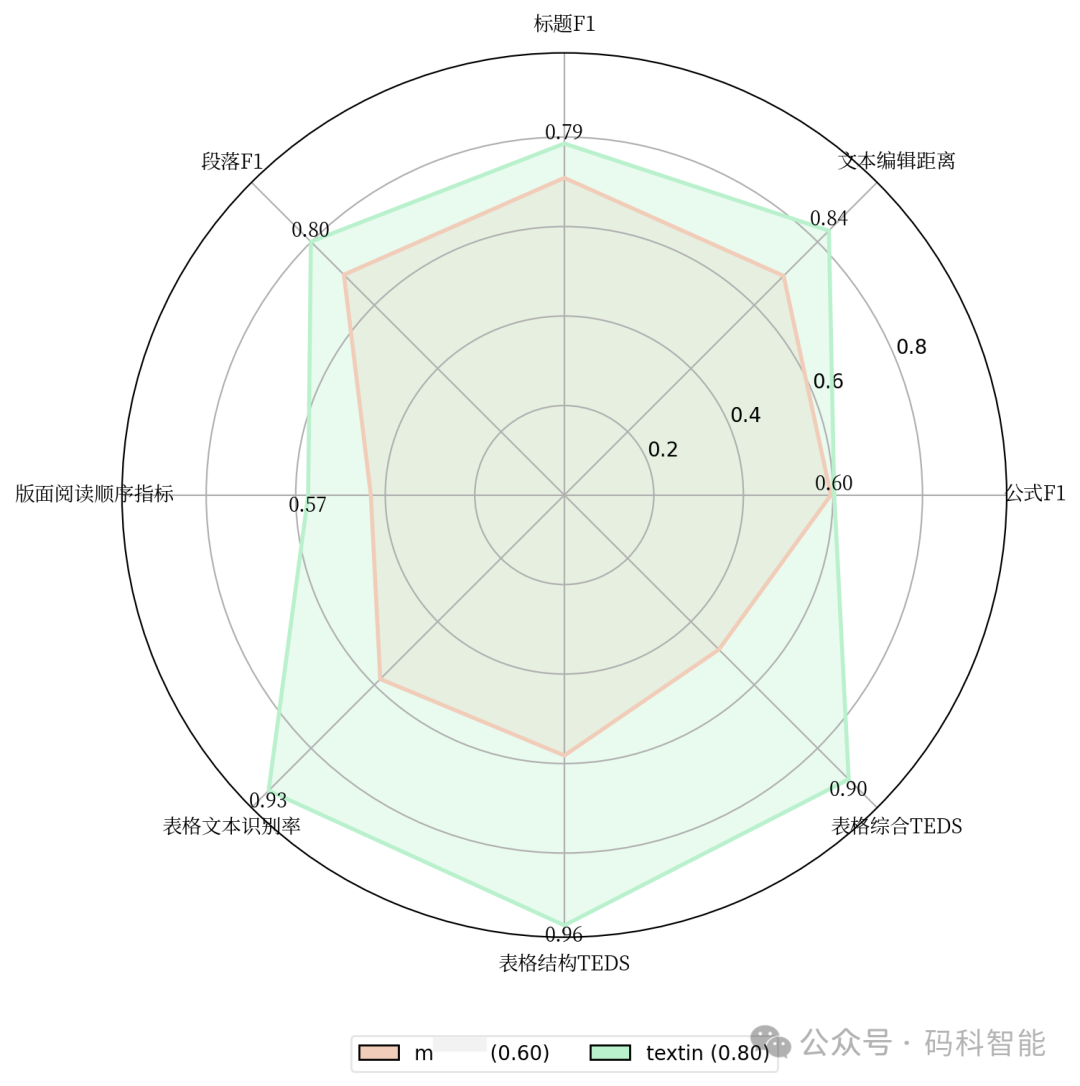
示例:
输入:source = [1,2,3,4], target = [2,1,4,5], allowedSwaps = [[0,1],[2,3]]
输出:1
解释:source 可以按下述方式转换:
- 交换下标 0 和 1 指向的元素:source = [2,1,3,4]
- 交换下标 2 和 3 指向的元素:source = [2,1,4,3]
source 和 target 间的汉明距离是 1 ,二者有 1 处元素不同,在下标 3 。
数据范围
- n == source.length == target.length
- 1 <= n <= 105
- 1 <= source[i], target[i] <= 105
- 0 <= allowedSwaps.length <= 105
- allowedSwaps[i].length == 2
- 0 <= ai, bi <= n - 1
- ai != bi
我的解题思路
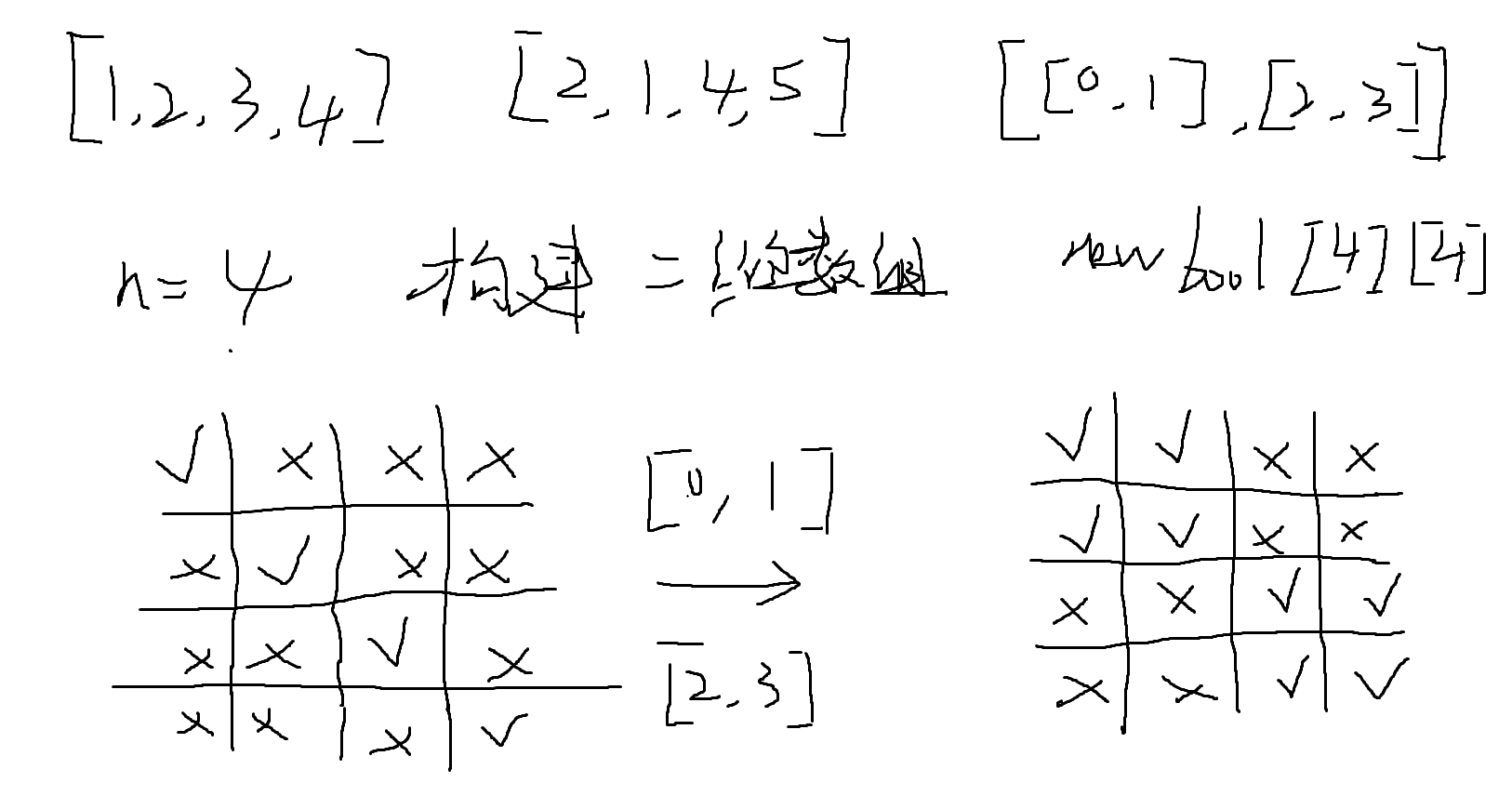
根据target和source的数组长度设置一个boolean的二维数组去制定访问规则,初始化时使得source下标对应的target下标都可以被访问,因为会出现这类数组target=[1,2,3,4],source=[1,3,2,4],此时我们不管是否存在交换我们都得去验证一下target[i]是否与source[i]相等。
之后就根据allowedSwaps这个数组去将[0,1]和[2,3]做交换,说是做交换其实就是去改变二维数组中的值,将其改成true,使其可以被访问,然后对比,忘了说明,对于这个二维数组,其实bool[i][j]中i代表的是target数组的下标j代表的是source数组的下标,这样就能很好的遍历然后进行对比。
这是我一开始认为的处理方式,后面提交后看测试样例,发现此题远不止此,首先对于交换数组allowedSwaps[]其可能出现该情况allowedSwaps[[0,1],[0,4]]这表明其实[1,4]也是可以交换的,所以我们在构建二维数组时也得将[1][4]和[4,1]变成true,所以在这个地方我就无所适从了,没法找到属于自己的解决方法,即使找到了,是不是会超时呢,这个也要打上一个问号
那么原题的解决方法是并查集,并查集的解决思路是,如图所示
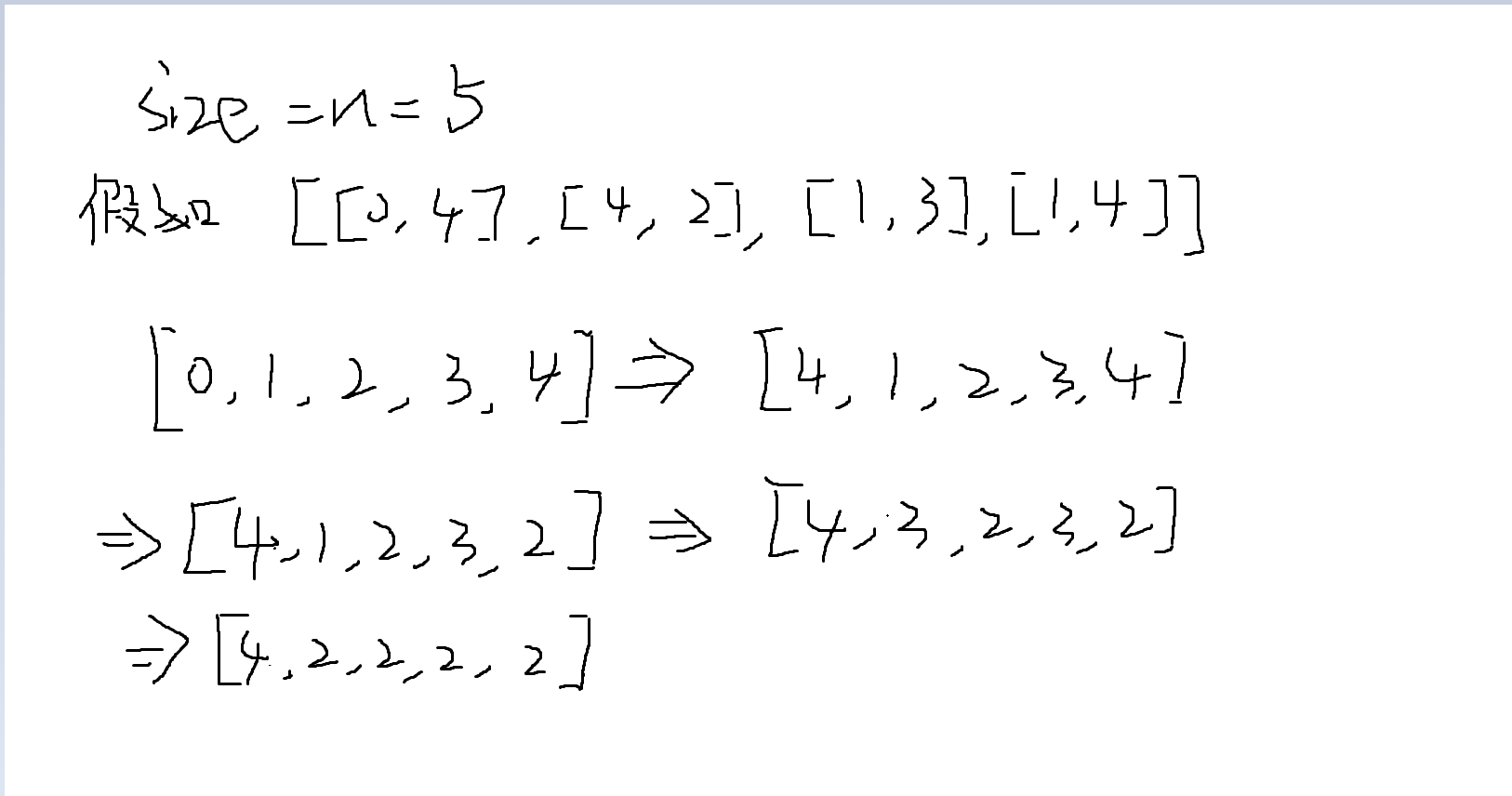
class UnionFind {
int[] parent;
public UnionFind(int n) {
parent = new int[n];
for (int i = 0; i < n; i++) parent[i] = i;
}
public int find(int x) {
if (parent[x] != x)
parent[x] = find(parent[x]);
return parent[x];
}
public void union(int x, int y) {
parent[find(x)] = find(y);
}
}
根节点合并的过程,然后使用map维护,将不同根节点的数字(下标)分组
Map<Integer, List<Integer>> groups = new HashMap<>();
for (int i = 0; i < n; i++) {
int root = uf.find(i);
groups.computeIfAbsent(root, k -> new ArrayList<>()).add(i);
}
以上是我第一个不会的点和犯的错,之后还有第二个点错误
boolean[][] ans = new boolean[n][n];
for(int i=0;i<n;i++){
Arrays.fill(ans[i],false);
}
for(int i=0;i<n;i++){
ans[i][i] = true;
}
//对每组内部下标打标记
for (List<Integer> group : groups.values()) {
for (int i : group) {
for (int j : group) {
if (i != j) {
ans[i][j] = true;
}
}
}
}
int num = 0;
for(int i=0;i<n;i++){
boolean plain = true;
for(int j=0;j<n;j++){
if(ans[i][j]){
if(target[i]==source[j]){
plain=false;
break;
}
}
}
System.out.println(plain);
//计数问题
if(plain){
num++;
}
}
之后我还是沿用上述思路,因为用并查集解决了数组的问题,我便认为可以就这么使用二维数组解决,结果不仅仅碰到了内存超出限制的问题还遇到了计数问题,现在我继续带大家看看我的思路和出现的问题
内存超出限制的问题是因为我们开了一个boolean的二维数组导致的,而计数问题是因为以上代码是根据target[i]==source[j]判断是否存在相同的值就可以了,但并没有考虑过是否已经在之前使用过了,所以这里我们也得使用map进行计数统计,防止算多了
int res = 0;
for (List<Integer> group : groups.values()) {
Map<Integer, Integer> freq = new HashMap<>();
// count source values
for (int idx : group) {
freq.put(source[idx], freq.getOrDefault(source[idx], 0) + 1);
}
// try to cancel with target values
for (int idx : group) {
int t = target[idx];
if (freq.getOrDefault(t, 0) > 0) {
freq.put(t, freq.get(t) - 1);
} else {
res++; // unmatched element
}
}
}
return res;
所以最后答案如下:
class Solution {
public int minimumHammingDistance(int[] source, int[] target, int[][] allowedSwaps) {
int n = target.length;
int m = allowedSwaps.length;
UnionFind uf = new UnionFind(n);
for (int[] pair : allowedSwaps) {
uf.union(pair[0], pair[1]);
}
Map<Integer, List<Integer>> groups = new HashMap<>();
for (int i = 0; i < n; i++) {
int root = uf.find(i);
groups.computeIfAbsent(root, k -> new ArrayList<>()).add(i);
}
for (Map.Entry<Integer, List<Integer>> entry : groups.entrySet()) {
System.out.println("Root: " + entry.getKey() + ", Group: " + entry.getValue());
}
int res = 0;
for (List<Integer> group : groups.values()) {
Map<Integer, Integer> freq = new HashMap<>();
// count source values
for (int idx : group) {
freq.put(source[idx], freq.getOrDefault(source[idx], 0) + 1);
}
// try to cancel with target values
for (int idx : group) {
int t = target[idx];
if (freq.getOrDefault(t, 0) > 0) {
freq.put(t, freq.get(t) - 1);
} else {
res++; // unmatched element
}
}
}
return res;
}
class UnionFind {
int[] parent;
public UnionFind(int n) {
parent = new int[n];
for (int i = 0; i < n; i++) parent[i] = i;
}
public int find(int x) {
if (parent[x] != x)
parent[x] = find(parent[x]);
return parent[x];
}
public void union(int x, int y) {
parent[find(x)] = find(y);
}
}
}