黑马Redis笔记高级篇 | 分布式缓存
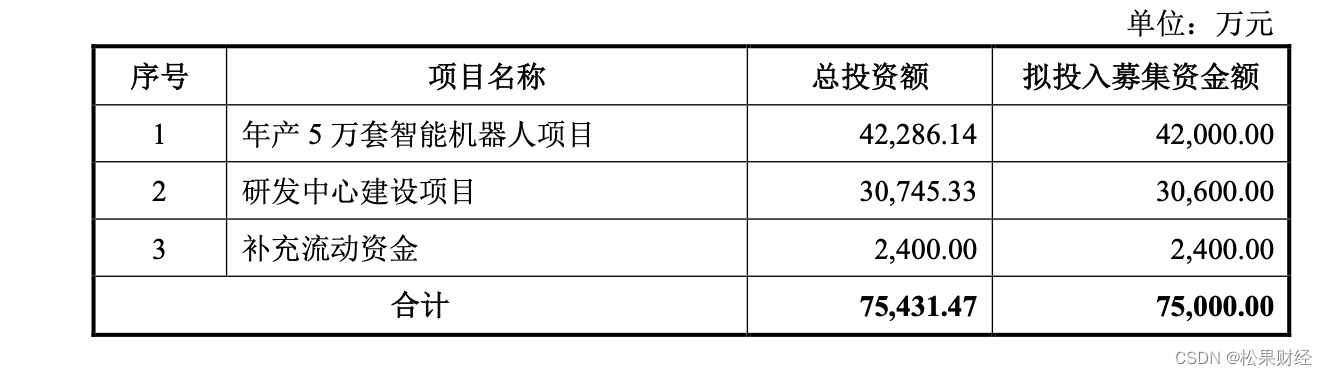
- 1、Redis持久化(解决数据丢失)
- 1.1 RDB持久化
- 1.1.1 定义
- 1.1.2 异步持久化bgsave原理
- 1.2 AOF持久化
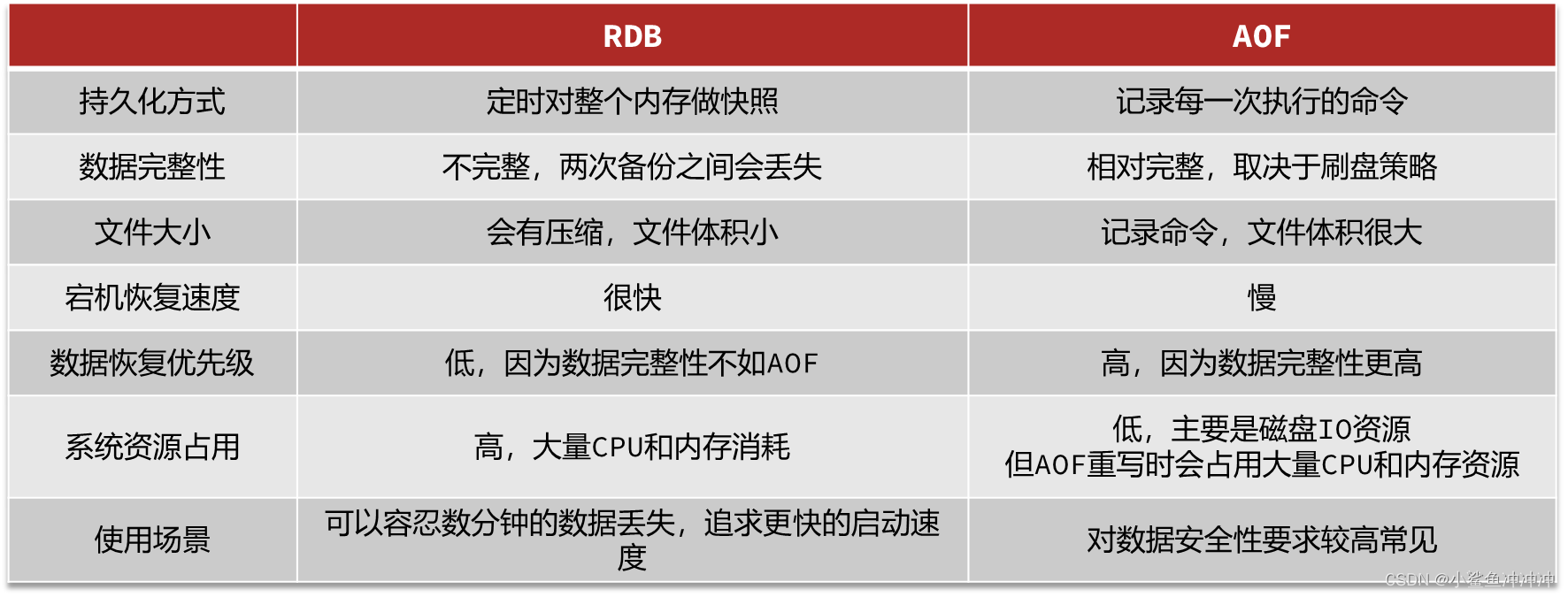
- 1.3 RDB和AOF比较
- 2、Redis主从(解决并发问题)
- 2.1 搭建主从架构
- 2.2 主从数据同步原理
- 2.2.1 全量同步
- 2.2.2 增量同步
- 3、Redis哨兵(解决故障恢复问题)
- 3.1哨兵的作用和原理
- 3.2搭建哨兵集群
- 3.3RedisTemplate的哨兵模式
- 4、Redis分片集群(增强存储能力)
- 4.1 搭建分片集群
- 4.2 散列插槽
- 4.3 集群伸缩
- 4.4 故障转移
- 4.4.1 自动故障转移
- 4.4.2 手动故障转移
- 4.5 RedisTemplate访问分片集群
1、Redis持久化(解决数据丢失)
1.1 RDB持久化
1.1.1 定义
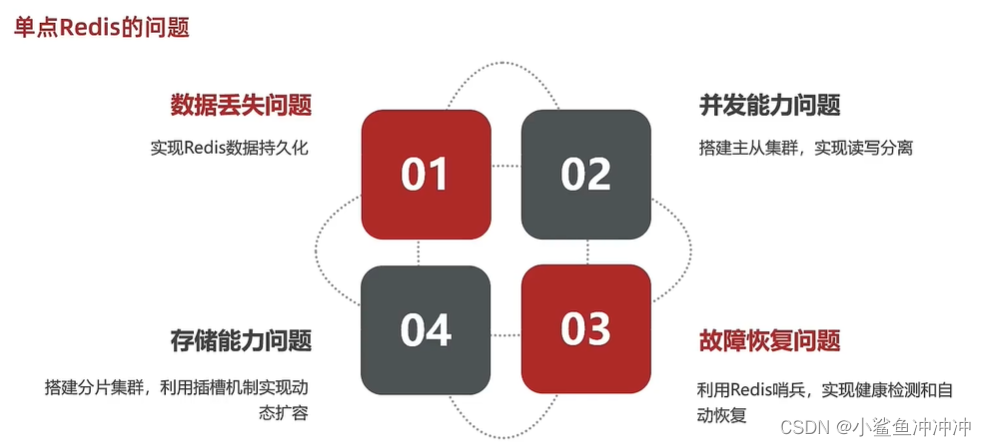
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。 简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
快照文件称为RDB文件,默认是保存在当前运行目录
RDB执行时机:
-
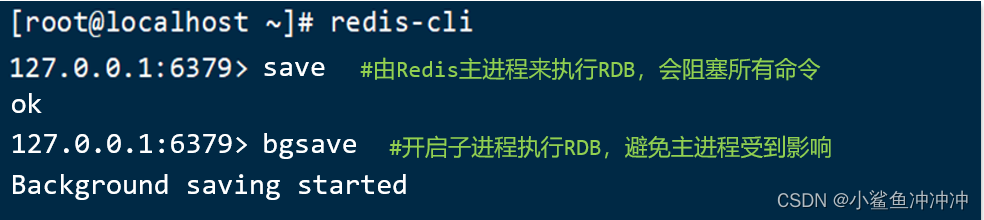
Redis停机时会执行一次RDB。 (save命令由Redis主进程来执行RDB,会阻塞所有命令;bgsave命令则开启子进程执行RDB,是异步的,避免主进程受到影响)
-
Redis内部有触发RDB的机制,可以在redis.conf文件中找到。

1.1.2 异步持久化bgsave原理
RDB方式bgsave的基本流程?
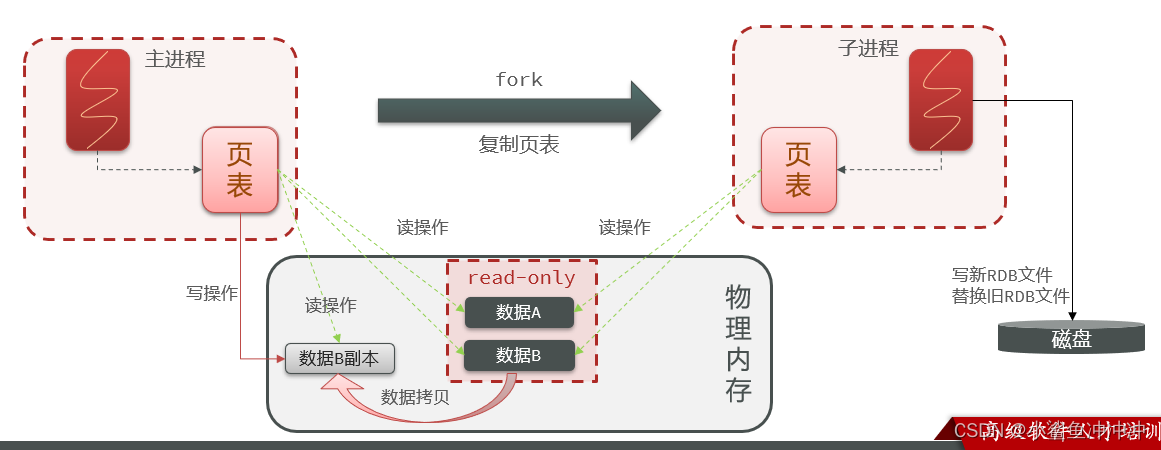
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件。
fork采用的是copy-on-write技术:
当主进程执行读操作时,访问共享内存;
当主进程执行写操作时,则会拷贝一份数据,执行写操作。
RDB会在什么时候执行?save 60 1000代表什么含义?
默认是服务停止时执行。也可以配置config文件触发执行。
save 60 1000代表60秒内至少执行1000次修改则触发RDB
RDB的缺点?
RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
fork子进程、压缩、写出RDB文件都比较耗时
1.2 AOF持久化
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。

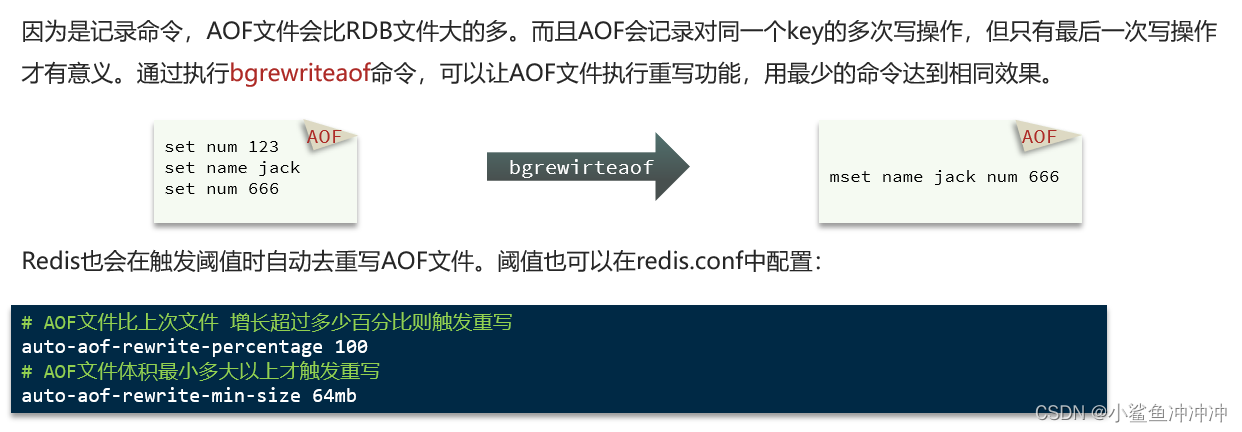
1.3 RDB和AOF比较

2、Redis主从(解决并发问题)
2.1 搭建主从架构
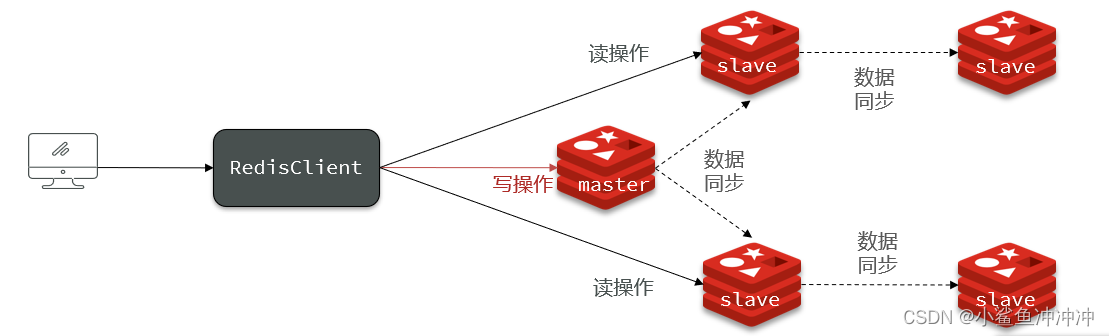
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离。
因为根据经验,对Redis的操作大部分都是读,写操作占少数,所以在集群中采用读写分离,同时以少量主节点和大量从节点搭配,大大提升Redis的读取性能。主节点需要注意的就是数据同步如何同步给从节点。
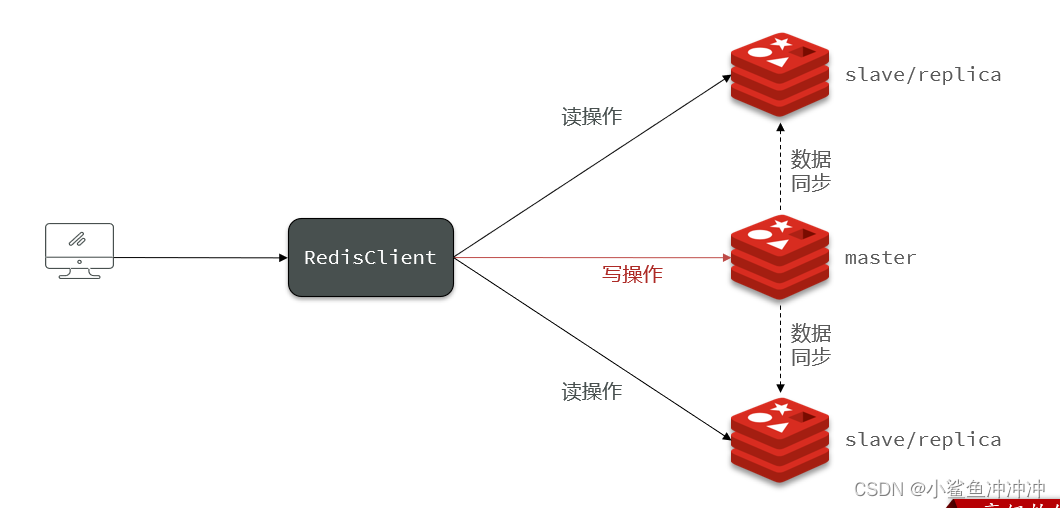
在同一台服务器上搭建集群的步骤:
1、安装Redis,这里不赘述,博主的redis是在云服务器上利用宝塔面板自动安装的,默认安装在/www/server/redis目录下。
2、这里我会在同一台服务器上开启3个redis实例,模拟主从集群,端口为7001、7002、7003。
3、准备实例和配置。要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。我在/tmp/目录下分别创建了7001、7002、7003三个子目录。# 创建目录 mkdir 7001 7002 7003
4、检查原始/www/server/redis/redis.conf文件中,持久化模式保持为默认的RDB模式,AOF保持关闭状态。
5、然后将/www/server/redis/redis.conf文件拷贝到/tmp/7001、/tmp/7002、/tmp/7003三个目录中
6、修改每个文件夹内的配置文件,将端口分别修改为7001、7002、7003,将rdb文件保存位置都修改为自己所在目录,具体执行命令详见黑马的资料
7、虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息(这里我直接将ip全部设置为云服务器ip)
8、由于我的数据库设置了数据库,在后续开启主从关系会出现主节点使用info replication查到的connected_slaves是0的情况。因此需要在从节点的配置文件中添加一行masterauth 自己的密码
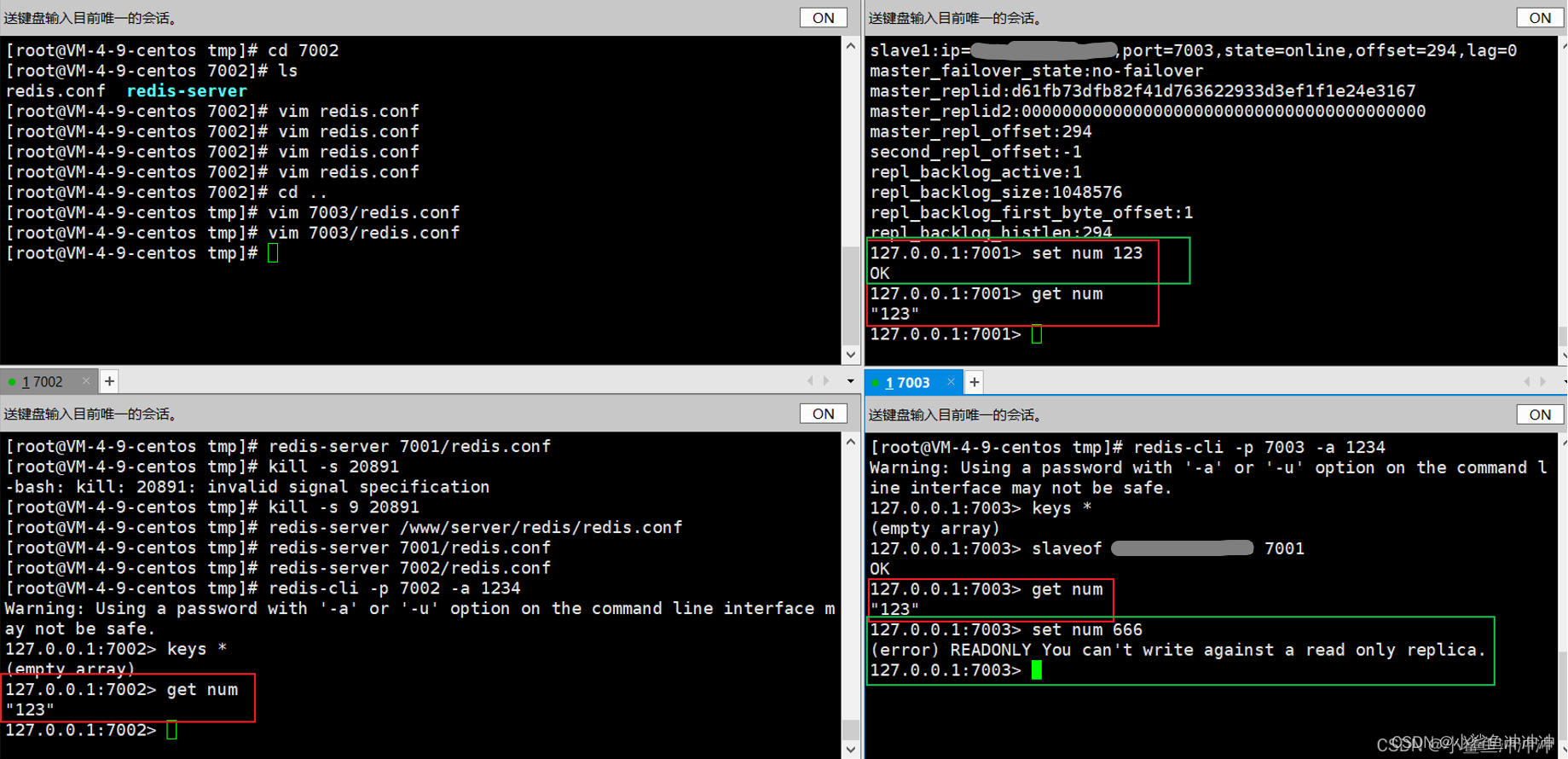
集群搭建成功:
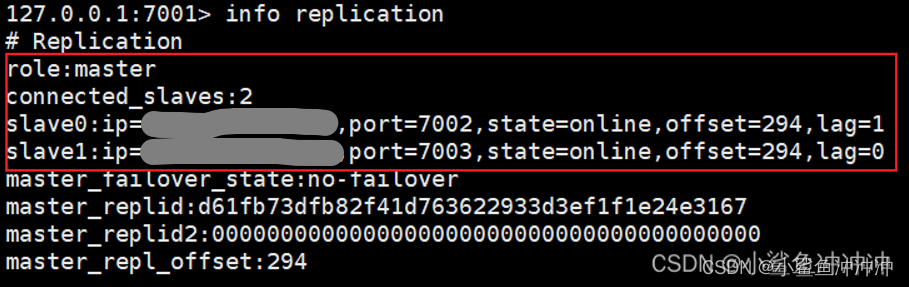
红色框验证数据同步,绿色框验证读写分离(只有主节点能写入)
2.2 主从数据同步原理
2.2.1 全量同步
主从第一次同步是全量同步
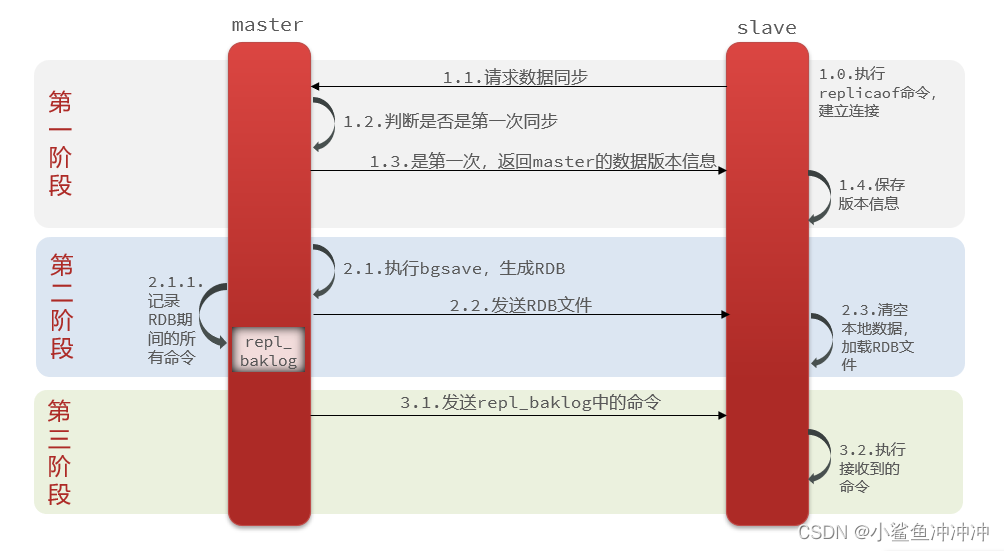

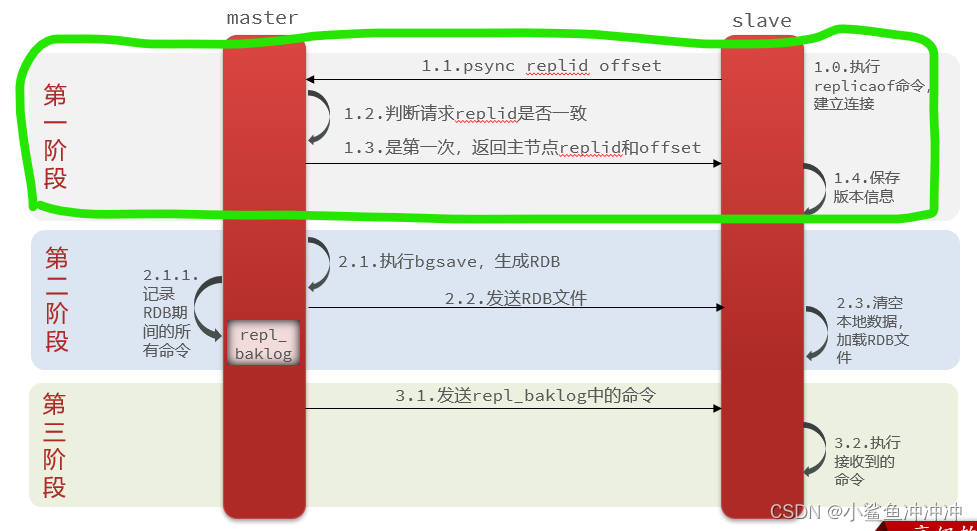
全量同步:

2.2.2 增量同步
但如果slave重启后同步,则执行增量同步
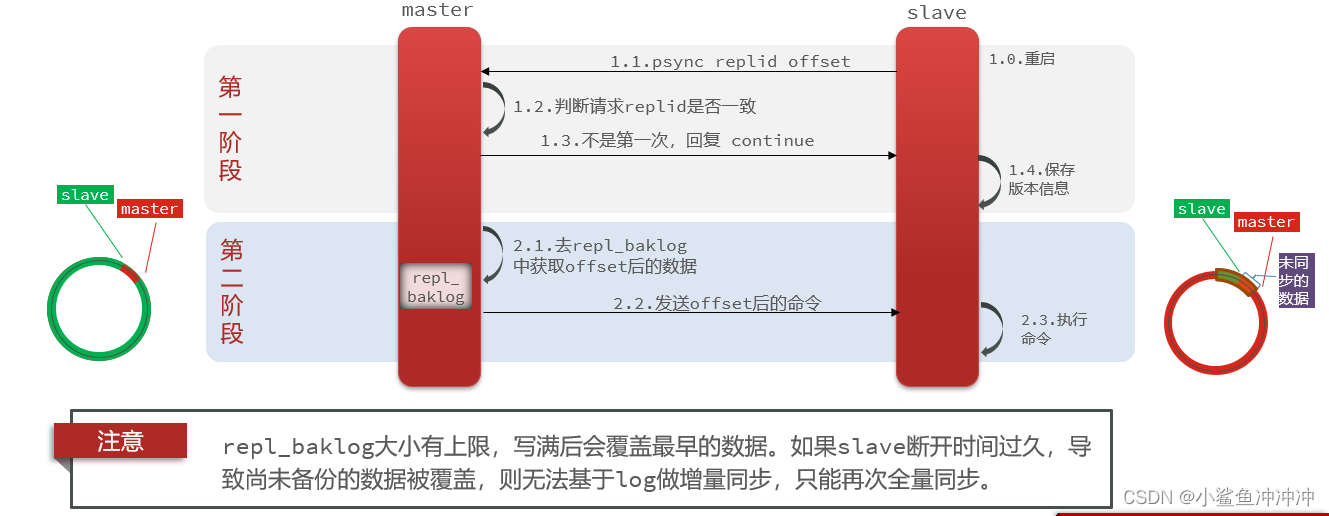

主-从-从链式结构示意图:

3、Redis哨兵(解决故障恢复问题)
3.1哨兵的作用和原理
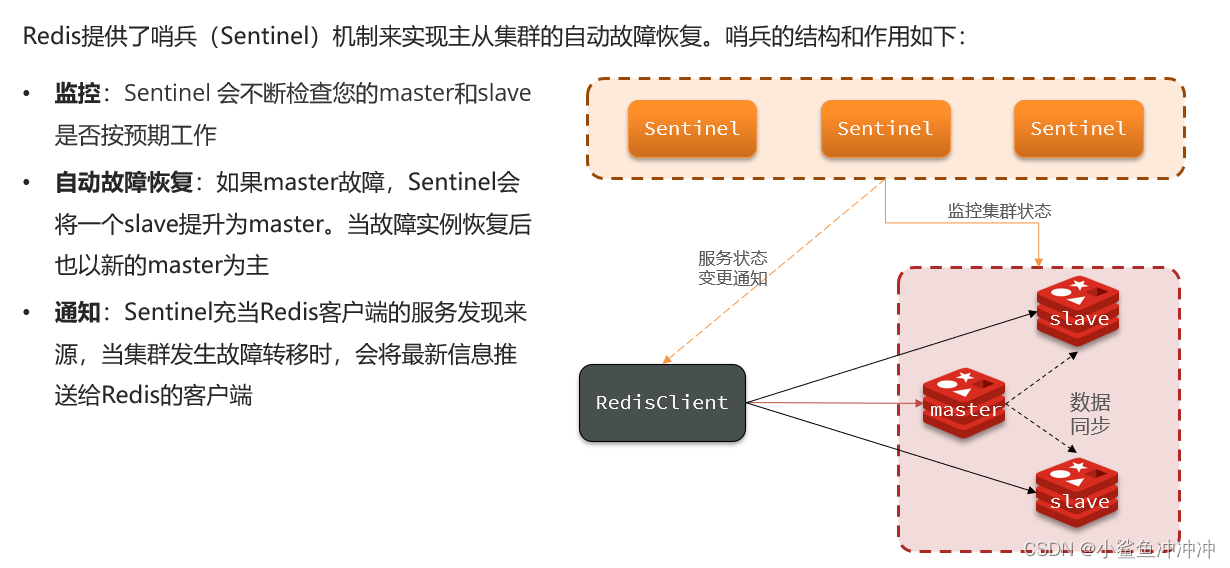
1、服务状态监控
2、选举新的master

3、如何实现故障转移
3.2搭建哨兵集群
搭建哨兵集群流程(基于上文搭建的Redis集群搭建):
1、在/tmp/下创建s1,s2,s3三个目录mkdir s1 s2 s3
2、在s1,s2,s3目录下创建sentinel.conf,写入哨兵配置信息,这部分参见黑马资料(因为我的redis设置了密码,所以sentinel.conf中需要添加sentinel auth-pass mymaster(集群名称) 密码)
3、在/tmp/下执行redis-sentinal s1/sentinel.conf或者redis-server s1/sentinrl.conf --sentinel启动哨兵sentinel,三台都要启动,此时哨兵已经监控了Redis集群(这里有大坑,本人的Redis集群时在云服务器上搭建的,要在安全组设置开启哨兵对应的端口,否则哨兵间不能进行通信,该情况表现为sentinel启动后日志出现+sdown sentinel 一串sentinelid...)
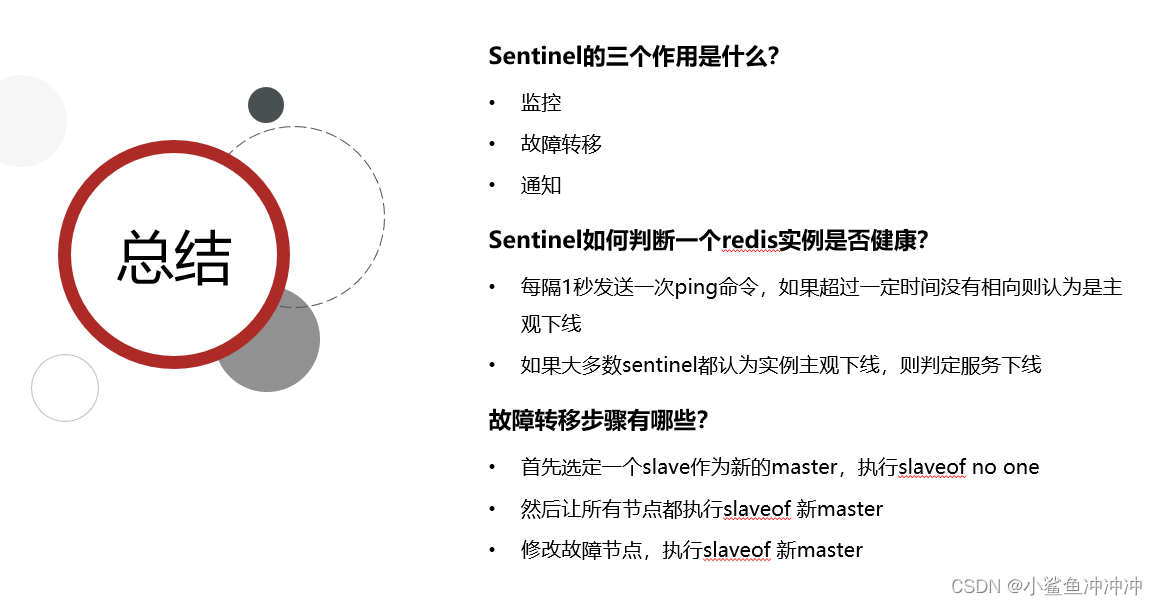
哨兵启动:
红框表示监控的集群信息,该集群有三个节点7001,7002和7003,其中主节点是7001
绿框表示哨兵集群信息,还有两个哨兵分别在27002和27003端口
这些信息都会被记录在sentinel.conf中
测试节点恢复:
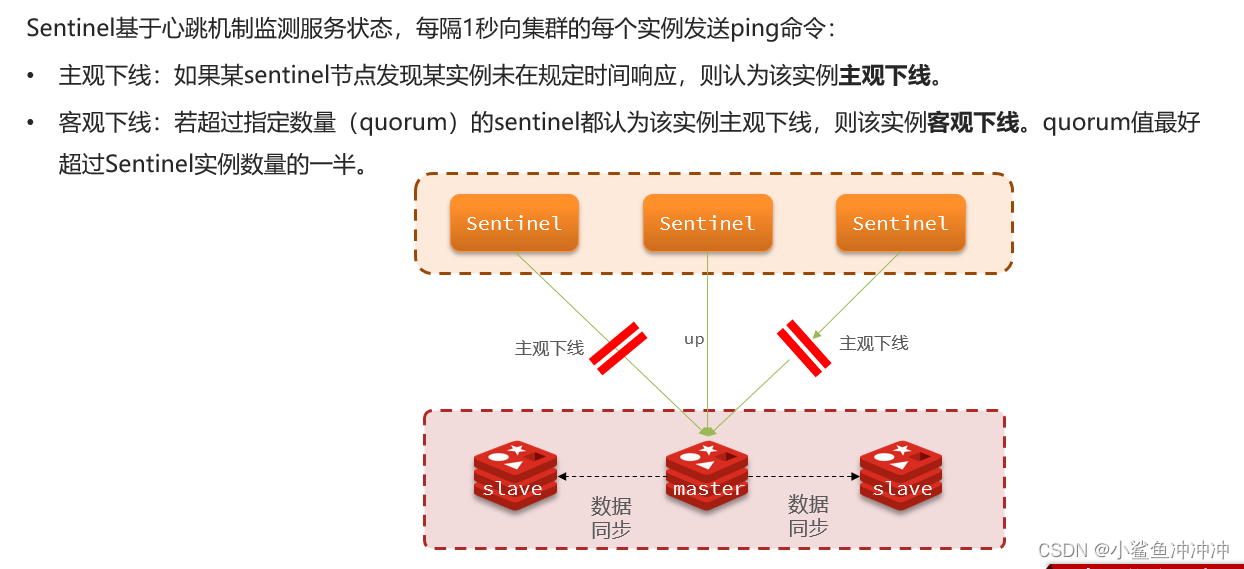
1、主观下线,客观下线

2、哨兵选主,因为只需要一个哨兵做故障恢复

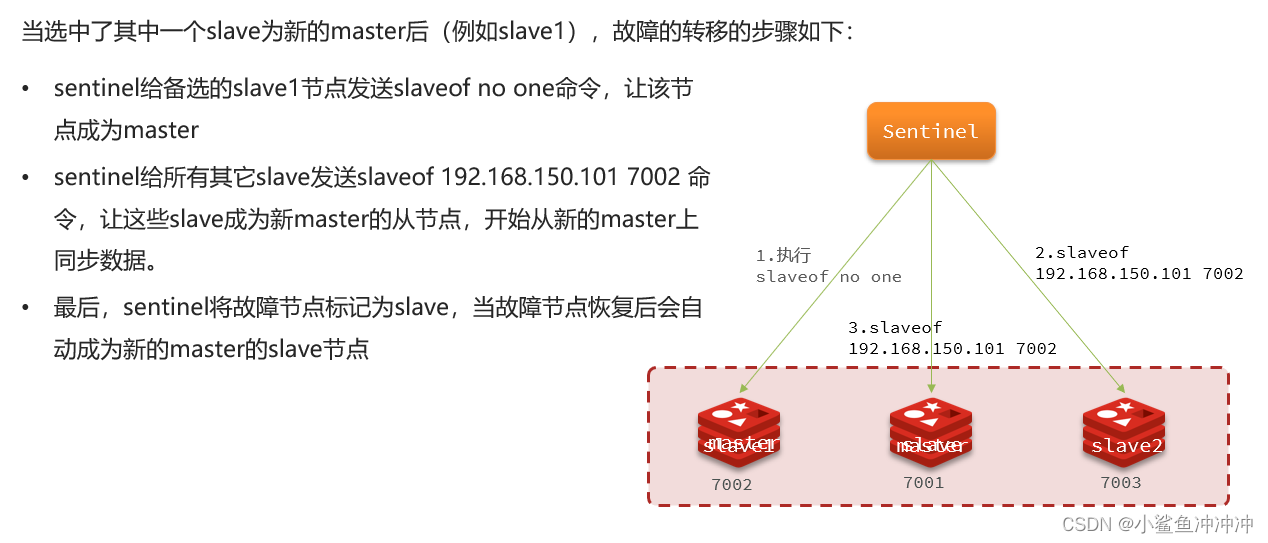
3、重新选取新的主节点并更新配置
选取新的master -> 将新选取的主节点7003设置为slaveof no one -> 将原本的主节点7001关于主节点的配置删除 -> 将新的主节点广播给剩余节点(7002)

4、手动重启7001端口
启动后自动执行replicaof ip 7002 ,成为一个从节点,同时重新进行全量同步。
3.3RedisTemplate的哨兵模式
 1、在pom文件中引入redis的starter依赖:
1、在pom文件中引入redis的starter依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2、然后在配置文件application.yml中指定sentinel相关信息:
spring:
redis:
password: 1234 #如果Redis有密码市一定要配置密码
sentinel:
master: mymaster #指定master名称
nodes: # 指定Redis集群信息
- ip地址:27001
- ip地址:27002
- ip地址:27003
3、配置主从读写分离(在启动类中)

@SpringBootApplication
public class RedisDemoApplication {
public static void main(String[] args) {
SpringApplication.run(RedisDemoApplication.class, args);
}
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer(){
return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
}
主从自动切换和读写分离由客户端自动完成。
4、Redis分片集群(增强存储能力)

4.1 搭建分片集群
1、在/tmp目录下删除之前的7001、7002、7003这几个目录,重新创建出7001、7002、7003、8001、8002、8003目录rm -rf 7001 7002 7003 # 删除旧的,避免配置干扰、mkdir 7001 7002 7003 8001 8002 8003 #创建目录
2、在/tmp下准备一个新的redis.conf文件
port 7001
# 开启集群功能
cluster-enabled yes
# 集群的配置文件名称,不需要我们创建,由redis自己维护
cluster-config-file /tmp/7001/nodes.conf
# 节点心跳失败的超时时间
cluster-node-timeout 5000
# 持久化文件存放目录
dir /tmp/7001
# 绑定地址
bind 0.0.0.0
# 让redis后台运行
daemonize yes
# 注册的实例ip
replica-announce-ip 你的ip
# 保护模式
protected-mode no
# 数据库数量
databases 1
# 日志
logfile /tmp/7001/run.log
# 密码
# 连接到节点的密码
requirepass 你的密码
# 节点之间的互访访问的密码
masterauth 你的密码
3、将这个文件拷贝到7001、7002、7003、8001、8002、8003目录下:echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf # 执行拷贝
4、修改每个目录下的redis.conf,将其中的6379修改为与所在目录一致printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf # 修改配置文件
5、直接启动服务printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf # 一键启动所有服务
6、带密码的集群创建(后面加 -a 密码)redis-cli --cluster create ip地址:7001 ip地址:7002 ip地址:70039 ip地址:8001 ip地址:8002 ip地址:8003 --cluster-replicas 1 -a 密码
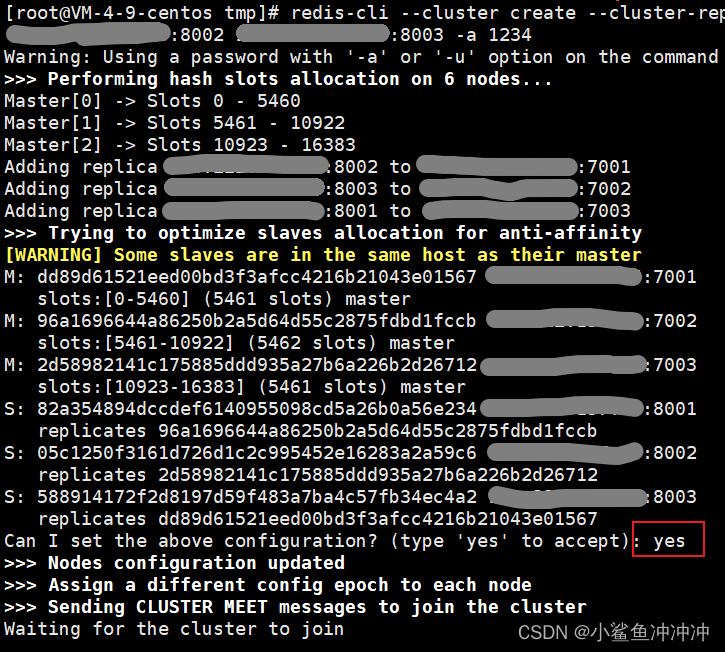
创建成功!(云服务器用户注意云服务器和宝塔都得开放端口17001,17002,17003,18001,18002,18003,这些是集群的总线端口。)
每个Redis集群中的节点都需要打开两个TCP连接。一个连接用于正常的给Client提供服务,比如7001,还有一个额外的端口(通过在这个端口号上加10000)作为数据端口,例如:redis的端口为7001,那么另外一个需要开通的端口是:7001 + 10000, 即需要开启 17001。17001端口用于集群总线,这是一个用二进制协议的点对点通信信道。这个集群总线(Cluster bus)用于节点的失败侦测、配置更新、故障转移授权,等等。
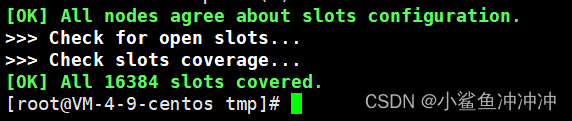
7、查询redis集群状态redis-cli -p 7001 -a 密码 cluster nodes
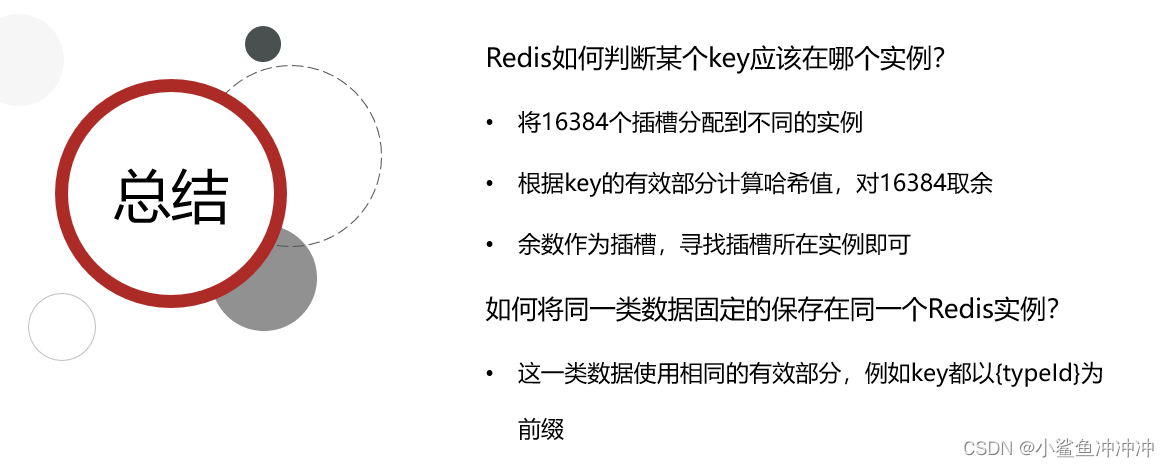
4.2 散列插槽
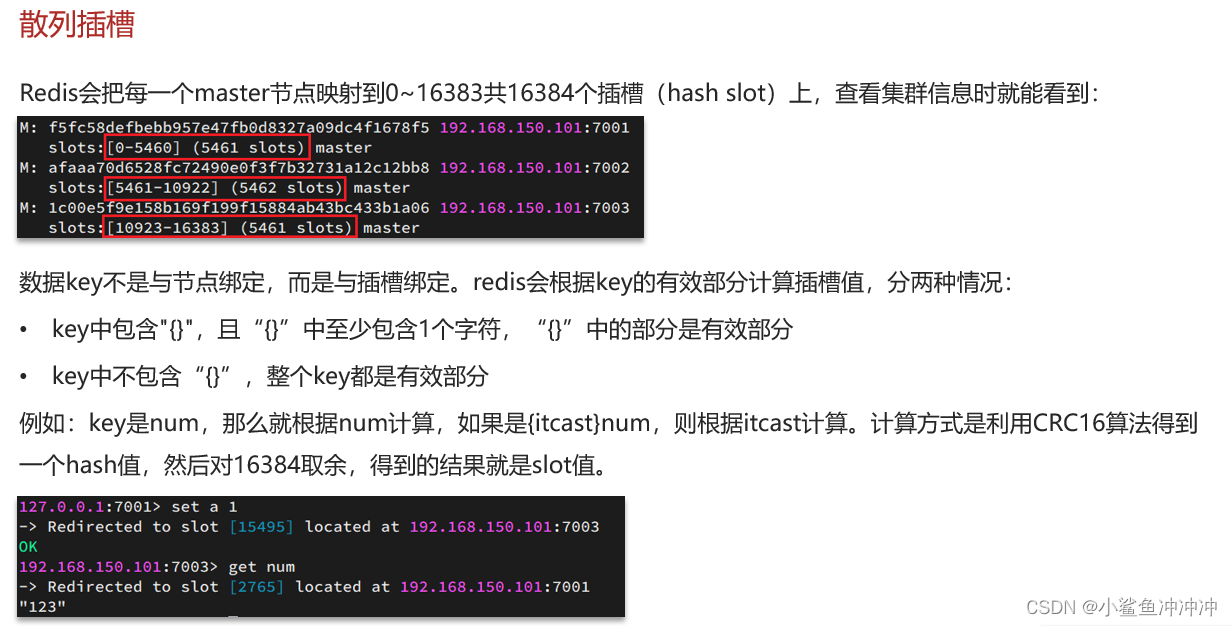
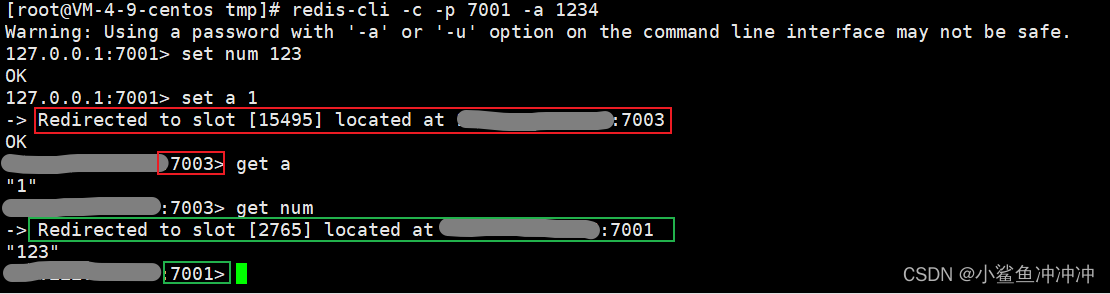
验证:redis-cli -c -p 7001 -a 密码
4.3 集群伸缩
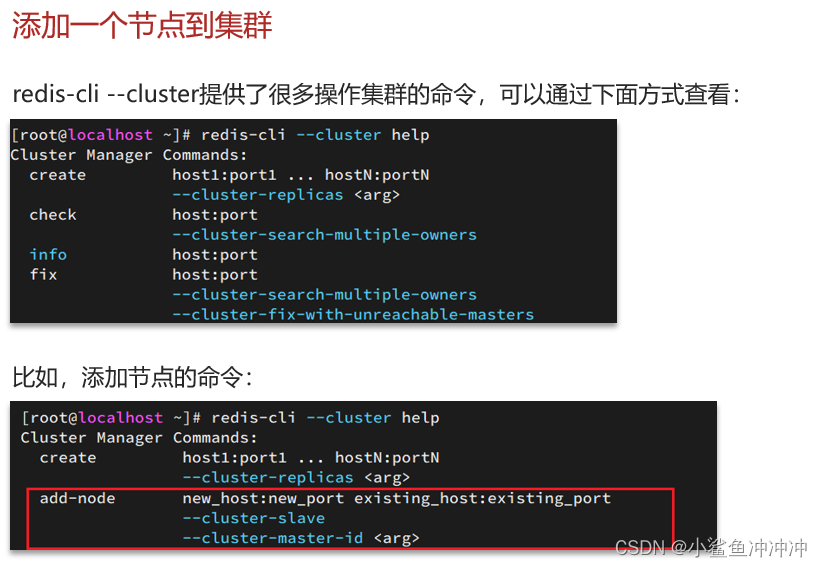
【案例】

1、启动一个新的redis实例,端口为7004redis-server 7004/redis.conf(云服务器和宝塔面板放开7004 和 17004端口)
2、添加7004到之前的集群,并作为一个master节点redis-cli -a 密码 --cluster add-node ip地址:7004 ip地址:7001
3、给7004节点分配插槽,使得num这个key可以存储到7004实例redis-cli -a 密码 --cluster reshard ip地址:7001,这里执行时需要输入:转移到插槽数量,接受插槽的节点id,原始插槽节点id

【练习】删除7004这个实例
1、将7004节点上的所有插槽转移到其他节点上(我返回给7001)redis-cli -a 密码 --cluster reshard ip地址:7004
2、删除节点redis-cli -a 密码 --cluster del-node ip地址:7004 节点id
4.4 故障转移
4.4.1 自动故障转移
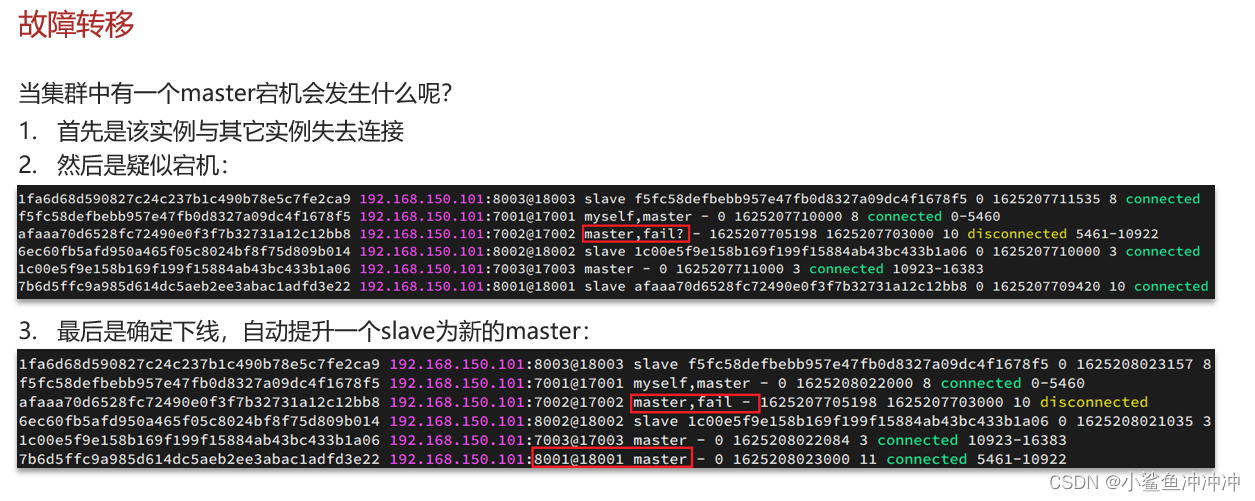
4.4.2 手动故障转移
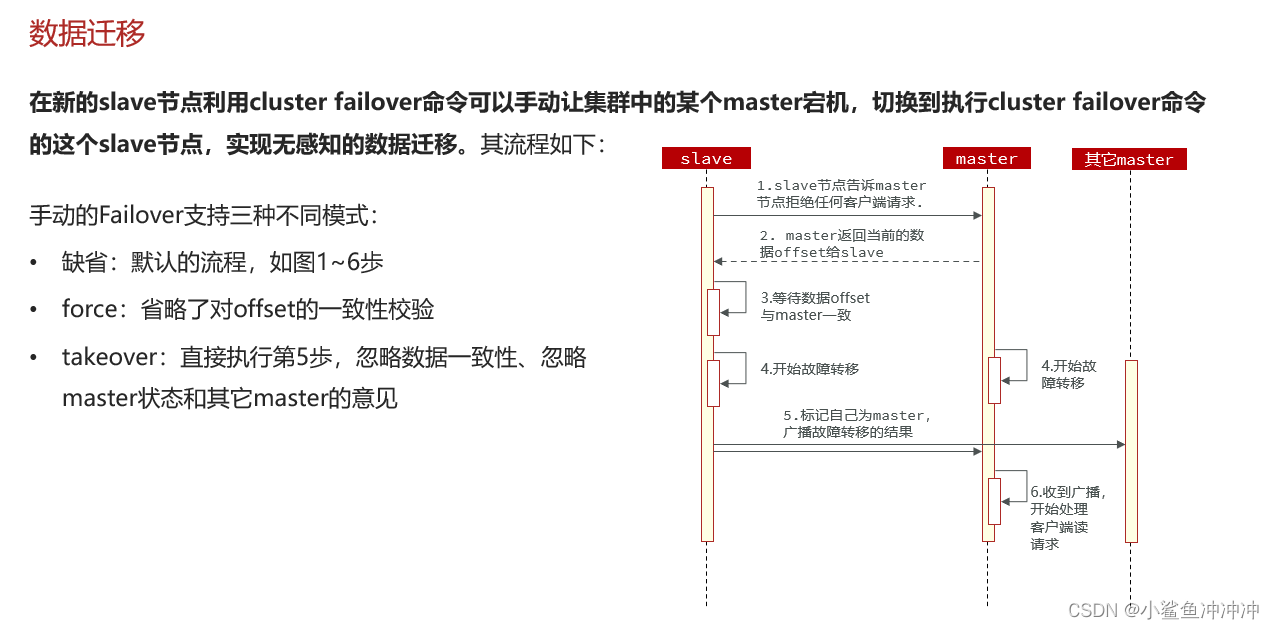
4.5 RedisTemplate访问分片集群
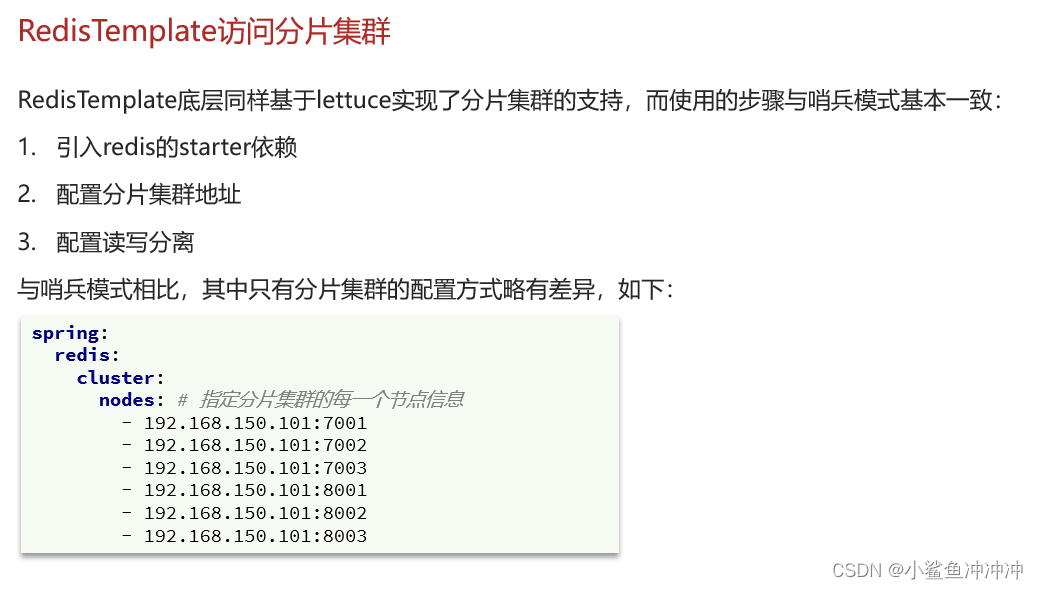





![沉痛悼念互联网[云原生领域]技术大牛----左耳朵耗子(陈皓老师)](https://img-blog.csdnimg.cn/img_convert/4075dbda60012b05d694c4c87fdd0a45.jpeg)