前言
最近在做 CDH -> CDP 的迁移,Yarn迁移完成后,发现在spark/flink 作业的executor内存参数和Yarn web ui 显示申请的内存不一致。
例如:一个 spark 任务申请了 10个 executor,每个executor 内存为 1G,driver内存为 1G ,共11G,但是Yarn web ui 上面显示单个容器内存为 2G,共22G。
环境
yarn 3.0capacity scheduler
问题排查
首先需要明确一点,不管是 spark/flink 任务,申请的 executor 的内存并不等于 yarn 的容器内存。
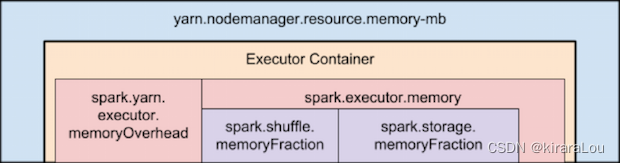
yarn 的容器内存肯定是要大于,spark/flink 的申请的executro的内存的。但是为什么是总大于1G,这个就是我们今天的排查方向。
问题原因
Capacity Scheduler 分配容器内存的大小是“最小容器内存”的倍数。例如,如果你的每个容器的最小调度器mb内存是1gb,而你要求一个4.5gb大小的容器,调度器会把这个请求四舍五入为5gb。对于非常高的最小值,这可能会造成巨大的资源浪费问题,例如,如果我们要求5GB的最小值,我们将得到8GB的服务,提供我们甚至从未计划使用的3GB的额外资源 当配置最小和最大的容器大小时,最大的容器应该被最小的容器平均分割。
结论
经过一系列排查,得出以下结论。
yarn的容器申请的内存肯定是要大于,spark/flink的申请的executro的内存的。Capacity Scheduler是根据最小容器内存的倍数分配,比如我们设置executor memory为1G, yarn 申请的容器内存肯定要高于1G,由于倍数分配的问题,最终yarn containor内存分配为2G。- 这里顺便说下
Fair Scheduler的机制是类似的,都是整数倍的分配,不同的是根据yarn.scheduler.increment-allocation-mb这个参数来设置的,默认为512M。
参考
- https://blog.cloudera.com/yarn-capacity-scheduler/
- https://hadoop.apache.org/docs/r3.1.2/hadoop-yarn/hadoop-yarn-site/FairScheduler.html