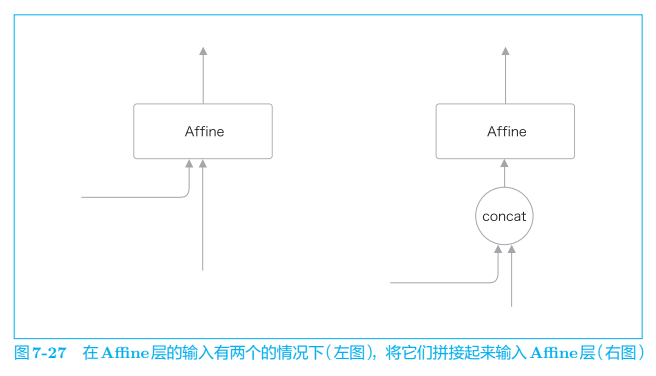
独立编译调试
Hi,我是阿昌,今天学习记录的是关于独立编译调试的内容。
当组件做 独立的版本演进时,如果开发在本地每次修改代码时,都需要进行集成打包验证,反而会影响日常的开发效率。所以如果能够让组件独立进行编译调试,测试验证的速度就会大大提升。通过对比,来看看集成编译以及组件独立编译的区别。
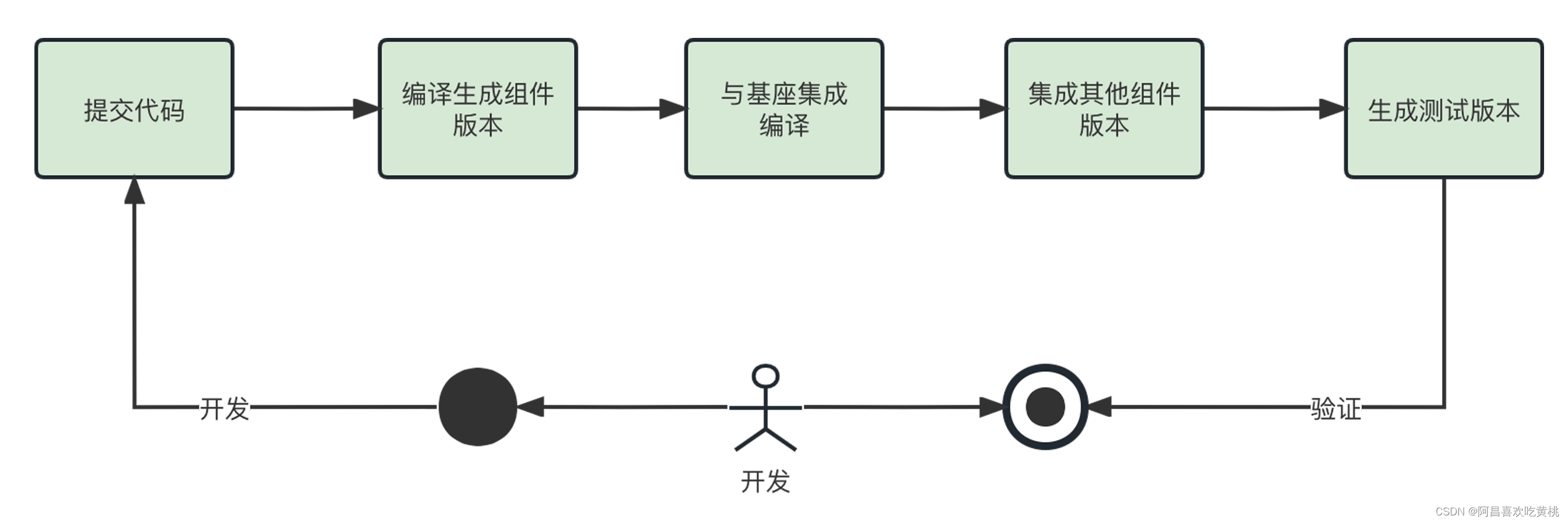
集成编译时,开发人员每次代码提交都需要编译生成组件版本,然后再与基座集成编译,同时也需要集成其他的组件版本才能生成最终的测试版本。
此时如果其他组件还都是源码编译,那么每次修改自己的组件代码后都要连带编译其他组件代码才能进行验证,非常浪费时间。情况就像后面这样。
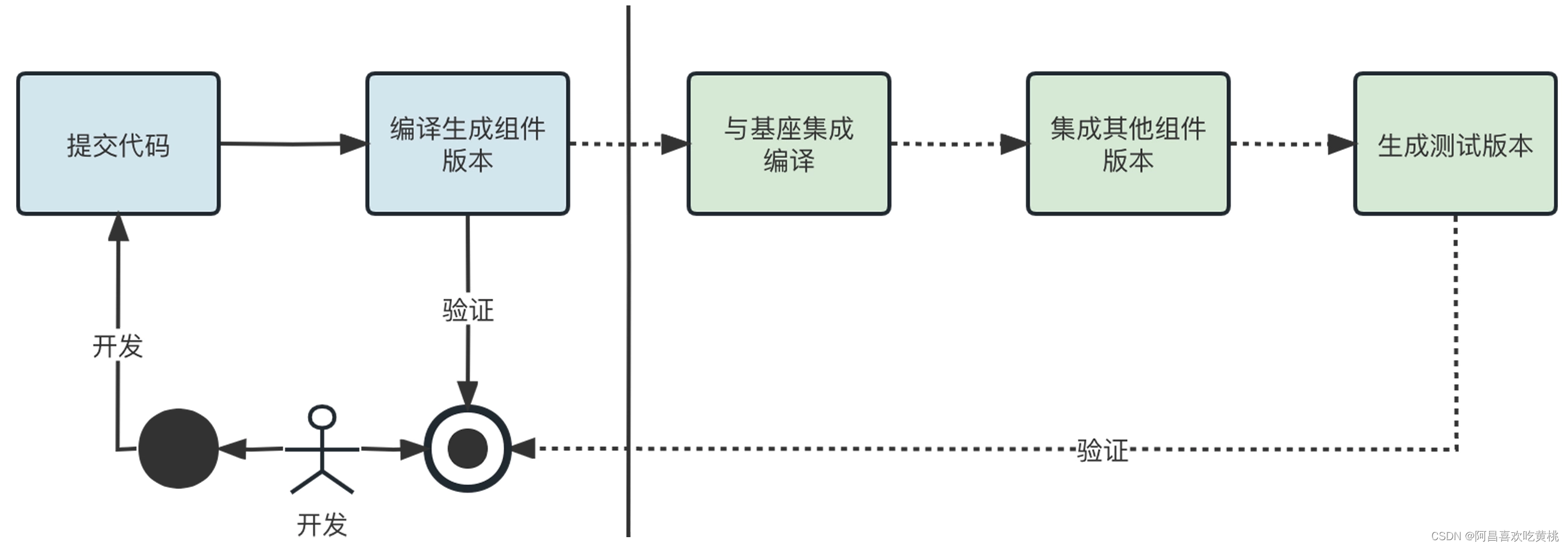
相比较集成验证,组件独立编译调试需要让组件能够进行自验证,避免每次都需要集成基座与其他组件才能进行验证。在日常的开发过程中,我们可以通过组件自验证来进行编译调试,最后再进行集成的验证,这样可以有效提高开发效率。思路是后图这样。
组件独立编译调试的 3 种常用的方式,分别为依赖基座进行测试、组件独立运行测试以及自动化测试验证。
掌握这 3 种独立编译调试的方法,可以帮助在日常开发中,更快验证代码功能验证和定位问题,避免每次修改代码都需要集成所有组件才能进行验证。
一、依赖基座进行测试
依赖基座进行测试:
与集成测试类似,依赖基座进行测试是将目标组件与基座一同打包生成测试版本进行验证。
和完整的集成验证不同,这个时候打包不会集成其他的非必要组件,你可以结合后面这张图来理解。
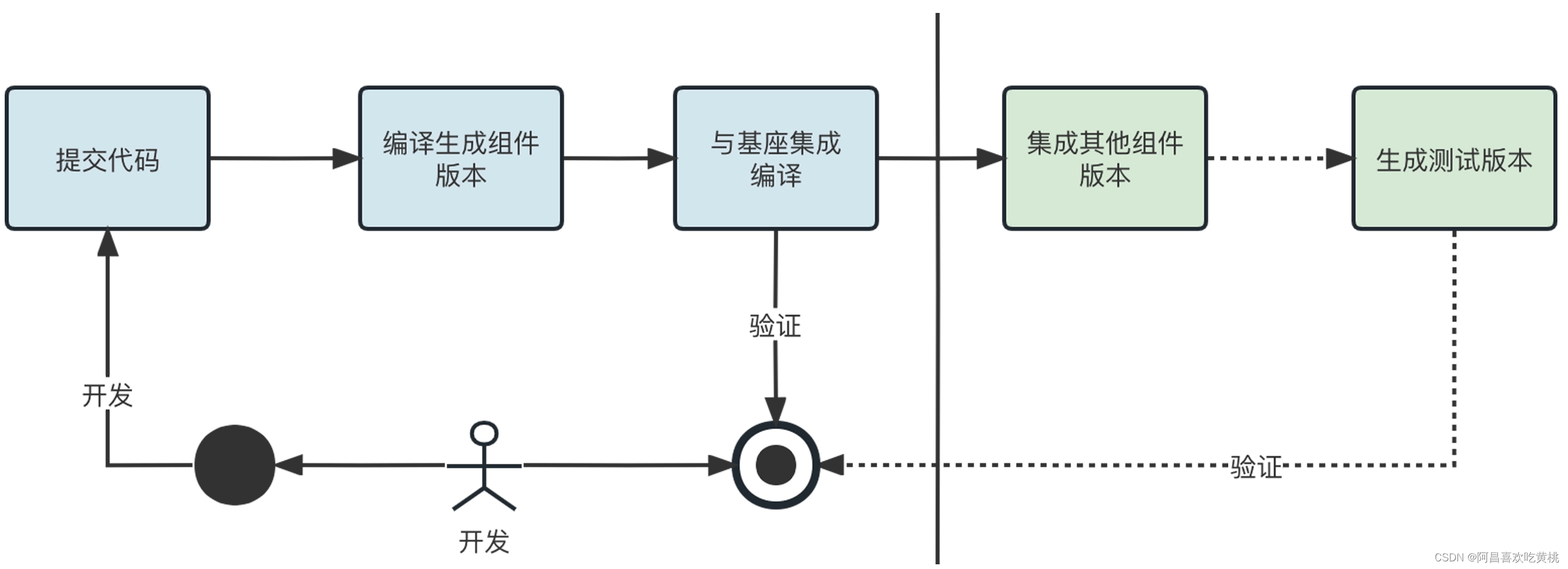
前面 Sharing 项目经过兼容性改造以后,已经支持了依赖基座进行测试的方式。
假如现在只需要对账户组件进行测试验证,那么在编译时,可以只将账户组件以及支持运行必要的组件集成打包即可。
//implementation project(':file')
//implementation project(':message')
//只集成账户组件
implementation project(':account')
此时我们就可以独立集成账户组件进行测试,不用加载其他的组件,运行结果是这样。

采用这种独立编译调试的方法除了提高编译的速度外,在测试时也可以减少其他组件的干扰,因为此时集成的有且仅有目标的测试组件。
当然,如果要达到这种运行的条件,需要做好组件的兼容性,具体参考组件运行时兼容:让组件可以灵活插拔的内容。
不然就算组件能独立编译,但是如果无法独立运行也无法满足测试要求。
二、组件独立运行测试
组件独立运行测试。与方式一的区别是这种方式组件能支持独立运行,不需要集成基座
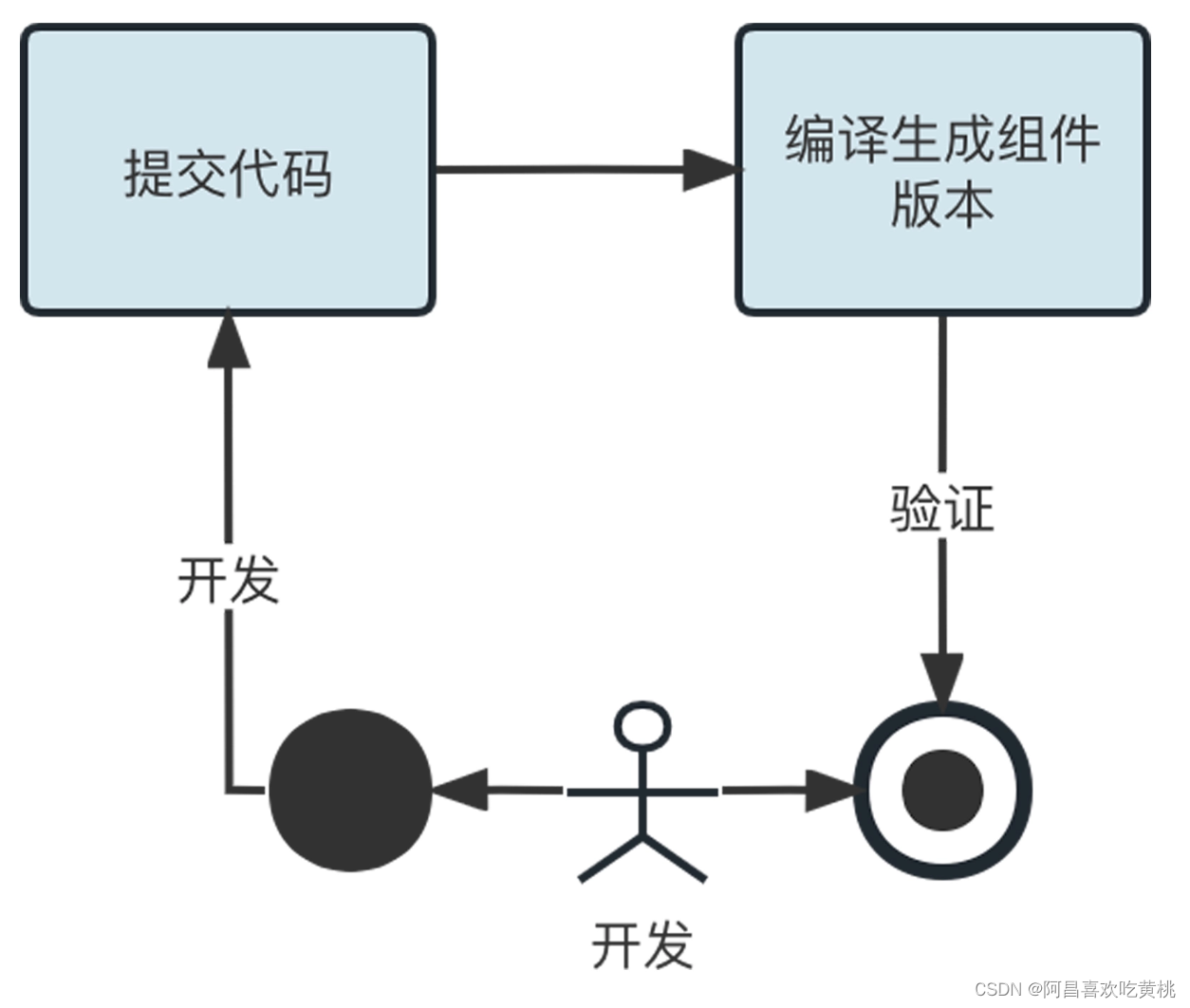
以 Sharing 项目的文件组件为例,来看看组件如何才能支持独立运行测试。
首先,组件要独立运行需要满足 2 个条件。
-
第一个是以 “com.android.application” 插件的形式运行,这样才能够以 APK 的形式运行;
-
第二个是要有主入口,能够展示相关的页面。
针对第一个条件,我们可以通过参数配置来控制 gradle 的插件集成形式,支持配置生成 application 插件。
def isApp = false
if (isApp) {
//可运行
apply plugin: 'com.android.application'
} else {
//作为库
apply plugin: 'com.android.library'
}
defaultConfig {
if (isApp) {
applicationId 'com.jkb.junbin.sharing.feature.file'
}
}
增加了配置脚本代码后,我们就可以通过改变 isApp 参数来调整组件的打包方式。我们将 isApp 设置为 true 后,重新触发编译,此时文件模块就变成可以支持 APK 运行的模块,像下图这样。
接下来看第二个条件,需要增加入口来启动主要的页面。
这里有一个问题是要控制好调试的代码不要在集成的时候被打入到发布的二进制制品中。
测试代码需要隔离开,避免产生干扰。
此时,可以采用在工程的 src 目录中增加 debug 目录的方式,专门用于存放编译调试的代码,这样在构建 release 版本时这些测试代码就不会被打包进来,工程目录你可以参考后面的截图。
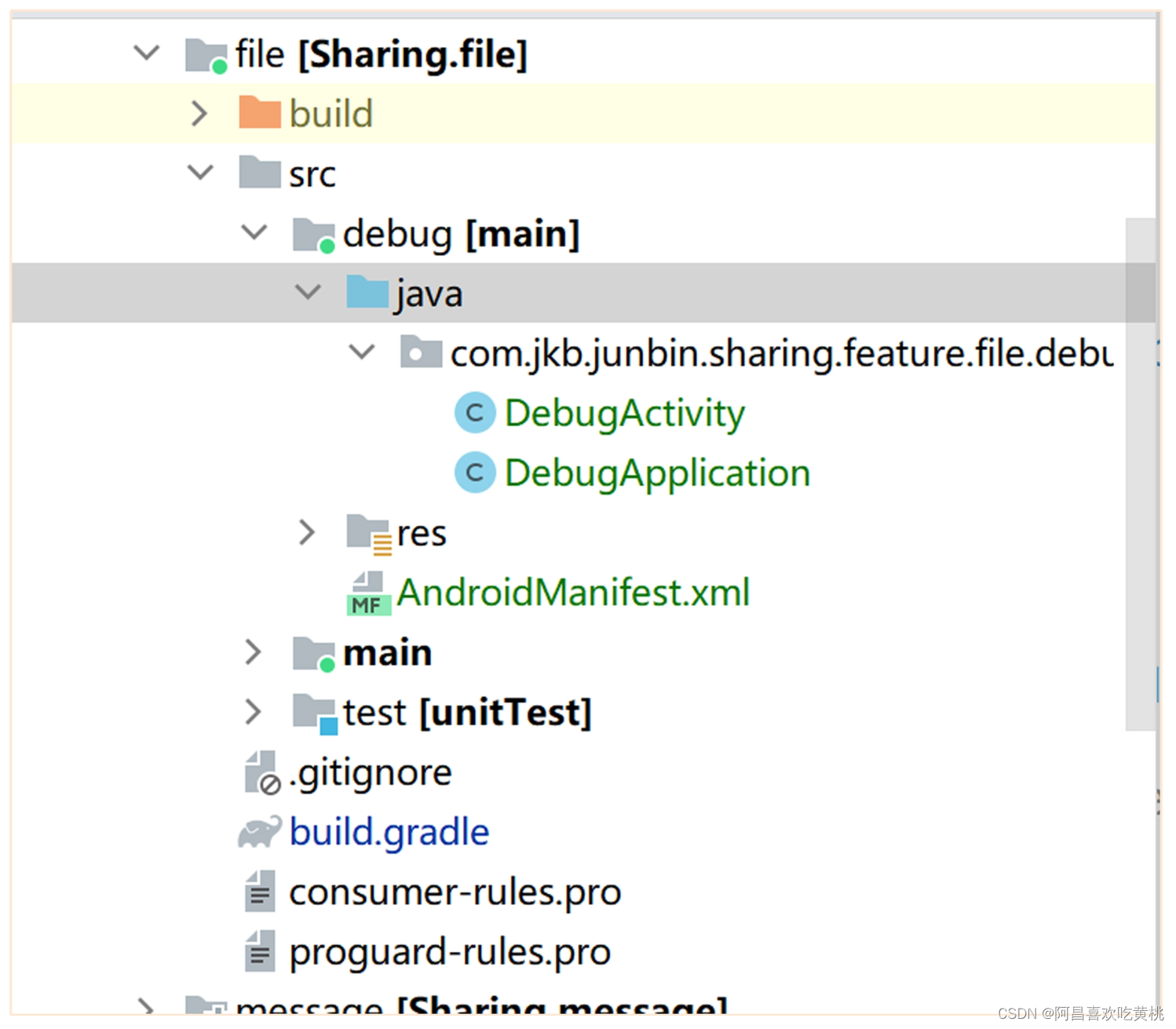
其中 DebugActivity 就是用来展示文件主页面,其代码也很简单,就是直接展示 FileFragment 的页面,代码是后面这样。
<?xml version="1.0" encoding="utf-8"?>
<androidx.constraintlayout.widget.ConstraintLayout
xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="match_parent">
<fragment
android:id="@+id/fragment_file"
class="com.jkb.junbin.sharing.feature.file.FileFragment"
android:layout_width="match_parent"
android:layout_height="match_parent"/>
</androidx.constraintlayout.widget.ConstraintLayout>
完成这些准备工作以后,就可以独立运行账户组件的内容,下图展示了运行结果。
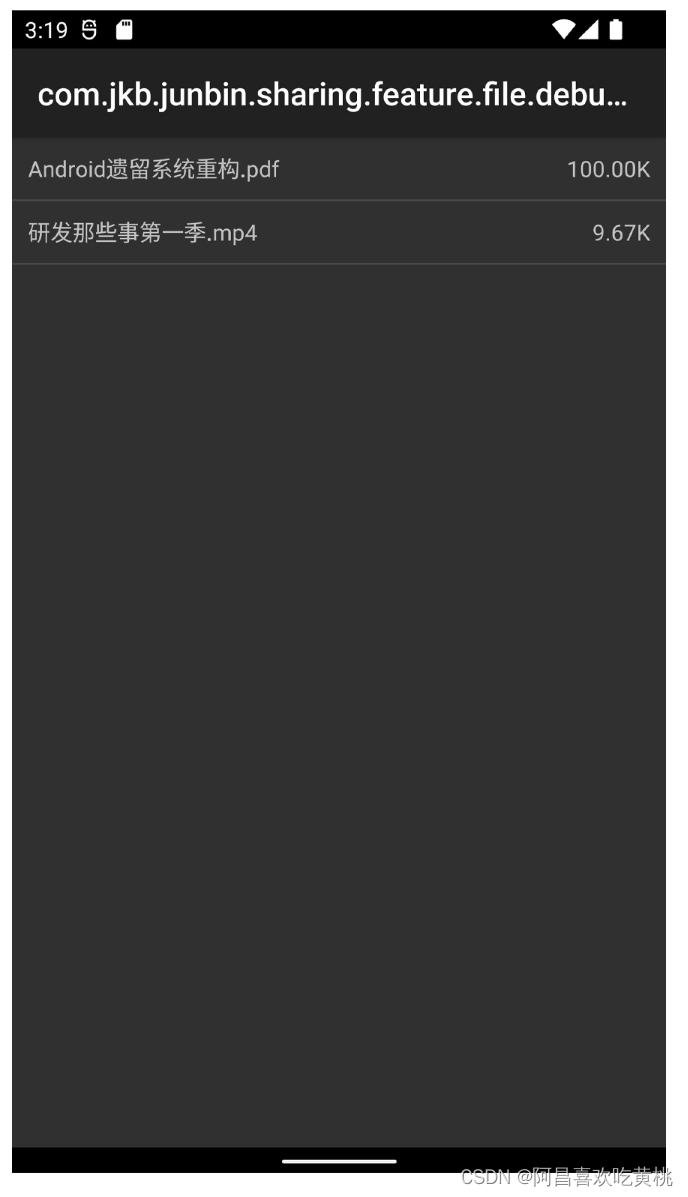
组件独立运行的好处是可以脱离于基座做到真正的独立运行,特别是当基座的代码也比较庞大,编译需要耗费一定时间的情况下,对于效率的提升就更加明显了。
但缺点就是需要额外增加编译调试的代码,而且如果长期没有和基座及其他组件集成,将可能导致一部分集成问题更晚发现。
通常情况下,独立编译调试一般在本地开发时使用,当代码提交时会有流水线来做集成的验证检查,保证最终的代码提交质量。
三、自动化测试验证
自动化测试验证。其实在前面的基础篇和解耦重构篇中,都大量地运用了自动化测试验证的手段。那么为什么说自动化测试验证是比较好的编译调试手段呢?
2 个优点。
- 第一个优点是自动化测试测试的粒度可以精确类及方法。在日常的开发过程中,很多时候修复一个 bug,或许就是对某个方法的表达式的修改,如果每次修改验证都需要打包验证,这个过程效率就非常低下。有了自动化测试验证就不一样了,可以在毫秒级别测试验证这段逻辑。这里结合 Sharing 项目来举一个例子,在文件组件的代码中,有一个展示文件大小格式化的代码逻辑。
public static String formatFileSize(long fileSize) {
DecimalFormat df = new DecimalFormat("#.00");
String fileSizeString = "";
if (fileSize < 1024) {
fileSizeString = df.format((double) fileSize) + "B";
} else if (fileSize < 1048576) {
fileSizeString = df.format((double) fileSize / 1024) + "K";
} else if (fileSize < 1073741824) {
fileSizeString = df.format((double) fileSize / 1048576) + "M";
} else {
fileSizeString = df.format((double) fileSize / 1073741824) + "G";
}
return fileSizeString;
}
假如现在产品增加了一个新需求,由于存在大量的数据,需要展示 T 的转换,需要扩展该方法,代码是后面这样。
else if (fileSize < 1099511627776L) {
fileSizeString = df.format((double) fileSize / 1073741824) + "G";
}else {
fileSizeString = df.format((double) fileSize / 1099511627776L) + "T";
}
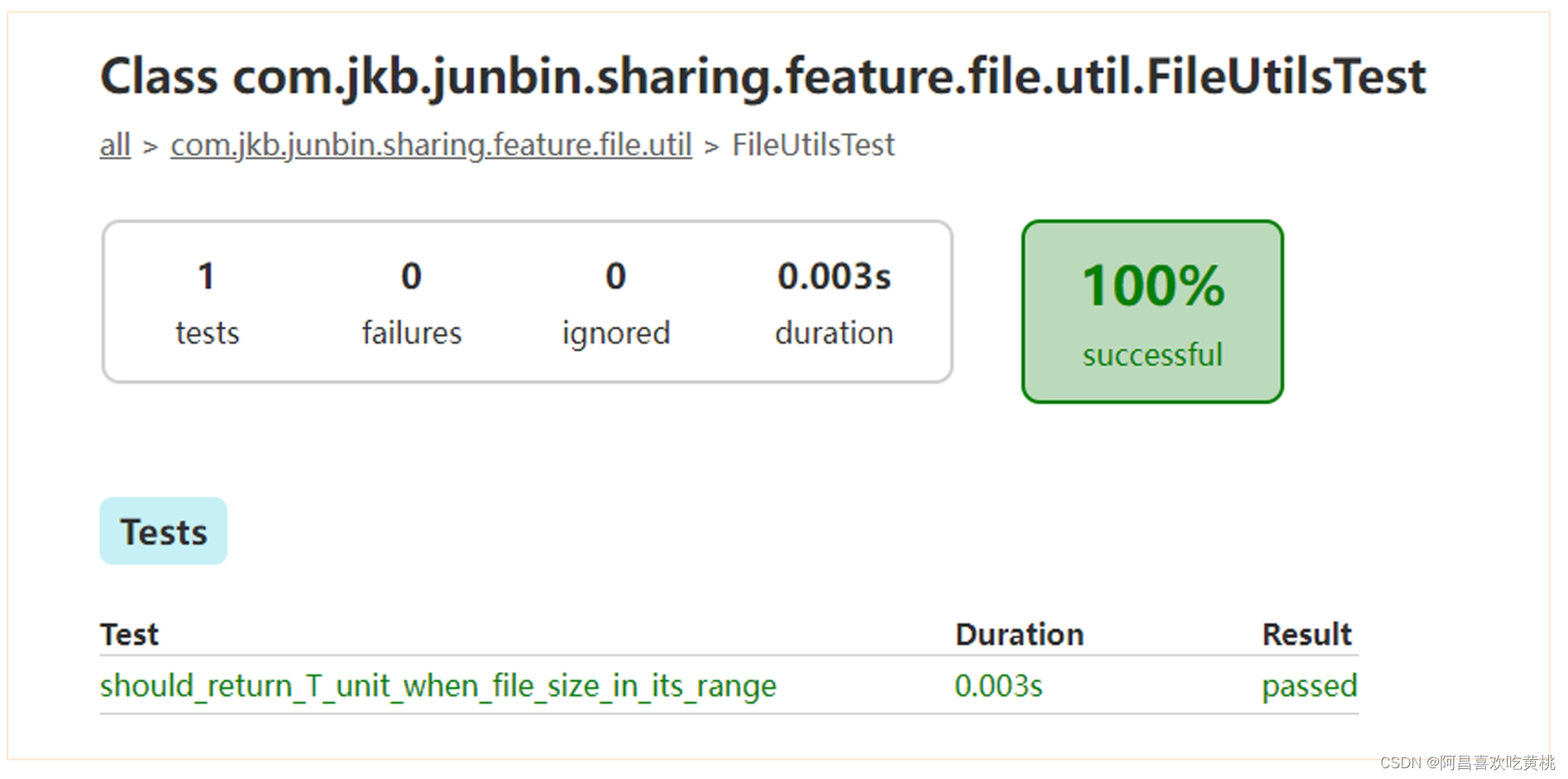
这个时候,修改完代码以后有 2 种选择来验证,一种就是通过上面介绍的方式,进行打包验证。可以通过配置服务下发有 T 级别的文件数据,然后确认数据格式化展示是否正常。另外一种方式就是就是通过自动化测试来验证,增加对应的用例来覆盖增加的代码逻辑。后面是具体用例。
@Test
public void should_return_T_unit_when_file_size_in_its_range() {
//given
long fileSize = 1199511627776L;
//when
String format = FileUtils.formatFileSize(fileSize);
//then
assertEquals("1.09T", format);
}
该测试用两个 i 运行结果如下图所示,从运行结果可以看出,只需要 3ms 的时间就可以完成这个功能的验证。
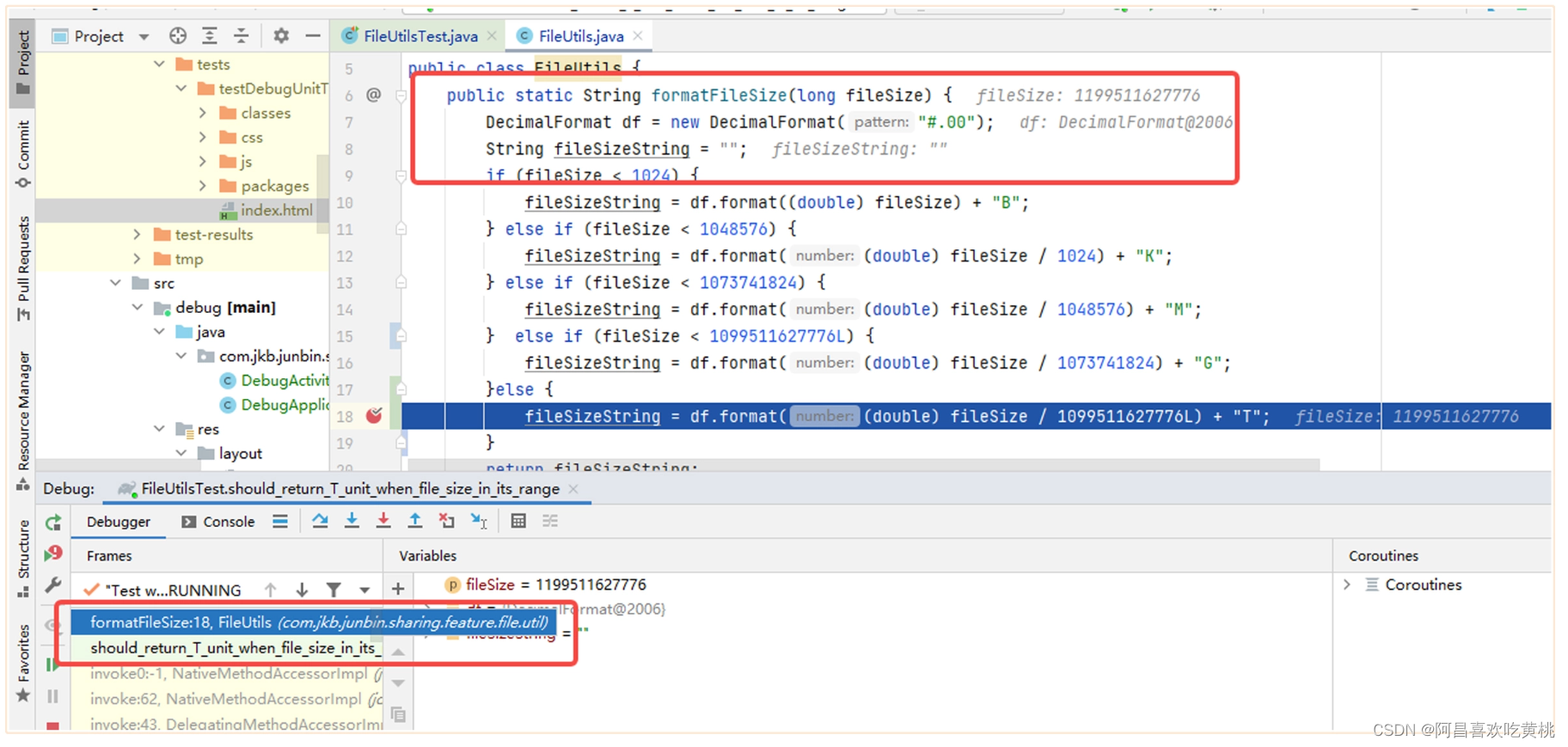
- 第二个优点是测试也支持进行 debug 断点调试,当用例运行失败时,可以通过断点查看对应的运行逻辑及数据。就像后面这样,可以在对应的被测试代码打上断点,在运行用例时选择 Debug 模式即可。
相比前面的验证方式,通过自动化验证的优点能够精确到类及方法,实现更加精准的测试,而且反馈的时间更快,通常在毫秒到秒的级别。
但缺点就是需要投入时间去设计,编写用例有一定的前期投入成本。
四、总结
3 种组件独立编译调试的方法。
传统的集成编译需要我们将所有组件一起打包进行测试验证,如果开发每次修改代码都需要进行集成验证,那么效率会比较低。
采用组件独立编译调试的方法,能够在开发阶段帮助更加高效对功能进行验证。
一张表,总结了这 3 种调试的优缺点对比,供参考:
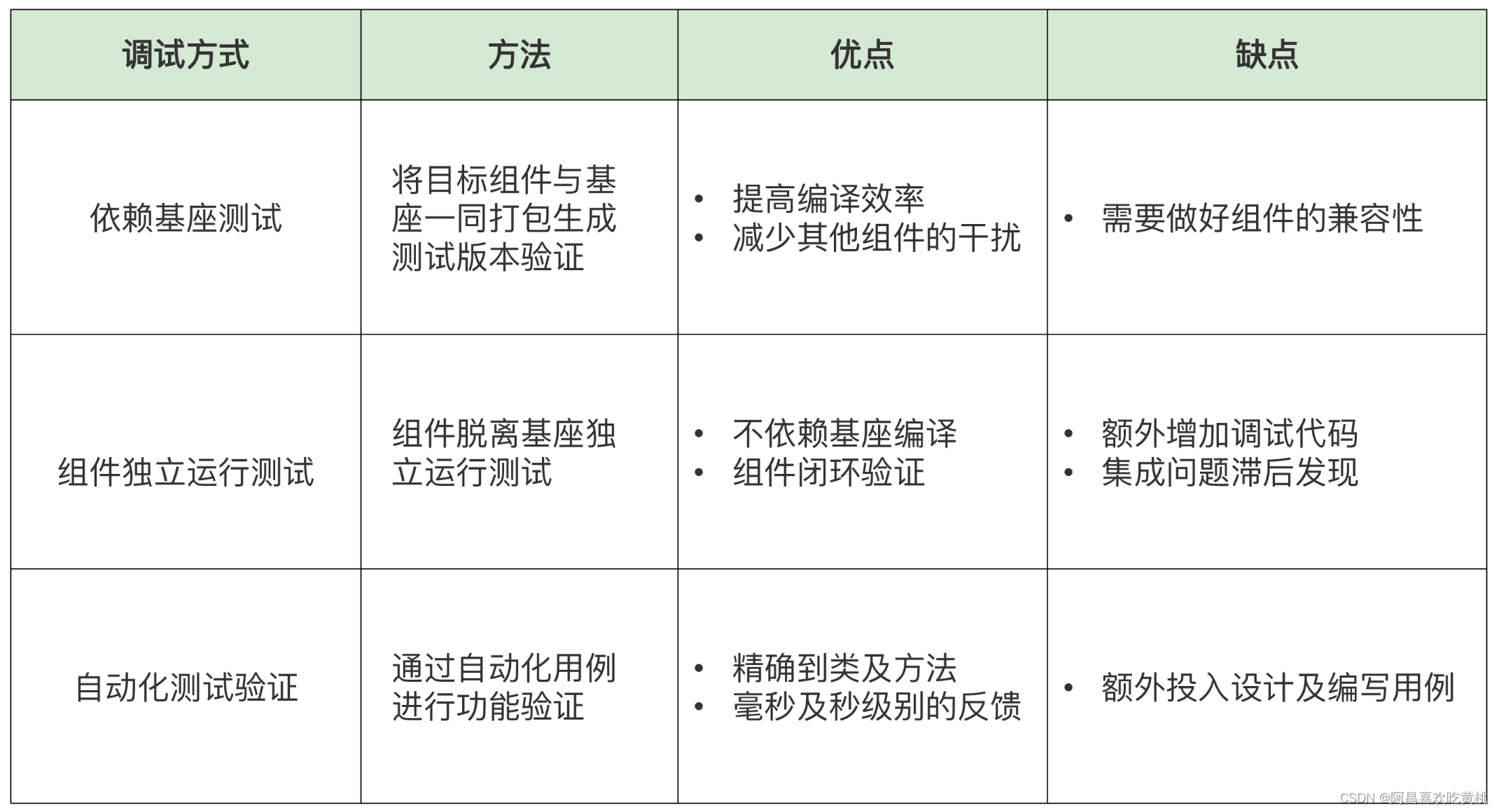
在实践中,一般在本地开发进行验证时采用组件独立编译调试的方式,但当代码提交时会有流水线来做集成的验证检查,保证最终的代码提交质量。
·





![Melis4.0[D1s]:7.lvgl添加物理按键](https://img-blog.csdnimg.cn/db6f40a87d174126897272b97f92a4de.gif#pic_center)