文章目录
- 1. 引言:什么是VLN及其重要性?
- 2. VLN问题定义
- 3. 核心挑战
- 4. 基石:关键数据集与模拟器
- 5. 评估指标
- 6. 主要方法与技术演进
- 6.1 前CLIP时代:奠定基础
- 6.2 后CLIP时代:视觉与语言的统一
- 7. 最新进展与前沿趋势 (2023-2025年初)
- 8. 未来研究方向与开放问题
- 9. 结论
视觉语言导航(Visual Language Navigation,VLN)是人工智能领域一个快速发展的交叉学科研究方向,融合了计算机视觉(CV)、自然语言处理(NLP)、机器人学和强化学习(RL)。其核心任务是训练一个智能体(Agent),使其能够理解自然语言指令,并在真实的或模拟的视觉环境中导航至目标位置。VLN不仅是衡量机器智能在理解和行动方面进展的关键基准,也为未来机器人助手、增强现实交互和人机协作应用奠定了基础。本综述旨在全面梳理VLN领域的核心概念、关键挑战、主要方法、基准数据集、评估指标、最新进展以及未来研究方向。
1. 引言:什么是VLN及其重要性?
想象一下,你可以告诉家里的机器人:“去厨房,帮我拿一下放在微波炉旁边的那个红色杯子。” 要完成这个任务,机器人需要:
- 理解指令 (NLP): 解析指令中的地点(厨房)、物体(红色杯子)以及空间关系(微波炉旁边)。
- 感知环境 (CV): 识别当前的视觉场景,定位可能的路径、障碍物以及指令中提到的关键物体和地标。
- 规划与行动 (Robotics/RL): 基于理解和感知,制定一系列动作(前进、左转、右转、停止)来到达目标位置并可能执行后续操作。
- 跨模态对齐/基准(Grounding): 将语言描述(“红色杯子”、“微波炉旁边”)与视觉世界中的具体实体和位置精确对应起来。
这就是VLN研究的核心。它要求智能体不仅仅被动地识别或描述,而是要主动地、有目的地在物理(或模拟物理)空间中行动,以完成由语言定义的目标。
VLN的重要性体现在:
- 人机交互的未来: 实现更自然、直观的人与机器人/AI系统交互方式。
- 具身智能(Embodied AI)的代表: 是测试和推动具身AI发展的关键任务,要求AI具备感知、推理、规划和行动的综合能力。
- 跨学科研究的熔炉: 促进CV、NLP、RL等领域的深度融合与协同发展。
- 潜在应用广泛: 服务机器人、智能家居、辅助导航(尤其对视障人士)、AR/VR内容交互、自动化探索等。
2. VLN问题定义
标准的VLN任务可以形式化地描述为:
- 输入:
- 自然语言指令 I: 一个描述目标位置或路径的文本序列。
- 环境观测 O: 在每个时间步 t,智能体接收到的视觉信息,通常是第一人称视角的图像(RGB图像,有时也包括深度图或全景图)。
- 输出:
- 动作序列 A = {a_1, a_2, …, a_T}: 智能体执行的一系列动作,动作空间通常是离散的(例如:
FORWARD,TURN_LEFT,TURN_RIGHT,STOP)。
- 动作序列 A = {a_1, a_2, …, a_T}: 智能体执行的一系列动作,动作空间通常是离散的(例如:
- 目标:
- 智能体执行动作序列 A 后,其最终位置 p_T 尽可能接近指令 I 所描述的目标位置 p_g。通常要求在预定义的停止动作
STOP执行时,满足距离阈值(例如,小于3米)。
- 智能体执行动作序列 A 后,其最终位置 p_T 尽可能接近指令 I 所描述的目标位置 p_g。通常要求在预定义的停止动作
3. 核心挑战
VLN任务面临着诸多固有挑战:
- 跨模态基准(Cross-Modal Grounding): 这是最核心的挑战。如何将抽象的语言描述(如“有沙发的那个房间”、“走过挂着画的走廊”)与复杂的视觉场景中的具体物体、区域和空间关系精确对应起来?
- 长期规划与记忆: 指令可能很长,描述的路径可能包含多个步骤或转折点。智能体需要具备长期记忆能力,记住指令的关键部分以及已经探索过的环境信息,并进行有效的长期动作规划。
- 泛化能力: 训练好的智能体需要在未见过的环境(Unseen Environments)和面对新的、风格可能不同的指令时仍能表现良好。模拟器与真实世界之间的差距(Sim-to-Real Gap)也是泛化的一大难题。
- 歧义性与不确定性: 自然语言指令本身可能存在歧义(如“那个大房间”),环境观测也可能因为遮挡、光照变化等因素带来不确定性。智能体需要具备一定的鲁棒性和推理能力来处理这些不确定性。
- 探索与利用的平衡: 在导航过程中,智能体需要在利用已知信息(指令、已探索区域)向目标前进和探索未知区域以寻找线索之间做出平衡。
4. 基石:关键数据集与模拟器
VLN的发展离不开高质量的数据集和逼真的模拟环境。其中,R2R和RxR两个标志性数据集堪称VLN领域的“ImageNet”,自发布以来便成为衡量算法和模型性能的黄金标准,是VLN领域不可或缺的“试金石”。
-
主要数据集:
- R2R (Room-to-Room): (Anderson et al., 2018) VLN领域的首个黄金标准。在R2R诞生前,VLN研究深陷「数据孤岛」困境。澳大利亚国立大学团队以ImageNet为蓝本,基于Matterport3D扫描的真实室内环境(90个多样户型,毫米级复刻)构建了R2R。标注员通过路径视频撰写自然语言指令,包含地标参照、方位指示与动作描述,并经第三方验证确保指令与路径偏差小于3米。它提供英文导航指令和对应的专家路径,包含训练集、验证集(Seen/Unseen)和测试集(Unseen),为VLN研究提供了统一基准。
- RxR (Room-across-Room): (Ku et al., 2020) 由谷歌推出,将任务复杂度推向“高阶考场”。其核心突破在于跨楼层长路径任务(平均30米)与多语言指令适配(英、印地、泰卢固语)。指令更详细、自然、口语化,包含更多细粒度的空间描述和指代。这不仅要求模型理解更复杂的逻辑,还需解析语言的多样表达,迫使模型摆脱单语言依赖。基于Matterport3D。
- R4R/R8R: R2R的扩展,包含更长的路径和指令。
- CVDN (Cooperative Vision-and-Dialog Navigation): (Thomason et al., 2019) 引入对话机制,导航智能体可以向引导者提问获取帮助,更接近真实人机协作。基于Matterport3D。
- Touchdown: (Chen et al., 2019) 基于Google街景的室外VLN任务,目标是根据指令找到并“触达”特定对象。
- HANNA (Help, Anna!): (Nguyen et al., 2021) 交互式VLN,允许人类在导航过程中提供实时反馈和纠正。基于Habitat模拟器。
- REVERIE: (Qi et al., 2020) 远程具身指代表达,目标是根据指令找到并定位远处的特定物体。
- SOON: (Zhu et al., 2021) 关注场景中的物体关系导航。
-
主要模拟器:
- Matterport3D Simulator: R2R、RxR等数据集的基础,基于真实建筑3D扫描重建,提供高质量视觉渲染。
- Habitat Platform (Habitat-Sim): (Savva et al., 2019; Szot et al., 2021) Meta AI开发的高效、轻量级具身AI模拟器,支持多种场景数据集,渲染速度快,适合大规模RL训练。后续版本增加了物理交互。
- AI2-THOR: (Kolve et al., 2017) AI2开发的交互式环境,支持物体交互和物理模拟。
- Gibson: (Xia et al., 2018) 注重物理真实感的模拟环境,基于真实世界扫描。
5. 评估指标
衡量VLN智能体性能的主要指标包括:
- 任务完成率 (Success Rate, SR): 最核心的指标。智能体停止位置与目标位置距离是否小于阈值(通常3米)。计算成功轨迹的比例。
- 导航误差 (Navigation Error, NE): 智能体停止时距离目标位置的平均欧氏距离。越小越好。
- 路径长度 (Trajectory Length, TL): 智能体实际行走的路径总长度。
- 最短路径长度 (Shortest Path Distance, SPD): 起点到终点的理论最短路径长度。
- 路径长度加权的成功率 (Success weighted by Path Length, SPL): (Anderson et al., 2018) 综合考虑成功率和路径效率。
SPL = (1/N) * Σ [ S_i * (l_i / max(p_i, l_i)) ]。奖励既成功又高效(接近最短路径)的智能体。是衡量导航效率的关键指标。 - 覆盖率加权长度得分 (Coverage weighted by Length Score, CLS): (Ku et al., 2020) 用于RxR数据集,衡量智能体路径与指令中提到的所有参考点(grounding)的对齐程度,同时考虑路径效率。
- 动态时间规整 (DTW) / 归一化DTW (nDTW) / 几何DTW (gDTW): (Ku et al., 2020) 用于RxR,衡量生成路径与专家路径的相似度,对微小偏差鲁棒。
6. 主要方法与技术演进
VLN的研究方法经历了显著的演进,可以大致划分为“前CLIP时代”和“后CLIP时代”。
6.1 前CLIP时代:奠定基础
在数据驱动的框架下,早期VLN研究主要围绕强化学习、模仿学习和跨模态对齐这三大核心技术路线,共同构筑AI“看-听-走”的认知闭环。
-
早期序列模型 (基于RNN/LSTM):
- 序列到序列(Seq2Seq)模型: 将指令编码为向量,使用RNN/LSTM基于视觉输入和历史状态逐步解码生成动作。
- 局限性: 对长指令和长路径记忆有限,跨模态对齐能力弱。
-
基于注意力的模型:
- 引入注意力机制动态关联指令词语与视觉特征,显著提升跨模态基准能力。
- 交叉模态注意力(Cross-Modal Attention): 成为后续模型基础,允许文本和视觉特征深度交互。Faster R-CNN的物体检测框与Bi-LSTM文本关键词经动态注意力耦合,可实现「锁定沙发区域」的精准映射。
-
强化学习(RL)的应用:
- 将VLN视为部分可观察马尔可夫决策过程(POMDP),使用RL学习导航策略。如同蒙眼探索迷宫,AI通过试错学习。
- 挑战: 奖励稀疏、样本效率低。
- 常用策略:
- IL + RL: 先用模仿学习预训练,再用RL(如A3C, PPO)微调。
- 辅助奖励(Reward Shaping): 设计中间奖励缓解稀疏性。
- Speaker-Follower模型: 如RCON, EnvDrop(通过视觉特征随机丢弃提升泛化能力)。Recurrent VLN-BERT利用长短期记忆模块解决路径回溯难题。
-
模仿学习(IL)的应用:
- 将导航建模为“行为模仿”,直接学习专家(人类演示)路径。
- 行为克隆(Behavior Cloning): 简单有效,但易受分布漂移影响(如“遇门必左转”的复合错误)。
- DAgger算法: 通过错误路径迭代修正注入动态纠偏能力,但面临数据标注瓶颈。
-
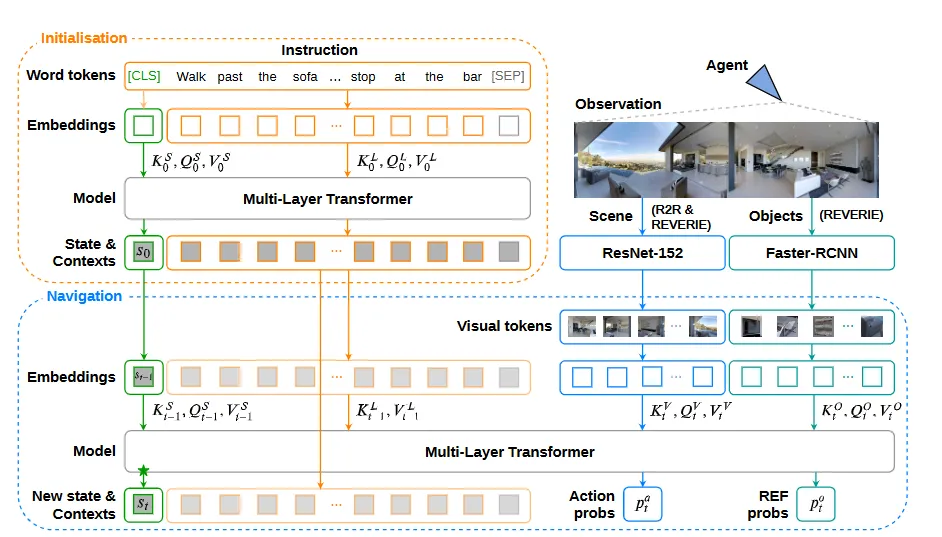
基于Transformer和预训练的模型(CLIP之前):
- 利用Transformer处理语言、视觉和历史动作序列。代表作如VLN-BERT, PREVALENT, HAMT,通过自注意力和交叉注意力融合多模态信息,捕捉长距离依赖。
- 使用全景视觉表示提供更完整的环境感知。
- 开始探索大规模预训练,利用图像、文本数据学习通用视觉-语言表示,然后迁移到VLN。预训练任务如MLM, MVM, VLM等。
-
其他方法:
- 模块化方法: 分解为指令解析、视觉感知、定位、规划、控制等子模块。
- 基于图的方法: 将环境表示为拓扑图或语义图,在图上进行路径搜索。
-
早期产业尝试与挑战:
- 当仿真成功率提升(如Habitat论文中超50%),产业界尝试将VLN推向现实(家庭、仓库)。
- 遭遇三重暴击:硬件算力限制(处理延迟导致碰撞)、动态环境问题(预存地图失效)、人性化交互缺失(无法处理指令模糊)。
- 早期产品试水充满“妥协艺术”(如亚马逊Kiva回归二维码,iRobot语音导航因误识别被叫停)。
- 揭示了**“仿真学霸可能是现实差生”**的真相,倒逼研究者直面成本、鲁棒性、人机协同的鸿沟。
“从强化学习到跨模态对齐,AI学会用人类的语言思考导航。” 这一阶段的技术积淀,为后续大模型登场埋下伏笔。
6.2 后CLIP时代:视觉与语言的统一
当学术界和工业界在挣扎时,2022年OpenAI发布的CLIP模型以其强大的零样本跨模态理解能力,开启了VLN技术进化的新维度。CLIP无需人工标注,从海量互联网图文对中自学习视觉概念与语言描述的关联,让机器首次真正意义上听懂“人话”与“物境”的关联。当视觉与语言在统一空间自由对话,VLN的“开挂时代”就此启幕。
此后,VLN领域佳作频出,每年都有显著进步,特别是利用CLIP及后续的大型视觉语言模型(VLMs)和大型语言模型(LLMs)。
-
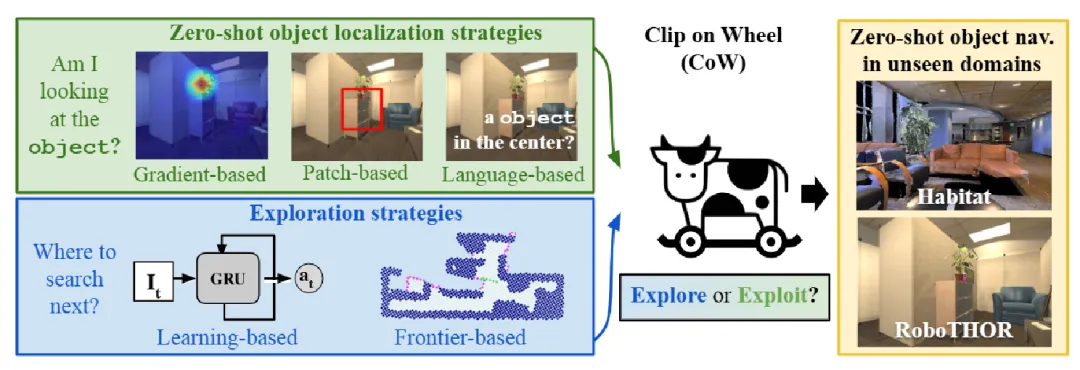
2022:CLIP on Wheels
- 突破: 将CLIP的跨模态理解与主动探索策略结合。使用语义热力图扫描环境锁定目标区域,目标隐匿时启动类人搜索逻辑(推门、检查角落、回溯)。
- 贡献: 首次实现无需预存数据的“直觉型导航”,在AI2-THOR中零样本导航成功率大幅提升(8% -> 55%)。开启了“CLIP+主动推理”浪潮。
- 局限: 依赖全局热力图暴力搜索,效率不高,仍基于“视觉->文本标签->语义匹配”链条。
-
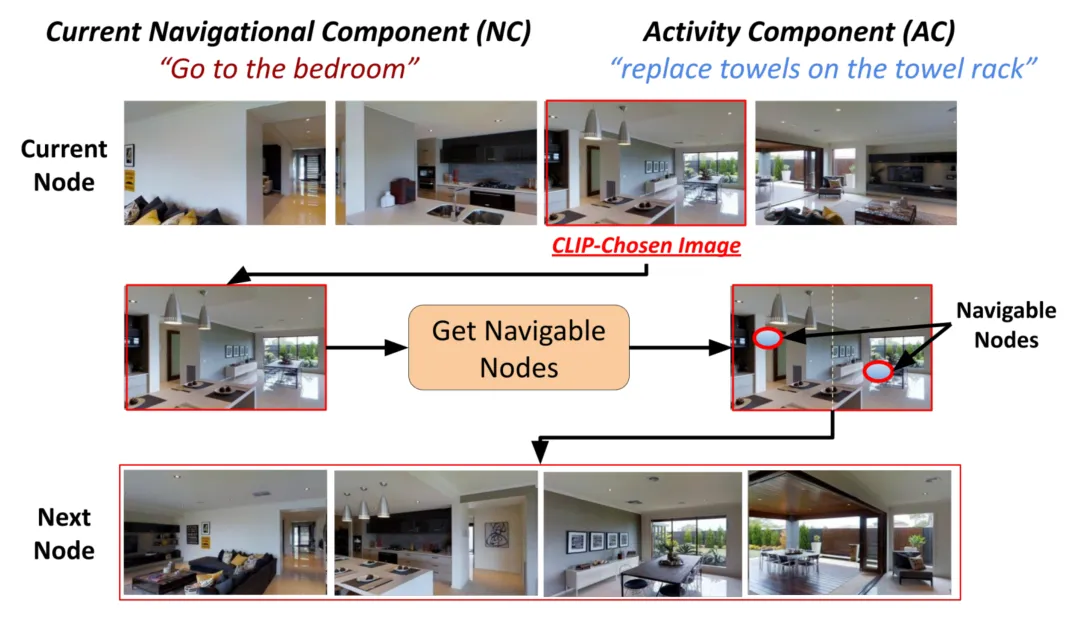
2022:CLIP-NAV
- 突破: 开创另一条CLIP导航路径。采用局部增量规划框架,将导航分解为单步决策。通过CLIP实时计算视觉场景与子指令匹配度,直接预测最优动作。
- 贡献: 动态指令分解省去全局热力图和物体检测算力(推理速度提升),解决长指令目标迷失问题。零样本成功率和推理效率优于CLIP on Wheels(67%)。为后续轻量化架构(如VLFM)提供范式。
-
2023:ESC (Embodied Scene Context)
- 突破: 在CLIP基础上引入常识推理机制。通过动态知识图谱将人类经验(如物品位置偏好)编码为概率化规则,并与CLIP语义热力图融合。
- 贡献: 实现混合策略(优先探索高概率区域,兼顾全局搜索)。零样本成功率(71%)和路径效率显著提升,抗模糊指令能力增强。标志着VLN从“视觉匹配”向“认知推理”的关键跨越。
- 相对CLIP on Wheels的升级: 从“机械匹配”到“经验推理”,效率提升,动态适应性增强。融合感知与经验,决策更近人类直觉。
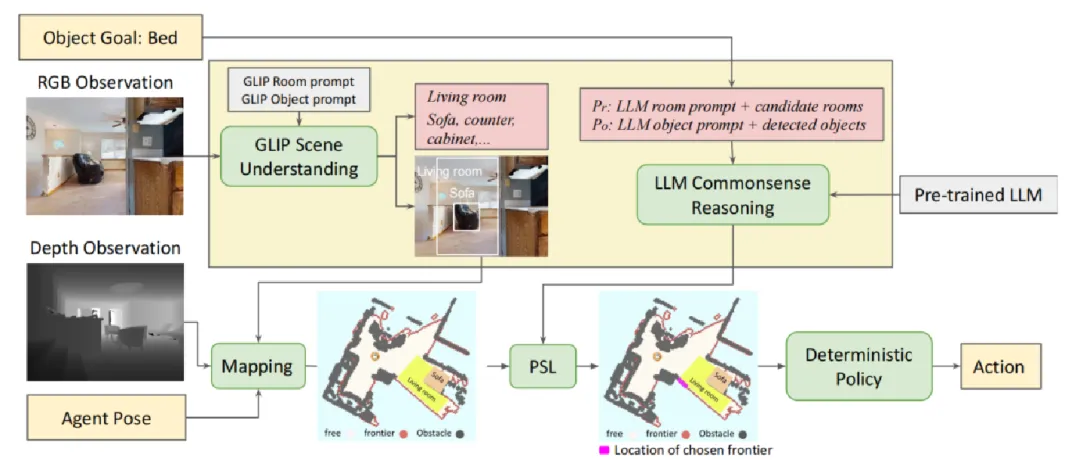
-
2024:VLFM (Vision-Language Frontier Maps)
- 突破: 实现视觉-语言端到端联合推理,终结“视觉→文本→语义”的冗余链条。使用BLIP-2等VLM直接将图像与指令映射至统一语义空间,生成融合语义关联度和物理可达性的动态价值地图。
- 贡献: 无需预设规则或中间特征转换,实时规划最优路径。开放场景导航效率和泛化能力达到新高度。在真实机器人(波士顿动力Spot)上成功部署,展示了从仿真到现实的可行性。
- 相对之前方法的升级: 从“两步走”到“一步到位”(像素级语义嵌入),从“静态经验”到“动态推理”(实时更新价值地图),从“仿真成功”到“真机落地”。标志着零样本导航从“感知-语言割裂”迈向“多模态共生”。
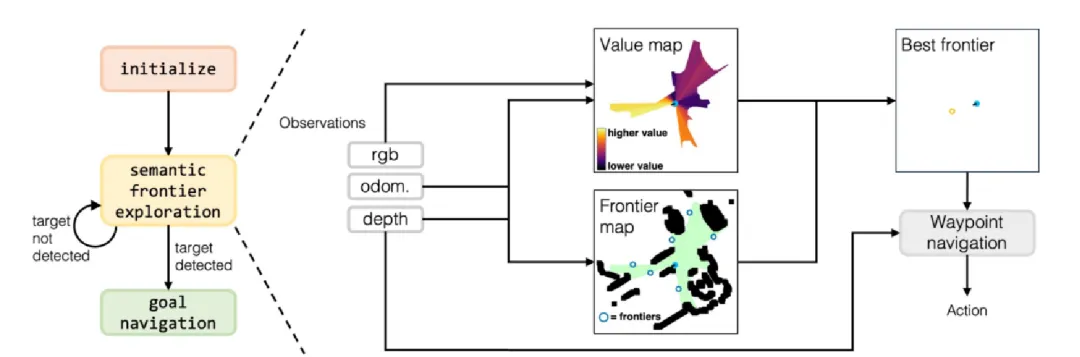
-
LLM/VLM驱动的VLN (更广泛的应用):
- 高级规划: 利用LLM进行子任务分解、常识推理,将指令转化为结构化行动计划。
- 端到端决策: 使用VLM直接进行导航决策,利用其强大的视觉理解和语言推理能力。
- 指令增强/解析: LLM用于理解更复杂、口语化的指令,进行歧义消除。
- 常识注入: 利用LLM/VLM的知识库提供环境布局、物体关系的常识。
- 零样本/少样本VLN: 显著降低对VLN特定标注数据的依赖。
7. 最新进展与前沿趋势 (2023-2025年初)
- LLM/VLM驱动的VLN持续深化: 成为主流,探索如何让模型更好理解空间几何信息,进行更复杂的推理。
- 大规模预训练的持续优化: 设计更有效的VLN相关预训练任务,利用更多样化数据,研究高效适配方法。Vision Transformer (ViT)应用增多。
- 零样本与少样本VLN: 成为研究热点,降低数据依赖。
- 交互式VLN与持续学习: 智能体能主动提问、接受反馈(如HANNA),并在导航中持续学习适应。
- 长距离、复杂指令导航: 处理多步骤、条件判断、复杂推理的指令,提升在更大规模环境中的能力。
- 向真实世界迈进 (Sim-to-Real): 开发更逼真的模拟器,研究域适应/随机化技术,应对真实机器人部署挑战(鲁棒性、安全、实时性)。
- 与其他具身AI任务的融合: 结合物体交互(如Embodied QA, ObjectNav, Manipulation)实现更复杂的任务。
8. 未来研究方向与开放问题
- 更强的泛化能力: 如何真正泛化到迥异的未知环境和指令风格?
- 数据效率: 如何用更少数据训练?无监督/自监督学习潜力?
- 鲁棒性与安全性: 如何处理动态变化、传感器噪声、执行器误差?如何保证安全?
- 可解释性: 如何理解模型决策过程?
- 更丰富的交互: 超越简单指令,实现自然对话、多模态指令。
- 常识与世界模型: 如何融入更丰富的物理、空间、功能常识?构建更完善的世界模型。
- 真实世界部署: 解决硬件限制、实时计算、地图构建更新、长期自主运行等实际问题。
- 评测体系: 开发更全面、反映真实世界能力的评估指标和基准。
- 伦理考量: 数据隐私、机器人行为的社会影响等。
9. 结论
视觉语言导航(VLN)作为一个充满挑战和机遇的研究领域,近年来经历了飞跃式发展。从早期序列模型和强化/模仿学习,到基于Transformer和大规模预训练的架构,再到近期由CLIP及后续LLM/VLM驱动的范式革新,VLN智能体的能力不断提升。R2R、RxR等基准数据集和Habitat等模拟器为研究提供了坚实基础。
然而,尽管取得了显著进展,实现能在复杂、动态、未知的真实世界中根据自然语言指令可靠导航的通用智能体,仍有很长的路要走。未来的研究需在跨模态理解、长期规划、泛化能力、鲁棒性、交互性、常识推理以及真实世界部署等方面持续突破。
VLN不仅推动着人工智能多个子领域的交叉融合,也为我们描绘了未来人机共存、协作的智能图景。随着新一代多模态大模型(如GPT-4o)的涌现和技术的不断进步,我们有理由期待VLN将在机器人助手、智能导览、虚拟现实等领域发挥越来越重要的作用,使机器人不仅能“听懂”指令,更能像人类一样“思考”导航路径,为AI在现实世界的自主决策奠定更坚实的基础。