第四章. Pandas进阶
4.5 数据转换
数据转换一般包括一列数据转换成多列数据,行列转换,DataFrame转换为字典,列表和元组等
1.一列数据转换成多列数据(str.split函数)
1).语法:
DataFrame.str.split(pat=None,n=-1,expand=False)
参数说明:
pat:字符串,符号或正则表达式,表示字符串分割的依据,默认空格
n:整数,分割次数,默认值-1,0和-1返回所有拆分的字符串
expand:分割后的结果是否转换成DataFrame
2).示例
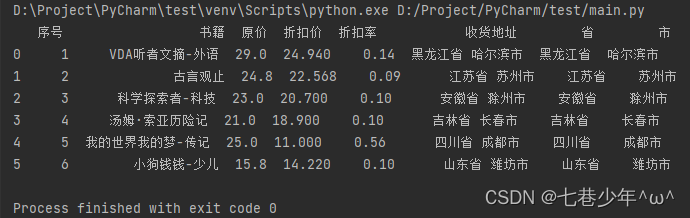
- 示例1:分割收货地址中的"省"“市”
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx')
# 一列数据转换成多列数据
df1=df['收货地址'].str.split(' ',expand=True)
#df = df.join(df1)与df['省']=df1[0] 和 df['市']=df1[1]作用相同
df['省']=df1[0]
df['市']=df1[1]
print(df)
结果展示:
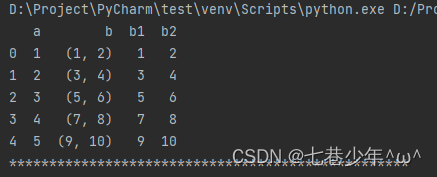
- 示例2:对元组数据进行分割
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx')
# 对元组进行分割
df = pd.DataFrame({'a': [1, 2, 3, 4, 5], 'b': [(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]})
#df = df.join(df['b'].apply(pd.Series))与 df[['b1', 'b2']] = df['b'].apply(pd.Series)作用相同
df[['b1', 'b2']] = df['b'].apply(pd.Series)
print(df)
print('*' * 50)
结果展示:
2.行列转换(stack,unstack,pivot函数)
1).stack函数:
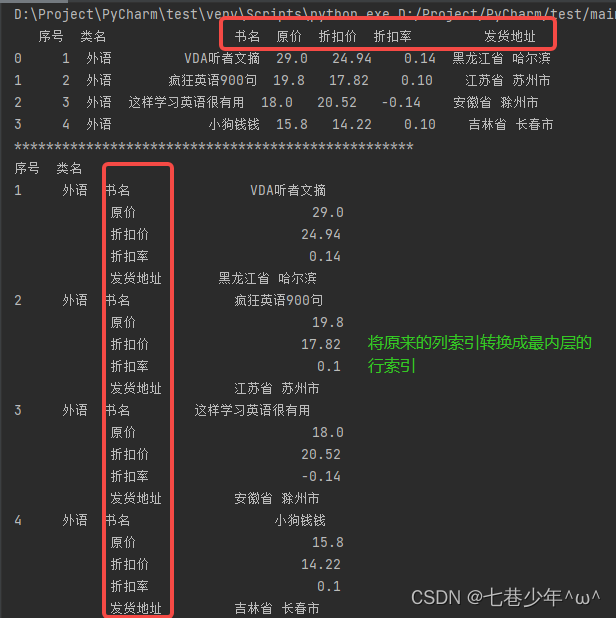
· 作用:将原来的列索引转换成最内层的行索引
· 语法:
DataFrame.stack(level=-1,dropna=True)
参数说明:
level:索引层次
dropna:是否删除缺失值
· 示例:
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx')
print(df)
print('*' * 50)
# stack函数进行行列转换
df = df.set_index(['序号','类名'])
df = df.stack()
print(df)
结果展示:
2).unstack
· 作用:将最内层的行索引转换成列索引,是stack函数的逆操作
· 语法:
DataFrame.unstack(level=-1,fill_value=None)
参数说明:
level:索引层次
fill_value:缺失值的填充值
· 示例:
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx')
print(df)
print('*' * 50)
# stack函数进行行列转换
df = df.set_index(['序号','类名'])
df = df.stack()
print(df)
结果展示:

3).pivot
· 作用:指定某列的值作为行索引,指定某列的值作为列索引,然后指定某列的值作为填充值
· 语法:
DataFrame.pivot(index =None,columns=None,values=None)
参数说明:
index :创建DataFrame数据的行索引
columns:创建DataFrame数据的列索引
values:创建DataFrame数据的填充值
· 示例:
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx')
print(df)
print('*' * 50)
#pivot函数进行行列转换
df1 = df.pivot(index='书名', columns='类名', values=['原价', '折扣价', '折扣率', '发货地址'])
print(df1)
结果展示:

3.DataFrame转换为字典(to_dict函数)
1).示例:
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx')
print(df)
print('*' * 50)
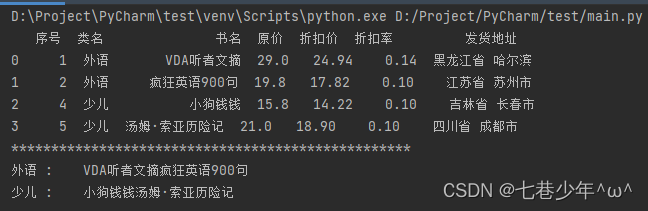
df1 = df.groupby('类名')['书名'].sum()
df1 = df1.to_dict()
for i, j in df1.items():
print(i, ':\t', j)
结果展示:
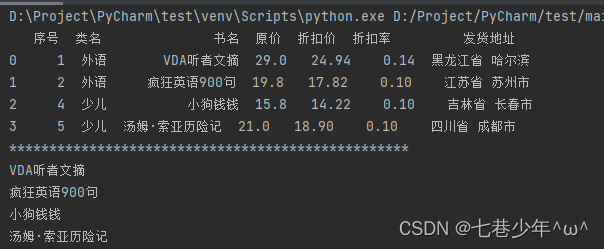
4.DataFrame转换为列表(tolist函数)
1).示例:
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx')
print(df)
print('*' * 50)
df1 = df['书名'].tolist()
for i in df1:
print(i)
结果展示:
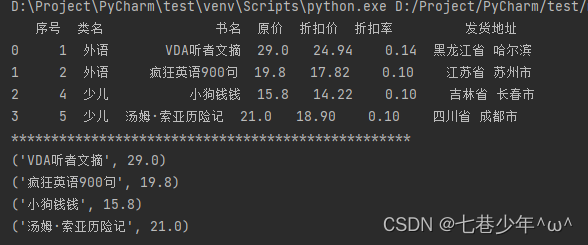
5.DataFrame转换为元组(tuple函数)
1).示例:
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx')
print(df)
print('*' * 50)
df1 = df[['书名','原价']]
tuples=[tuple(i) for i in df1.values]
for i in tuples :
print(i)
结果展示:
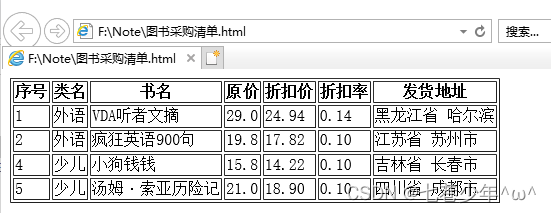
6.Excel转换成HTML网页格式(to_html函数)
1).示例:
import pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True) # 处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.east_asian_width', True) # 无法对齐主要是因为列标题是中文
df = pd.read_excel('F:\\Note\\图书采购清单.xlsx')
print(df)
print('*' * 50)
df.to_html('F:\\Note\\图书采购清单.html',header=True,index=False,justify='center',encoding='gbk')
结果展示:









![[附源码]SSM计算机毕业设计整形美容咨询网站JAVA](https://img-blog.csdnimg.cn/25e39ea3593642e083f179da98882a11.png)
