Redis分片(Sharding)是解决单机性能瓶颈的核心技术,其本质是将数据分散存储到多个Redis节点(实例)中,每个实例将只是所有键的一个子集,通过水平扩展提升系统容量和性能。
分片的核心价值
-
性能提升:
存储扩展:突破单机内存限制,支持TB级数据存储。
计算并行化:多节点同时处理请求,提高吞吐量(如电商大促场景下,分片集群可承载百万级QPS)。 -
高可用性:
故障隔离:单节点故障仅影响其管理的槽,其他节点正常服务。
主从复制:每个主节点可配置从节点,主节点宕机时从节点自动接管槽。 -
资源优化:
冷热数据分离:高频访问数据可分配至SSD节点,低频数据存机械硬盘,降低成本。
负载均衡:哈希槽机制确保数据均匀分布,避免“热点”问题。
分片的实现方式
按照分片的计算逻辑由谁来执行,可以分为以下几种实现方式:
-
客户端分片:由客户端直接计算键的槽编号,并连接对应节点。例如,使用一致性哈希算法或直接取模分配节点。
- 优点:实现简单,无需中间代理。
- 缺点:节点变更时需手动调整客户端逻辑,运维复杂度高。
-
代理分片:通过中间代理(如Twemproxy)转发请求,客户端不感知节点信息。代理根据分片规则将请求路由到目标节点。
- 优点:客户端无需关心分片细节。
- 缺点:代理层可能成为性能瓶颈。
-
服务端分片(Redis Cluster):Redis官方集群模式,节点间通过Gossip协议同步槽分配信息。客户端可连接任意节点,若请求的键不属于当前节点,服务端会返回重定向指令。
- 特点:支持自动故障转移、数据迁移,是生产环境首选方案。
查询路由:可发送你的查询到一个随机实例,该实例会保证转发你的查询到正确节点。
Redis集群在客户端的帮助下,实现了查询路由的一种混合形式,请求不是直接从Redis实例转发到另一个,而是客户端收到重定向到正确的节点。
分片的算法
范围分区
范围分区也叫顺序分区,最简单的分区方式。通过映射对象的范围到指定的Redis实例来完成分片。
假设用户ID的范围为1100,从133进入实例Redis1,3466进入Redis2,67100进入Redis3。
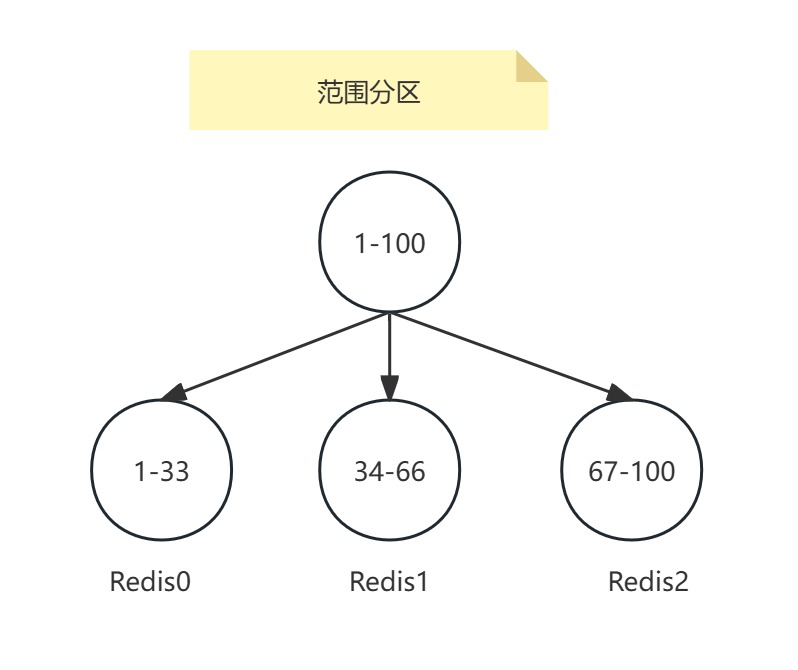
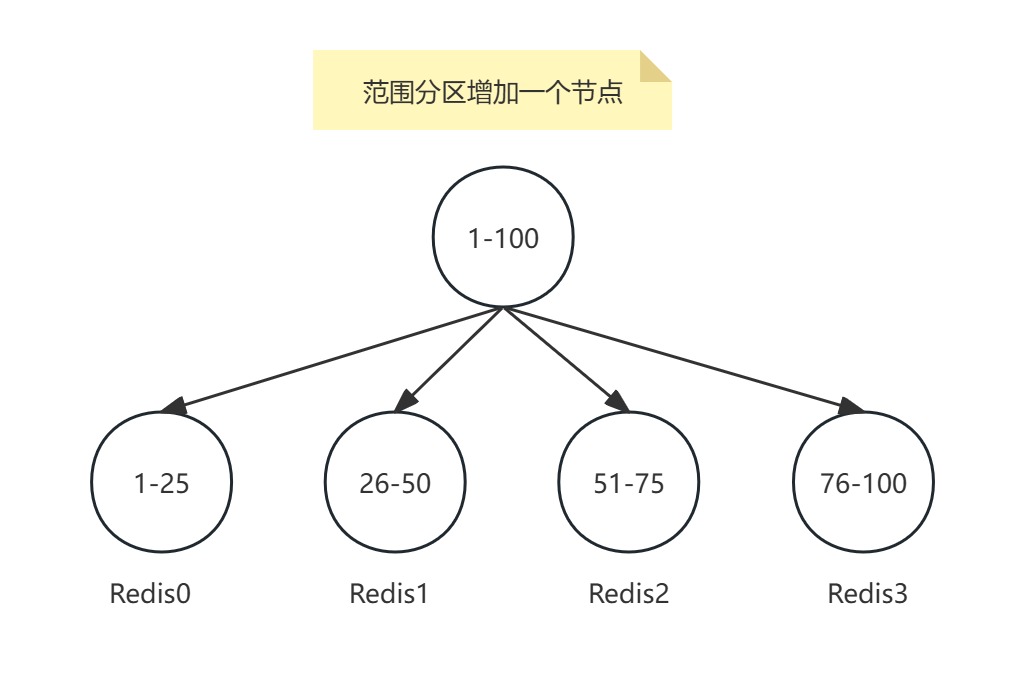
范围分区增加一个节点需要迁移大部分数据:
优点:
- 支持高效的范围查询:同一范围分区内的范围查询不需要跨节点,提升查询速度。
- 支持批量操作:支持同一范围分区内的批量操作如事务、pipeline、lua脚本等
- 实现简单直观:分区规则逻辑清晰,开发人员易于理解和维护。
缺点:
- 数据分散度易倾斜:若分区键范围设计不合理,可能导致部分分区数据量过大
- 分区键选择受限:范围分区要求分区键为数值型或可排序字段(如时间、ID)
- 维护范围映射表:需额外存储和管理分区范围与节点的映射关系,增加系统复杂性
- 数据迁移成本:调整分区范围时,需迁移大部分数据
哈希取余分区
哈希取余分区是分布式缓存中常用的数据分片策略,其核心原理是通过哈希函数和取模运算将数据均匀分布到多个节点。
对每个键(Key)使用哈希函数(如CRC16、MD5)计算哈希值,再对Redis节点总数取余,公式为:
目标节点 = hash(key) % 节点数量
例如,3个节点的集群中,键user:100的哈希值为93024922,则93024922 % 3 = 1,该键会被分配到第2个节点(编号从 0开始)。
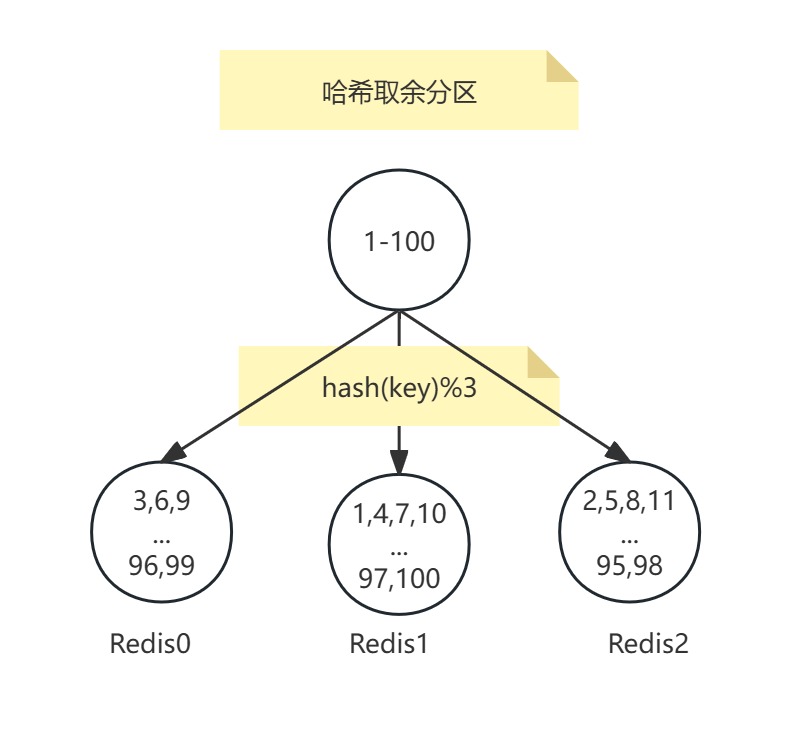
添加一个节点:
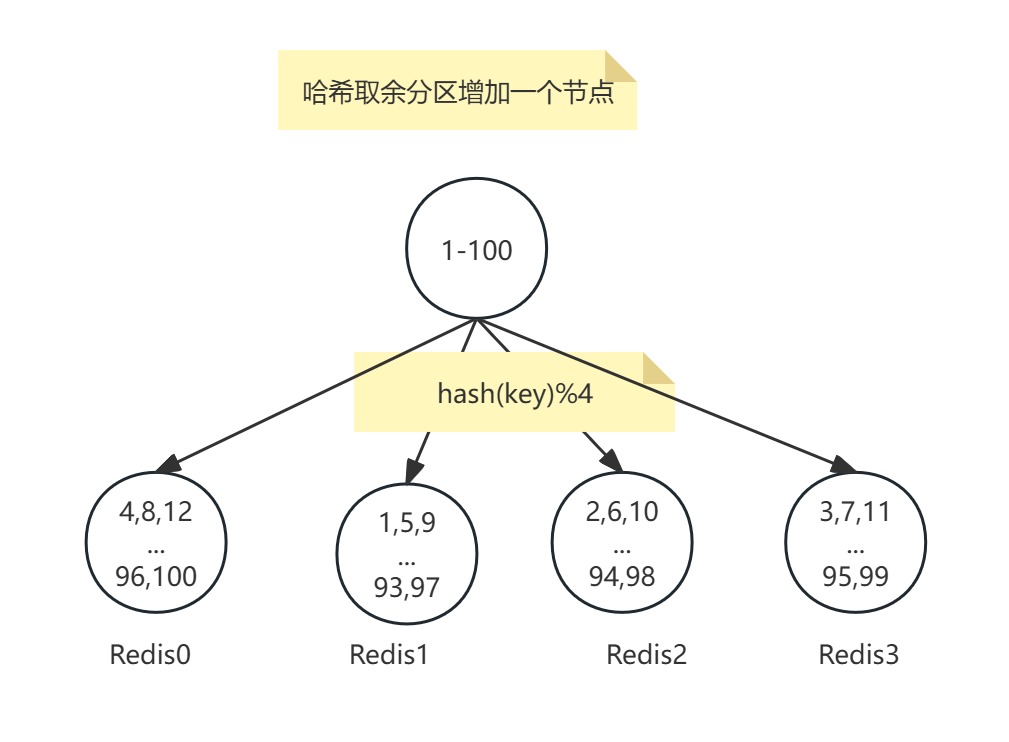
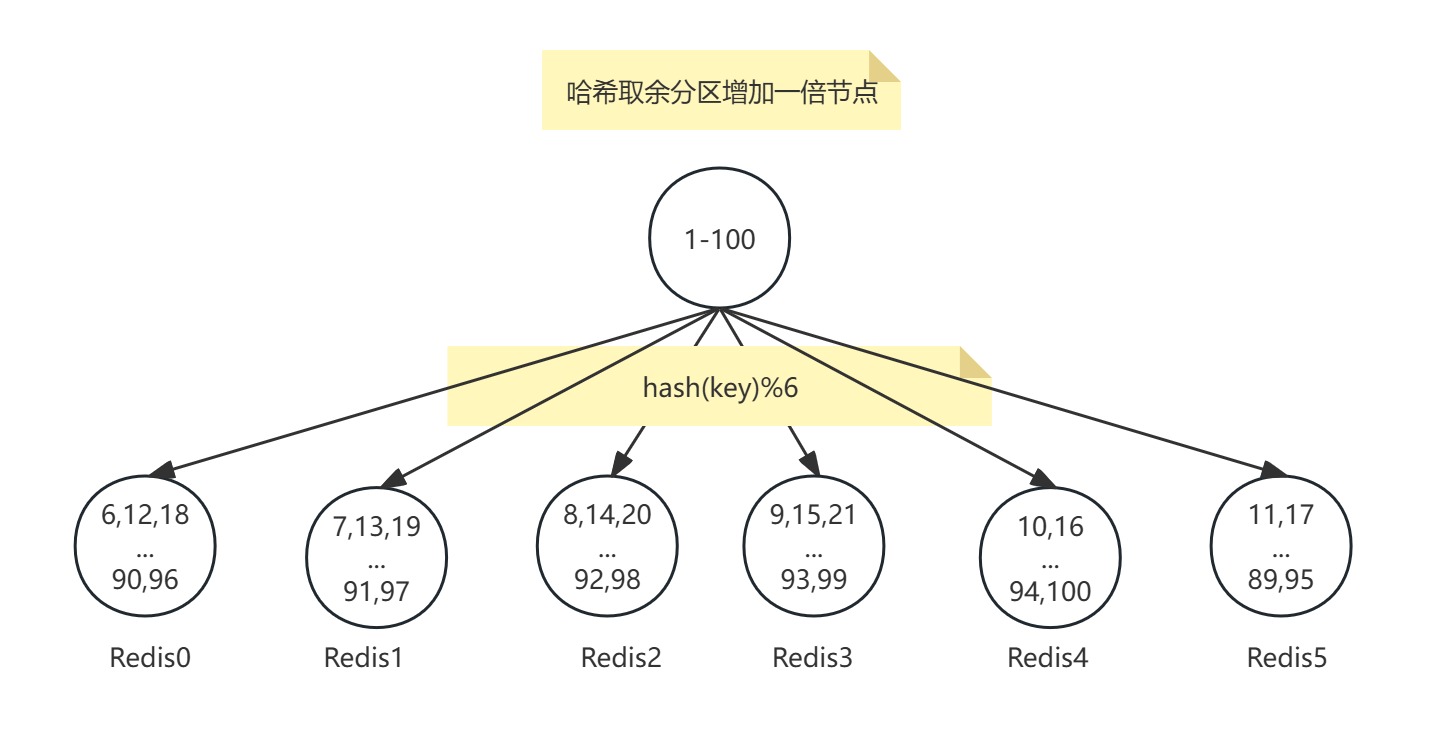
翻倍扩容
优点:
- 实现简单高效:仅需哈希函数和取模运算即可完成数据分布,适合快速搭建小型分布式系统。
- 负载均衡:数据均匀分布到所有节点,每个节点处理固定比例的请求,避免单点过载。
缺点:扩容/缩容成本高,节点数量变化时,取模分母改变,导致所有数据需重新计算映射关系并迁移,引发全量数据洗牌。从 3节点扩容至4节点时,hash(key) % 3变为hash(key) % 4,75%的数据需迁移。虽然翻倍扩容可以相对减少迁移量,但是翻倍所需的成本太大。
一致性哈希分区
一致性哈希分区是一种用于分布式系统的数据分片技术,旨在解决节点动态变化时数据迁移开销大的问题。
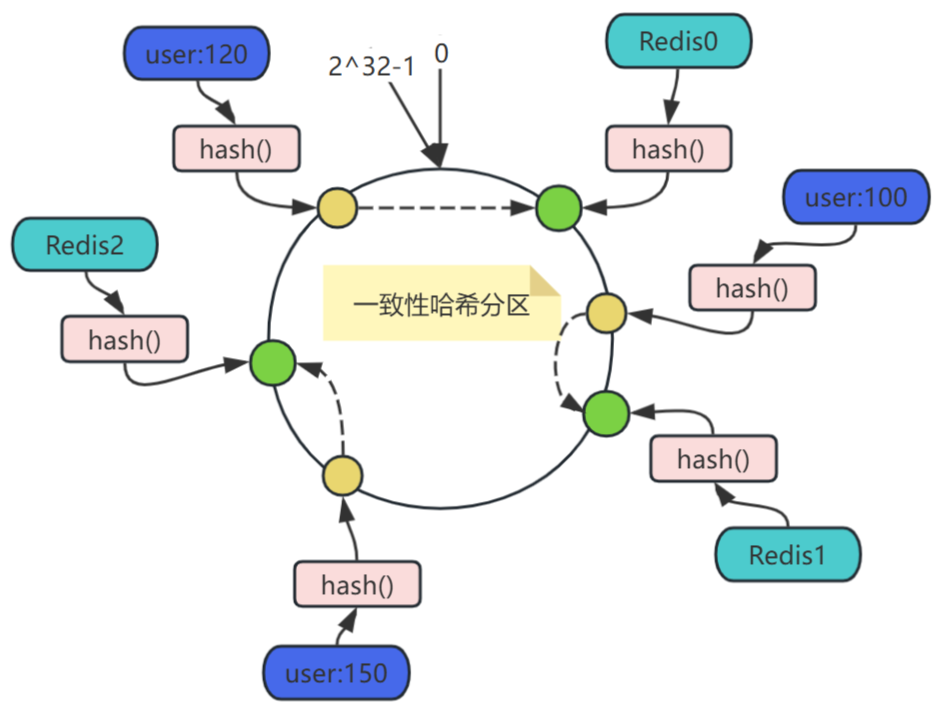
设计如下:
-
设计哈希函数Hash(key),要求取值范围为
[0, 2^32-1],将这个取值范围的数字头尾相连,想象成一个闭合环形,各哈希值在Hash环上的分布:时钟12点位置为0,按顺时针方向递增,临近12点的左侧位置为2^32-1。 -
将Redis节点映射至哈希环,如图哈希环上的绿球所示,三个节点Redis0、Redis1、Redis2,可以通过其IP地址或机器名,经过同一个Hash函数计算的结果,映射到哈希环上。
-
将key映射于哈希环,如图哈希环上的黄球所示,三个key
user:100、user:120、user:150经过同一个Hash()计算的结果,映射到哈希环上。 -
将key映射至Redis节点,在对象和节点都映射至同一个哈希环之后,要确定某个对象映射至哪个节点,只需从该对象开始,沿着哈希环顺时针方向查找,找到的第一个节点,即是。
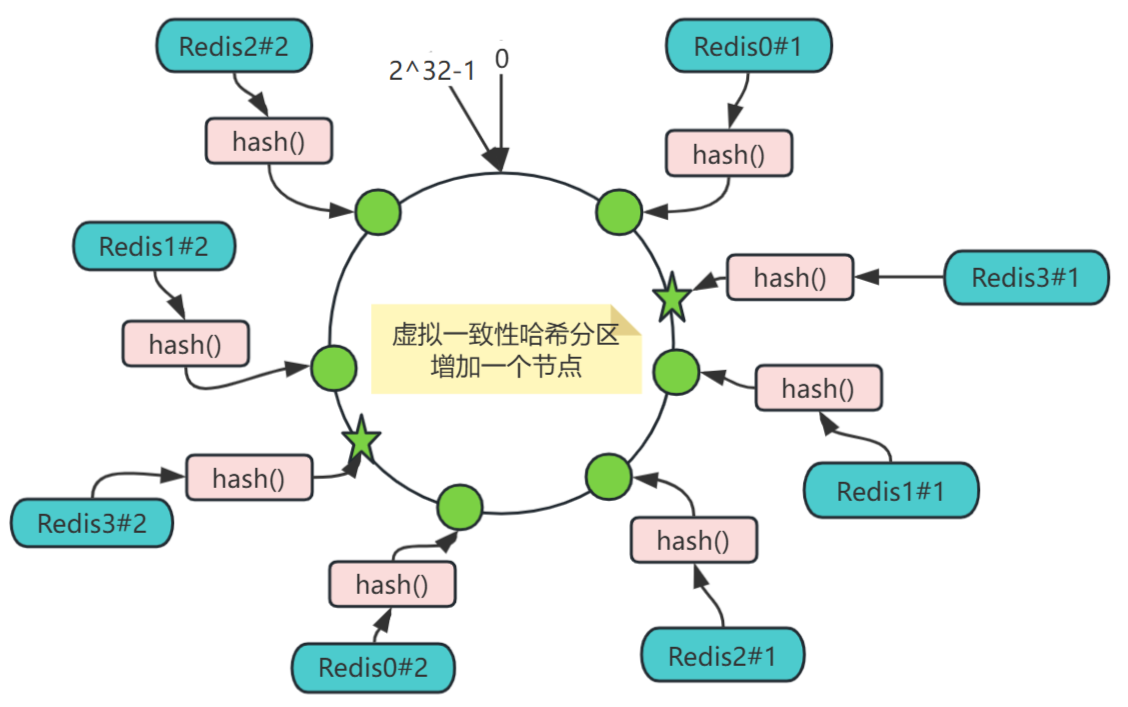
增加节点:服务器扩容时增加节点,比如要在Redis1和Redis2之间增加节点Redis3,只会影响欲新增节点Redis3与上一个(顺时针为前进方向)节点Redis1之间的对象,也就是user:300,这些对象的映射关系,按照上面的规则,调整映射至新增的节点Redis3,其他对象的映射关系,都无需调整。
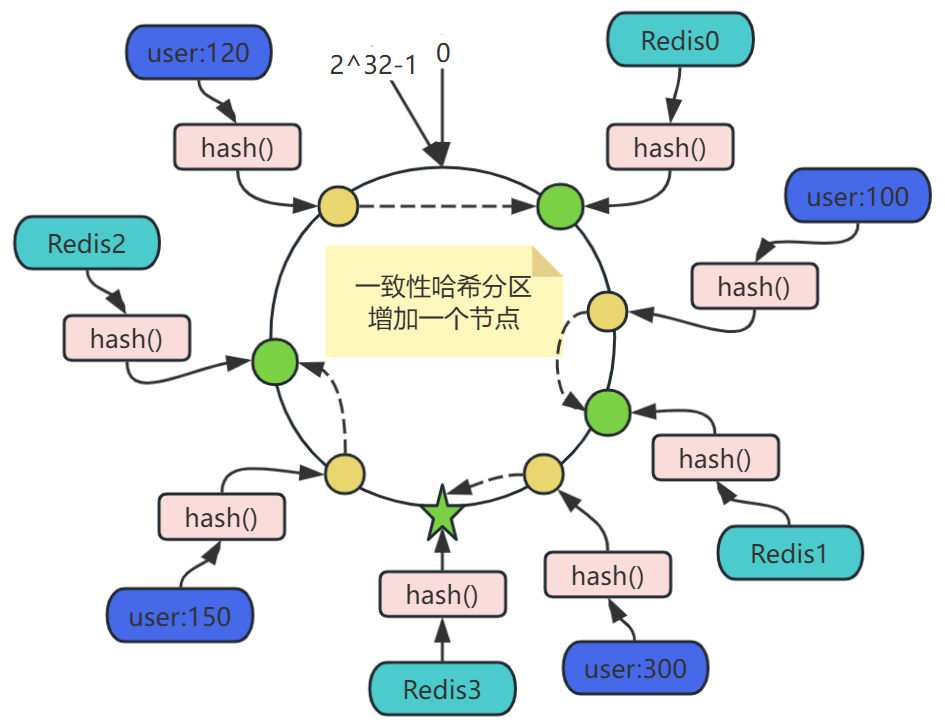
优点:
- 动态扩展友好:增减节点仅影响相邻节点,迁移量减少至约1/N(N为节点数)。
缺点:
- 数据倾斜风险:节点较少时分布不均。
- 数据丢失风险:欲新增节点与上一个节点之间的数据不可命中,丢失
虚拟一致性哈希分区
对于前面的方案,节点数越少,越容易出现节点在哈希环上的分布不均匀,导致各节点映射的对象数量严重不均衡(数据倾斜);相反,节点数越多越密集,数据在哈希环上的分布就越均匀。
但实际部署的物理节点有限,我们可以用有限的物理节点,虚拟出足够多的虚拟节点(Virtual Node),最终达到数据在哈希环上均匀分布的效果,如下图,实际只部署了3个节点Redis0、Redis1、Redis2,把每个节点都复制成2倍,结果看上去是部署了6个节点。
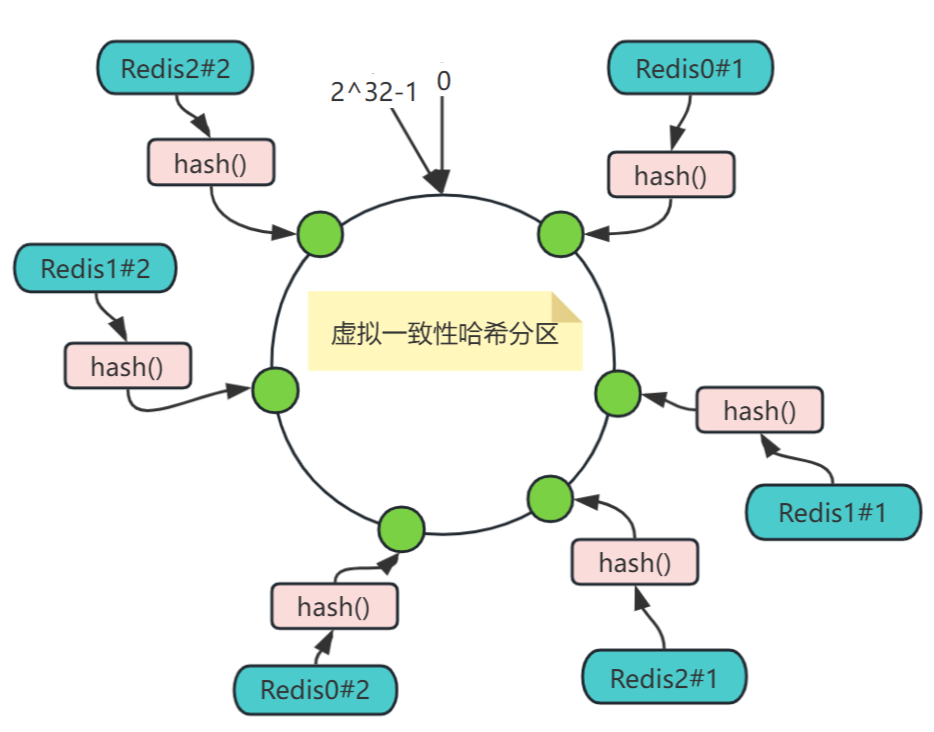
虚拟一致性哈希分区增加一个节点:
可以想象,当虚拟节点个数达到2^32时,就达到绝对的均匀,通常可取复制倍数为32或更高。
优点:
- 负载均衡优化:虚拟节点分散物理节点压力,减少数据倾斜。
- 异构节点适配:根据节点性能差异分配不同数量的虚拟节点。
缺点:
- 管理复杂度高:需维护虚拟节点与物理节点的映射关系。
- 迁移成本上升:节点变动需调整多个虚拟节点,操作复杂。
虚拟槽分区(Redis Cluster方案)
虚拟槽分区(Virtual Slot Partitioning)是Redis Cluster设计的核心分片机制,旨在解决分布式系统中数据分片、负载均衡和高可用性问题。其核心思想是将整个数据空间划分为固定数量的逻辑槽(Slot),通过动态分配槽到物理节点的方式实现数据分布。
虚拟槽分区是对一致性哈希分区进行的改造,虚拟槽中的槽就是大量的虚拟节点的抽象化,将原来的虚拟节点变成一个槽,槽的范围是0~16383,redis内置是有16384个槽也就是有16384个虚拟节点。
虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有数据映射到一个固定范围的整数集合中,这个整数定义为槽(slot),这个范围一般远远大于节点数。
假设当前集群有3个节点,每个节点平均大约负责5461个槽,所有的键根据哈希函数映射到0~16383整数槽内,计算公式:slot = CRC16(key)& 16383。每一个节点负责维护一部分槽以及槽所映射的键值数据,如下图所示:
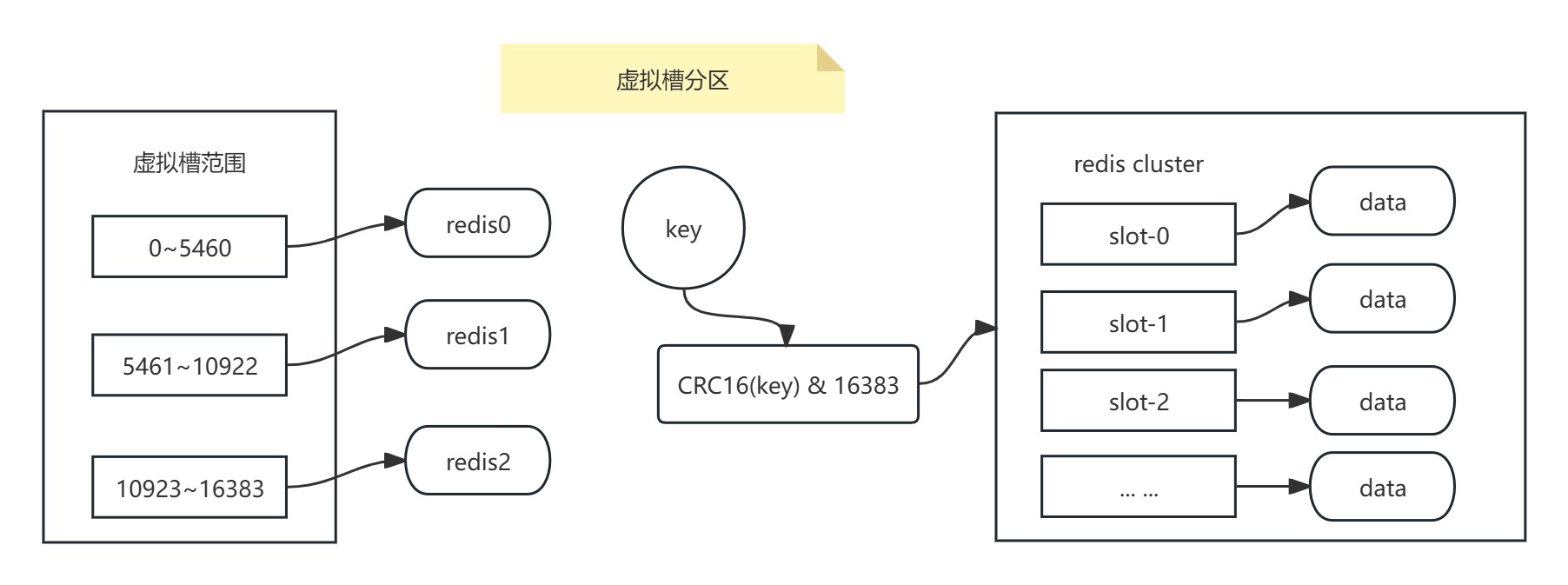
slot = CRC16(key)& 16383其实就是slot = CRC16(key)% 16384,一个数跟2^N取模的结果等于它与2^N-1按位与的结果。
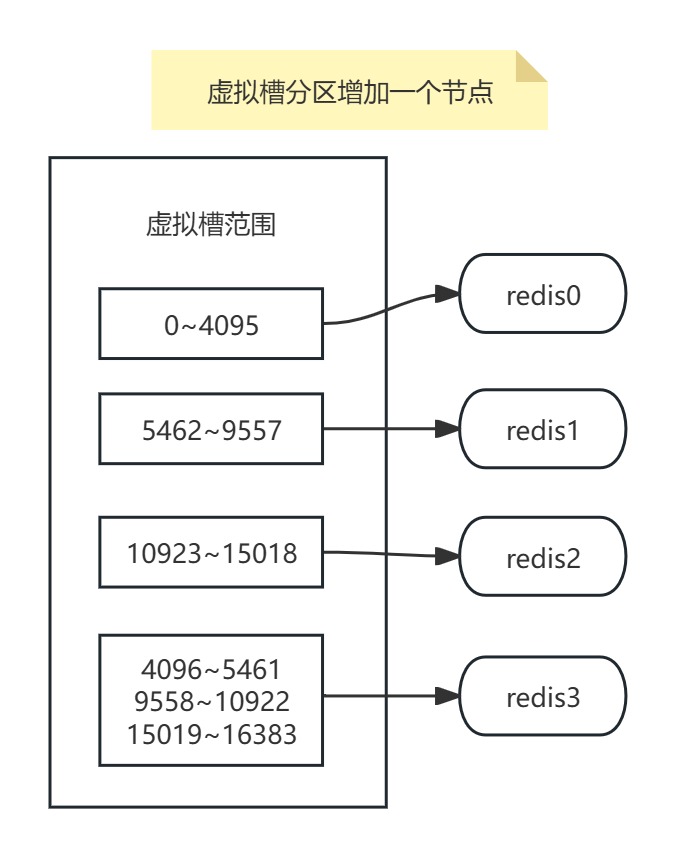
在虚拟槽分区中扩展一个节点(扩容)时,需通过槽迁移将部分槽从现有节点转移到新节点,实现数据重新分布和负载均衡。
优点:
- 动态扩缩容平滑:仅迁移受影响槽的数据,迁移量可控(如删除节点时仅重分配其槽)。当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了,当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了。
- 解耦数据与节点之间的直接关系:槽作为中间层,支持灵活调整节点与槽的映射关系。一致性hash分片需要映射key和节点的关系, 但是使用hash槽计算方式是
CRC16(key) % 槽的个数, 所以就解耦了数据和节点的关系 - 节点自身维护槽的映射关系, 不需要客户端和代理服务器进行维护处理
缺点:
- 实现复杂:需集群协议维护槽与节点状态,客户端需支持重定向逻辑。
- 功能限制:跨槽事务、多键操作受限。






![57.[前端开发-前端工程化]Day04-webpack插件模式-搭建本地服务器](https://i-blog.csdnimg.cn/direct/65a5bbd2e84a449c810dba872b13e55a.png)