目录
第一类:改变链接关系
第二类:快慢指针
第一类:改变链接关系
1. 删除链表中等于给定值 val 的所有结点。
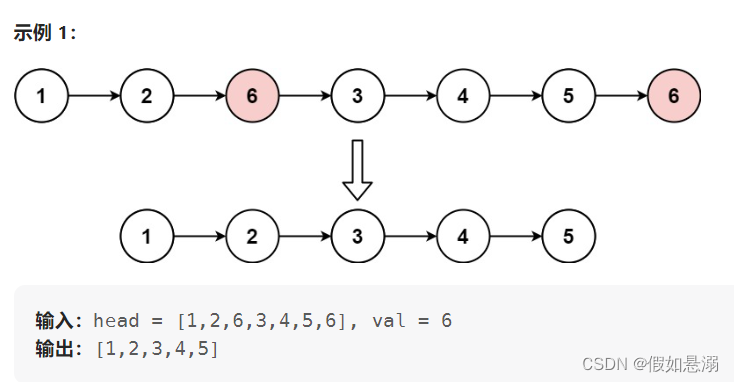
(1)原地删除
struct ListNode* removeElements(struct ListNode* head, int val){
if(head==NULL)
{
return head;
}
struct ListNode* cur=head,* pre=NULL,* ret;
while(cur)
{
//需要删除cur
if(cur->val==val)
{
//cur是首节点,需要改变头结点
if(pre==NULL)
{
ret=cur;
head=cur->next;
cur=cur->next;
}
//直接删除即可
else
{
ret=cur;
pre->next=cur->next;
cur=cur->next;
}
free(ret);
}
//不用删除,
else
{
pre=cur;
cur=cur->next;
}
}
return head;
}(2)建立一个新链表,将不用删除的节点依次尾插
if(head==NULL)
{
return head;
}
struct ListNode* cur=head,* pre=NULL,*newhead=NULL,*newtail=NULL;
while(cur)
{
//需要尾插cur
if(cur->val!=val)
{
//cur是首节点,需要改变newhead
if(!newhead)
{
newhead=newtail=cur;
}
//直接尾插即可
else
{
newtail->next=cur;
newtail=newtail->next;
}
}
pre=cur;
cur=cur->next;
}
if(newtail)
newtail->next=NULL;
return newhead;(3)在2的基础上使用带头节点链表
struct ListNode* removeElements(struct ListNode* head, int val){
if(head==NULL)
{
return head;
}
struct ListNode* cur=head,* pre=NULL;
struct ListNode* newhead=(struct ListNode* )malloc(sizeof(struct ListNode)),*newtail=newhead;
while(cur)
{
//需要尾插cur
if(cur->val!=val)
{
newtail->next=cur;
newtail=newtail->next;
}
pre=cur;
cur=cur->next;
}
newtail->next=NULL;
return newhead->next;
}(4)递归
struct ListNode* removeElements(struct ListNode* head, int val){
if(head==NULL)
{
return head;
}
if(head->val==val)
{
return removeElements(head->next, val);
}
else
{
head->next=removeElements(head->next, val);
return head;
}
}
2. 反转一个单链表。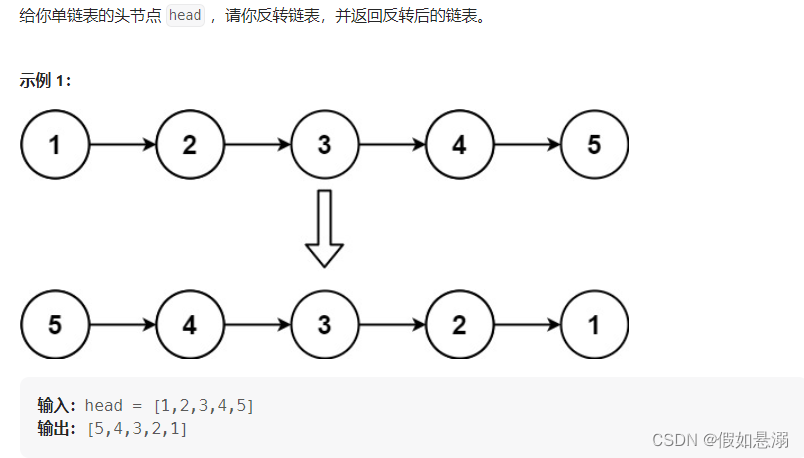
(1)原地逆转
struct ListNode* reverseList(struct ListNode* head){
struct ListNode* ret=NULL,*cur=head,*pre=NULL;
while(cur)
{
ret=cur->next;
cur->next=pre;
pre=cur;
cur=ret;
}
return pre;
}(2)建立一个新链表,将节点依次头插(带头结点链表)
struct ListNode* reverseList(struct ListNode* head){
struct ListNode* newhead=(struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode*cur=head,*ret;
newhead->next=NULL;
while(cur)
{
ret=cur->next;
cur->next=newhead->next;
newhead->next=cur;
cur=ret;
}
return newhead->next;
}(3)递归
struct ListNode* reverseList(struct ListNode* head){
if(head==NULL||head->next==NULL)
{
return head;
}
else
{
struct ListNode* newhead=reverseList(head->next);
head->next->next=head;
head->next=NULL;
return newhead;
}
}
第二类:快慢指针
3. 给定一个带有头结点 head 的非空单链表,返回链表的中间结点。如果有两个中间结点,则 返回第二个中间结点。
(1)快慢指针
struct ListNode* middleNode(struct ListNode* head){
struct ListNode* slow = head;
struct ListNode* fast = head;
while (fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
}
return slow;
}(2).求出size再遍历
struct ListNode* middleNode(struct ListNode* head){
struct ListNode* cur = head;
int size=0;
while (cur) {
size++;
cur=cur->next;
}
cur = head;
size/=2;
while(size--)
{
cur=cur->next;
}
return cur;
}(3)先遍历一遍将数据存入数组再处理
struct ListNode* middleNode(struct ListNode* head){
struct ListNode* cur = head;
struct ListNode* a[180];
int i=0;
while (cur) {
a[i++]=cur;
cur=cur->next;
}
return a[i/2];
}
4. 输入一个链表,输出该链表中倒数第k个结点。

(1)快慢指针
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {
if(pListHead==NULL||k==0)
return NULL;
struct ListNode* fast,*slow;
fast=slow=pListHead;
while(k&&fast)
{
fast=fast->next;
k--;
}
if(k)
{
return NULL;
}
while(fast)
{
fast=fast->next;
slow=slow->next;
}
return slow;
}
(2).求出size再遍历size-k次
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {
struct ListNode* cur = pListHead;
int size=0;
while (cur) {
size++;
cur=cur->next;
}
cur = pListHead;
if(k>size)
return NULL;
size-=k;
while(size--)
{
cur=cur->next;
}
return cur;
}5. 将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有 结点组成的。
 (1)直接迭代改变链接关系(使用带头链表)
(1)直接迭代改变链接关系(使用带头链表)
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){
struct ListNode* newhead=(struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* tail;
if(newhead!=NULL)
{
tail=newhead;
}
struct ListNode* p1=list1,*p2=list2;
tail->next=NULL;
while(p1&&p2)
{
if(p1->val<p2->val)
{
tail->next=p1;
tail=tail->next;
p1=p1->next;
}
else
{
tail->next=p2;
tail=tail->next;
p2=p2->next;
}
}
if(p1)
{
tail->next=p1;
}
if(p2)
{
tail->next=p2;
}
return newhead->next;
}(2)递归
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){
if(list1==NULL)
{
return list2;
}
if(list2==NULL)
{
return list1;
}
if(list1->val<list2->val)
{
list1->next=mergeTwoLists(list1->next,list2);
return list1;
}
else
{
list2->next=mergeTwoLists(list2->next,list1);
return list2;
}
return NULL;
}
6. 编写代码,以给定值x为基准将链表分割成两部分,所有小于x的结点排在大于或等于x的结 点之前 。

创建两个链表,分别链接小于x的节点和大于x的节点:
ListNode* partition(ListNode* pHead, int x) {
ListNode* newhead1=(ListNode*)malloc(sizeof(ListNode));
ListNode* newhead2=(ListNode*)malloc(sizeof(ListNode));
newhead1->next=NULL;
newhead2->next=NULL;
ListNode* tail1=newhead1;
ListNode* tail2=newhead2;
ListNode* cur=pHead;
while(cur)
{
if(cur->val < x)
{
tail1->next=cur;
tail1=tail1->next;
}
else
{
tail2->next=cur;
tail2=tail2->next;
}
cur=cur->next;
}
tail1->next=newhead2->next;
tail2->next=NULL;
return newhead1->next;
}7. 链表的回文结构。

快慢指针加逆序链表
struct ListNode* reverseList(struct ListNode* head){
struct ListNode* ret=NULL,*cur=head,*pre=NULL;
while(cur)
{
ret=cur->next;
cur->next=pre;
pre=cur;
cur=ret;
}
return pre;
}
bool chkPalindrome(ListNode* A) {
ListNode* slow=A,*fast=A;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
}
slow=reverseList(slow);
while(slow&&A!=slow)
{
if(slow->val!=A->val)
{
return false;
}
slow=slow->next;
A=A->next;
}
return true;
}
8. 输入两个链表,找出它们的第一个公共结点。

(1)先遍历两个链表,得出长度差,使得长链表先走长度差的步数,然后一起比较。
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
int difsize=0;
struct ListNode *p1=headA,*p2=headB;
struct ListNode*longL=headA,*shortL=headB;
while(p1||p2)
{
if(p1)
{
difsize++;
p1=p1->next;
}
if(p2)
{
difsize--;
p2=p2->next;
}
}
if(difsize<0)
{
longL=headB,shortL=headA;
}
difsize=abs(difsize);
while(difsize--)
{
longL=longL->next;
}
while(longL)
{
if(longL==shortL)
return longL;
else
{
longL=longL->next;
shortL=shortL->next;
}
}
return NULL;
}(2)不记录长度一直遍历达到两个指针指向长度一样的目的。
创建两个指针 初始时分别指向两个链表的头节点 ,然后将两个指针依次遍历两个链表的每个节点。
如果指针 pA不为空,则将指针 pA 移到下一个节点;pB同理。
如果指针 pA为空,则将指针 pA 移到链表 headB的头节点;pB同理。
当指针 pA,pB 指向同一个节点退出。

if(headA==NULL||headB==NULL)
{
return NULL;
}
struct ListNode * pA = headA, *pB = headB;
while (pA != pB) {
if(!pA)
pA =headB;
if(!pB)
pB =headA;
if(pA == pB)
break;
pA=pA->next,pB=pB->next;
}
return pA;
}
(3)哈希表查找
struct HashTable {
struct ListNode *key;
UT_hash_handle hh;
};
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
struct HashTable *hashTable = NULL;
struct ListNode *temp = headA;
while (temp != NULL) {
struct HashTable *tmp;
HASH_FIND(hh, hashTable, &temp, sizeof(struct HashTable *), tmp);
if (tmp == NULL) {
tmp = malloc(sizeof(struct HashTable));
tmp->key = temp;
HASH_ADD(hh, hashTable, key, sizeof(struct HashTable *), tmp);
}
temp = temp->next;
}
temp = headB;
while (temp != NULL) {
struct HashTable *tmp;
HASH_FIND(hh, hashTable, &temp, sizeof(struct HashTable *), tmp);
if (tmp != NULL) {
return temp;
}
temp = temp->next;
}
return NULL;
}
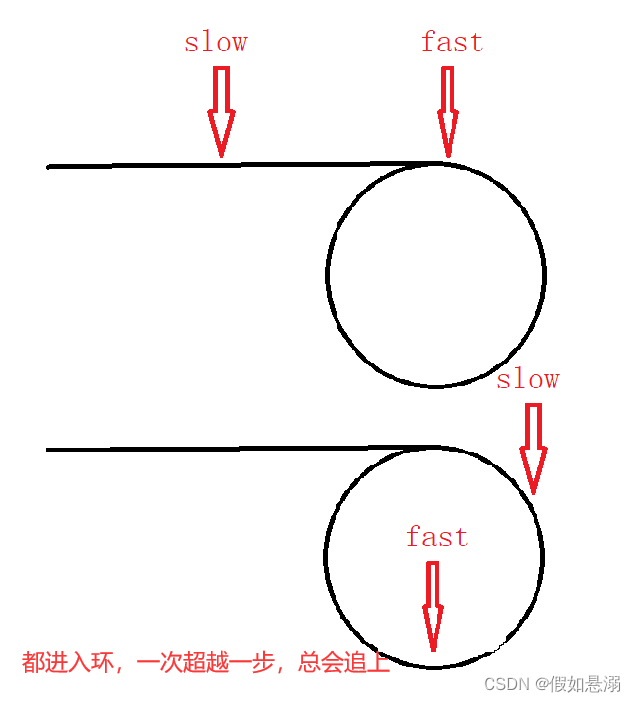
9. 给定一个链表,判断链表中是否有环。

(1)快慢指针
bool hasCycle(struct ListNode *head) {
if(head==NULL)
return false;
struct ListNode *fast=head,*slow=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
if(fast==slow)
return true;
}
return false;
}
(2)哈希表
struct hashTable {
struct ListNode* key;
UT_hash_handle hh;
};
struct hashTable* hashtable;
struct hashTable* find(struct ListNode* ikey) {
struct hashTable* tmp;
HASH_FIND_PTR(hashtable, &ikey, tmp);
return tmp;
}
void insert(struct ListNode* ikey) {
struct hashTable* tmp = malloc(sizeof(struct hashTable));
tmp->key = ikey;
HASH_ADD_PTR(hashtable, key, tmp);
}
bool hasCycle(struct ListNode* head) {
hashtable = NULL;
while (head != NULL) {
if (find(head) != NULL) {
return true;
}
insert(head);
head = head->next;
}
return false;
}10. 给定一个链表,返回链表开始入环的第一个结点。 如果链表无环,则返回 NULL

利用前一题的快慢指针。一指针从相遇点开始走,一指针从头开始,两者一定会在入环点相遇。
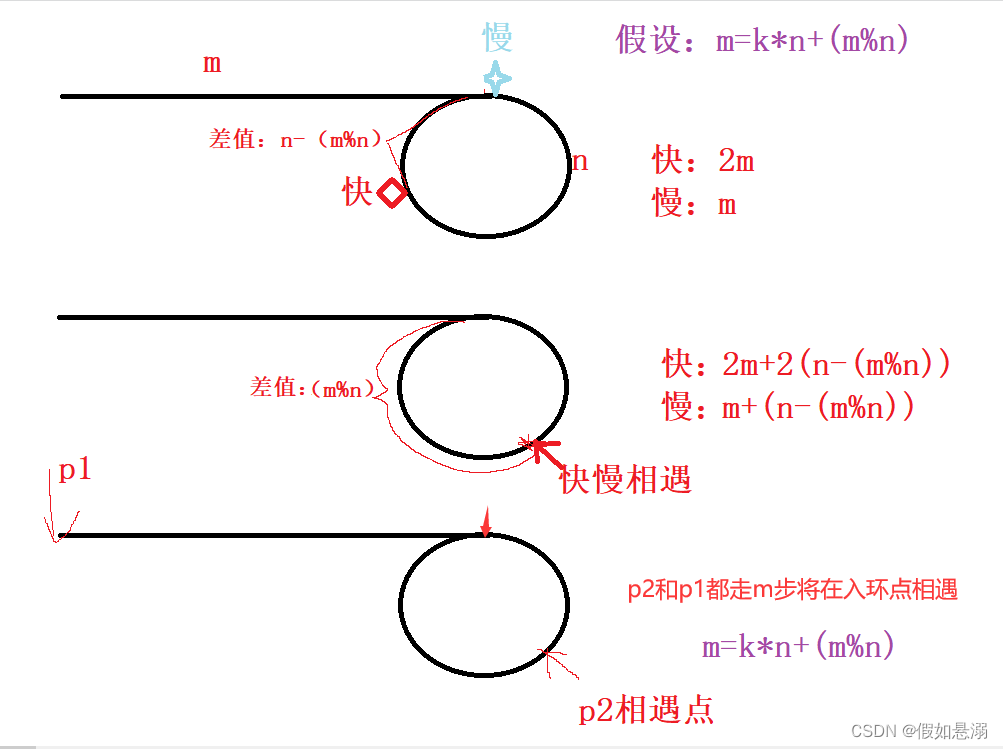
struct ListNode *detectCycle(struct ListNode *head) {
if(head==NULL)
return NULL;
struct ListNode *fast=head,*slow=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
if(fast==slow)
{
slow=head;
while(slow!=fast)
{
fast=fast->next,slow=slow->next;
}
return fast;
}
}
return NULL;
}11. 给定一个链表,每个结点包含一个额外增加的随机指针,该指针可以指向链表中的任何结点 或空结点。 要求返回这个链表的深度拷贝。

方法一:遍历两遍,第一遍创建新节点将next链接好,同时记录源节点与新节点对应关系,第二遍完成random的链接。
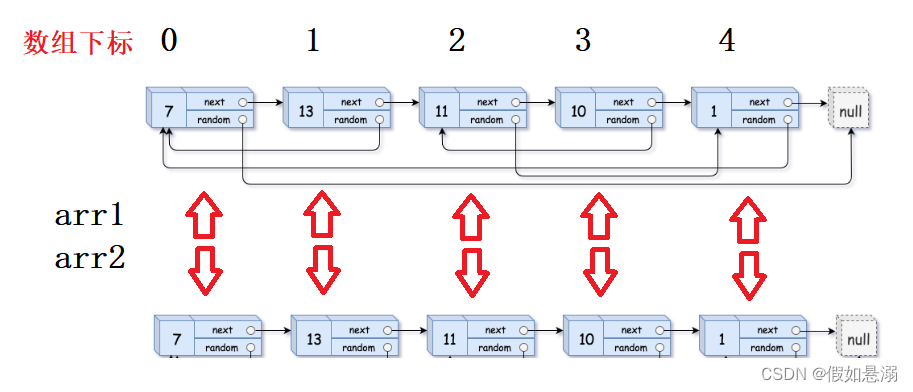
struct Node* copyRandomList(struct Node* head)
{
if(head==NULL)
return NULL;
struct Node* arr1[1001];
struct Node* arr2[1001];
struct Node*cur=head;
struct Node* newguard=(struct Node*)malloc(sizeof(struct Node));
struct Node*ptail=newguard;
assert(newguard);
int index=0;
while(cur)
{
struct Node* ret=(struct Node*)malloc(sizeof(struct Node));
ret->val=cur->val;
ptail->next=ret;
ptail=ret;
arr1[index]=cur;
arr2[index]=ret;
cur=cur->next;
index++;
}
cur=head;
struct Node*newcur=newguard->next;
while(cur)
{
struct Node* obj=cur->random;
if(obj!=NULL)
{
for(int i=0;i<index;i++)
{
if(obj==arr1[i])
{
newcur->random=arr2[i];
break;
}
}
}
else
{
newcur->random=NULL;
}
cur=cur->next,newcur=newcur->next;
}
ptail->next=NULL;
return newguard->next;
}方法二:新节点先链接进入原链表然后将新节点的random链接好,此时原来节点random指向的源节点后面就可以直接找到新节点应该指向的位置。
分为三步:
//创建新节点
//改变random指向
//将新节点剥离

struct Node* copyRandomList(struct Node* head)
{
if(head==NULL)
return NULL;
struct Node*cur=head;
//创建新节点
while(cur)
{
struct Node* ret=(struct Node*)malloc(sizeof(struct Node));
ret->val=cur->val;
ret->next=cur->next;
cur->next=ret;
cur=ret->next;
}
cur=head;
//改变random指向
while(cur)
{
struct Node* obj=cur->next;
if(cur->random==NULL)
{
obj->random=NULL;
}
else
{
obj->random=cur->random->next;
}
cur=obj->next;
}
cur=head->next;
//将新节点剥离
while(cur->next)
{
cur->next=cur->next->next;
cur=cur->next;
}
return head->next;
}
(3)
(4)

![[附源码]java毕业设计基于SSM的酒店管理系统](https://img-blog.csdnimg.cn/ac99b0c0ef4647699f3e1e497c4a7d39.png)









![[附源码]java毕业设计基于的楼盘销售管理系统论文2022](https://img-blog.csdnimg.cn/0b6bd4677d5a40dc8aa9674e198c5845.png)