在正文开始之前,请先来回答一下这个问题:
题目:输入为3个文件,a.txt 300MB,b.txt 100MB,c.txt 58.MB,使用MapReduce的example程序,计算Wordcount,请问,应该有多少个MapTask?
A、5 B、4 C、3 D、2
这是一个MR知识点中非常简单的一个问题,其中涉及到的知识点大概如下:
1.HDFS Block拆分,为啥是128MB
HDFS选择将数据块的默认大小设置为128MB,有以下几个原因:
1.减少元数据开销:较大的数据块大小可以减少元数据(metadata)的数量,因为元数据存储了文件的信息,如文件名、权限和数据块的位置等。较小的数据块会导致更多的元数据,增加了管理和存储的开销。
2.提高数据传输效率:较大的数据块可以提高数据传输的效率。在Hadoop集群中,数据块是以流的方式进行传输的,较大的数据块可以减少寻址和传输的开销,提高数据的读取和写入速度。
3.适应大规模数据处理:HDFS主要用于大规模数据处理,如大数据分析和批处理作业。较大的数据块可以更好地适应这些大规模数据处理需求,减少了数据切分和处理的开销。
2.MR对于输入数据的拆分
在 MapReduce 中,Map 操作的输入拆分格式取决于使用的输入格式。以下是常见的输入拆分格式:
1.TextInputFormat:将输入拆分为按行划分的文本块。每个 Map 任务处理一行或多行文本。
2.KeyValueTextInputFormat:类似于 TextInputFormat,但将每行拆分为键值对。键和值之间使用分隔符进行分割。
3.SequenceFileInputFormat:将输入拆分为 SequenceFile 格式的块。SequenceFile 是一种二进制文件格式,可存储键值对。
4.NLineInputFormat:将输入拆分为固定数量的行块。每个 Map 任务处理一块。
5.CombineTextInputFormat:将小文件组合成更大的输入拆分块,以减少 Map 任务的数量。这样可以提高作业的整体性能。
这些输入拆分格式的选择取决于输入数据的特性和处理需求。可以根据具体的情况选择合适的输入拆分格式来优化 Map 操作的性能。
以上都是大家在各个平台所能看到的理论答案,直接拿出来给大家做科普,那就太没诚意了。我们今天就来点实操性的,实践出真知。
1.Map Task个数验证
根据以上题目内容,咋们来制造一波测试数据集,按照题目设定,搞来三个文件,分别大小如下:
[root@bigdata input]# du -h *
299M a.txt
100M b.txt58M c.txt数据来源说明:下载的是《西游记》电子txt版,单个文件大概是3MB左右,然后使用追加的方式累计文件中。
我们将这个数据上传到HDFS,运行一波看看,这个有多少个Map个数。
#数据上传到DHFS
hdfs dfs -put input /apps/mapreduce/#运行测试命令hadoop jar ./hadoop-mapreduce-examples-3.3.4.jar \wordcount \/apps/mapreduce/input \/apps/mapreduce/output运行结果结果如下图展示,其中Map个数为5,Reduce为1,所以,开头的答案是A,请问,您答对了吗?

下图是使用Yarn UI2 看到的页面,这样更直观知道每个task任务的执行流程。
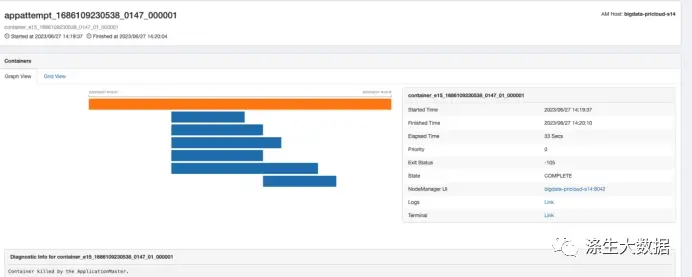
接下来,你是不是觉得我应该写:为啥是5,为啥是1呢?恭喜您,猜错了,还是太年轻,这东西值得我拿出来在公众号做分享吗,会被其他同行看不起的。咋们要讲,就要讲实际能用的,和工作相关的。
2.存储结构对比验证
在实际工作中,遇上题目这种a、b、c的情况比较少,但是分析一个???MB左右的数据却经常遇到。接下来分析一个同样的458MB的"文件",但是这里的文件存储结构是3MB * 153个,那么又会发生这么样的故事呢?
数据准备:将我们准备好的单个3MB的文件,循环copy并编号1-153,输入到input2文件夹。简单的shell,大家自己脑补下,毕竟,这不是今天的重点。完成后的数据格式如下:
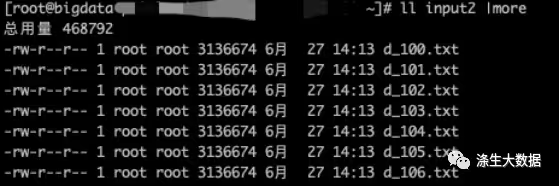
接下来上传数据,运行测试案例
#数据上传到DHFS
hdfs dfs -put input2 /apps/mapreduce/#运行测试命令hadoop jar ./hadoop-mapreduce-examples-3.3.4.jar \wordcount \/apps/mapreduce/input2 \/apps/mapreduce/output2毫无意外,这次运行,明显慢了很多,运行的结果情况如下:
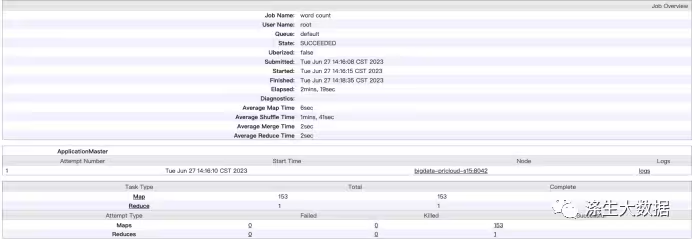
UI2任务流程图:
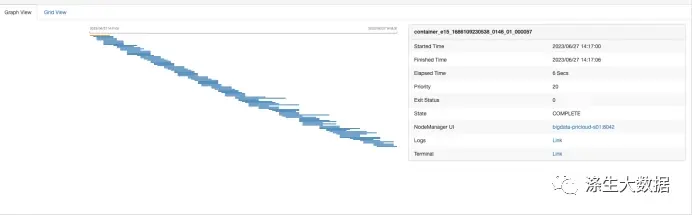
对比两次任务执行时间,第一次为:33s,第二次为139s,同样的大小的数据,居然差了4.21倍。这是啥概念?如果不是很明白,那就换个说法,加大点时间,老板让你去写个分析SQL,别人上午写,下午出结果,而你,上午写,让他明天等结果…,那么恭喜你,你在老板的小本本里面了。
你以为这就完了,NO,因为在实际企业中,没几个正常人写MR,都是些SQL,那么我们来看看,同样分析458MB的数据,A(a、b、c存储法),B(3 mb * 153存储法)两种存储结构,带来的花销是一样的吗?
3.Hive分区中结构对比实验
接下来,我们就使用同样的SQL,分析同样大小的数据,但是因为存储结构的不同,给运行带来的影响。
首先,创建一个实验表:
--创建表:
CREATE EXTERNAL TABLE IF NOT EXISTS `student.student0`( `id` string comment '学号', `name` string comment '姓名', `sex` string comment '性别', `age` int comment '年龄', `department` string comment '班级') partitioned by(dt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LINES TERMINATED BY '\n';验证下数据存储情况:
--插入数据:
insert into student.student0 values ("965","maoshu.ran","男",18,"Shanghai","2023-06-27");
--查看数据信息与存储结构:
hdfs dfs -get /warehouse/tablespace/external/hive/student.db/student0/dt=2023-06-27/000000_0--查看数据内容:965|maoshu.ran|男|18|Shanghai
接下来,我们就按上面的存储结构“965|maoshu.ran|男|18|Shanghai”制造一波测试案例数据。经过测试,大概75000条数据存储为3MB。我们先生成单个3MB文件,在批量叠加。
#单个3MB数据生产
for i in {0..75000}; do echo "20230627`printf "%06d\n" $i`|maoshu.ran|男|18|Shanghai">>000000_0.txt; done#创建数据集存储目录mkdir dt=2023-06-27mkdir dt=2023-06-28#数据集A制作cat 000000_0.txt >>dt=2023-06-27/000000_0.txtcat 000000_0.txt >>dt=2023-06-27/000000_0.txt...
#数据集B制作
sed s/20230627/20230628/g -i 000000_1.txtfor i in {1..157}; do cp 000000_1.txt dt\=2023-06-28/000000_$i.txt; done最后整个目录结构和文件结构如下:
![]()
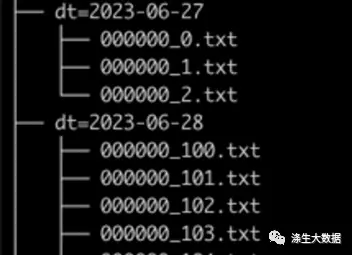
将数据上传到hive数据目录,并确认数据是否能够读取到。
#数据上传到hdfs
hdfs dfs -put dt\=2023-06-27 /warehouse/tablespace/external/hive/student.db/student0hdfs dfs -put dt\=2023-06-28 /warehouse/tablespace/external/hive/student.db/student0/#刷新hive分区(到hive命令行中)MSCK REPAIR TABLE student0;
> show partitions student0;
OK
dt=2023-06-27
dt=2023-06-28接下来,写SQL验证,太难的SQL,笔者不会写,因为“懒”,我们就写最简单的count(*)
测试结果前,确认下输入模式:
确认下输入格式:
Hive> set hive.input.formathive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;发现,默认使用的是CombineHiveInputFormat,看来HIVE很有先见之明啊。我们先用这个模式跑下验证
进行场景A验证
select count(*) from student0 where dt='2023-06-27';
其运行的流程图如下:3个Map,1个reduce,总执行时间是:39.959s
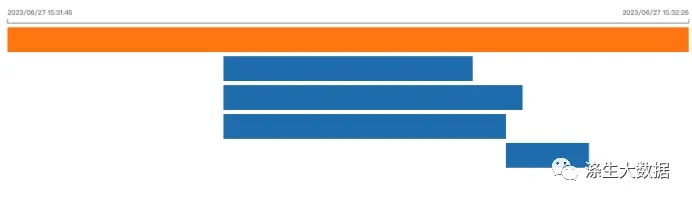
进行场景B验证
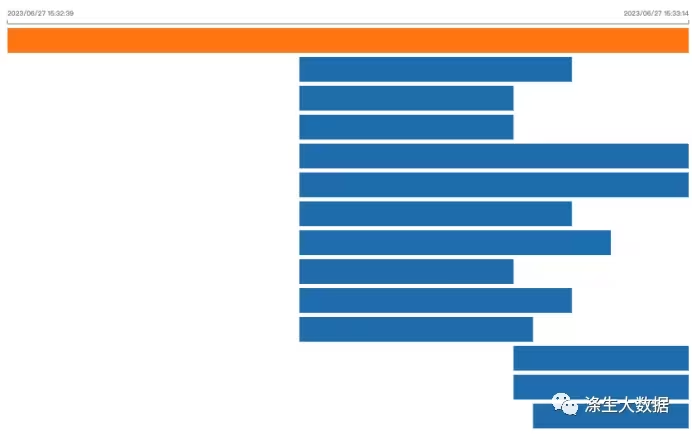
select count(*) from student0 where dt='2023-06-28';47.341
执行时间是47.341s,使用了Combine模式,这个Task个数,明显小于153,效果还是很明显的。但是很明显,执行时间和task个数均比场景A多。
接下来,我们切换为MR中默认的TextInputFormat看看
set hive.input.format=org.apache.hadoop.mapred.TextInputFormat;
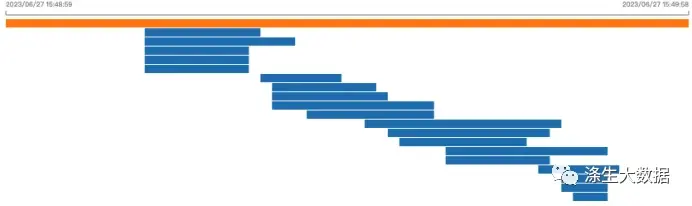
运行统计命令如上,其结果有点飘
场景A运行情况
场景B运行情况
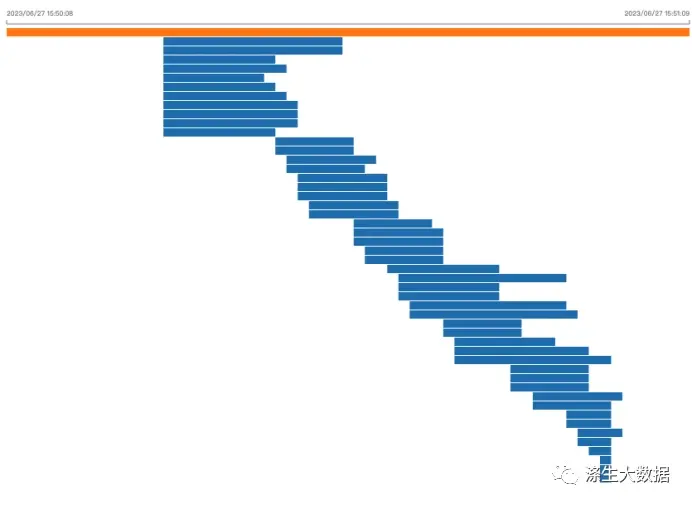
虽然运行情况不太如愿,但是也能看出来,情景B的Task个数,明显多于场景A。
4.总结
在我们的整个验证过程中, Hive中的SQL演示,在日常的数据分析工作中是很常见的。同样的SQL,同样规模数据,为啥运行时间不一样?可能并不是因为你写的SQL有问题,不妨思考下,会不会是底层存储的问题
所以,课后作业来了:HDFS 小文件会带来哪些影响?
![[架构之路-239]:目标系统 - 纵向分层 - 中间件middleware](https://img-blog.csdnimg.cn/c9bbd3b41e204ac6aaeb50a47033e2e8.png)