Whisper论文阅读笔记
- Robust Speech Recognition via Large-Scale Weak Supervision
- 1. 引言
- 2. 方法
- 2.1 数据处理
- 2.2 模型
- 2.3 多任务设置
- 2.4 训练细节
- 3. 实验结果
- 3.1 Zero-shot
- 3.2 多语言语音识别
- 3.3 多语言机器翻译
- 3.4 语种检测
- 3.5 对加性噪声的鲁棒性
- 3.6 长语音转录
- 3.7 人类基线
- 4. 分析与消融
- 4.1 模型大小
- 4.2 数据集大小(小时)
- 4.3 多任务和多语言迁移能力
Robust Speech Recognition via Large-Scale Weak Supervision
Blog
Paper
Model card
Colab example
这篇文档介绍OpenAI提出的新的语音识别系统:Whisper,它在英语语音识别方面实现了接近人类水平的鲁棒性和准确性。
1. 引言
背景
大规模基于纯语音预训练模型取得了很好的发展。(wav2vec2, et al.)
- 数据集已经达到了百万小时级,远超过千级的标注语音识别数据。
- 在下游任务的Finetune中可以实现SOTA (尤其是小规模的数据集上)
缺陷
- 这些无监督的预训练模型只能学习到一个非常高质量的音频表示。但是,
缺少一个相同质量的Decoder来映射这些音频表示以获取最终的输出。这意味着,这些预训练模型的使用是受限的,需要为下游任务的Finetune设置复杂的流程,而作者认为做这样的事情是需要比较高的专业知识的。 - 机器学习模型往往在它学习过的数据集上可以取得很好的性能。但是,
泛化能力不行。也就是说,在某一数据集上训练得到的模型,虽然它可能取得了超越人类的性能,但在其他数据集上的表现可能并不理想。
作者的见解
The goal of a speech recognition system should be to work reliably “out of the box” in a broad range of environments without requiring supervised fine-tuning of a decoder for every deployment distribution.
“语音识别系统的目标应该在通义环境下做到开箱即用,而不是需要针对于每个数据集,设置一个特定的解码器,来进行带监督的微调”
现有工作
拼接了多个有监督的数据集,实现跨多个数据集/领域的预训练。相较于以往依赖单一数据集的方式,模型的鲁棒性得到了很好的提升。
依然存在的挑战
缺乏高质量监督数据集:提供给语音识别系统的有监督数据集非常少,拼接起来也只有5000多个小时,很难达到无监督学习那样的百万小时级别。
事实
已有工作在探索使用带噪声的有监督语音识别数据集进行预训练。说明,权衡质量与数量是一个不错的探索的方向。
朝着这个方向发散,在计算机视觉中的一些研究也证明了,通过大规模的弱监督的数据集,可以显著提高模型的鲁棒性和泛化性。
Whisper
为解决上述问题,提出的Whisper
- 将有监督的语音识别数据集规模从千级提升到了
68万小时。- 在这种大规模的弱监督数据集上,模型无需微调就可以在任何数据集上实现有竞争力的结果。
- 将将弱监督预训练的范围扩大到
多语言和多任务。(Prompt learning)- 数据集中有11.7万小时的数据是涵盖了96种语言的。
- 数据中有12.5万小时是某种语言,但是监督数据是英语的。
- 证明了大模型对这种多语言,多任务的训练具有非常强的适应能力。
突出贡献
以往的工作都是往往需要收集特定的语音识别数据集进行有监督的学习,Whisper证明了,不需要做这些复杂的工作,通过足够大规模的弱监督学习,就可以实现一个非常有强的语音识别模型。
2. 方法
2.1 数据处理
- 数据处理中没有任何显著的标准化
- 也就是说Whisper是端到端的。(现有的ASR系统会对文本进行预处理,比如标点符号,首字母大小写,词形,词干等)
- 数据来源于互联网
- 多样化:不同环境、收音条件、语言、设备等
- 数据清洗
- 设置了不同方式来清洗ASR数据。
- 对混合人工和机器生成数据的数据集进行训练会严重影响翻译系统的性能
- 语言检测器,判断音频的发声的语种和是否在规定范围内(CLD2),对不在的进行剔除。
- 英语会特殊一点,只要文本是英语,语音发声是什么都可以。
- 设置了不同方式来清洗ASR数据。
- 以30S进行分割
- 包括有转录文本的数据和没有语音发声的片段(可以用于VAD)
- 更细粒度的清洗 (可借鉴)
- 训练了一个初始模型,将转录错误率高、对齐不良、不对齐等问题数据进行剔除
- 训练数据与验证、测试数据集的去重
2.2 模型
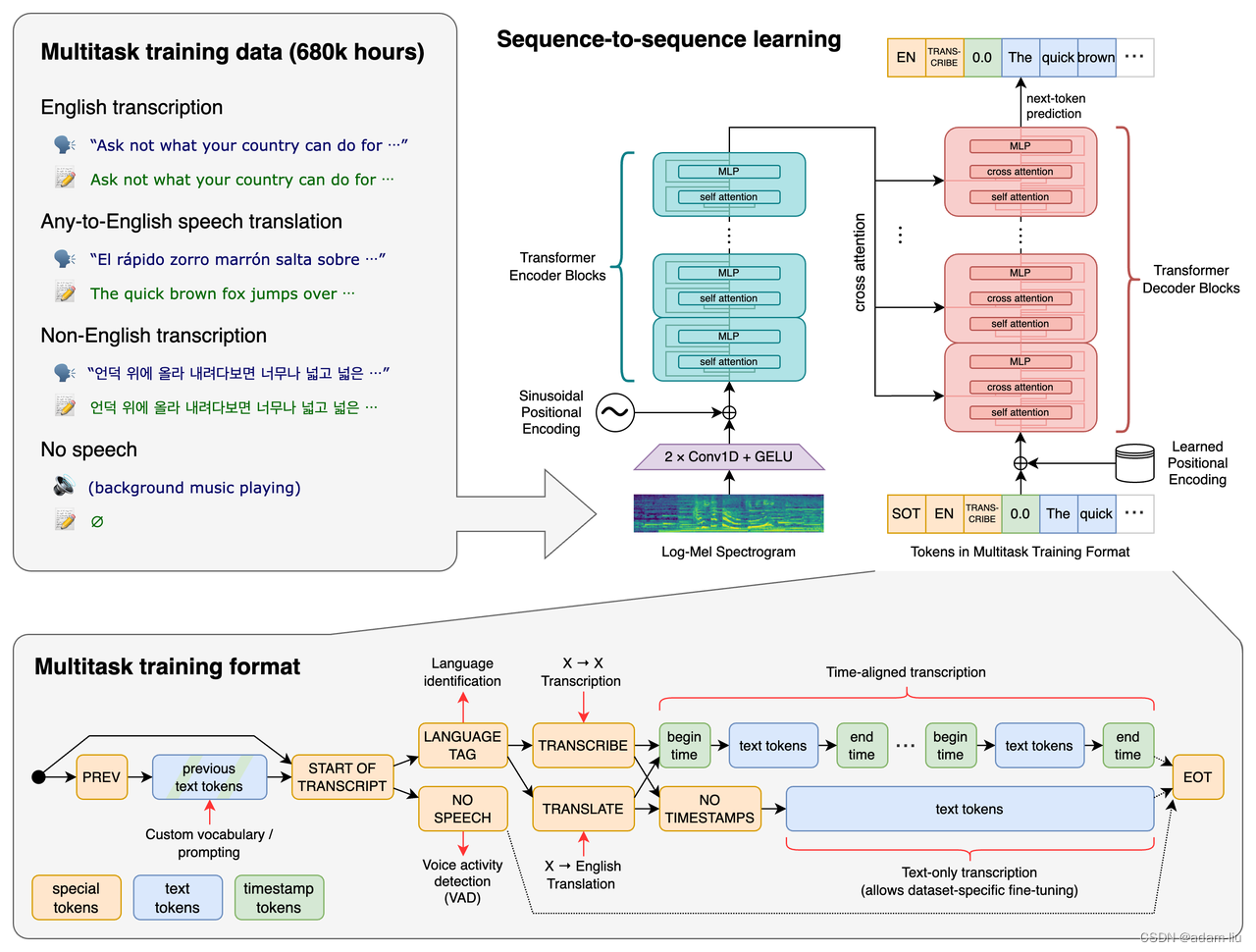
-
音频输入:Log-mel spectrogram (16,000Hz, 80-channel, 25ms windows, 10ms stride)
Input shape: (3000,80) 30S/10ms = 3,000, Zero mean [-1,1] -
文本输入:byte-level BPE Tokenizer (GPT-2, 由多语言数据训练得到的)
-
模型结构:
- 编码器:
- 2层1D的卷积,滤波器大小为3,GELU激活函数,第二层卷积步长为3。
- Output shape: (1500, 80)
- 标准Transformer encoder
- 2层1D的卷积,滤波器大小为3,GELU激活函数,第二层卷积步长为3。
- 解码器:
- 标准Transformer decoder
- 编码器:
2.3 多任务设置
Decoder input / Decoder output
conditional language model
prompt
prefix
4种训练任务6种组合方式:
- Spoken Language Identification: 99种
- voice activity detection (VAD): 有没有人声
- Multilingual Speech Recognition:发声与文本一致
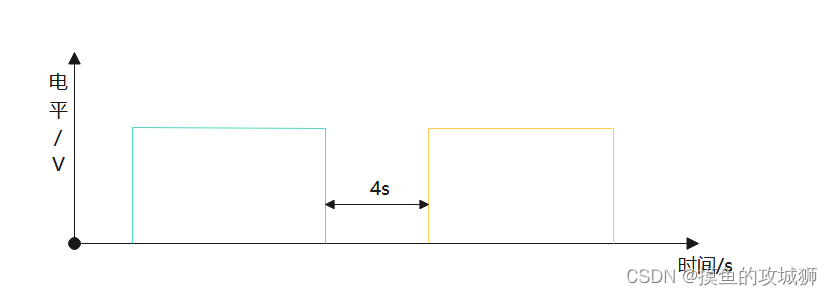
- 时间戳预测: 该语音片段开始发声的时候,结束发声的时间(相对值)
- 正常的Encoder-Decoder文本输入
- Speech Translation:发声与文本不一致,且文本为英语。
- 时间戳预测: 该语音片段开始发声的时候,结束发声的时间(相对值)
- 正常的Encoder-Decoder文本输入
2.4 训练细节
- FP16
- Dynamic loss scaling
- Activation checkpointing
- AdamW
- Gradient norm clipping
- linear learning rate decay (warmup 2048 steps)
- batch size 256
- Steps: 2**20=1,048,576 (
2-3epoch) - Do not use any data augmentation or regularization
3. 实验结果
3.1 Zero-shot
讨论
- 很多现有的模型,在特定数据集训练,并在与训练数据集分布一致的验证集上测试,虽然已经显示了超越人类的性能,但是在其他数据集上的表现却差强人意。
- 也就是说,之前的模型可能夸大的模型的能力,因为他们
不够泛化。
- 也就是说,之前的模型可能夸大的模型的能力,因为他们
- 作者认为简单的将机器学习模型和人类的评分进行衡量是不合理的。
- 因为机器是通过特定的语料学习得来的结果;而人往往没有在完全认识了解训练语料。
- 也就是说,人的表现是数据集外的泛化性的度量;而机器是特定于数据集的。
- 所以,Zero-shot的评估反而更像是与人相同的泛化性的评估。
数据集:LibriSpeech & TED-LIUM
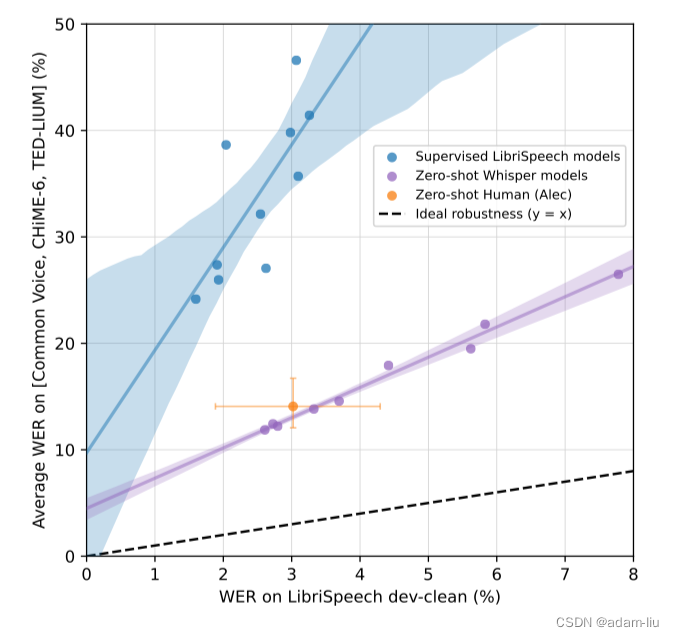
说明:
- 横轴为Librispeech数据集测试集上的WER,Y轴为其他数据集上的WER
- 紫色线为Whisper,蓝色线为其他模型(只在LibriSpeech上训练过)
- 黄色线为人类基准,给出了95%置信度区间。
分析:
- 虽然现有的模型在LibriSpeech上训练,可以实现非常低的WER,但是在其他数据集上的WER却很高
- Whipser在LibriSpeech上的Zero-shot虽然不如纯LibriSpeech数据集上训练的模型,但是,在其他数据集上的指标却很高。
- 而且,Whipser模型是可以取得与人相当或者优于人类的性能的。
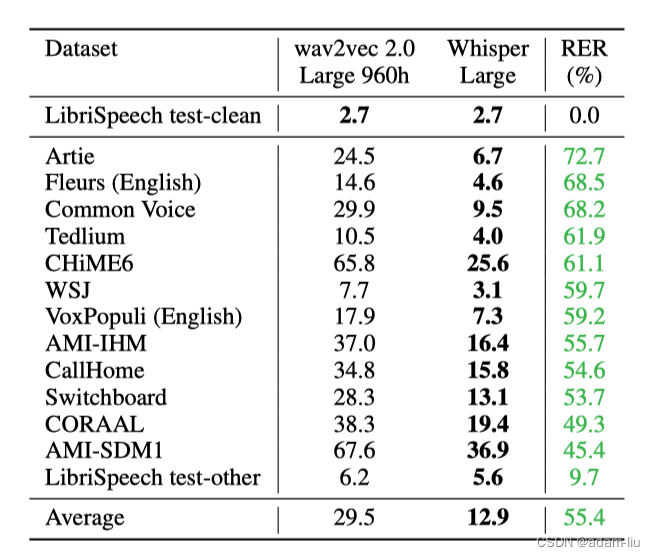
说明:
- 预训练的Wav2vec2 是包括了LibriSpeech的训练数据的。
- Whisper是在大量的互联网数据上预训练得到的。
分析:
- Whisper(Zero shot)和Wav2vec2(2020年提出)在LibriSpeech的测试集上都WER都是2.7
- Whipser在其他数据集上的表现与Wav2vec2截然不同
- 在其余13个数据集上Whisper的性能优于Wav2vec2模型性能 55.4%
- 证明:Whipser 准确且鲁棒
3.2 多语言语音识别
![[图片]](https://img-blog.csdnimg.cn/b4f12e30d32646e59beeb0c9e826a9d8.png)
分析
- 在MLS上实现了SOTA
- 在VoxPopuli上不如XLS和mSLAM的原因可能是后者的训练数据中有很多VoxPopuli的原始数据,而且,后者的训练语料更干净。
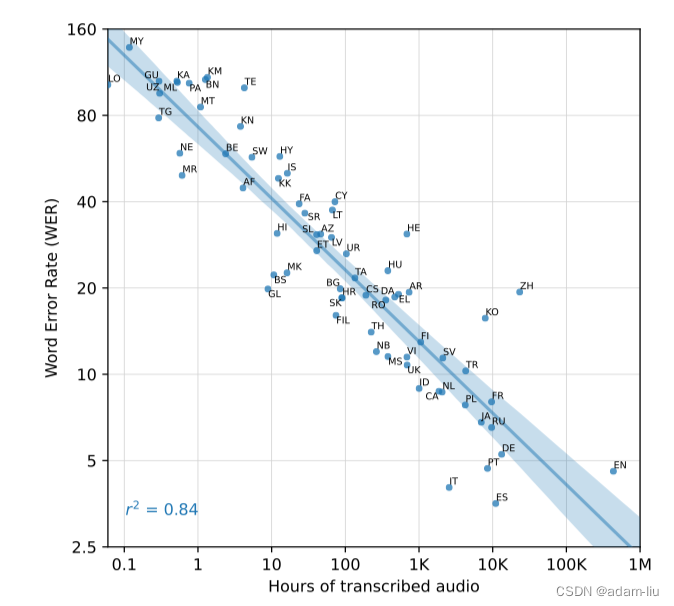
说明:
- 每种数据在Whisper预训练中具有不同的时长。
- 上述曲线是语言对应的时长与Whisper模型的WER之间的关系。
分析:
- 训练数据中语种的时长与WER是线性拟合的。(0.84的强平方相关系数)
- ZH(中)、KO(韩)等表现较差(可能是BPE不适合或者数据质量啥的)
3.3 多语言机器翻译
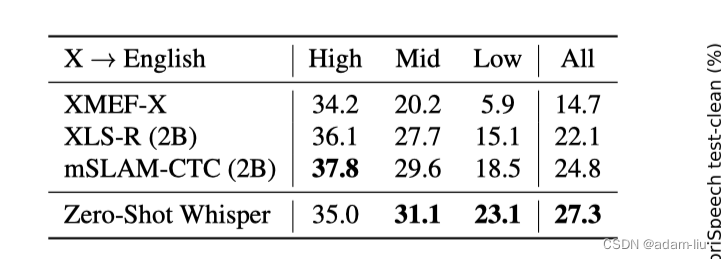
分析:
- Whisper在低、中资源下的性能更好,在高资源下,不如特定数据预训练的模型。
- 数量质量与数量的权衡(whisper 68万小时 VS CoVoST2 861小时)
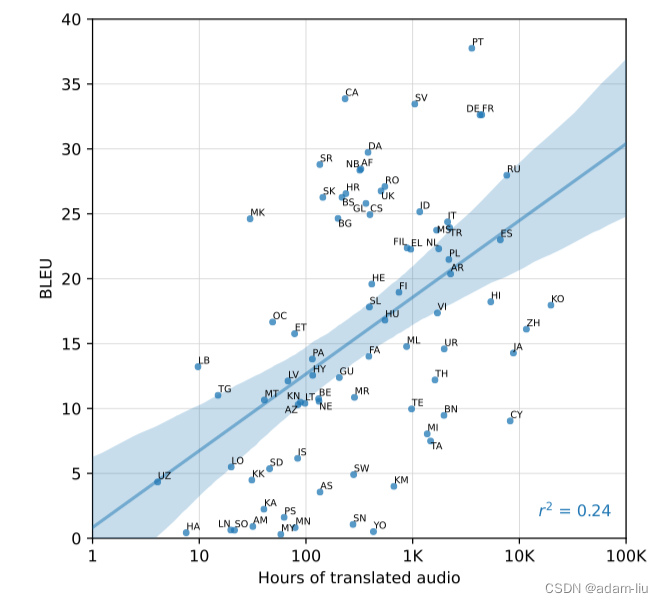
分析:
- 训练数据时长与BLEU有明显的线性关系。
- 0.24的强相关系数,低于0.84 。
- 可能是因为,异常数据造成的,比如CY语,9K小时->9BLEU
3.4 语种检测
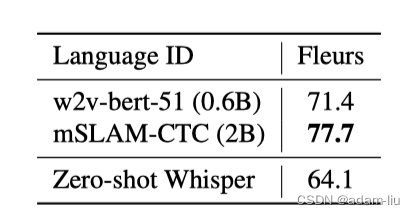
??? 作者说,这是因为Whisper的训练数据中不包含Fleurs训练数据中的20种语言,所以Whisper准确率的上限是80.4%,而不是100%。
在82中重叠的语言中,Whisper的准确率为79.7%。
3.5 对加性噪声的鲁棒性
![[图片]](https://img-blog.csdnimg.cn/79dd4c26db2e4d67bdc8449ccbf1d936.png)
分析:
- ASR系统的性能随着噪声的增加而降低。
- 很多模型在40dB的信噪比下性能是优于Whisper的
- 但随着噪声的增加,其他模型衰退剧烈,且逐渐接近Whisper甚至低于Whisper的性能。
- 证明了Whisper对噪声是鲁棒的
3.6 长语音转录
长格式的音频会通过30S的音频的窗口进行切分。
怎么合理的切分是一个问题,whisper提出了一套启发式方法:
# 1 beam search
beams = 5
# Temperature fallback
temperature = 0
while log(p) < -1 or gzip compression rate > 2.4 and temperature < 1:
temperature += 0.2
# previous-text conditioning
if temperature < 0.5:
conditioning = previous-text_conditioning + current_text_conditioning
# Initial timestamp constraint
if 0< start_time < 1:
do ---
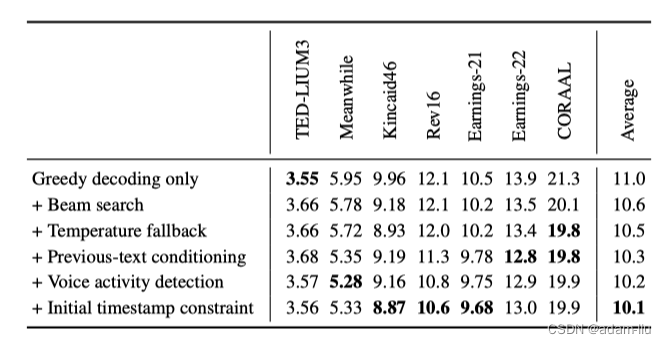
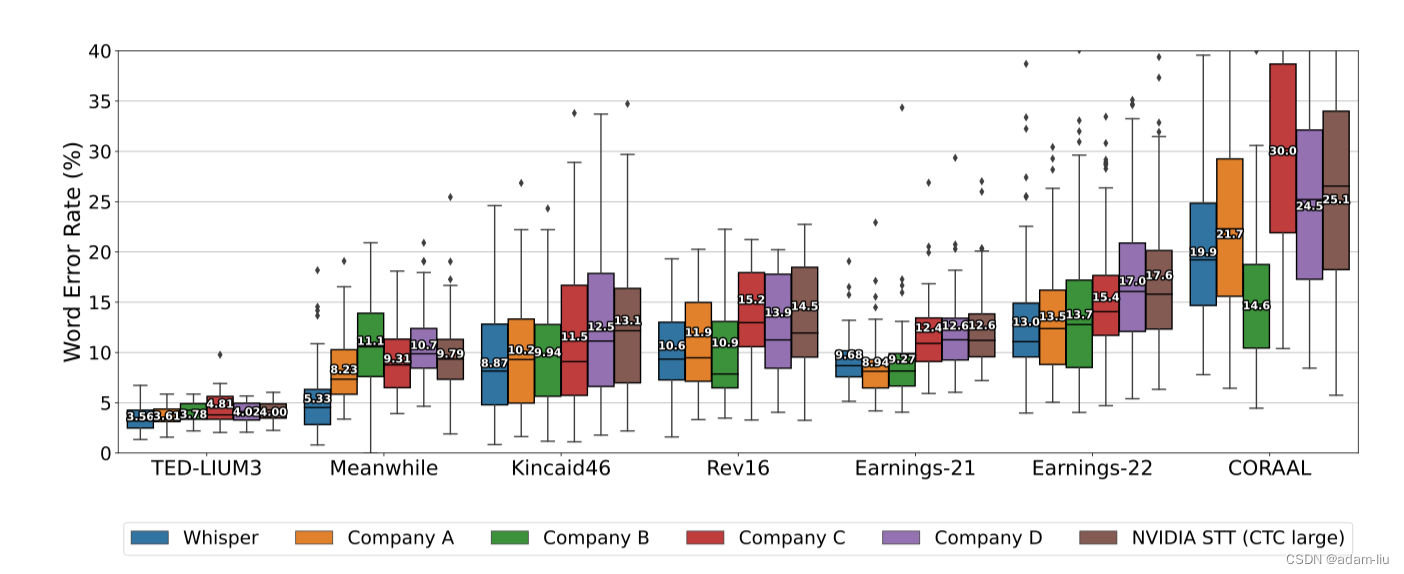
分析:
- !!Whisper在大多数数据集上的表现优于其他公司的模型 🐮🐮
- Whisper是端到端的,几乎没有任何的数据处理!
- 一些商业ASR系统可能已经在这些公开可用的数据集上进行了训练,所以Whisper的性能没准更优于图示。
3.7 人类基线
![[图片]](https://img-blog.csdnimg.cn/ecccf0cb1ef549a2b5f8a5f666dee73d.png)
分析:
- 计算机辅助服务的WER最低
- 纯人工的表现只比Whisper好一个点
- Whisper的英语ASR并不是很理想,但非常接近人类的水平。
4. 分析与消融
4.1 模型大小
![[图片]
[图片]](https://img-blog.csdnimg.cn/fad1f177572b4f059ea80ae1b06ac39c.png)
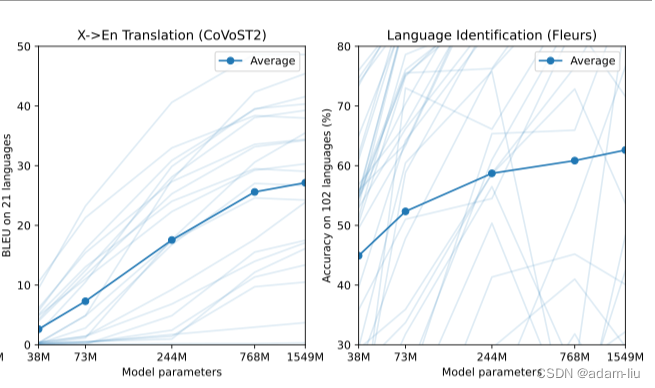
分析:
- 模型越大性能越好
4.2 数据集大小(小时)
![[图片]](https://img-blog.csdnimg.cn/d29f054896bd47e09191be5c0f8ff859.png)
分析:
- 训练数据时长越长,模型的性能越好。
- 纯英文上,超出1.3万小时后,感觉训练时长带来的收益已经很弱了。
- 而多语言、多任务(其他语种转英语)的性能,增加训练数据时长带来的收益还是可观的。
4.3 多任务和多语言迁移能力
![[图片]](https://img-blog.csdnimg.cn/91a40e209e5c44cfbd82689a14a301d7.png)
分析:
- 训练量少的时候,存在负迁移。
- 但是,训练量大的时候,是更优的。
- 不调整,联合模型也略优于纯英语训练的模型。