文章目录
Hi, 你好。我是茶桁。
上一节课,咱们用一个员工离职预测的案例来学习了LR和SVM。
那今天咱们还是来看案例,从案例来入手。那今天的例子会带着大家一起来做一个练习,是一个男男女声音识别的例子。数据集来自于3,168个录音的样本,有些男性和女性,采集了一些特征,特征都是跟频谱相关的,一共有21个属性,去基于这个属性来预测声音是男还是女。指标是以Accuracy为评价指标。
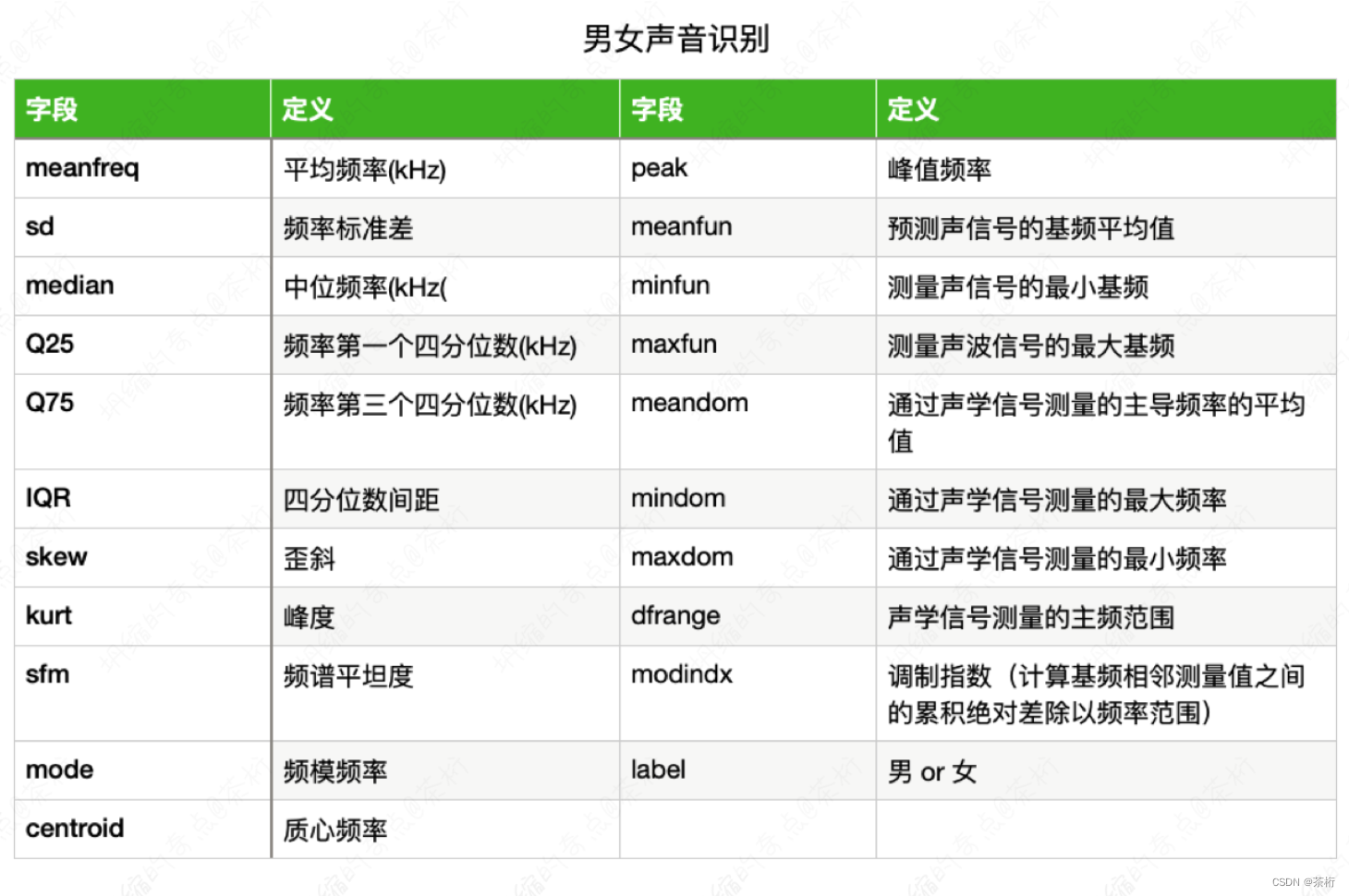
我们看一看,这个例子我们该怎么去用刚才的模型来解答?可以先看一看要预测是哪一个字段,就是label字段。除了label字段以外,其他的类型都属于我们的特征类型。
想基于这个特征来预测label思路是啥?先梳理一下思路。我们想想,跟上一节课的流程是一样的,如果对之前的那个离职预测问题能清楚它的结构的话。那这里我们的结构也是先去加载,加在以后去预处理。预处理环节先看看数据长什么样,尤其是那个target,就是这个label标签,平均还是不平均等等。
如果它是一个非数值类型需要给它做个映射,要采用这个SVM或者是LR这两种模型,跟距离有没有关系?就这个模型的运算流程跟距离有关系吗?是有关系的。
SVM可以把它理解成是跟平面的距离,就是这个坐标跟超平面的那个距离是有关系的。LR是个分类器,它本身是跟线性回归相关的,它也是一条线,所以它跟距离也有关系。
这两个模型跟距离计算是有联系的,所以我们需要先做一个归一化的处理,归一化处理以后去调包,调包以后就可以完成预测。就是这样一个任务。
这个任务我们一起来写写代码,大家可以熟练一下,看看这个流程。
这是一个csv数据集,voice.csv。老样子,文末有数据集地址。
dataframe = pd.read_csv('data/voice.csv')
dataframe.head()
---
meanfreq sd median Q25 Q75 IQR skew kurt sp.ent sfm ... centroid meanfun minfun maxfun meandom mindom maxdom dfrange modindx label
...
5 rows × 21 columns
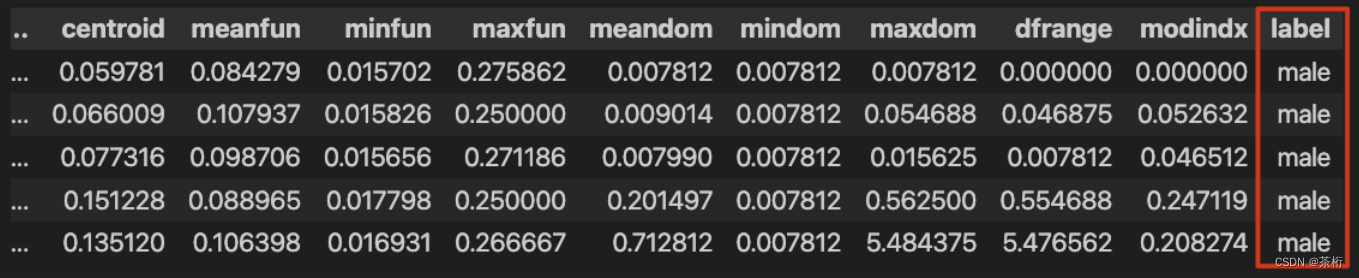
查看一下数据集的头部,来大概了解一下数据。一共大概有21个词段, 最后是label。label现在是male和female。除此之外,还有哪些比较常见的数据探索呢?比如说缺失值个数,是通过isnall加sum来做判断的:
# 缺失值个数
print(dataframe.isnull().sum())
# 矩阵的大小
print(dataframe.shape)
---
meanfreq 0
...
label 0
dtype: int64
(3168, 21)
打印出来查看的结果,所有数据没有缺失值。大小是3168个,21个指标,没有问题。也可以只使用shape[0]来查看样本个数。
然后我们还要查看一下样本个数分别男女各是多少,使用label来做一个判断进行筛选:
print('男性个数:{}'.format(dataframe[dataframe.label=='male'].shape[0]))
print('女性个数:{}'.format(dataframe[dataframe.label=='female'].shape[0]))
---
男性个数:1584
女性个数:1584
男性1,584,女性1,584,所以这个数据是不是比较规整,它属于一个均衡的一个样本,而且它没有缺失值。
那下面要去建模之前先要把它分割成为特征,就是提取特征列和目标列。目标列可以把它称为叫label列或叫target
X = dataframe.iloc[:, :-1]
那咱们在Python基础课里有教授过Python相关的切片操作,这里面[:, :-]前面一个冒号代表是的取所有行,后面:-1是除了最后一列之外。那为什么要去掉最后一列呢?因为最后一列是label,本来就是我们的目标列,在特征数据集内不应该存在目标。所以我们新的数据集不应该存在这一列。
那相对的,如果我们是要单独提取一个目标集,那就该反过来写:
y = dataframe.iloc[:, -1]
现在X和y就分别是我们的特征列和目标列。在调包之前一个很关键的过程就是把特征和目标提取出来,那么我们就用了iloc的方式,通过-1的方式给他做了个提取。
这些特征刚才说了,我们在用模型,如果你用LR模型的话跟距离相关,我们还要做什么操作呢?还要给它做一个归一化操作。label现在是male和female,还要给它做一个标签编码方式,还是使用sklearn里面的LabelEncoder,定义一个gender_encoder,用它来做一个fit和transform。fit是先指定我们的标签关系,然后transform来做一个应用。
# 使用标签编码
gender_encoder = LabelEncoder()
print(y)
y = gender_encoder.fit_transform(y)
print(y)
---
0 male
...
3167 female
Name: label, Length: 3168, dtype: object
[1 1 1 ... 0 0 0]
我们把前后的y都打印出来查看一下区别。可以看到之前打印出来的是male和female,字母的形式,在操作之后就变成了1和0.所以1代表的是male,0代表的是female。这是我们编码的一个映射。需要把所有的这个类别特征转化成为数值。
然后在运行机器学习模型之前,尤其是跟距离相关的,我们还需要给它做归一化操作。数据归一化。我们这里用另一种归一化方式: StandardScaler, 也是一样的,叫正在分布归一化。都是给它做了一个标准化操作.
# 数据归一化
scaler = StandardScaler()
# 对原时特征进行归一化
scaler.fit_transform(X)
print(X)
---
[[-4.04924806 0.4273553 -4.22490077 ... -1.43142165 -1.41913712
-1.45477229]
...
[-0.51474626 2.14765111 -0.07087873 ... -1.27608595 -1.2637521
1.47567886]]
一样,先定义一个scaler,然后用它去fit和transform我们的X,这个是对原始特征进行归一化。
归一化以后再把它喂回来,打一下我们的X看一下归一化之后的结果是什么样。正态分布归一化之后,均值就变成了0,所以它有可能小于0,也可能大于0。
这个数据归一化是因为我们用了一个叫做正态分布归一化,正态分布的话,它的归一化是以0为中心点,下图这样的曲线:
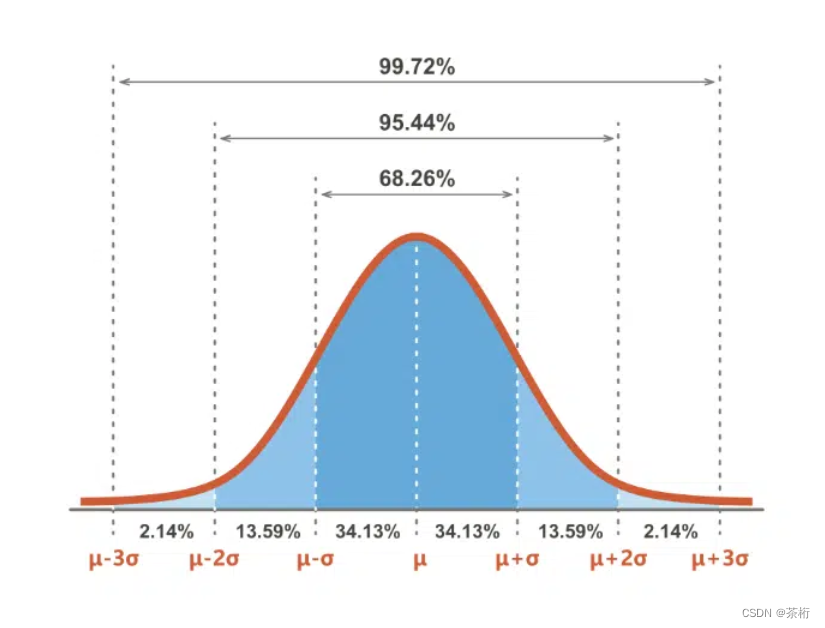
这个中心点 μ \mu μ是0,方差为1。所以我们就把它变成了这样的正态分布了,所以有没有小于0的?一定要有的。
正态分布有一个叫3Sigma原则,正1和-1之间的这个范围大概是68%,这叫1Sigma,2 Sigma的话是95%,3 Sigma是99.7%。所以它不是一个-1到1的结果,正态分布它是有可能小于-3的,也可能大于3,只是概率比较小。
如果我不用它,我用MinMaxScaler会有小于0的吗?我们来设置一下,这里scaler改为MinMaxScaler。
# 测试归一化
scaler = MinMaxScaler()
X = scaler.fit_transform(X)
print(X)
---
[[9.64185977e-02 4.73408557e-01 8.41252523e-02 ... 0.00000000e+00
0.00000000e+00 0.00000000e+00]
...
[5.95699639e-01 7.68963896e-01 6.87590032e-01 ... 2.50178699e-02
2.50357654e-02 3.75385802e-01]]
再看一看这个结果, 这个结果有可能小于0吗?不会。
后面就是用数据集切分。还是一样,20%测试集,给一个随机种子数, 我还是使用今年年份2023.
# 数据集切分
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.2, random_state=2023)
数据切完之后现在要做数据建模了,这里建模你可以用逻辑回归也可以用我们的SVC。
# 数据建模
svc = SVC()
# 模型训练
svc.fit(X_train, y_train)
# 用训练好的模型进行预测
y_pred = svc.predict(X_test)
print('SVM 预测结果:{}, \n 准确率: {}'.format(y_pred, accuracy_score(y_test, y_pred)))
---
SVM 预测结果:[1 0 1 ... 0 0 0],
准确率: 0.9715976331360947
这里用的是个非线性的SVC, 创建模型SVC之后就fit,这个就是模型训练。
之后模型预测是把刚才训练好的这个结果去做一个predict,用训练好的模型进行预测得到我们预测的结果,得到预测结果还要判断一下预测结果的准确性。我们先把结果打印出来,SVM的预测结果。再看一看它的准确率。
准确率我们用了accuracy_score,帮你计算它的准确性,把测试集的数据和预测的结果y_pred来对比判断一下。可以看到预测的结果,1为男性,0为女性。然后准确率达到了百分之97以上,这个结果还是比较好的。当然,这个数据集也比较的简单。
好,我们再回过头来说说归一化的问题,和上一节课不同,我们这次使用的是一个正态分布的方式去做归一化。这两个哪个好哪个不好,没有统一的标准。没有说正态分布或者是0-1分布的归一化哪个更好,都可以尝试。找适合的数据集。只不过是让它变得更加标准化,看看是不是方便你去找到它的规律。没有一个特别的规范还说明说该用哪一个不该用哪一个,这两个其实都可以。
如果真是要说一下区别的话,我个人感觉正态分布更关注于人的一些属性。比如说人的身高、体重这种就比较偏向于正态分布,它更有可能找到好的结果。
那作为归一化处理,也仅仅是处理特征。我们称呼其为weight, 也就是权重。整个流程中,y是不需要进行归一化的。回到刚才的例子里,一共有21个特征,除了最后一个以外的话应该就是20个特征。20个特征里面如果用它原始的数值,比如说它是0到1,000,另外一个是0到10,那它就自带的weight会很高,第一个是第二个的100倍。所以对于X来说,如果不给它做归一化,它的量纲就不统一。那我们就让它的weight都一样,就每个特征它的权重大小都是一致的。然后放到模型里面跟y来做对比就可以。
我们再换个场景,如果我们做的是一个树模型。大家知道最经典的数模型是CART,如果我们用CART角色树来做分类的话,请问需要提前做归一化操作吗?就是对我们的X都要转化,比如说转化成0-1之间区间范围吗?
因为数模型的计算原理与距离无关,它的原理是跟距离没有关系的。它跟顺序有关系跟你的大小没有关系,所以对树模型来说的话你做不做对它的结果没有影响。但是对于LR、SVM来说做不做会有影响,因为它的权重不一样。
好这是刚才我们整个的流程,刚刚就把整个的流程给大家梳理清楚了,现在这道题目跟上节课里那个离职预测的题目基本上是一致的过程。
这两个例子如果你能看明白,下来自己也能把它跑通,基本上机器学习应该就算入门了。比如说你至少能会调包去使用了,而且对它的流程,过程原理还是清楚的。这个是希望大家能明白它的整个过程原理。
那现在我们再给大家对比一下刚才我们两个项目讲解的两种分类器。一种叫LR,它的这个速度比较快,比较简单,通常用于我们的工业问题上。因为它速度快、资源少,而且方便调整,这是它的优点。
缺点是啥,刚才说了有20个特征,男女声音识别有20个特征。那请问LR里面要学的参数量有多少?他要学习的一共就是20+1个。针对这样的模型速度比较快,同样的代价就是容易欠拟合,准确性不高。有可能学的不好。
我们来看一下LR的准确性如何
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy_score(y_test, y_pred)
---
0.9692307692307692
可以看到,看到我们这两个模型里面,LR准确性是稍微差一点。虽然也有97%了,但它的准确性是比较差的。
对于非线性模型为什么它差,是因为它不好发现非线性的特征。那谁可以发现?SVM可以发现。因为SVM的原理就是把低维映射到高维,更容易找到非线性的特征。
处理非线性的特征同样要做数据归一化处理,因为它跟距离相关,刚才给大家讲过。
SVM的缺点是啥?效率低,刚才速度快的原因是因为样本数不多,如果样本数变成了10万个再去看一看速度,它可能需要十几秒几十秒。那对于LR来说照样速度会很快。
缺点二,你要做的是个非线性的映射,但不代表每次都能找到这样的一个映射。好的关系如果没有找到就得到不了很好的结果,所以非线性映射没有统一方案,可能很难找到合适的核函数。
我们有了四种kernel,这四种kernel都可以尝试。但这四种有可能都不属于最终的解。所以这个kernel没有统一的方案。
另外我们选择kernel还是有一点小的技巧的。比如说我们的样本数量比较小的情况下用简单的线性核,多的情况下就要用复杂的非线性核。
每种模型都有自己的适用场景,建议大家未来在工作过程中可以先用简单的模型跑一遍,比如说LR模型。它作为我们预测模型的baseline,baseline我们也把它称为叫做基线。基线就是速度快、简单、效果还可以。不能说好,它的目的不在于好而是在于快,可以拿到一个60分的结果。有了baseline以后再去做复杂的模型,可以知道复杂模型到底好
还是不好。
比如说LR刚才那个模型,97%这是个baseline。用SVM得到98%就可以知道它比baseline要高。如果你直接上了一个复杂模型,我们也无法对比。所以可以先用基线来做一个参考。
常见预测模型除了刚才说的分类模型以外其实还有树模型。树模型之后会详细给大家介绍,这个模型的模块是主要的内容,因为在未来的比赛过程中或项目过程中想要得到好的结果,还是要用到一些复杂的模型。
好,基本上,我们利用两个项目就基本介绍完了咱们最基本的LR和SVM。和之前讲解机器学习基础原理不同,我们现在主要是基于案例来看具体我们该怎么应用。
下一节课,咱们来看看几个机器学习神器。
链接: https://pan.baidu.com/s/1UgXmDZLOpVeXz21-Ebddog?pwd=5t4e 提取码: 5t4e
–来自百度网盘超级会员v7的分享


![[足式机器人]Part2 Dr. CAN学习笔记-Ch01自动控制原理](https://img-blog.csdnimg.cn/direct/0d4633f990284b3195ec45cf02c2c0eb.png#pic_center)