1. row_number() over (partition by uid order by dt
分析:
row_number():
- 这是一个窗口函数,用于为结果集中的每一行分配一个唯一的序号。
- 默认情况下,这个序号是按照查询结果的顺序来分配的,但你可以通过
OVER()子句中的ORDER BY来指定排序方式。OVER(PARTITION BY uid ORDER BY dt):
OVER()子句定义了窗口函数的操作范围和行为。PARTITION BY uid:这会将结果集按照uid字段的值进行分区。也就是说,每一个唯一的uid值都会被视为一个独立的分区,然后在每个分区内部分配序号。ORDER BY dt:在每个分区内部,序号会按照dt字段的值进行排序。dt很可能是一个日期或时间字段,但不一定是。rn:
- 这是你为
row_number()函数的结果分配的列名。在查询的结果集中,你会看到一个名为rn的列,其中包含了为每一行分配的序号。这个表达式
row_number() over (partition by uid order by dt) rn的作用是为查询结果集中的每一行分配一个序号,这个序号是基于uid字段进行分区并在每个分区内部按照dt字段进行排序的。
输出:
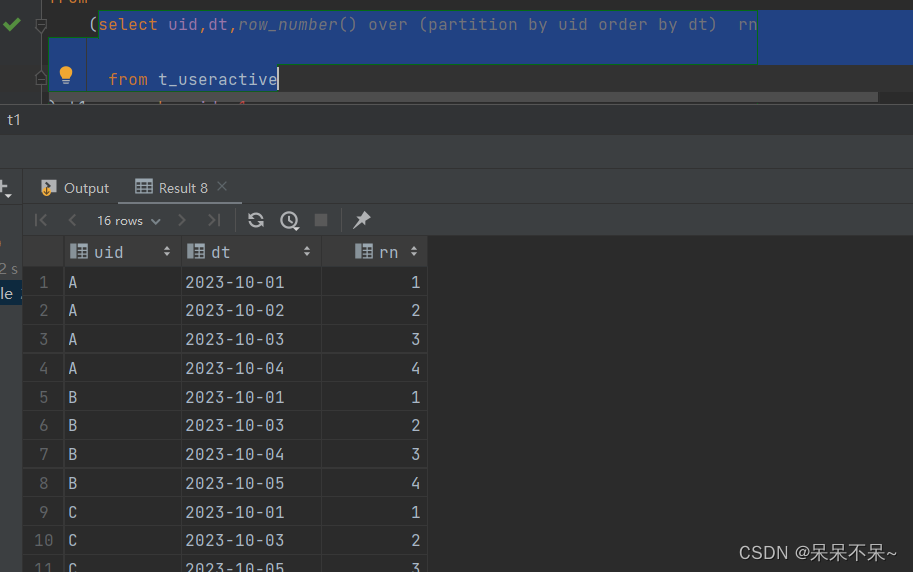 2. date_sub(date, INTERVAL expr unit)
2. date_sub(date, INTERVAL expr unit)
分析:
date_sub是一个函数(在某些数据库系统中,如 MySQL),用于从一个日期中减去一个时间间隔。在这里,date是你想要从中减去的日期,expr是你想要减去的数量,而unit是时间单位(例如 DAY, HOUR, MINUTE 等)。
输出:

3.datediff:日期比较
select datediff('2023-10-03','2023-10-01') -- 输出2
4.date_add / date_sub:日期增加/日期减少
select date_add('2023-10-03',1) -- 输出2023-10-04
select date_sub('2023-10-03',1) -- 输出2023-10-02
5. lag(order_date,1,order_date)
分析:
order_date:这是你想从前一行检索的列名。1:这是你想检索之前多少行的值。在这个例子中,它是 1,意味着你想检索前一行的值。order_date:这是当没有前一行可检索时(例如,对于结果集的第一行)的默认值。在这个例子中,如果当前行是第一行或者没有前一行,那么lag函数将返回当前行的order_date值作为默认值。


![[Linux]Crond任务调度以及at任务调度](https://img-blog.csdnimg.cn/direct/ae4d77323e2b4799bcb8724645bf2579.png)