操作系统概述
bit和byte区别
bit 位
说白了就是0或者1;计算机内存中的存储都是01这两个东西。
byte(B) 字节
-
1byte=8bit(一字节 = 8比特)
-
1byte就是1B
-
1byte 存1个英文字母,2个byte存一个汉字。
了解
操作系统的作用: 通过资源管理提高计算机系统的效率,改善人机界面,向用户提供友好的工作环境。
操作系统的特征:并发性、共享性、虚拟性、不确定性。
操作系统的功能:进程管理、存储管理、文件管理、设备管理、作业管理(不考)。
操作系统的分类:批处理操作系统、分时操作系统(轮流使用CPU工作片)、实时操作系统(快速响应)、网络操作系统、分布式操作系统(物理分散的计算机互联系 统)、微机操作系统(Windows)、嵌入式操作系统。
计算机启动的基本流程为:BOS->主引导记录->操作系统。
进程管理
进程的组成和状态
进程的组成:
进程控制块PCB(唯一标志),程序(描述进程要做什么),数据(存放进程执行时所需数据)
进程基础的状态是下左图中的三态图,这是系统自动控制时只有三种状态,而下右图 中的五态,是多了两种状态:静止就绪和静止阻塞,需要人为的操作才会进入对应状 态,活跃就绪即就绪,活跃阻塞即等待。
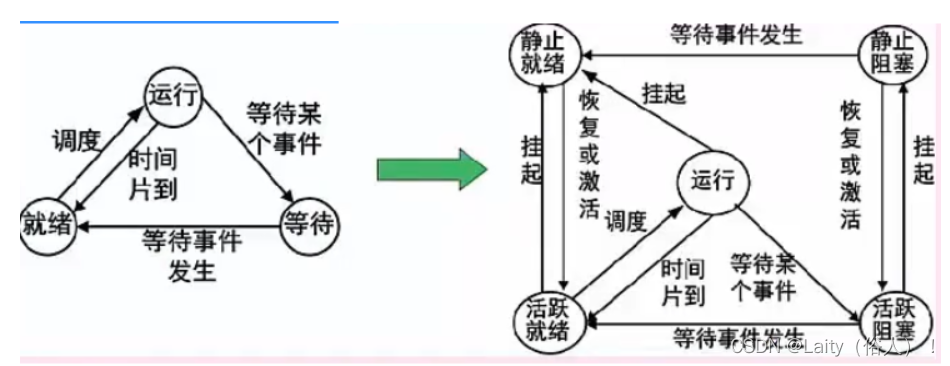
可知,当人为干预后,进程将被挂起,进入静止状态,此时,需要人为激活,才能恢复到活跃状态,之后的本质还是三态图。
- 等待 和 就绪的区别 ?? 等待 需要有io或者外设的输入 , 就绪则是等待cpu的调度
前趋图
前趋图作用:
用来表示任务并行或串行执行关系,任务之间顺序关系,例如:
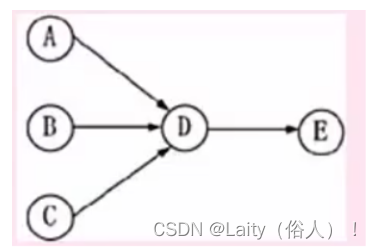
可知,ABC可以并行执行,到DE是串行,确定了入无间的并行、任务间的先后顺序。
进程资源图
进程资源图作用:
用来表示进程和资源之间的分配和请求关系。
阻塞节点 和 非阻塞节点
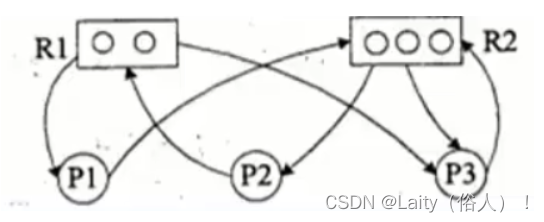
例如:
P代表进程,R代表资源,R方框中有几个圆球就表示 有几个这种资源,在图中,R1指向P1,表示R1有 个资源已经分配给了P1,P1指向R2,表示P1还需要 请求一个R2资源才能执行
阻塞节点:某进程所请求的资源已经全部分配完毕,无法获取所需资源,该进程被阻 塞了无法继续。如上图中P2。
非阻塞节点:某进程所请求的资源还有剩余,可以分配给该进程继续运行。如上图中 P1、P3.
当一个进程资源图中所有进程都是阻寒节点时,即陷入死锁状态。
进程资源图化简的方法: – 即所有进程不会发生死锁
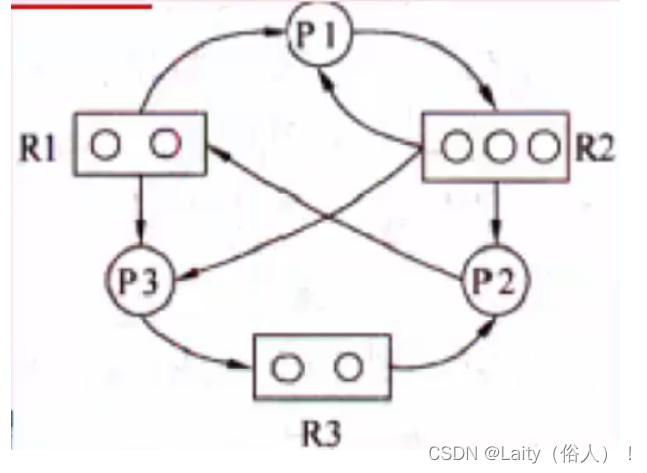
先看系统还剩下多少资源没分配,再看有哪些进程是不阻塞的,接着把不阻塞的进程的所有边都去掉,形成一个孤立的点,再把系统分配给这个进程的资源回收回来,这样,系统剩余的空闲资源便多了起来,接着又去看看剩下的进程有哪些是不阻塞的,然后又把它们逐个变成孤立的点。最后,所有的资源和进程都变成孤立的点。图中p3是不阻寒的,故P3为化简图的开始,把P3孤立再回收分配给他的资源,可以看到P1也变为不阻塞节点了,故P3、P1、P2是可以的。
同步和互斥
同步和互斥不是反义词!!!
互斥:某资源(即临界资源)在同一时间内只能由一个任务单独使用,使用时需要加锁,使用完后解锁才能被其他任务使用;如打印机。
同步:多个任务可以并发执行,只不过有速度上的差异,在一定情况下停下等待,不存在资源是否单独或共享的问题;如自行车和汽车。
临界资源:各进程间需要以互斥方式对其进行访问的资源。
临界区:指进程中对临界资源实施操作的那段程序。本质是一段程序代码。
信号量操作
两类信号量
互斥信号量:对临界资源采用互斥访问,使用互斥信号量后其他进程无法访问,初值 1(类似于true),信号量代表的是前趋图里进程的一个操作(一个互斥量只能用于一个资源的互斥访问,它不能实现多个资源的多线程互斥问题)。
- 解读:https://blog.csdn.net/qq_36362721/article/details/118915361
同步信号量:对共享资源的访问控制,初值一般是共享资源的数量。
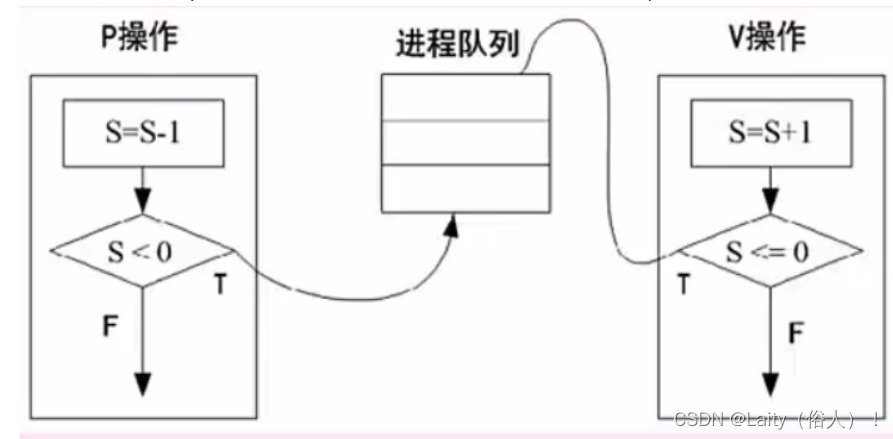
P操作(Passeren通过–荷兰语):申请资源,S=S-1,若s>=0,则执行P操作的进程继续执行;若S<0,则置该进程为阻塞状态(因为无可用资源),并将其插入阻塞队列。
V操作(Vrijgeven释放–荷兰语):释放资源,S=S+1,若s>0,则执行V操作的进程继续执行;若s<=0,则从阻塞状态唤醒一个进程,并将其插入就绪队列(此时因为缺少资源被P操作阻塞的进程可以继续执行),然后执行V操作的进程继续。
生产者和消费者问题【经典问题】
三个信号量:
互斥信号量S0(仓库独立使用权),同步信号量S1(仓库空闲个数), 同步信号量S2(仓库商品个数)。
| 生产者流程 | 消费者流程 |
|---|---|
| 生产一个商品S | P(S0) |
| P(S0) | P(S2) |
| P(S1) | 取出一个商品 |
| 将商品放入仓库中 | V(S1) |
| V(S2) | V(S0) |
| V(S0) |
必考例题:
– 截屏 –
死锁
当一个进程在等待永远不可能发生的事件时,就会产生死锁,若系统中有多个进程处 于死锁状态,就会造成系统死锁。
死锁四个必要条件
资源互斥,每个进程占有资源并等待其他资源,系统不能剥夺现场资源,进程资源图是一个环路
死锁避免:
一般采用银行家算法来避免,银行家算法,就是提前计算出一条不会死锁 的资源分配方法,才分配资源,否则不分配资源,相当于借贷,考虑对方还得起才借 钱,提前考虑好以后,就可以避免死锁。
死锁计算问题:
系统内有n个进程,每个进程都需要R个资源,那么其发生死锁的最大 资源数为n*(R-1)。其不发生死锁的最小资源数为n(R-1)+1。
例:某个系统中有3个并发进程资源,每个进程需要5个R,那么至少有(?)个R,才能保证系统不会发生死锁。
3*4+1 = 13
银行家算法真题
【重点】
进程和线程
进程是拥有资源的最小单位
线程是独立调度的最小单位
线程可以共享进程的公共数据、全局变量、代码、文件等资源;但不能共享线程独有的资源,如线程的栈指针等表示数据。
存储管理
存储器的结构:寄存器–高速缓存Cache–主存–外存
地址重定位:将逻辑地址转化为实际主存物理地址的过程,分为静态重定位(在程序装入主存是就完成了转化)、动态重定位(边运行边转化)
分区存储管理
所谓分区存储组织,就是整存,将某进程运行所需的内存整体一起分配给它,然后再执行。
有三种分区方式:
固定分区:静态分区方法,将主存分为若干个固定的分区,由于分区固定,大小和作业所需的大小不同,会产生内部碎片。
可变分区:动态分区方法,分区实在作业转入时划分所需大小,不存在内部碎片,但存在外部碎片
可变分区的算法
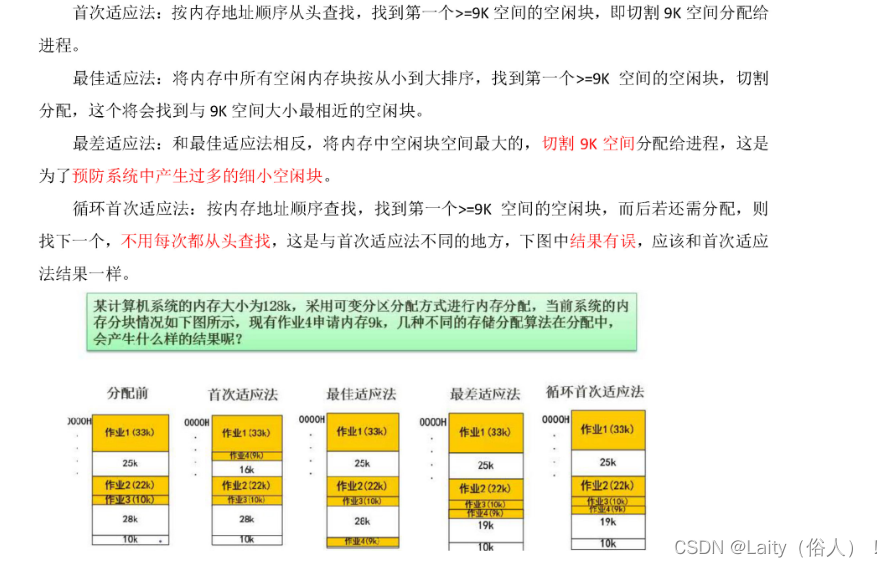
**可重定位分区:**可以解决碎片问题。前两个整合。
页式存储管理
如果采用分区存储,都是整存,就会出现一个问题,即当进程运行所需的内存大于系统内存时,就无法将整个进程一起调入内存,因此无法运行。页式存储是基于可变分区而提出的,
页(逻辑地址) 和 块(物理地址)的区别
页:对程序进行分页存储
块:对内存进行分块存储
页(逻辑地址):由两部分组成,即页号(2^n 段内最大页数) + 页内地址(2^n 每个页的大小B)!
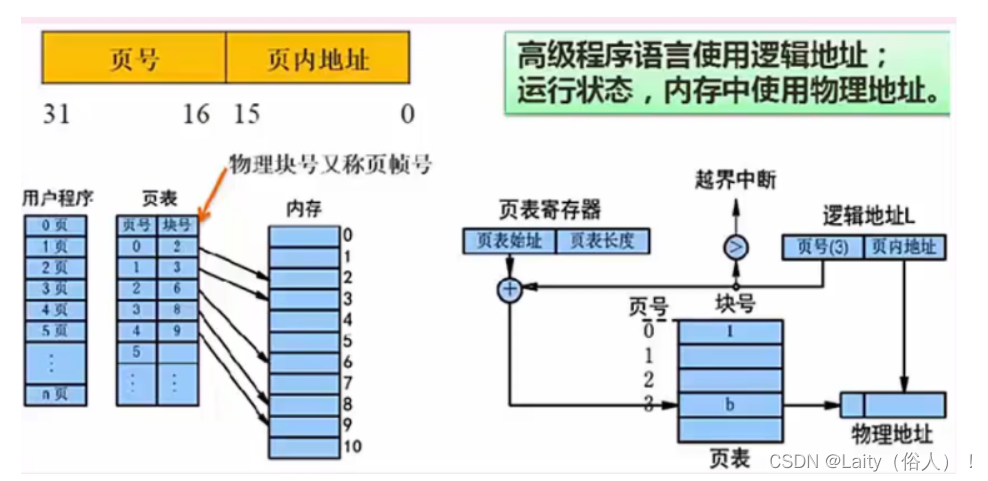
优点:利用率高、碎片小(只在最后一个页中有)、分配及管理简单。
缺点:增加了系统开销,可能产生抖动现象。
例题:某计算机系统页面大小为4k,若进程的页面变换表如下所示,逻辑地址为十六进制1D16H。该地址进过变换后,其物理地址应为十六进制(?)。
页号 物理块号
0 1
1 3
2 4
3 6
解:
页面地址 为4k = 2^12
逻辑地址 = 页号【1】 + 页内地址(2^12即3位)【D16】 , 页号就只有1位
对应表后 - 页内地址大小是不变的:
物理地址 = 3D16H
其实就是 (第一位页号 替换成对应 物理块号)+页内地址
页面淘汰原理
1. 系统应该先淘汰未被访问的页面
2. 如果页面最近都被访问,先淘汰未修改过的页面,因为未修改过的页面内存和辅存一直,无需写回辅存,使系统页面置换代价小
快表
快表是将当前访问最频繁的页表存于Cache中;慢表示将页表存于内存上。
因此慢表需要访问两次内存才能取出页,而快表是访问一次Cache和一次内存,因此快。
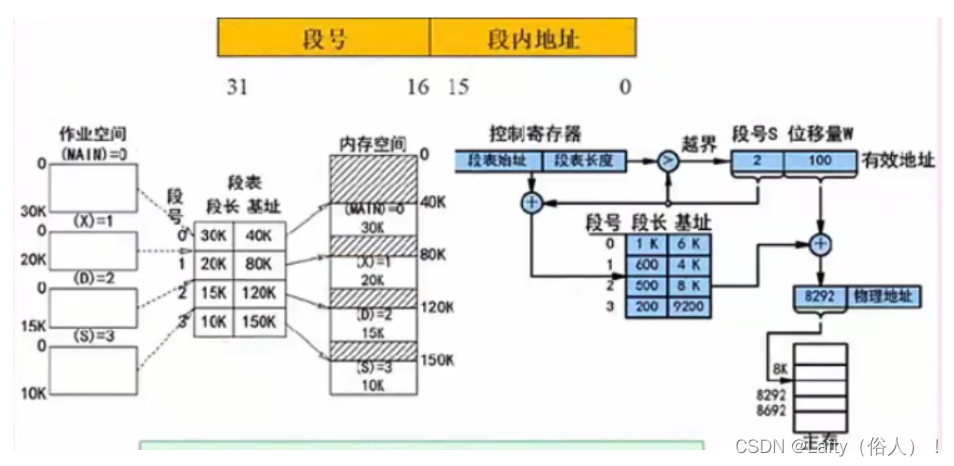
段式存储管理
将进程空间分为一个个段,每段也有段号和段内地止(段长),与页式存储不同的是,每段物理大小不同,分段是根据逻辑整体分段的。
段表:
- 基址:内存空间开始的地址
- 段长:当前段所需要的内存空间
优点:逻辑清晰
缺点:内存利用率低,内存碎片浪费大
例:
(0,1597) -- 0段号 1597段长
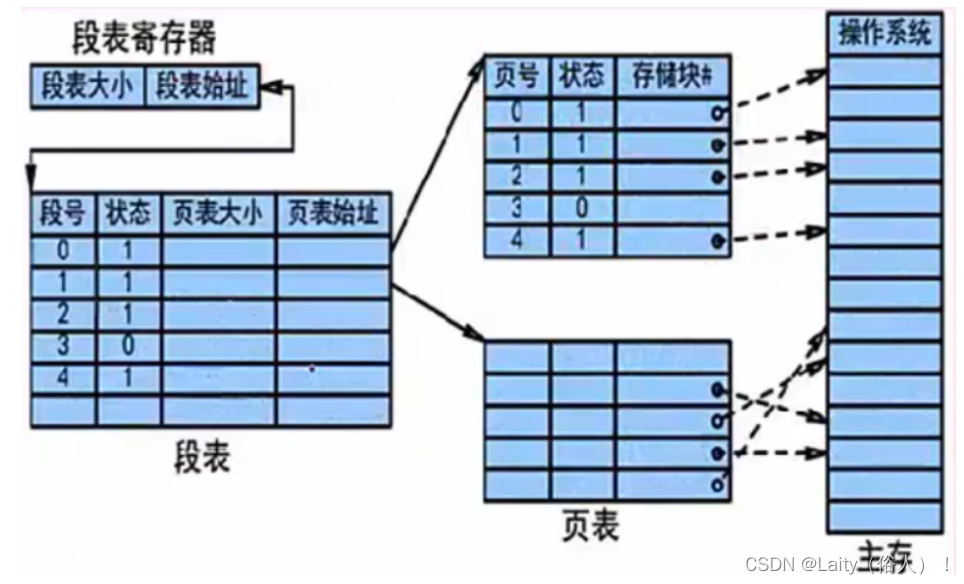
段页式存储管理
对进程空间先分段,后分页,具体原理图和优缺点如下:
优点:空间浪费小、存储共享容易、能动态连接。
缺点:由于管理软件的增加,复杂性和开销也增加,执行速度下降
页面置换算法
有时候,进程空间分为100个页面,而系统内存只有10个物理块,无法全部满足分配,就需要 将马上要执行的页面先分配进去,而后根据算法进行淘汰,使100个页面能够按执行顺序调入 物理块中执行完。
缺页表示需要执行的页不在内存物理块中,需要从外部调入内存,会增加执行时间,因此, 缺页数越多,系统效率越低。
- 最优算法:OPT,理论上的算法,无法实现,是在进程执行完后进行的最佳效率计算,用来 让其他算法比较差距。原理是选择未来最长时问内不被访问的页面置换,这详可以保证未来 执行的都是马上要访问的。
- 先进先出算法:FO,先调入内存的页先被置换淘汰,会产生抖动现象,即分配的页数越多, 缺页率可能越多(即效率越低),缺页计算如下:
- 最近最少使用:LU,在最近的过去,进程执行过程中,过去最少使用的页面被置换淘汰,根 据局部性原理,这种方式效率高,且不会产生抖动现象。
例题:。。。。淘汰表中页号(?)代价最小 状态位,访问位,修改位
解析:
淘汰最近没有被访问过的,在看最近没有被修改过的!
文件管理
索引文件结构
计算机系统中采用的索引文件结构如下图所示:
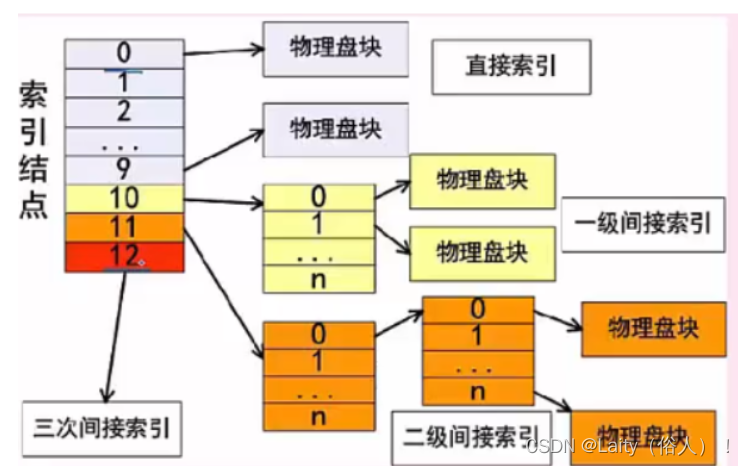
上例中:
系统中有13个索引节点
0-9为直接索引,即每个索引节点存放的是内容,假设每个物理盘大 小为4KB,共可存4KB*10=40KB数据;
10号索引节点为一级间接索引节点,大小为4KB,存放的并非直接数据,而是链接到直接物理 盘块的地址,假设每个地址占4B,4kb/4B=1K,则共有1024个地址,对应1024个物理盘,可存1024* 4KB=4098KB数据。
11号为二级索引节点类似,直接盘存放一级地址, 一 级地址再存放物理盘快地址, 而后链接到存放数据的物理盘块, 容量又扩大了一个数量级, 为1024*1024*4KB数据。
以此类推。。
列题:设文件索引结点中有8个地址项,每个地址项大小为4字节,其中5个地址为直接地址索引,2给地址项是一级间接地址索引,1个地址项是二级间接地址索引,磁盘索引块和磁盘数据块大小均为1KB,若要访问文件的逻辑块号分别为5和518,则系统分别采用(??),而且可表示的单个文件最大长度是(?)KB。
逻辑块号默认从0开始
直接地址索引 0 -- 4
一级间接地址索引2个 5 -- 5+1KB/4*1KB*2-1 == 5 -- 516
二级间接地址索引1个 516 -- 516+(1KB/4*1KB/4*1KB)-1
单个文件最大长度是 直接地址索引+一级间接地址索引*2+二级间接地址索引 = 66053
多级索引结构计算【计算磁盘块有多少物理块】
题目:某文件系统采用多级索引结构,若磁盘块的大小为512B,每个块号需占3B,那么根索引采用一级索引时的文件最大长度为 (?) KB;采用二级索引时的文件最大长度为 (?) KB。
解:
直接索引:即直接存放在物理块中!
一级索引:即一个索引指向一整个 磁盘块的 地址,
首先计算出磁盘有多少个块号 513/3 = 170(块)
170*512B 即最大长度,单位转换 160*512B/1024=85KB
二级索引:即存放一级索引地址!
170块*170块*512B/1024=14460KB
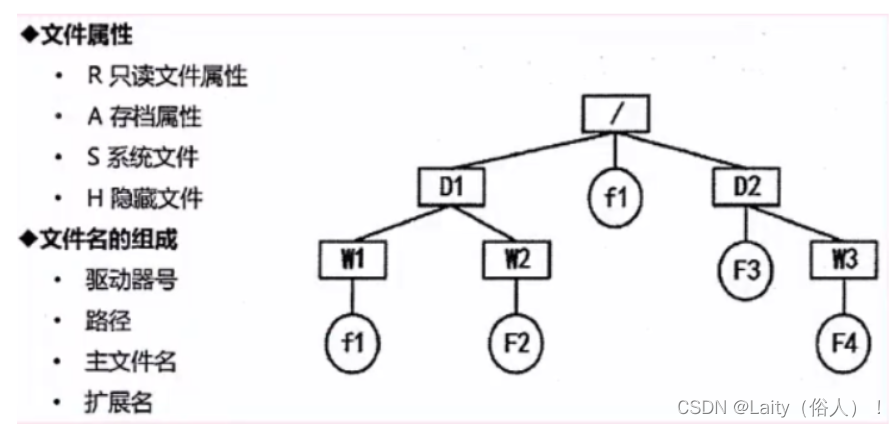
文件和树形目录结构
文件安全分为四级,从高到底:
- 系统安全
- 用户安全
- 目录安全
- 文件安全
相对路径:是从当前路径开始的路径。
绝对路径:是从根目录开始的路径。
全文件名=绝对路径+文件名。要注意,绝对路径和相对路径是不加最后的文件名的,只是单纯的路径序列.
树形结构主要是区分相对路径和绝对路径,如下图:
空闲存储空间管理
空闲区表法:将所有空闲空间整合成一张表,即空闲文件目录。【不考】
空闲链表法:将所有空闲空间链接成一个链表,根据需要分配。【不考】
成组链接法:既分组,每组内又链接成链表,是上述两种方法的综合。【不考】
位示图法:对每个物理空间用一位标识,为1则使用,为0则空闲,形成一张位示图。
题目1:某文件管理系统在磁盘上建立了位示图(bitmap) ,记录磁盘的使用情况。若计算机系统的字长为 32 位,磁盘的容量为 300GB ,物理块的大小为4MB ,那么位示图的大小需要( )个字。
磁盘容量为300GB,物理块大小4MB,则磁盘共3001024/4=751024个物理块,位示图用每1位表示1个磁盘块的使用情况,1个字是32位,所以1个字可以表示32块物理块使用情况,那么需要75*1024/32=2400个字
题目2:某文件管理系统采用位示图(bitmap)记录磁盘的使用情况。如果系统的字长为32位(一个字有32个物理块),磁盘物理块大小为4MB,物理块和位示图依次编号从0开始,那么16385号物理块的使用情况在位示图中的第(?)个字中描述:如果磁盘容量为1000GB,那么位示图需要(?)个字来表示。
第16385号物理块 = 16386(物理块)
字长与物理块的关系:设字长为32位,也就是说每个字可以记录32个物理块的使用情况
一个字的位数 16386(物理块)/32(物理块) = 512 ... 2 即是513字,第512字(从0开始)
1000GB / 4MB = 250*1024(bit) /32 = 8000
设备管理
设备的分类方式:
-
按数据组织分类:块设备、字符设备。
-
资源分配角度分类:独占设备、共享设备和虚拟设备。
-
数据传输速率分类:低速设备、中速设备、高速设备。
I/O软件层次结构:【会考】
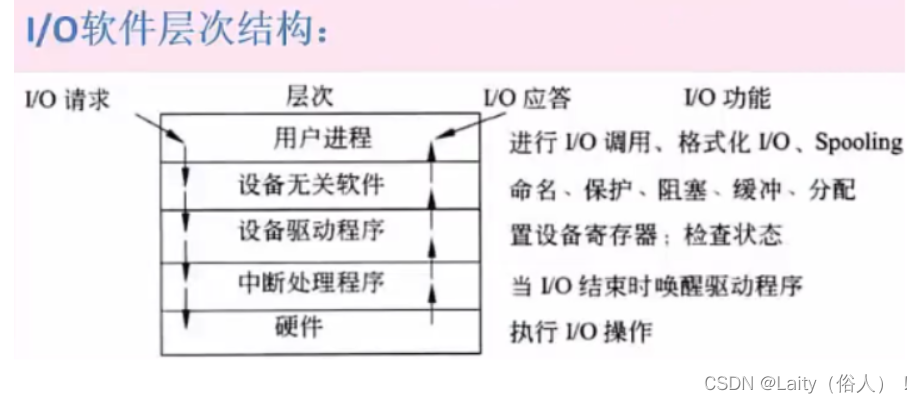
输入输出技术
-
程序控制(查询)方式:CPU主动查询外设是否完成数据传输,效率极低。
-
程序中断方式:外设完成数据传输后,向cPU发送中断,等待CPU处理数据,效率相对较高。适用于键盘等实时性较高的场景。
- 中断响应时间指的是从发出中断请求到开始进入中断处理程序;中断处理时间指的是从中断处理开始到中断处理结束。中断向量提供中断服务程序的入口地址。多级中断嵌套,使用堆栈来保护断点和现场。
-
DMA方式(直接主存存取):CPU只需完成必要的初始化等操作,数据传输的整个过程都由DMA控制器来完成,在主存和外设之间建立直接的数据通路,效率很高。适用于硬盘等高速设备。
- 在一个总线周期结束后,CPU会响应DMA请求开始读取数据;CPU响应程序中断方式请求是在一条指令执行结束时;区分指令执行结束和总线周期结束。
占用CPU时间按多到少排序:程序查询方式(程序控制方式)>程序中断方式>DMA工作方式>通道方式>I/O处理机。
虚设备和SPOOLING技术
一台实际的物理设备,例如打印机,在同一时间只能由一个进程使用,其他进程只能等待, 且不知道什么时候打印机空闲,此时,极大的浪费了外设的工作效率。【互斥】
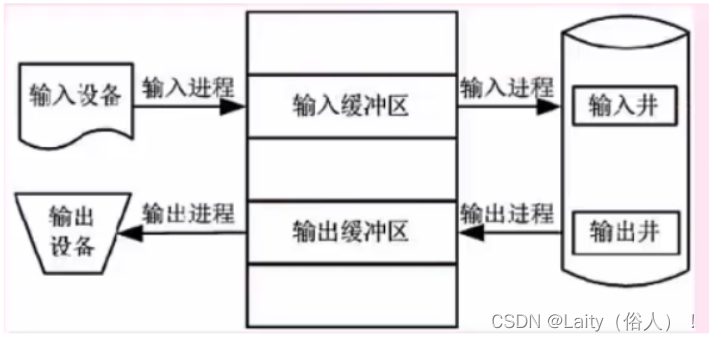
引入SPOOLING技术,就是在外设上建立两个数据缓冲区【队列】,分别称为输入井和输出井,这样, 无论多少进程,都可以共用这一台打印机,只需要将打印命令发出,数据就会排队存储在缓 冲区中,打印机会自动按顺序打印,实现了物理外设的共享,使得每个进程都感觉在使用 个打印机,这就是物理设备的虚拟化。如下图所示:
磁盘结构
磁盘有正反两个盘面,每个盘面有多个同心圆,每个同心圆是一个磁道,每个同心圆又被划分为多个扇区,数据就被存放在一个个扇区中。
读取数据时,磁头首先要寻找到对应的磁道,然后等待磁盘进行周期旋转,旋转到指定 的扇区,才能读取到对应的数据,因此,会产生寻道时间和等待时间,就是磁头移动到 磁道所需的时间和等待读写的扇区转到磁头的下方所用的时间。其中寻道时间耗时最长, 寻道时间的调度算法如下:
-
先来先服务FCFS:根据进程请求访问磁盘的先后顺序进行调度。
-
最短寻道时间优先SSTF:请求访问的磁道与当前磁道最近的进程优先调度,使得每次的 寻道时间最短。会产生“饥饿”现象,即远处进程可能永远无法访问。
-
扫描算法SCAN:又称“电梯算法”,磁头在磁盘上双向移动,其会选择离磁头当前所在 磁道最近的请求访问的磁道,并且与磁头移动方向一致,磁头永远都是从里向外或者从 外向里一直移动完才掉头,与电梯类似。
-
单向扫描调度算法CSCAN:与SCAN不同的是,其只做单向移动,即只能从里向外或者从 外向里。
例:某磁盘有100个磁盘,磁头从一个磁道移至另一个磁道需要6ms。文件在磁盘上非连续存放,逻辑上相邻数据块的平均距离位10个磁道,每块的旋转延迟时间及传输时间分别为100ms和20ms,则读取一个100块的文件需要(?)ms。
解:磁盘读取时间 = 寻道时间+等待时间(周期旋转)
寻道时间: 10*6 = 60ms
等待时间: 100+20 = 120ms
100个磁道 (120+60)*100 = 18000ms
柱面,磁头和扇区
硬盘划分为 磁头,柱面,扇区
- 磁头:每张磁片的正反面各有一个磁头,一个磁头对应一张磁片的一个面,因此用第几个磁头就可以标识数据在哪个磁面
- 柱面:所有磁片中半径相同的同心构成柱面,意思是这一系列的磁道垂直叠在一起,就是柱面形状,简单的理解,柱面就是磁道
- 扇区:将磁道划分位若干个小的区段就是扇区,每个扇区的一般大小为512字节
采用 单缓冲区和双缓冲区
但缓冲区:一条一条的执行,效率低
双缓冲区:先将数据存入缓存区,在一次性传送至用户区
作业管理
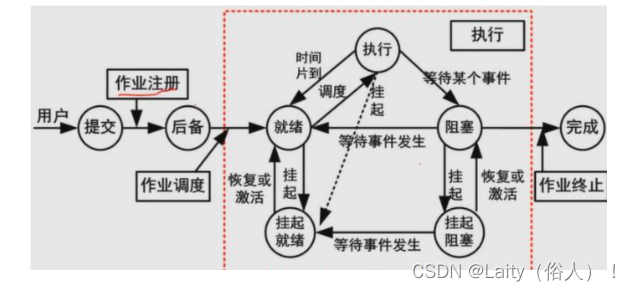
作业状态与作业管理
作业有四种状态:提交、后备、执行、完成。其中执行就是作业调入系统中执行,与进程执行类似。
实际上,作业调度是比进程调度更高级的调度,以整体可执行的作业为调度单位。

作业调度算法
- 优先级:按作业优先级来决定先执行哪个作业
- 先来先服务FCFS:按作业调入时间顺序
- 短作业优先SJF(Shot Job First):按作业的时间长度来决定,运行时间短的优先
- 响应比高者优先HRN:定义响应比公式:(等待时间+运行时间)/运行时间,高者优先执行,即等的越久,就先执行
- 定时转轮(时间片转轮):将一个作业分为n分,并行时轮询1/n执行,强调雨露均沾
作业周转时间
-
单个作业周转时间:作业进入系统时间点-作业执行完时间点
-
作业平均周转时间:作业周转时间/作业数
-
单个作业的带权周转时间:作业的周转时间/作业的实际运行 时间
操作系统分类
嵌入式操作系统
嵌入式操作系统特点:微型化、代码质量高、专业化、实时性强、可裁剪可配置。
实时嵌入式操作系统的内核服务:异常和中断、计时器、i/o管理。
常见的嵌入式RTOS(实时操作系统):VxWorks、RT-Linux、QNX、pSOS。
嵌入式系统初始化过程按照自底向上、从硬件到软件的次序依次为:
片级初始化->板级初始化->系统初始化。
芯片级是微处理器的初始化,板卡级是其他硬件设备初始化,系统级初始化就是软件及操作 系统初始化。
微内核操作系统
微内核,顾名思义,就是尽可能的将内核做的很小,只将最为核心必要的东西放入内核中,其他能独立的东西都放入用户进程中,这样,系统就被分为了用户态和内核态。
参考文献
- 前趋图和信号量:https://blog.csdn.net/qq_36362721/article/details/118915361



![[go学习笔记.第十五章.反射] 1.反射的基本介绍以及实践](https://img-blog.csdnimg.cn/45de9293f3564768b6ca6794279c3ffb.png)