能否不使用锁保证多线程安全?
在多线程编程中,锁(如互斥锁、信号量)是实现线程同步的传统方式,但并非唯一方式。不使用锁保证多线程安全的核心思路是避免共享状态、使用原子操作或采用线程本地存储。以下从几个方面详细阐述:
无锁数据结构:无锁数据结构通过原子操作(如 CAS,Compare-And-Swap)实现线程安全。CAS 是一种原子指令,它比较内存中的值与期望值,如果相同则更新为新值。例如,实现一个无锁的计数器:
#include <atomic>
class LockFreeCounter {
private:
std::atomic<int> count;
public:
LockFreeCounter() : count(0) {}
void increment() {
int oldValue;
do {
oldValue = count.load();
} while (!count.compare_exchange_weak(oldValue, oldValue + 1));
}
int get() const {
return count.load();
}
};
线程本地存储(Thread-Local Storage):线程本地存储为每个线程提供独立的变量副本,避免线程间共享数据。例如:
#include <iostream>
#include <thread>
thread_local int threadLocalValue = 0;
void worker() {
threadLocalValue++;
std::cout << "Thread " << std::this_thread::get_id()
<< ": " << threadLocalValue << std::endl;
}
int main() {
std::thread t1(worker);
std::thread t2(worker);
t1.join();
t2.join();
return 0;
}
不可变数据结构:不可变数据结构一旦创建就不能修改,因此天然线程安全。例如,函数式编程中常用的不可变链表:
template<typename T>
class ImmutableList {
private:
T value;
ImmutableList* next;
ImmutableList(T val, ImmutableList* n) : value(val), next(n) {}
public:
static ImmutableList* empty() { return nullptr; }
ImmutableList* add(T val) {
return new ImmutableList(val, this);
}
// 其他只读方法...
};
内存模型与原子操作:C++11 引入了内存模型和原子类型(如 std::atomic),提供了比锁更细粒度的同步机制。例如:
#include <atomic>
#include <thread>
std::atomic<bool> ready(false);
std::atomic<int> data(0);
void producer() {
data.store(42, std::memory_order_relaxed);
ready.store(true, std::memory_order_release);
}
void consumer() {
while (!ready.load(std::memory_order_acquire));
std::cout << data.load(std::memory_order_relaxed) << std::endl;
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
无锁编程的优势在于避免了锁带来的上下文切换和线程阻塞开销,提高了并发性能。然而,它也带来了复杂性:需要深入理解内存模型、原子操作语义,并且调试难度大。在实际应用中,应根据场景选择合适的同步方式,无锁编程更适合对性能要求极高且并发冲突频繁的场景。
面向对象的三个特性是什么?请分别解释。
面向对象编程(OOP)的三个核心特性是封装、继承和多态。这三个特性相互配合,使代码更具可维护性、可扩展性和可复用性。
封装(Encapsulation):封装是将数据(属性)和操作数据的方法(行为)捆绑在一起,并隐藏对象的内部实现细节。通过封装,对象的使用者只需关注接口,而不必关心具体实现。例如,一个简单的银行账户类:
class BankAccount {
private:
double balance; // 私有属性,外部无法直接访问
public:
// 构造函数
BankAccount(double initialBalance) : balance(initialBalance) {}
// 公有方法,提供访问接口
double getBalance() const { return balance; }
void deposit(double amount) {
if (amount > 0) {
balance += amount;
}
}
bool withdraw(double amount) {
if (amount > 0 && amount <= balance) {
balance -= amount;
return true;
}
return false;
}
};
封装的优点包括:保护数据不被外部随意修改、降低模块间的耦合度、便于代码维护和升级。通过访问控制(如 private、protected、public),类可以精确控制哪些成员对外可见,哪些是内部实现细节。
继承(Inheritance):继承允许一个类(子类、派生类)继承另一个类(父类、基类)的属性和方法,从而实现代码复用和层次化组织。例如:
class Shape {
protected:
std::string color;
public:
Shape(const std::string& c) : color(c) {}
virtual double area() const = 0; // 纯虚函数,使Shape成为抽象类
std::string getColor() const { return color; }
};
class Circle : public Shape {
private:
double radius;
public:
Circle(double r, const std::string& c) : Shape(c), radius(r) {}
double area() const override {
return 3.14159 * radius * radius;
}
};
class Rectangle : public Shape {
private:
double width, height;
public:
Rectangle(double w, double h, const std::string& c)
: Shape(c), width(w), height(h) {}
double area() const override {
return width * height;
}
};
继承分为单继承(一个子类只有一个直接父类)和多继承(一个子类有多个直接父类)。C++ 支持多继承,但过度使用会导致菱形继承等问题,需要通过虚继承解决。继承的优点是提高代码复用性、建立类的层次结构,但缺点是增加了类之间的耦合度,父类的修改可能影响子类。
多态(Polymorphism):多态允许不同类的对象通过相同的接口进行调用,实现 “一个接口,多种实现”。C++ 中的多态主要通过虚函数和运行时类型识别(RTTI)实现。例如:
void printArea(const Shape& shape) {
std::cout << "Area: " << shape.area() << std::endl;
}
int main() {
Circle circle(5.0, "red");
Rectangle rectangle(4.0, 6.0, "blue");
printArea(circle); // 输出圆的面积
printArea(rectangle); // 输出矩形的面积
return 0;
}
在这个例子中,printArea 函数接受一个 Shape 引用,但实际调用时会根据对象的实际类型调用相应的 area 方法。这就是运行时多态,也称为动态绑定。静态多态(如函数重载、模板)则在编译时确定调用的函数。多态的优点是提高代码的灵活性和可扩展性,使代码可以处理未知类型的对象。
构造函数和析构函数能否被继承?
构造函数和析构函数在 C++ 中具有特殊的语义,它们不能被继承,但在继承体系中起着关键作用。以下从几个方面详细分析:
构造函数不能被继承:构造函数负责对象的初始化,每个类的构造函数是专门为该类设计的,因此不能被继承。当创建子类对象时,会先调用父类的构造函数,再调用子类的构造函数。例如:
class Base {
public:
Base(int value) {
std::cout << "Base constructor: " << value << std::endl;
}
};
class Derived : public Base {
public:
Derived(int value) : Base(value) {
std::cout << "Derived constructor" << std::endl;
}
};
int main() {
Derived d(42);
return 0;
}
输出结果:
Base constructor: 42
Derived constructor
C++11 引入了构造函数委托,可以在同一个类中调用其他构造函数,但这不是继承。例如:
class MyClass {
public:
MyClass() : MyClass(0) {}
MyClass(int value) {
// 初始化逻辑
}
};
析构函数不能被继承:析构函数负责对象的资源释放,同样不能被继承。当子类对象销毁时,会先调用子类的析构函数,再调用父类的析构函数。例如:
class Base {
public:
~Base() {
std::cout << "Base destructor" << std::endl;
}
};
class Derived : public Base {
public:
~Derived() {
std::cout << "Derived destructor" << std::endl;
}
};
int main() {
{
Derived d;
} // 离开作用域,d被销毁
return 0;
}
输出结果:
Derived destructor
Base destructor
虚析构函数的重要性:当通过基类指针删除派生类对象时,如果基类析构函数不是虚函数,只会调用基类的析构函数,导致派生类资源泄漏。例如:
class Base {
public:
~Base() { /* ... */ } // 非虚析构函数
};
class Derived : public Base {
private:
int* data;
public:
Derived() { data = new int[100]; }
~Derived() { delete[] data; }
};
int main() {
Base* ptr = new Derived();
delete ptr; // 只调用Base的析构函数,Derived的析构函数未被调用
return 0;
}
解决方法是将基类的析构函数声明为虚函数:
class Base {
public:
virtual ~Base() { /* ... */ } // 虚析构函数
};
这样,当 delete ptr 时,会先调用 Derived 的析构函数,再调用 Base 的析构函数,确保资源正确释放。
继承体系中的构造和析构顺序:在多重继承或多层继承中,构造函数按继承顺序调用(从最基类到最派生类),析构函数按相反顺序调用。例如:
class A { public: A() { std::cout << "A "; } ~A() { std::cout << "~A "; } };
class B { public: B() { std::cout << "B "; } ~B() { std::cout << "~B "; } };
class C : public A, public B {
public:
C() { std::cout << "C "; }
~C() { std::cout << "~C "; }
};
int main() {
C c;
return 0;
}
输出结果:
A B C ~C ~B ~A
C++ 中函数重载是如何实现的?
C++ 中的函数重载(Function Overloading)允许在同一作用域内定义多个同名但参数列表不同的函数。编译器通过名称修饰(Name Mangling)技术实现函数重载,下面详细解释其原理和机制。
函数重载的条件:重载函数必须满足以下条件之一:
- 参数数量不同
- 参数类型不同
- 参数顺序不同(如果类型不同)
返回类型不能作为重载的依据,因为调用时编译器无法根据返回类型推断应该调用哪个函数。例如:
// 合法的重载示例
int add(int a, int b) { return a + b; }
double add(double a, double b) { return a + b; }
int add(int a, int b, int c) { return a + b + c; }
// 非法的重载示例(仅返回类型不同)
// void func(int x) {}
// int func(int x) { return x; } // 错误:无法重载仅返回类型不同的函数
名称修饰(Name Mangling):C++ 编译器通过名称修饰将函数名和参数信息编码成唯一的内部名称。例如,GCC 编译器可能将上述 add 函数编码为:
int add(int, int)→_Z3addiidouble add(double, double)→_Z3addddint add(int, int, int)→_Z3addiii
其中,_Z是前缀,3表示函数名长度,add是原函数名,后面的i和d分别表示int和double类型。这种编码方式确保了重载函数在编译后具有唯一的标识符。
重载解析(Overload Resolution):当调用重载函数时,编译器通过以下步骤确定最佳匹配:
- 精确匹配:参数类型完全相同,或只需进行微不足道的转换(如数组名到指针、函数名到指针、T 到 const T)。
- 提升转换:如 char 到 int、float 到 double。
- 标准转换:如 int 到 double、Derived到 Base。
- 用户定义转换:通过类的转换构造函数或转换运算符。
- 省略号匹配:如函数参数为
...。
如果存在多个匹配,编译器会选择最精确的匹配。如果无法判断唯一最佳匹配,则会产生二义性错误。例如:
void f(int);
void f(double);
f('a'); // 调用f(int),因为char到int是提升转换,比到double更优先
f(3.14); // 调用f(double)
模板函数重载:函数模板也可以重载,并且可以与普通函数重载共存。例如:
template<typename T>
T max(T a, T b) { return a > b ? a : b; }
int max(int a, int b) { return a > b ? a : b; }
int main() {
max(1, 2); // 调用普通函数max(int, int)
max(1.0, 2.0); // 调用模板函数max<double>(double, double)
max(1, 2.0); // 错误:二义性,无法确定调用哪个函数
return 0;
}
命名空间与重载:函数重载只在同一作用域内有效。如果在不同命名空间中定义同名函数,它们不会形成重载,而是通过名称查找规则来选择。例如:
namespace A {
void func(int);
}
namespace B {
void func(double);
}
void test() {
A::func(42); // 调用A::func
B::func(3.14); // 调用B::func
}
函数重载是 C++ 静态多态的一种实现方式,它提高了代码的可读性和灵活性,使程序员可以使用相同的名称处理不同类型的操作。编译器通过名称修饰和重载解析机制确保了正确的函数调用。
C 语言中是否支持函数重载?
C 语言不支持函数重载(Function Overloading),即不能在同一作用域内定义多个同名但参数列表不同的函数。这是由 C 语言的编译模型和名称管理机制决定的。以下从几个方面详细分析:
C 语言的编译模型:C 编译器在编译函数时,只关注函数名本身,不考虑参数类型和数量。因此,同名函数会产生冲突。例如:
// C语言中无法编译通过的代码
int add(int a, int b) { return a + b; }
double add(double a, double b) { return a + b; } // 错误:重复定义add函数
C 编译器会报错 “redefinition of 'add'”,因为它认为这两个函数具有相同的名称和标识符。
C 语言的名称修饰:C 语言没有像 C++ 那样的名称修饰(Name Mangling)机制。C 编译器通常只使用函数名作为唯一标识符,不包含参数信息。例如,上述两个 add 函数在 C 编译后可能都被简单地标识为add,导致链接时冲突。
替代方案:在 C 语言中,可以通过以下方式实现类似函数重载的功能:
- 使用不同的函数名:最直接的方法是为不同参数的函数取不同的名称。例如:
int add_int(int a, int b) { return a + b; }
double add_double(double a, double b) { return a + b; }
这种方法简单直接,但缺点是需要记住不同的函数名,降低了代码的可读性和易用性。
- 使用函数指针:通过函数指针可以根据参数类型选择不同的实现。例如:
typedef int (*IntOp)(int, int);
typedef double (*DoubleOp)(double, double);
int add_int(int a, int b) { return a + b; }
double add_double(double a, double b) { return a + b; }
// 根据类型选择函数
void* get_adder(int type) {
if (type == 0) return (void*)add_int;
else return (void*)add_double;
}
这种方法需要手动管理函数指针,增加了代码复杂度。
- 使用可变参数:C 语言的可变参数函数(如 printf)可以处理不同数量和类型的参数。例如:
#include <stdarg.h>
int sum(int count, ...) {
va_list args;
va_start(args, count);
int result = 0;
for (int i = 0; i < count; i++) {
result += va_arg(args, int);
}
va_end(args);
return result;
}
但这种方法的缺点是类型安全由程序员负责,编译器无法进行类型检查。
- 使用宏:通过宏可以根据参数类型选择不同的实现。例如:
#define add(a, b) _Generic((a), \
int: add_int, \
double: add_double \
)(a, b)
这种方法利用了 C11 的_Generic 关键字,但需要预先定义好不同类型的处理函数。
C++ 与 C 的兼容性:由于 C++ 支持函数重载而 C 不支持,为了在 C++ 中调用 C 函数,需要使用 extern "C" 声明:
extern "C" {
int add_int(int a, int b);
double add_double(double a, double b);
}
这样 C++ 编译器会按照 C 的方式处理这些函数名,避免名称修饰。
C 语言不支持函数重载是其设计决策的结果,反映了语言的简洁性和底层特性。在 C 语言中实现类似功能需要使用替代方案,但这些方案都不如 C++ 的函数重载直观和安全。函数重载是 C++ 相对于 C 的一个重要扩展,提高了代码的可读性和灵活性。
什么是左值和右值?请举例说明。
在 C++ 中,左值(lvalue)和右值(rvalue)是表达式的基本属性,它们决定了表达式能否出现在赋值语句的左边或右边。理解左值和右值对于掌握 C++ 的引用、移动语义和重载函数匹配至关重要。
左值(lvalue):左值是一个表示对象或函数的表达式,它具有持久的内存地址,可以被取地址。左值可以出现在赋值语句的左边,但并非所有左值都能被赋值(如 const 对象)。例如:
int x = 10; // x是左值
int* p = &x; // 可以取x的地址
x = 20; // x可以被赋值
const int y = 30; // y是左值,但不能被赋值
// y = 40; // 错误:不能修改const对象
int& ref = x; // 左值引用可以绑定到左值
右值(rvalue):右值是一个临时对象或字面量,它没有持久的内存地址,不能被取地址。右值只能出现在赋值语句的右边。C++11 将右值进一步分为纯右值(prvalue)和将亡值(xvalue):
- 纯右值(prvalue):基本类型的字面量、临时对象、函数返回的非引用类型等。例如:
int a = 5; // 5是纯右值
int b = a + 3; // a+3的结果是纯右值
int func() { return 10; }
int c = func(); // func()的返回值是纯右值
- 将亡值(xvalue):通过 std::move 或类型转换得到的表达式,它表示资源可以被移动。例如:
std::vector<int> v1 = {1, 2, 3};
std::vector<int> v2 = std::move(v1); // std::move(v1)是将亡值
左值引用和右值引用:C++11 引入了右值引用(&&),它可以绑定到右值,用于实现移动语义和完美转发。例如:
int&& rref = 10; // 右值引用绑定到纯右值
rref = 20; // 可以修改右值引用
std::vector<int> getVector() {
return std::vector<int>{1, 2, 3};
}
std::vector<int> vec = getVector(); // getVector()返回的临时对象被移动到vec
左值和右值的判断规则:
- 能取地址的是左值,否则是右值。
- 函数返回左值引用的是左值,返回右值引用或非引用类型的是右值。
- 字面量(如 42、"hello")通常是纯右值,但字符串字面量是左值(因为它们存储在静态存储区)。
移动语义与完美转发:右值引用的主要用途是实现移动语义,避免不必要的深拷贝。例如:
class MyString {
private:
char* data;
size_t length;
public:
// 移动构造函数
MyString(MyString&& other) noexcept : data(other.data), length(other.length) {
other.data = nullptr;
other.length = 0;
}
// 移动赋值运算符
MyString& operator=(MyString&& other) noexcept {
if (this != &other) {
delete[] data;
data = other.data;
length = other.length;
other.data = nullptr;
other.length = 0;
}
return *this;
}
};
左值和右值是 C++ 中重要的概念,它们影响着引用绑定、函数重载解析和对象生命周期管理。理解左值和右值的区别,尤其是右值引用的使用,对于编写高效的 C++ 代码至关重要。
C++ 中子类的构造和析构顺序是怎样的?
在 C++ 的继承体系中,子类对象的构造和析构遵循特定的顺序,这确保了对象的正确初始化和资源释放。以下从几个方面详细分析:
构造顺序:创建子类对象时,构造函数按以下顺序调用:
- 基类构造函数:按照继承列表中的顺序调用直接基类的构造函数。如果有多个基类,按声明顺序调用。
- 成员对象构造函数:按照成员变量在类中声明的顺序调用成员对象的构造函数。
- 子类构造函数:执行子类构造函数的主体。
例如:
class Base1 {
public:
Base1() { std::cout << "Base1 constructor" << std::endl; }
};
class Base2 {
public:
Base2() { std::cout << "Base2 constructor" << std::endl; }
};
class Member {
public:
Member() { std::cout << "Member constructor" << std::endl; }
};
class Derived : public Base2, public Base1 {
private:
Member member;
public:
Derived() { std::cout << "Derived constructor" << std::endl; }
};
int main() {
Derived d;
return 0;
}
输出结果:
Base2 constructor
Base1 constructor
Member constructor
Derived constructor
构造函数调用细节:
- 基类构造函数的调用由子类构造函数的初始化列表控制。如果未显式指定基类构造函数,将调用默认构造函数。
- 如果基类没有默认构造函数,子类必须在初始化列表中显式调用基类的带参构造函数。
例如:
class Base {
public:
Base(int value) { std::cout << "Base constructor: " << value << std::endl; }
};
class Derived : public Base {
public:
Derived(int x) : Base(x) { // 必须显式调用Base的构造函数
std::cout << "Derived constructor" << std::endl;
}
};
析构顺序:销毁子类对象时,析构函数按以下顺序调用:
- 子类析构函数:执行子类析构函数的主体。
- 成员对象析构函数:按照成员变量声明的逆序调用成员对象的析构函数。
- 基类析构函数:按照继承列表的逆序调用直接基类的析构函数。
例如:
class Base1 {
public:
~Base1() { std::cout << "Base1 destructor" << std::endl; }
};
class Base2 {
public:
~Base2() { std::cout << "Base2 destructor" << std::endl; }
};
class Member {
public:
~Member() { std::cout << "Member destructor" << std::endl; }
};
class Derived : public Base2, public Base1 {
private:
Member member;
public:
~Derived() { std::cout << "Derived destructor" << std::endl; }
};
int main() {
{
Derived d;
} // d离开作用域,析构开始
return 0;
}
输出结果:
Derived destructor
Member destructor
Base1 destructor
Base2 destructor
虚析构函数的影响:当通过基类指针删除派生类对象时,如果基类析构函数不是虚函数,只会调用基类的析构函数,导致派生类资源泄漏。例如:
class Base {
public:
~Base() { std::cout << "Base destructor" << std::endl; }
};
class Derived : public Base {
private:
int* data;
public:
Derived() { data = new int[100]; }
~Derived() {
delete[] data;
std::cout << "Derived destructor" << std::endl;
}
};
int main() {
Base* ptr = new Derived();
delete ptr; // 只调用Base的析构函数,Derived的析构函数未被调用
return 0;
}
解决方法是将基类的析构函数声明为虚函数:
class Base {
public:
virtual ~Base() { std::cout << "Base destructor" << std::endl; }
};
这样,当 delete ptr 时,会先调用 Derived 的析构函数,再调用 Base 的析构函数,确保资源正确释放。
多层继承的顺序:在多层继承中,构造和析构顺序同样遵循上述规则。例如:
class A {
public:
A() { std::cout << "A constructor" << std::endl; }
~A() { std::cout << "A destructor" << std::endl; }
};
class B : public A {
public:
B() { std::cout << "B constructor" << std::endl; }
~B() { std::cout << "B destructor" << std::endl; }
};
class C : public B {
public:
C() { std::cout << "C constructor" << std::endl; }
~C() { std::cout << "C destructor" << std::endl; }
};
int main() {
C c;
return 0;
}
输出结果:
A constructor
B constructor
C constructor
C destructor
B destructor
A destructor
C++ 中子类的构造和析构顺序是固定的,构造时从基类到子类,析构时从子类到基类。理解这个顺序对于正确管理对象生命周期和资源至关重要,特别是在处理复杂的继承层次和动态内存分配时。
C++ 中虚函数表的变化过程是怎样的?
C++ 中的虚函数表(Virtual Table,简称 VTable)是实现动态多态的核心机制。当一个类包含虚函数时,编译器会为该类创建一个虚函数表,存储虚函数的地址。虚函数表的变化过程与类的继承、虚函数的重写密切相关。
单继承下的虚函数表:在单继承体系中,每个类有自己的虚函数表。如果子类重写了基类的虚函数,子类的虚函数表会替换相应的函数地址。例如:
class Base {
public:
virtual void func1() { std::cout << "Base::func1" << std::endl; }
virtual void func2() { std::cout << "Base::func2" << std::endl; }
};
class Derived : public Base {
public:
void func1() override { std::cout << "Derived::func1" << std::endl; }
virtual void func3() { std::cout << "Derived::func3" << std::endl; }
};
这个继承体系的虚函数表结构如下:
-
Base 的虚函数表:
- Base::func1()
- Base::func2()
-
Derived 的虚函数表:
- Derived::func1 () // 重写的函数
- Base::func2 () // 未重写的函数
- Derived::func3 () // 新增的虚函数
多继承下的虚函数表:在多继承体系中,子类会为每个基类维护一个虚函数表指针。例如:
class Base1 {
public:
virtual void func1() { std::cout << "Base1::func1" << std::endl; }
};
class Base2 {
public:
virtual void func2() { std::cout << "Base2::func2" << std::endl; }
};
class Derived : public Base1, public Base2 {
public:
void func1() override { std::cout << "Derived::func1" << std::endl; }
void func2() override { std::cout << "Derived::func2" << std::endl; }
virtual void func3() { std::cout << "Derived::func3" << std::endl; }
};
这个继承体系的虚函数表结构如下:
-
Derived 的 Base1 虚函数表:
- Derived::func1()
- Derived::func3 () // 新增的虚函数
-
Derived 的 Base2 虚函数表:
- Derived::func2()
虚继承下的虚函数表:虚继承用于解决菱形继承问题,子类会共享虚基类的虚函数表。例如:
class Base {
public:
virtual void func() { std::cout << "Base::func" << std::endl; }
};
class Derived1 : virtual public Base {
public:
void func() override { std::cout << "Derived1::func" << std::endl; }
};
class Derived2 : virtual public Base {
public:
void func() override { std::cout << "Derived2::func" << std::endl; }
};
class Final : public Derived1, public Derived2 {
public:
void func() override { std::cout << "Final::func" << std::endl; }
};
这个继承体系的虚函数表结构如下:
-
Final 的虚函数表:
- Final::func () // 重写的虚基类函数
-
Final 的 Base 虚函数表:
- Final::func () // 共享同一个实现
虚函数表的动态变化:当对象的类型在运行时确定时,虚函数表的指针会动态调整。例如:
Base* ptr = new Final();
ptr->func(); // 调用Final::func(),通过虚函数表动态绑定
在这个例子中,虽然 ptr 的静态类型是 Base*,但它指向的实际对象是 Final 类型。因此,调用 func () 时会通过 Final 的虚函数表找到 Final::func () 的地址。
虚函数表的初始化:每个包含虚函数的类在程序启动时会初始化其虚函数表。当创建对象时,对象的虚函数表指针会被设置为该类的虚函数表地址。例如:
Final f; // 创建Final对象
// f的虚函数表指针指向Final的虚函数表
虚函数表的变化过程与类的继承结构和虚函数的重写密切相关。在单继承中,子类的虚函数表会替换重写的函数地址;在多继承中,子类为每个基类维护虚函数表;在虚继承中,虚基类的虚函数表被共享。理解虚函数表的工作原理对于掌握 C++ 的动态多态机制至关重要。
C++ 中 STL 的六大组件分别是什么?在项目中使用过哪些组件?
C++ 标准模板库(STL)是 C++ 标准库的核心组成部分,提供了通用的算法和数据结构,大大提高了代码的复用性和效率。STL 由六大组件构成,每个组件都有其独特的功能和应用场景。
容器(Containers):容器是用于存储和管理数据的类模板。STL 提供了多种容器,分为序列式容器、关联式容器和无序容器。
- 序列式容器:如 vector、list、deque,元素按插入顺序存储。
- 关联式容器:如 set、map,元素按键排序,支持快速查找。
- 无序容器:如 unordered_set、unordered_map,基于哈希表实现,提供平均 O (1) 的查找时间。
算法(Algorithms):算法是操作容器中元素的函数模板。STL 提供了丰富的算法,如排序(sort)、查找(find)、复制(copy)、转换(transform)等。算法与容器分离,通过迭代器实现通用化,可应用于不同类型的容器。
迭代器(Iterators):迭代器是一种抽象的指针,用于遍历容器中的元素。STL 定义了五种迭代器类别:输入迭代器、输出迭代器、前向迭代器、双向迭代器和随机访问迭代器。不同容器支持不同类型的迭代器,例如 vector 支持随机访问迭代器,而 list 支持双向迭代器。
适配器(Adapters):适配器是一种特殊的容器,它通过修改现有容器的接口来提供不同的功能。常见的适配器有 stack、queue 和 priority_queue,它们通常基于 deque 或 vector 实现。
分配器(Allocators):分配器是负责内存分配和释放的类模板。STL 容器默认使用 std::allocator,但用户可以自定义分配器来满足特定需求,如内存池管理。
函数对象(Function Objects):函数对象是重载了函数调用运算符 () 的类或结构体,也称为仿函数。它们可以像函数一样被调用,并且可以保存状态。STL 提供了许多预定义的函数对象,如 less、greater 等,用于算法中的比较操作。
项目中使用的 STL 组件示例:
- vector:在需要动态数组的场景中使用,例如存储用户数据或中间计算结果。vector 支持随机访问,并且可以自动扩容。
- map:在需要键值对存储和快速查找的场景中使用,例如缓存系统或配置管理。map 基于红黑树实现,保证元素按键有序。
- unordered_map:在需要高效查找且不要求元素有序的场景中使用,例如哈希表实现的缓存。unordered_map 基于哈希表,平均查找时间为 O (1)。
- sort 算法:对容器中的元素进行排序,例如对用户列表按年龄或姓名排序。
- lambda 表达式:作为函数对象传递给算法,例如在 sort 中自定义比较函数。
在一个典型的项目中,这些组件经常组合使用。例如,使用 vector 存储数据,用 sort 算法对数据进行排序,再用 map 建立索引以便快速查找。STL 的六大组件通过迭代器无缝协作,提供了强大而灵活的编程工具。
vector 的底层实现原理是什么?resize、reserve 和 insert 方法的工作机制分别是什么?
C++ 中的 vector 是一个动态数组,它提供了与数组相似的随机访问能力,但可以自动调整大小。理解 vector 的底层实现和方法工作机制对于高效使用它至关重要。
底层实现原理:vector 的底层实现基于动态数组,通常包含三个指针:
- begin:指向数组的起始位置。
- end:指向最后一个有效元素的下一个位置。
- capacity_end:指向数组的容量末尾。
vector 的容量(capacity)是指当前分配的内存能够容纳的元素数量,而大小(size)是指实际存储的元素数量。当元素数量超过容量时,vector 会重新分配更大的内存空间,并将原有元素复制到新空间。
resize 方法:resize 用于改变 vector 的大小。如果新大小大于当前大小,会在末尾添加默认构造的元素;如果新大小小于当前大小,会删除超出的元素。例如:
std::vector<int> v = {1, 2, 3};
v.resize(5); // v现在包含 {1, 2, 3, 0, 0}
v.resize(2); // v现在包含 {1, 2}
resize 可能会导致容量增加,但不会减少容量。如果新大小超过当前容量,vector 会重新分配内存,通常是按两倍增长策略。
reserve 方法:reserve 用于预分配内存,增加 vector 的容量,但不改变其大小。例如:
std::vector<int> v;
v.reserve(100); // 预分配100个元素的空间
reserve 不会创建新元素,只是增加容量。如果预分配的容量小于当前容量,reserve 不会有任何效果。这在需要插入大量元素时很有用,可以避免多次重新分配内存。
insert 方法:insert 用于在指定位置插入元素。它有多种重载形式,例如在指定位置插入单个元素、插入多个相同元素或插入一个范围的元素。例如:
std::vector<int> v = {1, 2, 4};
auto it = v.begin() + 2;
v.insert(it, 3); // 在位置2插入3,v现在包含 {1, 2, 3, 4}
insert 的工作机制如下:
- 如果插入后元素数量不超过容量,vector 会将插入位置之后的所有元素向后移动,并在插入位置放置新元素。
- 如果插入后元素数量超过容量,vector 会重新分配更大的内存空间(通常是两倍),将原有元素复制到新空间,然后在指定位置插入新元素。
insert 操作的时间复杂度取决于插入位置:在末尾插入是 O (1)(如果不需要重新分配),在中间或开头插入是 O (n)。
内存管理策略:vector 的内存增长通常采用指数增长策略,即每次需要扩容时,容量翻倍。这种策略保证了插入操作的均摊时间复杂度为 O (1)。例如:
std::vector<int> v;
for (int i = 0; i < 10; i++) {
v.push_back(i);
std::cout << "Size: " << v.size() << ", Capacity: " << v.capacity() << std::endl;
}
可能的输出:
Size: 1, Capacity: 1
Size: 2, Capacity: 2
Size: 3, Capacity: 4
Size: 4, Capacity: 4
Size: 5, Capacity: 8
Size: 6, Capacity: 8
Size: 7, Capacity: 8
Size: 8, Capacity: 8
Size: 9, Capacity: 16
Size: 10, Capacity: 16
理解 vector 的底层实现和方法工作机制有助于优化代码性能。例如,在插入大量元素前使用 reserve 预分配内存可以减少重新分配的次数,而 resize 可以用于初始化 vector 的大小。
vector 如何实现扩容?是否可以不拷贝元素实现扩容?
vector 是 C++ 标准库中的一个动态数组容器,其扩容机制是其实现的重要部分。理解 vector 的扩容过程以及是否能不拷贝元素实现扩容,对于掌握 vector 的性能和使用方法很关键。
vector 的扩容过程:vector 在存储元素时,其实际分配的内存空间(容量,capacity)通常大于当前存储的元素数量(大小,size)。当插入新元素导致元素数量超过当前容量时,vector 会进行扩容操作,具体步骤如下:
- 分配新内存:vector 会分配一块更大的内存空间,新空间的大小通常是原容量的两倍(不同实现可能有所不同,但一般遵循指数增长策略)。例如,若原容量为 4,新容量可能为 8。
- 拷贝元素:将原 vector 中的元素逐个拷贝到新分配的内存空间中。这是通过迭代器遍历原 vector 的元素,并使用拷贝构造函数或移动构造函数(C++11 及以后)来完成的。
- 释放旧内存:拷贝完元素后,vector 会释放原有的内存空间,从而完成扩容操作。
以下是一个简单的代码示例,展示 vector 的扩容过程:
#include <iostream>
#include <vector>
int main() {
std::vector<int> v;
std::cout << "Initial capacity: " << v.capacity() << std::endl;
// 插入元素,触发扩容
for (int i = 0; i < 10; ++i) {
v.push_back(i);
std::cout << "Size: " << v.size() << ", Capacity: " << v.capacity() << std::endl;
}
return 0;
}
是否可以不拷贝元素实现扩容:在传统的 vector 扩容中,元素拷贝是必要的,因为新内存空间与旧内存空间是独立的。然而,C++11 引入了移动语义,使得在某些情况下可以避免不必要的元素拷贝。当 vector 的元素类型支持移动构造函数时,在扩容过程中,原 vector 的元素会使用移动构造函数移动到新的内存空间,而不是拷贝构造函数。移动构造函数通常比拷贝构造函数更高效,因为它不需要复制数据,而是将资源的所有权转移到新对象。
以下是一个示例,展示移动语义在 vector 扩容中的应用:
#include <iostream>
#include <vector>
#include <string>
class MyClass {
public:
MyClass() { std::cout << "Default constructor" << std::endl; }
MyClass(const MyClass&) { std::cout << "Copy constructor" << std::endl; }
MyClass(MyClass&&) { std::cout << "Move constructor" << std::endl; }
~MyClass() { std::cout << "Destructor" << std::endl; }
};
int main() {
std::vector<MyClass> v;
for (int i = 0; i < 2; ++i) {
v.push_back(MyClass());
}
return 0;
}
在上述示例中,当 vector 扩容时,如果元素类型(MyClass)提供了移动构造函数,vector 会优先使用移动构造函数将元素移动到新的内存空间,从而减少拷贝操作。
vector 的扩容是通过分配新内存、拷贝或移动元素以及释放旧内存来实现的。虽然传统扩容需要拷贝元素,但 C++11 的移动语义使得在某些情况下可以通过移动元素来提高扩容效率,减少不必要的拷贝操作。
vector 和 list 的使用场景有何区别?
C++ 中的 vector 和 list 都是标准库中的容器,但它们的底层实现和特性不同,这导致了它们在使用场景上存在明显的区别。理解这些区别对于选择合适的容器来解决具体问题非常重要。
vector 的特点和使用场景:
- 底层实现:vector 是一个动态数组,其元素在内存中是连续存储的。这意味着可以通过索引快速访问元素,时间复杂度为 O (1)。
- 随机访问:由于内存连续,vector 支持高效的随机访问,适合需要频繁访问特定位置元素的场景,例如数组运算、数据遍历等。
- 插入和删除操作:在 vector 的末尾插入或删除元素通常是高效的,时间复杂度为 O (1)。但在中间位置插入或删除元素时,需要移动后续元素,时间复杂度为 O (n)。
- 扩容机制:当 vector 的元素数量超过当前容量时,会进行扩容操作,通常是分配一块更大的内存空间,将原元素拷贝或移动到新空间,然后释放旧内存。
以下是 vector 的使用示例:
#include <iostream>
#include <vector>
int main() {
std::vector<int> v = {1, 2, 3};
// 随机访问
std::cout << "Element at index 1: " << v[1] << std::endl;
// 末尾插入
v.push_back(4);
// 中间插入(效率较低)
v.insert(v.begin() + 1, 5);
return 0;
}
list 的特点和使用场景:
- 底层实现:list 是一个双向链表,每个节点包含一个元素和两个指针,分别指向前一个节点和后一个节点。
- 随机访问:list 不支持高效的随机访问,访问第 n 个元素需要从链表头或尾开始遍历,时间复杂度为 O (n)。
- 插入和删除操作:在 list 的任意位置插入或删除元素都很高效,时间复杂度为 O (1),因为只需要修改指针,不需要移动元素。
- 内存管理:list 的内存是动态分配的,每个节点独立分配内存,因此不需要像 vector 那样进行扩容操作。
以下是 list 的使用示例:
#include <iostream>
#include <list>
int main() {
std::list<int> l = {1, 2, 3};
// 遍历
for (auto it = l.begin(); it != l.end(); ++it) {
std::cout << *it << " ";
}
// 任意位置插入
l.insert(++l.begin(), 4);
// 删除元素
l.erase(++l.begin());
return 0;
}
使用场景的区别总结:
- 需要随机访问:如果需要频繁访问特定位置的元素,如数组运算、数据遍历等,vector 是更好的选择。
- 频繁的插入和删除操作:如果需要在容器中间频繁插入或删除元素,list 更高效,尤其是在插入和删除操作较多而随机访问较少的场景,如链表操作、队列操作等。
- 内存管理:vector 的内存是连续分配的,适合存储大量连续数据;list 的内存是分散分配的,每个节点独立,适合存储不连续的数据。
- 数据增长和扩容:vector 在元素数量超过容量时需要扩容,可能会导致数据拷贝;list 不需要扩容,因为每个节点独立分配内存。
vector 和 list 在底层实现、随机访问、插入删除操作和内存管理等方面存在显著差异。根据具体的应用场景,选择合适的容器可以提高程序的性能和效率。
vector 和数组的本质区别是什么?
在 C++ 中,vector 是标准库中的容器,而数组是一种内置的数据类型。它们在多个方面存在本质区别,理解这些区别对于正确使用它们非常重要。
内存管理:
- 数组:数组的内存是在栈上或堆上静态或动态分配的。静态数组在编译时确定大小,其内存分配在栈上,生命周期与所在作用域相同。动态数组通过
new运算符在堆上分配内存,需要手动使用delete释放内存。例如:
int staticArray[5]; // 静态数组,内存分配在栈上
int* dynamicArray = new int[5]; // 动态数组,内存分配在堆上
delete[] dynamicArray; // 手动释放动态数组内存
- vector:vector 的内存由其内部管理,通过分配器(allocator)来分配和释放内存。vector 在需要时会自动进行内存的分配和释放,不需要手动管理内存。当 vector 的元素数量超过当前容量时,它会自动扩容,分配更大的内存空间,并将原元素拷贝或移动到新空间。例如:
std::vector<int> v;
v.push_back(1); // vector自动管理内存,可能会触发扩容
大小和可变性:
- 数组:数组的大小在定义时或分配内存时确定,一旦确定就不能改变。静态数组的大小在编译时确定,动态数组的大小在使用
new分配内存时确定。例如:
int arr[10]; // 大小为10的静态数组,大小不可变
- vector:vector 是动态数组,其大小可以在运行时改变。可以通过
push_back、insert等方法添加元素,通过pop_back、erase等方法删除元素。vector 的大小会根据元素的添加和删除自动调整。例如:
std::vector<int> v;
v.push_back(1); // vector大小增加
v.pop_back(); // vector大小减小
访问元素:
- 数组:数组支持通过索引快速访问元素,索引从 0 开始。可以使用
[]运算符或指针算术运算来访问数组元素。例如:
int arr[5] = {1, 2, 3, 4, 5};
int element = arr[2]; // 通过索引访问元素
int* ptr = arr;
int element2 = *(ptr + 3); // 通过指针算术运算访问元素
- vector:vector 也支持通过索引访问元素,使用
[]运算符或at成员函数。[]运算符不进行边界检查,而at函数会进行边界检查并在越界时抛出std::out_of_range异常。例如:
std::vector<int> v = {1, 2, 3};
int element = v[1]; // 使用[]运算符访问元素
int element2 = v.at(2); // 使用at函数访问元素
迭代器和算法支持:
- 数组:数组本身不提供迭代器,需要使用指针来遍历数组元素。虽然 C++ 标准库中的算法可以操作数组,但需要传递数组的首地址和元素个数。例如:
int arr[5] = {1, 2, 3, 4, 5};
std::sort(arr, arr + 5); // 对数组进行排序
- vector:vector 提供了迭代器,支持使用标准库中的各种算法。迭代器是一种抽象的指针,用于遍历 vector 中的元素。例如:
std::vector<int> v = {3, 1, 2};
std::sort(v.begin(), v.end()); // 对vector进行排序
vector 和数组在内存管理、大小可变性、访问元素方式以及对迭代器和算法的支持等方面存在本质区别。vector 提供了更高级的功能和更好的内存管理,而数组则更底层,需要手动管理内存和大小。根据具体的需求选择合适的数据结构可以提高程序的性能和可维护性。
map 和 unordered_map 的底层实现和扩容机制分别是什么?
在 C++ 标准库中,map 和 unordered_map 都是用于存储键值对的关联容器,但它们的底层实现和扩容机制有所不同。了解这些差异有助于根据具体需求选择合适的容器。
map 的底层实现和扩容机制:
- 底层实现:map 的底层通常使用红黑树(一种自平衡的二叉搜索树)来实现。红黑树保证了插入、删除和查找操作的时间复杂度为 O (log n),其中 n 是 map 中元素的数量。每个节点包含一个键值对,键用于排序和查找,值是与键关联的数据。例如:
#include <map>
#include <string>
#include <iostream>
int main() {
std::map<std::string, int> m;
m["apple"] = 1;
m["banana"] = 2;
// 红黑树保证键的有序性
for (const auto& pair : m) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
return 0;
}
- 扩容机制:当 map 插入新元素时,如果红黑树的结构需要调整以保持平衡,可能会涉及到节点的旋转和颜色调整。虽然红黑树没有像动态数组那样的 “扩容” 概念,但随着元素的增加,树的高度会增长,查找操作的时间复杂度仍然保持为 O (log n)。在极端情况下,当树的高度过高时,可能会影响性能,但这种情况相对较少见。
unordered_map 的底层实现和扩容机制:
- 底层实现:unordered_map 的底层使用哈希表(Hash Table)来实现。哈希表通过哈希函数将键映射到特定的桶(bucket)中,从而实现快速查找。每个桶可以存储一个或多个键值对,当多个键映射到同一个桶时,会发生哈希冲突,通常使用链地址法(Separate Chaining)或开放地址法(Open Addressing)来解决冲突。例如:
#include <unordered_map>
#include <string>
#include <iostream>
int main() {
std::unordered_map<std::string, int> um;
um["apple"] = 1;
um["banana"] = 2;
// 哈希表不保证键的有序性
for (const auto& pair : um) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
return 0;
}
- 扩容机制:unordered_map 有一个负载因子(load factor),表示哈希表中元素数量与桶数量的比例。当元素数量超过负载因子与桶数量的乘积时,unordered_map 会进行扩容操作。扩容时,会创建一个更大的哈希表,将原哈希表中的元素重新哈希到新表中。这个过程可能会导致性能开销,因为需要重新计算每个元素的哈希值并插入到新表中。例如:
std::unordered_map<int, int> um;
// 当元素数量超过负载因子与桶数量的乘积时,unordered_map会扩容
for (int i = 0; i < 1000; ++i) {
um[i] = i * 2;
}
两者的比较:
- 查找效率:在理想情况下,unordered_map 的查找操作平均时间复杂度为 O (1),而 map 的查找时间复杂度为 O (log n)。但在哈希冲突严重的情况下,unordered_map 的查找时间可能会退化到 O (n)。
- 空间效率:unordered_map 可能会浪费一些空间来存储哈希表的桶和解决哈希冲突,而 map 的空间利用率相对较高,因为它是基于树结构的。
- 有序性:map 保证键的有序性,而 unordered_map 不保证键的顺序。
map 和 unordered_map 在底层实现和扩容机制上有明显的区别。map 适用于需要键有序的场景,而 unordered_map 适用于对查找效率要求高且不关心键顺序的场景。根据具体需求选择合适的容器可以优化程序的性能和空间利用率。
如何实现 vector 扩容时不拷贝元素?
在 C++ 中,vector 是一个动态数组容器,当插入元素导致容量不足时,vector 会进行扩容操作。传统的扩容过程中,原 vector 的元素会被拷贝到新的内存空间,这可能会带来性能开销,特别是对于大型对象或频繁扩容的情况。C++11 引入的移动语义可以在一定程度上避免不必要的元素拷贝,实现 vector 扩容时不拷贝元素。以下是具体的实现方法和原理:
移动语义与 vector 扩容:
移动语义允许将一个对象的资源(如动态分配的内存)转移到另一个对象,而不是进行拷贝。当 vector 的元素类型支持移动构造函数时,在扩容过程中,原 vector 的元素会使用移动构造函数移动到新的内存空间,而不是拷贝构造函数。移动构造函数通常比拷贝构造函数更高效,因为它不需要复制数据,而是将资源的所有权转移到新对象。
示例代码:
#include <iostream>
#include <vector>
#include <string>
class MyClass {
public:
MyClass() { std::cout << "Default constructor" << std::endl; }
MyClass(const MyClass&) { std::cout << "Copy constructor" << std::endl; }
MyClass(MyClass&&) { std::cout << "Move constructor" << std::endl; }
~MyClass() { std::cout << "Destructor" << std::endl; }
};
int main() {
std::vector<MyClass> v;
for (int i = 0; i < 2; ++i) {
v.push_back(MyClass());
}
return 0;
}
在上述代码中,MyClass类提供了移动构造函数。当vector扩容时,如果元素类型(MyClass)提供了移动构造函数,vector会优先使用移动构造函数将元素移动到新的内存空间,从而减少拷贝操作。
原理分析:
- 分配新内存:当
vector需要扩容时,它会分配一块更大的内存空间。 - 移动元素:原
vector中的元素会使用移动构造函数移动到新的内存空间。移动构造函数会将原对象的资源(如指针)转移到新对象,而不是复制数据。 - 释放旧内存:移动完元素后,原
vector会
C++ 内存管理机制是如何设计的?
C++ 内存管理机制是其核心特性之一,它提供了灵活但复杂的内存控制方式。该机制主要基于三个层面:栈内存、堆内存和静态存储区,同时通过不同的内存分配和释放方式以及智能指针来确保内存的有效使用和避免泄漏。
内存区域分类:C++ 程序的内存通常分为四个主要区域。栈内存(Stack)由编译器自动管理,存储局部变量和函数调用信息。当函数被调用时,其参数和局部变量被压入栈中,函数返回时这些变量自动销毁。栈内存的分配和释放速度快,但容量有限。堆内存(Heap)则用于动态分配内存,由程序员手动管理(或通过智能指针自动管理)。堆内存的空间较大,但分配和释放的效率较低。静态存储区(Static Storage)存储全局变量和静态变量,在程序启动时分配,程序结束时释放。常量存储区(Constant Storage)存储常量值,通常是只读的。
内存分配和释放操作符:C++ 提供了 new 和 delete 操作符用于动态内存管理。new 操作符用于在堆上分配内存并初始化对象,而 delete 操作符用于释放 new 分配的内存并销毁对象。例如:int* ptr = new int(42); 分配一个整数并初始化为 42,delete ptr; 释放该内存。对于数组,使用 new[] 和 delete[],如 int* arr = new int[10]; delete[] arr;。这种手动管理方式要求程序员确保每个 new 都有对应的 delete,否则会导致内存泄漏。
智能指针:为了简化内存管理并避免泄漏,C++ 引入了智能指针。智能指针是一种类模板,它通过 RAII(资源获取即初始化)技术自动管理动态分配的内存。当智能指针离开作用域时,其析构函数会自动释放所指向的内存。C++11 引入了三种主要的智能指针:unique_ptr、shared_ptr 和 weak_ptr。unique_ptr 独占所指向的对象,不允许拷贝但可以转移所有权;shared_ptr 使用引用计数来管理多个指针共享的对象,当引用计数为零时自动释放内存;weak_ptr 是 shared_ptr 的弱引用,不增加引用计数,用于解决循环引用问题。
内存管理的挑战:手动内存管理容易导致多种问题。内存泄漏发生在动态分配的内存未被释放时,长期运行的程序可能因此耗尽内存。野指针指向已释放的内存,访问野指针会导致未定义行为。双重释放是指对同一块内存多次调用 delete,也会导致未定义行为。循环引用则发生在两个或多个对象通过 shared_ptr 相互引用时,导致引用计数永远不为零,从而造成内存泄漏。智能指针的引入大大减少了这些问题,但程序员仍需正确使用它们。
高级内存管理技术:C++ 还提供了更高级的内存管理技术。自定义分配器(Allocator)允许用户控制内存分配的细节,例如使用内存池来提高性能。定位 new(Placement New)允许在已分配的内存块上构造对象,这在实现内存池或高性能数据结构时非常有用。标准库中的容器(如 vector、list)和智能指针都使用了这些技术来优化内存使用。此外,C++17 引入了 std::pmr(多态内存资源),提供了更灵活的内存分配策略,允许在运行时选择不同的内存分配器。
C++ 内存管理机制通过多种方式提供了强大而灵活的内存控制能力。从手动的 new 和 delete 到自动的智能指针,从栈内存到堆内存,每个组件都有其特定的用途和挑战。理解这些机制对于编写高效、安全的 C++ 代码至关重要。
请解释智能指针 unique_ptr 的使用场景和实现原理。
unique_ptr 是 C++ 标准库中的一种智能指针,用于管理动态分配的内存资源,确保资源在不再需要时被自动释放。它通过独占所有权的方式来实现这一目标,即同一时间只能有一个 unique_ptr 指向特定的资源。这种设计使得 unique_ptr 成为管理动态资源的安全且高效的工具。
使用场景:unique_ptr 适用于多种场景。当需要确保一个对象在任何时候都只有一个所有者时,unique_ptr 是理想选择。例如,在实现工厂模式时,工厂函数通常返回一个 unique_ptr,将对象的所有权转移给调用者。在资源管理方面,unique_ptr 可以封装各种系统资源,如文件句柄、网络连接或图形上下文,确保这些资源在 unique_ptr 离开作用域时被正确释放。此外,unique_ptr 还可以作为容器元素,用于存储动态分配的对象,避免手动管理内存。
实现原理:unique_ptr 的核心是通过 RAII(资源获取即初始化)技术和移动语义来实现的。当一个 unique_ptr 被创建时,它获取资源的所有权;当它离开作用域时,其析构函数会自动释放资源。unique_ptr 禁止拷贝构造和拷贝赋值,因为拷贝会导致多个指针指向同一资源,违反独占所有权的原则。但它支持移动构造和移动赋值,允许资源的所有权从一个 unique_ptr 转移到另一个。这种转移通过移动构造函数和移动赋值运算符实现,它们会将源 unique_ptr 置为 nullptr,确保资源的独占性。
示例代码:
#include <memory>
#include <iostream>
class MyClass {
public:
MyClass() { std::cout << "MyClass constructor" << std::endl; }
~MyClass() { std::cout << "MyClass destructor" << std::endl; }
void doSomething() { std::cout << "Doing something..." << std::endl; }
};
void createAndUse() {
std::unique_ptr<MyClass> ptr = std::make_unique<MyClass>();
ptr->doSomething();
// ptr 离开作用域时,自动释放资源
} // 析构函数在此处被调用
int main() {
createAndUse();
// 移动语义示例
std::unique_ptr<MyClass> ptr1 = std::make_unique<MyClass>();
std::unique_ptr<MyClass> ptr2 = std::move(ptr1); // 所有权转移
if (!ptr1) {
std::cout << "ptr1 is now null" << std::endl;
}
ptr2->doSomething();
return 0;
}
自定义删除器:unique_ptr 允许用户自定义删除器(Deleter),以处理非标准的资源释放方式。默认情况下,unique_ptr 使用 delete 释放资源,但对于某些资源(如文件句柄或 Windows API 句柄),需要特定的释放函数。可以通过模板参数或构造函数参数指定自定义删除器。例如:
std::unique_ptr<FILE, decltype(&fclose)> file(fopen("test.txt", "r"), &fclose);
在容器中的应用:unique_ptr 可以作为容器(如 vector 或 map)的元素,用于存储动态分配的对象。由于 unique_ptr 不可拷贝,需要使用移动语义将其插入容器:
std::vector<std::unique_ptr<MyClass>> vec;
vec.push_back(std::make_unique<MyClass>());
注意事项:在使用 unique_ptr 时,需要注意避免将原始指针暴露给外部,因为这可能导致多个指针管理同一资源。此外,虽然 unique_ptr 可以转换为 shared_ptr(通过 std::shared_ptr 的构造函数),但这种转换会导致所有权转移,原 unique_ptr 会变为 nullptr。
unique_ptr 通过独占所有权和移动语义,为动态资源管理提供了安全且高效的解决方案。它适用于多种场景,特别是需要确保资源唯一所有者的情况。通过理解其实现原理和使用方法,可以有效避免内存泄漏和野指针问题,提高代码的健壮性。
weak_ptr 的作用是什么?如何避免使用 weak_ptr 导致崩溃?
weak_ptr 是 C++ 标准库中的一种智能指针,用于解决 shared_ptr 可能引起的循环引用问题。它提供了对 shared_ptr 所管理对象的弱引用,不会增加对象的引用计数,因此不会阻止对象被销毁。理解 weak_ptr 的作用和正确使用方法对于避免内存泄漏和程序崩溃至关重要。
循环引用问题:当两个或多个对象通过 shared_ptr 相互引用时,会形成循环引用。每个对象的引用计数至少为 1,即使这些对象在程序中不再被使用,它们的引用计数也不会变为 0,导致内存泄漏。例如:
#include <memory>
class B;
class A {
public:
std::shared_ptr<B> b_ptr;
~A() { std::cout << "A destructor" << std::endl; }
};
class B {
public:
std::shared_ptr<A> a_ptr;
~B() { std::cout << "B destructor" << std::endl; }
};
void createCycle() {
std::shared_ptr<A> a = std::make_shared<A>();
std::shared_ptr<B> b = std::make_shared<B>();
a->b_ptr = b;
b->a_ptr = a;
// a 和 b 离开作用域,但由于循环引用,它们不会被销毁
} // 内存泄漏发生
weak_ptr 的作用:weak_ptr 可以打破循环引用。它允许一个对象引用另一个对象,但不增加其引用计数。当 shared_ptr 管理的对象被销毁时,所有指向该对象的 weak_ptr 都会自动变为空,因此可以安全地检查对象是否存在。在上面的例子中,如果将 B::a_ptr 改为 weak_ptr,则循环引用被打破,对象可以被正确销毁。
使用 weak_ptr 避免崩溃:为了安全地使用 weak_ptr,需要遵循以下原则。在使用 weak_ptr 访问对象之前,必须先通过 lock() 方法创建一个临时的 shared_ptr。lock() 方法会检查对象是否仍然存在,如果存在则返回一个 shared_ptr,增加引用计数,确保对象在使用期间不会被销毁;如果对象已被销毁,则返回一个空的 shared_ptr。例如:
#include <memory>
#include <iostream>
class B;
class A {
public:
std::shared_ptr<B> b_ptr;
void doSomething() { std::cout << "A::doSomething" << std::endl; }
};
class B {
public:
std::weak_ptr<A> a_ptr; // 使用 weak_ptr 避免循环引用
void accessA() {
std::shared_ptr<A> a = a_ptr.lock(); // 创建临时 shared_ptr
if (a) {
a->doSomething(); // 对象存在,安全访问
} else {
std::cout << "A is no longer available" << std::endl;
}
}
};
void safeUsage() {
std::shared_ptr<A> a = std::make_shared<A>();
std::shared_ptr<B> b = std::make_shared<B>();
a->b_ptr = b;
b->a_ptr = a;
b->accessA(); // 安全访问,a 仍然存在
a.reset(); // 释放 a
b->accessA(); // 输出 "A is no longer available"
}
其他注意事项:避免长时间持有通过 lock() 创建的 shared_ptr,因为这会延长对象的生命周期。只在需要访问对象时临时创建 shared_ptr。不要从 weak_ptr 直接获取原始指针,因为原始指针可能已经无效。始终通过 lock() 获取 shared_ptr 后再进行操作。注意 weak_ptr 的生命周期,确保在使用 weak_ptr 时,它所引用的 shared_ptr 仍然有效。
weak_ptr 是解决循环引用问题的关键工具,但必须正确使用以避免崩溃。通过在访问对象前使用 lock() 方法创建临时 shared_ptr,并遵循安全使用原则,可以确保代码的健壮性。理解 weak_ptr 的作用和实现原理是编写高效、安全的 C++ 代码的重要组成部分。
shared_ptr 和 unique_ptr 的实现原理有何不同?
shared_ptr 和 unique_ptr 是 C++ 标准库中两种重要的智能指针,它们在内存管理上采用了不同的策略。shared_ptr 通过引用计数实现共享所有权,允许多个指针指向同一个对象;而 unique_ptr 则通过独占所有权确保同一时间只有一个指针管理对象。理解它们的实现原理有助于在不同场景下选择合适的智能指针。
shared_ptr 的实现原理:shared_ptr 的核心是引用计数机制。每个 shared_ptr 对象包含一个指向对象的指针和一个指向控制块(Control Block)的指针。控制块是一个动态分配的结构体,包含引用计数(记录有多少个 shared_ptr 指向该对象)、弱引用计数(记录有多少个 weak_ptr 指向该对象)以及删除器和分配器等信息。当创建一个 shared_ptr 时,引用计数初始化为 1。每当一个 shared_ptr 被拷贝(如通过拷贝构造函数或赋值运算符),引用计数加 1;当一个 shared_ptr 被销毁(如离开作用域或被重置),引用计数减 1。当引用计数变为 0 时,控制块会调用删除器释放对象内存。控制块本身则在弱引用计数也变为 0 时被释放。
示例代码:
#include <memory>
#include <iostream>
class MyClass {
public:
MyClass() { std::cout << "Constructor" << std::endl; }
~MyClass() { std::cout << "Destructor" << std::endl; }
};
void sharedPtrExample() {
std::shared_ptr<MyClass> ptr1 = std::make_shared<MyClass>();
std::cout << "ptr1 use count: " << ptr1.use_count() << std::endl; // 输出 1
{
std::shared_ptr<MyClass> ptr2 = ptr1; // 拷贝,引用计数加 1
std::cout << "ptr1 use count: " << ptr1.use_count() << std::endl; // 输出 2
std::cout << "ptr2 use count: " << ptr2.use_count() << std::endl; // 输出 2
} // ptr2 离开作用域,引用计数减 1
std::cout << "ptr1 use count: " << ptr1.use_count() << std::endl; // 输出 1
} // ptr1 离开作用域,引用计数变为 0,对象被销毁
unique_ptr 的实现原理:unique_ptr 采用独占所有权模型,禁止拷贝构造和拷贝赋值,确保同一时间只有一个 unique_ptr 指向特定对象。它通过将拷贝构造函数和拷贝赋值运算符声明为删除函数(= delete)来实现这一点。不过,unique_ptr 支持移动构造和移动赋值,允许资源的所有权从一个 unique_ptr 转移到另一个。当发生移动时,源 unique_ptr 会被置为 nullptr,目标 unique_ptr 获得资源的所有权。unique_ptr 的析构函数会在其离开作用域时释放所指向的对象。由于 unique_ptr 不使用引用计数,它的实现更加轻量级,性能也更好。
示例代码:
#include <memory>
#include <iostream>
class MyClass {
public:
MyClass() { std::cout << "Constructor" << std::endl; }
~MyClass() { std::cout << "Destructor" << std::endl; }
};
void uniquePtrExample() {
std::unique_ptr<MyClass> ptr1 = std::make_unique<MyClass>();
// std::unique_ptr<MyClass> ptr2 = ptr1; // 错误:拷贝构造函数被删除
std::unique_ptr<MyClass> ptr2 = std::move(ptr1); // 移动构造,所有权转移
std::cout << "ptr1 is null: " << (ptr1 == nullptr) << std::endl; // 输出 1 (true)
ptr2.reset(); // 显式释放资源
std::cout << "ptr2 is null: " << (ptr2 == nullptr) << std::endl; // 输出 1 (true)
}
关键区别总结:
- 所有权模型:
shared_ptr允许多个指针共享同一个对象,而unique_ptr独占对象的所有权。 - 内存开销:
shared_ptr需要额外的控制块来存储引用计数和其他信息,而unique_ptr只需要存储指向对象的指针,内存开销更小。 - 性能:
shared_ptr的拷贝和赋值操作涉及原子操作(用于更新引用计数),而unique_ptr的移动操作几乎没有开销。 - 使用场景:
shared_ptr适用于需要共享资源的场景,而unique_ptr适用于资源的生命周期应该与单个所有者绑定的场景。
shared_ptr 和 unique_ptr 在实现原理上的差异决定了它们的适用场景。shared_ptr 通过引用计数提供了灵活的资源共享机制,但增加了内存和性能开销;而 unique_ptr 通过独占所有权提供了高效、安全的资源管理方式。理解这些差异有助于在编写 C++ 代码时做出合适的选择。
常用的设计模式有哪些?请举例说明。
设计模式是软件开发中针对反复出现的问题所总结的通用解决方案。C++ 作为一种广泛使用的编程语言,常应用多种设计模式来提高代码的可维护性、可扩展性和复用性。以下介绍几种常见的设计模式及其应用场景。
单例模式(Singleton Pattern):确保一个类只有一个实例,并提供一个全局访问点。单例模式常用于需要全局唯一资源的场景,如配置管理器、日志系统或数据库连接池。实现单例模式的关键是将构造函数私有化,防止外部实例化,并提供一个静态方法来获取唯一实例。例如:
class Logger {
private:
static Logger* instance;
Logger() = default; // 私有构造函数
Logger(const Logger&) = delete; // 禁止拷贝
Logger& operator=(const Logger&) = delete; // 禁止赋值
public:
static Logger* getInstance() {
if (instance == nullptr) {
instance = new Logger();
}
return instance;
}
void log(const std::string& message) {
// 实现日志记录逻辑
}
};
// 初始化静态成员
Logger* Logger::instance = nullptr;
工厂模式(Factory Pattern):定义一个创建对象的接口,让子类决定实例化哪个类。工厂模式将对象的创建和使用分离,提高了代码的可维护性。例如,一个图形绘制系统可能使用工厂模式来创建不同类型的图形:
class Shape {
public:
virtual void draw() = 0;
virtual ~Shape() = default;
};
class Circle : public Shape {
public:
void draw() override { std::cout << "Drawing Circle" << std::endl; }
};
class Rectangle : public Shape {
public:
void draw() override { std::cout << "Drawing Rectangle" << std::endl; }
};
class ShapeFactory {
public:
static std::unique_ptr<Shape> createShape(const std::string& type) {
if (type == "circle") {
return std::make_unique<Circle>();
} else if (type == "rectangle") {
return std::make_unique<Rectangle>();
}
return nullptr;
}
};
观察者模式(Observer Pattern):定义对象间的一对多依赖关系,当一个对象的状态发生改变时,所有依赖它的对象都会得到通知并自动更新。这种模式常用于事件处理系统、消息通知等场景。例如,一个股票价格变化系统可以使用观察者模式通知所有订阅者:
#include <vector>
#include <memory>
class Observer {
public:
virtual void update(double price) = 0;
virtual ~Observer() = default;
};
class Subject {
public:
virtual void attach(std::shared_ptr<Observer> observer) = 0;
virtual void detach(std::shared_ptr<Observer> observer) = 0;
virtual void notify() = 0;
virtual ~Subject() = default;
};
class Stock : public Subject {
private:
double price;
std::vector<std::shared_ptr<Observer>> observers;
public:
void attach(std::shared_ptr<Observer> observer) override {
observers.push_back(observer);
}
void detach(std::shared_ptr<Observer> observer) override {
// 从列表中移除观察者
}
void notify() override {
for (auto& observer : observers) {
observer->update(price);
}
}
void setPrice(double price) {
this->price = price;
notify();
}
};
class Investor : public Observer {
private:
std::string name;
public:
explicit Investor(const std::string& name) : name(name) {}
void update(double price) override {
std::cout << name << " notified: stock price changed to " << price << std::endl;
}
};
装饰器模式(Decorator Pattern):动态地给一个对象添加一些额外的职责。装饰器模式通过组合而非继承来扩展对象的功能,提供了比继承更灵活的替代方案。例如,一个咖啡店系统可以使用装饰器模式来添加不同的调料到咖啡中:
class Beverage {
public:
virtual std::string getDescription() const = 0;
virtual double cost() const = 0;
virtual ~Beverage() = default;
};
class Espresso : public Beverage {
public:
std::string getDescription() const override { return "Espresso"; }
double cost() const override { return 1.99; }
};
class CondimentDecorator : public Beverage {
protected:
std::shared_ptr<Beverage> beverage;
public:
explicit CondimentDecorator(std::shared_ptr<Beverage> beverage) : beverage(beverage) {}
};
class Milk : public CondimentDecorator {
public:
explicit Milk(std::shared_ptr<Beverage> beverage) : CondimentDecorator(beverage) {}
std::string getDescription() const override {
return beverage->getDescription() + ", Milk";
}
double cost() const override {
return beverage->cost() + 0.30;
}
};
适配器模式(Adapter Pattern):将一个类的接口转换成客户希望的另一个接口。适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。例如,一个系统需要使用第三方库的矩形类,但接口与系统不兼容,可以使用适配器模式进行转换:
// 第三方库的矩形类
class ThirdPartyRectangle {
public:
void draw(int x1, int y1, int x2, int y2) {
// 绘制矩形的实现
}
};
// 系统需要的接口
class Rectangle {
public:
virtual void draw() = 0;
virtual ~Rectangle() = default;
};
// 适配器类
class RectangleAdapter : public Rectangle {
private:
ThirdPartyRectangle thirdPartyRect;
int x1, y1, x2, y2;
public:
RectangleAdapter(int x1, int y1, int x2, int y2)
: x1(x1), y1(y1), x2(x2), y2(y2) {}
void draw() override {
thirdPartyRect.draw(x1, y1, x2, y2);
}
};
以上设计模式在 C++ 开发中经常使用。单例模式确保资源的唯一性,工厂模式分离对象的创建和使用,观察者模式实现对象间的事件通知,装饰器模式灵活扩展对象功能,适配器模式解决接口不兼容问题。理解这些设计模式的原理和应用场景,有助于编写更高效、更易维护的代码。
工厂模式和单例模式的主要区别是什么?
工厂模式和单例模式是两种不同的设计模式,它们在目的、实现和应用场景上有明显的区别。工厂模式主要用于对象的创建,它将对象的创建逻辑封装在一个工厂类中,使得客户端不需要直接依赖具体类的构造函数,从而降低了耦合度。而单例模式则是确保一个类只有一个实例,并提供一个全局访问点,主要用于需要全局唯一资源的场景。
核心目的:工厂模式的核心目的是将对象的创建和使用分离,提供一个统一的创建接口,使得客户端可以通过这个接口创建不同类型的对象,而不需要关心具体的创建细节。单例模式的核心目的是保证一个类在整个应用程序中只有一个实例,并提供一个全局访问点来获取这个实例,避免多个实例导致的资源冲突或数据不一致问题。
实现方式:工厂模式通常通过定义一个工厂类或工厂方法来实现,工厂类或方法根据传入的参数或其他条件来决定创建哪种具体对象。例如,一个图形工厂可以根据用户指定的类型创建圆形、矩形等不同图形。单例模式则通过将类的构造函数私有化,防止外部直接实例化,同时提供一个静态方法来获取唯一的实例。这个实例通常在第一次调用时创建,并在后续调用中直接返回。
应用场景:工厂模式适用于对象创建逻辑复杂、需要根据不同条件创建不同类型对象的场景,或者在系统设计初期不确定具体实现类,需要灵活扩展的情况。单例模式适用于需要全局唯一资源的场景,如配置管理器、日志系统、数据库连接池等,这些资源在整个应用程序中只需要一个实例来避免资源浪费或冲突。
示例对比:
// 工厂模式示例
class Shape {
public:
virtual void draw() = 0;
virtual ~Shape() = default;
};
class Circle : public Shape {
public:
void draw() override { std::cout << "Drawing Circle" << std::endl; }
};
class Rectangle : public Shape {
public:
void draw() override { std::cout << "Drawing Rectangle" << std::endl; }
};
class ShapeFactory {
public:
static std::unique_ptr<Shape> createShape(const std::string& type) {
if (type == "circle") {
return std::make_unique<Circle>();
} else if (type == "rectangle") {
return std::make_unique<Rectangle>();
}
return nullptr;
}
};
// 单例模式示例
class Logger {
private:
static Logger* instance;
Logger() = default; // 私有构造函数
Logger(const Logger&) = delete; // 禁止拷贝
Logger& operator=(const Logger&) = delete; // 禁止赋值
public:
static Logger* getInstance() {
if (instance == nullptr) {
instance = new Logger();
}
return instance;
}
void log(const std::string& message) {
// 实现日志记录逻辑
}
};
// 初始化静态成员
Logger* Logger::instance = nullptr;
工厂模式和单例模式在设计目的、实现方式和应用场景上都有明显的区别。工厂模式关注于对象的创建过程,通过封装创建逻辑提供灵活性;而单例模式关注于对象的唯一性,通过限制实例化确保全局只有一个实例。理解它们的区别有助于在实际开发中选择合适的设计模式来解决问题。
如何定位和解决死锁问题?
死锁是多线程编程中常见的问题,当两个或多个线程互相等待对方释放资源时,就会发生死锁。定位和解决死锁问题需要系统性的方法和工具。
定位死锁:
- 日志分析:在关键资源获取和释放点添加日志,记录线程 ID、时间戳和资源状态。通过分析日志,可以发现线程是否长时间持有资源而不释放,或者是否存在循环等待的情况。
- 工具检测:使用专业工具如 Valgrind、Helgrind 或 ThreadSanitizer 来检测死锁。这些工具可以在运行时分析线程行为,识别潜在的死锁情况。
- 线程转储分析:在程序运行时获取线程堆栈信息,分析各个线程的状态和持有的资源。如果发现多个线程互相等待对方持有的资源,就可以确定发生了死锁。
- 资源分配图:绘制资源分配图,显示线程和资源之间的关系。如果图中存在循环,说明可能存在死锁。
解决死锁:
- 预防死锁:通过破坏死锁的四个必要条件(互斥、占有并等待、不可抢占、循环等待)来预防死锁。例如,一次性获取所有需要的资源,避免占有部分资源后再等待其他资源;按照固定顺序获取资源,避免循环等待。
- 避免死锁:使用资源分配算法如银行家算法来动态检查资源分配的安全性,确保系统不会进入可能发生死锁的状态。
- 检测和恢复:定期检测系统是否存在死锁,如果发现死锁,则通过终止某些线程或抢占资源来恢复系统。
- 使用更高级的同步原语:使用 std::lock 或 std::scoped_lock 来一次性锁定多个互斥量,避免手动锁定顺序导致的死锁。
- 减少锁的粒度:只在必要的代码段使用锁,减少锁的持有时间,降低死锁的可能性。
示例代码:
#include <mutex>
#include <thread>
#include <iostream>
std::mutex mutex1, mutex2;
void thread1() {
// 错误方式:可能导致死锁
std::lock_guard<std::mutex> lock1(mutex1);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
std::lock_guard<std::mutex> lock2(mutex2);
std::cout << "Thread 1 acquired both locks" << std::endl;
}
void thread2() {
// 错误方式:与 thread1 的加锁顺序相反,可能导致死锁
std::lock_guard<std::mutex> lock2(mutex2);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
std::lock_guard<std::mutex> lock1(mutex1);
std::cout << "Thread 2 acquired both locks" << std::endl;
}
void fixedThread1() {
// 正确方式:使用 std::lock 同时锁定多个互斥量
std::lock(mutex1, mutex2);
std::lock_guard<std::mutex> lock1(mutex1, std::adopt_lock);
std::lock_guard<std::mutex> lock2(mutex2, std::adopt_lock);
std::cout << "Fixed Thread 1 acquired both locks" << std::endl;
}
void fixedThread2() {
// 正确方式:与 fixedThread1 使用相同的加锁顺序
std::lock(mutex1, mutex2);
std::lock_guard<std::mutex> lock1(mutex1, std::adopt_lock);
std::lock_guard<std::mutex> lock2(mutex2, std::adopt_lock);
std::cout << "Fixed Thread 2 acquired both locks" << std::endl;
}
int main() {
// 演示死锁
std::thread t1(thread1);
std::thread t2(thread2);
t1.join();
t2.join();
// 演示修复后的代码
std::thread ft1(fixedThread1);
std::thread ft2(fixedThread2);
ft1.join();
ft2.join();
return 0;
}
定位和解决死锁需要综合使用日志分析、工具检测、合理的设计和编码实践。预防死锁是最好的策略,通过遵循良好的编程规范和使用高级同步原语,可以有效减少死锁的发生。
信号量和互斥量的底层设计原理是什么?
信号量(Semaphore)和互斥量(Mutex)是多线程编程中常用的同步原语,它们的底层设计原理有所不同,但都基于操作系统提供的原子操作和线程调度机制。
信号量的底层设计原理:信号量是一种更通用的同步原语,它维护一个计数器,用于控制对共享资源的访问。计数器的值表示可用资源的数量。当一个线程想要访问资源时,它会尝试对信号量执行 P 操作(也称为 wait 操作),这会将计数器减 1。如果减 1 后计数器的值大于等于 0,则线程可以继续访问资源;否则,线程会被阻塞,直到有其他线程释放资源。当一个线程释放资源时,它会执行 V 操作(也称为 signal 操作),这会将计数器加 1。如果加 1 后计数器的值大于 0,则会唤醒一个等待的线程。
信号量的底层实现通常依赖于操作系统提供的原子操作,如原子递增和递减。在 Linux 系统中,信号量的实现可能基于 futex(Fast Userspace Mutex)机制,这是一种用户空间和内核空间结合的高效同步机制。当信号量不需要内核干预时(如计数器值允许访问),操作在用户空间完成,避免了内核切换的开销;只有当需要阻塞或唤醒线程时,才会进入内核空间。
互斥量的底层设计原理:互斥量是一种特殊的信号量,其计数器值只能是 0 或 1,用于实现对共享资源的独占访问。当一个线程想要访问资源时,它会尝试锁定互斥量。如果互斥量当前未被锁定,则线程可以锁定它并继续访问资源;否则,线程会被阻塞,直到互斥量被释放。当线程完成对资源的访问后,它会解锁互斥量,允许其他线程锁定它。
互斥量的底层实现同样依赖于原子操作。在现代处理器中,通常使用比较并交换(Compare-and-Swap, CAS)或测试并设置(Test-and-Set)等原子指令来实现互斥量的锁定和解锁操作。例如,CAS 指令可以原子地比较一个内存位置的值与预期值,如果相等则将该内存位置的值更新为新值。这种原子操作可以确保在多线程环境中只有一个线程能够成功锁定互斥量。
与信号量类似,互斥量的实现也可能使用 futex 机制来提高效率。当互斥量未被持有时,线程可以在用户空间快速获取锁;只有当锁被持有时,线程才会进入内核空间等待,从而减少不必要的内核切换。
示例代码:
#include <semaphore.h>
#include <mutex>
#include <thread>
#include <iostream>
// POSIX 信号量示例
sem_t semaphore;
void semaphoreWorker() {
sem_wait(&semaphore); // P 操作
std::cout << "Thread acquired semaphore" << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "Thread releasing semaphore" << std::endl;
sem_post(&semaphore); // V 操作
}
// C++ 互斥量示例
std::mutex mtx;
void mutexWorker() {
std::lock_guard<std::mutex> lock(mtx);
std::cout << "Thread acquired mutex" << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "Thread releasing mutex" << std::endl;
}
int main() {
// 初始化信号量,初始值为 1
sem_init(&semaphore, 0, 1);
// 创建使用信号量的线程
std::thread t1(semaphoreWorker);
std::thread t2(semaphoreWorker);
t1.join();
t2.join();
// 销毁信号量
sem_destroy(&semaphore);
// 创建使用互斥量的线程
std::thread t3(mutexWorker);
std::thread t4(mutexWorker);
t3.join();
t4.join();
return 0;
}
信号量和互斥量的底层设计都依赖于操作系统提供的原子操作和线程调度机制。信号量通过计数器控制对资源的访问,适用于允许多个线程同时访问的资源;而互斥量则确保同一时间只有一个线程访问资源,适用于独占访问的场景。理解它们的底层原理有助于在实际编程中正确使用这些同步原语。
socket 通信的基本流程是什么?
Socket 通信是网络编程的基础,它提供了一种跨网络的进程间通信机制。Socket 通信的基本流程包括服务器端和客户端两个部分,涉及创建 socket、绑定地址、监听连接、建立连接、数据传输和关闭连接等步骤。
服务器端流程:
- 创建 Socket:服务器首先需要创建一个 socket 对象,指定通信协议(如 TCP 或 UDP)和地址族(如 IPv4 或 IPv6)。在 C++ 中,可以使用
socket()函数创建 socket。 - 绑定地址:服务器将创建的 socket 绑定到一个特定的 IP 地址和端口号上,以便客户端能够连接到该地址。使用
bind()函数完成绑定操作。 - 监听连接:对于 TCP 通信,服务器需要调用
listen()函数开始监听客户端的连接请求。该函数将 socket 设置为被动模式,等待客户端的连接。 - 接受连接:当有客户端连接请求到达时,服务器使用
accept()函数接受连接,该函数返回一个新的 socket 对象,用于与客户端进行通信。 - 数据传输:服务器和客户端通过各自的 socket 进行数据传输。对于 TCP 连接,可以使用
send()和recv()函数;对于 UDP 连接,可以使用sendto()和recvfrom()函数。 - 关闭连接:通信结束后,服务器和客户端分别关闭各自的 socket,释放资源。
客户端流程:
- 创建 Socket:客户端同样需要创建一个 socket 对象,指定与服务器相同的通信协议和地址族。
- 连接服务器:客户端使用
connect()函数连接到服务器的指定 IP 地址和端口号。对于 TCP 连接,这一步会触发三次握手过程,建立可靠连接。 - 数据传输:连接建立后,客户端可以通过 socket 与服务器进行数据交换,使用与服务器相同的数据传输函数。
- 关闭连接:通信结束后,客户端关闭 socket,释放资源。
示例代码:
// TCP 服务器示例
#include <iostream>
#include <cstring>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <unistd.h>
int main() {
// 创建 socket
int serverSocket = socket(AF_INET, SOCK_STREAM, 0);
if (serverSocket == -1) {
std::cerr << "Failed to create socket" << std::endl;
return 1;
}
// 准备地址结构
sockaddr_in serverAddr{};
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = INADDR_ANY;
serverAddr.sin_port = htons(8080);
// 绑定地址
if (bind(serverSocket, (sockaddr*)&serverAddr, sizeof(serverAddr)) == -1) {
std::cerr << "Failed to bind socket" << std::endl;
close(serverSocket);
return 1;
}
// 监听连接
if (listen(serverSocket, 5) == -1) {
std::cerr << "Failed to listen" << std::endl;
close(serverSocket);
return 1;
}
std::cout << "Server listening on port 8080..." << std::endl;
// 接受连接
sockaddr_in clientAddr{};
socklen_t clientAddrLen = sizeof(clientAddr);
int clientSocket = accept(serverSocket, (sockaddr*)&clientAddr, &clientAddrLen);
if (clientSocket == -1) {
std::cerr << "Failed to accept connection" << std::endl;
close(serverSocket);
return 1;
}
std::cout << "Client connected: " << inet_ntoa(clientAddr.sin_addr) << std::endl;
// 数据传输
char buffer[1024] = {0};
int bytesRead = recv(clientSocket, buffer, sizeof(buffer), 0);
if (bytesRead > 0) {
std::cout << "Received: " << buffer << std::endl;
send(clientSocket, "Message received", 17, 0);
}
// 关闭连接
close(clientSocket);
close(serverSocket);
return 0;
}
// TCP 客户端示例
#include <iostream>
#include <cstring>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <unistd.h>
int main() {
// 创建 socket
int clientSocket = socket(AF_INET, SOCK_STREAM, 0);
if (clientSocket == -1) {
std::cerr << "Failed to create socket" << std::endl;
return 1;
}
// 准备地址结构
sockaddr_in serverAddr{};
serverAddr.sin_family = AF_INET;
serverAddr.sin_port = htons(8080);
// 将 IPv4 地址从点分十进制转换为二进制形式
if (inet_pton(AF_INET, "127.0.0.1", &serverAddr.sin_addr) <= 0) {
std::cerr << "Invalid address/ Address not supported" << std::endl;
close(clientSocket);
return 1;
}
// 连接服务器
if (connect(clientSocket, (sockaddr*)&serverAddr, sizeof(serverAddr)) == -1) {
std::cerr << "Connection failed" << std::endl;
close(clientSocket);
return 1;
}
std::cout << "Connected to server" << std::endl;
// 数据传输
const char* message = "Hello, server!";
send(clientSocket, message, strlen(message), 0);
char buffer[1024] = {0};
int bytesRead = recv(clientSocket, buffer, sizeof(buffer), 0);
if (bytesRead > 0) {
std::cout << "Server response: " << buffer << std::endl;
}
// 关闭连接
close(clientSocket);
return 0;
}
Socket 通信的基本流程包括服务器端和客户端的一系列操作,从创建 socket 到关闭连接。理解这些步骤和相应的系统调用是进行网络编程的基础。无论是简单的客户端 - 服务器应用还是复杂的分布式系统,socket 通信都是实现网络功能的核心机制。
TIME_WAIT 状态出现在哪个阶段?其作用是什么?
TIME_WAIT 状态出现在 TCP 连接关闭过程中的主动关闭方,是 TCP 协议中一个重要的状态。理解 TIME_WAIT 状态的出现阶段和作用对于网络编程和系统调优非常重要。
TIME_WAIT 状态的出现阶段:在 TCP 连接关闭过程中,通常需要通过四次挥手(Four-Way Handshake)来完成。具体步骤如下:
- 主动关闭方发送 FIN:主动关闭方(通常是客户端)发送一个 FIN 包,表示请求关闭数据发送。
- 被动关闭方发送 ACK:被动关闭方(通常是服务器)收到 FIN 后,发送一个 ACK 包作为确认。此时,被动关闭方的发送通道仍然开放,主动关闭方的接收通道也仍然开放。
- 被动关闭方发送 FIN:被动关闭方在完成数据发送后,发送一个 FIN 包,表示请求关闭数据接收。
- 主动关闭方发送 ACK:主动关闭方收到 FIN 后,发送一个 ACK 包作为确认。此时,主动关闭方进入 TIME_WAIT 状态,而被动关闭方直接进入 CLOSED 状态。
TIME_WAIT 状态持续的时间通常是两倍的最大段生存期(Maximum Segment Lifetime, MSL),在大多数系统中,MSL 为 30 秒或 1 分钟,因此 TIME_WAIT 状态通常持续 1 到 4 分钟。
TIME_WAIT 状态的作用:
- 确保最后一个 ACK 到达对端:在四次挥手中,主动关闭方发送的最后一个 ACK 可能会丢失。如果发生这种情况,被动关闭方会重新发送 FIN 包。主动关闭方在 TIME_WAIT 状态下可以接收这个重传的 FIN 包,并再次发送 ACK,从而确保连接的正确关闭。如果没有 TIME_WAIT 状态,主动关闭方可能会直接关闭连接,导致被动关闭方无法收到确认,从而无法正确关闭连接。
- 防止旧连接的数据包干扰新连接:TCP 协议允许在相同的 IP 地址和端口号之间建立新的连接。如果没有 TIME_WAIT 状态,旧连接的延迟数据包可能会出现在新连接中,导致数据混乱。TIME_WAIT 状态的存在确保了在这个时间段内,旧连接的所有数据包都会自然消失,不会影响新连接。
- 保证 TCP 协议的可靠性:TIME_WAIT 状态是 TCP 协议可靠性的重要组成部分。它通过确保连接的正确关闭和防止旧数据包干扰,保证了数据传输的可靠性和顺序性。
示例场景:假设客户端和服务器之间建立了一个 TCP 连接,客户端主动发起关闭请求。在四次挥手过程中,客户端发送最后一个 ACK 后进入 TIME_WAIT 状态。如果这个 ACK 丢失,服务器会重新发送 FIN 包。客户端在 TIME_WAIT 状态下会接收这个 FIN 包,并再次发送 ACK,确保服务器能够正确关闭连接。此外,如果客户端和服务器在 TIME_WAIT 状态期间尝试建立新的连接,由于旧连接的数据包已经消失,新连接不会受到干扰。
系统影响和优化:在高并发的服务器环境中,大量的 TIME_WAIT 状态可能会导致系统资源耗尽,特别是在使用固定端口范围的情况下。为了缓解这个问题,可以调整系统参数,如缩短 TIME_WAIT 状态的持续时间,或启用 TCP_TIMESTAMP 选项来允许快速重用处于 TIME_WAIT 状态的端口。然而,这些优化措施可能会影响 TCP 协议的可靠性,需要谨慎使用。
TIME_WAIT 状态是 TCP 协议中确保连接可靠关闭和防止旧数据包干扰的重要机制。它出现在主动关闭方发送最后一个 ACK 之后,持续时间通常为两倍的 MSL。理解 TIME_WAIT 状态的作用和影响对于编写高性能、可靠的网络应用程序至关重要。
HTTPS 通信过程是怎样的?会话密钥如何生成?
HTTPS 通信过程是在 HTTP 协议基础上加入了 SSL/TLS 协议,通过加密和身份验证确保数据传输的安全性。其通信过程主要包括 TCP 连接建立、TLS 握手、HTTP 数据传输和连接关闭四个阶段。会话密钥的生成是 TLS 握手过程中的关键环节,它通过一系列加密算法和随机数生成,确保通信双方拥有相同的临时加密密钥。
HTTPS 通信过程:
- TCP 连接建立:客户端向服务器发起 TCP 连接请求,通过三次握手建立连接。这是普通 HTTP 通信的基础步骤。
- TLS 握手阶段:
- 客户端问候(Client Hello):客户端发送支持的 TLS 版本、加密算法列表、随机数(Client Random)等信息。
- 服务器问候(Server Hello):服务器选择一个 TLS 版本和加密算法,并发送证书、服务器随机数(Server Random)等信息。
- 证书验证:客户端验证服务器证书的有效性,包括证书颁发机构(CA)签名、证书有效期、域名匹配等。
- 预主密钥生成(Pre-Master Secret):客户端生成一个预主密钥,用服务器证书中的公钥加密后发送给服务器。
- 会话密钥生成:客户端和服务器分别使用 Client Random、Server Random 和 Pre-Master Secret 生成相同的会话密钥(Master Secret)。这个过程使用伪随机函数(PRF)确保密钥的随机性和安全性。
- 握手完成:双方发送握手完成消息,使用会话密钥进行加密通信。
- HTTP 数据传输:客户端和服务器使用生成的会话密钥对 HTTP 请求和响应进行加密传输,确保数据的机密性和完整性。
- 连接关闭:通信结束后,通过 TCP 四次挥手关闭连接。
会话密钥生成过程:会话密钥的生成是 TLS 握手的核心安全机制。客户端和服务器通过以下步骤生成相同的会话密钥:
- 随机数交换:在 Client Hello 和 Server Hello 消息中,双方交换随机数(Client Random 和 Server Random)。
- 预主密钥生成:客户端生成一个预主密钥(Pre-Master Secret),并使用服务器证书中的公钥加密后发送给服务器。服务器使用自己的私钥解密得到预主密钥。
- 主密钥生成:双方使用 Client Random、Server Random 和 Pre-Master Secret 作为输入,通过伪随机函数(PRF)生成主密钥(Master Secret)。这个过程确保双方生成相同的主密钥,即使预主密钥在传输过程中被截获,攻击者也无法推导出主密钥。
- 会话密钥派生:主密钥进一步派生出用于加密和验证的会话密钥,包括加密密钥、MAC 密钥等。这些密钥用于后续的数据传输阶段。
示例代码:
// 简化的 HTTPS 通信流程示例
#include <iostream>
#include <string>
#include <openssl/ssl.h>
#include <openssl/err.h>
void initializeSSL() {
SSL_library_init();
OpenSSL_add_all_algorithms();
SSL_load_error_strings();
}
void cleanupSSL() {
EVP_cleanup();
ERR_free_strings();
}
void httpsClient(const std::string& server, int port) {
initializeSSL();
// 创建 SSL 上下文
SSL_CTX* ctx = SSL_CTX_new(TLS_client_method());
if (!ctx) {
std::cerr << "Failed to create SSL context" << std::endl;
cleanupSSL();
return;
}
// 创建 socket 并连接服务器
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) {
std::cerr << "Failed to create socket" << std::endl;
SSL_CTX_free(ctx);
cleanupSSL();
return;
}
sockaddr_in serverAddr{};
serverAddr.sin_family = AF_INET;
serverAddr.sin_port = htons(port);
inet_pton(AF_INET, server.c_str(), &serverAddr.sin_addr);
if (connect(sockfd, (sockaddr*)&serverAddr, sizeof(serverAddr)) < 0) {
std::cerr << "Failed to connect to server" << std::endl;
close(sockfd);
SSL_CTX_free(ctx);
cleanupSSL();
return;
}
// 创建 SSL 对象
SSL* ssl = SSL_new(ctx);
if (!ssl) {
std::cerr << "Failed to create SSL object" << std::endl;
close(sockfd);
SSL_CTX_free(ctx);
cleanupSSL();
return;
}
// 将 SSL 对象与 socket 关联
SSL_set_fd(ssl, sockfd);
// 执行 TLS 握手
if (SSL_connect(ssl) != 1) {
std::cerr << "SSL connection failed" << std::endl;
ERR_print_errors_fp(stderr);
SSL_shutdown(ssl);
SSL_free(ssl);
close(sockfd);
SSL_CTX_free(ctx);
cleanupSSL();
return;
}
std::cout << "SSL connection established" << std::endl;
std::cout << "Using cipher: " << SSL_get_cipher(ssl) << std::endl;
// 发送 HTTP 请求
const char* request = "GET / HTTP/1.1\r\n"
"Host: "
"Connection: close\r\n\r\n";
SSL_write(ssl, request, strlen(request));
// 接收响应
char buffer[1024];
int bytes = SSL_read(ssl, buffer, sizeof(buffer) - 1);
if (bytes > 0) {
buffer[bytes] = '\0';
std::cout << "Response:\n" << buffer << std::endl;
}
// 关闭连接
SSL_shutdown(ssl);
SSL_free(ssl);
close(sockfd);
SSL_CTX_free(ctx);
cleanupSSL();
}
int main() {
httpsClient("example.com", 443);
return 0;
}
HTTPS 通信通过 TLS 握手建立安全连接,其中会话密钥的生成是确保通信安全的关键。通过随机数交换、预主密钥生成和派生,客户端和服务器能够在不安全的网络上建立安全的加密通道,保护数据不被窃听和篡改。理解 HTTPS 通信过程和会话密钥生成机制对于开发安全的网络应用至关重要。
影响网络服务器性能的因素有哪些?除了多线程和 IO 多路复用,还有哪些优化方法?
影响网络服务器性能的因素众多,涉及硬件、软件、网络和算法等多个层面。除了多线程和 IO 多路复用外,还有许多其他优化方法可以提高服务器的性能和吞吐量。
影响网络服务器性能的因素:
- 硬件资源:CPU 性能直接影响服务器处理请求的速度,多核 CPU 可以并行处理多个请求。内存大小和访问速度影响数据缓存和处理效率,不足的内存会导致频繁的磁盘交换,严重降低性能。网络带宽限制了数据传输的最大速率,高速网络接口可以减少数据传输延迟。磁盘 I/O 性能影响文件读写和持久化操作的速度,SSD 相比传统 HDD 具有显著的性能优势。
- 操作系统参数:TCP/IP 堆栈参数(如 backlog 队列大小、TCP 窗口大小)会影响连接建立和数据传输效率。文件描述符限制影响服务器同时处理的连接数,需要适当调整以支持高并发。内核调度策略影响线程和进程的调度效率,对多线程服务器尤为重要。
- 网络环境:网络延迟(Latency)影响请求响应时间,特别是在分布式系统中。网络带宽限制了数据传输速率,可能成为瓶颈。网络稳定性(丢包率、抖动)影响数据传输的可靠性和重传开销。
- 应用程序设计:算法复杂度影响请求处理时间,高效的算法可以显著提高性能。内存管理策略(如内存池、对象复用)影响内存分配和回收效率,减少内存碎片。锁竞争和同步机制影响多线程程序的并发性能,过多的锁会导致线程阻塞。
- 数据库和存储系统:数据库查询性能影响数据访问速度,优化查询语句和索引可以提高性能。数据库连接池大小影响数据库访问效率,合理配置可以减少连接开销。存储系统的读写性能影响数据持久化和读取速度。
除多线程和 IO 多路复用外的优化方法:
- 零拷贝技术:通过避免数据在用户空间和内核空间之间的多次拷贝,减少 CPU 开销,提高数据传输效率。例如,Linux 系统的
sendfile()函数可以直接将文件内容从磁盘传输到网络套接字,无需经过用户空间。 - 内存池和对象池:预先分配一定数量的内存块或对象,避免频繁的内存分配和释放操作,减少内存碎片和系统调用开销。这对于需要频繁创建和销毁对象的场景特别有效。
- 异步编程模型:使用异步 I/O 和回调机制处理请求,避免线程阻塞,提高并发处理能力。例如,libevent、libev 等事件库提供了高效的异步编程接口。
- 缓存机制:在服务器端使用缓存(如内存缓存 Redis)存储频繁访问的数据,减少对后端数据源的访问,提高响应速度。
- 负载均衡:通过负载均衡器(如 Nginx、HAProxy)将请求分发到多个服务器实例,实现水平扩展,提高整体吞吐量和可用性。
- 协议优化:使用高效的二进制协议替代文本协议,减少数据传输量和解析开销。例如,使用 Protobuf、MessagePack 等二进制序列化协议。
- 连接池:对于数据库、缓存等外部资源,使用连接池管理连接,避免频繁创建和销毁连接的开销。
- 预取和批处理:预测用户请求模式,提前加载数据到缓存中。将多个小请求合并为一个批处理请求,减少系统开销。
- 优化系统调用:减少不必要的系统调用,例如使用 writev () 替代多次 write () 调用,减少上下文切换开销。
- 使用高性能库和框架:选择经过优化的高性能网络库和框架,如 Boost.Asio、Netty 等,它们通常实现了高效的事件循环和内存管理。
- 代码优化:使用高效的数据结构和算法,减少不必要的计算和内存访问。进行代码性能分析(Profiling),找出性能瓶颈并进行针对性优化。
- 硬件加速:对于特定应用场景,使用硬件加速(如 GPU、FPGA)处理计算密集型任务。
示例代码:
// 使用内存池优化对象分配的示例
#include <iostream>
#include <vector>
#include <memory>
template<typename T>
class MemoryPool {
private:
std::vector<T*> chunks;
std::vector<T*> freeList;
size_t chunkSize;
public:
explicit MemoryPool(size_t initialSize = 1024) : chunkSize(initialSize) {
allocateChunk();
}
~MemoryPool() {
for (T* chunk : chunks) {
delete[] chunk;
}
}
T* allocate() {
if (freeList.empty()) {
allocateChunk();
}
T* obj = freeList.back();
freeList.pop_back();
return obj;
}
void deallocate(T* obj) {
freeList.push_back(obj);
}
private:
void allocateChunk() {
T* chunk = new T[chunkSize];
chunks.push_back(chunk);
for (size_t i = 0; i < chunkSize; ++i) {
freeList.push_back(&chunk[i]);
}
}
};
// 使用内存池的示例类
class MyObject {
private:
int data[1000]; // 模拟较大的对象
public:
static MemoryPool<MyObject> pool;
void* operator new(size_t size) {
return pool.allocate();
}
void operator delete(void* obj) {
pool.deallocate(static_cast<MyObject*>(obj));
}
// 其他成员函数
};
// 初始化静态内存池
MemoryPool<MyObject> MyObject::pool;
int main() {
// 频繁创建和销毁对象
for (int i = 0; i < 1000000; ++i) {
MyObject* obj = new MyObject();
delete obj;
}
return 0;
}
优化网络服务器性能需要综合考虑多个因素,从硬件配置到软件设计,从操作系统参数到应用程序代码。除了多线程和 IO 多路复用外,还有许多其他优化方法可以显著提高服务器的性能和吞吐量。通过合理选择和组合这些优化技术,可以构建出高效、稳定的网络服务器系统。
TCP 和 UDP 的主要区别是什么?各自适用于哪些场景?
TCP(Transmission Control Protocol)和 UDP(User Datagram Protocol)是两种不同的传输层协议,它们在设计目标、可靠性、性能和应用场景等方面存在显著差异。理解这些差异对于选择合适的协议进行网络编程至关重要。
主要区别:
- 可靠性:TCP 是面向连接的、可靠的协议。它通过三次握手建立连接,使用确认机制(ACK)、重传机制和滑动窗口协议确保数据的可靠传输。如果数据在传输过程中丢失、损坏或乱序,TCP 会自动处理这些问题。UDP 是无连接的、不可靠的协议。它不保证数据的可靠传输,也不提供重传机制。数据发送后,UDP 不会关心数据是否到达目的地。
- 连接机制:TCP 需要在通信前建立连接,通信结束后释放连接。这个过程增加了一定的开销,但确保了通信的可靠性。UDP 不需要建立连接,发送方直接将数据报发送到目标地址,接收方直接接收数据报。这种无连接的特性使得 UDP 的开销更小,传输速度更快。
- 有序性:TCP 保证数据的有序性,即发送方发送的数据顺序与接收方接收的数据顺序一致。UDP 不保证数据的有序性,数据报可能会乱序到达。
- 拥塞控制:TCP 实现了拥塞控制机制,当网络出现拥塞时,TCP 会自动降低发送速率,以避免进一步恶化网络状况。UDP 没有拥塞控制机制,它会尽可能快地发送数据,即使网络已经拥塞。这可能导致网络性能下降,但也使得 UDP 在某些场景下更具优势。
- 传输效率:由于 TCP 需要维护连接状态、确认机制和拥塞控制等,它的传输效率相对较低,特别是在传输少量数据时。UDP 由于没有这些额外开销,传输效率更高,适合对实时性要求高的应用。
- 头部开销:TCP 头部大小为 20 字节(不包括选项),包含序列号、确认号、窗口大小等字段。UDP 头部只有 8 字节,包含源端口、目的端口、长度和校验和等基本信息。更小的头部开销使得 UDP 在传输小数据包时更具优势。
适用场景:
- TCP 适用场景:
- 文件传输:如 FTP、HTTP,需要确保文件完整无误地传输。
- 电子邮件:如 SMTP、POP3、IMAP,需要可靠地传输邮件内容。
- 远程登录:如 Telnet、SSH,需要确保命令准确无误地传输。
- 数据库访问:如 MySQL、PostgreSQL,需要可靠地传输查询和结果。
- 任何需要可靠传输的应用:如金融交易系统、在线支付等。
- UDP 适用场景:
- 实时音视频传输:如 VoIP、视频会议、流媒体,对实时性要求高,少量数据丢失不会严重影响用户体验。
- 游戏网络:如在线游戏,需要快速响应,对实时性要求高,允许少量数据包丢失。
- 广播和多播应用:如 DHCP、SNMP,需要向多个目标发送数据。
- DNS 查询:需要快速响应,单次查询数据量小,适合 UDP 的特性。
- 实时监控系统:如网络监控、传感器数据采集,需要快速传输数据,允许少量数据丢失。
示例代码:
// TCP 服务器示例
#include <iostream>
#include <cstring>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <unistd.h>
int main() {
// 创建 TCP socket
int serverSocket = socket(AF_INET, SOCK_STREAM, 0);
if (serverSocket == -1) {
std::cerr << "Failed to create socket" << std::endl;
return 1;
}
// 准备地址结构
sockaddr_in serverAddr{};
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = INADDR_ANY;
serverAddr.sin_port = htons(8080);
// 绑定地址
if (bind(serverSocket, (sockaddr*)&serverAddr, sizeof(serverAddr)) == -1) {
std::cerr << "Failed to bind socket" << std::endl;
close(serverSocket);
return 1;
}
// 监听连接
if (listen(serverSocket, 5) == -1) {
std::cerr << "Failed to listen" << std::endl;
close(serverSocket);
return 1;
}
std::cout << "TCP Server listening on port 8080..." << std::endl;
// 接受连接
sockaddr_in clientAddr{};
socklen_t clientAddrLen = sizeof(clientAddr);
int clientSocket = accept(serverSocket, (sockaddr*)&clientAddr, &clientAddrLen);
if (clientSocket == -1) {
std::cerr << "Failed to accept connection" << std::endl;
close(serverSocket);
return 1;
}
std::cout << "Client connected: " << inet_ntoa(clientAddr.sin_addr) << std::endl;
// 数据传输
char buffer[1024] = {0};
int bytesRead = recv(clientSocket, buffer, sizeof(buffer), 0);
if (bytesRead > 0) {
std::cout << "Received: " << buffer << std::endl;
send(clientSocket, "Message received", 17, 0);
}
// 关闭连接
close(clientSocket);
close(serverSocket);
return 0;
}
// UDP 服务器示例
#include <iostream>
#include <cstring>
#include <sys/socket.h>
#include <arpa/inet.h>
#include <unistd.h>
int main() {
// 创建 UDP socket
int serverSocket = socket(AF_INET, SOCK_DGRAM, 0);
if (serverSocket == -1) {
std::cerr << "Failed to create socket" << std::endl;
return 1;
}
// 准备地址结构
sockaddr_in serverAddr{};
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = INADDR_ANY;
serverAddr.sin_port = htons(8080);
// 绑定地址
if (bind(serverSocket, (sockaddr*)&serverAddr, sizeof(serverAddr)) == -1) {
std::cerr << "Failed to bind socket" << std::endl;
close(serverSocket);
return 1;
}
std::cout << "UDP Server listening on port 8080..." << std::endl;
// 接收数据
sockaddr_in clientAddr{};
socklen_t clientAddrLen = sizeof(clientAddr);
char buffer[1024] = {0};
int bytesRead = recvfrom(serverSocket, buffer, sizeof(buffer), 0,
(sockaddr*)&clientAddr, &clientAddrLen);
if (bytesRead > 0) {
std::cout << "Received from " << inet_ntoa(clientAddr.sin_addr) << ": " << buffer << std::endl;
sendto(serverSocket, "Message received", 17, 0,
(sockaddr*)&clientAddr, clientAddrLen);
}
// 关闭 socket
close(serverSocket);
return 0;
}
TCP 和 UDP 各有其优缺点和适用场景。TCP 提供可靠的、有序的、面向连接的通信,适合对数据准确性要求高的应用;UDP 提供高效的、无连接的通信,适合对实时性要求高、允许少量数据丢失的应用。在实际应用中,需要根据具体需求选择合适的协议。
ARP 协议的工作原理是什么?
ARP(Address Resolution Protocol)是一种网络层协议,用于将 IP 地址解析为对应的物理地址(MAC 地址)。在局域网中,设备之间的通信需要知道对方的 MAC 地址,而应用层通常只知道对方的 IP 地址,因此需要 ARP 协议来完成这种地址转换。
ARP 协议的工作原理:
- ARP 请求:当一台设备(发送方)需要向另一台设备(目标方)发送数据,但不知道目标方的 MAC 地址时,发送方会构建一个 ARP 请求数据包。该数据包包含发送方的 MAC 地址和 IP 地址,以及目标方的 IP 地址。发送方将这个 ARP 请求以广播的形式发送到局域网中的所有设备。
- ARP 响应:局域网中的所有设备都会接收到这个 ARP 请求,并检查其中的目标 IP 地址是否与自己的 IP 地址匹配。如果匹配,目标设备会构建一个 ARP 响应数据包,其中包含自己的 MAC 地址,并将该响应直接发送给发送方。如果不匹配,设备会忽略该 ARP 请求。
- ARP 缓存更新:发送方收到 ARP 响应后,会将目标方的 IP 地址和 MAC 地址映射关系存储在自己的 ARP 缓存中,以便将来再次通信时直接使用,而不需要再次发送 ARP 请求。同时,目标方也会将发送方的 IP-MAC 映射关系存储在自己的 ARP 缓存中。
- ARP 缓存超时:ARP 缓存中的映射关系不会永久保存,而是有一个超时时间(通常为几分钟)。超时后,设备会再次发送 ARP 请求来获取最新的 MAC 地址,以处理设备移动或网络变化等情况。
ARP 数据包格式:ARP 数据包包含以下主要字段:
- 硬件类型:标识网络硬件类型,如以太网(值为 1)。
- 协议类型:标识上层协议类型,如 IPv4(值为 0x0800)。
- 硬件地址长度:MAC 地址长度,通常为 6 字节。
- 协议地址长度:IP 地址长度,通常为 4 字节。
- 操作码:标识数据包类型,1 表示 ARP 请求,2 表示 ARP 响应。
- 发送方 MAC 地址:发送方的物理地址。
- 发送方 IP 地址:发送方的 IP 地址。
- 目标方 MAC 地址:目标方的物理地址(在 ARP 请求中通常为全 0)。
- 目标方 IP 地址:目标方的 IP 地址。
ARP 工作流程示例:假设主机 A(IP 地址:192.168.1.100,MAC 地址:AA-AA-AA-AA-AA-AA)需要向主机 B(IP 地址:192.168.1.101,MAC 地址未知)发送数据。
- 主机 A 检查自己的 ARP 缓存,发现没有 192.168.1.101 的 MAC 地址记录。
- 主机 A 构建一个 ARP 请求数据包,其中目标 IP 地址为 192.168.1.101,目标 MAC 地址为全 0,并将该数据包以广播形式发送到局域网中。
- 局域网中的所有设备都接收到该 ARP 请求。主机 B 检查发现目标 IP 地址与自己的 IP 地址匹配,于是构建一个 ARP 响应数据包,包含自己的 MAC 地址(BB-BB-BB-BB-BB-BB),并将该响应直接发送给主机 A。
- 主机 A 收到 ARP 响应后,将 192.168.1.101 与 BB-BB-BB-BB-BB-BB 的映射关系存入 ARP 缓存,并使用该 MAC 地址向主机 B 发送数据。
ARP 协议的安全性问题:ARP 协议存在一些安全隐患,主要包括 ARP 欺骗(ARP Spoofing)和 ARP 中毒(ARP Poisoning)。攻击者可以通过发送伪造的 ARP 响应来欺骗网络中的设备,使其将错误的 IP-MAC 映射关系存入缓存。这可能导致中间人攻击(Man-in-the-Middle Attack),攻击者可以截获、修改或伪造通信数据。为了防范这些攻击,可以使用静态 ARP 绑定、ARP 防火墙或更高级的网络安全协议。
ARP 协议是局域网中实现 IP 地址到 MAC 地址转换的关键机制。它通过广播请求和单播响应的方式,高效地完成地址解析过程,并通过缓存机制减少重复请求。理解 ARP 协议的工作原理对于网络故障排查和网络安全防范都非常重要。
描述 TCP 建立连接的三次握手和断开连接的四次挥手过程。
TCP 协议通过三次握手(Three-Way Handshake)建立连接,通过四次挥手(Four-Way Handshake)断开连接。这两个过程确保了通信双方的可靠性和数据传输的有序性。
三次握手建立连接:
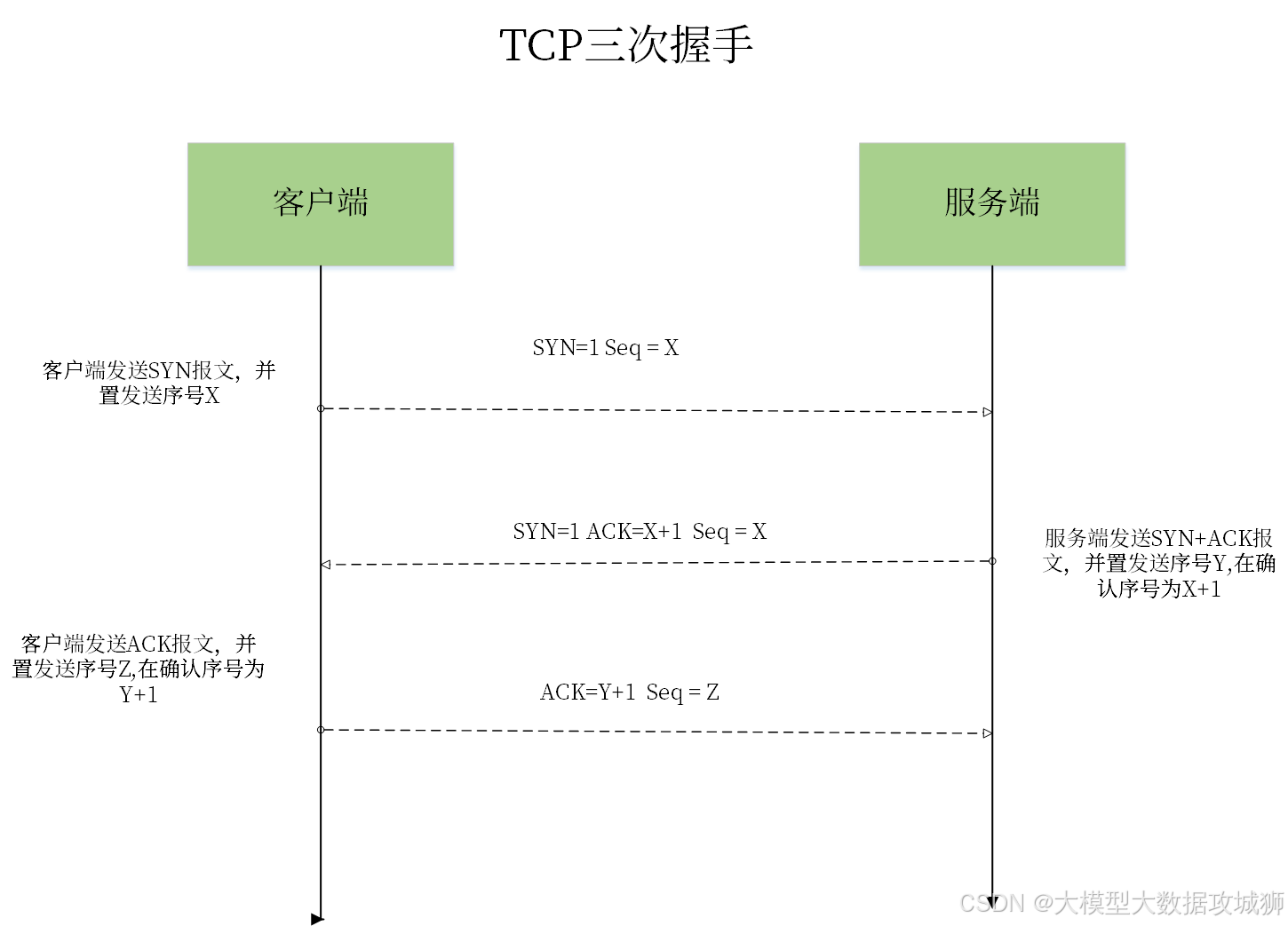
- 客户端发送 SYN 包:客户端向服务器发送一个 TCP 包,其中 SYN 标志位被设置为 1,表示请求建立连接。同时,客户端选择一个初始序列号(Initial Sequence Number, ISN),并将其放入序列号字段中。这个包不包含任何应用层数据,称为 SYN 包。
- 服务器发送 SYN+ACK 包:服务器收到客户端的 SYN 包后,向客户端发送一个确认包。这个包的 SYN 和 ACK 标志位都被设置为 1,表示同时响应客户端的连接请求并确认收到。服务器选择自己的初始序列号,并将客户端的序列号加 1 后放入确认号字段中,表示确认收到客户端的 SYN 包。这个包也不包含应用层数据,称为 SYN+ACK 包。
- 客户端发送 ACK 包:客户端收到服务器的 SYN+ACK 包后,向服务器发送一个确认包。这个包的 ACK 标志位被设置为 1,表示确认收到服务器的响应。客户端将服务器的序列号加 1 后放入确认号字段中,表示确认收到服务器的 SYN 包。此时,如果客户端有数据要发送,可以在这个 ACK 包中携带应用层数据。
三次握手的作用:
- 同步初始序列号:双方通过交换初始序列号,为后续的数据传输建立起点。
- 确认双方的发送和接收能力:通过三次通信,双方都确认了自己和对方的发送和接收能力正常。
- 防止旧连接的初始化:确保新连接的建立不会受到旧连接残留数据包的干扰。
四次挥手断开连接:
- 主动关闭方发送 FIN 包:当一方(通常是客户端,但也可以是服务器)完成数据发送后,它会向另一方发送一个 TCP 包,其中 FIN 标志位被设置为 1,表示请求关闭连接。这个包可能包含最后一段数据,也可能不包含数据。
- 被动关闭方发送 ACK 包:被动关闭方收到 FIN 包后,向主动关闭方发送一个确认包,其中 ACK 标志位被设置为 1,表示确认收到关闭请求。此时,被动关闭方的接收通道仍然开放,可以继续接收主动关闭方发送的数据(如果有)。
- 被动关闭方发送 FIN 包:当被动关闭方也完成数据发送后,它会向主动关闭方发送一个 FIN 包,表示请求关闭自己的发送通道。
- 主动关闭方发送 ACK 包:主动关闭方收到 FIN 包后,向被动关闭方发送一个确认包,表示确认收到关闭请求。此时,主动关闭方进入 TIME_WAIT 状态,持续一段时间(通常是两倍的 MSL,即 Maximum Segment Lifetime),以确保最后一个 ACK 包能够到达被动关闭方。被动关闭方收到 ACK 包后,立即关闭连接。
四次挥手的作用:
- 确保双方都完成数据发送:通过两次 FIN 包,确保双方都能够通知对方自己已经完成数据发送。
- 可靠地关闭连接:通过四次通信,确保双方都能够正确地关闭自己的发送和接收通道。
- 处理延迟的数据包:TIME_WAIT 状态的存在确保了旧连接的所有数据包都能够自然消失,不会影响新连接。
状态转换:在三次握手和四次挥手过程中,双方的 TCP 状态会发生相应的变化。
- 三次握手状态转换:客户端从 CLOSED 状态进入 SYN_SENT 状态,然后进入 ESTABLISHED 状态;服务器从 LISTEN 状态进入 SYN_RCVD 状态,然后进入 ESTABLISHED 状态。
- 四次挥手状态转换:主动关闭方从 ESTABLISHED 状态进入 FIN_WAIT_1 状态,然后进入 FIN_WAIT_2 状态,再进入 TIME_WAIT 状态,最后回到 CLOSED 状态;被动关闭方从 ESTABLISHED 状态进入 CLOSE_WAIT 状态,然后进入 LAST_ACK 状态,最后回到 CLOSED 状态。
TCP 的流量控制机制是如何实现的?
TCP 的流量控制机制是通过滑动窗口协议实现的,其主要目的是防止发送方发送数据过快,导致接收方无法及时处理而造成数据丢失。这种机制允许接收方动态地调整发送方的发送窗口大小,从而实现流量控制。
滑动窗口协议:滑动窗口是 TCP 流量控制的核心机制。每个 TCP 连接的两端都维护两个窗口:发送窗口和接收窗口。发送窗口表示发送方可以发送的数据范围,接收窗口表示接收方能够接收的数据范围。窗口大小动态调整,取决于接收方的处理能力和网络状况。
窗口大小的通告:接收方在每个确认报文(ACK)中包含一个窗口字段,指示自己当前的接收窗口大小(以字节为单位)。发送方根据这个窗口大小来调整自己的发送窗口。例如,如果接收方在 ACK 中通告窗口大小为 5000 字节,发送方就知道自己最多可以发送 5000 字节的数据而无需等待新的确认。
窗口滑动过程:随着数据的发送和接收,窗口会向前滑动。当发送方发送数据后,发送窗口的左边界向右移动;当接收方接收并确认数据后,接收窗口的左边界也向右移动。例如,发送方发送了序列号 1 到 1000 的数据,发送窗口的左边界从 1 移动到 1001。接收方成功接收这些数据后,在 ACK 中确认序列号 1001,并通告新的窗口大小,接收窗口的左边界也相应移动。
零窗口通知:当接收方的缓冲区已满,无法再接收更多数据时,它会在 ACK 中设置窗口大小为 0,通知发送方停止发送数据。发送方收到零窗口通知后,会暂停发送数据,直到收到接收方发送的非零窗口通知。
窗口探测机制:为了避免发送方在收到零窗口通知后永远等待,TCP 实现了窗口探测机制。发送方在收到零窗口通知后,会定期发送一个窗口探测报文(通常只包含 1 字节的数据),询问接收方的窗口是否已重新打开。接收方在处理探测报文后,会在响应中包含新的窗口大小。
糊涂窗口综合症(Silly Window Syndrome):这是一种由于窗口大小过小而导致的性能问题。如果发送方或接收方频繁地通告小窗口,会导致网络中充满小数据包,降低传输效率。为了避免这种情况,TCP 实现了以下策略:
- Nagle 算法:发送方在有数据要发送时,如果当前发送窗口很小(通常小于最大段大小 MSS),并且还有未确认的数据,发送方会延迟发送,直到收集到足够的数据或收到确认。
- 接收方窗口管理:接收方在窗口大小小于某个阈值(通常是 MSS 的一半)时,不会通告新的窗口大小,直到有足够的缓冲区空间可用。
流量控制与拥塞控制的区别:虽然流量控制和拥塞控制都涉及调整发送方的发送速率,但它们的目的和机制不同。流量控制是为了防止接收方缓冲区溢出,由接收方控制发送方的窗口大小;而拥塞控制是为了防止网络拥塞,由网络状况决定发送方的发送速率。TCP 通过拥塞窗口(cwnd)和慢启动、拥塞避免等算法实现拥塞控制,与流量控制的滑动窗口机制协同工作。
示例代码:
// 简化的 TCP 流量控制示例
#include <iostream>
#include <vector>
#include <cstring>
#include <thread>
#include <mutex>
#include <condition_variable>
class TCPSocket {
private:
int windowSize; // 接收窗口大小
int sendWindowSize; // 发送窗口大小
int nextSeqNum; // 下一个要发送的序列号
int ackedSeqNum; // 已确认的序列号
std::vector<char> buffer; // 接收缓冲区
std::mutex mtx;
std::condition_variable cv;
bool zeroWindow; // 窗口是否为零
public:
TCPSocket() : windowSize(1024), sendWindowSize(1024), nextSeqNum(0),
ackedSeqNum(0), zeroWindow(false) {
buffer.resize(4096); // 假设接收缓冲区大小为 4KB
}
// 发送数据,模拟流量控制
void sendData(const char* data, int length) {
std::unique_lock<std::mutex> lock(mtx);
// 等待窗口可用
while (nextSeqNum + length > ackedSeqNum + sendWindowSize || zeroWindow) {
std::cout << "Sender: Waiting for window space..." << std::endl;
cv.wait(lock);
}
// 发送数据
std::cout << "Sender: Sending " << length << " bytes, seq=" << nextSeqNum << std::endl;
nextSeqNum += length;
// 模拟网络延迟
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
// 接收确认,更新窗口大小
void receiveACK(int ackNum, int newWindowSize) {
std::lock_guard<std::mutex> lock(mtx);
// 更新已确认的序列号
if (ackNum > ackedSeqNum) {
std::cout << "Sender: Received ACK " << ackNum
<< ", window size=" << newWindowSize << std::endl;
ackedSeqNum = ackNum;
}
// 更新发送窗口大小
if (newWindowSize != sendWindowSize) {
sendWindowSize = newWindowSize;
std::cout << "Sender: Window size updated to " << sendWindowSize << std::endl;
// 如果窗口从 0 变为非 0,通知发送线程
if (newWindowSize > 0 && zeroWindow) {
zeroWindow = false;
cv.notify_all();
}
}
// 处理零窗口
if (newWindowSize == 0) {
zeroWindow = true;
std::cout << "Sender: Received zero window notification" << std::endl;
// 启动窗口探测计时器
std::thread([this]() {
std::this_thread::sleep_for(std::chrono::seconds(1));
this->probeWindow();
}).detach();
}
}
// 窗口探测
void probeWindow() {
std::lock_guard<std::mutex> lock(mtx);
if (zeroWindow) {
std::cout << "Sender: Sending window probe..." << std::endl;
// 发送窗口探测包(实际中会发送 1 字节数据)
}
}
// 接收数据,更新接收窗口
void receiveData(const char* data, int length, int seqNum) {
std::lock_guard<std::mutex> lock(mtx);
// 检查数据是否在接收窗口内
if (seqNum >= ackedSeqNum && seqNum + length <= ackedSeqNum + windowSize) {
std::cout << "Receiver: Received " << length << " bytes, seq=" << seqNum << std::endl;
// 处理数据(此处简化)
// ...
// 更新接收窗口
ackedSeqNum = seqNum + length;
// 计算新的窗口大小(假设处理后释放了部分缓冲区)
windowSize = 4096 - (ackedSeqNum % 4096);
// 发送确认,包含新的窗口大小
std::cout << "Receiver: Sending ACK " << ackedSeqNum
<< ", window size=" << windowSize << std::endl;
// 实际中会发送 ACK 包到对方
} else {
std::cout << "Receiver: Data out of window, seq=" << seqNum << std::endl;
}
}
};
TCP 的流量控制机制通过滑动窗口协议实现,允许接收方动态调整发送方的发送窗口大小,从而防止接收方缓冲区溢出。这种机制通过窗口通告、窗口滑动、零窗口通知和窗口探测等技术,确保了数据传输的高效性和可靠性。理解 TCP 流量控制对于网络编程和性能优化至关重要。
什么是 MySQL 的深分页问题?
MySQL 的深分页问题是指在查询大量数据时,使用 LIMIT 和 OFFSET 进行分页查询会导致性能显著下降的现象。当偏移量(OFFSET)非常大时,即使只需要少量结果,查询也会变得非常缓慢。例如,查询 LIMIT 1000000, 10 表示跳过前 100 万条记录,只返回接下来的 10 条记录,但这种查询的执行效率会随着偏移量的增加而急剧下降。
深分页问题的本质:MySQL 在处理 LIMIT OFFSET 查询时,会先扫描到偏移量位置的记录,然后再返回所需数量的记录。即使最终只需要少量记录,MySQL 也必须遍历并丢弃偏移量之前的所有记录。这个过程涉及大量的磁盘 I/O 和内存操作,尤其是在没有合适索引的情况下,性能会更加糟糕。
深分页问题的表现:随着 OFFSET 值的增大,查询执行时间会显著增加。例如,在一个包含 1000 万条记录的表中,查询 LIMIT 1000, 10 可能只需要几毫秒,而查询 LIMIT 1000000, 10 可能需要几秒甚至更长时间。这种性能差异使得深分页在处理大数据量时变得不可用。
深分页问题的原因:
- 全表扫描开销:如果查询没有使用索引,MySQL 必须全表扫描到偏移量位置,这会导致大量的磁盘 I/O。
- 索引扫描开销:即使使用了索引,MySQL 也需要遍历索引到偏移量位置,然后再回表获取数据。当偏移量很大时,这个过程仍然非常耗时。
- 内存和 CPU 消耗:遍历大量记录会消耗大量的内存和 CPU 资源,尤其是在排序操作中。
- 缓存失效:偏移量很大时,MySQL 无法利用查询缓存,因为每次查询的偏移量不同,导致缓存命中率低。
示例场景:假设有一个包含 1000 万条用户记录的表,需要分页展示。当用户翻到第 10000 页时,查询可能是 SELECT * FROM users ORDER BY id LIMIT 100000, 10。即使表上有主键索引,MySQL 也需要遍历 100000 条记录才能获取所需的 10 条记录,这个过程非常耗时。
深分页问题的影响:深分页问题不仅影响用户体验,还会增加数据库服务器的负载。在高并发场景下,大量的深分页查询可能导致数据库性能急剧下降,甚至影响其他业务操作。
MySQL 的深分页问题是由于 LIMIT OFFSET 查询机制导致的性能瓶颈,特别是在处理大数据量时。理解深分页问题的本质和原因是优化这类查询的关键。
深分页会带来哪些性能问题?
深分页(使用 LIMIT OFFSET 查询大数据量)会带来一系列性能问题,主要包括查询执行缓慢、资源消耗过高、锁争用加剧等。这些问题不仅影响用户体验,还可能导致整个数据库系统的稳定性下降。
查询执行缓慢:深分页最明显的问题是查询执行时间显著增加。当 OFFSET 值很大时,MySQL 需要扫描大量记录才能到达目标位置。即使最终只返回少量记录,前面的扫描过程也会消耗大量时间。例如,查询 LIMIT 1000000, 10 可能需要几秒甚至几十秒,而查询 LIMIT 0, 10 可能只需要几毫秒。这种性能差异使得深分页在实际应用中变得不可用。
磁盘 I/O 开销:深分页查询通常需要大量的磁盘 I/O。如果表数据没有完全加载到内存中,MySQL 需要从磁盘读取数据页。当偏移量很大时,需要读取的页数也会相应增加,导致磁盘 I/O 成为瓶颈。即使数据已经在内存中,大量的内存访问也会增加 CPU 的缓存失效,降低查询效率。
内存和 CPU 资源消耗:深分页查询会消耗大量的内存和 CPU 资源。在扫描大量记录时,MySQL 需要维护查询状态、排序缓冲区等数据结构,这会增加内存压力。如果内存不足,可能会导致频繁的磁盘交换,进一步恶化性能。此外,排序操作(如果有)会消耗更多的 CPU 资源,特别是在处理大数据量时。
索引效率下降:虽然索引可以加速数据检索,但在深分页场景下,索引的效率会显著下降。当偏移量很大时,MySQL 需要遍历索引到目标位置,这个过程可能比全表扫描还要慢。例如,对于一个按主键排序的大表,查询 LIMIT 1000000, 10 需要遍历主键索引的前 100 万条记录,然后再回表获取数据,这个过程的开销非常大。
锁争用加剧:在事务环境中,深分页查询可能会加剧锁争用。如果查询需要扫描大量记录,会持有锁的时间更长,从而增加与其他事务的锁冲突概率。这可能导致事务回滚、死锁等问题,进一步影响数据库的整体性能。
缓存失效:深分页查询通常无法利用查询缓存。由于每次查询的 OFFSET 值不同,即使查询条件相同,MySQL 也会认为是不同的查询,导致缓存命中率低。此外,大量的深分页查询可能会挤出其他常用查询的缓存,影响整体缓存效果。
数据库连接池耗尽:在高并发场景下,大量的深分页查询可能会耗尽数据库连接池。由于每个深分页查询的执行时间很长,连接会被长时间占用,无法及时释放给其他请求使用。这可能导致新的请求无法获取连接,从而影响整个系统的可用性。
示例代码:
// 模拟深分页查询的性能问题
#include <iostream>
#include <mysql/mysql.h>
#include <chrono>
void testDeepPaging(const char* host, const char* user, const char* password,
const char* db, int offset, int limit) {
// 初始化 MySQL 连接
MYSQL* conn = mysql_init(nullptr);
if (!conn) {
std::cerr << "Failed to initialize MySQL connection" << std::endl;
return;
}
// 连接数据库
if (!mysql_real_connect(conn, host, user, password, db, 0, nullptr, 0)) {
std::cerr << "Failed to connect to database: " << mysql_error(conn) << std::endl;
mysql_close(conn);
return;
}
// 构建深分页查询
char query[256];
snprintf(query, sizeof(query), "SELECT * FROM large_table ORDER BY id LIMIT %d, %d", offset, limit);
// 执行查询并计时
auto start = std::chrono::high_resolution_clock::now();
if (mysql_query(conn, query)) {
std::cerr << "Query failed: " << mysql_error(conn) << std::endl;
mysql_close(conn);
return;
}
// 获取结果集
MYSQL_RES* result = mysql_store_result(conn);
if (!result) {
std::cerr << "Failed to get result set: " << mysql_error(conn) << std::endl;
mysql_close(conn);
return;
}
// 计算查询时间
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
// 输出结果数和查询时间
std::cout << "Query: " << query << std::endl;
std::cout << "Number of rows: " << mysql_num_rows(result) << std::endl;
std::cout << "Execution time: " << duration << " ms" << std::endl;
// 释放资源
mysql_free_result(result);
mysql_close(conn);
}
int main() {
// 测试不同偏移量的查询性能
testDeepPaging("localhost", "user", "password", "test", 0, 10); // 浅分页
testDeepPaging("localhost", "user", "password", "test", 100000, 10); // 深分页
testDeepPaging("localhost", "user", "password", "test", 1000000, 10); // 更深的分页
return 0;
}
深分页会带来一系列严重的性能问题,包括查询缓慢、资源消耗过高、锁争用加剧等。这些问题在处理大数据量时尤为明显,需要通过优化查询方式、改进索引设计或采用其他分页策略来解决。
如何优化 MySQL 的深分页查询?
优化 MySQL 的深分页查询可以从多个角度入手,包括改进查询方式、优化索引、使用覆盖索引、调整数据库参数以及采用替代分页策略等。以下是一些有效的优化方法:
利用索引优化查询:确保查询使用合适的索引,特别是在 ORDER BY 和 WHERE 子句中涉及的字段。例如,如果查询是 SELECT * FROM users ORDER BY created_at LIMIT 100000, 10,则应该在 created_at 字段上创建索引。这样可以避免全表扫描,加速数据定位。
覆盖索引优化:使用覆盖索引可以避免回表操作,进一步提高查询效率。覆盖索引是指索引包含了查询所需的所有字段,这样 MySQL 可以直接从索引中获取数据,而不需要访问数据表。例如,将查询改为 SELECT id, created_at FROM users ORDER BY created_at LIMIT 100000, 10,并在 created_at 字段上创建包含 id 的复合索引。
记录上次查询的位置:避免使用 OFFSET 进行深分页,而是记录上次查询的最后一条记录的位置,下次查询时直接从该位置开始。例如:
-- 第一次查询
SELECT id, created_at FROM users ORDER BY created_at LIMIT 10;
-- 记录最后一条记录的 created_at 值(假设为 '2023-01-01 12:00:00')
-- 后续查询
SELECT id, created_at FROM users
WHERE created_at > '2023-01-01 12:00:00'
ORDER BY created_at LIMIT 10;
这种方法称为 “书签分页”,性能远优于 OFFSET 分页,特别是在大数据量下。
优化排序操作:如果查询需要排序,确保排序字段有索引,避免文件排序(filesort)。文件排序是一种效率较低的排序方式,特别是在处理大量数据时。如果无法避免文件排序,可以通过调整 sort_buffer_size 参数来提高排序性能。
分页预取与缓存:对于热门分页数据,可以使用缓存(如 Redis)来存储查询结果,减少对数据库的访问。另外,可以实现预取机制,提前加载可能被访问...
C++ 和 C 语言的主要区别有哪些?
C++ 和 C 语言虽然有共同的起源,且 C++ 保留了大部分 C 语言的语法和特性,但它们在设计目标、编程范式、类型系统和功能特性等方面存在显著差异。这些差异使得 C++ 更适合开发大型、复杂的应用程序,而 C 语言则更侧重于系统编程和对性能要求极高的场景。
面向对象编程:C++ 是一种面向对象的编程语言,支持类、对象、继承、多态等面向对象的核心概念。通过类和对象,C++ 可以实现数据封装和信息隐藏,提高代码的可维护性和可复用性。例如,C++ 可以定义一个抽象基类,并派生出多个具体子类,通过虚函数实现多态行为。而 C 语言是纯粹的过程式语言,没有提供面向对象的支持,主要通过函数和结构体来组织代码。
类型系统:C++ 拥有更严格的类型系统。在 C++ 中,变量和函数必须先声明后使用,隐式类型转换受到更多限制。例如,C++ 不允许将 void* 指针隐式转换为其他类型的指针,而 C 语言则允许这种转换。此外,C++ 引入了引用类型,提供了更安全、更方便的变量别名机制。
泛型编程:C++ 支持泛型编程,通过模板(Template)机制可以编写与类型无关的代码。模板使得算法和数据结构可以独立于具体类型,提高了代码的复用性。例如,C++ 标准库中的容器(如 vector、list、map)和算法(如 sort、find)都是通过模板实现的。C 语言没有模板机制,通常需要通过函数指针和 void* 指针来实现类似的泛型功能,但这种方法不够类型安全。
异常处理:C++ 提供了异常处理机制(try-catch-throw),用于处理程序运行时的异常情况。异常处理使得错误处理代码与正常业务逻辑分离,提高了代码的可读性和可维护性。而 C 语言主要通过返回错误码和设置全局错误变量(如 errno)来处理错误,这种方法需要调用者主动检查返回值,容易导致错误处理代码分散在各处。
标准库:C++ 标准库比 C 语言丰富得多。除了包含 C 语言的标准库(如 stdio.h、stdlib.h)外,C++ 还提供了面向对象的输入输出流(iostream)、字符串处理(string)、容器(vector、list、map 等)、算法(algorithm)、正则表达式(regex)等功能。这些标准库组件大大提高了开发效率。
内存管理:C++ 支持动态内存分配(new/delete)和静态内存分配,而 C 语言主要使用 malloc/free 进行动态内存分配。new/delete 与构造函数和析构函数自动关联,能够更安全地管理对象的生命周期。此外,C++ 引入了智能指针(如 unique_ptr、shared_ptr),通过引用计数等机制自动管理内存,减少了内存泄漏的风险。
函数重载和运算符重载:C++ 支持函数重载和运算符重载,允许定义多个同名但参数列表不同的函数,以及重新定义运算符的行为。这使得代码更加直观和灵活。例如,可以重载 + 运算符实现自定义类型的加法操作。C 语言不支持函数重载和运算符重载,每个函数必须有唯一的名称。
命名空间:C++ 引入了命名空间(namespace)的概念,用于解决全局标识符命名冲突的问题。命名空间可以将代码组织成逻辑上的组,不同命名空间中的标识符可以重名。而 C 语言没有命名空间的概念,所有全局标识符都共享同一个命名空间。
编译模型:C++ 的编译模型比 C 语言复杂。由于支持模板、类模板、函数模板等特性,C++ 的编译过程分为编译和链接两个阶段,且模板的实例化可能导致编译时间增加。C 语言的编译模型相对简单,主要是将源文件分别编译为目标文件,然后链接成可执行文件。
代码示例:
// C++ 示例:面向对象编程
#include <iostream>
#include <string>
#include <vector>
// 基类
class Animal {
protected:
std::string name;
public:
Animal(const std::string& n) : name(n) {}
virtual void speak() const {
std::cout << "Animal " << name << " speaks" << std::endl;
}
virtual ~Animal() {}
};
// 派生类
class Dog : public Animal {
public:
Dog(const std::string& n) : Animal(n) {}
void speak() const override {
std::cout << "Dog " << name << " barks" << std::endl;
}
};
class Cat : public Animal {
public:
Cat(const std::string& n) : Animal(n) {}
void speak() const override {
std::cout << "Cat " << name << " meows" << std::endl;
}
};
// 泛型函数
template<typename T>
T max(T a, T b) {
return a > b ? a : b;
}
int main() {
// 面向对象示例
std::vector<Animal*> animals;
animals.push_back(new Dog("Buddy"));
animals.push_back(new Cat("Whiskers"));
for (const auto& animal : animals) {
animal->speak(); // 多态调用
}
for (const auto& animal : animals) {
delete animal;
}
// 泛型示例
std::cout << "Max of 5 and 10: " << max(5, 10) << std::endl;
std::cout << "Max of 3.2 and 4.5: " << max(3.2, 4.5) << std::endl;
return 0;
}
C++ 和 C 语言在设计理念和功能特性上有很大差异。C++ 通过引入面向对象编程、泛型编程、异常处理等机制,提供了更强大的抽象能力和更高的开发效率,适合开发大型、复杂的应用程序。而 C 语言由于其简洁性和对底层硬件的直接访问能力,仍然是系统编程和嵌入式开发的首选语言。理解这些差异有助于开发者在合适的场景选择合适的编程语言。