目录
一、引言
二、蓝耘元生代和 ComfyUI 工作流初印象
(一)蓝耘元生代平台简介
(二)ComfyUI 工作流创建是啥玩意儿
三、计算机视觉是个啥
(一)计算机视觉的基本概念
(二)计算机视觉的应用场景
四、蓝耘元生代平台上的 ComfyUI 工作流与计算机视觉的联系
(一)数据处理方面的联系
(二)模型训练方面的联系
(三)模型部署方面的联系
五、实际案例分析
(一)基于蓝耘元生代和 ComfyUI 工作流的图像分类项目
1. 数据收集和预处理
2. 模型选择和训练
3. 模型评估和优化
4. 模型部署和应用
六、遇到的问题和解决方案
(一)数据处理方面的问题
(二)模型训练方面的问题
(三)模型部署方面的问题
七、总结
一、引言
嘿,各位热爱学习编程的小伙伴们!咱们都知道,在计算机领域里,新技术就跟雨后春笋似的,一个接一个地冒出来。最近我就对蓝耘元生代这个平台特别感兴趣,尤其是它实现的工作流(ComfyUI)创建和计算机视觉之间的联系。今天呢,我就想跟大家好好唠唠这两者之间到底有啥关系,说不定能给咱们的学习和研究带来一些新的启发呢!
二、蓝耘元生代和 ComfyUI 工作流初印象
(一)蓝耘元生代平台简介
蓝耘元生代这个平台啊,在我看来就像是一个超级大的技术宝库。它整合了好多先进的技术和工具,能让我们在上面搞各种开发和研究。感觉它就像是一个充满魔法的舞台,能让我们的想法和创意尽情地展现出来。而且听说它在很多领域都有应用,像人工智能、大数据啥的,都能在这个平台上找到用武之地。
登录与注册:打开浏览器,访问蓝耘 GPU 智算云平台官网(https://cloud.lanyun.net//#/registerPage?promoterCode=0131 )。新用户需先进行注册,注册成功后即可享受免费体验 18 小时算力的优惠。登录后,用户将进入蓝耘平台的控制台,在这里可以看到丰富的功能模块,如容器云市场、应用市场等 。

(二)ComfyUI 工作流创建是啥玩意儿
ComfyUI 工作流创建呢,其实就是在蓝耘元生代平台上搭建一套工作流程。打个比方吧,就像是我们做手工,得有个步骤和顺序,先做啥后做啥都得安排好。ComfyUI 工作流就是把计算机程序里的各种任务和操作按照一定的顺序和规则组合起来,让它们能自动地完成一系列的工作。比如说,我们要处理一批图片,可能得先把图片下载下来,然后对图片进行裁剪、调整颜色啥的,最后再把处理好的图片保存起来。用 ComfyUI 工作流,我们就能把这些步骤都安排好,让程序自动地完成这些操作,是不是很方便?
三、计算机视觉是个啥
(一)计算机视觉的基本概念
计算机视觉啊,简单来说就是让计算机像人一样 “看” 东西。我们人类的眼睛能看到周围的世界,然后大脑会对看到的东西进行分析和理解。计算机视觉就是要让计算机也能做到这一点,它通过摄像头或者其他设备获取图像或视频,然后用各种算法和技术对这些图像和视频进行处理和分析,从而识别出图像里有啥东西,它们的位置在哪里,甚至还能理解图像所表达的含义。比如说,人脸识别技术就是计算机视觉的一个典型应用,它能让计算机准确地识别出人的脸,还能判断这个人是谁。
(二)计算机视觉的应用场景
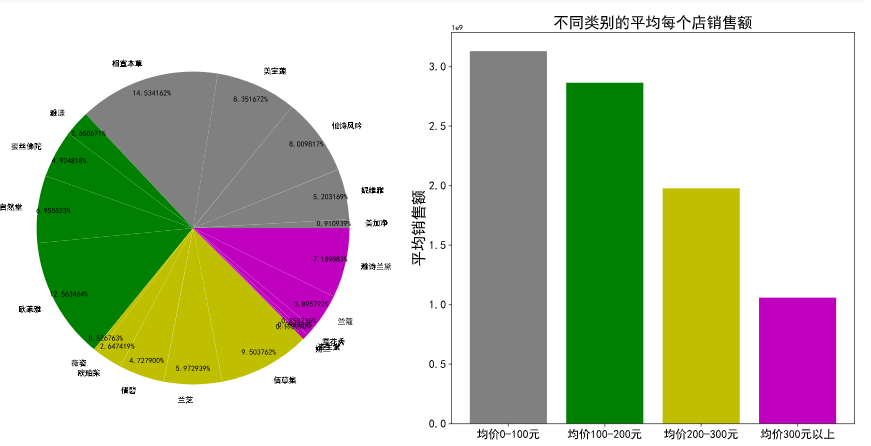
计算机视觉的应用场景那可多了去了。在安防领域,它可以用于监控摄像头,自动识别出可疑人员和异常行为;在自动驾驶领域,计算机视觉能让汽车 “看” 到周围的路况,识别出道路、交通标志和其他车辆,从而实现自动驾驶;在医疗领域,它可以帮助医生分析 X 光片、CT 图像等,辅助诊断疾病。还有电商领域,计算机视觉可以用于商品识别和推荐,根据用户上传的商品图片,推荐相似的商品给用户。总之,计算机视觉在我们生活的方方面面都有着广泛的应用。
四、蓝耘元生代平台上的 ComfyUI 工作流与计算机视觉的联系
(一)数据处理方面的联系
在计算机视觉里,数据处理可是非常重要的一步。我们要对大量的图像和视频数据进行预处理,比如调整图像的大小、亮度、对比度,把图像转换成计算机能处理的格式等等。而 ComfyUI 工作流在蓝耘元生代平台上就能很好地完成这些数据处理任务。
比如说,我们有一个计算机视觉项目,需要处理一批从网上下载下来的图片。这些图片的大小和格式都不一样,我们得把它们统一成相同的大小和格式,才能进行后续的分析。这时候,我们就可以用 ComfyUI 工作流来完成这个任务。我们可以在工作流里设置一个图片处理节点,这个节点可以调用 Python 的图像处理库(像 Pillow 库)来对图片进行处理。下面是一段简单的 Python 代码示例,展示了如何用 Pillow 库来调整图片的大小:
from PIL import Image
def resize_image(input_path, output_path, width, height):
try:
image = Image.open(input_path)
resized_image = image.resize((width, height))
resized_image.save(output_path)
print(f"Image resized and saved to {output_path}")
except Exception as e:
print(f"Error resizing image: {e}")
# 使用示例
input_image_path = 'input.jpg'
output_image_path = 'output.jpg'
new_width = 800
new_height = 600
resize_image(input_image_path, output_image_path, new_width, new_height)在 ComfyUI 工作流里,我们可以把这个函数封装成一个节点,然后通过设置节点的输入参数(比如输入图片的路径、输出图片的路径、新的宽度和高度),就可以让工作流自动地对图片进行处理。这样,我们就可以用 ComfyUI 工作流来批量处理大量的图片,提高数据处理的效率。
(二)模型训练方面的联系
计算机视觉的核心就是各种模型,像卷积神经网络(CNN)、目标检测模型(如 YOLO)等等。这些模型需要大量的数据来进行训练,才能达到较好的效果。而 ComfyUI 工作流在模型训练方面也能发挥很大的作用。
比如说,我们要训练一个人脸识别模型。在训练之前,我们需要准备好训练数据,包括人脸图片和对应的标签(也就是这个人是谁)。然后,我们需要对数据进行划分,分成训练集和测试集。接着,我们要选择合适的模型架构,设置好训练参数,开始训练模型。最后,我们还要对训练好的模型进行评估,看看它的性能怎么样。
在这个过程中,ComfyUI 工作流可以把这些步骤都整合起来。我们可以在工作流里设置数据准备节点、模型训练节点、模型评估节点等等。每个节点都可以调用相应的 Python 代码来完成特定的任务。下面是一段简单的 Python 代码示例,展示了如何用 PyTorch 来训练一个简单的卷积神经网络:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 定义一个简单的卷积神经网络
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(16 * 16 * 16, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.pool1(x)
x = x.view(-1, 16 * 16 * 16)
x = self.fc1(x)
return x
# 数据预处理
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载训练集和测试集
train_dataset = datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=32, shuffle=False)
# 初始化模型、损失函数和优化器
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 训练模型
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(train_loader)}')
# 评估模型
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the test images: {100 * correct / total}%')在 ComfyUI 工作流里,我们可以把这个训练过程封装成一个节点,然后通过设置节点的输入参数(比如训练数据的路径、模型的保存路径、训练的轮数等等),就可以让工作流自动地完成模型的训练和评估。这样,我们就可以用 ComfyUI 工作流来管理复杂的模型训练过程,提高训练的效率和可重复性。
(三)模型部署方面的联系
训练好的模型还得部署到实际的应用中才能发挥作用。在计算机视觉里,模型部署也有很多挑战,比如要考虑模型的性能、内存占用、推理速度等等。而 ComfyUI 工作流在模型部署方面也能提供一些帮助。
比如说,我们训练好了一个目标检测模型,要把它部署到一个移动设备上。在部署之前,我们需要对模型进行优化,比如量化模型、剪枝模型等等,以减少模型的内存占用和提高推理速度。然后,我们还需要把优化后的模型转换成适合移动设备的格式,比如 TensorFlow Lite 格式。
在这个过程中,ComfyUI 工作流可以把这些步骤都整合起来。我们可以在工作流里设置模型优化节点、模型转换节点等等。每个节点都可以调用相应的工具和库来完成特定的任务。下面是一段简单的 Python 代码示例,展示了如何用 TensorFlow Lite 来转换一个 TensorFlow 模型:
import tensorflow as tf
# 加载训练好的TensorFlow模型
model = tf.keras.models.load_model('saved_model.h5')
# 创建一个TensorFlow Lite转换器
converter = tf.lite.TFLiteConverter.from_keras_model(model)
# 进行模型量化
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# 转换模型
tflite_model = converter.convert()
# 保存转换后的TensorFlow Lite模型
with open('converted_model.tflite', 'wb') as f:
f.write(tflite_model)五、实际案例分析
(一)基于蓝耘元生代和 ComfyUI 工作流的图像分类项目
我们来详细搞一个实际的图像分类项目,看看蓝耘元生代平台上的 ComfyUI 工作流和计算机视觉是怎么完美结合起来的。就假设我们要对水果图片进行分类,把苹果、香蕉、橙子等不同的水果图片准确地区分开来。
1. 数据收集和预处理
首先,数据收集这一步至关重要。我们可以通过多种途径来获取水果图片数据。一方面,我们可以从网上搜索一些公开的水果图片数据集,这些数据集通常已经经过了一定的整理和标注,使用起来比较方便。另一方面,我们也可以自己动手,用相机拍摄一些水果图片,这样可以保证数据的多样性和真实性。
收集到数据后,就该进行预处理了。在 ComfyUI 工作流里,我们可以设置一系列的数据预处理节点。比如,我们要调整图片的大小,让所有的图片都具有相同的尺寸,这样可以方便后续的模型处理。可以使用 Python 的图像处理库 Pillow 来实现图片大小的调整,代码如下:
from PIL import Image
def resize_image(input_path, output_path, width, height):
try:
image = Image.open(input_path)
resized_image = image.resize((width, height))
resized_image.save(output_path)
print(f"Image resized and saved to {output_path}")
except Exception as e:
print(f"Error resizing image: {e}")
# 使用示例
input_image_path = 'input.jpg'
output_image_path = 'output.jpg'
new_width = 224
new_height = 224
resize_image(input_image_path, output_image_path, new_width, new_height)除了调整大小,我们还可能需要对图片进行亮度、对比度的调整,去除噪声等操作。这些操作都可以在 ComfyUI 工作流中通过设置相应的节点来完成。
2. 模型选择和训练
接下来就是模型选择和训练的环节了。对于图像分类任务,卷积神经网络(CNN)是一个非常不错的选择。在 ComfyUI 工作流中,我们可以设置一个模型选择节点,从众多的 CNN 模型中挑选出适合我们水果分类任务的模型,比如 ResNet、VGG 等。
选好模型后,就可以开始训练了。在训练之前,我们需要对数据进行划分,分成训练集和测试集。训练集用于训练模型,让模型学习水果图片的特征;测试集用于评估模型的性能,看看模型在未见过的数据上的表现如何。
在 ComfyUI 工作流中,我们可以设置一个模型训练节点,调用深度学习框架(如 PyTorch 或 TensorFlow)来进行模型训练。以下是一个使用 PyTorch 进行水果分类模型训练的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义一个简单的卷积神经网络
class FruitCNN(nn.Module):
def __init__(self):
super(FruitCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(32 * 56 * 56, 128)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(128, 3) # 假设我们有3种水果
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.pool2(x)
x = x.view(-1, 32 * 56 * 56)
x = self.fc1(x)
x = self.relu3(x)
x = self.fc2(x)
return x
# 数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载训练集和测试集
train_dataset = datasets.ImageFolder(root='train_data', transform=transform)
test_dataset = datasets.ImageFolder(root='test_data', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 初始化模型、损失函数和优化器
model = FruitCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 训练模型
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(train_loader)}')
# 评估模型
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the test images: {100 * correct / total}%')在 ComfyUI 工作流中,我们可以把这个训练过程封装成一个节点,通过设置节点的输入参数(如训练数据的路径、模型的保存路径、训练的轮数等),让工作流自动完成模型的训练和评估。
3. 模型评估和优化
训练好模型之后,我们要对模型进行评估,看看它的性能到底怎么样。可以使用一些评估指标,如准确率、召回率、F1 值等。在 ComfyUI 工作流中,我们可以设置一个模型评估节点,调用相应的评估函数来计算这些指标。
如果模型的性能不理想,我们就需要对模型进行优化。优化的方法有很多种,比如调整模型的架构,增加模型的层数或者神经元的数量;调整训练参数,如学习率、批次大小等;增加训练数据的数量,让模型学习到更多的特征。在 ComfyUI 工作流中,我们可以设置一个模型优化节点,根据评估结果自动调整模型的参数,进行多次训练和评估,直到模型的性能达到满意的程度。
4. 模型部署和应用
最后,我们要把训练好的模型部署到实际的应用中。可以把模型部署到一个 Web 应用中,让用户上传水果图片,然后用模型对图片进行分类,返回分类结果。在 ComfyUI 工作流中,我们可以设置一个模型部署节点,调用相应的工具和库来完成模型的部署。
以下是一个简单的使用 Flask 框架搭建 Web 应用,实现水果图片分类的示例代码:
from flask import Flask, request, jsonify
import torch
import torchvision.transforms as transforms
from PIL import Image
import io
app = Flask(__name__)
# 加载训练好的模型
model = torch.load('fruit_model.pth')
model.eval()
# 数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
@app.route('/classify', methods=['POST'])
def classify():
try:
# 获取上传的图片
file = request.files['image']
image = Image.open(io.BytesIO(file.read()))
# 预处理图片
image = transform(image).unsqueeze(0)
# 进行分类
with torch.no_grad():
outputs = model(image)
_, predicted = torch.max(outputs.data, 1)
# 返回分类结果
classes = ['apple', 'banana', 'orange'] # 假设我们有3种水果
result = classes[predicted.item()]
return jsonify({'result': result})
except Exception as e:
return jsonify({'error': str(e)})
if __name__ == '__main__':
app.run(debug=True)在 ComfyUI 工作流中,我们可以把这个 Web 应用的部署过程封装成一个节点,通过设置节点的输入参数(如模型的路径、端口号等),让工作流自动完成模型的部署和 Web 应用的启动。
六、遇到的问题和解决方案
(一)数据处理方面的问题
在数据处理过程中,我们可能会遇到一些问题。比如说,图片数据的质量不高,有噪声、模糊等问题。这时候,我们可以用一些图像处理技术来对图片进行去噪、锐化等处理。在 ComfyUI 工作流里,我们可以设置一个图像处理节点,调用相应的图像处理库来完成这些任务。
还有,数据的标注可能会有错误或者不一致的情况。这时候,我们可以人工检查标注数据,修正错误的标注。也可以用一些数据增强技术,比如随机裁剪、旋转、翻转等,来增加数据的多样性,减少标注错误对模型训练的影响。
(二)模型训练方面的问题
在模型训练过程中,我们可能会遇到过拟合或者欠拟合的问题。过拟合就是模型在训练集上表现很好,但是在测试集上表现很差;欠拟合就是模型在训练集和测试集上的表现都不好。
如果遇到过拟合的问题,我们可以采用一些正则化技术,比如 L1 和 L2 正则化,来减少模型的复杂度。也可以增加训练数据的数量,让模型学习到更多的特征。在 ComfyUI 工作流里,我们可以设置一个正则化节点,调用相应的深度学习框架来实现正则化。
如果遇到欠拟合的问题,我们可以增加模型的复杂度,比如增加神经网络的层数或者神经元的数量。也可以调整模型的训练参数,比如学习率、训练的轮数等等。在 ComfyUI 工作流里,我们可以设置一个模型调整节点,调用相应的深度学习框架来调整模型的参数。
(三)模型部署方面的问题
在模型部署过程中,我们可能会遇到一些性能问题。比如说,模型的推理速度太慢,不能满足实际应用的需求。这时候,我们可以对模型进行优化,比如量化模型、剪枝模型等等,以减少模型的内存占用和提高推理速度。在 ComfyUI 工作流里,我们可以设置一个模型优化节点,调用相应的工具和库来完成模型的优化。
还有,模型在不同的设备上可能会有兼容性问题。这时候,我们可以把模型转换成适合不同设备的格式,比如 TensorFlow Lite 格式、ONNX 格式等等。在 ComfyUI 工作流里,我们可以设置一个模型转换节点,调用相应的工具和库来完成模型的转换。
七、总结
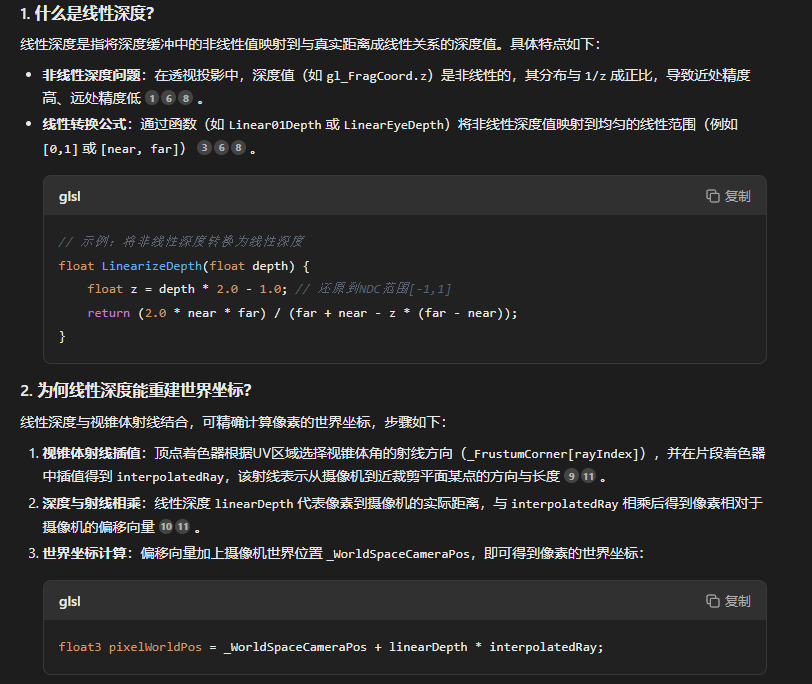
通过上面的分析,我们可以看到蓝耘元生代平台上的 ComfyUI 工作流和计算机视觉之间有着非常紧密的联系。在数据处理方面,ComfyUI 工作流可以帮助我们高效地完成图像和视频数据的预处理;在模型训练方面,它可以帮助我们管理复杂的模型训练过程,提高训练的效率和可重复性;在模型部署方面,它可以帮助我们管理复杂的模型部署过程,提高部署的效率和可靠性。








![57.[前端开发-前端工程化]Day04-webpack插件模式-搭建本地服务器](https://i-blog.csdnimg.cn/direct/65a5bbd2e84a449c810dba872b13e55a.png)