二十分钟入门pandas,学不会私信教学!
有需要pyecharts资源的可以点击文章上面下载!!!
需要本项目运行源码可以点击资源进行下载
资源
#coding:utf8
%matplotlib inline
这个一篇针对pandas新手的简短入门,想要了解更多复杂的内容,参阅Cookbook
通常,我们首先要导入以下几个库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
创建对象
通过传递一个list来创建Series,pandas会默认创建整型索引:
s = pd.Series([1,3,5,np.nan,6,8])
s
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
通过传递一个numpy array,日期索引以及列标签来创建一个DataFrame:
dates = pd.date_range('20130101', periods=6)
dates
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
df
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-01 | 0.194873 | 0.298287 | 0.073043 | -0.681957 |
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 1.187169 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 1.752973 |
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | -1.634272 |
| 2013-01-05 | 0.405459 | -1.151989 | -1.309286 | 1.023221 |
| 2013-01-06 | -0.445221 | -1.520998 | 0.717376 | 1.657476 |
通过传递一个能够被转换为类似series的dict对象来创建一个DataFrame:
df2 = pd.DataFrame({ 'A' : 1.,
'B' : pd.Timestamp('20130102'),
'C' : pd.Series(1,index=list(range(4)),dtype='float32'),
'D' : np.array([3]*4,dtype='int32'),
'E' : pd.Categorical(["test","train","test","train"]),
'F' : 'foo' })
df2
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| 0 | 1.0 | 2013-01-02 | 1.0 | 3 | test | foo |
| 1 | 1.0 | 2013-01-02 | 1.0 | 3 | train | foo |
| 2 | 1.0 | 2013-01-02 | 1.0 | 3 | test | foo |
| 3 | 1.0 | 2013-01-02 | 1.0 | 3 | train | foo |
可以看到各列的数据类型为:
df2.dtypes
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
查看数据
查看frame中头部和尾部的几行:
df.head()
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-01 | 0.194873 | 0.298287 | 0.073043 | -0.681957 |
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 1.187169 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 1.752973 |
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | -1.634272 |
| 2013-01-05 | 0.405459 | -1.151989 | -1.309286 | 1.023221 |
df.tail(3)
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | -1.634272 |
| 2013-01-05 | 0.405459 | -1.151989 | -1.309286 | 1.023221 |
| 2013-01-06 | -0.445221 | -1.520998 | 0.717376 | 1.657476 |
显示索引、列名以及底层的numpy数据
df.index
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04',
'2013-01-05', '2013-01-06'],
dtype='datetime64[ns]', freq='D')
df.columns
Index(['A', 'B', 'C', 'D'], dtype='object')
df.values
array([[ 0.19487255, 0.29828663, 0.07304296, -0.68195723],
[-0.67942918, 0.39797196, 0.88738797, 1.18716883],
[ 0.78224424, -0.25182784, -0.73624252, 1.75297344],
[-1.8770662 , -0.06096652, -2.10376905, -1.63427152],
[ 0.40545892, -1.15198867, -1.30928606, 1.02322057],
[-0.44522115, -1.52099782, 0.71737636, 1.65747636]])
describe()能对数据做一个快速统计汇总
df.describe()
| A | B | C | D | |
|---|---|---|---|---|
| count | 6.000000 | 6.000000 | 6.000000 | 6.000000 |
| mean | -0.269857 | -0.381587 | -0.411915 | 0.550768 |
| std | 0.955046 | 0.785029 | 1.180805 | 1.385087 |
| min | -1.877066 | -1.520998 | -2.103769 | -1.634272 |
| 25% | -0.620877 | -0.926948 | -1.166025 | -0.255663 |
| 50% | -0.125174 | -0.156397 | -0.331600 | 1.105195 |
| 75% | 0.352812 | 0.208473 | 0.556293 | 1.539899 |
| max | 0.782244 | 0.397972 | 0.887388 | 1.752973 |
对数据做转置:
df.T
| 2013-01-01 | 2013-01-02 | 2013-01-03 | 2013-01-04 | 2013-01-05 | 2013-01-06 | |
|---|---|---|---|---|---|---|
| A | 0.194873 | -0.679429 | 0.782244 | -1.877066 | 0.405459 | -0.445221 |
| B | 0.298287 | 0.397972 | -0.251828 | -0.060967 | -1.151989 | -1.520998 |
| C | 0.073043 | 0.887388 | -0.736243 | -2.103769 | -1.309286 | 0.717376 |
| D | -0.681957 | 1.187169 | 1.752973 | -1.634272 | 1.023221 | 1.657476 |
按轴进行排序(1代表横轴;0代表纵轴):
df.sort_index(axis=1, ascending=False)
| D | C | B | A | |
|---|---|---|---|---|
| 2013-01-01 | -0.681957 | 0.073043 | 0.298287 | 0.194873 |
| 2013-01-02 | 1.187169 | 0.887388 | 0.397972 | -0.679429 |
| 2013-01-03 | 1.752973 | -0.736243 | -0.251828 | 0.782244 |
| 2013-01-04 | -1.634272 | -2.103769 | -0.060967 | -1.877066 |
| 2013-01-05 | 1.023221 | -1.309286 | -1.151989 | 0.405459 |
| 2013-01-06 | 1.657476 | 0.717376 | -1.520998 | -0.445221 |
按值进行排序 :
df.sort_values(by='D')
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | -1.634272 |
| 2013-01-01 | 0.194873 | 0.298287 | 0.073043 | -0.681957 |
| 2013-01-05 | 0.405459 | -1.151989 | -1.309286 | 1.023221 |
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 1.187169 |
| 2013-01-06 | -0.445221 | -1.520998 | 0.717376 | 1.657476 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 1.752973 |
数据选择
注意:虽然标准的Python/Numpy的表达式能完成选择与赋值等功能,但我们仍推荐使用优化过的pandas数据访问方法:.at,.iat,.loc,.iloc和.ix
选取
选择某一列数据,它会返回一个Series,等同于df.A:
df['A']
2013-01-01 0.194873
2013-01-02 -0.679429
2013-01-03 0.782244
2013-01-04 -1.877066
2013-01-05 0.405459
2013-01-06 -0.445221
Freq: D, Name: A, dtype: float64
通过使用 [ ]进行切片选取:
df[0:4]
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-01 | 0.194873 | 0.298287 | 0.073043 | -0.681957 |
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 1.187169 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 1.752973 |
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | -1.634272 |
df['20130102':'20130104']
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 1.187169 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 1.752973 |
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | -1.634272 |
通过标签选取
通过标签进行交叉选取:
dates[0]
Timestamp('2013-01-01 00:00:00', freq='D')
df.loc[dates[0]]
A 0.194873
B 0.298287
C 0.073043
D -0.681957
Name: 2013-01-01 00:00:00, dtype: float64
使用标签对多个轴进行选取
df.loc[:,['A','B']]
| A | B | |
|---|---|---|
| 2013-01-01 | 0.194873 | 0.298287 |
| 2013-01-02 | -0.679429 | 0.397972 |
| 2013-01-03 | 0.782244 | -0.251828 |
| 2013-01-04 | -1.877066 | -0.060967 |
| 2013-01-05 | 0.405459 | -1.151989 |
| 2013-01-06 | -0.445221 | -1.520998 |
df.loc[:,['A','B']][:3]
| A | B | |
|---|---|---|
| 2013-01-01 | 0.194873 | 0.298287 |
| 2013-01-02 | -0.679429 | 0.397972 |
| 2013-01-03 | 0.782244 | -0.251828 |
进行标签切片,包含两个端点
df.loc['20130102':'20130104',['A','B']]
| A | B | |
|---|---|---|
| 2013-01-02 | -0.679429 | 0.397972 |
| 2013-01-03 | 0.782244 | -0.251828 |
| 2013-01-04 | -1.877066 | -0.060967 |
对于返回的对象进行降维处理
df.loc['20130102',['A','B']]
A -0.679429
B 0.397972
Name: 2013-01-02 00:00:00, dtype: float64
获取一个标量
df.loc[dates[0],'A']
0.19487255317338711
快速获取标量(与上面的方法等价)
df.at[dates[0],'A']
0.19487255317338711
通过位置选取
通过传递整型的位置进行选取
df.iloc[3]
A -1.877066
B -0.060967
C -2.103769
D -1.634272
Name: 2013-01-04 00:00:00, dtype: float64
通过整型的位置切片进行选取,与python/numpy形式相同
df.iloc[3:5,0:2]
| A | B | |
|---|---|---|
| 2013-01-04 | -1.877066 | -0.060967 |
| 2013-01-05 | 0.405459 | -1.151989 |
只对行进行切片
df.iloc[1:3,:]
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 1.187169 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 1.752973 |
只对列进行切片
df.iloc[:,1:3]
| B | C | |
|---|---|---|
| 2013-01-01 | 0.298287 | 0.073043 |
| 2013-01-02 | 0.397972 | 0.887388 |
| 2013-01-03 | -0.251828 | -0.736243 |
| 2013-01-04 | -0.060967 | -2.103769 |
| 2013-01-05 | -1.151989 | -1.309286 |
| 2013-01-06 | -1.520998 | 0.717376 |
只获取某个值
df.iloc[1,1]
0.39797195640479976
快速获取某个值(与上面的方法等价)
df.iat[1,1]
0.39797195640479976
布尔索引
用某列的值来选取数据
df[df.A > 0]
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-01 | 0.194873 | 0.298287 | 0.073043 | -0.681957 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 1.752973 |
| 2013-01-05 | 0.405459 | -1.151989 | -1.309286 | 1.023221 |
用where操作来选取数据
df[df > 0]
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-01 | 0.194873 | 0.298287 | 0.073043 | NaN |
| 2013-01-02 | NaN | 0.397972 | 0.887388 | 1.187169 |
| 2013-01-03 | 0.782244 | NaN | NaN | 1.752973 |
| 2013-01-04 | NaN | NaN | NaN | NaN |
| 2013-01-05 | 0.405459 | NaN | NaN | 1.023221 |
| 2013-01-06 | NaN | NaN | 0.717376 | 1.657476 |
用**isin()**方法来过滤数据
df2 = df.copy()
df2['E'] = ['one', 'one', 'two', 'three', 'four', 'three']
df2
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 2013-01-01 | 0.194873 | 0.298287 | 0.073043 | -0.681957 | one |
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 1.187169 | one |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 1.752973 | two |
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | -1.634272 | three |
| 2013-01-05 | 0.405459 | -1.151989 | -1.309286 | 1.023221 | four |
| 2013-01-06 | -0.445221 | -1.520998 | 0.717376 | 1.657476 | three |
df2[df2['E'].isin(['two', 'four'])]
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 1.752973 | two |
| 2013-01-05 | 0.405459 | -1.151989 | -1.309286 | 1.023221 | four |
赋值
赋值一个新的列,通过索引来自动对齐数据
s1 = pd.Series([1,2,3,4,5,6], index=pd.date_range('20130102',periods=6))
s1
2013-01-02 1
2013-01-03 2
2013-01-04 3
2013-01-05 4
2013-01-06 5
2013-01-07 6
Freq: D, dtype: int64
df['F'] = s1
df
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2013-01-01 | 0.194873 | 0.298287 | 0.073043 | -0.681957 | NaN |
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 1.187169 | 1.0 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 1.752973 | 2.0 |
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | -1.634272 | 3.0 |
| 2013-01-05 | 0.405459 | -1.151989 | -1.309286 | 1.023221 | 4.0 |
| 2013-01-06 | -0.445221 | -1.520998 | 0.717376 | 1.657476 | 5.0 |
通过标签赋值
df.at[dates[0], 'A'] = 0
df
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | 0.298287 | 0.073043 | -0.681957 | NaN |
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 1.187169 | 1.0 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 1.752973 | 2.0 |
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | -1.634272 | 3.0 |
| 2013-01-05 | 0.405459 | -1.151989 | -1.309286 | 1.023221 | 4.0 |
| 2013-01-06 | -0.445221 | -1.520998 | 0.717376 | 1.657476 | 5.0 |
通过位置赋值
df.iat[0,1] = 8888
df
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | 8888.000000 | 0.073043 | -0.681957 | NaN |
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 1.187169 | 1.0 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 1.752973 | 2.0 |
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | -1.634272 | 3.0 |
| 2013-01-05 | 0.405459 | -1.151989 | -1.309286 | 1.023221 | 4.0 |
| 2013-01-06 | -0.445221 | -1.520998 | 0.717376 | 1.657476 | 5.0 |
通过传递numpy array赋值
df.loc[:,'D'] = np.array([5] * len(df))
df
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | 8888.000000 | 0.073043 | 5 | NaN |
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 5 | 1.0 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 5 | 2.0 |
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | 5 | 3.0 |
| 2013-01-05 | 0.405459 | -1.151989 | -1.309286 | 5 | 4.0 |
| 2013-01-06 | -0.445221 | -1.520998 | 0.717376 | 5 | 5.0 |
通过where操作来赋值
df2 = df.copy()
df2[df2 > 0] = -df2
df2
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | -8888.000000 | -0.073043 | -5 | NaN |
| 2013-01-02 | -0.679429 | -0.397972 | -0.887388 | -5 | -1.0 |
| 2013-01-03 | -0.782244 | -0.251828 | -0.736243 | -5 | -2.0 |
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | -5 | -3.0 |
| 2013-01-05 | -0.405459 | -1.151989 | -1.309286 | -5 | -4.0 |
| 2013-01-06 | -0.445221 | -1.520998 | -0.717376 | -5 | -5.0 |
缺失值处理
在pandas中,用np.nan来代表缺失值,这些值默认不会参与运算。
reindex()允许你修改、增加、删除指定轴上的索引,并返回一个数据副本。
dates[0]
Timestamp('2013-01-01 00:00:00', freq='D')
df1 = df.reindex(index=dates[0:4], columns=list(df.columns)+['E'])
df1.loc[dates[0]:dates[1],'E'] = 1
df1
| A | B | C | D | F | E | |
|---|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | 8888.000000 | 0.073043 | 5 | NaN | 1.0 |
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 5 | 1.0 | 1.0 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 5 | 2.0 | NaN |
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | 5 | 3.0 | NaN |
剔除所有包含缺失值的行数据
df1.dropna(how='any')#any是任意,所以保留下来了
| A | B | C | D | F | E | |
|---|---|---|---|---|---|---|
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 5 | 1.0 | 1.0 |
填充缺失值
df1.fillna(value=5)
| A | B | C | D | F | E | |
|---|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | 8888.000000 | 0.073043 | 5 | 5.0 | 1.0 |
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 5 | 1.0 | 1.0 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 5 | 2.0 | 5.0 |
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | 5 | 3.0 | 5.0 |
获取值是否为nan的布尔标记
pd.isnull(df1)
| A | B | C | D | F | E | |
|---|---|---|---|---|---|---|
| 2013-01-01 | False | False | False | False | True | False |
| 2013-01-02 | False | False | False | False | False | False |
| 2013-01-03 | False | False | False | False | False | True |
| 2013-01-04 | False | False | False | False | False | True |
运算
统计
运算过程中,通常不包含缺失值。
进行描述性统计
df.mean()#默认为0
A -0.302336
B 1480.902032
C -0.411915
D 5.000000
F 3.000000
dtype: float64
对其他轴进行同样的运算
df.mean(1)#对所有行
2013-01-01 2223.268261
2013-01-02 1.321186
2013-01-03 1.358835
2013-01-04 0.791640
2013-01-05 1.388837
2013-01-06 1.750231
Freq: D, dtype: float64
对于拥有不同维度的对象进行运算时需要对齐。除此之外,pandas会自动沿着指定维度计算。
s = pd.Series([1,3,5,np.nan,6,8], index=dates).shift(2)
#意思就是前面两个填充为空,后面的自动往下移动
s
2013-01-01 NaN
2013-01-02 NaN
2013-01-03 1.0
2013-01-04 3.0
2013-01-05 5.0
2013-01-06 NaN
Freq: D, dtype: float64
df
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | 8888.000000 | 0.073043 | 5 | NaN |
| 2013-01-02 | -0.679429 | 0.397972 | 0.887388 | 5 | 1.0 |
| 2013-01-03 | 0.782244 | -0.251828 | -0.736243 | 5 | 2.0 |
| 2013-01-04 | -1.877066 | -0.060967 | -2.103769 | 5 | 3.0 |
| 2013-01-05 | 0.405459 | -1.151989 | -1.309286 | 5 | 4.0 |
| 2013-01-06 | -0.445221 | -1.520998 | 0.717376 | 5 | 5.0 |
df.sub(s, axis='index')
# 然后对df和s中的对应位置的元素进行减法运算,即df中的元素减去s中对应索引元素的值。
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2013-01-01 | NaN | NaN | NaN | NaN | NaN |
| 2013-01-02 | NaN | NaN | NaN | NaN | NaN |
| 2013-01-03 | -0.217756 | -1.251828 | -1.736243 | 4.0 | 1.0 |
| 2013-01-04 | -4.877066 | -3.060967 | -5.103769 | 2.0 | 0.0 |
| 2013-01-05 | -4.594541 | -6.151989 | -6.309286 | 0.0 | -1.0 |
| 2013-01-06 | NaN | NaN | NaN | NaN | NaN |
Apply 函数作用
通过apply()对函数作用
df.apply(np.cumsum)
# df.apply(np.cumsum)对DataFrame中的每一列应用np.cumsum函数进行累积求和。
# np.cumsum计算累积和,它将每一列中的元素按顺序进行累加。
| A | B | C | D | F | |
|---|---|---|---|---|---|
| 2013-01-01 | 0.000000 | 8888.000000 | 0.073043 | 5 | NaN |
| 2013-01-02 | -0.679429 | 8888.397972 | 0.960431 | 10 | 1.0 |
| 2013-01-03 | 0.102815 | 8888.146144 | 0.224188 | 15 | 3.0 |
| 2013-01-04 | -1.774251 | 8888.085178 | -1.879581 | 20 | 6.0 |
| 2013-01-05 | -1.368792 | 8886.933189 | -3.188867 | 25 | 10.0 |
| 2013-01-06 | -1.814013 | 8885.412191 | -2.471490 | 30 | 15.0 |
df.apply(lambda x:x.max()-x.min())
# 这个lambda函数会对df的每一列调用x.max()求最大值和x.min()求最小值,最后计算最大值减最小值。
A 2.659310
B 8889.520998
C 2.991157
D 0.000000
F 4.000000
dtype: float64
频数统计
s = pd.Series(np.random.randint(0, 7, size=10))
s
0 2
1 5
2 1
3 3
4 2
5 0
6 0
7 1
8 4
9 1
dtype: int32
s.value_counts()
1 3
2 2
0 2
5 1
3 1
4 1
dtype: int64
字符串方法
对于Series对象,在其str属性中有着一系列的字符串处理方法。就如同下段代码一样,能很方便的对array中各个元素进行运算。值得注意的是,在str属性中的模式匹配默认使用正则表达式。
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'])
s.str.lower()
0 a
1 b
2 c
3 aaba
4 baca
5 NaN
6 caba
7 dog
8 cat
dtype: object
合并
Concat 连接
pandas中提供了大量的方法能够轻松对Series,DataFrame和Panel对象进行不同满足逻辑关系的合并操作
通过**concat()**来连接pandas对象
df = pd.DataFrame(np.random.randn(10,4))
df
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 0.639168 | 0.881631 | 0.198015 | 0.393510 |
| 1 | 0.503544 | 0.155373 | 1.218277 | 0.128893 |
| 2 | -0.661486 | 1.365067 | -0.010755 | 0.058110 |
| 3 | 0.185698 | -0.750695 | -0.637134 | -1.811947 |
| 4 | -0.493348 | -0.246197 | -0.700524 | 0.692042 |
| 5 | -2.280015 | 0.986806 | 1.297614 | -0.749969 |
| 6 | 0.688663 | 0.088751 | -0.164766 | -0.165378 |
| 7 | -0.382894 | -0.157371 | 0.000836 | -1.947379 |
| 8 | -1.618486 | 0.804667 | 1.919125 | -0.290719 |
| 9 | 0.392898 | -0.264556 | 0.817233 | 0.680797 |
#break it into pieces
pieces = [df[:3], df[3:7], df[7:]]
pieces
[ 0 1 2 3
0 0.639168 0.881631 0.198015 0.393510
1 0.503544 0.155373 1.218277 0.128893
2 -0.661486 1.365067 -0.010755 0.058110,
0 1 2 3
3 0.185698 -0.750695 -0.637134 -1.811947
4 -0.493348 -0.246197 -0.700524 0.692042
5 -2.280015 0.986806 1.297614 -0.749969
6 0.688663 0.088751 -0.164766 -0.165378,
0 1 2 3
7 -0.382894 -0.157371 0.000836 -1.947379
8 -1.618486 0.804667 1.919125 -0.290719
9 0.392898 -0.264556 0.817233 0.680797]
pd.concat(pieces)
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 0.639168 | 0.881631 | 0.198015 | 0.393510 |
| 1 | 0.503544 | 0.155373 | 1.218277 | 0.128893 |
| 2 | -0.661486 | 1.365067 | -0.010755 | 0.058110 |
| 3 | 0.185698 | -0.750695 | -0.637134 | -1.811947 |
| 4 | -0.493348 | -0.246197 | -0.700524 | 0.692042 |
| 5 | -2.280015 | 0.986806 | 1.297614 | -0.749969 |
| 6 | 0.688663 | 0.088751 | -0.164766 | -0.165378 |
| 7 | -0.382894 | -0.157371 | 0.000836 | -1.947379 |
| 8 | -1.618486 | 0.804667 | 1.919125 | -0.290719 |
| 9 | 0.392898 | -0.264556 | 0.817233 | 0.680797 |
Join 合并
类似于SQL中的合并(merge)
left = pd.DataFrame({'key':['foo', 'foo'], 'lval':[1,2]})
left
| key | lval | |
|---|---|---|
| 0 | foo | 1 |
| 1 | foo | 2 |
right = pd.DataFrame({'key':['foo', 'foo'], 'lval':[4,5]})
right
| key | lval | |
|---|---|---|
| 0 | foo | 4 |
| 1 | foo | 5 |
pd.merge(left, right, on='key')
| key | lval_x | lval_y | |
|---|---|---|---|
| 0 | foo | 1 | 4 |
| 1 | foo | 1 | 5 |
| 2 | foo | 2 | 4 |
| 3 | foo | 2 | 5 |
Append 添加
将若干行添加到dataFrame后面
df = pd.DataFrame(np.random.randn(8, 4), columns=['A', 'B', 'C', 'D'])
df
| A | B | C | D | |
|---|---|---|---|---|
| 0 | -1.526419 | 0.868844 | -1.379758 | 0.498004 |
| 1 | -0.917867 | -0.137874 | -0.909232 | -0.523873 |
| 2 | 1.370409 | -0.948766 | 1.728098 | 0.361813 |
| 3 | -1.274621 | -1.224051 | -0.749470 | -2.712027 |
| 4 | -0.303875 | -0.177942 | 0.496359 | 0.048004 |
| 5 | -0.941436 | 0.044570 | -0.229654 | 0.092941 |
| 6 | 0.465798 | -0.835244 | 0.131745 | 2.219413 |
| 7 | 0.875844 | 0.243440 | -1.050471 | 1.761330 |
s = df.iloc[3]
s
A -1.274621
B -1.224051
C -0.749470
D -2.712027
Name: 3, dtype: float64
import warnings
df.append(s, ignore_index=True)
C:\Users\48125\AppData\Local\Temp\ipykernel_17504\1384017944.py:3: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df.append(s, ignore_index=True)
| A | B | C | D | |
|---|---|---|---|---|
| 0 | -1.526419 | 0.868844 | -1.379758 | 0.498004 |
| 1 | -0.917867 | -0.137874 | -0.909232 | -0.523873 |
| 2 | 1.370409 | -0.948766 | 1.728098 | 0.361813 |
| 3 | -1.274621 | -1.224051 | -0.749470 | -2.712027 |
| 4 | -0.303875 | -0.177942 | 0.496359 | 0.048004 |
| 5 | -0.941436 | 0.044570 | -0.229654 | 0.092941 |
| 6 | 0.465798 | -0.835244 | 0.131745 | 2.219413 |
| 7 | 0.875844 | 0.243440 | -1.050471 | 1.761330 |
| 8 | -1.274621 | -1.224051 | -0.749470 | -2.712027 |
分组
对于“group by”操作,我们通常是指以下一个或几个步骤:
- 划分 按照某些标准将数据分为不同的组
- 应用 对每组数据分别执行一个函数
- 组合 将结果组合到一个数据结构
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar',
'foo', 'bar', 'foo', 'bar'],
'B' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'C' : np.random.randn(8),
'D' : np.random.randn(8)})
df
| A | B | C | D | |
|---|---|---|---|---|
| 0 | foo | one | -0.491461 | -0.550970 |
| 1 | bar | one | -0.468956 | 0.584847 |
| 2 | foo | two | 0.461989 | 0.372785 |
| 3 | bar | three | 0.290600 | -2.142788 |
| 4 | foo | two | 0.448364 | -2.036729 |
| 5 | bar | two | 0.639793 | 0.577440 |
| 6 | foo | one | 1.335309 | -0.582853 |
| 7 | bar | three | 0.629100 | 0.223494 |
分组并对每个分组应用sum函数
df.groupby('A').sum()
C:\Users\48125\AppData\Local\Temp\ipykernel_17504\1885751491.py:1: FutureWarning: The default value of numeric_only in DataFrameGroupBy.sum is deprecated. In a future version, numeric_only will default to False. Either specify numeric_only or select only columns which should be valid for the function.
df.groupby('A').sum()
| C | D | |
|---|---|---|
| A | ||
| bar | 1.090537 | -0.757006 |
| foo | 1.754201 | -2.797767 |
按多个列分组形成层级索引,然后应用函数
df.groupby(['A','B']).sum()
| C | D | ||
|---|---|---|---|
| A | B | ||
| bar | one | -0.468956 | 0.584847 |
| three | 0.919700 | -1.919294 | |
| two | 0.639793 | 0.577440 | |
| foo | one | 0.843848 | -1.133823 |
| two | 0.910352 | -1.663943 |
变形
堆叠
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz',
'foo', 'foo', 'qux', 'qux'],
['one', 'two', 'one', 'two',
'one', 'two', 'one', 'two']]))
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
df2 = df[:4]
df2
| A | B | ||
|---|---|---|---|
| first | second | ||
| bar | one | 0.138584 | 0.661800 |
| two | 0.206128 | 0.668363 | |
| baz | one | -0.531729 | -0.695009 |
| two | 0.746672 | -0.735620 |
**stack()**方法对DataFrame的列“压缩”一个层级
stacked = df2.stack()
stacked
first second
bar one A 0.138584
B 0.661800
two A 0.206128
B 0.668363
baz one A -0.531729
B -0.695009
two A 0.746672
B -0.735620
dtype: float64
对于一个“堆叠过的”DataFrame或者Series(拥有MultiIndex作为索引),stack()的逆操作是unstack(),默认反堆叠到上一个层级
stacked.unstack()
| A | B | ||
|---|---|---|---|
| first | second | ||
| bar | one | 0.138584 | 0.661800 |
| two | 0.206128 | 0.668363 | |
| baz | one | -0.531729 | -0.695009 |
| two | 0.746672 | -0.735620 |
stacked.unstack(1)
| second | one | two | |
|---|---|---|---|
| first | |||
| bar | A | 0.138584 | 0.206128 |
| B | 0.661800 | 0.668363 | |
| baz | A | -0.531729 | 0.746672 |
| B | -0.695009 | -0.735620 |
stacked.unstack(0)
| first | bar | baz | |
|---|---|---|---|
| second | |||
| one | A | 0.138584 | -0.531729 |
| B | 0.661800 | -0.695009 | |
| two | A | 0.206128 | 0.746672 |
| B | 0.668363 | -0.735620 |
数据透视表
df = pd.DataFrame({'A' : ['one', 'one', 'two', 'three'] * 3,
'B' : ['A', 'B', 'C'] * 4,
'C' : ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 2,
'D' : np.random.randn(12),
'E' : np.random.randn(12)})
df
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 0 | one | A | foo | 0.014262 | -0.732936 |
| 1 | one | B | foo | 0.853949 | 1.719331 |
| 2 | two | C | foo | -0.344640 | 0.765832 |
| 3 | three | A | bar | 1.908338 | -1.447838 |
| 4 | one | B | bar | -1.469287 | 0.954153 |
| 5 | one | C | bar | -1.341587 | -0.606839 |
| 6 | two | A | foo | 0.961927 | 0.054527 |
| 7 | three | B | foo | 0.829778 | -0.581417 |
| 8 | one | C | foo | 0.623418 | -0.456098 |
| 9 | one | A | bar | 1.745817 | -0.684403 |
| 10 | two | B | bar | -1.457706 | -0.272665 |
| 11 | three | C | bar | 1.336044 | 2.080870 |
我们可以轻松地从这个数据得到透视表
pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'])
| C | bar | foo | |
|---|---|---|---|
| A | B | ||
| one | A | 1.745817 | 0.014262 |
| B | -1.469287 | 0.853949 | |
| C | -1.341587 | 0.623418 | |
| three | A | 1.908338 | NaN |
| B | NaN | 0.829778 | |
| C | 1.336044 | NaN | |
| two | A | NaN | 0.961927 |
| B | -1.457706 | NaN | |
| C | NaN | -0.344640 |
时间序列
pandas在对频率转换进行重新采样时拥有着简单,强大而且高效的功能(例如把按秒采样的数据转换为按5分钟采样的数据)。这在金融领域很常见,但又不限于此。
rng = pd.date_range('1/1/2012', periods=100, freq='S')
rng[:5]
DatetimeIndex(['2012-01-01 00:00:00', '2012-01-01 00:00:01',
'2012-01-01 00:00:02', '2012-01-01 00:00:03',
'2012-01-01 00:00:04'],
dtype='datetime64[ns]', freq='S')
ts = pd.Series(np.random.randint(0,500,len(rng)), index=rng)
ts
2012-01-01 00:00:00 193
2012-01-01 00:00:01 447
2012-01-01 00:00:02 407
2012-01-01 00:00:03 450
2012-01-01 00:00:04 368
...
2012-01-01 00:01:35 102
2012-01-01 00:01:36 446
2012-01-01 00:01:37 290
2012-01-01 00:01:38 256
2012-01-01 00:01:39 154
Freq: S, Length: 100, dtype: int32
ts.resample(‘5Min’) 表示对时间序列数据ts进行重采样,改变其索引的时间频率。
具体来说:
ts: 一个时间序列数据,索引为datetime类型。
'5Min': 表示将索引频率改为每5分钟一个。
resample函数将按照新频率重新采样,原索引不能被5分钟整除的时间点会被删除,新的索引会在5分钟的时间点上。
ts.resample('5Min')
# Datafream才这样写
# ts.resample('5Min', how='sum')
<pandas.core.resample.DatetimeIndexResampler object at 0x0000017E3D5A86D0>
时区表示
rng = pd.date_range('3/6/2012', periods=5, freq='D')
rng
DatetimeIndex(['2012-03-06', '2012-03-07', '2012-03-08', '2012-03-09',
'2012-03-10'],
dtype='datetime64[ns]', freq='D')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2012-03-06 -0.967180
2012-03-07 -0.917108
2012-03-08 0.252346
2012-03-09 0.461718
2012-03-10 -0.931543
Freq: D, dtype: float64
ts_utc = ts.tz_localize('UTC')
ts_utc
2012-03-06 00:00:00+00:00 -0.967180
2012-03-07 00:00:00+00:00 -0.917108
2012-03-08 00:00:00+00:00 0.252346
2012-03-09 00:00:00+00:00 0.461718
2012-03-10 00:00:00+00:00 -0.931543
Freq: D, dtype: float64
时区转换
ts_utc.tz_convert('US/Eastern')
2012-03-05 19:00:00-05:00 -0.967180
2012-03-06 19:00:00-05:00 -0.917108
2012-03-07 19:00:00-05:00 0.252346
2012-03-08 19:00:00-05:00 0.461718
2012-03-09 19:00:00-05:00 -0.931543
Freq: D, dtype: float64
时间跨度转换
rng = pd.date_range('1/1/2012', periods=5, freq='M')
rng
DatetimeIndex(['2012-01-31', '2012-02-29', '2012-03-31', '2012-04-30',
'2012-05-31'],
dtype='datetime64[ns]', freq='M')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
2012-01-31 -0.841095
2012-02-29 -1.548459
2012-03-31 -0.473997
2012-04-30 -0.602313
2012-05-31 -0.519119
Freq: M, dtype: float64
ps = ts.to_period()
ps
2012-01 -0.841095
2012-02 -1.548459
2012-03 -0.473997
2012-04 -0.602313
2012-05 -0.519119
Freq: M, dtype: float64
ps.to_timestamp()
2012-01-01 -0.841095
2012-02-01 -1.548459
2012-03-01 -0.473997
2012-04-01 -0.602313
2012-05-01 -0.519119
Freq: MS, dtype: float64
日期与时间戳之间的转换使得可以使用一些方便的算术函数。例如,我们把以11月为年底的季度数据转换为当前季度末月底为始的数据
prng = pd.period_range('1990Q1', '2000Q4', freq='Q-NOV')
prng
PeriodIndex(['1990Q1', '1990Q2', '1990Q3', '1990Q4', '1991Q1', '1991Q2',
'1991Q3', '1991Q4', '1992Q1', '1992Q2', '1992Q3', '1992Q4',
'1993Q1', '1993Q2', '1993Q3', '1993Q4', '1994Q1', '1994Q2',
'1994Q3', '1994Q4', '1995Q1', '1995Q2', '1995Q3', '1995Q4',
'1996Q1', '1996Q2', '1996Q3', '1996Q4', '1997Q1', '1997Q2',
'1997Q3', '1997Q4', '1998Q1', '1998Q2', '1998Q3', '1998Q4',
'1999Q1', '1999Q2', '1999Q3', '1999Q4', '2000Q1', '2000Q2',
'2000Q3', '2000Q4'],
dtype='period[Q-NOV]')
ts = pd.Series(np.random.randn(len(prng)), index = prng)
ts[:5]
1990Q1 -0.316562
1990Q2 -0.055698
1990Q3 -0.267225
1990Q4 0.514381
1991Q1 -0.716024
Freq: Q-NOV, dtype: float64
ts.index = (prng.asfreq('M', 'end') ) .asfreq('H', 'start') +9
ts[:6]
1990-02-01 09:00 -0.316562
1990-05-01 09:00 -0.055698
1990-08-01 09:00 -0.267225
1990-11-01 09:00 0.514381
1991-02-01 09:00 -0.716024
1991-05-01 09:00 1.530323
Freq: H, dtype: float64
分类
从版本0.15开始,pandas在DataFrame中开始包括分类数据。
df = pd.DataFrame({"id":[1,2,3,4,5,6], "raw_grade":['a', 'b', 'b', 'a', 'e', 'e']})
df
| id | raw_grade | |
|---|---|---|
| 0 | 1 | a |
| 1 | 2 | b |
| 2 | 3 | b |
| 3 | 4 | a |
| 4 | 5 | e |
| 5 | 6 | e |
把raw_grade转换为分类类型
df["grade"] = df["raw_grade"].astype("category")
df["grade"]
0 a
1 b
2 b
3 a
4 e
5 e
Name: grade, dtype: category
Categories (3, object): ['a', 'b', 'e']
重命名类别名为更有意义的名称
df["grade"].cat.categories = ["very good", "good", "very bad"]
C:\Users\48125\AppData\Local\Temp\ipykernel_17504\2985790766.py:1: FutureWarning: Setting categories in-place is deprecated and will raise in a future version. Use rename_categories instead.
df["grade"].cat.categories = ["very good", "good", "very bad"]
对分类重新排序,并添加缺失的分类
df["grade"] = df["grade"].cat.set_categories(["very bad", "bad", "medium", "good", "very good"])
df["grade"]
0 very good
1 good
2 good
3 very good
4 very bad
5 very bad
Name: grade, dtype: category
Categories (5, object): ['very bad', 'bad', 'medium', 'good', 'very good']
排序是按照分类的顺序进行的,而不是字典序
df.sort_values(by="grade")
| id | raw_grade | grade | |
|---|---|---|---|
| 4 | 5 | e | very bad |
| 5 | 6 | e | very bad |
| 1 | 2 | b | good |
| 2 | 3 | b | good |
| 0 | 1 | a | very good |
| 3 | 4 | a | very good |
按分类分组时,也会显示空的分类
df.groupby("grade").size()
grade
very bad 2
bad 0
medium 0
good 2
very good 2
dtype: int64
绘图
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
ts = ts.cumsum()
ts.plot()

对于DataFrame类型,**plot()**能很方便地画出所有列及其标签
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=['A', 'B', 'C', 'D'])
df = df.cumsum()
plt.figure(); df.plot(); plt.legend(loc='best')

获取数据的I/O
CSV
写入一个csv文件
df.to_csv('data/foo.csv')
从一个csv文件读入
pd.read_csv('data/foo.csv')
| Unnamed: 0 | A | B | C | D | |
|---|---|---|---|---|---|
| 0 | 2000-01-01 | -0.055622 | 1.889998 | -1.094622 | 0.591568 |
| 1 | 2000-01-02 | -0.408948 | 3.388888 | -0.550835 | 1.362462 |
| 2 | 2000-01-03 | -0.041353 | 1.880637 | -2.417740 | 0.383862 |
| 3 | 2000-01-04 | -0.442517 | 0.807854 | -2.409478 | 1.418281 |
| 4 | 2000-01-05 | 0.442292 | -0.735053 | -2.970804 | 1.435721 |
| ... | ... | ... | ... | ... | ... |
| 995 | 2002-09-22 | -28.470361 | 14.628723 | -68.388462 | -37.630887 |
| 996 | 2002-09-23 | -28.995055 | 14.517615 | -68.247657 | -36.363608 |
| 997 | 2002-09-24 | -28.756586 | 15.852227 | -68.328996 | -36.032141 |
| 998 | 2002-09-25 | -29.331636 | 15.557680 | -68.450159 | -35.825427 |
| 999 | 2002-09-26 | -31.065863 | 16.141154 | -68.852564 | -36.462825 |
1000 rows × 5 columns
HDF5
HDFStores的读写
写入一个HDF5 Store
df.to_hdf('data/foo.h5', 'df')
从一个HDF5 Store读入
pd.read_hdf('data/foo.h5', 'df')
| A | B | C | D | |
|---|---|---|---|---|
| 2000-01-01 | -0.055622 | 1.889998 | -1.094622 | 0.591568 |
| 2000-01-02 | -0.408948 | 3.388888 | -0.550835 | 1.362462 |
| 2000-01-03 | -0.041353 | 1.880637 | -2.417740 | 0.383862 |
| 2000-01-04 | -0.442517 | 0.807854 | -2.409478 | 1.418281 |
| 2000-01-05 | 0.442292 | -0.735053 | -2.970804 | 1.435721 |
| ... | ... | ... | ... | ... |
| 2002-09-22 | -28.470361 | 14.628723 | -68.388462 | -37.630887 |
| 2002-09-23 | -28.995055 | 14.517615 | -68.247657 | -36.363608 |
| 2002-09-24 | -28.756586 | 15.852227 | -68.328996 | -36.032141 |
| 2002-09-25 | -29.331636 | 15.557680 | -68.450159 | -35.825427 |
| 2002-09-26 | -31.065863 | 16.141154 | -68.852564 | -36.462825 |
1000 rows × 4 columns
Excel
MS Excel的读写
写入一个Excel文件
df.to_excel('data/foo.xlsx', sheet_name='Sheet1')
从一个excel文件读入
pd.read_excel('data/foo.xlsx', 'Sheet1', index_col=None, na_values=['NA'])
| Unnamed: 0 | A | B | C | D | |
|---|---|---|---|---|---|
| 0 | 2000-01-01 | -0.055622 | 1.889998 | -1.094622 | 0.591568 |
| 1 | 2000-01-02 | -0.408948 | 3.388888 | -0.550835 | 1.362462 |
| 2 | 2000-01-03 | -0.041353 | 1.880637 | -2.417740 | 0.383862 |
| 3 | 2000-01-04 | -0.442517 | 0.807854 | -2.409478 | 1.418281 |
| 4 | 2000-01-05 | 0.442292 | -0.735053 | -2.970804 | 1.435721 |
| ... | ... | ... | ... | ... | ... |
| 995 | 2002-09-22 | -28.470361 | 14.628723 | -68.388462 | -37.630887 |
| 996 | 2002-09-23 | -28.995055 | 14.517615 | -68.247657 | -36.363608 |
| 997 | 2002-09-24 | -28.756586 | 15.852227 | -68.328996 | -36.032141 |
| 998 | 2002-09-25 | -29.331636 | 15.557680 | -68.450159 | -35.825427 |
| 999 | 2002-09-26 | -31.065863 | 16.141154 | -68.852564 | -36.462825 |
1000 rows × 5 columns
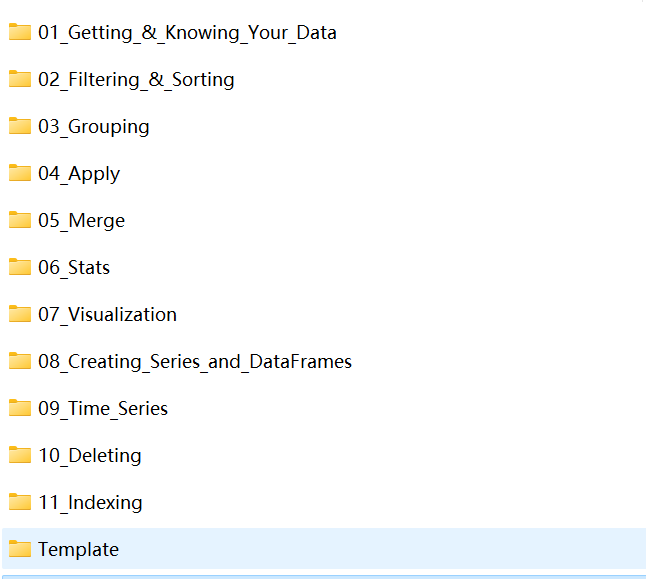 Pandas练习题目录
Pandas练习题目录
1.Getting and knowing
- Chipotle
- Occupation
- World Food Facts
2.Filtering and Sorting
- Chipotle
- Euro12
- Fictional Army
3.Grouping
- Alcohol Consumption
- Occupation
- Regiment
4.Apply
- Students
- Alcohol Consumption
- US_Crime_Rates
5.Merge
- Auto_MPG
- Fictitious Names
- House Market
6.Stats
- US_Baby_Names
- Wind_Stats
7.Visualization
- Chipotle
- Titanic Disaster
- Scores
- Online Retail
- Tips
8.Creating Series and DataFrames
- Pokemon
9.Time Series
- Apple_Stock
- Getting_Financial_Data
- Investor_Flow_of_Funds_US
10.Deleting
- Iris
- Wine
使用方法
每个练习文件夹有三个不同类型的文件:
1.Exercises.ipynb
没有答案代码的文件,这个是你做的练习
2.Solutions.ipynb
运行代码后的结果(不要改动)
3.Exercise_with_Solutions.ipynb
有答案代码和注释的文件
你可以在Exercises.ipynb里输入代码,看看运行结果是否和Solutions.ipynb里面的内容一致,如果真的完成不了再看下Exercise_with_Solutions.ipynb的答案。
每文一语
开教传授,私信教学!!!