一、 背景描述
在跨国性企业日常经营过程中,经常会遇到专业性较强的文档翻译的需求,例如法律文书、商务合同、技术文档等;以往遇到此类场景,企业内部往往需要指派专人投入数小时甚至数天来整理和翻译,效率低下,严重影响了企业日常经营和生产。如何利用自动化工具来自动化批量处理专业文档翻译的工作,使员工更加专注于业务创新,成为摆在企业面前的重要课题。
随着机器学习和大语言模型等技术的飞速发展,专业文档翻译的自动化成为了可能。客户希望构建一个地理领域专业文档的翻译方案,使其通过大语言模型进行翻译,并且提出如下几点要求:
-
自动识别文档的语言种类,自动进行中翻英或者英翻中;
-
翻译后的文档尽可能地保留 Microsoft Office Word 文档中的格式;
-
尽可能地使用地理专业领域的术语,支持客户的术语表并可以用简单的方式扩展;
-
避免中式英语,符合英文的语序和表达习惯。
二、 方案概述
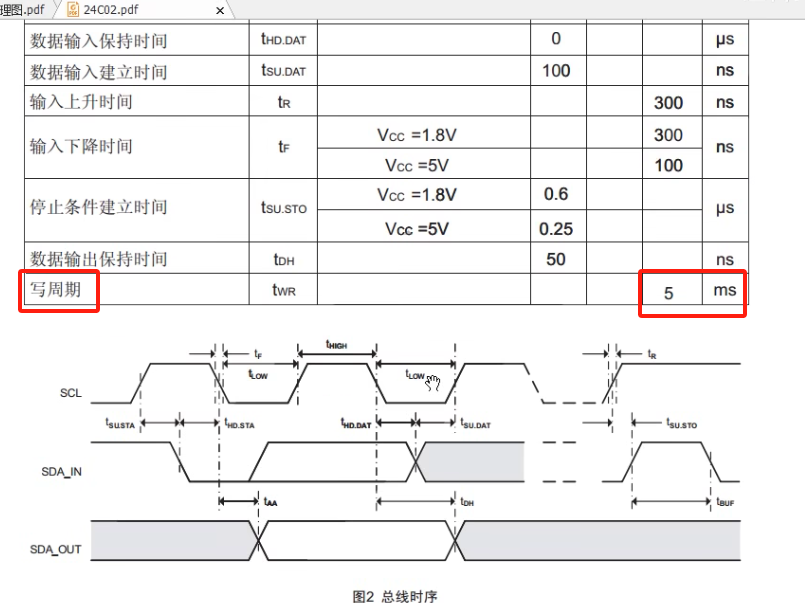
根据客户需求,我们进行了方案的概念模型设计:
方案执行的流程如下:
-
用户上传中文/英文文档到“输入文档存储”;
-
上传完成的动作,触发文档翻译的处理作业,该作业会调用大语言模型;
-
翻译作业完成后,生成对应的英文/中文文档,结果保存到“输出文档存储”。
基于以上概念模型和流程设计,我们形成了如下的方案组件选型:
-
文档存储,包括原始输入文档存储和翻译后的输出文档存储,我们选用 Amazon S3,因为该服务支持事件通知,可以触发无服务器资源例如 Amazon Lambda 进行处理;
-
文档处理,也就是具体的文档翻译作业,我们选择使用 Lambda,并在代码中调用 Amazon Bedrock 上的大模型来实现;
-
日志记录,开启 Amazon CloudWatch Logs 记录 Lambda 执行过程,方便故障排查和代码调试。
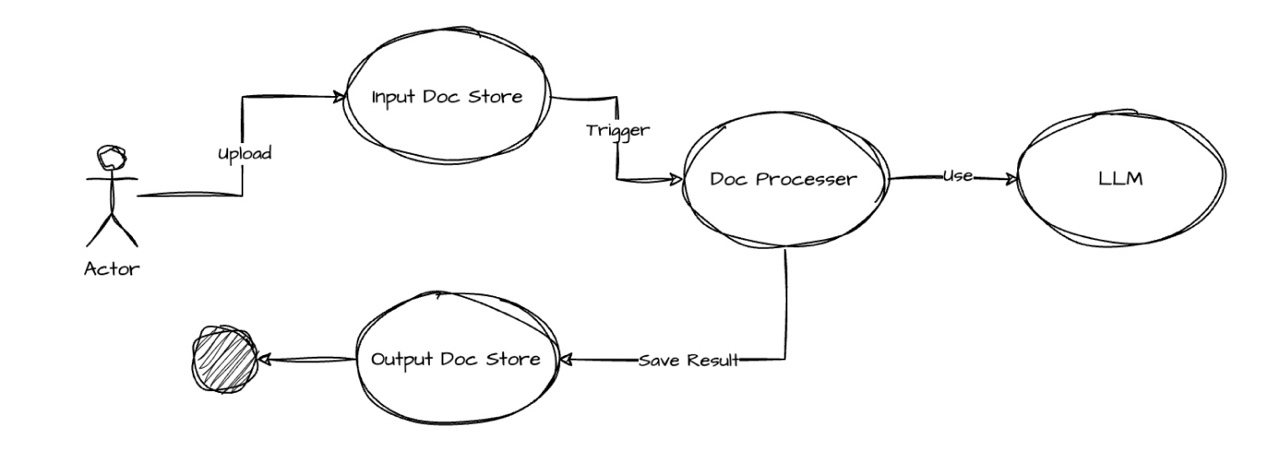
方案部署架构设计如下:
具体执行过程如下:
-
用户通过亚马逊云科技控制台上传原始文档到 Amazon S3 Input 存储桶;
-
S3 对象上传成功的通知,触发 Amazon Lambda 调用 Amazon Bedrock 上的大模型执行文档翻译;
-
Lambda 执行完成后,翻译后的文档自动保存到 S3 Output 存储桶;
用户可以在 Amazon CloudWatch Logs 中查看 Lambda 执行记录。
三、 核心代码实现
-
语种检测
本方案使用 Amazon Bedrock 上的大模型对用户上传的文档,实现了自动化识别其语种是英语还是中文,如果是中文自动翻译成英文,如果是英文则翻译成中文。以下是语种检测部分的代码:
def language_detector(query):
print("debug")
model_id = '<you-model-id>'
print(<you-model-id>')
response = bedrock.invoke_model(body=_get_complete_lang_detect_prompt(query), modelId=model_id)
print('<< call <you-model-id>')
response_body = json.loads(response.get('body').read())
print(response_body)
match = re.search(r'<lang>([\s\S]*?)</lang>', response_body['content'][0]['text'])
print(f"response_body:{ response_body['content'][0]['text']}")
if match:
final_response = match.group(1)
print(f"> in: {query}")
print(f"> Language detected: {final_response}")
return final_response
else:
# print(f"> in: {query}")
print(f"< out: BR ERROR in language detect!!!")
另外,在调用 Amazon Bedrock 上的大模型时,需要按照其格式提供提示词模版,语种检测提示词模板部分的代码如下:
def _get_complete_lang_detect_prompt(query, domain='None'):
system_prompt = f"""You need to detect the language in the given text.
If the text contains characters from different languages, then you should respond the major ONE language that is used.
Your output will be processed by a program so no explaintaion is needed.
NOTE: You are detecting the language in the given text, not the topic it is telling about.
<text> + {query} + </text>
The result should be in the tag of <lang></lang>. No explanation is needed. <lang>Respond only within these tags and do not provide any additional text outside the tags.</lang>. E.G. <lang>English</lang> or <lang>Chinese</lang>."""
user_message = {"role": "user", "content": query}
messages = [user_message]
return json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 80960,
"system": system_prompt,
"messages": messages
})
-
文档翻译
本方案中文档翻译使用了 Amazon Bedrock 上的大模型,核心代码如下:
def agent_bedrock(query, to_language, domain="None"):
model_id = <you-model-id>'
response = bedrock.invoke_model(body=_get_complete_prompt(query, to_language, domain), modelId=model_id)
response_body = json.loads(response.get('body').read())
match = re.search(r'<TRANSLATED>([\s\S]*?)</TRANSLATED>', response_body['content'][0]['text'])
if match:
final_response = match.group(1)
# print(f"> in: {query}")
# print(f"< out: {final_response}")
return final_response
else:
# print(f"> in: {query}")
print(f"< out: BR ERROR!!!")
return query
文档翻译对应的提示词如下:
def _get_complete_prompt(query, to_language='English', domain='None'):
system_prompt = f"""
You are a helpful and honest AI assistant, now I want you to
help in translation for the give text.
you will translate the given text to its {to_language} version.
The following are the rules to follow during the translation.
* The input will be in <TO_TRANSLATE> tag. they can be words, numbers, or single character,
Sometimes they are already in the target language, then only respond the original text into the <TRANSLATED> tag.
* it is OK if you don't very confident to translate,
in such cases, you can give the best translate you can, because we will have human review later on.
* Your output will be put to <TRANSLATED></TRANSLATED> tag.
* So, in summary, <TRANSLATED> tag should contain translated or original text,
<error> tag should contain the reason why you cannot translate.
* The given content is in the {domain} domain, so you should use the professional terms if applicable.
* If it is the Chinese-to-English translation, please be aware that the order of terms may very different between the two language. Use the order of English
to make it flow better.
* the following is the terms for you to follow up: {_geo_terms}
"""
user_message = {"role": "user", "content": "<TO_TRANSLATE>" + query + "</TO_TRANSLATE>"}
messages = [user_message]
return json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 80960,
"system": system_prompt,
"messages": messages
})
-
文档解析
由于客户提供的输入文档限定为 Microsoft Office Word 格式,因此本方案采用 Python 中的 docx 库进行 Word 文档解析,代码参考如下:
import docx
def parse_doc_and_translate(input_file_name, output_file_name):
"""
Parse the document and translate the text
"""
doc = docx.Document(input_file_name)
texts = []
-
专业术语翻译
地理领域的专业术语,放在文本文件中(命名为 terms.txt),上传到 Amazon S3 存储桶;在翻译的时候会先行从 S3 上读取专有词汇表,并自动将专有名词注入到提示词中。专有名词的格式如下:
Airy Hypothesis 艾里假说;
alias 假频;
amplitude spectrum 振幅谱;
antiroots 反山根;
Bouguer anomaly 布格异常;
Bouguer correction 布格改正;
continuation 延拓;
density 密度;
如果有新的专有词汇需要加入,只需要更新 S3 上的词汇表即可自动生效。在调用 Amazon Bedrock 上的大模型进行翻译时,提示词要求按照该术语表翻译,这部分核心代码如下:
import os
import boto3
s3 = boto3.client('s3')
S3_BUCKET = os.environ.get('APP_BUCKET_NAME', 'aaa-demo')
S3_TERMS_FILE = os.environ.get('S3_TERMS_FILE', 'terms.txt')
def geo_terms():
# Download the object content to a variable
response = s3.get_object(Bucket=S3_BUCKET, Key=S3_TERMS_FILE)
file_content = response['Body'].read().decode('utf-8')
return file_content
if __name__ == '__main__':
print(geo_terms())
# Amazon Bedrock 上的大模型的提示词中引用该术语表
def _get_complete_prompt(query, to_language='English', domain='None'):
system_prompt = f"""
…
* the following is the terms for you to follow up: {_geo_terms}
"""
-
并发配置和异常处理
本方案 Lambda 的并发配置如下:
CONCURRENT_FOR_BEDROCK_INVOCATION = os.environ.get(
'CONCURRENT_FOR_BEDROCK_INVOCATION', '3')
如果同时上传多个文件,每个 Doc 会相应地启动一个 Lambda 实例来进行翻译工作;在执行翻译的时候,文档会被拆分成段落,并对每个段落进行翻译。一个文档可能会被拆分成 200~400 个片段,为了加快翻译速度,我们加入了并发执行的逻辑,并发数由上面的“CONCURRENT_FOR_BEDROCK_INVOCATION”来控制。设置该参数时需要考虑亚马逊云科技账号中 Bedrock 上的大模型的最大并发数(一般是每分钟 200 次),同时需要考虑并发的文档数量。
四、总结与展望
本次我们采用亚马逊云科技原生服务搭建了一套地理领域专业文档翻译的解决方案,该方案核心处理逻辑采用了亚马逊云科技无服务器化服务 Amazon Lambda,翻译处理完全基于事件触发,对于用户来说大幅降低使用成本,同时运维负担小,用户体验友好。但客户也提出了一些改进意见,例如希望提供独立于亚马逊云科技 Console 的 Web 页面、对用户进行权限划分、专业术语表用户可自行添加、翻译任务状态展示等,后续我们将联合合作伙伴,对这些工程化和定制化功能继续深入合作。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。
本篇作者
本期最新实验《多模一站通 —— Amazon Bedrock 上的基础模型初体验》
✨ 精心设计,旨在引导您深入探索Amazon Bedrock的模型选择与调用、模型自动化评估以及安全围栏(Guardrail)等重要功能。无需管理基础设施,利用亚马逊技术与生态,快速集成与部署生成式AI模型能力。
⏩️[点击进入实验] 即刻开启 AI 开发之旅
构建无限, 探索启程!