一、基础概念
- 样本: 所研究对象的单个个体、实例。
- 样本集: 若干样本的集合。
- 类或类别: 在所有样本上定义的一个子集,处于同一类的样本具有相似的性质,即具有相同的模式。
- 特征: 用于表征样本的观测,也称属性。通常是数值表示的某些量化特征,如果存在多个特征,则它们就组成了特征向量。样本的特征构成了样本的“特征空间”,空间的维数就是特征的个数,而每一个样本就是特征空间中的一个点。
- 已知样本: 事先知道所属类别的样本。
- 未知样本: 特征已知,但类别未知的样本。
- 模式识别: 用计算的方法根据样本特征将样本划分到一定的类别。
二、模式识别的主要方法
- 基于知识的方法: 根据人们已知的关于研究对象的知识,整理出若干描述特征与类别间关系的准则,建立一定的计算机推理系统,对未知样本通过这些知识推理决策其类别。
- 基于数据的方法: 确定了样本所采用的特征后,不是依靠人们对所研究对象的认识来建立分类系统,而是收集一定数量的已知样本,用这些样本作为训练集(training set)来训练一定的模式识别机器,使之在训练后能够对未知样本进行分类。
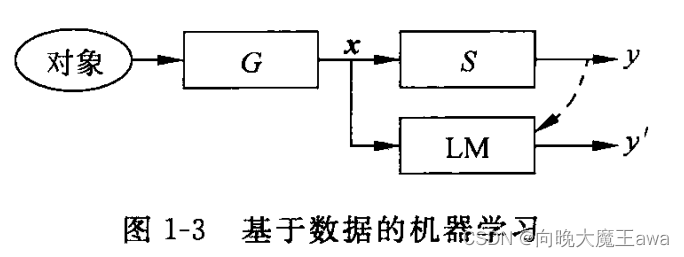
G表示从对象观测特征的过程,特征用向量x表示,y表示对象的性质,S表示决定x和y之间关系的系统,它存在但我们不知道其内部机理(如果知道就可采用基于知识的方法)。首先得到一定数量的已知样本,即一定数量的x和对应的y的数据对{(x, y)}。基于数据的模式识别就是利用这样的训练样本来训练学习机器LM,也就是建立实现从特征向量x判断类别y’的一个数学模型,用来对未知样本计算(预测)其类别。
基于数据的方法是模式识别最主要的方法,具体任务可以描述为:在类别标号y与特征向量x存在一定的未知依赖关系,但已知的信息只有一组训练数据对{(x, y)}的情况下,求解定义在x上的某一函数y’= f(x),对未知样本的类别进行预测。这一函数叫做分类器(classifier)。
三、监督模式识别和非监督模式识别
- 监督模式识别: 在模式识别问题中,需要已知要划分的类别,并且能够获得一定数量的类别已知的训练样本。
- 非监督模式识别: 事先并不知道要划分的是什么类别,更没有一定数量的类别已知的样本用作训练,甚至不知道有多少类别。需要做的是根据样本特征将样本聚成几个类,使属于同一类的样本在一定意义上是相似的,而不同类之间的样本则有较大差异。所得到的类别称作聚类。
四、模式识别的应用
- 语音识别: 识别说话语句的含义,如电话中的语音助手。
- 说话人识别: 识别说话人的身份,如苹果的Siri。
- 字符和文字识别: 识别符号或文字,如图片提取文字。
- 复杂图像中特定目标识别: 识别具体目标。如监控中违章车辆的识别。
五、模式识别系统的典型构成
特征提取与选择、分类器设计或聚类分析、分类器或聚类结果的性能评价方法,是各种模式识别系统中具有共性的步骤,是整个模式识别系统的核心。
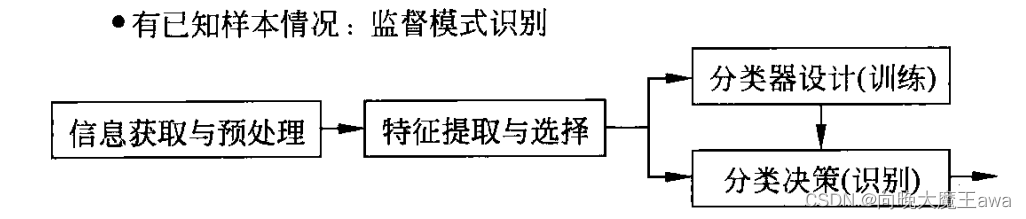
- 特征提取与选择: 得到已知样本,对样进行预处理,获取可能与样本分类有关的观测向量(原始特征)。为了更好地进行分类,可能需采用一定的算法对特征进行再次提取和选择。
- 分类器设计(训练): 选择分类器方法,用已知样本进行分类器训练。
- 分类决策(识别): 利用一定的算法对分类器性能进行评价,对未知样本实施同样预处理和特征提取与选择,用所设计的分类器进行分类。
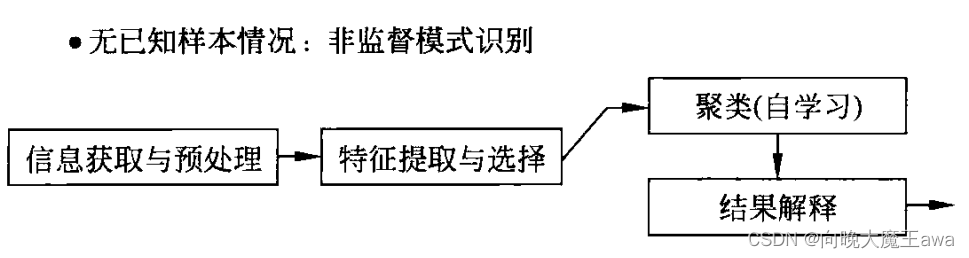
- 特征提取与选择: 得到已知样本,对样进行预处理,获取可能与样本分类有关的观测向量(原始特征)。为了更好地进行聚类,可能需要采用一定的算法对特征进行再次提取和选择。
- 聚类(自学习): 选择非监督模式识别方法,用样本进行聚类分析。
- 结果解释: 检验聚类结果的性能,分析所得聚类与研究目标之间的关系,分析结果的合理性,对聚类的含义给出解释;如果有新样本,把聚类结果用于新样本分类。





![[datawhale202211]跨模态神经搜索实践:跨模态模型](https://img-blog.csdnimg.cn/096bf986a6584da4b670de37d815f06f.png)





![[附源码]java毕业设计农村留守儿童帮扶系统](https://img-blog.csdnimg.cn/70677c50c58d4af59eb4839da22d614f.png)



