论文介绍
题目:SGFormer: Satellite-Ground Fusion for 3D Semantic Scene Completion
会议:IEEE / CVF Computer Vision and Pattern Recognition Conference
论文:https://www.arxiv.org/abs/2503.16825
代码:https://github.com/gxytcrc/SGFormer
年份:2025
单位:浙江大学,香港中文大学
SGFormer:卫星-地面融合 3D 语义场景补全
郭溪月 1 ∗ 胡佳瑞 胡 1∗ 胡俊杰 胡 2 包胡军 1† 中国科学院计算机技术研究所 1 浙江大学 2 香港中文大学

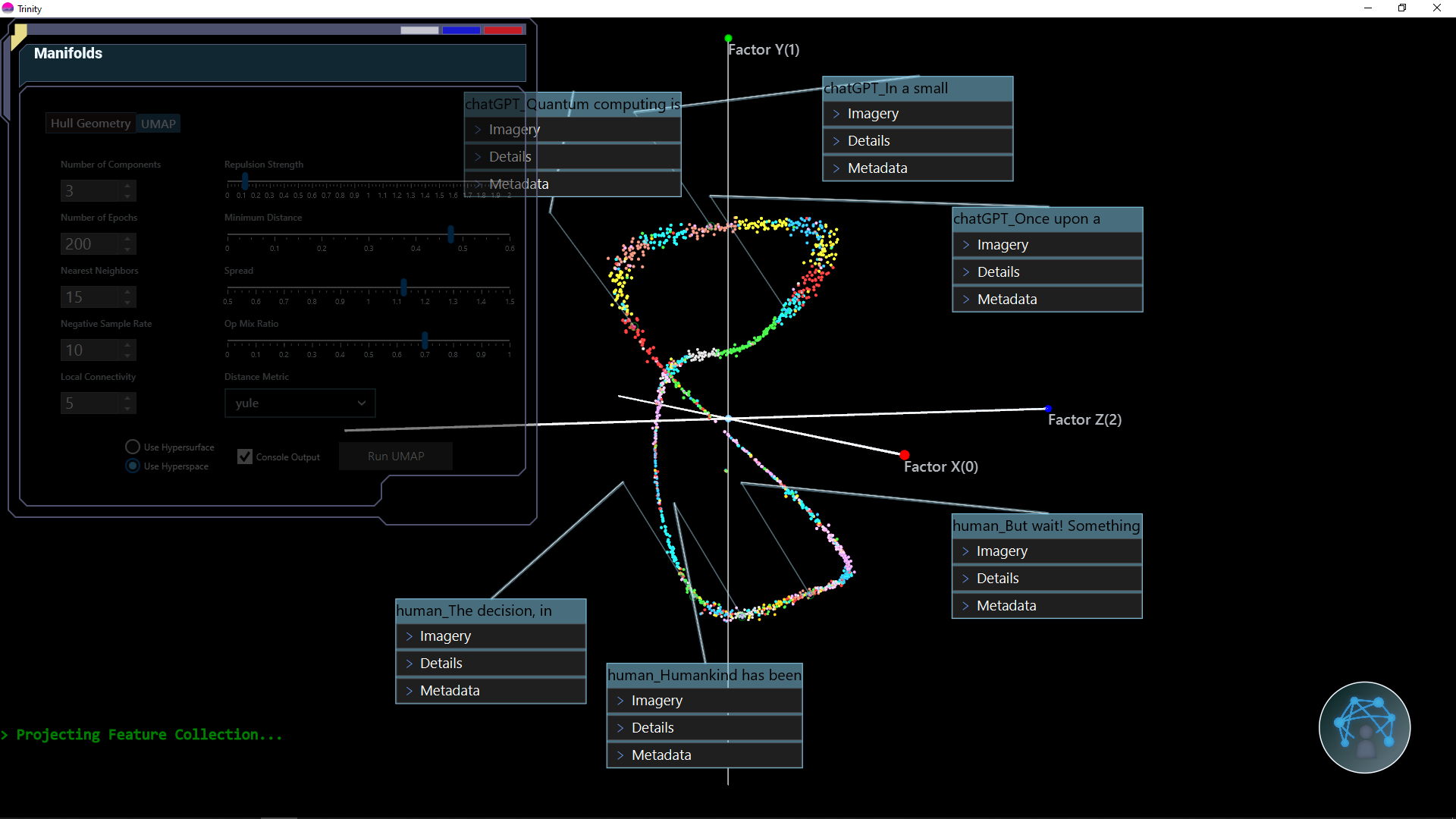
图 1. SGFormer 采用卫星-地面协同融合,在场景补全和语义预测方面可以达到最先进的性能。得益于信息丰富的卫星图像和精心设计的双分支管道,SGFormer 可以有效提高语义预测精度,并解决纯地面方法长期遭受的视觉遮挡瓶颈问题。
摘要
最近,基于摄像头的解决方案在场景语义补全(SSC)方面得到了广泛探索。尽管它们在可见区域取得了成功,但现有方法由于频繁的视觉遮挡,在捕捉完整场景语义方面存在困难。为了解决这一局限性,本文提出了第一个卫星-地面协同 SSC 框架,即 SGFormer,探索卫星-地面图像对在 SSC 任务中的潜力。具体来说,我们提出了一种双分支架构,并行编码正交的卫星和地面视图,并将它们统一到公共域中。此外,我们设计了一种地面视图引导策略,在特征编码期间纠正卫星图像偏差,解决卫星和地面视图之间的错位。此外,我们还开发了一种自适应加权策略,平衡卫星和地面视图的贡献。实验表明,SGFormer 在 SemanticKITTI 和 SSCBench-KITTI-360 数据集上优于现有技术。我们的代码可在 https://github.com/gxytcrc/SGFormer 上找到。
1. 引言
城市场景语义补全(SSC)在过去的几十年里已成为 3D 计算机视觉中越来越突出的问题,它旨在预测立即观察到的周围环境的 3D 语义和几何占用,具有自动驾驶、机器人导航和增强现实(AR)等多种下游应用。基于激光雷达的方法取得了显著的进步和良好的性能[26, 31, 38],而其背后的点云表示本质上却因仅从几何形状中提取的弱语义上下文而受到限制。相比之下,成本效益高的基于摄像头的方 法可以将丰富的 2D 线索提升到 3D 世界,显示出在场景重建和理解方面的潜力。
现有基于摄像头的方 法在 SSC 任务上表现出良好的性能[9, 13, 18, 35, 40]。然而,即使对于可见区域具有深度信息,它们仍然面临着 3D 体积和 2D 像素之间非唯一对应关系的挑战。具体来说,多个 3D 体积对应于 2D 图像平面内显著重叠的区域,这导致最终重建中的语义模糊和径向伪影。对于遮挡区域,这些方法通常缺乏长程全局视角,这使得它们难以恢复完整场景并服务于后续规划和决策步骤。
本文首次提出将卫星图像纳入 3D 语义场景补全任务。随着遥感技术的发展,卫星图像已成为一种低成本且易于获取的参考信息。覆盖城市主要交通流的卫星图像通常需要轻量级的存储占用,这使得它成为一种紧凑且内存高效的表示。同时,鸟瞰视图(BEV)观察非常适合城市场景的水平布局。它提供了对周围明显物体的广泛视角,从而有效地增强了语义确定性。这两个正交视图,即卫星视图和地面视图,可以最优地互相补偿盲区,为之前的遮挡瓶颈问题提供理想的解决方案。
然而,将卫星图像纳入 SSC 任务中存在两个困难。第一个是错位问题。局部卫星图像被捕获为一个固定大小的 2D 段,以特定位置为中心。卫星图像中由于噪声定位和自上而下的遮挡引起的不可预测偏差是这一问题的根本原因。错位的卫星特征往往会导致融合中的特征级别不一致,并对收敛效率产生负面影响。其次,卫星图像通常是预先捕获的,主要关注场景布局,不可避免地丢弃了细节和长期变化,如交通标志和临时停放的车辆,从而降低了在低占用但重要区域中的 SSC 性能。
为了解决上述挑战,我们提出了 SGFormer,一个紧密耦合的卫星辅助框架,用于 SSC 任务。为了执行卫星-地面跨视图融合,SGFormer 创新性地提出了一种定制双分支框架,以同步编码地面和卫星图像,并在统一特征域内对齐它们。为了克服错位问题,我们设计了一种针对垂直压缩地面视图特征的特征级卫星校正策略。具体来说,我们初始化可学习的 BEV 参数,并在可变形自注意力层中迭代查询压缩地面视图特征,其中地面视图引导在提前预热 BEV 查询以实现协调融合方面起着至关重要的作用。此外,我们提出了一种具有双路径权重生成器的自适应融合模块,以在两个正交视图之间实现合理的权衡。在此模块中,卫星-地面特征被解码为每个体素中两个视图的通道权重向量。此模块允许我们的融合流程处理时间更新和不同大小的物体。
我们在两个基准语义数据集上评估了我们的方法,包括 SemanticKITTI [1] 和 SSCBench-KITTI-360 [17]。大量的实验结果表明,我们的 SGFormer 在场景补全和语义预测方面优于先前的方法,如图 1 所示。总的来说,我们的贡献可以总结如下:
• 我们提出了第一个与卫星辅助的 SSC 框架紧密耦合,具有针对卫星观测的双分支设计。
• 我们提出了一种基于可变形自注意力的特征级卫星校正策略,以解决卫星和地面视图之间的不匹配问题。
• 我们开发了一种自适应加权策略,以平衡卫星和地面视图的贡献,从而实现有效感知动态更新和不同尺寸的对象。
实验表明,与基线方法相比,我们的方法在各种数据集上可以实现更好的场景语义补全结果。

图 2. SGFormer 概述。总体而言,SGFormer 将卫星-地面图像对输入到不同分支的相似骨干网络中,分别提取多级特征图(左侧部分)。然后,利用可变形注意力,将卫星和地面特征转换到体积和 BEV 空间(中间部分)以进行后续的特征融合和解码(右侧部分)。具体来说,在地面分支中,我们使用深度估计器生成体素提议,以在非空特征体积上进行目标查询。在卫星分支中,将垂直压缩的地面视图特征融合到 BEV 查询中,以预热卫星特征(红线)。在最终融合之前,来自两个分支的编码特征通过 2D/3D 卷积网络进行增强。我们提出的融合模块,如图 3 所示,能够自适应地融合卫星和地面特征,随后通过 seg 头输出语义重建结果。
2. 相关工作
2.1. 3D 语义场景补全
3D 语义场景补全(SSC)最早由 SSCNet[31]提出,旨在预测 3D 空间中每个体素的占用和语义信息[5, 26, 37, 38]。后续方法可以分为两类:一类依赖于深度传感器,如激光雷达,直接计算空间特征以估计 3D 语义,另一类基于相机,涉及将图像特征提升到 3D 空间后再估计语义信息。早期方法主要关注第一类,而近年来,基于相机的解决方案因其高性价比而受到越来越多的关注[3, 13, 18, 35]。
MonoScene[3]提出了第一个纯视觉解决方案,利用由视场投影模块连接的 2D 和 3D U-Nets。OccFormer[41]遵循 LSS[25]的策略,估计图像的深度分布,然后通过深度引导将特征投影到 3D 空间。
一些工作受到 BEVFormer [19]的启发,该工作利用 Transformer 框架来估计占用情况。这些方法使用从 3D 到 2D 的空间关系,通过空间可变形注意力[43]查询图像特征中的信息。其中,TPVFormer [13]提出了三视角视图表示。它首先获取这些平面的特征,并相应地将其恢复到 3D。SurrunodOcc [35]引入了粗到细的策略,在多个尺度上生成 3D 特征,并逐步整合占用网格预测。这些基于 Transformer 的方法在 3D 语义预测的性能上取得了显著进展。然而,由于 3D-2D 投影关系的非一对一性质和缺乏几何约束,这些方法在准确重建 3D 场景的语义分布方面存在困难。
为了解决这个问题,一些工作利用深度输入并尝试将几何先验纳入占用预测中。OccDepth [23] 通过立体深度投影图像特征。Voxformer [18] 从预训练的深度初始化稀疏提议。后续研究 [15, 33, 34] 通过整合深度信息进一步改进了这一点,从而提高了 SSC 的性能。然而,由于地面相机观测范围限制和遮挡固有的问题,预测语义模糊性和几何分布错误几乎是不可避免的。
2.2. 卫星辅助感知
最近,将卫星图像与地面图像集成已受到越来越多的关注。这主要归因于卫星图像的低经济和存储成本,以及它们所包含的丰富信息。
大多数这些工作主要关注定位问题,旨在通过匹配地面和卫星图像来估计地面车辆在真实世界坐标系中的位置。一些方法将卫星地图划分为许多小块,旨在通过图像检索方法找到与地面图像最相似的块 [2, 4, 12, 21]。其他方法尝试将卫星和地面特征整合到公共坐标系中,以实现更高的定位精度,例如应用单应性将卫星特征投影到地面视图中,然后确定精确的定位结果 [30] 或将地面图像投影到鸟瞰图(BEV)中,并与卫星特征对齐 [6, 8, 27]。在此基础上,一些工作尝试将此类跨视图定位的结果纳入传统的 SLAM 系统中,以增强 SLAM 的定位性能 [8, 24, 42]。
除了本地化工作之外,一些研究将卫星图像纳入了地图构建任务中。SG-BEV [39] 首次将地面和卫星特征结合起来,完成精细的建筑物属性分割任务,而 SNAP [28] 则将卫星图像纳入了二维神经地图的构建中。
在此背景下,我们的方法首次将卫星图像引入到 SSC 任务中,探索了卫星和地面感知协作的潜力。
3. 方法
3.1. 概述
我们提出的 SGFormer 框架如图 2 所示。我们的工作将地面和卫星图像作为输入,通过两个独立的分支进行处理:地面分支和卫星分支。每个分支包括两步操作,第一步是从地面和卫星图像中提取特征以生成多尺度特征,第二步是将特征转换为体素或 BEV 空间,然后进行特征扩散和增强。随后,通过融合模块将体素和 BEV 特征进行融合。
在 SGFormer 中,我们做出了以下主要技术贡献:1)卫星视图特征校正:卫星校正方法采用地面分支的压缩特征来引导和校正卫星分支的特征学习(详见第 3.3.2 节)。2)自适应融合:自适应融合模块通过注意力机制将卫星分支的 BEV 特征与地面分支的体素特征融合。融合两个分支的特征后,我们进一步细化它们,并将输出传递到分割头,该分割头对这些特征进行上采样,并产生体素级的类别预测(详见第 3.4 节)。
3.2. 特征提取。
地面分支的特征提取旨在从地面图像中提取 2D 特征 F g 2 D ∈ R H g ′ × W g ′ × D \mathbf{F}_{g}^{2D}\in\mathbb{R}^{H_{g}^{\prime}\times W_{g}^{\prime}\times D} Fg2D∈RHg′×Wg′×D ,其中 H g ′ × W g ′ H_{g}^{\prime}\times W_{g}^{\prime} Hg′×Wg′ 代表特征分辨率, D 是特征维度。同样,在卫星分支中,我们获得 2D 卫星特征 F s 2 D ~ ∈ R H s ′ × W s ′ × D \mathbf{F}_{s}^{\tilde{2D}}\in\mathbb{R}^{H_{s}^{\prime}\times W_{s}^{\prime}\times D} Fs2D~∈RHs′×Ws′×D 。EfficientNet-B7 [32] 作为地面图像的主干网络,而 ResNet-50 [10] 用于卫星图像,两者之后都跟随特征金字塔网络(FPN)[20]。
深度估计。在将地面视图的特征编码到 3D 空间之前,我们使用深度估计来估计可见体素,采用预训练的 MobileStereoNet 进行深度估计,与 VoxFormer 对齐[cite id=4][18]。然而,与 VoxFormer[cite id=7][18]使用额外的阶段来细化二进制占用不同,我们直接将体素化深度作为我们的查询提议进行特征编码。具体来说,深度点被投影到体素图中,如果占用点的数量超过阈值,则将体素设置为 1;否则,设置为 0。

图 3. 融合模块。我们的融合模块(顶部)主要由两部分组成:权重模块和概率网络。此权重模块(底部左侧)可以促进 BEV 特征 F′sBEV 和体素特征 F′g3D 在二维和三维空间中的相互感知,以产生通道权重向量。此概率网络(底部右侧)以加权平均的 3D 体素特征为输入,推断每个体素的近似占用概率,以实现更好的几何重建。
ResNet-50 [10] 用于卫星图像,采用两种骨干网络,随后接特征金字塔网络 (FPN) [20]。深度估计。在将地面视图特征编码到 3D 空间之前,我们使用深度估计来估计可见体素,采用预训练的 MobileStereoNet [29] 进行深度估计,并与 VoxFormer [18] 对齐。然而,与 VoxFormer [18] 不同,我们不是使用额外的阶段来细化二进制占用,而是直接将体素化深度作为我们的特征编码查询提议。具体来说,深度点被投影到体素图中,如果占用点的数量超过阈值,则体素设置为 1;否则,设置为 0。
3.3. 特征变换
为了高效地将图像特征转换为真实世界坐标,我们使用可变形注意力机制 43,表示为 DA,以聚合目标图像特征 q,如方程所示:
D
A
(
q
,
p
,
v
)
=
∑
k
=
1
K
A
k
W
v
(
p
+
Δ
p
)
,
{\mathrm{DA}}\left(q,p,v\right)=\sum_{k=1}^{K}A_{k}W v\left(p+\Delta p\right),
DA(q,p,v)=k=1∑KAkWv(p+Δp),
其中 p \boldsymbol{\mathrm{p}} p 是参考点, Δ p \Delta p Δp 是可学习的采样偏移量, A k \boldsymbol{A}_{k} Ak 代表注意力权重, W W W 表示投影权重。
3.3.1 地面视图特征变换
在地面分支中,我们使用可学习的嵌入初始化体素查询
Q
v
∈
\mathbf{Q}_{v}\in
Qv∈
R
H
×
W
×
Z
×
D
\mathbb{R}^{H\times W\times Z\times D}
RH×W×Z×D ,其中
H
×
W
×
H\times W\times
H×W×
Z
Z
Z 被视为体素维度。在查询提议的引导下,
我们通过使用可变形交叉注意力从图像特征
F
^
g
2
D
~
\mathbf{\hat{F}}_{g}^{2\tilde{D}}
F^g2D~ 中查询体素特征:
Q p = D A ( Q p , P ( p , g ) , F g 2 D ) , \mathbf{Q}_{p}=\mathrm{DA}\left(\mathbf{Q}_{p},\mathcal{P}(\mathbf{p},g),\mathbf{F}_{g}^{2D}\right), Qp=DA(Qp,P(p,g),Fg2D),
其中 Q p \mathbf{Q}_{p} Qp 由查询提议中的可见体素组成。 P ( p , g ) \mathcal{P}(\mathbf{p},g) P(p,g) 表示由相机投影函数生成的 F g 2 D \mathbf{F}_{g}^{2D} Fg2D 中的对应像素。
经过几层交叉注意力后,我们将查询特征 Q p Q_{p} Qp 与 Q v Q_{v} Qv 中的其他不可见体素合并,以获得体素特征 F g 3 D \mathbf{F}_{g}^{3D} Fg3D ,然后通过可变形子注意力将特征扩散到所有体素,如公式所示:
F g 3 D = D A ( F g 3 D , p v , F g 3 D ) , \mathbf{F}_{g}^{3D}=\mathrm{DA}\left(\mathbf{F}_{g}^{3D},\mathbf{p}_{\mathbf{v}},\mathbf{F}_{g}^{3D}\right), Fg3D=DA(Fg3D,pv,Fg3D),
其中 p v \mathbf{p}_{v} pv 是 3D 空间中的参考点。
3.3.2 卫星视图特征变换
在卫星分支中,我们在地面观测的引导下将卫星特征编码到 BEV 空间。我们首先初始化BEV查询 Q b e v Π ˉ ∈ R H × W × D \mathbf{Q}_{b e v}^{\mathsf{\bar{\Pi}}}\in\mathbb{R}^{H\times W\times D} QbevΠˉ∈RH×W×D . 同时,我们通过最大池化将来自地面分支的体素特征 F g 3 D \mathbf{F}_{g}^{3D} Fg3D 压缩成 BEV 查询 F g B E V \mathbf{F}_{g}^{B E V} FgBEV 同时,我们通过最大池化将来自地面分支的体素特征 Q b e v \mathbf{Q}_{b e v} Qbev 和 F g B E V \mathbf{F}_{g}^{B E V} FgBEV 结合形成混合特征 v h y b r i d v_{h y b r i d} vhybrid , 并将其输入到自注意力模块中:
Q b e v = D A ( Q b e v , p b e v , v h y b r i d ) , \mathbf{Q}_{b e v}=\mathrm{DA}\left(\mathbf{Q}_{b e v},\mathbf{p}_{b e v},v_{h y b r i d}\right), Qbev=DA(Qbev,pbev,vhybrid),
其中, p b e v \mathbf{p_{bev}} pbev 是BEV空间中的参考点。通过子注意力机制,BEV查询从地面视图信息中高效融合。然后将输出查询传递到交叉注意力模块,以查询卫星特征 F s 2 D \mathbf{F}_{s}^{2D} Fs2D 的信息:
Q b e v = DA ( Q b e v , P ( p , s ) , F s 2 D ) , \mathbf{Q}_{b e v}=\operatorname{DA}\left(\mathbf{Q}_{b e v},\mathcal{P}(\mathbf{p},s),\mathbf{F}_{s}^{2D}\right), Qbev=DA(Qbev,P(p,s),Fs2D),
P ( p , s ) \mathcal{P}(\mathbf{p},s) P(p,s) 代表卫星图像中BEV网络的对应像素。在地面视图观测下,偏移层在交叉注意力过程中预测更合适的偏移量。我们多次迭代自注意力和交叉注意力,最终得到BEV特征 F g B E V \mathbf{F}_{g}^{BEV} FgBEV
3.3.3 卷积增强
将特征编码到体素和 BEV 空间后,我们将其输入到卷积层,通过邻域交互进一步增强特征表示。在地面分支中,我们使用 3D-UNet 进行特征聚合,在卫星分支中使用 2D-UNet。
3.4. 特征融合
我们的自适应融合模块如图 3 所示。卫星分支的 BEV 特征 F s ′ B E V \mathbf{F}_{\textit{s}}^{\prime B E V} Fs′BEV 能够覆盖更广的范围,从而更完整地表示场景布局,如道路和建筑物。然而,BEV 特征缺乏占用几何(空或占用)信息,且在小物体上的表现不佳。另一方面,基于地面图像的体素特征 F ′ g 3 D \mathbf{F^{\prime}}_{g}^{3D} F′g3D 在处理小型、动态物体和细节元素以及空间占用方面具有显著优势,但它们包含的有效信息仅限于未被遮挡的视野。因此,在保持每个视图的优点的同时,最大限度地减少其局限性的影响是很重要的。
为了解决这些挑战,我们提出了一种融合模块,该模块可以动态预测特征通道和空间域的权重。具体来说,我们处理来自两个分支的特征:通道注意力网络 [11] 和空间注意力网络,以平衡物体级别和感知域级别的贡献。
在通道注意力路径中,我们首先将 BEV 特征 F ′ s B E V {\mathbf{F}^{\prime}}_{s}^{BEV} F′sBEV 提升到 3D 体积,记为 F ′ s 3 D {\mathbf{F}^{\prime}}_{s}^{3D} F′s3D 。然后,我们将地面和卫星分支的 3D 体积特征连接起来,形成组合特征,并将其传递到通道注意力网络中,从而得到通道域权重 Wc ∈ RD×1×1×1.
在空间注意力路径中,我们将体素特征 F ′ g 3 D {\mathbf{F}^{\prime}}_{g}^{3D} F′g3D沿 z \mathbf{z} z 轴压缩到 BEV 空间,得到 F ′ g B E V {\mathbf{F}^{\prime}}_{g}^{BEV} F′gBEV .与通道注意力路径类似,我们将 BEV 特征连接起来,并将其传递到空间注意力网络中,在 BEV 空间中生成空间域权重 W s ∈ R 1 × H × W \mathbf{W}_{s}\in\mathbb{R}^{1\times H\times W} Ws∈R1×H×W 。将这两个注意力权重相加,然后与额外的 MLP 结果结合,获得融合权重 W a ∈ R D × H × W × Z \mathbf{W}_{a}\in\mathbb{R}^{D\times H\times W\times Z} Wa∈RD×H×W×Z , 如下所示:
W a = M L P ( F ′ c 3 D ) ⊕ C ( F ′ c 3 D ) ⊕ S ( F ′ c B E V ) , \mathbf{W}_{a}=\mathrm{MLP}({\mathbf{F^{\prime}}}_{c}^{3D})\oplus\mathrm{C}({\mathbf{F^{\prime}}}_{c}^{3D})\oplus\mathrm{S}({\mathbf{F^{\prime}}}_{c}^{B E V}), Wa=MLP(F′c3D)⊕C(F′c3D)⊕S(F′cBEV),
其中 C 和 S 分别代表通道和空间注意力网络。
F
′
c
3
D
{\mathbf{F}^{\prime}}_{c}^{3D}
F′c3D 和
F
′
c
B
E
V
{\mathbf{F}^{\prime}}_{c}^{BEV}
F′cBEV 是 3D 和 BEV 空间中的连接特征。
MLP
指的是用于
F
c
′
3
D
\mathbf{F}_{c}^{\prime3D}
Fc′3D 的 MLP 操作。在获得注意力权重后,我们通过以下方程融合两个分支的特征:
F f 3 D = W a ⋅ F ′ g 3 D + ( 1 − W a ) ⋅ F ′ s 3 D , \mathbf{F}_{f}^{3D}=\mathbf{W}_{a}\cdot\mathbf{F^{\prime}}_{g}^{3D}+\left(1-\mathbf{W}_{a}\right)\cdot\mathbf{F^{\prime}}_{s}^{3D}, Ff3D=Wa⋅F′g3D+(1−Wa)⋅F′s3D,
其中 F f 3 D \mathbf{F}_{f}^{3D} Ff3D 是融合的体素特征。
此外,为了最小化空体素带来的负面影响,我们借鉴了 [16] 和 [36] 的方法,应用概率网络和空间注意力来识别有价值的体素。这些有价值的体素将通过网络获得更高的权重,以增强学习效率。
特征细化。 我们在输出最终的体素预测之前进一步细化融合的特征。我们不是使用密集操作来细化所有网格,而是只关注具有高不确定性的网格。因此,我们首先将特征 F f 3 D \mathbf{F}_{f}^{3D} Ff3D 投影到语义类别 L c o a r s e ∈ \mathbf{L}_{c o a r s e}\in Lcoarse∈ R N × H × W × Z \mathbb{R}^{N\times H\times W\times Z} RN×H×W×Z 中,其中 N \mathrm{N} N 是类别数量。然后我们计算每个网格的熵,并选择熵分数最高的前 k 个网格。这些高不确定性的体素通过可变形交叉注意力从地面特征 F g 2 D \mathbf{F}_{g}^{2D} Fg2D 中重新采样特征。然后,细化后的特征被上采样并通过我们的语义头输出。
3.5. 训练损失
在文献[3]和[18]之后,我们使用加权交叉熵损失 L c e \mathcal{L}_{c e} Lce , 训练我们的模型,以及场景类别亲和力损失 L s c a l g e o \mathcal{L}_{s c a l}^{g e o} Lscalgeo 和 L s c a l s e m \mathcal{L}_{s c a l}^{s e m} Lscalsem . 。此外,为了增强监督,我们还额外应用了来自卫星分支的 BEV 损失 L b e v \mathcal{L}_{b e v} Lbev 和来自不确定性细化模块的粗略损失 L c o \mathcal{L}_{c o} Lco 。具体来说, L b e v \mathcal{L}_{b e v} Lbev 是来自卫星分支的 BEV 语义估计 L B E V ∈ R N × H × W \mathbf{L}_{B E V}\in\mathbb{R}^{N\times H\times W} LBEV∈RN×H×W 与压缩后的真实值之间的交叉熵,而 L c o \mathcal{L}_{c o} Lco 是 L c o a r s e \mathbf{L}_{c o a r s e} Lcoarse 与下采样真实值之间的交叉熵。这两个损失分别由比例因子 λ b e v \lambda_{b e v} λbev 和 λ c o \lambda_{c o} λco 加权。总损失函数可以表示如下:
L = L s c a l g e o + L s c a l s e m + L c e + λ b e v L b e v + λ c o L c o , \mathcal{L}=\mathcal{L}_{s c a l}^{g e o}+\mathcal{L}_{\mathrm{scal}}^{s e m}+\mathcal{L}_{c e}+\lambda_{b e v}\mathcal{L}_{b e v}+\lambda_{c o}\mathcal{L}_{c o}, L=Lscalgeo+Lscalsem+Lce+λbevLbev+λcoLco,
其中尺度因子 L b e v L_{b e v} Lbev 和 λ c o \lambda_{c o} λco 分别设置为 1 和 0.25。此外,我们采用类权重参考 [18] .
4. 实验
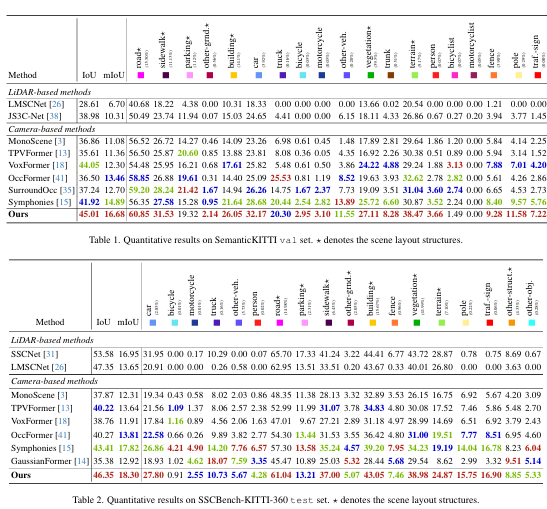
为了公平地评估 SGFormer 的性能,我们在 SemanticKITTI [1] 和 SSCBench-KITTI-360 [17] 数据集上进行了实验。在第 4.3 节中,我们将我们的方法与现有方法在两个数据集上进行了比较。我们用红色、绿色和蓝色标记了基于摄像头的三种最佳结果。在第 4.4 节中,我们展示了消融研究,以证明每个模块和选择的有效性。最后,在第 4.5 节中,我们展示了我们的可视化结果。
4.1. 数据集
语义 KITTI 数据集包含 22 个序列。其中,11 个序列用于训练,1 个序列用于验证,10 个序列用于测试。它提供了形状为 1226×370的地面图像。同时,相应的卫星图像数据由[cite id=0][30] 提供。每个卫星图像的大小为 512×512,像素分辨率为 0.2 米。在本文中,由于缺乏 GPS 信息,我们仅使用 10 个序列来训练模型(不包括序列 03)并在验证集上评估性能。SSCBench-KITTI-360 数据集包含 9 个序列,其中 7 个序列用于训练,1 个序列用于验证,1 个序列用于测试。地面图像的输入大小为 1480×376。由于数据集不包含卫星数据,我们使用提供的地面真值位姿从 Google Maps 获取相应的卫星图像 7。卫星图像设置与 SemanticKITTI 中使用的设置一致。SemanticKITTI 和 SSCBench-KITTI-360 数据集都提供了带有标签的体素化点云作为地面真值,测量 3D 体积的范围为 51.2m×51.2m×6.4m 。体素网格的维度为 256×256×32,使每个网格单元为 0.2 米立方。在我们的评估中,我们报告了用于几何性能的交并比(IoU)和用于语义性能的平均交并比(mIoU)指标,与主流工作保持一致。
4.2. 实现细节
我们在 3 个 NVIDIA 3090 GPU 上对 SGFormer 进行 25 个 epoch 的训练,批大小为 3。我们使用 AdamW 优化器[22],初始学习率为 4e-4,权重衰减为 0.01。我们采用余弦学习率策略在训练过程中降低学习率。此外,特征维度设置为 128,每个批次大约消耗 20GB 的 GPU 内存。
4.3. 主要结果
我们在 3 块 NVIDIA 3090 GPU 上训练 SGFormer 25 个 epoch,批大小为 3。我们使用 AdamW 优化器 [22],初始学习率为 4e-4,权重衰减为 0.01。我们采用余弦学习率策略在训练过程中降低学习率。此外,特征维度设置为 128,每个批次大约消耗 20GB 的 GPU 内存。


4.4 消融研究
在本节中,我们在 SemanticKITTI 数据集上进行了消融实验,主要分析我们核心设计的效果以及定位噪声的影响。除了 IoU 和 mIoU 之外,我们还报告了不同语义类别的平均预测精度(mIoU)以进行进一步分析。具体来说,我们将那些场景布局结构设置为“全局”类别,而将其他动态、小型物体视为“细节”类别,报告了细节估计的性能。

图 4:语义 KITTI 场景语义补全 [1]。左侧:我们展示了卫星-地面图像对,并用黄色箭头指示车辆的行驶方向。右侧:我们定性地比较了 SGFormer 和其他基线方法的场景语义补全结果,其中 SGFormer 可以基于卫星-地面融合产生更完整和准确的语义重建。
4.4.1 核心设计的效果
表格 3 展示了三个核心设计的消融实验:卫星分支(表格中的 sat.-branch.)、卫星校正策略(表格中的 sat.-corr.)和自适应融合模块(表格中的 fusion)。将单一的地面分支方法设置为基线。
卫星分支。 如图所示,添加带有卫星输入的新分支可以提高整体性能。然而,在两个类别中,这种改进都很小,并且会导致 IoU 性能下降。这些观察结果表明两个关键点。首先,添加卫星观测数据确实增强了场景分布的预测,但定位错误和垂直遮挡等对齐问题可能会限制这种改进。其次,卫星图像中缺乏对动态对象、小对象和占用信息的观测,导致对“详细”对象的预测以及几何预测产生负面影响。
卫星校正策略。 如表所示,采用我们的卫星校正策略可以显著提高“全局”类别场景布局结构的预测精度,从 26.54 提升到 28.43。这种改进表明我们的卫星校正策略可以解决对齐问题。地面观测视图有助于卫星分支完成场景布局。
自适应融合模块。 消融实验也表明,使用我们的自适应融合模块可以显著提高小型和动态对象的精度。如表所示,融合模块使得“细节”类别的 mIoU 从 8.26 提升到 9.01。此外,添加融合模块还将导致 IoU 的提升。
注意到,将这些组件结合起来,如表格最后一行所示,将带来显著的性能提升。
4.4.2 定位噪声的影响
我们进行实验以探索定位噪声的影响,如表 4 所示。我们在经纬度方向上添加了±5 米的随机噪声,以对齐现实世界中的可能定位误差。总体而言,我们的方法对定位噪声敏感:添加 5 米噪声导致 SGFormer 在有和没有卫星校正策略的情况下,mIoU 分别下降了 4.3%和 4.5%。我们的卫星校正确实减少了定位噪声带来的负面影响,这在场景布局性能上尤为明显。没有卫星校正,"全局"类别的 mIoU 降至 26.08,甚至低于表 3 中的基线值,这表明卫星观测几乎不再提供积极的影响。然而,当使用我们的校正策略时,场景布局预测的性能下降得到了显著缓解。
4.5 定性比较
图 4 展示了我们的 SGFormer 与两种基线方法 VoxFormer [18] 和 Symphonies [15] 在 SemanticKITTI 上的定性比较。如图所示,我们方法预测的结果显著优于其他两种方法。总体而言,我们的输出显示了更准确的场景布局,尤其是在像十字路口这样的复杂场景中。其他两种方法在完全重建这些复杂场景方面存在困难,而我们的方法有效地处理了这种情况。在细节方面,VoxFormer 生成的场景存在径向伪影,而 Symphonies 在这方面表现略好,但由于遮挡仍然存在许多杂乱区域。我们的重建结果不仅避免了这些问题,而且产生了不同语义之间的更清晰的边界。这些比较证明了我们的方法在全局和局部尺度上的优越性。
5. 结论
本文介绍了 SGFormer,这是第一个采用紧密耦合的双分支框架设计的卫星-地面协同方法,用于城市语义场景补全。SGFormer 有效地融合了地面视图和卫星视图图像的观测结果,使得在占用网格预测中能够同时考虑全局场景布局和局部细节。实验结果表明,我们的方法在许多指标上超过了最先进的基于摄像头的方案,并在性能上与基于激光雷达的方法相当。这些发现表明,将卫星图像集成到 SSC 任务中提供了一种既经济高效又极具前景的解决方案。我们希望我们的工作能够激发该领域进一步的研究。
Acknowledgment
本工作部分得到中国国家自然科学基金委(项目号:62425209)的支持。作者胡俊杰感谢广东省自然科学基金(项目号:2024A1515010252)的资助。作者们感谢刘尚提供本文使用的图表。同时,也特别感谢文博、余兴元、张汉和左然对他们的宝贵支持。
参考文献
[1] Jens Behley, Martin Garbade, Andres Milioto, Jan Quenzel, Sven Behnke, Cyrill Stachniss, and Jurgen Gall. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9297–9307, 2019. 2, 5, 8
[2] Sudong Cai, Yulan Guo, Salman Khan, Jiwei Hu, and Gongjian Wen. Ground-to-aerial image geo-localization with a hard exemplar reweighting triplet loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8391–8400, 2019. 3
[3] Anh-Quan Cao and Raoul De Charette. Monoscene: Monocular 3d semantic scene completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3991–4001, 2022. 2, 5, 6
[4] Yue Cao, Mingsheng Long, Jianmin Wang, and Shichen Liu. Deep visual-semantic quantization for efficient image retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1328–1337, 2017. 3
[5] Ran Cheng, Christopher Agia, Yuan Ren, Xinhai Li, and Liu Bingbing. S3cnet: A sparse semantic scene completion network for lidar point clouds. In Conference on Robot Learning, pages 2148–2161. PMLR, 2021. 2
[6] Florian Fervers, Sebastian Bullinger, Christoph Bodensteiner, Michael Arens, and Rainer Stiefelhagen. Uncertainty-aware vision-based metric cross-view geolocalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21621– 21631, 2023. 3
[7] Google. Google maps api, 2024. Accessed: 2024-11-14. 5
[8] Xiyue Guo, Haocheng Peng, Junjie Hu, Hujun Bao, and Guofeng Zhang. From satellite to ground: Satellite assisted visual localization with cross-view semantic matching. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 3977–3983. IEEE, 2024. 3
[9] Adrian Hayler, Felix Wimbauer, Dominik Muhle, Christian Rupprecht, and Daniel Cremers. S4c: Self-supervised semantic scene completion with neural fields. In 2024 International Conference on 3D Vision (3DV), pages 409–420. IEEE, 2024. 1
[10] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 4
[11] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7132–7141, 2018. 5
[12] Sixing Hu, Mengdan Feng, Rang MH Nguyen, and Gim Hee Lee. Cvm-net: Cross-view matching network for imagebased ground-to-aerial geo-localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7258–7267, 2018. 3
[13] Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. Tri-perspective view for visionbased 3d semantic occupancy prediction. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9223–9232, 2023. 1, 2, 6
[14] Yuanhui Huang, Wenzhao Zheng, Yunpeng Zhang, Jie Zhou, and Jiwen Lu. Gaussianformer: Scene as gaussians for vision-based 3d semantic occupancy prediction. arXiv preprint arXiv:2405.17429, 2024. 6
[15] Haoyi Jiang, Tianheng Cheng, Naiyu Gao, Haoyang Zhang, Tianwei Lin, Wenyu Liu, and Xinggang Wang. Symphonize 3d semantic scene completion with contextual instance queries. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20258– 20267, 2024. 2, 6, 8
[16] Peidong Li, Wancheng Shen, Qihao Huang, and Dixiao Cui. Dualbev: Cnn is all you need in view transformation. arXiv preprint arXiv:2403.05402, 2024. 5
[17] Yiming Li, Sihang Li, Xinhao Liu, Moonjun Gong, Kenan Li, Nuo Chen, Zijun Wang, Zhiheng Li, Tao Jiang, Fisher Yu, et al. Sscbench: A large-scale 3d semantic scene completion benchmark for autonomous driving. arXiv preprint arXiv:2306.09001, 2023. 2, 5, 6
[18] Yiming Li, Zhiding Yu, Christopher Choy, Chaowei Xiao, Jose M Alvarez, Sanja Fidler, Chen Feng, and Anima Anandkumar. Voxformer: Sparse voxel transformer for camerabased 3d semantic scene completion. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9087–9098, 2023. 1, 2, 4, 5, 6, 8
[19] Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Yu Qiao, and Jifeng Dai. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In European conference on computer vision, pages 1–18. Springer, 2022. 2
[20] Tsung-Yi Lin, Piotr Dolla´r, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017. 4
[21] Liu Liu and Hongdong Li. Lending orientation to neural networks for cross-view geo-localization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5624–5633, 2019. 3
[22] I Loshchilov. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017. 6
[23] Ruihang Miao, Weizhou Liu, Mingrui Chen, Zheng Gong, Weixin Xu, Chen Hu, and Shuchang Zhou. Occdepth: A depth-aware method for 3d semantic scene completion. arXiv preprint arXiv:2302.13540, 2023. 2
[24] Ian D Miller, Anthony Cowley, Ravi Konkimalla, Shreyas S Shivakumar, Ty Nguyen, Trey Smith, Camillo Jose Taylor, and Vijay Kumar. Any way you look at it: Semantic crossview localization and mapping with lidar. IEEE Robotics and Automation Letters, 6(2):2397–2404, 2021. 3
[25] Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16, pages 194–210. Springer, 2020. 2
[26] Luis Roldao, Raoul de Charette, and Anne Verroust-Blondet. Lmscnet: Lightweight multiscale 3d semantic completion. In 2020 International Conference on 3D Vision (3DV), pages 111–119. IEEE, 2020. 1, 2, 6
[27] Paul-Edouard Sarlin, Daniel DeTone, Tsun-Yi Yang, Armen Avetisyan, Julian Straub, Tomasz Malisiewicz, Samuel Rota Bulo, Richard Newcombe, Peter Kontschieder, and Vasileios Balntas. Orienternet: Visual localization in 2d public maps with neural matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21632–21642, 2023. 3
[28] Paul-Edouard Sarlin, Eduard Trulls, Marc Pollefeys, Jan Hosang, and Simon Lynen. Snap: Self-supervised neural maps for visual positioning and semantic understanding. Advances in Neural Information Processing Systems, 36, 2024.
[29] Faranak Shamsafar, Samuel Woerz, Rafia Rahim, and Andreas Zell. Mobilestereonet: Towards lightweight deep networks for stereo matching. In Proceedings of the ieee/cvf winter conference on applications of computer vision, pages 2417–2426, 2022. 4
[30] Yujiao Shi and Hongdong Li. Beyond cross-view image retrieval: Highly accurate vehicle localization using satellite image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17010– 17020, 2022. 3, 5
[31] Shuran Song, Fisher Yu, Andy Zeng, Angel X Chang, Manolis Savva, and Thomas Funkhouser. Semantic scene completion from a single depth image. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1746–1754, 2017. 1, 2, 6
[32] Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, pages 6105–6114. PMLR, 2019. 3
[33] Xin Tan, Wenbin Wu, Zhiwei Zhang, Chaojie Fan, Yong Peng, Zhizhong Zhang, Yuan Xie, and Lizhuang Ma. Geocc: Geometrically enhanced 3d occupancy network with implicit-explicit depth fusion and contextual selfsupervision. arXiv preprint arXiv:2405.10591, 2024. 2
[34] Pin Tang, Zhongdao Wang, Guoqing Wang, Jilai Zheng, Xiangxuan Ren, Bailan Feng, and Chao Ma. Sparseocc: Rethinking sparse latent representation for vision-based semantic occupancy prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15035–15044, 2024. 2
[35] Yi Wei, Linqing Zhao, Wenzhao Zheng, Zheng Zhu, Jie Zhou, and Jiwen Lu. Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 21729–21740, 2023. 1, 2, 6
[36] Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), pages 3–19, 2018. 5
[37] Zhaoyang Xia, Youquan Liu, Xin Li, Xinge Zhu, Yuexin Ma, Yikang Li, Yuenan Hou, and Yu Qiao. Scpnet: Semantic scene completion on point cloud. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17642–17651, 2023. 2
[38] Xu Yan, Jiantao Gao, Jie Li, Ruimao Zhang, Zhen Li, Rui Huang, and Shuguang Cui. Sparse single sweep lidar point cloud segmentation via learning contextual shape priors from scene completion. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 3101–3109, 2021. 1, 2, 6
[39] Junyan Ye, Qiyan Luo, Jinhua Yu, Huaping Zhong, Zhimeng Zheng, Conghui He, and Weijia Li. Sg-bev: Satellite-guided bev fusion for cross-view semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27748–27757, 2024. 3
[40] Zhu Yu, Runmin Zhang, Jiacheng Ying, Junchen Yu, Xiaohai Hu, Lun Luo, Si-Yuan Cao, and Hui-liang Shen. Context and geometry aware voxel transformer for semantic scene completion. In Advances in Neural Information Processing Systems, pages 1531–1555, 2024. 1
[41] Yunpeng Zhang, Zheng Zhu, and Dalong Du. Occformer: Dual-path transformer for vision-based 3d semantic occupancy prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9433–9443, 2023. 2, 6
[42] Yanhao Zhang, Yujiao Shi, Shan Wang, Ankit Vora, Akhil Perincherry, Yongbo Chen, and Hongdong Li. Increasing slam pose accuracy by ground-to-satellite image registration. arXiv preprint arXiv:2404.09169, 2024. 3
[43] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159, 2020. 2, 4