由于一开始的代码没有考虑多语言场景,导致代码中提示框和UI显示直接用了中文,最近开始提取代码的中文,提取起来太麻烦,所以拓展了之前的多语言包,降低了操作复杂度。最后把工具代码提取出来到单独项目里面,做一个分享,项目资源放到最后。
接入方案和使用步骤
- 导入package
- 修改EnumMessageTxt文件内容,根据自己的需求新增或删除语言,如删除繁体中文,则删除第一行中的,繁体中文,删除第三行的繁体中文缩写|Cht,删除多余的繁体语言包内容(可以把下面所有行都删除),删除后内容为
S,Key,简体中文 //Area| 1|Area|Cn //Common2~500|Common 2|CommonTip|公共提示 3|CommonTip2|公共提示2 4|CommonTip3|公共提示 5|CommonFormatTip|提示{0} //PanelA501~601|PanelA 501|PanelABtn|按钮若要添加其他语言,务必要记得第三行中加入对应的缩写
-
点击拓展工具Tools/MessageDataTool/EnumMessageEditor,打开界面,点击加载按钮,选择文件进行修改,修改完毕点击生成代码按钮,等待生成完成,编译完成即可,加载代码在Panel脚本中,需要先初始化语言类型(缩写),再进行加载
-
语言包加载逻辑在MessageManager.InitCyData中,根据自己项目的资源加载方式进行修改
-
由于只是简单的分享, 所以工具可能缺少部分合法验证,如遇到报错等情况,可以查看堆栈信息,或者私信咨询
逻辑介绍
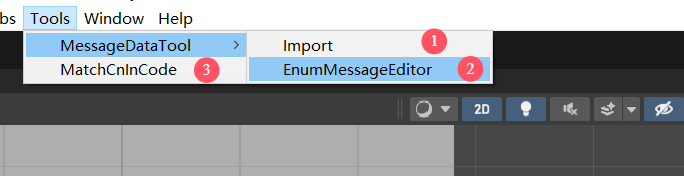
项目目录结构
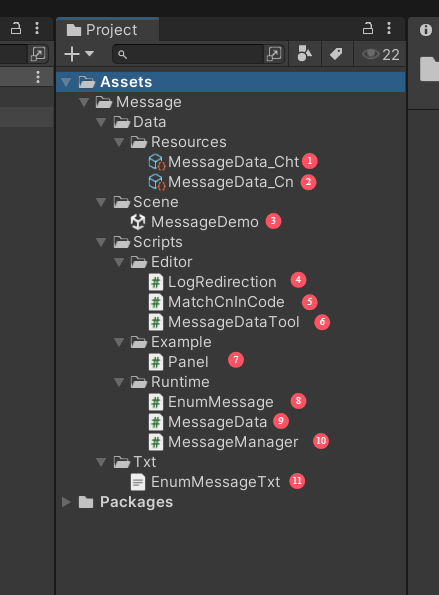
1.生成的Asset资源,繁体多语言数据
2.生成的Asset资源,简体多语言数据,路径可以通过代码修改,测试需要,放在Resources下加载
3.Demo场景
4.Unity Console日志重定向脚本,方便根据日志跳转代码中文处
5.匹配代码中文的脚本
6.多语言工具窗口脚本
7.Demo界面
8.生成的多语言key脚本,枚举类型
9.1,2中Asset资源对应的源Scriptable脚本
10.多语言管理器,加载多语言内容
11.多语言源txt文件,存放源内容
编辑器拓展功能
1.导入txt源文件,生成脚本,最初始的多语言工具拓展功能,没有删除,保留了下来,如果不使用预览工具时,可使用该功能
2.多语言工具预览和操作界面
3.匹配代码中文 功能
多语言txt源文件
S,Key,简体中文,繁体中文
//Area|
1|Area|Cn|Cht
//Common2~500|Common
2|CommonTip|公共提示|公共提示繁体
3|CommonTip2|公共提示2|
4|CommonTip3|公共提示|
5|CommonFormatTip|提示{0}|
//PanelA501~601|PanelA
501|PanelABtn|按钮|按钮繁体
1.首行格式固定为 S,Key,语言A,语言B,语言C 代码会根据该行后面的语言类型数量创建对应的数据
2.第二行及后续所有以//开头的内容,表示为注释,不参与逻辑预算,主要功能是提示,以|分割,|后内容表示为标头,无逻辑意义,主要功能是方面添加Key,后面结合工具介绍
3.除去首行及注释行,其他行内容均为多语言内容,格式为 枚举整型值|枚举名称|语言A文本|语言B文本...第三行这个枚举整型值为1的是特例,表示上面各个语言的缩写,也表示了生成的资源文件名称,不能重复。注意并不是1中有多少种语言,这里就要添加多少种语言文本,但是至少多语言A的要有值,如果语言文本没有定义,那么会取最前面的语言文本,也就是假如这里没有定义语言C的多内容语言,那么语言C对应的多语言内容会取语言A的。配合生成的枚举脚本和数据可以更直观理清,这里实例用了两种简体中文和繁体中文。
生成的枚举脚本
namespace Message
{
public enum EnumMessage
{
//Area|
/// <summary>
/// Cn
/// </summary>
Area = 1,
//Common2~500|Common
/// <summary>
/// 公共提示
/// </summary>
CommonTip = 2,
/// <summary>
/// 公共提示2
/// </summary>
CommonTip2 = 3,
/// <summary>
/// 公共提示
/// </summary>
CommonTip3 = 4,
/// <summary>
/// 提示{0}
/// </summary>
CommonFormatTip = 5,
//PanelA501~601|PanelA
/// <summary>
/// 按钮
/// </summary>
PanelABtn = 501,
MaxNum,
}
}
生成的简体中文多语言资源内容,注意名称和上面源文件第三行的关系
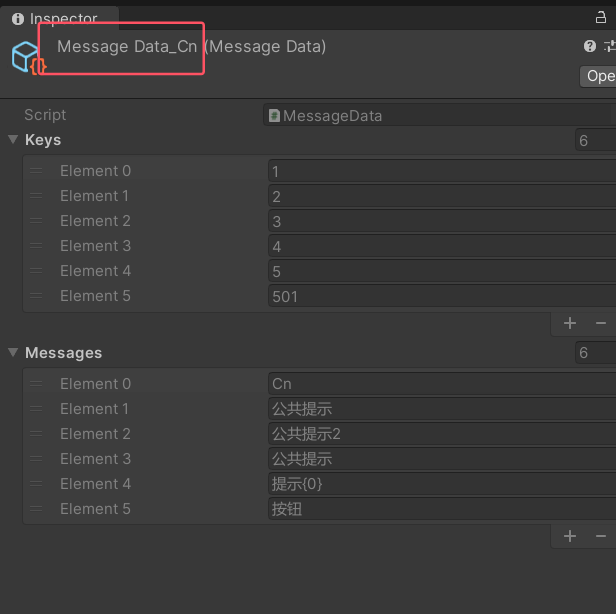
生成的繁体中文多语言资源内容,注意名称和上面源文件第三行的关系和空值填充
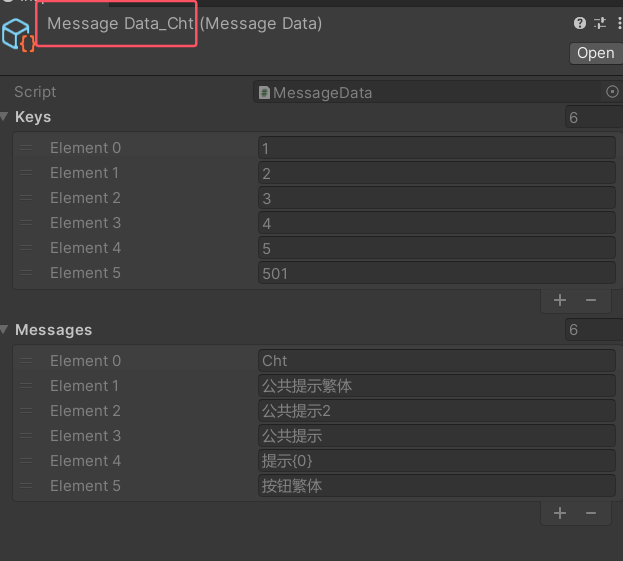
多语言工具预览和操作界面
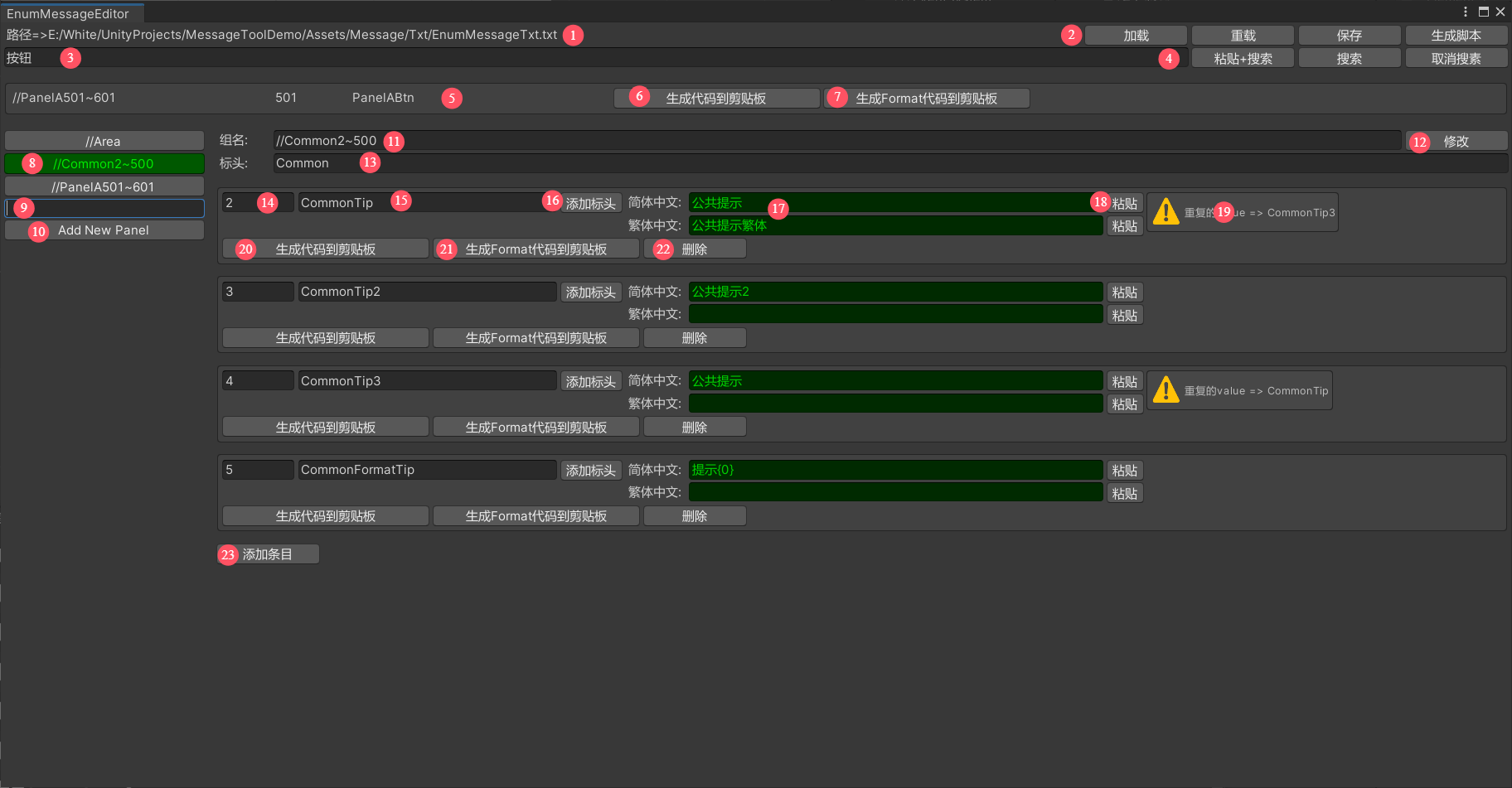
1. 选择的多语言txt源文件路径
2.加载:拉起选择框,选择要加载的源文件。重载:依据1中的路径,重新刷新当前界面的数据。保存:保存界面数据到1中的路径。生成脚本:先保存到源文件,再根据当前界面的数据生成枚举脚本和Asset数据
3.输入要搜索的多语言内容,内容为多语言A的内容
4.粘贴+搜索:粘贴剪贴板内容到3的输入框,并进行搜索。搜索:搜索3的输入框内容。取消搜索:隐藏搜索结果
5.搜索到的结果,可能有多条。内容从左到右依次为所在组名,枚举整型值,枚举名称
6.根据当前条目生成获取多语言值的代码,代码内容为
Message.MessageManager.I.GetMessage(Message.EnumMessage.PanelABtn)代码生成格式可以自行修改,逻辑在脚本文件MessageDataTool的GenerateMessage函数中
7.根据当前条目生成获取Format多语言值的代码,代码内容为
Message.MessageManager.I.GetMessageFormat(Message.EnumMessage.PanelABtn)注意要配合format类型的多语言使用,代码生成格式可以修改,逻辑在脚本文件MessageDataTool的GenerateFormatMessage函数中
8.组列表,所有 // 开头的行,选中的为绿色高亮
9.要添加的组名称,格式需要以//开头
10.添加新组,组名为9中内容
11.当前选中的组,可以在此处修改组名称
12.修改组名称按钮,必须点击按钮才能修改,同时为了保证源文件的组顺序不变化,这里会自动保存文件
13.组的标头,可以理解为当前组下所有内容的枚举名称前缀,方面增加前缀的,可以为空
14.枚举整型值,全局唯一索引,可以手动修改,同一组内添加条目默认递增1,组内的第一个新建条目需要手动修改索引值为合适值
15.枚举名称,全局唯一,可以手动修改
16.给枚举名称添加标头前缀,保证格式统一
17.多语言内容,在这里修改
18.将当前剪贴板内容粘贴到17的输入框内
20.同6
21.同7
22.删除当前条目,为了防止旧数据出错,删除条目不会修正索引,比如之前索引列表为2,3,4,删除了3之后,索引为4不会修正为3,而是留空
23.添加新的条目,索引递增1,若13有标头,会自动给15输入框中赋值标头内容
界面的操作的逻辑都在脚本里面,因为涉及到布局代码过多,这里不再解读,可以搜索按钮名称查看对应的逻辑
匹配代码中文脚本
using System.IO;
using System.Text.RegularExpressions;
using UnityEditor;
using UnityEngine;
/// <summary>
/// 匹配代码中的中文
/// </summary>
public class MatchCnInCode : Editor
{
// 正则表达式匹配中文字符
static Regex chineseCharRegex = new Regex("[\u4e00-\u9fa5]");
//忽略的文件夹
static string[] IgnoreDir = new string[] { @"/Message/", @"/ProtoBuffer/", @"/ThirdPlugins/" };
//忽略的代码行
static string[] IgnoreCode = new string[] { "[Header(", "Debugger.Log", "Debug.Log","#region" };
//搜索的脚本路径
static string searchScriptPath = "Assets/HotUpdate/Scripts";
[MenuItem("Tools/MatchCnInCode")]
static void Method()
{
if (EditorUtility.DisplayDialog("提示", "开始匹配代码中的中文", "确定", "取消"))
{
Do();
}
}
static void Do()
{
// 搜索所有的 .cs 文件
var csFiles = AssetDatabase.FindAssets("t:script", new string[] { searchScriptPath });
for (int i = 0; i < csFiles.Length; i++)
{
var file = AssetDatabase.GUIDToAssetPath(csFiles[i]);
bool hit = false;
for (int j = 0; j < IgnoreDir.Length; j++)
{
if (file.Contains(IgnoreDir[j]))
{
hit = true;
break;
}
}
if (hit)
{
continue;
}
var obj = AssetDatabase.LoadAssetAtPath<Object>(file);
using (StreamReader sr = new StreamReader(file))
{
//匹配到中文
bool matchCn = false;
//在多行注释中
bool inMulAnnotation = false;
int lineIndex = 0;
while (!sr.EndOfStream)
{
lineIndex++;
//要匹配的内容
bool matched = false;
var line = sr.ReadLine();
if (string.IsNullOrEmpty(line))
{
continue;
}
//多行注释开始的索引
int mulAnnotationStartIndex = line.IndexOf("/*");
if (mulAnnotationStartIndex != -1)
{
//在多行注释中
inMulAnnotation = true;
var indexBeforeStr = line.Substring(0, mulAnnotationStartIndex);
var match = chineseCharRegex.Match(indexBeforeStr);
if (match.Success)
{
Debug.LogError($"{file}=>{lineIndex}=> {match.Value} => {line} ", obj);
matched = true;
}
}
//在多行注释中
if (inMulAnnotation)
{
//不含多行注释开始标识的匹配串
string noAnnotationStartStr = string.Empty;
//该行没有开始标识,直接找结束标识
if (mulAnnotationStartIndex == -1)
{
noAnnotationStartStr = line;
}
else//有开始标识,从开始标识后找结束标识防止/*/的情况
{
noAnnotationStartStr = line.Substring(mulAnnotationStartIndex + 2);
}
var mulAnnotationEndIndex = noAnnotationStartStr.IndexOf("*/");
//有结尾符
if (mulAnnotationEndIndex != -1)
{
inMulAnnotation = false;
var indexAfterStr = noAnnotationStartStr.Substring(mulAnnotationEndIndex);
var match = chineseCharRegex.Match(indexAfterStr);
if (match.Success)
{
Debug.LogError($"{file}=>{lineIndex}=> {match.Value} => {line} ", obj);
matched = true;
}
}
}
else
{
//查找是否有单行注释
var singleAnnotationIndex = line.IndexOf("//");
if (singleAnnotationIndex == -1)
{
bool hitIgnore = false;
for (int j = 0; j < IgnoreCode.Length; j++)
{
var logIndex = line.IndexOf(IgnoreCode[j]);
if (logIndex != -1)
{
hitIgnore = true;
}
}
if (!hitIgnore)
{
var match = chineseCharRegex.Match(line);
if (match.Success)
{
Debug.LogError($"{file}=>{lineIndex}=> {match.Value} => {line} ", obj);
matched = true;
}
}
}
else
{
var match = chineseCharRegex.Match(line.Substring(0, singleAnnotationIndex));
if (match.Success)
{
Debug.LogError($"{file}=>{lineIndex}=> {match.Value} => {line} ", obj);
matched = true;
}
}
}
//匹配所有行,还是匹配到一行后返回
//if (matched)
//{
// break;
//}
}
}
}
}
}
主要逻辑就是根据正则匹配中文,同时要忽略掉注释以及特殊字符开头的行,注意上面的Debug.LogError输出格式为脚本路径=>行数=>匹配到的首字=>整行内容,下面日志重定向要用。这几处输出可以封装,这里省略了封装代码,下面是实际运行时的日志输出,注意这里的堆栈信息,也是日志重定向需要使用的

日志重定向脚本
using System;
using System.Reflection;
using System.Text.RegularExpressions;
using UnityEditor;
using UnityEditor.Callbacks;
using UnityEditorInternal;
namespace TEngine.Editor
{
/// <summary>
/// 日志重定向相关的实用函数。
/// </summary>
internal static class LogRedirection
{
[OnOpenAsset(0)]
private static bool OnOpenAsset(int instanceID, int line)
{
if (line <= 0)
{
return false;
}
// 获取资源路径
string assetPath = AssetDatabase.GetAssetPath(instanceID);
// 判断资源类型
if (!assetPath.EndsWith(".cs"))
{
return false;
}
var stackTrace = GetStackTrace();
if (!string.IsNullOrEmpty(stackTrace) && stackTrace.Contains("MatchCnInCode.cs") && stackTrace.StartsWith("Assets"))
{
//中文匹配的输出
var arr = stackTrace.Split("=>");
//0:路径 ,1: 行数
var path = arr[0];
var lineNum = int.Parse(arr[1]);
var fullPath = UnityEngine.Application.dataPath.Substring(0, UnityEngine.Application.dataPath.LastIndexOf("Assets", StringComparison.Ordinal));
fullPath = $"{fullPath}{path}";
// 跳转到目标代码的特定行
InternalEditorUtility.OpenFileAtLineExternal(fullPath.Replace('/', '\\'), lineNum);
return true;
}
return false;
}
/// <summary>
/// 获取当前日志窗口选中的日志的堆栈信息。
/// </summary>
/// <returns>选中日志的堆栈信息实例。</returns>
private static string GetStackTrace()
{
// 通过反射获取ConsoleWindow类
var consoleWindowType = typeof(EditorWindow).Assembly.GetType("UnityEditor.ConsoleWindow");
// 获取窗口实例
var fieldInfo = consoleWindowType.GetField("ms_ConsoleWindow",
BindingFlags.Static |
BindingFlags.NonPublic);
if (fieldInfo != null)
{
var consoleInstance = fieldInfo.GetValue(null);
if (consoleInstance != null)
if (EditorWindow.focusedWindow == (EditorWindow)consoleInstance)
{
// 获取m_ActiveText成员
fieldInfo = consoleWindowType.GetField("m_ActiveText",
BindingFlags.Instance |
BindingFlags.NonPublic);
// 获取m_ActiveText的值
if (fieldInfo != null)
{
var activeText = fieldInfo.GetValue(consoleInstance).ToString();
return activeText;
}
}
}
return null;
}
}
}主要逻辑在函数OnOpenAsset中,var stackTrace = GetStackTrace();这里获取了整个输出的所有信息,然后下一行代码判断信息中是否有“MatchCnInCode.cs”以及是否以“Assets”开头,如果满足这两个条件,我们需要对该日志输出进行重定向。再根据我们上面的输出格式脚本路径=>行数=>匹配到的首字=>整行内容,可以取到路径和行数,就可以实现点击该行输出,直接定位到日志中标记的行数了,注意这里的路径不能多空格,结尾的空格也不行,否则会无法定位到脚本编辑工具中,所以日志输出的时候要检查是否有多余的空格。
资源地址
https://download.csdn.net/download/a598211757/90628215