{-1} \right)_{-p} \tag{3}
H−q−1=(H−1−[H−1]qq1H:,q−1Hq,:−1)−p(3)
对于
d
row
×
d
col
d_\text{row}\times d_\text{col}
drow×dcol的参数矩阵,OBQ的时间复杂度为
O
(
d
row
⋅
d
col
3
)
O(d_\text{row}\cdot d_\text{col}^3)
O(drow⋅dcol3)。
算法实现
裁剪过程
裁剪与量化的转换
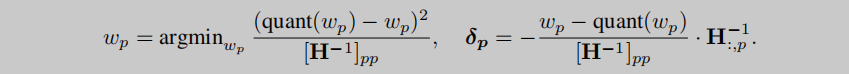
量化过程

GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
步骤1: 任意顺序量化(Arbitrary Order Insight)
OBQ贪婪地严格选择当前产生最小量化误差的参数进行量化,对于参数量大的网络层,这种严格选择顺序的量化结果相比于按随机顺序量化结果差异不大。 原因可能是产生较大误差的参数始终留在最后,这时已没有多少参数可以参与补偿,也就是说,量化顺序对最终效果的影响有限。
GPTQ对所有行都按从左到右的顺序量化,所有行的 H F − 1 \mathbf H_F^{-1} HF−1仅与输入有关,始终一致,整个量化过程中只需要按照公式 2 2 2更新 d col d_\text{col} dcol次。如果不同行按不同顺序,则需要更新 d row ⋅ d col d_\text{row}\cdot d_\text{col} drow⋅dcol次。
步骤2: 批量量化(Lazy Batch-Updates)
OBQ算法每一步都需要按公式 3 3 3更新 H − 1 \mathbf H^{-1} H−1中的所有参数,受内存带宽影响很大,计算/访存比很低,未有效利用GPU的并行计算能力。
列 i i i的量化与左侧已量化的列无关,仅需考虑右侧列。GPTQ每次量化权重矩阵相邻的128列,这与单列量化在计算结果上无差异,但可以充分利用GPU算力,提高计算/访存比。
使用以下公式更新参数:
δ
F
=
−
(
w
Q
−
quant
(
w
Q
)
)
(
[
H
F
−
1
]
Q
Q
)
−
1
(
H
F
−
1
)
:
,
Q
(4)
\boldsymbol{\delta}_F =-(\mathbf{w}_Q-\operatorname{quant}(\mathbf{w}_Q))([\mathbf{H}_F^{-1}]_{QQ})^{-1}(\mathbf{H}_F^{-1})_{:, Q} \tag{4}
δF=−(wQ−quant(wQ))([HF−1]QQ)−1(HF−1):,Q(4)
使用以下公式更新
H
−
1
\mathbf H^{-1}
H−1:
H
−
Q
−
1
=
(
H
−
1
−
H
:
,
Q
−
1
(
[
H
−
1
]
Q
Q
)
−
1
H
Q
,
:
−
1
)
−
Q
(5)
\mathbf{H}_{-Q}^{-1} =\left(\mathbf{H}^{-1}-\mathbf{H}_{:, Q}^{-1}([\mathbf{H}^{-1}]_{Q Q})^{-1} \mathbf{H}_{Q,:}^{-1}\right)_{-Q}\tag{5}
H−Q−1=(H−1−H:,Q−1([H−1]QQ)−1HQ,:−1)−Q(5)
步骤3: Cholesky矩阵分解(Cholesky Reformulation)
当模型参数规模在数十亿以上时, H F − 1 \mathbf H_F^{-1} HF−1非正定,使用block策略量化参数时,可能会因为重复利用公式 5 5 5,求逆会产生累积误差,导致未量化参数的更新方向不正确。
对于小模型,常在 H \mathbf H H的对角元素上加入大约特征均值1%的噪声,以解决数值不稳定的问题。
推理过程略,大致思想就是 δ F \delta_F δF和 H − 1 H^{-1} H−1的更新都可以用 L \mathcal L L表示,每次迭代把 H − 1 H^{-1} H−1的变化累加到 L \mathcal L L,通过 L L L去更新参数。
算法过程

AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
AWQ认为每个权重的重要性不一样,仅保护大约1%的重要性参数能显著降低量化误差。AWQ遵循激活感知原则,通过观察激活值判断权重的重要性(大的激活值对应重要的权重),搜索最优的per-channel缩放因子,以最小化量化误差。
AWQ不需要后向传播和重构模型,不会在校准集上过拟合,能够保留模型不同模态、不同领域的泛化性。仅量化所有权重参数,能够利用硬件加速。
GPTQ使用二阶导数信息补偿量化误差,但对部分模型(如LLaMA-7B)需要开启重排序(硬件利用率低2x)。GPTQ利用校准集重构模型,可能会出现过拟合,从而丢失泛化性,特别对于多模态模型。AWQ是reorder-free算法,开发的在线反量化tensor core,比GPTQ快1.45x,比cuBLAS FP16快1.85x。
保留1%重要性参数可提升量化性能
相比绝对大多参数,有小部分参数非常影响模型的性能。如果不量化这部分参数,有助于缓解量化其他参数带来的误差。
如下表所示,基于激活值、权重参数和随机性选择不同比例的重要性参数保留为FP16精度,其他参数量化为INT3,观测对PPL的影响。
对于超过6.7B的模型,保留通过激活值选择的0.1%的重要性参数就可以获得较好的性能;根据权重数值选择重要性参数与随机选择差不多。虽然仅保留少部分重要性权重为FP16就可以获得较好的量化性能,但是混合精度实现比较复杂。
根据权重数值或者L2-Norm判断权重的重要性可能不准确!
激活感知缩放保护重要权重
对重要性权重执行per-channel缩放。
启发式缩放
minmax量化方法(非对称量化),在最大最小值处无量化损失。因此可见,保护离群权重通道比较直接的方式就是直接放大这些权重通道的缩放系数,但这与直接保留1%的FP16权重相比,还是存在差异。随着缩放系数的增加,量化效果不断变好,但大到一定尺度,其他参数能利用的量化点位过少,性能开始下降。因此,需要找到能降低重要性权重的量化误差,而又不增加其他参数的量化误差的方法。
搜索缩放
s
∗
=
arg
min
s
L
(
s
)
,
L
(
s
)
=
∥
Q
(
W
⋅
s
)
(
s
−
1
⋅
X
)
−
W
X
∥
\mathbf{s}^*=\underset{\mathbf{s}}{\arg \min } \mathcal{L}(\mathbf{s}), \quad \mathcal{L}(\mathbf{s})=\left\|Q(\mathbf{W} \cdot \mathbf{s})\left(\mathbf{s}^{-\mathbf{1}} \cdot \mathbf{X}\right)-\mathbf{W} \mathbf{X}\right\|
s∗=sargminL(s),L(s)=
Q(W⋅s)(s−1⋅X)−WX
式中,
Q
Q
Q表示组大小为128的INT3/INT4量化函数,
X
\mathbf X
X表示小校准集的输入特征,
s
\mathbf s
s是per-in-channel的量化缩放因子。
Q
Q
Q不可微,现有一些近似梯度的方法,但收敛较差,还存在过拟合风险。
通过分析影响缩放因子选择的因素来设计搜索空间,直觉上来说,最优缩放因子的关联因素有:
- 激活尺度: 之前已验证激活尺度与参数的重要性相关,首先计算将激活尺度的均值作为重要性因子,即 s x = mean c _ o u t ∣ X ∣ \mathbf s_{\mathbf x}=\text{mean}_{c\_out}|\mathbf X| sx=meanc_out∣X∣。
- 权重尺度: 为降低非重要性权重的量化损失,应当使这些通道的分布扁平化,从而更容易量化。自觉的做法就是将这些通道各自除以其均值,即 s w = mean c _ o u t ∣ W ^ ∣ \mathbf s_{\mathbf w}=\text{mean}_{c\_out}|\hat{\mathbf W}| sw=meanc_out∣W^∣,其中 W ^ \hat{\mathbf W} W^是指每组内归一化的 W \mathbf W W。
最终考虑这两个尺度的缩放因子表示为
s
=
f
(
s
X
,
s
W
)
=
s
X
α
⋅
s
W
−
β
,
α
∗
,
β
∗
=
arg
min
α
,
β
L
(
s
X
α
⋅
s
W
−
β
)
\mathbf s=f(\mathbf s_{\mathbf X}, \mathbf s_{\mathbf W})=\mathbf s_{\mathbf X}^{\alpha} \cdot \mathbf s_{\mathbf W}^{-\beta}, \quad \alpha^{*},\beta^{*}=\underset{\alpha,\beta}{\arg\min}\mathcal L(\mathbf s_{\mathbf X}^{\alpha} \cdot \mathbf s_{\mathbf W}^{-\beta})
s=f(sX,sW)=sXα⋅sW−β,α∗,β∗=α,βargminL(sXα⋅sW−β)
α
,
β
\alpha,\beta
α,β是位于
[
0
,
1
]
[0, 1]
[0,1]之间的超参数,可通过网格搜索获得。
s
X
\mathbf s_{\mathbf X}
sX的重要性远超
s
W
\mathbf s_{\mathbf W}
sW,
s
W
\mathbf s_{\mathbf W}
sW的提升有限。
通过搜索收缩率(表示为“+clip”)来调整裁剪范围有时也能进一步提升量化性能,调整裁剪范围可以轻微移动缩放因子,这可能有助于保护重要性权重。