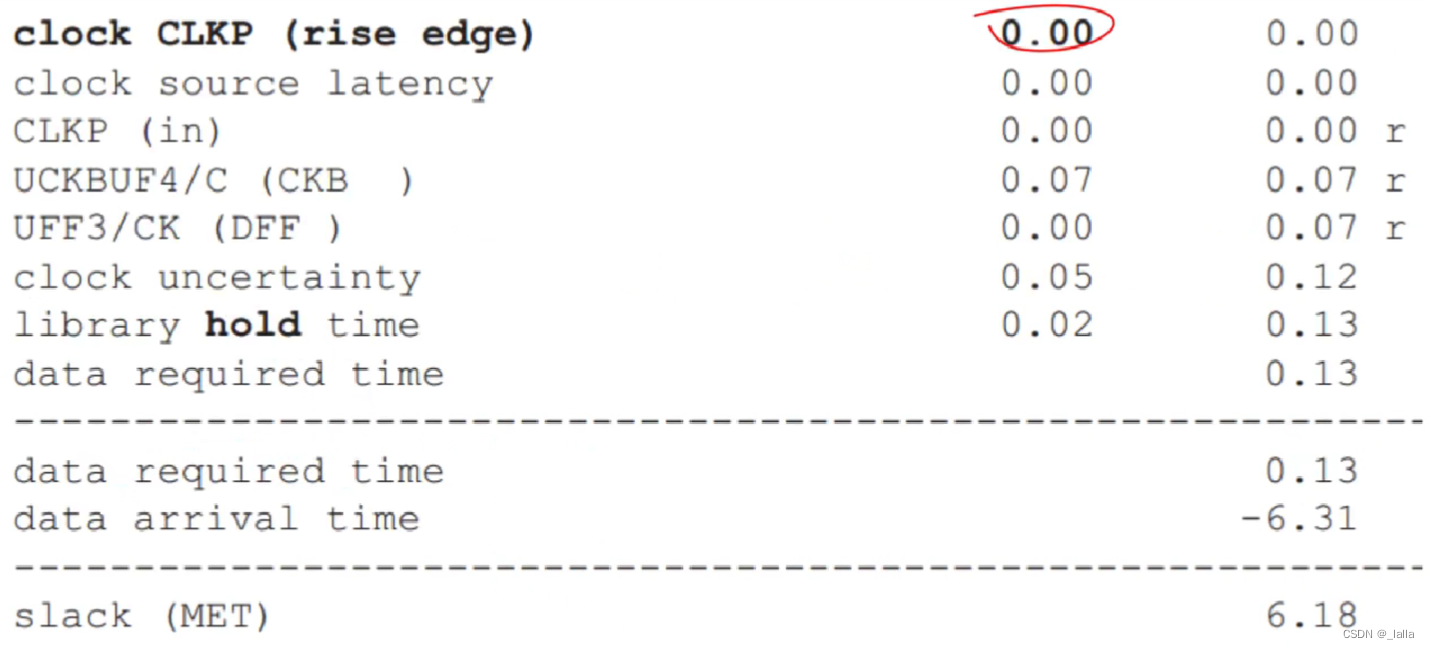
目录
- 7.1 使用语言模型生成文本
- 7.1.1 使用 RNN 生成文本的步骤
- 7.1.2 文本生成的实现
- 7.1.3 更好的文本生成
- 7.2 seq2seq 模型
- 7.2.1 seq2seq 的原理
- 7.2.2 时序数据转换的简单尝试
- 7.2.3 可变长度的时序数据
- 7.2.4 加法数据集
- 7.3 seq2seq 的实现
- 7.3.1 Encoder类
- 7.3.2 Decoder类
- 7.3.3 Seq2seq类
- 7.3.4 seq2seq的评价
- 7.4 seq2seq的改进
- 7.4.1 反转输入数据(Reverse)
- 7.4.2 偷窥(Peeky)
- 7.5 seq2seq的应用
- 7.5.1 聊天机器人
- 7.5.2 算法学习
- 7.5.3 自动图像描述
在第 5 章和第 6 章中,我们仔细研究了 RNN 和 LSTM 的结构及其实现。现在我们已经在代码层面理解了它们。
首先,本章将使用语言模型进行文本生成。具体来说,就是使用在语料库上训练好的语言模型生成新的文本。然后,我们将了解如何使用改进过的语言模型生成更加自然的文本。通过这项工作,我们可以(简单地)体验基于 AI 的文本创作。
另外,本章还会介绍一种结构名为 seq2seq 的新神经网络。seq2seq 是 “(from) sequence to sequence”(从时序到时序)的意思,即将一个时序数据转换为另一个时序数据。本章我们将看到,通过组合两个 RNN,可以轻松实现 seq2seq。seq2seq 可以应用于多个应用,比如机器翻译、聊天机器人和邮件自动回复等。通过理解这个简单但聪明强大的 seq2seq,应用深度学习的可能性将进一步扩大。
7.1 使用语言模型生成文本
7.1.1 使用 RNN 生成文本的步骤
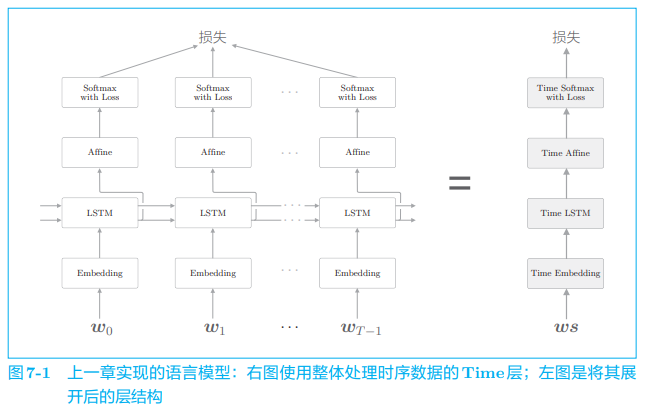
在上一章中,我们使用 LSTM 层实现了语言模型,这个语言模型的网络结构如图 7-1 所示。顺便说一下,我们还实现了整体处理(T 个)时序数据的 Time LSTM 层和 Time Affine 层。
现在我们来说明一下语言模型生成文本的顺序。这里仍以 “you say goobye and i say hello.” 这一在语料库上学习好的语言模型为例,考虑将单词 i i i 赋给这个语言模型的情况。此时,这个语言模型输出图 7-2 中的概率分布。
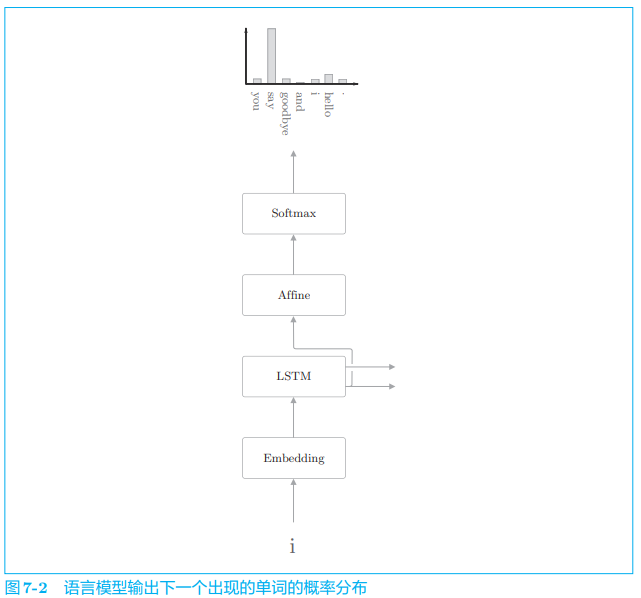
语言模型根据已经出现的单词输出下一个出现的单词的概率分布。在图 7-2 的例子中,语言模型输出了当给定单词 i i i 时下一个出现的单词的概率分布。那么,它如何生成下一个新单词呢?
一种可能的方法是选择概率最高的单词。在这种情况下,因为选择的是概率最高的单词,所以结果能唯一确定。也就是说,这是一种 “确定性的” 方法。另一种方法是 “概率性地” 进行选择。根据概率分布进行选择,这样概率高的单词容易被选到,概率低的单词难以被选到。在这种情况下,被选到的单词(被采样到的单词)每次都不一样。
这里我们想让每次生成的文本有所不同,这样一来,生成的文本富有变化,会更有趣。因此,我们通过后一种方法(概率性地选择的方法)来选择单词。回到我们的例子中,如图 7-3 所示,假设(概率性地)选择了单词 say。
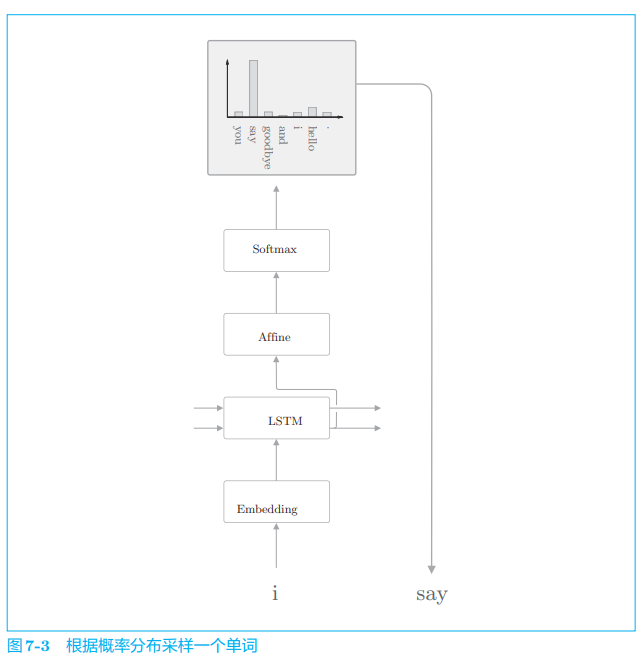
图 7-3 中显示了根据概率分布进行采样后结果为 say 的例子。在图 7-3 的概率分布中,say 的概率最高,所以它被采样到的概率也最高。不过请注意,这里选到 say 并不是必然的(不是确定性的),而是概率性的。因此,say 以外的其他单词根据出现的概率也可能被采样到。
“确定性的” 是指(算法的)结果是唯一确定的,是可预测的。在上例中, 假设选择概率最高的单词,那么这就是一种确定性的算法。而 “概率性的” 算法则概率性地确定结果,因此每次实验时选到的单词都会有所变化(或者说,存在变化的可能性)。
接下来,采样第 2 个单词。这只需要重复一下刚才的操作。也就是说,将生成的单词 say 输入语言模型,获得单词的概率分布,然后再根据这个概率分布采样下一个出现的单词,如图 7-4 所示。
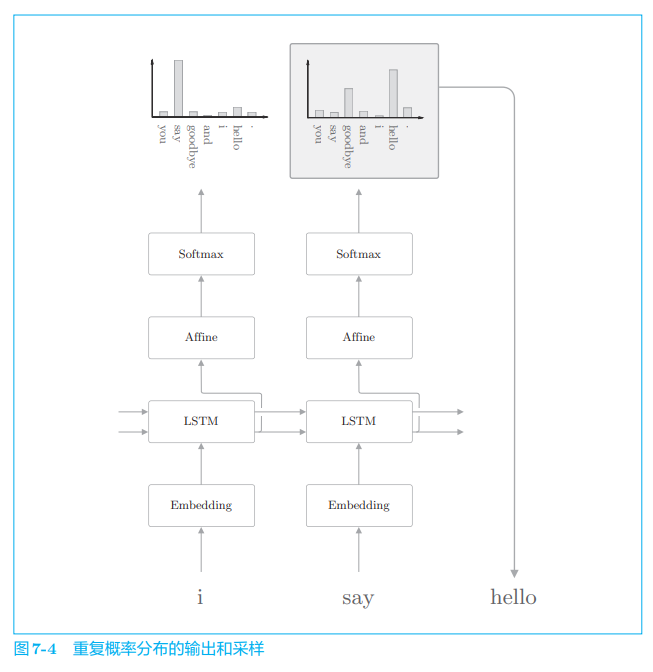
之后根据需要重复此过程即可(或者直到出现 < e o s > <eos> <eos> 这一结尾记号)。这样一来,我们就可以生成新的文本。这里需要注意的是,像上面这样生成的新文本是训练数据中没有的新生成的文本。因为语言模型并不是背诵了训练数据,而是学习了训练数据中单词的排列模式。如果语言模型通过语料库正确学习了单词的出现模式,我们就可以期待该语言模型生成的文本对人类而言是自然的、有意义的。
7.1.2 文本生成的实现
见书
7.1.3 更好的文本生成
如果有更好的语言模型,就可能有更好的文本。在上一章中,我们改进 了简单的 RNNLM,实现了“更好的 RNNLM”,将模型的困惑度从 136 降 至 75。现在,我们看一下这个 “更好的 RNNLM” 生成文本的能力。
其余见书
7.2 seq2seq 模型
这个世界充满了时序数据。文本数据、音频数据和视频数据都是时序数据。另外,还存在许多需要将一种时序数据转换为另一种时序数据的任务, 比如机器翻译、语音识别等。其他的还有进行对话的聊天机器人应用、将源代码转为机器语言的编译器等。
像这样,世界上存在许多输入输出均为时序数据的任务。从现在开始, 我们会考察将时序数据转换为其他时序数据的模型。作为它的实现方法,我 们将介绍使用两个 RNN 的 seq2seq 模型。
7.2.1 seq2seq 的原理
seq2seq 模型也称为 Encoder-Decoder 模型。顾名思义,这个模型有两个模块——Encoder(编码器)和 Decoder(解码器)。编码器对输入数据进行编码,解码器对被编码的数据进行解码。
现在,我们举一个具体的例子来说明 seq2seq 的机制。这里考虑将日语翻译为英语,比如将 “吾輩は猫である” 翻译为 “I am a cat”。此时,如图 7-5 所示,seq2seq 基于编码器和解码器进行时序数据的转换。
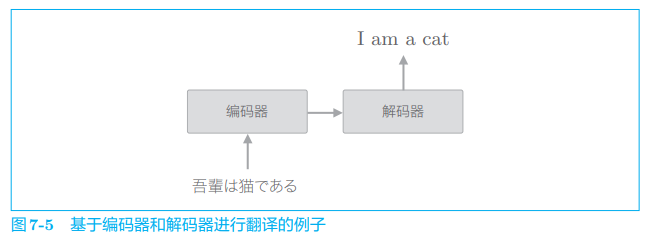
如图 7-5 所示,编码器首先对 “吾輩は猫である” 这句话进行编码,然后将编码好的信息传递给解码器,由解码器生成目标文本。此时,编码器编码的信息浓缩了翻译所必需的信息,解码器基于这个浓缩的信息生成目标文本。
以上就是 seq2seq 的全貌图。编码器和解码器协作,将一个时序数据转换为另一个时序数据。另外,在这些编码器和解码器内部可以使用 RNN。 下面我们来看一下细节。首先来看编码器,它的层结构如图 7-6 所示。
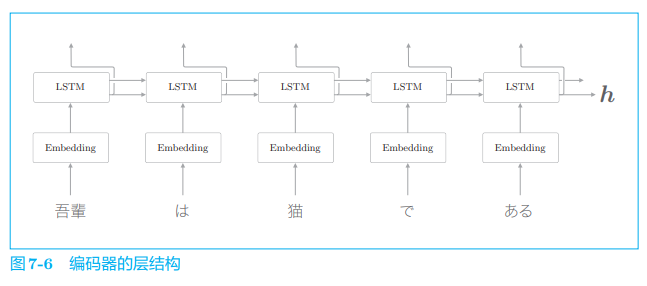
由图 7-6 可以看出,编码器利用 RNN 将时序数据转换为隐藏状态 h h h。 这里的RNN使用的是 LSTM,不过也可以使用 “简单RNN” 或者GRU等。 另外,这里考虑的是将日语句子分割为单词进行输入的情况。
图 7-6 的编码器输出的向量 h h h 是 LSTM 层的最后一个隐藏状态,其中编码了翻译输入文本所需的信息。这里的重点是,LSTM 的隐藏状态 h h h 是 一个固定长度的向量。说到底,编码就是将任意长度的文本转换为一个固定长度的向量(图 7-7)。
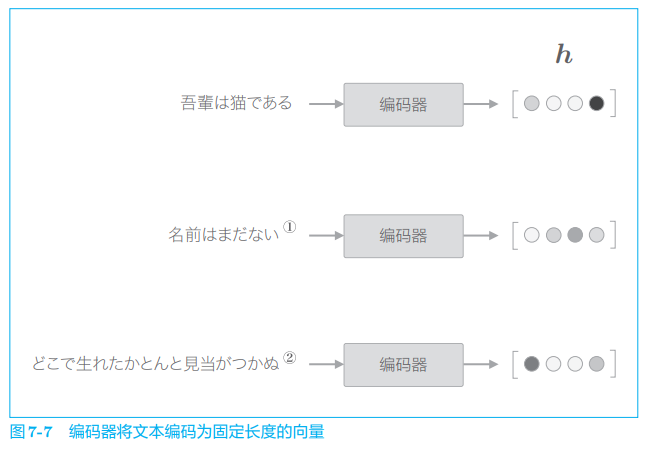
如图 7-7 所示,编码器将文本转换为固定长度的向量。那么,解码器是如何 “处理” 这个编码好的向量,从而生成目标文本的呢?其实,我们已经知道答案了。因为我们只需要直接使用上一节讨论的进行文本生成的模型即可,如图 7-8 所示。
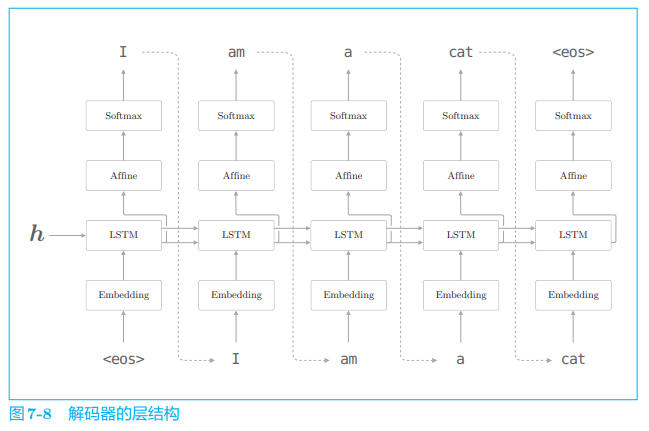
从图 7-8 中可以看出,解码器的结构和上一节的神经网络完全相同。 不过它和上一节的模型存在一点差异,就是 LSTM 层会接收向量 h。在上一节的语言模型中,LSTM 层不接收任何信息(硬要说的话,也可以说 LSTM 的隐藏状态接收 “0 向量” )。这个唯一的、微小的改变使得普通的语言模型进化为可以驾驭翻译的解码器。
图 7-8 中使用了 < e o s > <eos> <eos> 这一分隔符(特殊符号)。这个分隔符被用作通知解码器开始生成文本的信号。另外,解码器采样到出现 < e o s > <eos> <eos> 为止,所以它也是结束信号。也就是说,分隔符可以用来指示解码器的 “开始 / 结束”。在其他文献中,也有使用 、 或者 “_”(下划线)作为分隔符的例子。
现在我们连接编码器和解码器,并给出它的层结构,具体如图 7-9 所示。
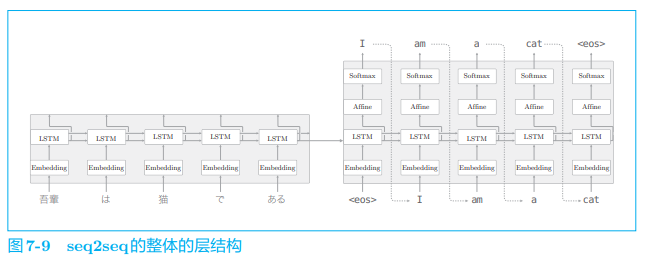
如图 7-9 所示,seq2seq 由两个 LSTM 层构成,即编码器的 LSTM 和 解码器的 LSTM。此时,LSTM 层的隐藏状态是编码器和解码器的 “桥梁”。 在正向传播时,编码器的编码信息通过 LSTM 层的隐藏状态传递给解码器; 在反向传播时,解码器的梯度通过这个 “桥梁” 传递给编码器。
7.2.2 时序数据转换的简单尝试
下面我们来实现 seq2seq,不过在此之前,首先说明一下我们要处理的问题。这里我们将 “加法” 视为一个时序转换问题。具体来说,如图 7-10 所示,在 seq2seq 学习后,如果输入字符串 “57 + 5”,seq2seq 要能正确回答 “62”。顺便说一下,这种为了评价机器学习而创建的简单问题,称为 “toy problem”。
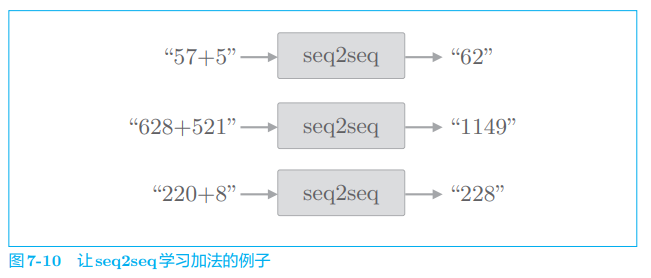
在我们看来,这里做的加法运算是非常简单的问题,但是 seq2seq 对加法(更确切地说是加法的逻辑)一无所知。seq2seq 从加法的例子(样本) 中学习出现的字符模式,这样真的可以学习到加法运算的规则吗?这正是本次实验的看头。
顺便说一下,在之前的 word2vec 和语言模型中,我们都把文本以单词为单位进行了分割,但并非必须这样做。对于本节的这个问题,我们将不以单词为单位,而是以字符为单位进行分割。在以字符为单位进行分割的情况 下,“57 + 5” 这样的输入会被处理为 [‘5’, ‘7’, ‘+’, ‘5’] 这样的列表。
7.2.3 可变长度的时序数据
我们将 “加法” 视为字符(数字)列表。这里需要注意的是,不同的加法问题(“57 + 5” 或者 “628 + 521” 等)及其回答(“62” 或者 “1149” 等) 的字符数是不同的。比如,“57 + 5” 共有 4 个字符,而 “628 + 521” 共有 7 个字符。
如此,在加法问题中,每个样本在时间方向上的大小不同。也就是说,加法问题处理的是可变长度的时序数据。因此,在神经网络的学习中,在进行 mini-batch 处理时,需要想一些应对办法。
在使用批数据进行学习时,会一起处理多个样本。此时,(在我们的 实现中)需要保证一个批次内各个样本的数据形状是一致的。
在基于 mini-batch 学习可变长度的时序数据时,最简单的方法是使用填充(padding)。所谓填充,就是用无效(无意义)数据填入原始数据,从而使数据长度对齐。就上面这个加法的例子来说,如图 7-11 所示,在多余位置插入无效字符(这里是空白字符),从而使所有输入数据的长度对齐。
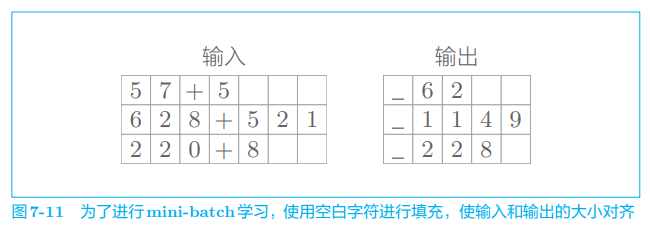
本次的问题处理的是 0 ∼ 999 0 \sim 999 0∼999 的两个数的加法。因此,包括 “+” 在内,输入的最大字符数是 7 7 7。另外,加法的结果最大是 4 4 4 个字符(最大为 “999 + 999 = 1998” )。因此,对监督数据也进行类似的填充,从而对齐所有样本数据的长度。另外,在本次的问题中,在输出的开始处加上了分隔符 “_”(下划线),使得输出数据的字符数统一为 5。这个分隔符作为通知解码器开始生成文本的信号使用。
对于解码器的输出,可以在监督标签中插入表示字符输出结束的分隔符(比如 “ _ 62 _ \_ 62\_ _62_” 或 “ _ 1149 _ \_ 1149 \_ _1149_” )。但是,简单起见,这里我们不使用表示字符输出结束的分隔符。也就是说,在解码器生成字符串时,始终输出固定数量的字符(这里是包括开始处的 “_” 在内的 5 个字符)
像这样,通过填充对齐数据的大小,可以处理可变长度的时序数据。但是,因为使用了填充,seq2seq 需要处理原本不存在的填充用字符,所以如果追求严谨,使用填充时需要向 seq2seq 添加一些填充专用的处理。比如,在解码器中输入填充时,不应计算其损失(这可以通过向 Softmax with Loss 层添加 mask 功能来解决)。再比如,在编码器中输入填充时,LSTM 层应按原样输出上一时刻的输入。这样一来,LSTM 层就可以像不存在填充一样对输入数据进行编码。
7.2.4 加法数据集
见书
7.3 seq2seq 的实现
seq2seq 是组合了两个 RNN 的神经网络。这里我们首先将这两个 RNN 实现为 Encoder 类和 Decoder 类,然后将这两个类组合起来,来实现 seq2seq 类。
7.3.1 Encoder类
见书
7.3.2 Decoder类
见书
7.3.3 Seq2seq类
见书
7.3.4 seq2seq的评价
正确率(正确回答了多少问题),具体来说,就是针对每个 epoch 对正确回答了测试数据中的多少问题进行统计。
实现见书
7.4 seq2seq的改进
7.4.1 反转输入数据(Reverse)
第一个改进方案是非常简单的技巧。如图 7-23 所示,反转输入数据的 顺序。
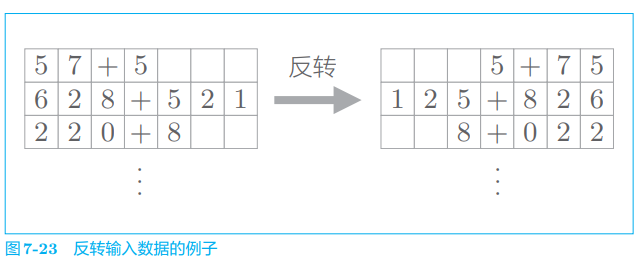
据研究,在许多情况 下,使用这个技巧后,学习进展得更快,最终的精度也有提高。
实现见书
为什么反转数据后,学习进展变快,精度提高了呢?虽然理论上不是很清楚,但是直观上可以认为,反转数据后梯度的传播可以更平滑。比如,考虑将“吾輩 は 猫 で ある” 翻译成 “I am a cat” 这一问题,单词 “吾輩” 和单词 “I” 之间有转换关系。此时,从 “吾輩” 到 “I” 的路程必须经过 “は” “猫” “で” “ある” 这 4 个单词的 LSTM 层。因此,在反向传播时, 梯度从 “I” 抵达 “吾輩”,也要受到这个距离的影响。
那么,如果反转输入语句,也就是变为 “あるで猫は吾輩”,结果 会怎样呢?此时,“吾輩” 和 “I” 彼此相邻,梯度可以直接传递。如此,因 为通过反转,输入语句的开始部分和对应的转换后的单词之间的距离变近 (这样的情况变多),所以梯度的传播变得更容易,学习效率也更高。不过,在反转输入数据后,单词之间的 “平均” 距离并不会发生改变。
7.4.2 偷窥(Peeky)
如前所述,编码器将输入语句转换为固定长度的向量 h h h,这个 h h h 集中了解码器所需的全部信息。也就是说,它是解码器唯一的信息源。但 是,如图 7-25 所示,当前的 seq2seq 只有最开始时刻的 LSTM 层利用了 h h h。 我们能更加充分地利用这个 h 吗?
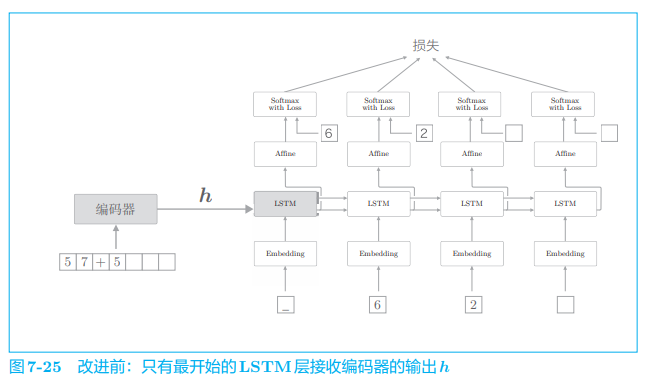
为了达成该目标,seq2seq 的第二个改进方案就应运而生了。具体来说,就是将这个集中了重要信息的编码器的输出 h h h 分配给解码器的其他层。我们的解码器可以考虑图 7-26 中的网络结构。
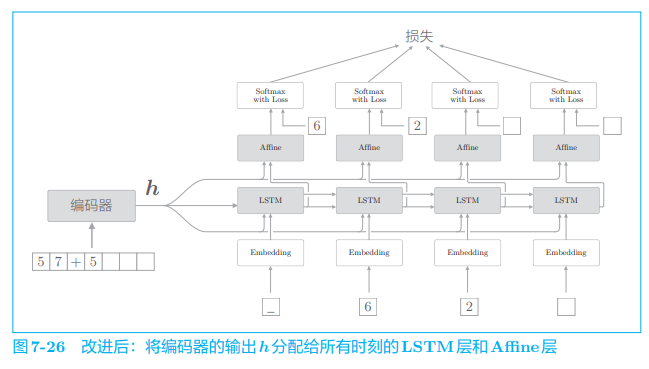
如图 7-26 所示,将编码器的输出 h h h 分配给所有时刻的 Affine 层和 LSTM 层。比较图 7-26 和图 7-25 可知,之前 LSTM 层专用的重要信息 h h h 现在在多个层(在这个例子中有 8 个层)中共享了。重要的信息不是一个人专有,而是多人共享,这样我们或许可以做出更加正确的判断。
这里的改进是将编码好的信息分配给解码器的其他层,这可以解释为其他层也能 “偷窥” 到编码信息。因为 “偷窥” 的英语是 peek,所 以将这个改进了的解码器称为 Peeky Decoder。同理,将使用了 Peeky Decoder 的 seq2seq 称为 Peeky seq2seq。
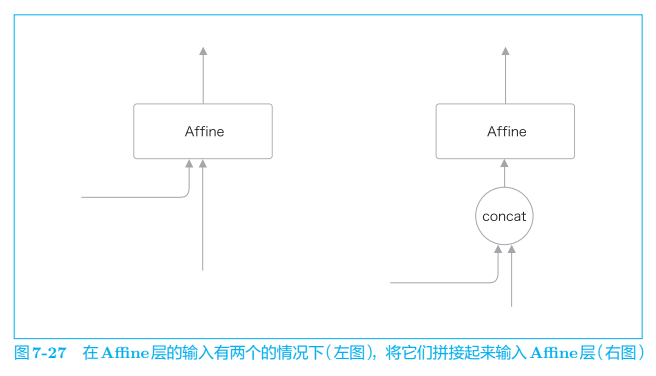
在图 7-26 中,有两个向量同时被输入到了 LSTM 层和 Affine 层,这实际上表示两个向量的拼接(concatenate)。因此,在刚才的图中,如果使用 concat 节点拼接两个向量,则正确的计算图可以绘制成图 7-27。
代码实现见书。
7.5 seq2seq的应用
seq2seq 将某个时序数据转换为另一个时序数据,这个转换时序数据的框架可以应用在各种各样的任务中,比如以下几个例子。
- 机器翻译:将 “一种语言的文本” 转换为 “另一种语言的文本”
- 自动摘要:将 “一个长文本” 转换为 “短摘要”
- 问答系统:将 “问题” 转换为 “答案”
- 邮件自动回复:将 “接收到的邮件文本” 转换为 “回复文本”
像这样,seq2seq 可以用于处理成对的时序数据的问题。除了自然语言之外,也可以用于语音、视频等数据。有些乍一看不属于 seq2seq 的问题,通过对输入输出数据进行预处理,也可以应用 seq2seq。本节将介绍几个使 用 seq2seq 的应用。如果读者能由此感受到 seq2seq 的潜力和乐趣,那就再好不过了。
7.5.1 聊天机器人
见书
7.5.2 算法学习
见书
7.5.3 自动图像描述
见书