1.常见的ORM框架都有哪些呢?
什么是ORM框架?
所谓的ORM框架,就是对象关系映射框架,就是让我们程序中的类里面的属性直接映射到我的数据库中的表里面的列,我们在Java中操作这个类的时候,就相当于直接操作数据库中的表和字段,运用OOP思想;
1)Mybatis是⼀种典型的半⾃动的 ORM 框架,所谓的半自动,是因为还需要⼿动的写 SQL 语句,再由框架根据SQL以及传入数据来进行组装执行的SQL,下面是他的优点:
1. 因为由程序员自己写 SQL,相对来说学习⻔槛更低,更容易⼊⻔,在高级也就写个联表查询,所以说很灵活
2. 更⽅便做 SQL的性能优化及维护。
3. 对关系型数据库的模型要求不⾼,这样在做数据库模型调整的时候,影响不会太大,适合于软件需求变更比较频繁的系统
4)他的缺陷就是:不能跨数据库,因为写的SQL可能存在数据库特有的语法或者关键词,做数据库转换不方便,
mybatis的数据库移植性较差,这个是它的一个非常大的缺点了。
具体的来说,例:
mysql移植到Orecle,SQL语句会有差异从而引起error
3)Hibernate是⼀种典型的全⾃动 ORM 框架,所谓的全⾃动,是 SQL 语句都不⽤在编写,基于框 架的 API,可以将对象⾃动的组装为要执⾏的 SQL 语句,比如说,底层会提供一个Insert方法,我们只需要将对象的属性设置进去,将这个对象放到方法的参数里面,就可以进行使用了,其优点为:
1. 全⾃动 ORM 框架,⾃动的组装为 SQL 语句。
2. 可以跨数据库,框架提供了多套主流数据库的 SQL ⽣成规则。
其缺点为:
1)学习⻔槛更⾼,要学习框架 API 与 SQL 之间的转换关系,况且如果实现一个简单的增删改查是非常简单的,但是说如果写一些复杂的SQL调用API就会很麻烦,Hibernate提供了一些自己复杂的语法进行连表查询,HQL语法是一个中间语法
2)对数据库模型依赖⾮常⼤,在软件需求变更频繁的系统中,会导致⾮常难以调整及维护。可 能数据库中随便改⼀个表或字段的定义,Java代码中要修改⼏⼗处。
4)很难定位问题,也很难进⾏性能优化:需要精通框架,对数据库模型设计也⾮常熟悉。
2.谈谈你对Bean容器和IOC容器的理解:
Spring容器主要是对IoC设计模式的实现,主要是使⽤容器来统⼀管理Bean对象,及管理对象之间的依赖关系,但是IOC只是Bean容器实现的一种模式,有可能也有其他的实现模式
创建容器的API主要是BeanFactory和ApplicationContext两种:
1)BeanFactory是最底层的容器接⼝,只提供了最基础的容器功能:Bean 的实例化和依赖注⼊,并且使⽤懒加载的⽅式,这意味着 beans 只有在我们通过 getBean() ⽅法直接调⽤它们时才进⾏实例化。
2.)ApplicationContext(应⽤上下⽂)是BeanFactory的⼦接⼝,与 BeanFactory 懒加载的⽅式不同,它是预加载,所以,每⼀个 bean 都在 ApplicationContext 启动之后实例化。
3) 除了基础功能,还添加了很多增强:3.1)整合了Bean的⽣命周期管理
3.2)国际化功能(MessageSource)
3.3)载⼊多个(有继承关系)上下⽂ ,使得每⼀个上下⽂都专注于⼀个特定的层次,⽐如应⽤的web层
3.4)事件发布响应机制
3.5)AOP
对IOC和DI的理解:
IOC:是Inversion of Control,是面向对象编程中的一种常见的设计原则,主要是通过IOC容器,对Bean对象来进行统一的一个管理,以及组织对象的之间的依赖关系,获取依赖对象的过程,原本是由程序自己进行控制的,现在变成了IOC容器进行自动注入,控制权发生了反转,所以叫IOC控制反转
DI:就是在IOC容器在运行期间,动态地将某种依赖关系注入到对象里面
DI的实现方式只有两种,构造方法注入和属性注入
实现原理:主要是依赖于反射或者是ASM字节码框架实现(字节码框架操作字节码更为高效,功能是更强大的)
3.Spring单例Bean的线程安全问题:
我们在默认情况下,Bean是单例模式,所有人都是在用这一个对象,如果有人针对这个对象进行属性的修改的时候,那么就会存在数据覆盖的问题,所以不是线程安全的
1)在Bean对象中尽量避免可变的成员变量,设置成final,不能被修改
2)在类中定义一个ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal里面,每一个线程设置的是自己的变量,用于处理线程安全的单例Bean
4.BeanFactory和FactoryBean又什么区别呢?
1)BeanFactory就类似于线程池,FactoryBean就类似于线程工厂,咱们的BeanFactory是Spring容器的顶级接口,所有的Bean对象都是通过BeanFactory也就是Bean容器来进行管理
2)FactoryBean是一个实例化一个Bean对象的工厂类,实现了Factory<T>接口的Bean,根据该Bean的ID从BeanFactory中获取的是其实FactoryBean方法返回的对象,而不是FactoryBean本身
5.对Spring三级缓存的理解:换种说法就是Spring是如何进行解决循环依赖问题的,本质上就是三个HashMap
我们先来说一说什么是循环依赖?
简单来说就是A对象依赖于B对象,B对象又依赖于A对象,咱们的类似的代码如下: @Component public class A{ @Autowired private B b; } @Component public class B{ @Autowired private A a; }那么默认单例的属性注⼊场景,Spring是如何⽀持循环依赖的?
Spring是使⽤三级缓存的机制来解决循环依赖问题,以下为三级缓存的定义:
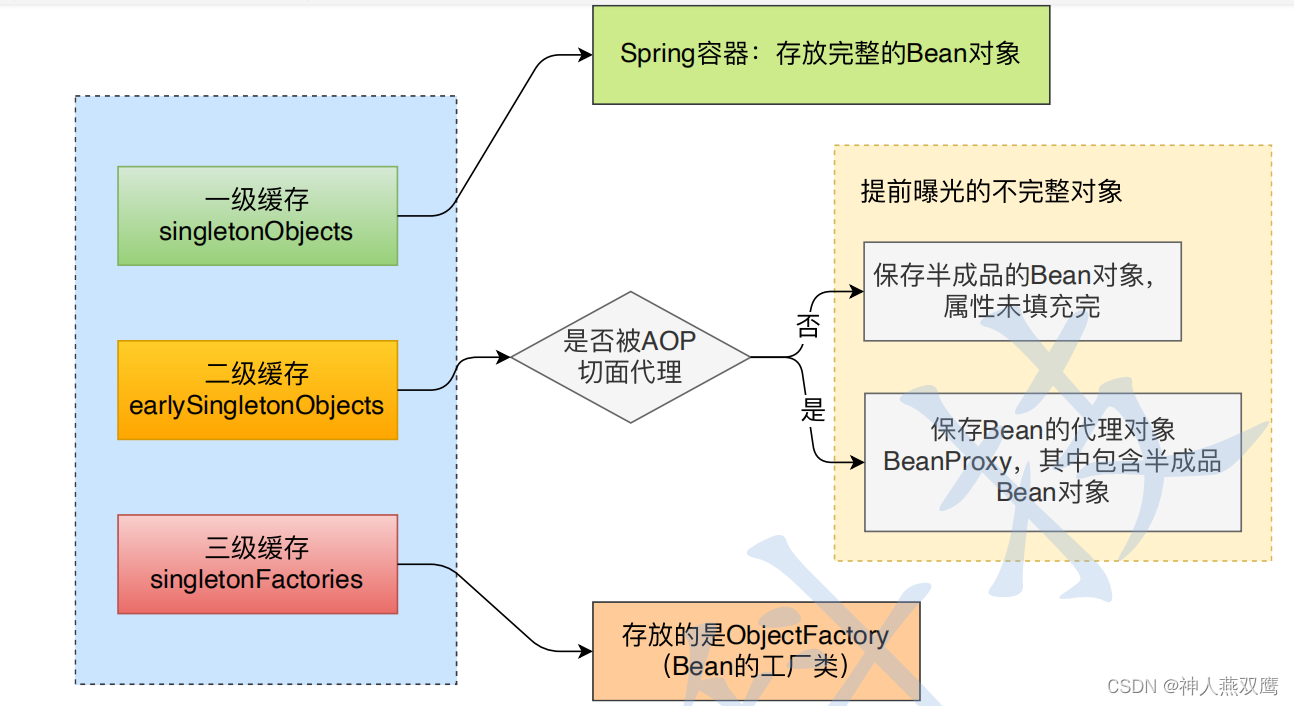
一级缓存:Spring容器,存放完整的Bean对象,如果A对象被完整地初始化了,就会放到一级缓存里面,让其他人可以直接去用
二级缓存:里面主要保存的是一个半成品,就是提前曝光不完整对象,一个是保存初始化一半的Bean,比如说A里面是依赖B的,B又去依赖A了,就会先把A的一半对象保存在二级缓存里面里面,只有一个引用,只有一个地址;
三级缓存:存放的是ObjectFactory(Bean的工厂类),咱们再Spring里面,获取到每一个类,都会对应到一个ObjectFactory,只有ObjectFactory,我们才可以获取到Bean,所有Bean的创建,都是要依赖Bean的工厂进行创建的(就像线程池创建线程),一开始实例化的时候,是放在三级缓存里面的,实例化一半的过程中是把对象放到二级缓存里面了
三级缓存singletonFactories中保存的是ObjectFactory对象(Bean⼯⼚),其中包含了
BeanName,Bean对象,RootBeanDefinition,该⼯⼚可以⽣成Bean对象。
解决的过程:
1)A在进行加载的时候,首先我们会生成一个A的一个ObjectFactory(创建Bean的一个工厂类),存到三级缓存里面,然后我们执行对A的初始化,我们发现A里面引用了B对象了
2)此时我们进行初始化B操作,我们首先在三级缓存里面创建一个B的ObjectFactory,我们发现初始化B的时候,发现属性要用到A,又要用到A了,我们就会通过A的三级缓存,生成一个A一半的Bean,因为我执行一半,里面的初始化还没有执行完呢,这是就是一个A的半成品,我们把半成品存到二级缓存里面
3)然后我们的Bcontroller继续执行,此时B就已经拿到了半成品的A了,直接把A的内存地址放到B的属性里面,B就会针对本身进行初始化后面的代码了,最后,我们生成了一个完整的B的Bean对象,然后B直接放到一级缓存里面了,然后我们再把B的二级缓存和三级缓存中的半成品和ObjectFactory进行删除
4)然后我们的A继续初始化(A在这时就可以拿到完整的B了),把A初始化好的Bean放到Spring容器里面,删除A二级缓存和三级缓存的ObjectFactory和一半的Bean
因此,Spring一开始提前暴露的并不是实例化的 Bean,而是将 Bean 包装起来的ObjectFactory,为什么要这么做呢?
1)这实际上涉及到 AOP。如果创建的 Bean 是有代理的,那么注入的就应该是代理 Bean,而不是原始的 Bean。但是,Spring一开始并不知道 Bean是否会有循环依赖,通常情况下(没有循环依赖的情况下),Spring 都会在“完成填充属性并且执行完初始化方法”之后再为其创建代理。但是,如果出现了循环依赖,Spring 就不得不为其提前创建"代理对象";否则,注入的就是一个原始对象,而不是代理对象。因此,这里就涉及到"应该在哪里提前创建代理对象"
2)Spring 的做法就是:在 ObjectFactory 中去提前创建代理对象
总结:加入缓存中是从下向上加的,查找缓存是从上向下进行查找的
对AOP的理解:
AOP:是面向切面编程,对针对业务代码横切来实现统一的业务管理,而不用侵入业务代码本身,这样面向切面编程的思想就是AOP
使用场景:日志管理,事务管理,性能统计,安全控制,异常处理
优点:实现了代码的解耦,统一业务功能对具体业务没有什么侵入性,这样可扩展性更好,灵活性更高
Spring是采取动态代理的方式,具体是基于JDK和CGLIB两种:
JDK动态代理需要被代理类实现接口
CGLIB需要被代理类能够被继承,不能被final修饰,底层是基于ASM字节码框架,在运行的时候动态生成代理类
SpringAOP如何进行使用:使用@Aspect来进行定义切面,并注册到容器里面,使用@Pointcut定义好切点方法之后,可以对目标方法来进行拦截,然后执行我们的前置通知,后置通知之类的东西
SpringMVC的执行流程:
1)DispatcherServlet:前端控制器它是用来接收请求,响应结果,相当于转发器,中央处理器。有了DispatcherServlet减少了其它组件之间的耦合度,是由调度器来进行数据的分发和返回操作的----不需要程序员来进行开发
2)HanderMapping:处理器映射器,经过处理器映射器之后:(根据URL来进行查找,最终的目的就是匹配Controller的,最终找到执行类)-----不需要程序员来进行开发
3)HanderAdapter:叫做处理器适配器,按照特定规则去执行Handler----不需要程序员来进行开发
4)处理器Handler:编写Handler的时候需要按照HandlerAdapter的要求去做,这样适配器才可以真正的执行Handler
1)用户发起请求到我们的前端控制器:DispatcherServlet
2)前端控制器请求HandlerMapping查找 Handler(可以根据xml配置、注解进⾏查
找)--------作⽤根据请求的url查找Handler(方法,就是一个Controller);
3)他的这个处理器映射器也就是HanderMapping执行之后,会返回一个执行链给DispatcherServlet(因为我们在这个时候可能会有拦截器,执行一些逻辑,比如说登录功能的校验等等,如果有拦截器,会执行拦截器,没有就会继续向下执行)
4)HanderMapping会把请求映射成HanderExecutionChain对象,这个对象里面就包含了一个Hander处理器对象,还有多个HanderInterceptor对象)
5)然后再根据这个DispatcherServlet调用处理器适配器去执行Hander
6)此时如果加上了@RestController或者是@ResponseBody表示此时返回给前端的是一个完整的数据而不是页面
7)如果此时没有加这两个注解,那么Handler会向处理器适配器(HanderAdapter)返回一个ModelAndView
8)然后处理器适配器会向DisDispatcherServlet返回一个ModelAndView
9)前端控制器请求视图解析器来进行视图解析,视图解析器把结果返回给前端控制器,前端控制器返回结果
4)适配器是去确定最终执行的Controller的,执行完适配器中的Controller,会返回一个ModelAndView,先返回给我们的DispatcherServlet,然后在传递请求给我们的视图解析器进行视图解析,
其实根据RequestBody一些注解来进行确定来决定我们返回的是是view还是非view的一些其他信息,如果是视图,视图解析器时进行处理服务器的一些标签的(当服务器有模板引擎,解析,把咱们的标签来解析成一些值),如果说咱们的返回数据是一个Json对象的话,就不会有视图解析器这一步操作了,解析完成之后,会返回view给DispatherServlet,然后再由DispatcherServlet发送请求给view进行视图渲染,将模型数据Model填充到request域,再把视图渲染返回给DispatcherServlet,再把结果返回给前端
SpringBoot自动装配原理/SpringBoot自动化配置的理解
SpringBoot再进行自动配置的时候,尤其是我再进行Bean加载的时候,启动的时候,我是根据@SpringBootApplication注解来进行启动的,他是一个组合注解
约定大于配置
启动类的@SpringBootApplication注解由@SpringBootConfiguration,
@EnableAutoConfiguration,@ComponentScan三个注解组成,三个注解共同完成自动装配;
1)@SpringBootConfiguration 注解标记启动类为配置类
2)@ComponentScan 注解实现启动时扫描启动类所在的包以及子包下所有标记为bean的类由IOC容器注册为bean
3)@EnableAutoConfiguration通过 @Import 注解导入 AutoConfigurationImportSelector类,然后通过AutoConfigurationImportSelector 类的 selectImports 方法去读取需要被自动装配的组件依赖下的spring.factories文件配置的组件的类全名,并按照一定的规则过滤掉不符合要求的组件的类全名,将剩余读取到的各个组件的类全名集合返回给IOC容器并将这些组件注册为bean,其中这里面的@import注解,他会把所有满足条件的Bean全部加载到SpringBoot里面,什么是满足条件的Bean呢?
在SpringBoot里面有一个jar包,叫做:Maven:org.springframework.boot:spring-boot:2.5.11里面有一个MEAT-INF目录,里面有一个文件叫做spring.factories,里面就记录了所有可以加载和支配启动加载的Bean,里面有PropertySourceLoader,配置信息
在我们的MyBatis中,我们为什么可以将Mapper接口直接进行注入使用?
我们为什么只在UserService里面写了一个@Resource就可以把标记了@Mapper的接口直接注入使用?
表面上是一个接口,但实际上咱们的程序时不会进行new这个接口的,而是我们使用代理的方式来进行实现的(调用动态代理子类)
1)JVM从JDK1.6是有锁升级的一个过程的,偏向锁--->轻量级锁---->重量级锁,在对象头里面有一个标识,用来表示当前有没有锁,是属于哪一个线程里面的,会进行判断线程ID和我们对象头中的线程ID是不是一致的,如果是一致的,那么代表我是可以重入的,重新获取到这把锁;
2)如果ID不同,就会尝试获取锁,使用自旋锁





![[附源码]java毕业设计基于Java烟支信息管理系统](https://img-blog.csdnimg.cn/8c12f2f3342e4556855613ea01cec0e0.png)