TorchRec中的Optimizer
文章目录
- TorchRec中的Optimizer
- 前言
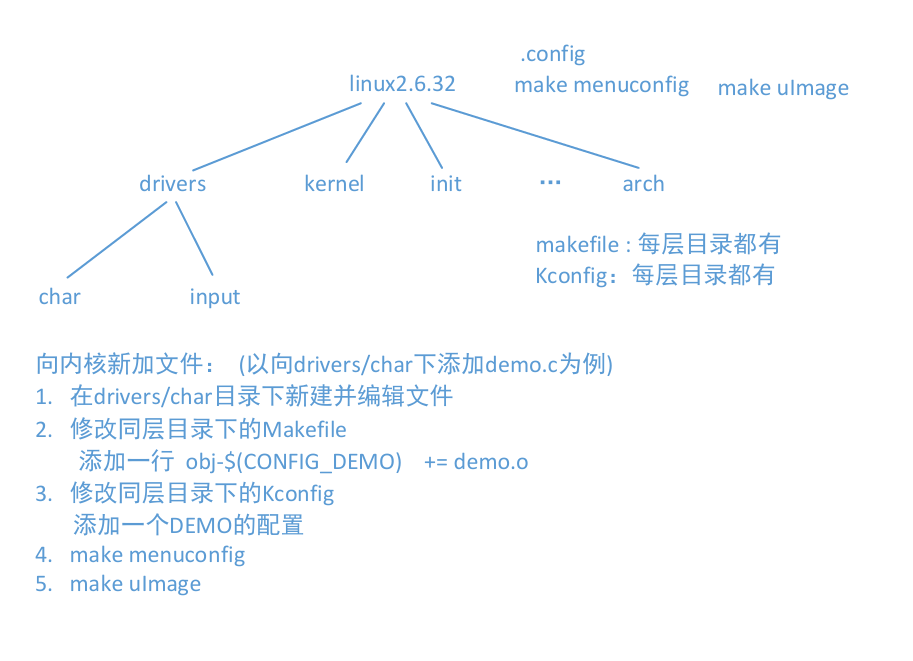
- 一、嵌入后向传递与稀疏优化器融合如下图所示:
- 二、上述图片的关键步骤讲解:
- 三、优势
- 四、与传统优化器对比
- 总结
前言
- TorchRec 模块提供了一个无缝 API,用于在训练中融合后向传递和优化器步骤,从而显着优化性能并减少使用的内存,同时还可以在将不同的优化器分配给不同的模型参数方面提供粒度。
一、嵌入后向传递与稀疏优化器融合如下图所示:

二、上述图片的关键步骤讲解:
-
1、梯度生成(Output Gradient)
- 来自模型前向传播的输出梯度(如损失函数的梯度),对应具体样本(Sample 1 和 Sample 2)
- Sample 1 的梯度可能包含 row 1、row 2和 row 6 的嵌入梯度
- Sample 2 的梯度可能包含 row 1、row 3 和 row 6 的嵌入梯度
-
2、梯度排序(Gradient Sorting)
- 目的 :将不同样本中相同行(Row)的梯度合并到一起,便于后续聚合
- row 1 的梯度来自 Sample 1 和 Sample 2
- row 6 的梯度也来自 Sample 1 和 Sample 2
-
3、梯度聚合(Gradient Aggregation)
- 操作 :对相同行的梯度求和(或平均),得到该行的总梯度
- row 1 的总梯度 = Sample 1 的 row 1 梯度 + Sample 2 的 row 1 梯度
- row 6 的总梯度 = Sample 1 的 row 6 梯度 + Sample 2 的 row 6 梯度
-
4、稀疏优化器(Sparse Optimizer)
- 功能 :仅更新非零梯度对应的嵌入参数(稀疏更新),节省计算和内存。
- 只更新 row 1、row 2、row 3、row 6 的嵌入参数,其他行保持不变。
三、优势
- 1、减少冗余计算
- 通过梯度聚合,避免重复计算相同行的梯度(如 row 1 在两个样本中出现)。
- 2、稀疏性优化
- 只更新实际有梯度的行(如 row 3 只出现在 Sample 2 中),跳过全零梯度的行。
- 3、并行化加速
- 融合反向传播与优化步骤,减少内存拷贝和计算开销。
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
四、与传统优化器对比
| 特性 | 传统优化器 | TorchRec中的稀疏优化器 |
|---|---|---|
| 更新粒度 | 全量参数更新(稠密) | 仅更新非零梯度对应的行(稀疏) |
| 内存占用 | 需存储所有参数梯度 | 仅存储非零梯度 |
| 计算效率 | 低效(大量零梯度参与计算) | 高效(跳过零梯度) |
总结
- TorchRec 的优化器设计通过 梯度排序、聚合与稀疏更新 ,极大提升了稀疏特征的训练效率。
- 这一机制尤其适用于推荐系统中常见的高维稀疏数据场景,是其高性能的核心原因之一。