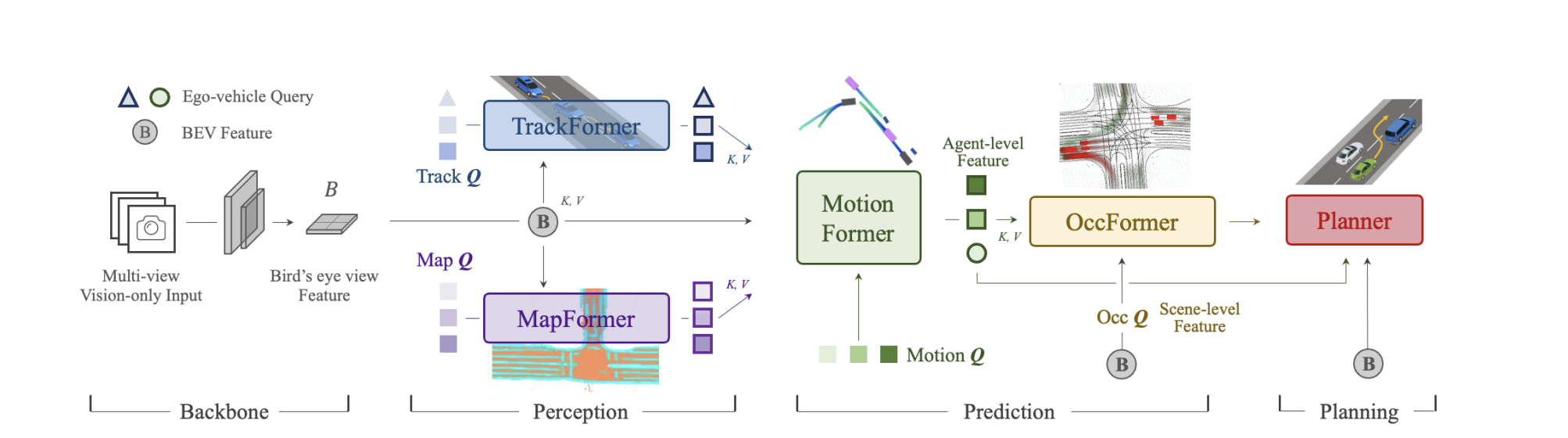
25年3月来自 UC Berkeley 和 Nvidia 的论文“AutoEval: Autonomous Evaluation of Generalist Robot Manipulation Policies in the Real World”。
可规模化且可复现的策略评估一直是机器人学习领域长期存在的挑战。评估对于评估进展和构建更优策略至关重要,但在现实世界中进行评估,尤其是在能够提供统计上可靠结果的规模上,耗费大量人力时间且难以获得。评估日益通才的机器人策略,需要日益多样化的评估环境,这使得评估瓶颈更加突出。为了使现实世界中的机器人策略评估更加实用,本文提出 AutoEval,一个能够在极少人工干预的情况下全天候自主评估通才机器人策略的系统。用户将评估作业提交到 AutoEval 队列,与 AutoEval 交互,类似于使用集群调度系统提交软件作业的方式,AutoEval 将在提供自动成功检测和自动场景重置的框架内调度策略进行评估。
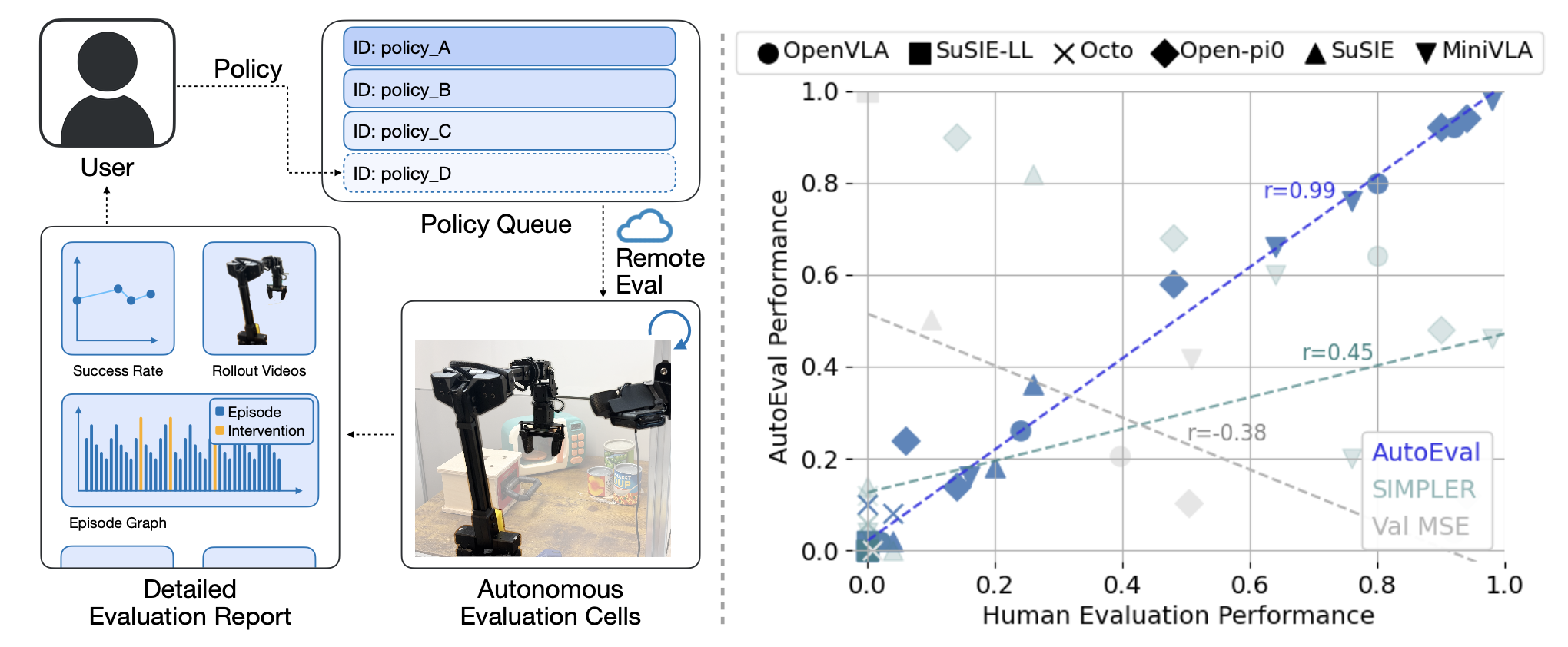
AutoEval 几乎可以完全消除评估过程中的人工干预,实现全天候评估,并且评估结果与手动进行的真实评估结果高度一致。为了促进机器人社区对通才策略的评估,开放多个 AutoEval 场景,这些场景均来自广受欢迎的 BridgeData 机器人配置,并配备 WidowX 机械臂。未来,希望 AutoEval 场景能够跨机构建立,从而形成一个多样化的分布式评估网络。
机器人基础模型有望彻底改变机器人学习的“工作流程”:这些模型不再针对单个任务或环境训练策略,而是在一系列场景、任务和机器人实例中进行训练[13,12,60,36,68,69,21,11,31],从而提供能够在新环境中解决新任务的通才策略。这种向通才训练的转变,必然要求这些策略的评估方式也发生类似的转变。传统的单任务策略评估通常涉及几十次手动可完成的策略部署,而机器人基础模型可能需要在各种任务和场景中进行数百次策略部署,才能准确评估其通才能力。例如,对最近推出的 OpenVLA 模型 [36] 与其基线进行全面评估,需要在四个机器人设置和三个机构中进行 2500 多次策略部署,并且总共需要超过 100 小时的人工来重置场景、部署策略和记录成功率。在模型开发和设计改进过程中进行的评估可能会使这项工作复杂化数倍。
通才机器人策略。近期,在大规模机器人数据集 [16, 77, 35, 68] 的推动下,机器人基础模型取得了重大进展 [13, 36, 60, 34, 24, 9, 50, 3, 69, 81, 11, 63]。这些模型经过训练,可以执行各种任务(例如,取放、折叠衣物)[77, 36, 11, 63],适应具有不同背景和干扰因素的各种场景 [87, 25],并控制多个机器人实例(例如,四足动物、机械臂、无人机)[80, 21]。随着这些通才机器人策略能力的提升,评估变得越来越耗时,因为衡量模型性能需要评估各种不同的技能和场景。例如,Kim [36] 的报告结果需要数千次评估试验和超过 100 小时的人工劳动。开发过程中所需的评估试验可能使这个数字增加数倍。这使得通才机器人策略的开发和全面评估变得越来越具有挑战性,需要一种更具可扩展性的评估方法。
自主机器人操作。先前的多项研究已将人类监督的需求视为机器人学习的一个关键限制因素 [87, 2, 34, 65, 15, 40]。虽然这些研究通常侧重于自主策略改进而非自主策略评估,但它们在机器人重置和成功检测方面面临着许多共同的挑战。因此,用于学习重置策略和成功检测器的许多技术,都受到自主机器人学习领域先前研究的启发,甚至一些指标也是共享的,例如测量人为干预的频率 [6]。虽然大多数机器人学习研究人员都意识到评估的成本,但现有的自动化真实机器人评估的努力,仅限于特定于任务的解决方案,这些解决方案通常涉及环境监测,例如使用弹簧驱动或脚本化的重置机制 [57, 19, 34]。
先前的研究试图通过构建逼真的模拟环境来解决这一评估瓶颈 [46],但模拟环境与现实世界之间的差距可能导致结果不可靠,而且许多任务(如布料或液体操作)都难以以足够的保真度进行模拟。这项工作的目标是开发一个机器人策略评估系统,该系统将现实世界评估的可靠性与评估通才机器人策略所需的可扩展性相结合。现实世界机器人评估可扩展性的一个关键瓶颈,是人类操作员进行评估、重置场景和评估策略成功所需的时间。如果能够将所需的人工参与降至最低,可以通过全天候运行评估来大幅提高真实机器人评估的吞吐量。
为此,本文提出 AutoEval,一个用于设计自主真实机器人评估的系统(如图所示)。要使用 AutoEval,人类用户需要将策略排队等待评估,随后 AutoEval 系统会在极少的人工干预下进行评估。该系统会自动运行策略、评估结果、重置场景,并最终向用户返回详细的评估报告。AutoEval 代表一种现实世界机器人评估的新范式,由于对人工干预的依赖程度极低,吞吐量更高,每次评估的试验次数越多,方差就越小。
设计一个有效的系统来自主评估真实机器人操作策略面临多重挑战,例如需要自主重置场景和成功检测。本文工作利用大型预训练模型来学习自动重置策略和成功检测器。重要的是,会根据评估场景和任务调整这些模型,以实现高可靠性并最大限度地减少人工干预。其提出一种构建自动化机器人评估的通用方案,并在流行的 BridgeV2 机器人评估环境中将其实例化用于常见任务 [77]。
考虑的策略评估问题设置相当简单:给定一个机器人策略 𝜋(𝑎|𝑜, 𝑙),该策略在给定观测 𝑜 和语言指令 𝑙 的情况下输出动作,以及一个任务定义 𝑇 ∶ S → {0, 1},该任务定义将状态映射到任务成功,感兴趣的是估计机器人策略 𝜋 成功完成任务 𝑇 的概率。
策略评估的输出是一个从 0 到 1 的评估分数,表示成功概率。在机器人评估期间,通常要求策略多次执行相同的任务,同时对机器人和环境的初始状态应用随机化,以便在初始状态分布 𝜌(𝑠) 下对策略的性能进行统计上显著的估计。
传统上,人类评估员需要在整个评估过程中在场,监督机器人,在试验之间将场景重置到新的初始位置,并对策略的性能进行评分。每次试验可能只需几分钟,但对于需要在多个任务和试验中进行评估的通才策略,对单个检查点进行全面评估可能很快就会花费数天时间。
用于自主策略评估的 AutoEval 系统,旨在最大限度地减少机器人评估所需的人工时间。在如下算法 1 中概述了 AutoEval 系统。其核心遵循与传统的人工评估相同的结构,运行多个试验,并间歇性地重置和性能评分。然而,AutoEval 引入多个学习模块,可以自动执行通常需要人类评估员完成的任务。 AutoEval 由三个关键模块组成:(1) 成功分类器,用于评估策略在给定任务上的成功程度;(2) 重置策略,用于在试验完成后将场景从初始状态分布重置回某个状态;(3) 程序化安全措施和故障检测,用于防止机器人损坏并在必要时请求人工干预。这三个组件均通过灵活的学习模型实现,因此可以轻松适应各种机器人任务的自动化评估。
成功分类器。成功分类器 C_T ∶ S → {0, 1} 用于近似真实任务成功值 𝑇 ∶ S → {0, 1},将图像状态映射到二值成功标签。 AutoEval 并不像前人工作 [27, 57] 中那样手工制定特定任务的成功规则,而是训练一个学习的成功分类器 C_T,这个方法可以轻松应用于各种机器人任务。具体来说,收集一小组成功和失败状态的示例图像。使用大约 1000 张图像,通过遥操作机器人并将帧保存在轨迹中,收集这些图像只需不到 10 分钟。然后,对预训练的视觉语言模型 (VLM) 进行微调,以完成二进制成功检测任务。给定一个语言提示,例如“抽屉打开了吗?回答是或否”,以及一个图像观察结果,该模型经过训练可以预测任务是否成功完成。使用预训练的 VLM 来获得一个对环境的小扰动具有鲁棒性的分类器,无需收集大量示例图像进行微调。在实践中,使用 Paligemma VLM [8] 来训练成功分类器,但许多其他开源 VLM 也适用。
重置策略。重置策略 𝜋_𝑇 (𝑎|𝑠) “撤销”了评估策略 𝜋 在评估部署过程中执行的操作,将场景和机器人恢复到初始状态分布 𝜌(𝑠) 的状态。同样,AutoEval 的目标并非依赖于弹簧或磁铁等特定于任务的“硬件重置”,而是设计一个能够灵活应用于各种机器人任务的系统。因此,使用学习的策略来重置场景。脚本化的重置策略,也可用于一些结构更复杂的任务,但学习的策略提供了一种更通用的方法,可应用于各种任务。为了学习重置策略,手动收集一小组约 100 条高质量的演示轨迹,这些轨迹根据策略部署成功和失败的合理最终状态重置场景。实际上,此类数据收集通常只需不到两个小时。然后,利用行为克隆对通才机器人策略进行微调,将其作为重置策略。从通才策略检查点开始可确保重置策略更加稳健,并且只需更少的重置演示即可获得可靠的重置。
安全检测器。虽然成功检测器和重置策略在理论上可以实现自主评估,但在实践中,存在许多问题和极端情况会阻碍评估的自主进行,例如机器人硬件故障、场景或机器人损坏,或者物体超出范围。在 AutoEval 中,采用多种措施来预防或妥善处理此类问题。首先,实施机器人受限的安全工作空间边界,因此性能较差的策略不会损坏机器人或 AutoEval 场景。其次,通过程序检查机器人的电机状态,并在电机发生故障(例如由于机器人与环境发生碰撞)时重新启动电机。还训练一个“重置成功分类器”,类似于上面的成功分类器,它可以识别重置是否成功,否则重新运行重置策略。在这两种情况下,如果多次重启或重置失败(例如由于目标从工作区掉落),会实现一个自动通知系统,请求“随叫随到”的人工操作员进行人工干预。实践中表明,对于实现的 AutoEval 单元来说,此类人工干预非常罕见(每 24 小时自主评估仅需 3 次干预)。
设置时间。总体而言,为新任务构建 AutoEval 单元只需 1-3 小时的人工操作,总计不到 5 小时,包括成功分类器的模型训练时间和重置策略。相比之下,即使在单个典型研究项目中,人工评估时间也可以节省数十小时。
这是一个基于 BridgeData V2 数据集 [77, 23] 的自动评估系统实例,该系统适用于多种环境和任务。BridgeData 是一个多样化的操作数据集,包含 60+ 个使用 WidowX 6DoF 机械臂的操作演示,涵盖 13 种不同的技能和 24 种环境。OpenVLA [36]、RT2-X [13]、CrossFormer [21] 和 Pi0 [11, 63] 等最先进的通才操作策略均在 BridgeData 或其超集 [16] 上进行训练,因此,在此设置上进行的策略评估是通才策略可扩展评估方法的天然试验台。
与 Walke [77] 的研究类似,该 Bridge-AutoEval 装置使用配备第三人称 Logitech C920 HD RGB 摄像头的 WidowX 250 6 自由度机械臂来捕捉机器人工作空间自上而下的 256×256 图像,如图所示。使用带有阻塞控制的末端执行器增量动作。

如图所示,构建三个可以并行评估策略的 Bridge-AutoEval 单元,称为抽屉场景、水槽场景和布料场景。在每个机器人站上方使用铝制三脚架灯保持恒定照明。每个场景支持对一到两个操作任务进行评估:抽屉支持评估“打开抽屉”和“关闭抽屉”;水槽支持评估取放任务“将茄子放入蓝色水槽”和“将茄子放入黄色篮子”;布料支持可变形体操作任务“将布料从右上向左下折叠”。虽然 BridgeData 数据集中没有完全相同的场景,但所有场景都包含在 BridgeData 所包含的任务分布中,并且已在先前的研究中用于评估通才策略 [36, 87, 84, 10]。之所以选择这些任务,是因为它们代表不同类型的操作任务:拾取和放置、铰接体操作和可变形体操作。

对于每个场景,按照前面提到的步骤训练成功分类器并重置策略。还为 WidowX 机器人实现了安全检测器,以及一个自动消息传递系统,该系统通过以编程方式向 Slack 频道发送推送通知来请求人工干预,该频道有“随叫随到”的操作员,用于给定的评估班次。
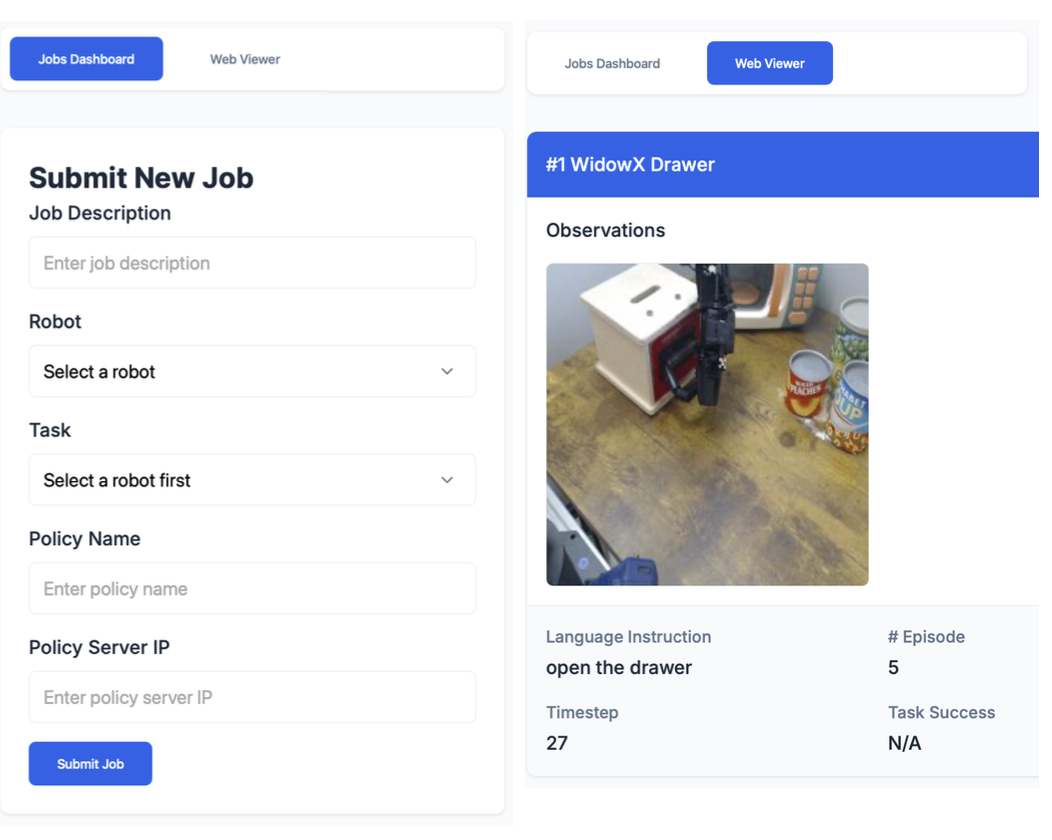
本文工作将两个 Bridge-AutoEval 单元公开,以便其他研究人员可以安排对其策略的评估。随着时间的推移,这将有助于提高机器人评估的可重复性和可比性。为了实现这一目标,提供一个公共的 Web UI,用于访问 Bridge-AutoEval 单元并监控评估进度,如图所示。用户可以选择要执行评估的任务,并提供“策略服务器”的 IP 地址,该服务器负责执行他们想要评估的策略。根据图像观测值和任务指令,服务器将运行该策略并返回一系列 7D 动作供 WidowX 机器人执行(提供在服务器界面中包装用户策略的示例代码)。
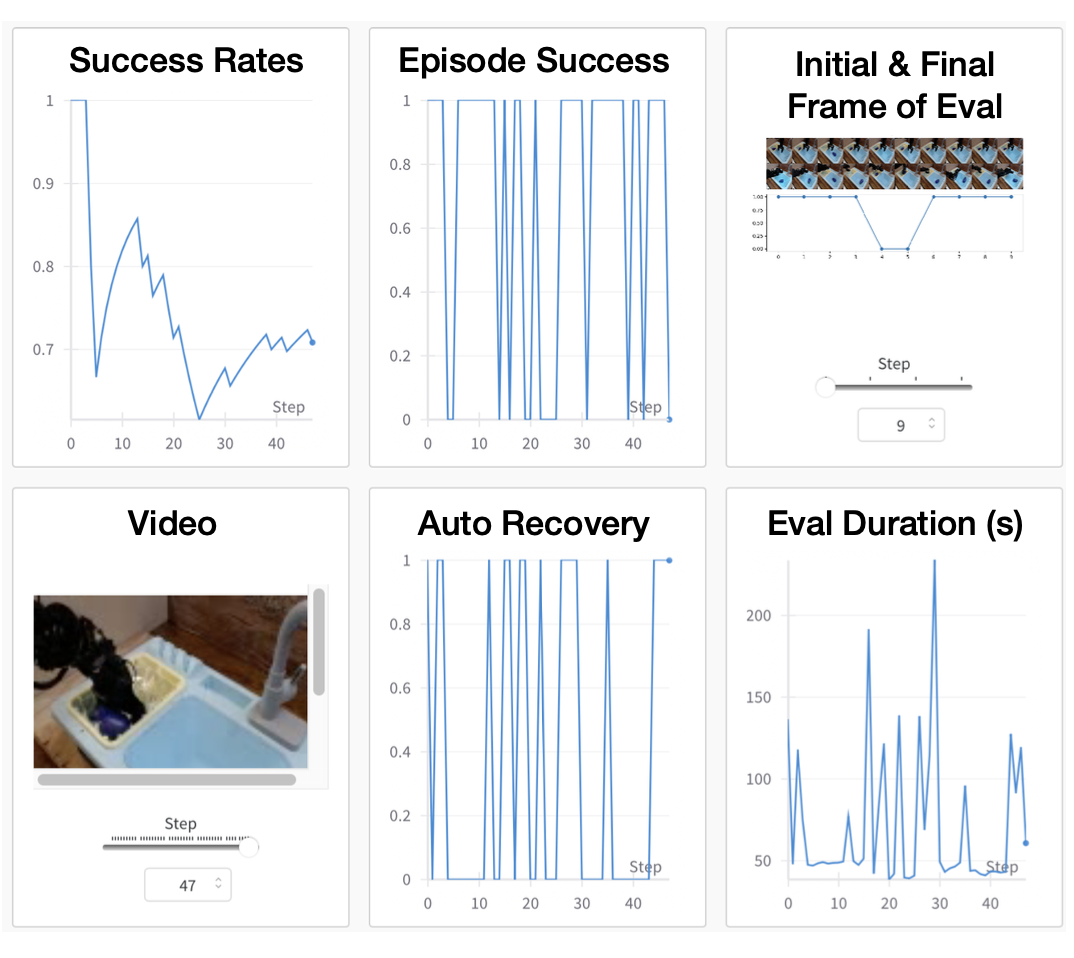
Bridge-AutoEval 系统会自动将待评估的作业排队,并在执行策略评估时向策略服务器查询机器人操作。AutoEval 系统可以全天候运行,并按照提交的顺序执行所有用户的评估作业。在策略评估结束时,AutoEval 会向用户提供可下载的部署数据和自主评估的详细性能报告,其中包含部署视频、成功率、事件持续时间以及电机重置或所需人为干预的频率。如图展示了示例报告的一部分,AutoEval 完成后即可立即在线访问。
实验细节。
任务。基于五项 Bridge V2 [77] 评估任务来评估策略:打开和关闭抽屉、将塑料茄子放入水槽和篮子中以及折叠布料。所有任务均使用 WidowX 6 自由度机械臂执行。在人工评估中,当抽屉完全关闭或打开至少 1.5 厘米时,如果茄子在回合结束时完全放入水槽或篮子中,以及布料折叠至对角线方向至少四分之一处,则视为成功。会在每回合开始时随机化茄子、抽屉和布料的初始位置。
策略。使用机器人社区最近发布的六种通才机器人策略进行评估:OpenVLA [36],一个在 Open X-Embodiment 数据集 [16] 上预训练的 7B 参数视觉-语言-动作模型 (VLA);Octo [72],一个 27M 参数的变换策略,也是在 Open X-Embodiment 上预训练的;Open 𝝅𝟎 [67],一个 3B 参数 𝜋0 VLA [11] 的开源复制品(在撰写本文时,原始𝜋0 尚未开源),在 Bridge V2 数据集上预训练的;MiniVLA [7],一个在 Bridge V2 数据集 [77] 上预训练的 3B 参数 VLA;SuSIE [10],一个将图像扩散子目标预测器与小型扩散低级策略相结合的分层策略,在 Bridge V2 上预训练的; SuSIE-LL 直接执行 SuSIE 中的目标条件行为克隆低级策略。这组策略是当前最先进的通才策略代表性样本。所有策略都包含 Bridge V2 数据集作为其训练数据的一部分,并且评估所有模型公开发布的检查点。
比较。比较多种可扩展的通才策略评估方法。具体而言,将方法 AutoEval 与先前关于机器人操作策略模拟评估的研究 SIMPLER [46] 进行比较。SIMPLER 构建真实世界环境的逼真模拟版本,并纯粹在模拟中评估策略。在本文实验中,将现有的 SIMPLER 环境重用于 Bridge 接收器环境,并按照 Li [46] 的分步指南为抽屉场景(图 6)构建了一个新的 SIMPLER 模拟环境。可变形体(例如布料场景中的布料)通常难以模拟[28, 48],而且在编写 SIMPLER 模拟器 Maniskill [56] 时,它不支持模拟可变形体,因此没有在模拟中评估布料场景。此外,与使用验证集上的均方误差(“val-MSE”)进行比较,将其作为一种可扩展的机器人策略离线评估方法。