文章目录
- Abstract
- Introduction
- 现有工作的不足
- 为了解决上述问题
- 主要贡献
- Methodology(方法论)
- PROBLEM FORMULATION(问题公式化)
- LEARNING DISCRETE WHOLE - BODY REPRESENTATIONS(学习离散的全身表征)
- Vanilla Motion VQ-VAE
- Holistic Hierarchical VQ-VAE
- HIERARCHICAL WHOLE - BODY MOTION GENERATION(分层的全身运动生成)
- Facial conditional VAE
- PRE-TRAINED TEXT-MOTION RETRIEVAL MODEL AS A PRIOR(作为先验的预训练文本运动检索模型)
- MODEL TRAINING AND INFERENCE(模型训练和推理)
- Model Training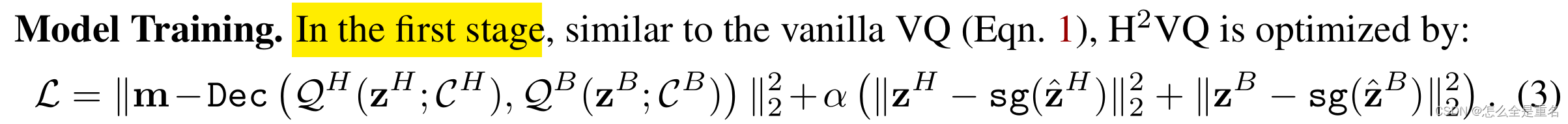
- Model Inference
- Experiments
- Conclusion
原文链接
源代码
Abstract
这项工作的目标是一种新的文本驱动的全身运动生成任务,该任务以给定的文本描述为输入,旨在同时生成高质量、多元和连贯的面部表情、手势和身体运动。以往关于文本驱动运动生成任务的工作主要存在两个局限性:忽略了细粒度手和面部控制在生动的全身运动生成中的关键作用,缺乏文本和运动之间的良好对齐。为了解决这一具有挑战性的任务,我们的解决方案包括两个关键设计:(1)一个整体分层VQ- VAE(又名h2 VQ)和一个分层GPT,用于细粒度的身体和手部运动重建和生成两个结构化代码本;(2)预训练文本-运动-对齐模型,帮助生成的运动与输入文本描述明确对齐
Introduction
近年来,在游戏、电影、动画和机器人等许多场景中,对生成高质量3D人体运动的巨大需求呈爆炸式增长。为了减少动画创作的费力工作,最近的研究尝试以自然交互的方式生成带有文本描述的人体动作,并在相关研究领域取得了快速进展
现有工作的不足
然而,从现有的工作中产生的运动仍然不能满足实际应用的需要。这个问题主要是由于两个方面:
首先,现有的文本驱动运动生成模型只能生成单体运动,而不能生成全身运动,具有很强的表现力,但也更具挑战性
其次,生成的动作与文本描述缺乏语义一致性
为了解决上述问题
我们提出了一个新的文本对齐的整体运动生成工作框架(HumanTOMATO),该框架包括两个关键设计:
首先,提出了一种身体和手部运动的整体分层离散建模策略,以生动地重建和生成全身运动
在第一阶段,我们提出了一个整体分层VQ- VAE(又名h2 VQ),将运动分别压缩为身体和手的两级离散代码
在第二阶段,我们提出了一个分层GPT以自回归的方式预测身体和手的层次离散码
其次,首次引入预训练文本-运动对齐模型,增强生成运动的文本对齐
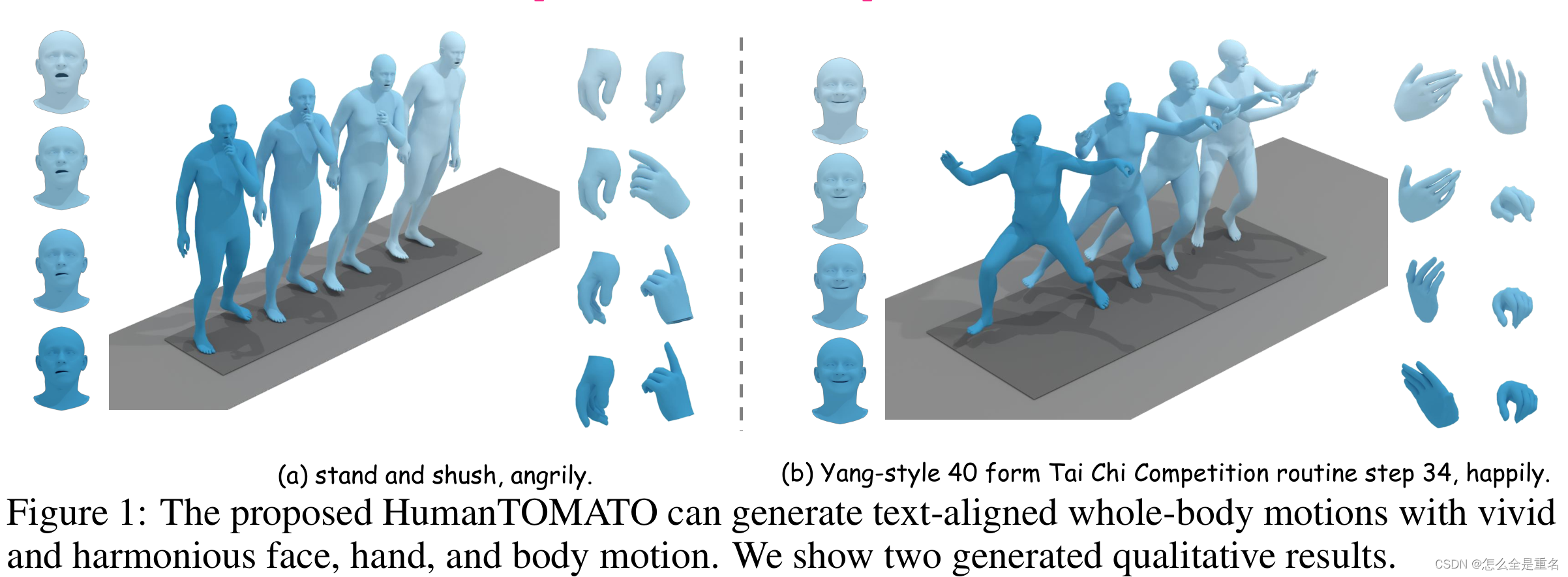
(提出的HumanTOMATO可以生成与文本对齐的全身动作,面部、手部和身体的动作生动和谐。我们展示了两个生成的定性结果)
通过这些关键设计,与之前的文本驱动运动生成作品相比,HumanTOMATO可以生成语义上与文本描述一致的全身运动,如图1所示
主要贡献
1.据我们所知,我们首次提出了具有挑战性的文本驱动全身运动生成任务,并设计了一个模型(HumanTOMATO)来生成与文本很好地对齐的生动的全身运动
2.为了解决具有挑战性的全身运动生成问题,我们引入了用于细粒度身体和手部运动重建的h2 VQ。因此,我们开发了一种结合面部cVAE的分层gpt来产生全身运动
3.为了增强文本和运动之间的一致性和对齐,我们通过对比目标预训练文本-运动对齐编码器,并引入序列级语义监督来帮助运动-文本对齐
4.我们提出了两个新的标准(TMR-R-Precision和TMR-Matching-score),它们对评估文本-运动对齐更加准确和具有挑战性
Methodology(方法论)
PROBLEM FORMULATION(问题公式化)
我们澄清了符号,建立了文本驱动全身运动生成的新研究问题。给出一个人类动作的文字描述,比如“这个人正在愉快地弹着尤克里里。”,则模型应生成一个与文本描述对齐的生动的全身运动m = [m1, m2,···,m L]∈R L×d,其中L和d分别表示该运动在每一帧中的帧数和尺寸。由于全身运动涉及手、身体和面部运动,我们也可以将m分别分解为{mH,mB,mF},其中mH∈R L×dh,m B∈R L×db,m F∈R L×d F,d = d H + d B + d F。在数学上,我们将文本驱动的全身运动生成表述如下:

式中Θ为模型参数,P Θ(·)为运动分布
在2.2节中,我们首先介绍h2 VQ来学习身体和手的细粒度离散运动代码。然后,我们在第2.3节中提出了分层gpt模块,该模块旨在预测全身运动的文本对齐离散运动代码。由于面部表情通常对文本描述具有确定性,因此我们采用Petrovich et al.(2022)中描述的方法来训练面部条件VAE,从而直接生成详细的表情。对于全身运动的生成,我们整合了身体、手和脸的运动来产生最终的输出。值得注意的是,在介绍我们的hierarchal - gpt时,我们还在第2.4节中探讨了文本到全身运动检索模型如何明确地有利于文本-运动对齐
LEARNING DISCRETE WHOLE - BODY REPRESENTATIONS(学习离散的全身表征)
Vanilla Motion VQ-VAE
运动VQ-VAE旨在以编码解码的方式学习人类运动的离散表示。具体来说,VQ-VAE通过使用自编码器恢复运动,并学习一个码本C = {e k} k k=1,其中k表示码本大小,e(k)表示码本中嵌入的第k个表示。给定一个矢量z和量化器Q(·;C),量化后的矢量应为码本C中选取的能使重构误差最小的元素,为
在vanilla VQ-VAE中,z = Enc(m)表示从运动编码器Enc(·)中提取的潜在代码。因此VQ-VAE可以通过
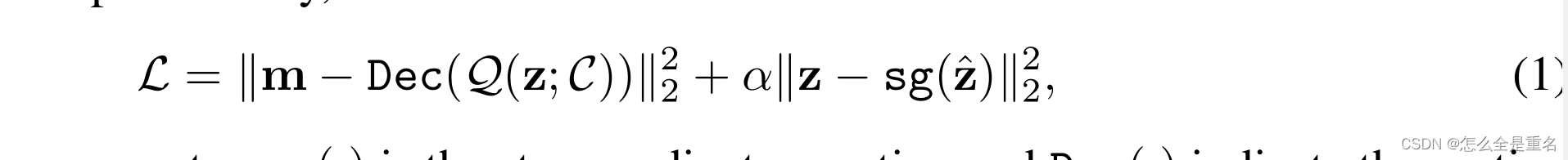
其中,α为超参数,sg(·)为停止梯度运算,Dec(·)为运动解码器
Holistic Hierarchical VQ-VAE
受此启发(dsamossez等人,2022),我们提出了一种新的整体层次矢量量化方案,简称h2 VQ,用于运动生成领域。与RVQ不同,我们在h2 VQ建模之前结合了运动学结构,使其能够以极低的比特率学习细粒度全身运动的紧凑表示。鉴于身体和手部运动在幅度和频率上的明显差异,我们进一步设计了两个独立的编码器和码本来学习身体和手部运动的离散表示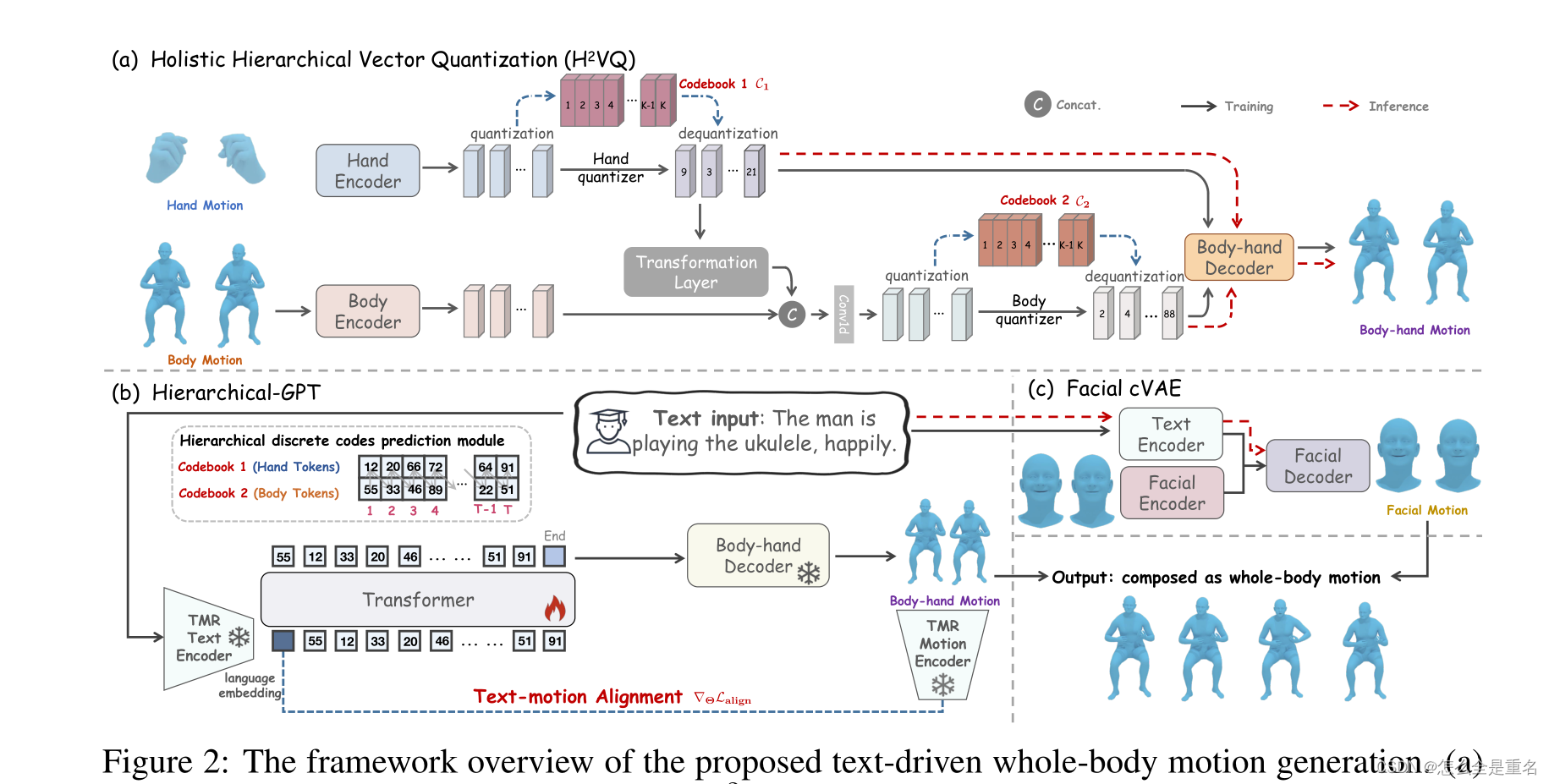
(a)整体层次矢量量化(h2vq),将细粒度的体手运动压缩成两个具有层次结构关系的离散码本
(b)层次化gpt,使用运动感知文本嵌入作为输入,层次化地生成手-体运动
©面部文本-条件VAE (cVAE)生成相应的面部动作。身体、手和面部运动的输出组成了一个生动的、与文本对齐的全身运动
HIERARCHICAL WHOLE - BODY MOTION GENERATION(分层的全身运动生成)
为了更好地模拟手-体运动的自然一致性,我们设计了一个分层离散代码预测模块,名为hierarchy - gpt,如图2(b)所示,用于生成手-体运动
Facial conditional VAE
在TEMOS (Petrovich et al., 2022)的激励下,我们的面部cVAE如图2©所示,由一个面部编码器、一个文本编码器和一个面部解码器组成,并对面部重建损失、KL损失和交叉模态损失进行了优化。在推理阶段,给定文本描述,文本编码器和运动解码器将根据给定文本中的表达和运动长度产生不同的面部运动
PRE-TRAINED TEXT-MOTION RETRIEVAL MODEL AS A PRIOR(作为先验的预训练文本运动检索模型)
在现有的预训练模型中,由于文本和运动的内容表示粒度不同,文本的表示与相应的运动之间往往存在明显的语义差距
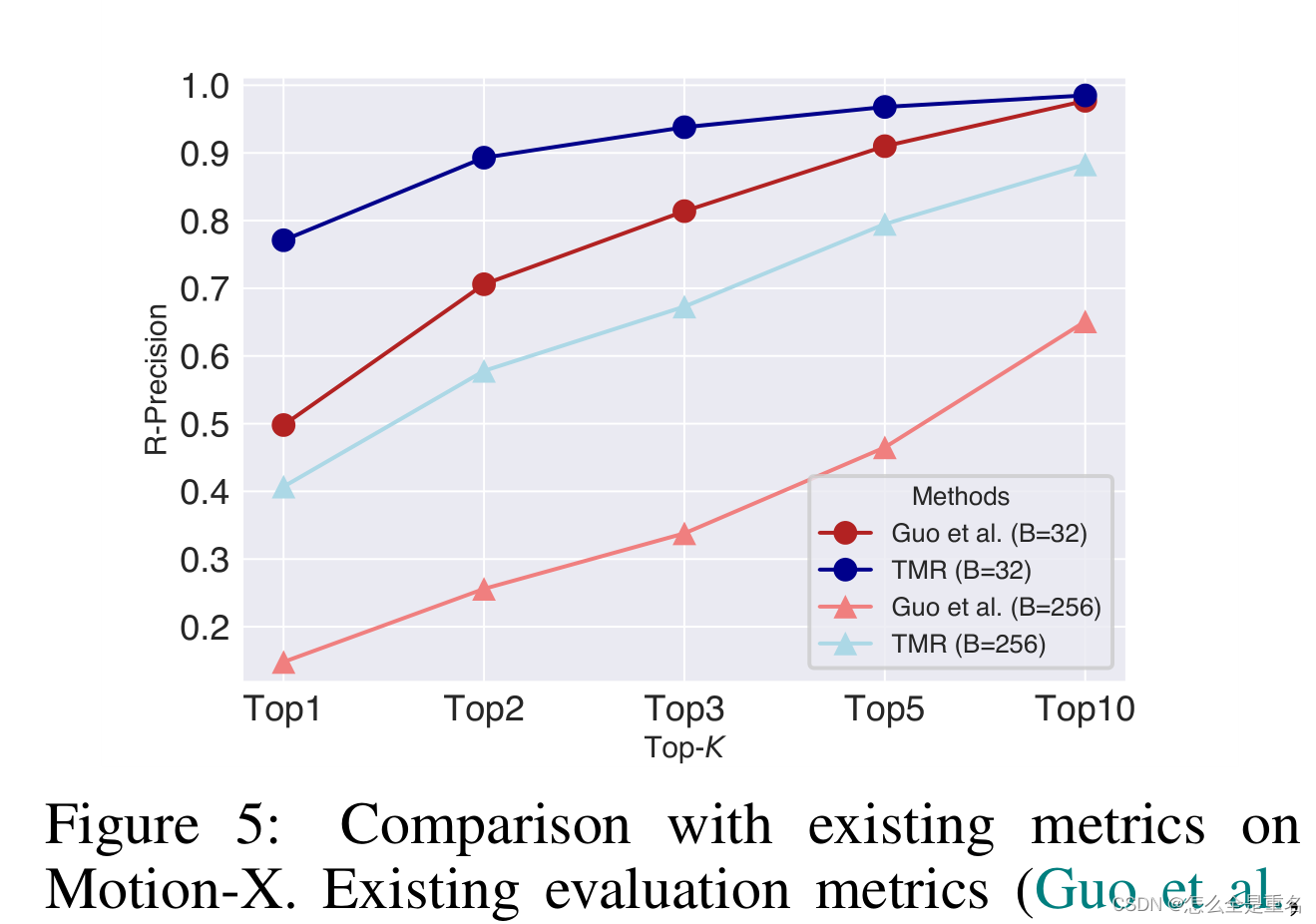
如图3(a)和图3(b)所示,我们可以简单地将它们分为两类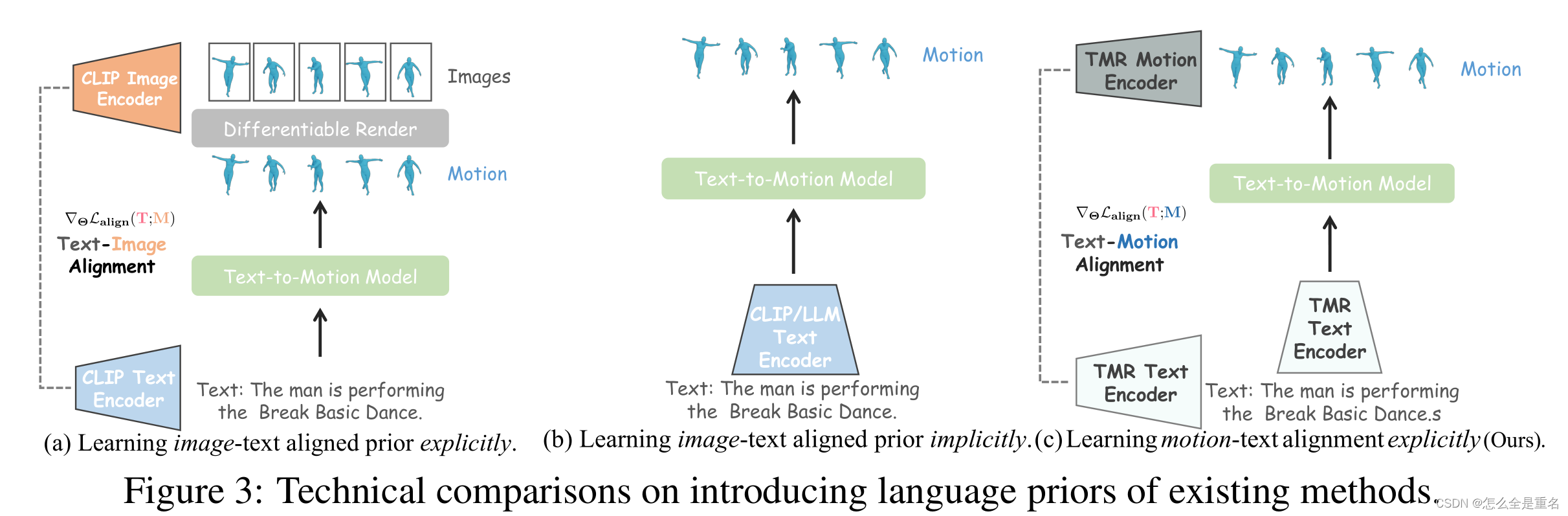
第一种是通过明确对齐的图像-文本先验进行监督
第二种是隐式图像-文本对齐先验学习
因此,有必要引入一种文本-运动对齐的预训练方法,以确保训练后的文本编码器能够输出更有利于完成文本-运动生成任务的文本嵌入,而不是从图像-文本对齐模型中进行调整
我们通过一个名为TMR的检索目标,以对比的方式对齐文本和运动(Radford等人,2021),预训练了一个运动编码器和一个文本编码器。与以往工作不同, TMR的文本嵌入比CLIP或llm的嵌入更优先发挥运动感知语言的作用,这有利于生成文本对齐的运动。在这项工作中,TMR是由我们自己重新训练的。
基于预训练的TMR,我们从两个方面探索增强给定文本与生成运动之间的对齐,如图3©所示
第一种是用TMR文本编码器替换CLIP文本编码器
二是引入基于TMR的运动-文本对齐监督
MODEL TRAINING AND INFERENCE(模型训练和推理)
Model Training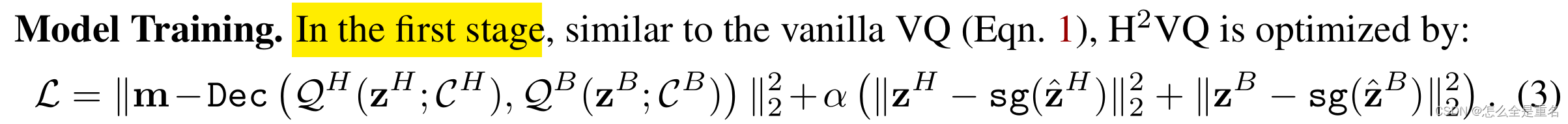
此外,还利用EMA和Code ReSet技术对码本进行了优化
在第二阶段,我们同时训练交叉熵损失lce和文本运动对齐损失Lalign,总体上为lce + ηLalign
Model Inference
在推理阶段,我们首先从TMR中提取文本嵌入。然后,我们将TMR文本嵌入作为初始令牌输入到hierarchistic - gpt中,然后以自动回归的方式预测离散的身体和手令牌。身体和手标记被输入到身体-手解码器中,以生成与文本对齐的人体动作。最终,结合面部cVAE产生的面部动作,输出综合的全身动作
Experiments
在本节中,我们在全身和仅身体运动生成基准上评估拟议的HumanTOMATO模型。此外,我们还将介绍我们的方法的一些技术设计。我们构建实验来回答以下四个研究问题(RQs):
RQ1:我们提出的HumanTOMATO模型在全身运动生成任务上是否优于现有的生成方法?
RQ2:全身运动的分层离散表示如何帮助提高运动生成的质量?
RQ3:预训练的文本-动作检索模型如何帮助生成的动作和文本之间的对齐?
RQ4:为什么在生成的运动和给定文本之间对齐的拟议评估指标更准确和更具挑战性?
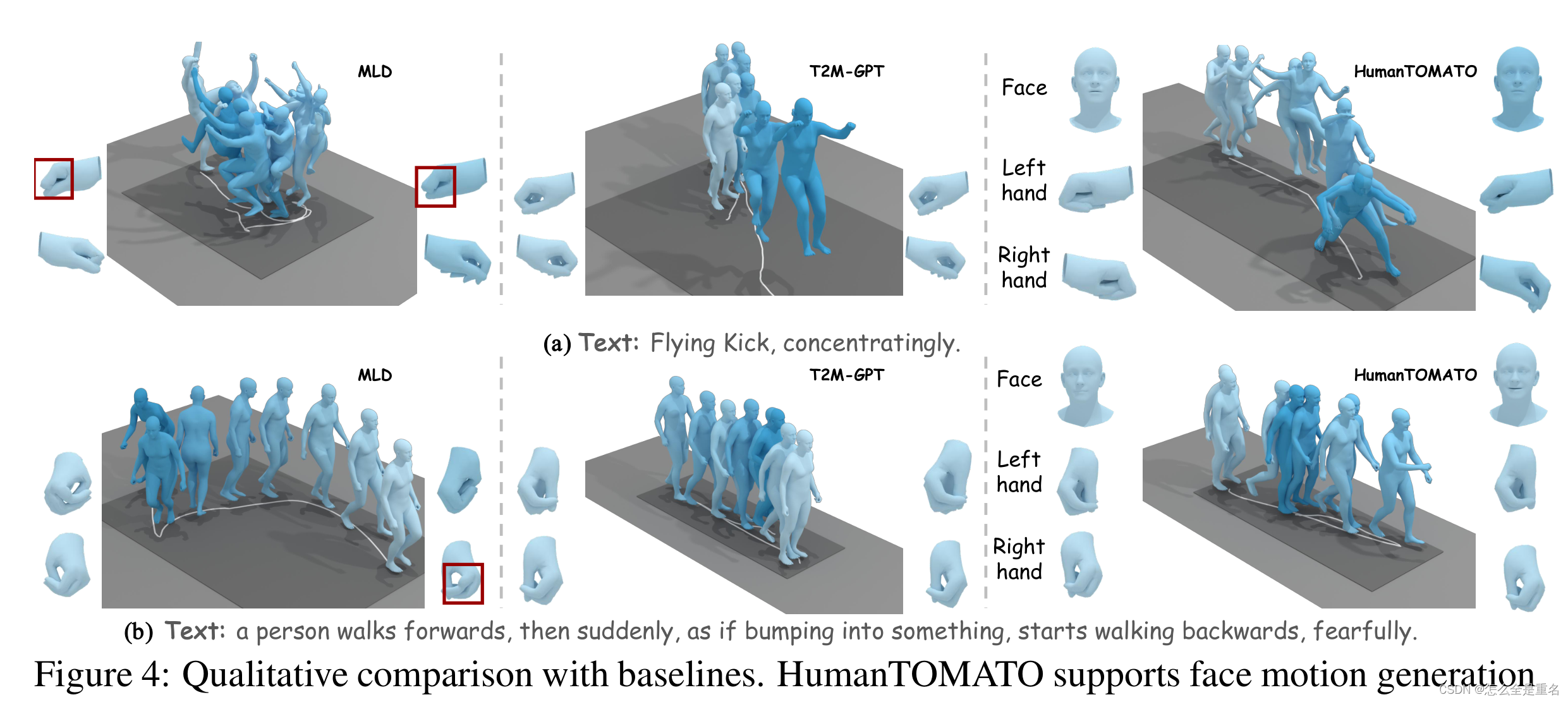
与基线的定性比较。HumanTOMATO支持面部运动生成,在手部运动生成和文本运动对齐方面优于MLD和T2M-GPT
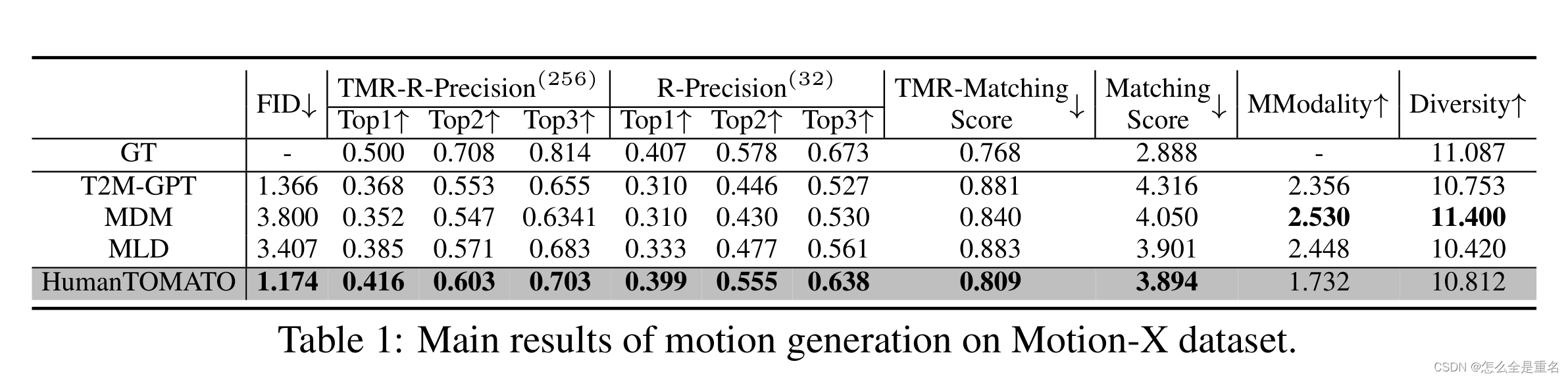
在motion - x数据集上运动生成的主要结果

不同量化方法在motion - x、GRAB和HumanML3D上的运动重建误差(MPJPE,单位mm)比较我们的h2 VQ显示出显著的改进
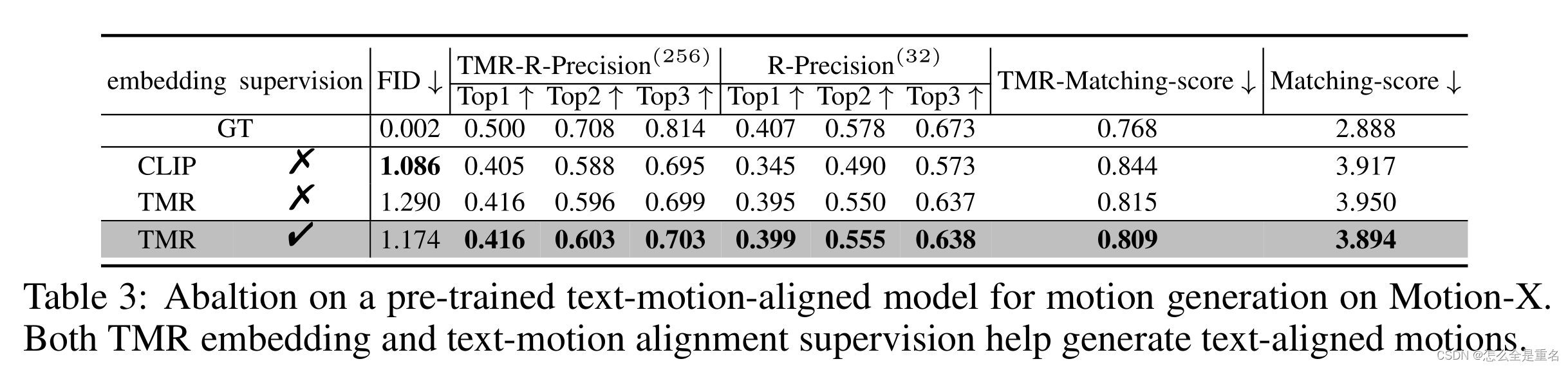
基于预训练的文本-运动对齐模型在motion- x上的运动生成。TMR嵌入和文本运动对齐监督都有助于生成文本对齐的运动
Conclusion
本文研究了文本驱动的全身运动生成问题。我们仔细地阐明了在生成生动的文本对齐的全身运动、运动重建和文本-运动对齐方面存在的挑战。为了应对这些挑战,提出了两项主要的技术贡献:(1)基于整体分层VQ- vae (h2 - VQ)和分层gpt的精细身体和手部运动重建与生成;(2)基于预训练的文本-运动对齐模型,帮助生成文本对齐运动。我们在Motion-X和HumanML3D数据集上进行了全面的实验,验证了所提出解决方案的优越性和有效性。实验结果表明,HumanTOMATO可以产生生动的文本对齐全身运动










![[UDS] --- TesterPresent 0x3E](https://img-blog.csdnimg.cn/fe5226cd103145bf8bbfc7602d646706.png)