一、PyTorch的简介和安装
因为在学习pytorch之前就已经配置和安装好了相关的环境和软件,所以这里就不对第一章进行详细的总结,就简要总结一下:
1.1 pytorch的发展
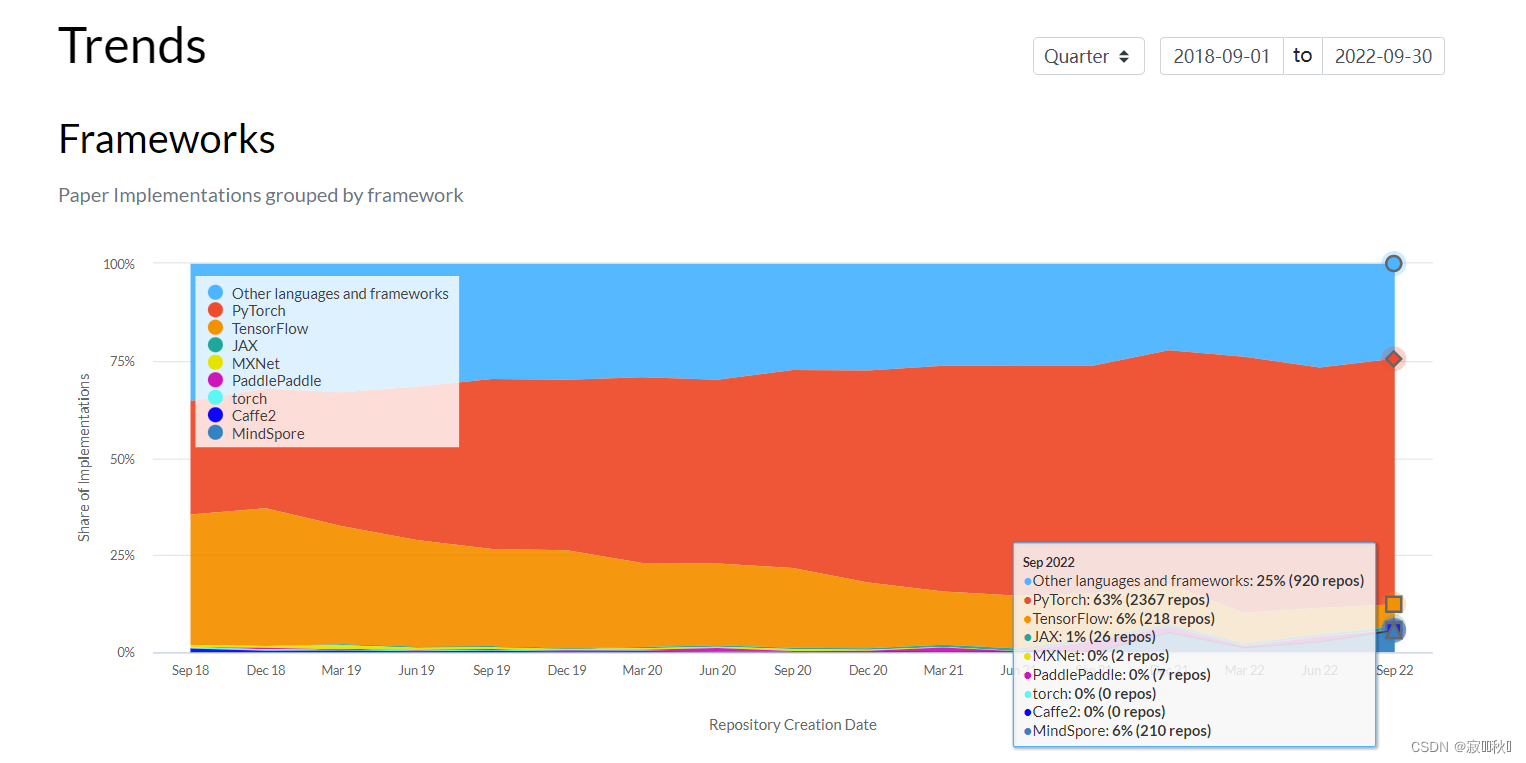
去了Paper with code网站查看了现在pytorch的使用,远超tensorflow
1.2 PyTorch的优势
简洁、上手快、良好的文档API、社区强大、项目开源。
1.3 PyTorch的安装
1.3.1 Anaconda的安装
官网:Anaconda | Individual Edition
安装成功你的电脑会有以下应用。
1.3.2 查看显卡
(1)使用NVIDIA控制面板
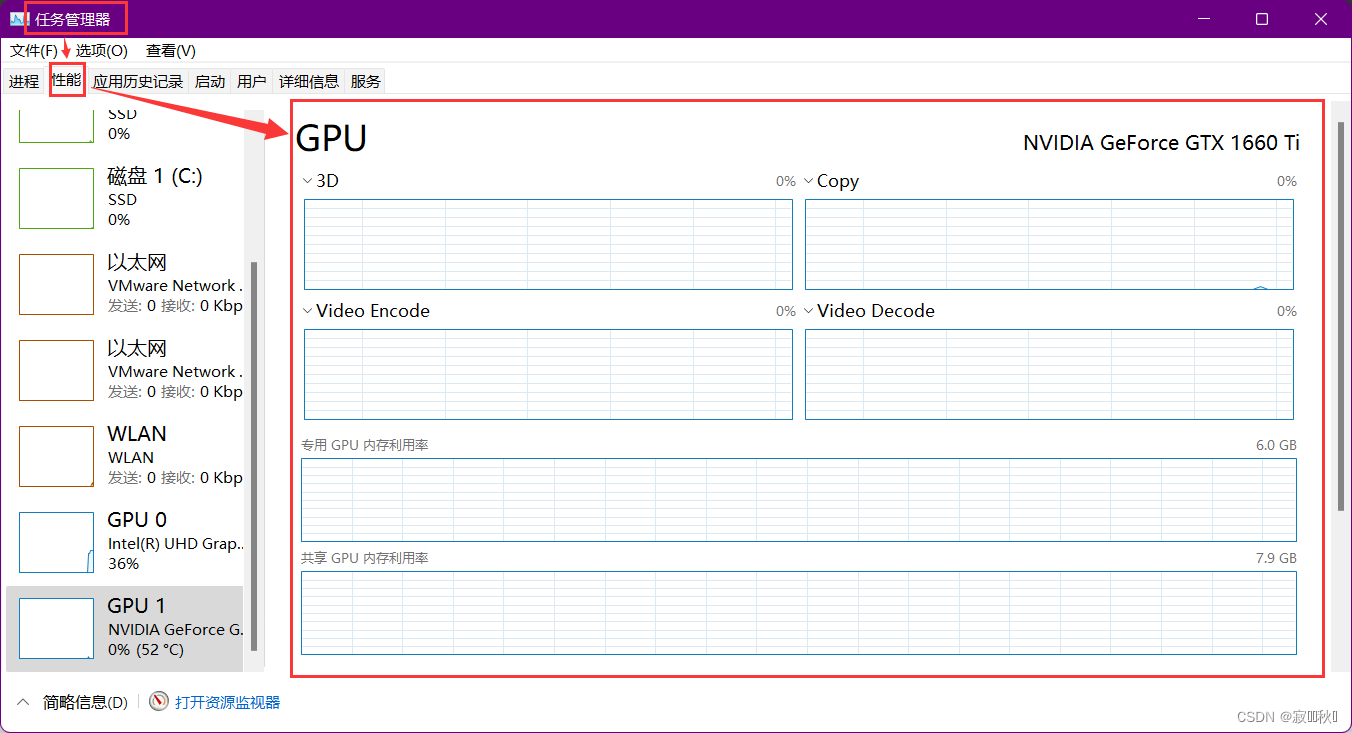
(2)使用任务管理器查看自己是否有NVIDIA的独立显卡及其型号
打开自己任务管理器——>性能
1.4 PyTorch安装
(1)官网:PyTorch官网
(2)进入官网找到适合自己电脑的pytorch,使用conda下载或者pip下载(建议conda安装),可以结合电脑是否有显卡,选择CPU版本还是CUDA版本,CUDA版本需要拥有独显且是NVIDIA的GPU
(3)检验是否安装成功,打开Anaconda终端
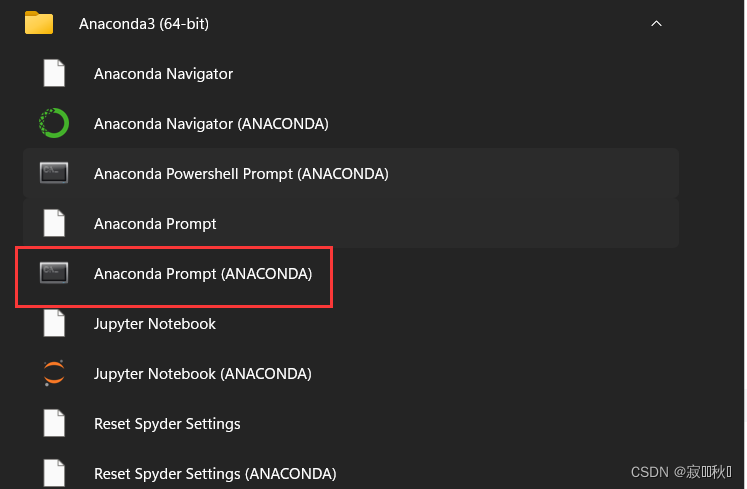
输入以下代码,如果显示Ture,则说明安装成功,可以使用。
import torch
torch.cuda.is_available()1.5 pycharm安装
(1)官网
(2)建议配置Anaconda的内置环境,这样电脑就不要重复下载了。
二、PyTorch基础知识
2.1 张量
2.1.1 简介
| 张量维度 | 代表含义 |
| 0维张量 | 标量(数字) |
| 1维张量 | 向量 |
| 2维张量 | 矩阵 |
| 3维张量 | 时间序列数据、股价、文本数据、单张彩色图片(RGB) |
2.1.2 创建tensor
以下为创建tensor的几种方法,用法如下,举一例:
import torch
torch.zeros(4,3)
# 创建的时候输入类型 torch.zeros(4,3,dtype=torch.long)| Tensor(sizes) | 基础构造函数 |
| tensor(data) | 类似于np.array |
| ones(sizes) | 全1 |
| zeros(sizes) | 全0 |
| eye(sizes) | 对角为1,其余为0 |
| arange(s,e,step) | 从s到e,步长为step |
| linspace(s,e,steps) | 从s到e,均匀分成step份 |
| rand/randn(sizes) | rand是[0,1)均匀分布;randn是服从N(0,1)的正态分布 |
| normal(mean,std) | 正态分布(均值为mean,标准差是std) |
| randperm(m) | 随机排列 |
2.1.3 张量的操作
(1)运算
| 直接相加(四则运算都可) | x+y |
| 使用torch.add() | torch.add(x,y) |
| 进行原值修改 | y.add_(x) |
| 求幂 | torch.exp(x) |
(2)索引操作
| 取元素 | x[1:3] |
| 取第一行 | x[0,:] |
| 取第一列 | x[:,0] |
索引出来的结果与原数据共享内存,修改一个,另一个会跟着修改
2.1.4 维度变换
torch.view(),简要的说就是我们创建一个矩阵,然后通过view()从不同的维度去观察这个矩阵,当然在我们对原矩阵进行操作更改后,我们从不同维度进行观察时也会发生改变。这里我们就可以先将原来的进行深度复制,用一个变量进行存储,防止后面的数据丢失
2.1.5 广播机制

2.2 自动求导
2.2.1 autograd的求导机制
“一个设置,三个函数量”

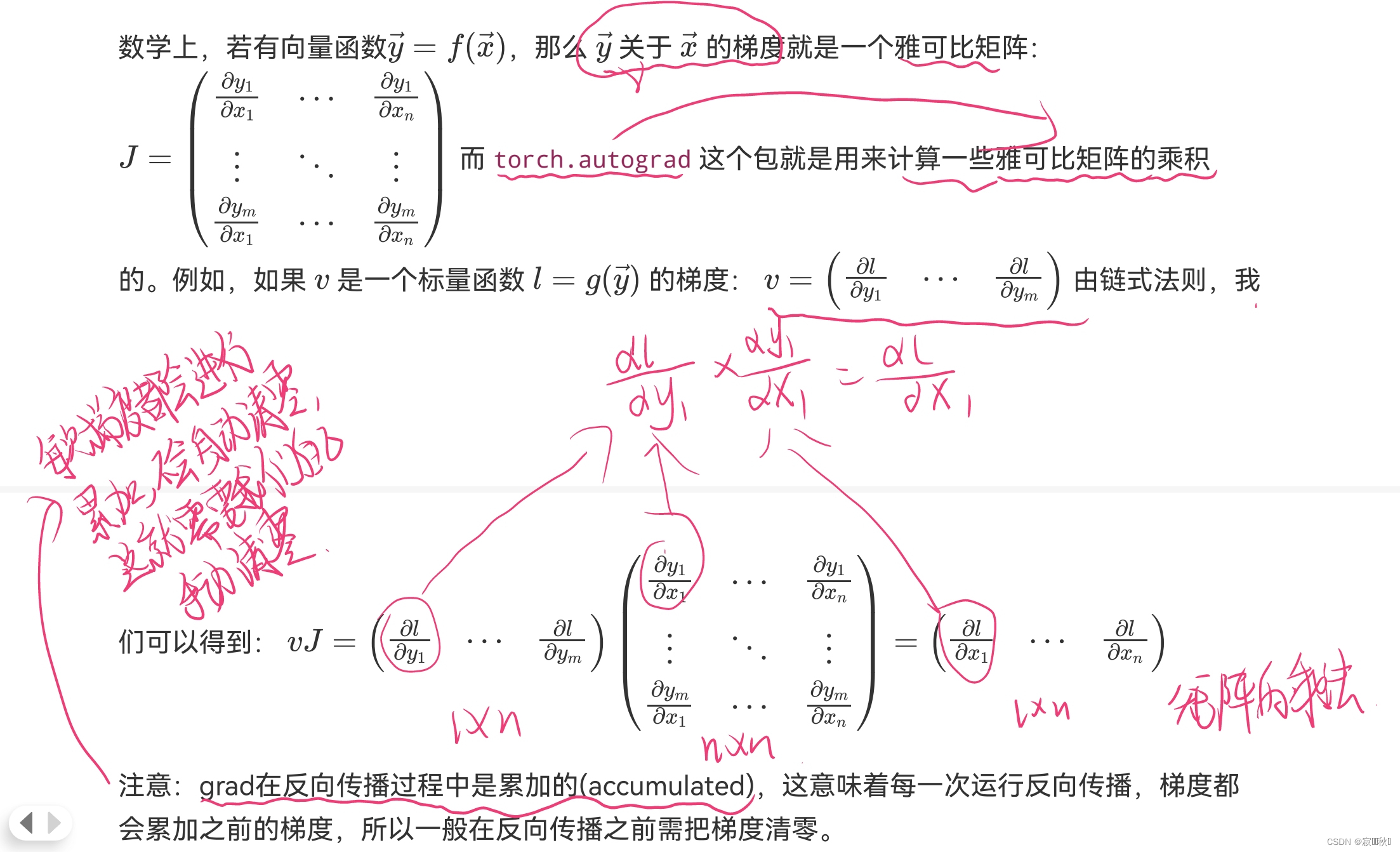
2.2.2 梯度的返向传播
torch.autograd计算一些雅可比矩阵的乘积
2.3 并行计算
2.3.1 为什么进行并行计算
随着数据量的越来越大,计算量也随之越来越大,而为了加快计算的速度,可以使用多个GPU进行并行计算,减少运行的时间。
2.3.2 使用CUDA
CUDA支持GPU计算,设置方法如下:
#设置在文件最开始部分
import os
os.environ["CUDA_VISIBLE_DEVICE"] = "2" # 设置默认的显卡
# 选择GPU的块数以及从多块中指定其中n块GPU计算
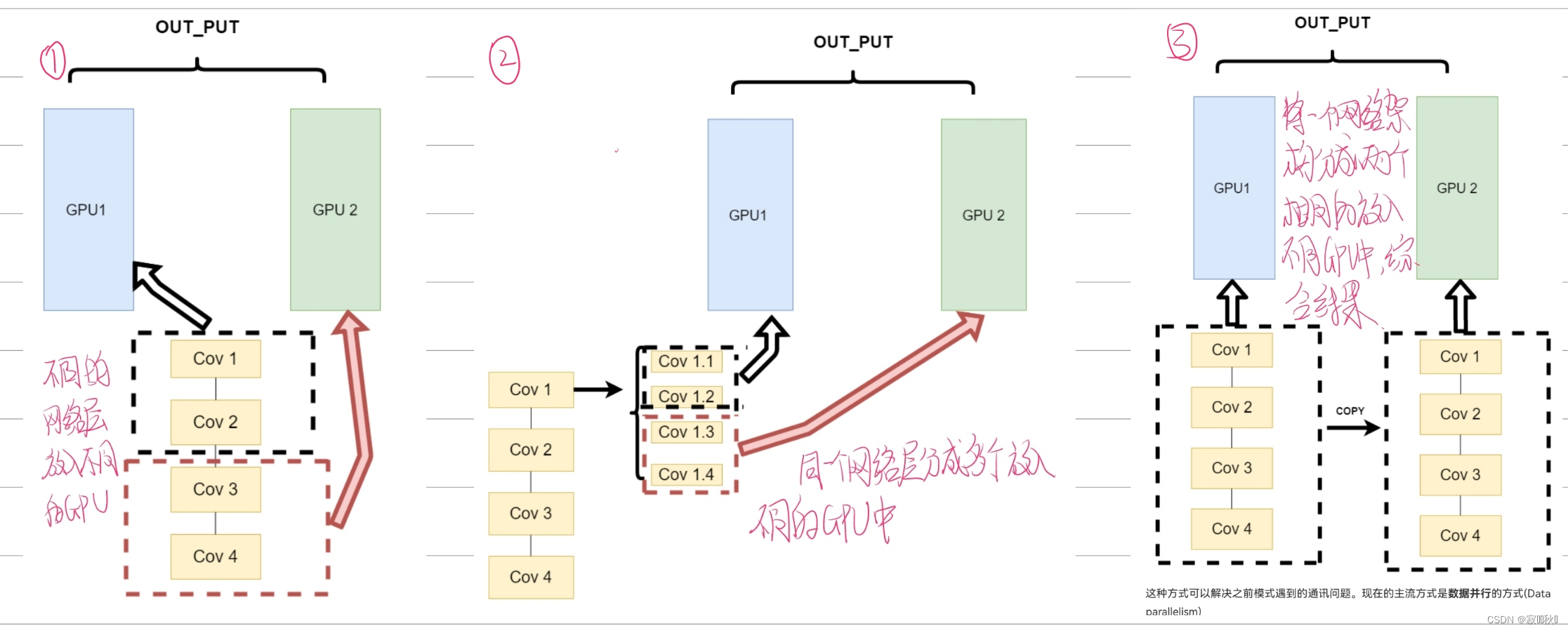
CUDA_VISBLE_DEVICE=0,1 python train.py # 使用0,1两块GPU2.3.3 不同的GPU并行运行方式
深入浅出PyTorch:https://github.com/datawhalechina/thorough-pytorch






![[附源码]java毕业设计基于Java烟支信息管理系统](https://img-blog.csdnimg.cn/8c12f2f3342e4556855613ea01cec0e0.png)