虽然了解了整个内存池管理的细节,包括它的内存分配的具体逻辑,但是每次从NioSocketChannel中读取数据时,应该分配多少内存去读呢? 例如,客户端发送的数据为1KB , 应该分配多少内存去读呢? 例如: 客户端发送的数据为1KB , 若每次都分配8KB的内存去读取数据,则会导致内存大量浪费,若分配16B的内存去读取数据,那么需要64次才能全部读完, 对性能的有很大的影响 , 那么对于 这个问题,Netty是如何解决的呢?
NioEventLoop线程在处理OP_READ事件,进入NioByteUnsafe循环读取数据时,使用了两个类来处理内存的分配,一个是ByteBufAllocator, PooledByteBufAllocator为它的默认实现类, 另一个是RecvByteBufAllocator,AdaptiveRecvByteBufAllocator是它的默认实现类,在DefaultChannelConfig初始化时设置 , PooledByteBufAllocator主要用来处理内存分配,并最终委托PoolArena去完成,AdaptiveRecvByteBufAllocator主要用来计算每次读循环时应该分配多少内存,NioByteUnsafe之所有需要循环读取,主要是因为分配的初始ByteBuf不一定能够容纳读取到的所有数据,NioByteUnsafe循环读取的核心代码解读如下 :
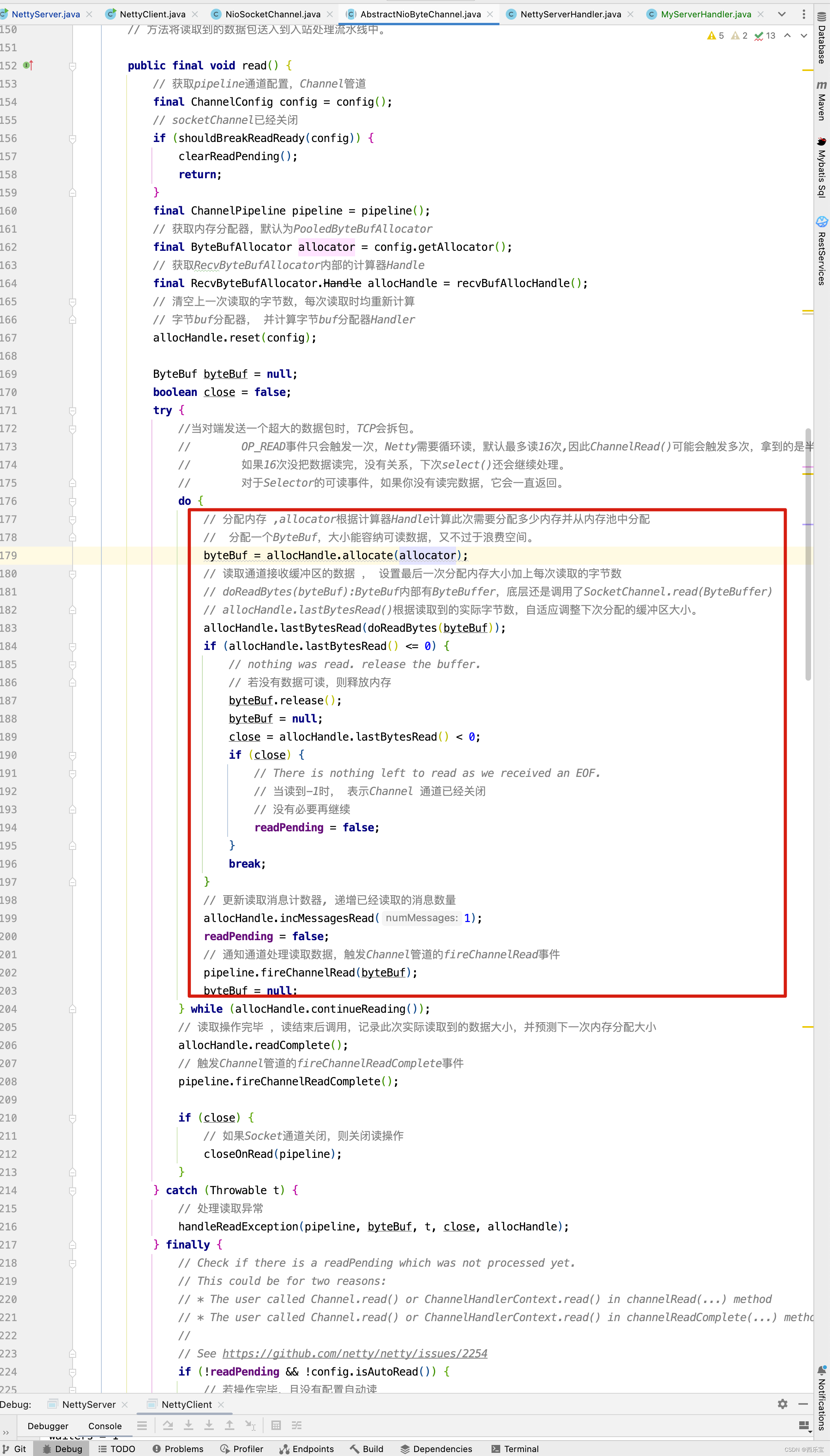
public final void read() {
// 获取pipeline通道配置,Channel管道
final ChannelConfig config = config();
// socketChannel已经关闭
if (shouldBreakReadReady(config)) {
clearReadPending();
return;
}
final ChannelPipeline pipeline = pipeline();
// 获取内存分配器,默认为PooledByteBufAllocator
final ByteBufAllocator allocator = config.getAllocator();
// 获取RecvByteBufAllocator内部的计算器Handle
final RecvByteBufAllocator.Handle allocHandle = recvBufAllocHandle();
// 清空上一次读取的字节数,每次读取时均重新计算
// 字节buf分配器, 并计算字节buf分配器Handler
allocHandle.reset(config);
ByteBuf byteBuf = null;
boolean close = false;
try {
//当对端发送一个超大的数据包时,TCP会拆包。
// OP_READ事件只会触发一次,Netty需要循环读,默认最多读16次,因此ChannelRead()可能会触发多次,拿到的是半包数据。
// 如果16次没把数据读完,没有关系,下次select()还会继续处理。
// 对于Selector的可读事件,如果你没有读完数据,它会一直返回。
do {
// 分配内存 ,allocator根据计算器Handle计算此次需要分配多少内存并从内存池中分配
// 分配一个ByteBuf,大小能容纳可读数据,又不过于浪费空间。
byteBuf = allocHandle.allocate(allocator);
// 读取通道接收缓冲区的数据 , 设置最后一次分配内存大小加上每次读取的字节数
// doReadBytes(byteBuf):ByteBuf内部有ByteBuffer,底层还是调用了SocketChannel.read(ByteBuffer)
// allocHandle.lastBytesRead()根据读取到的实际字节数,自适应调整下次分配的缓冲区大小。
allocHandle.lastBytesRead(doReadBytes(byteBuf));
if (allocHandle.lastBytesRead() <= 0) {
// nothing was read. release the buffer.
// 若没有数据可读,则释放内存
byteBuf.release();
byteBuf = null;
close = allocHandle.lastBytesRead() < 0;
if (close) {
// There is nothing left to read as we received an EOF.
// 当读到-1时, 表示Channel 通道已经关闭
// 没有必要再继续
readPending = false;
}
break;
}
// 更新读取消息计数器, 递增已经读取的消息数量
allocHandle.incMessagesRead(1);
readPending = false;
// 通知通道处理读取数据,触发Channel管道的fireChannelRead事件
pipeline.fireChannelRead(byteBuf);
byteBuf = null;
} while (allocHandle.continueReading());
// 读取操作完毕 ,读结束后调用,记录此次实际读取到的数据大小,并预测下一次内存分配大小
allocHandle.readComplete();
// 触发Channel管道的fireChannelReadComplete事件
pipeline.fireChannelReadComplete();
if (close) {
// 如果Socket通道关闭,则关闭读操作
closeOnRead(pipeline);
}
} catch (Throwable t) {
// 处理读取异常
handleReadException(pipeline, byteBuf, t, close, allocHandle);
} finally {
// Check if there is a readPending which was not processed yet.
// This could be for two reasons:
// * The user called Channel.read() or ChannelHandlerContext.read() in channelRead(...) method
// * The user called Channel.read() or ChannelHandlerContext.read() in channelReadComplete(...) method
//
// See https://github.com/netty/netty/issues/2254
if (!readPending && !config.isAutoRead()) {
// 若操作完毕,且没有配置自动读
// 则从选择Key兴趣集中移除读操作事件
removeReadOp();
}
}
}
}
每一次创建byteBuf分配内存大小是多大呢? 这个由allocate()方法内部的guess()方法来决定 。
public ByteBuf allocate(ByteBufAllocator alloc) {
return alloc.ioBuffer(guess());
}
如果是第一次 调用guess()方法,默认分配1024B的内存空间 ,后面分配内存大小动态调节 。
// 实现doReadBytes()方法,从SocketChannel中读取数据。
protected int doReadBytes(ByteBuf byteBuf) throws Exception {
// 获取计算内存分配器Handle
final RecvByteBufAllocator.Handle allocHandle = unsafe().recvBufAllocHandle();
// 设置尝试读取字节数组的buf的可写字节数
allocHandle.attemptedBytesRead(byteBuf.writableBytes());
// 从Channel中读取字节并写入到buf中,返回读取的字节数
return byteBuf.writeBytes(javaChannel(), allocHandle.attemptedBytesRead());
}
在这里,我们需要明白byteBuf.writableBytes()这个方法,writableBytes()方法的返回值为byteBuf中可写的字节数,内部计算方法用byteBuf的容量- byteBuf的写索引得出,而byteBuf.writeBytes(javaChannel(), allocHandle.attemptedBytesRead());这一行代码,实际上就是将Channel中的数据写入到byteBuf中,返回值为实际写入到ByteBuf中的字节数。
RecvByteBufAllocator的默认实现类AdaptiveRecvByteBufAllocator是实际的缓冲管理区,这个类可以根据读取到的数据预测所需要的字节的多少,从而自动增加或减少,如果上一次读循环将缓冲区的写满了,那么预测的字节数会变大,如果连续两次循环都不能填满已经分配的缓冲区,则预测字节数会变小。
public void lastBytesRead(int bytes) {
// If we read as much as we asked for we should check if we need to ramp up the size of our next guess.
// This helps adjust more quickly when large amounts of data is pending and can avoid going back to
// the selector to check for more data. Going back to the selector can add significant latency for large
// data transfers.
// 如果上 一次读循环将缓冲区填充满了,那么预测的字节数会变大
if (bytes == attemptedBytesRead()) {
// 如果此次读取将缓冲区填充满了,增加一次记录的机会
record(bytes);
}
super.lastBytesRead(bytes);
}
// 该方法的参数是一次读取操作中实际读取到的数据大小,将其与nextReceiveBufferSize 进行比较,如果实际字节数actualReadBytes大于等于该值,则立即更新nextReceiveBufferSize ,
// 其更新后的值与INDEX_INCREMENT有关。INDEX_INCREMENT为默认常量,值为4。也就是说在扩容时会一次性增大多一些,以保证下次有足够空间可以接收数据。而相对扩容的策略,
// 缩容策略则实际保守些,常量为INDEX_INCREMENT,值为1,同样也是进行对比, 但不同的是,若实际字节小于所用nextReceiveBufferSize,并不会立马进行大小调整,
// 而是先把 decreaseNow 设置为true,如果下次仍然小于,则才会减少nextReceiveBufferSize的大小
private void record(int actualReadBytes) {
// 如果小了两个数量级,则需要缩容
if (actualReadBytes <= SIZE_TABLE[max(0, index - INDEX_DECREMENT - 1)]) {
if (decreaseNow) { // 若减少标识decreaseNow连续两次为true, 则说明下次读取字节数需要减少SIZE_TABLE下标减1
index = max(index - INDEX_DECREMENT, minIndex);
nextReceiveBufferSize = SIZE_TABLE[index];
decreaseNow = false;
} else {
decreaseNow = true; // 第一次减少,只做记录
}
} else if (actualReadBytes >= nextReceiveBufferSize) { // 实际读取的字节大小要大于或等于预测值
index = min(index + INDEX_INCREMENT, maxIndex); // SIZE_TABLE 下标 + 4
nextReceiveBufferSize = SIZE_TABLE[index]; // 若当前缓存为512,则变成 512 * 2 ^ 4
decreaseNow = false;
}
}
public void lastBytesRead(int bytes) {
// 设置最后读取的字节数
lastBytesRead = bytes;
if (bytes > 0) {
// 总读取的字节数
totalBytesRead += bytes;
}
}
上述过程中,SIZE_TABLE是什么呢? 请看AdaptiveRecvByteBufAllocator源码实现。
public class AdaptiveRecvByteBufAllocator extends DefaultMaxMessagesRecvByteBufAllocator {
static final int DEFAULT_MINIMUM = 64; // 接收缓冲区的最小长度下限
static final int DEFAULT_INITIAL = 1024; // 接收缓冲区的最大长度上限
static final int DEFAULT_MAXIMUM = 65536; // 接收缓冲区最大长度上限
// 在调整缓冲区大小时,若是增加缓冲区容量,那么增加的索引值。
// 比如,当前缓冲区的大小为SIZE_TABLE[20],若预测下次需要创建的缓冲区需要增加容量大小,
// 则新缓冲区的大小为SIZE_TABLE[20 + INDEX_INCREMENT],即SIZE_TABLE[24]
private static final int INDEX_INCREMENT = 4; // 扩容增长量
// 在调整缓冲区大小时,若是减少缓冲区容量,那么减少的索引值。
// 比如,当前缓冲区的大小为SIZE_TABLE[20],若预测下次需要创建的缓冲区需要减小容量大小,
// 则新缓冲区的大小为SIZE_TABLE[20 - INDEX_DECREMENT],即SIZE_TABLE[19]
private static final int INDEX_DECREMENT = 1; // 扩容减少量
private static final int[] SIZE_TABLE;
// 分配了一个int类型的数组,并进行了数组的初始化处理, 从实现来看,该数组的长度是53,前32位是16的倍数,value值是从16开始的,到512,从33位开始,值是前一位的
// 两倍,即从1024,2048 , 到最大值 1073741824 。
static {
List<Integer> sizeTable = new ArrayList<Integer>();
for (int i = 16; i < 512; i += 16) {
sizeTable.add(i);
}
for (int i = 512; i > 0; i <<= 1) {
sizeTable.add(i);
}
SIZE_TABLE = new int[sizeTable.size()];
for (int i = 0; i < SIZE_TABLE.length; i++) {
SIZE_TABLE[i] = sizeTable.get(i);
}
System.out.println("================");
}
/**
* @deprecated There is state for {@link #maxMessagesPerRead()} which is typically based upon channel type.
*/
public static final AdaptiveRecvByteBufAllocator DEFAULT = new AdaptiveRecvByteBufAllocator();
// 入参是一个大小,然后利用二分查找法对该数组进行size定位 ,目标是为了找出该size值在数组中的下标位置 , 主要是为了初始化maxIndex, maxIndex这两个参数
private static int getSizeTableIndex(final int size) {
for (int low = 0, high = SIZE_TABLE.length - 1; ; ) {
if (high < low) {
return low;
}
if (high == low) {
return high;
}
int mid = low + high >>> 1;
int a = SIZE_TABLE[mid];
int b = SIZE_TABLE[mid + 1];
if (size > b) {
low = mid + 1;
} else if (size < a) {
high = mid - 1;
} else if (size == a) {
return mid;
} else {
return mid + 1;
}
}
}
private final int minIndex;
private final int maxIndex;
private final int initial;
/**
* Creates a new predictor with the default parameters. With the default
* parameters, the expected buffer size starts from {@code 1024}, does not
* go down below {@code 64}, and does not go up above {@code 65536}.
*/
public AdaptiveRecvByteBufAllocator() {
this(DEFAULT_MINIMUM, DEFAULT_INITIAL, DEFAULT_MAXIMUM);
}
/**
* Creates a new predictor with the specified parameters.
* @param minimum the inclusive lower bound of the expected buffer size
* @param initial the initial buffer size when no feed back was received
* @param maximum the inclusive upper bound of the expected buffer size
*/
public AdaptiveRecvByteBufAllocator(int minimum, int initial, int maximum) {
checkPositive(minimum, "minimum");
if (initial < minimum) {
throw new IllegalArgumentException("initial: " + initial);
}
if (maximum < initial) {
throw new IllegalArgumentException("maximum: " + maximum);
}
int minIndex = getSizeTableIndex(minimum);
if (SIZE_TABLE[minIndex] < minimum) {
this.minIndex = minIndex + 1;
} else {
this.minIndex = minIndex;
}
int maxIndex = getSizeTableIndex(maximum);
if (SIZE_TABLE[maxIndex] > maximum) {
this.maxIndex = maxIndex - 1;
} else {
this.maxIndex = maxIndex;
}
this.initial = initial;
}
@Override
public Handle newHandle() {
return new HandleImpl(minIndex, maxIndex, initial);
}
@Override
public AdaptiveRecvByteBufAllocator respectMaybeMoreData(boolean respectMaybeMoreData) {
super.respectMaybeMoreData(respectMaybeMoreData);
return this;
}
}
SIZE_TABLE由上述加粗代码进行初始化 。 AdaptiveRecvByteBufAllocator内部维护了一个SIZE_TABLE数组,记录了不同的内存的内存块大小,按照分配需要寻找最合适的内存块,SIZE_TABLE数组中的值为2^n,这样便于软硬件进行处理,SIZE_TABLE数组的初始化与PoolArena中的normalizeCapacity的初始化类似,当需要的内存很小时 , 增长的幅度不大, 当需要的内存较大时, 增长的幅度比较大,因此在[16,512]区间每次增加16,直到512,而从512起,每次翻一倍, 直到int的最大值 。 那size的具体大小值是什么呢?
SIZE_TABLE 数组的toString()打印如下 :
[16B, 32B, 48B, 64B, 80B, 96B, 112B, 128B, 144B, 160B, 176B, 192B, 208B, 224B, 240B, 256B, 272B, 288B, 304B, 320B, 336B, 352B, 368B, 384B, 400B, 416B, 432B, 448B, 464B, 480B, 496B, 512B, 1k, 2k, 4k, 8k, 16k, 32k, 64k, 128k, 256k, 512k, 1M, 2M, 4M, 8M, 16M, 32M, 64M, 128M, 256M, 512M, 1G]
当对内部计算器Handle的具体实现类HandleImpl进行初始化时,可根据AdaptiveRecvByteBufAllocator的getSizeTableIndex()二分查找方法获取SIZE_TABLE的下标index并保存,通过SIZE_TABLE[index]获取下次需要分配的缓冲区大小nextReceiveBufferSize并记录,缓冲区的最小容量属性对SIZE_TABLE中的下标为minIndex的值 , 最大容量属性对应的SIZE_TABLE中的下标为maxIndex的值及bool类型标识属性decreaseNow ,这三个属性用于判断下一次创建缓冲区是否需要减少 。
NioByteUnsafe每次循环完成后会根据实际读取到的字节数和当前缓冲区的大小重新设置下次需要分配的缓冲区的大小。 具体代码如下 。
// 循环读取完后被调用
public void readComplete() {
record(totalBytesRead());
}
//返回已经读取的字节个数,若‘totalBytesRead < 0’则说明已经读取的字节数已经操作了’Integer.MAX_VALUE’,则返回Integer.MAX_VALUE;否则返回真实的已经读取的字节数。
protected final int totalBytesRead() {
return totalBytesRead < 0 ? Integer.MAX_VALUE : totalBytesRead;
}
可以模拟NioByteUnsafe的read()方法,在每次循环开始时, 一定要先重置totalMessages与totalByteRead(清零),读取完成后, readComplete会计算并调整下次预计需要分配的缓冲区的大小, 具体代码如下
public static void main(String[] args) throws Exception {
AdaptiveRecvByteBufAllocator allocator = new AdaptiveRecvByteBufAllocator();
RecvByteBufAllocator.Handle handle = allocator.newHandle();
System.out.println("==============开始 I/O 读事件模拟==============");
// 读取循环开始前先重置,将读取的次数和字节数设置为0, 将totalMessages与totalBytesRead设置为0
handle.reset(null);
System.out.println(String.format("第一次模拟读,需要分配大小 :%d", handle.guess()));
handle.lastBytesRead(256);
// 调整下次预测值
handle.readComplete();
// 在每次读取数据时都需要重置totalMessage 与totalBytesRead
handle.reset(null);
System.out.println(String.format("第2次花枝招展读,需要分配大小:%d ", handle.guess()));
handle.lastBytesRead(256);
handle.readComplete();
System.out.println("===============连续2次读取的字节数小于默认分配的字节数= =========================");
handle.reset(null);
System.out.println(String.format("第3次模拟读,需要分配大小 : %d", handle.guess()));
handle.lastBytesRead(512);
// 调整下次预测值,预测值应该增加到512 * 2 ^ 4
handle.readComplete();
System.out.println("==================读取的字节数变大 ===============");
handle.reset(null);
// 读循环中缓冲区的大小
System.out.println(String.format("第4次模拟读,需要分配的大小为:%d ", handle.guess()));
}
结果输出

当然啦,如果觉得自己已经很明白了,可以看看下面这个例子。
public class Test2 {
public static void main(String[] args) {
AdaptiveRecvByteBufAllocator allocator = new AdaptiveRecvByteBufAllocator();
RecvByteBufAllocator.Handle handle = allocator.newHandle();
System.out.println("==============开始 I/O 读事件模拟==============");
// 读取循环开始前先重置,将读取的次数和字节数设置为0, 将totalMessages与totalBytesRead设置为0
handle.reset(null);
System.out.println(String.format("第一次模拟读,需要分配大小 :%d", handle.guess()));
handle.lastBytesRead(512);
// 调整下次预测值
handle.readComplete();
// 在每次读取数据时都需要重置totalMessage 与totalBytesRead
handle.reset(null);
System.out.println(String.format("第2次花枝招展读,需要分配大小:%d ", handle.guess()));
handle.lastBytesRead(512);
handle.readComplete();
System.out.println("===============连续2次读取的字节数小于默认分配的字节数= =========================");
handle.reset(null);
System.out.println(String.format("第3次模拟读,需要分配大小 : %d", handle.guess()));
}
}

最后一次结果输出为1024,并没有缩容,源码读到这里,我相信对输出结果已经没有什么意外了。
接下来看一个例子。
Netty服务端代码
public class NettyServer {
public static void main(String[] args) {
// 创建两个线程组bossGroup 和workerGroup , 含有的子线程NioEventLoop 的个数默认为CPU 核数的两倍
// BossGroup只是处理连接请求,真正的和客户端业务处理,会交给workerGroup完成
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
// 创建服务端的启动对象
ServerBootstrap bootstrap = new ServerBootstrap();
// 使用链式编程来配置参数
bootstrap.group(bossGroup, workerGroup)//设置两个线程组
.channel(NioServerSocketChannel.class) // 使用NioServerSocketChannel 作为服务器的通道实现
// 初始化服务器连接队列大小,服务端处理客户端连接请求是顺序处理的,所以同一时间,只能处理一个客户端连接,多个客户端同时来的时候
// 服务端将不能处理的客户端连接请求放在队列中等待处理
.option(ChannelOption.SO_BACKLOG, 1024)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
//ch.config().setRecvByteBufAllocator(new FixedRecvByteBufAllocator(2056));
// 对workerGroup 的SocketChannel设置处理器
ch.pipeline().addLast(new NettyServerHandler());
}
});
System.out.println("netty server start ....");
// 绑定一个商品并且同步,生成一个ChannelFuture异步对象,通过isDone()等方法可以判断异步事件的执行情况
// 启动服务器(并绑定端口),bind是异步操作,sync方法是等待异步操作执行完毕
ChannelFuture cf = bootstrap.bind(9000).sync();
// 给注册监听器,监听我们关心的事件
cf.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
if (cf.isSuccess()) {
System.out.println("监听端口9000成功");
} else {
System.out.println("监听端口9000失败");
}
}
});
// 对通道关闭进行监听,closeFuture是异步操作,监听通道关闭
// 通过sync方法同步等待通道关闭处理完毕,这里会阻塞等待通道关闭完成
cf.channel().closeFuture().sync();
} catch (Exception e) {
e.printStackTrace();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}
// 自定义Handler需要继承netty 规定好的某个HandlerAdapter(规范)
public class NettyServerHandler extends ChannelInboundHandlerAdapter {
/**
* 读取客户端发送的数据
*
* @param ctx 上下文对象,含有通道channel ,管道 pipeline
* @param msg 就是客户端发送的数据
* @throws Exception
*/
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
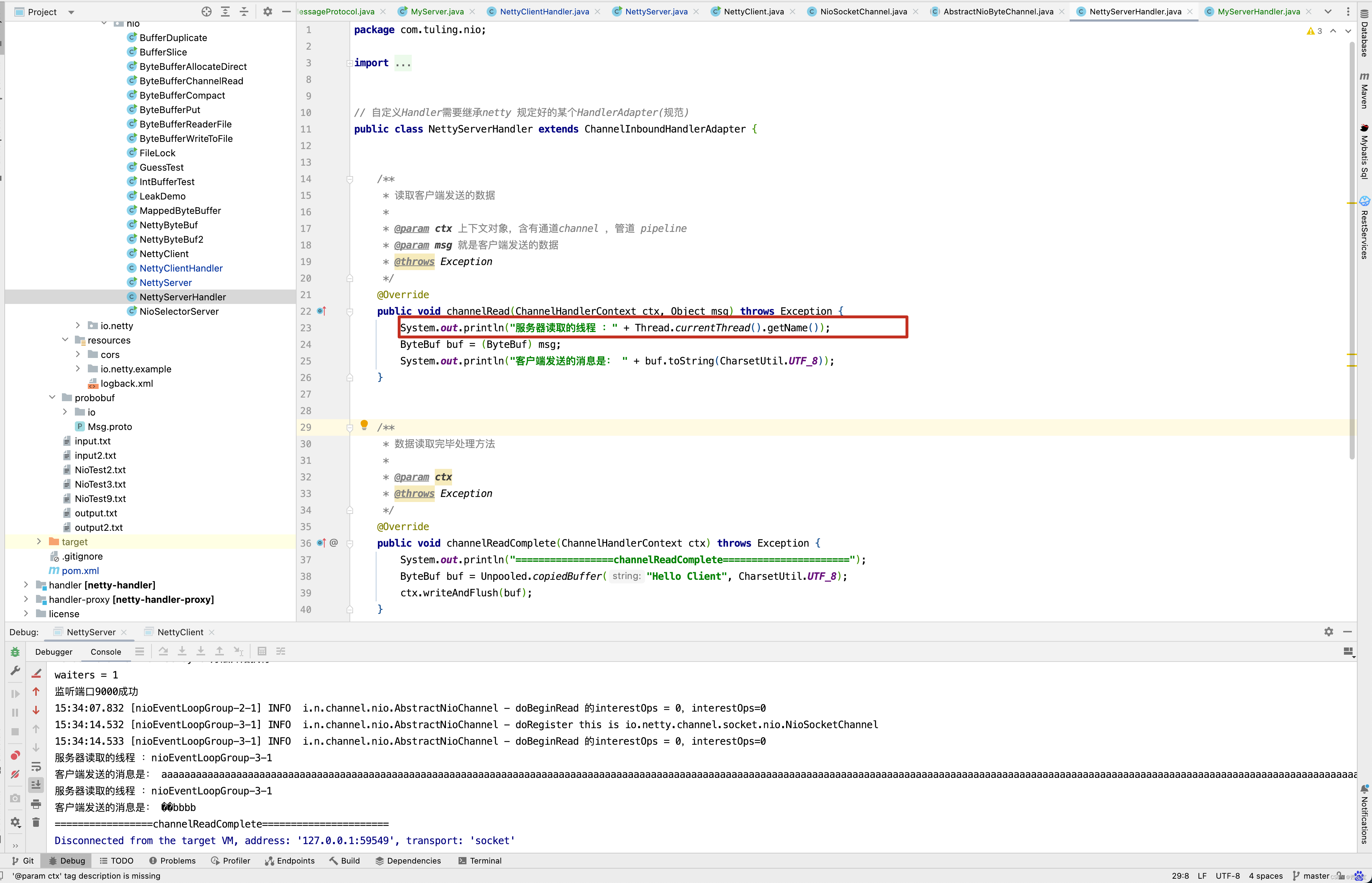
System.out.println("服务器读取的线程 :" + Thread.currentThread().getName());
ByteBuf buf = (ByteBuf) msg;
System.out.println("客户端发送的消息是: " + buf.toString(CharsetUtil.UTF_8));
}
/**
* 数据读取完毕处理方法
* @param ctx
* @throws Exception
*/
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
System.out.println("=================channelReadComplete======================");
ByteBuf buf = Unpooled.copiedBuffer("Hello Client", CharsetUtil.UTF_8);
ctx.writeAndFlush(buf);
}
// 处理异常,一般需要关闭通道
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
ctx.close();
}
}
Netty客户端代码
public class NettyClient {
public static void main(String[] args) {
// 客户端需要一个事件循环组
EventLoopGroup group = new NioEventLoopGroup();
try {
// 创建客户端启动对象
// 注意,客户端使用的不是ServerBootstrap , 而是Bootstrap
Bootstrap bootstrap = new Bootstrap();
// 设置相关的参数
bootstrap.group(group) //设置线程组
.channel(NioSocketChannel.class) // 使用NioSocketChannel作为客户端的通道实现
.handler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new NettyClientHandler());
}
});
System.out.println("netty client start ");
// 启动客户端去连接服务器端
ChannelFuture channelFuture = bootstrap.connect("127.0.0.1",9000).sync();
// 对关闭通道进行监听
channelFuture.channel().closeFuture().sync();
}catch (Exception e ){
e.printStackTrace();
}finally {
group.shutdownGracefully();
}
}
}
public class NettyClientHandler extends ChannelInboundHandlerAdapter {
// 当客户端连接服务器完成就会触发这个方法
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
StringBuffer sb = new StringBuffer();
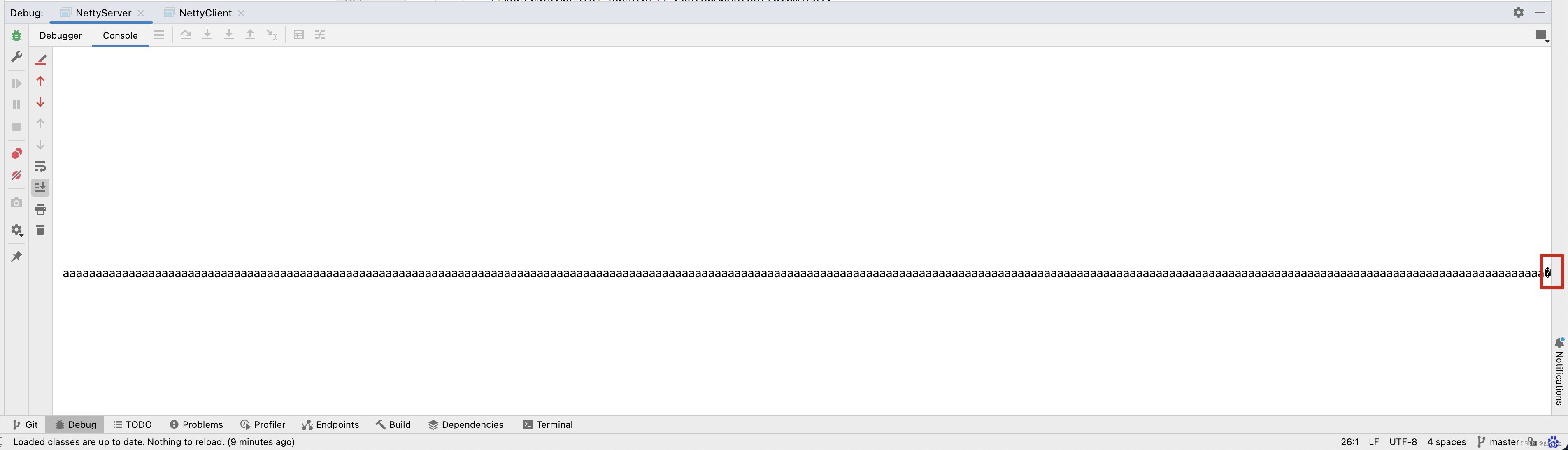
for(int i = 0 ;i < 1023;i ++){
sb.append("a");
}
sb.append("中");
sb.append("bbbb");
ByteBuf buf = Unpooled.copiedBuffer(sb.toString(), CharsetUtil.UTF_8);
ctx.writeAndFlush(buf);
}
// 当通道在读取事件时会触发,即服务端发送数据给客户端
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf buf = (ByteBuf) msg;
System.out.println(" 收到服务端的消息: " + buf.toString(CharsetUtil.UTF_8));
System.out.println("服务端的地址:" + ctx.channel().remoteAddress());
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
cause.printStackTrace();
ctx.close();
}
}
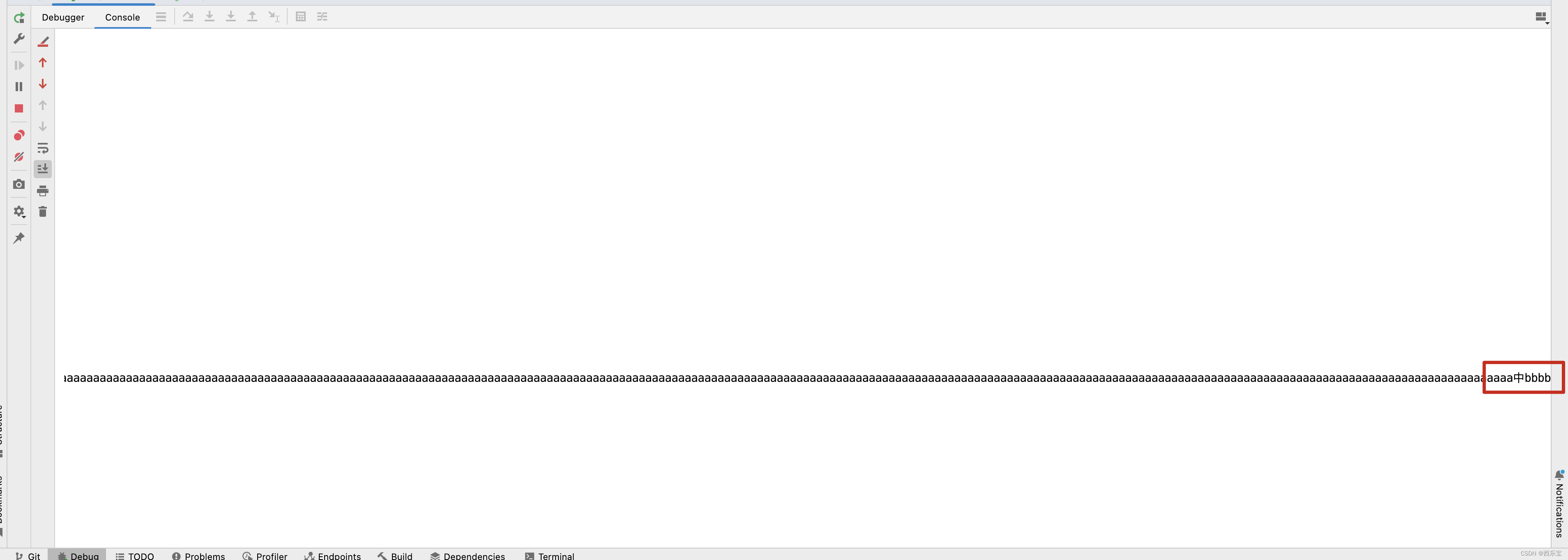
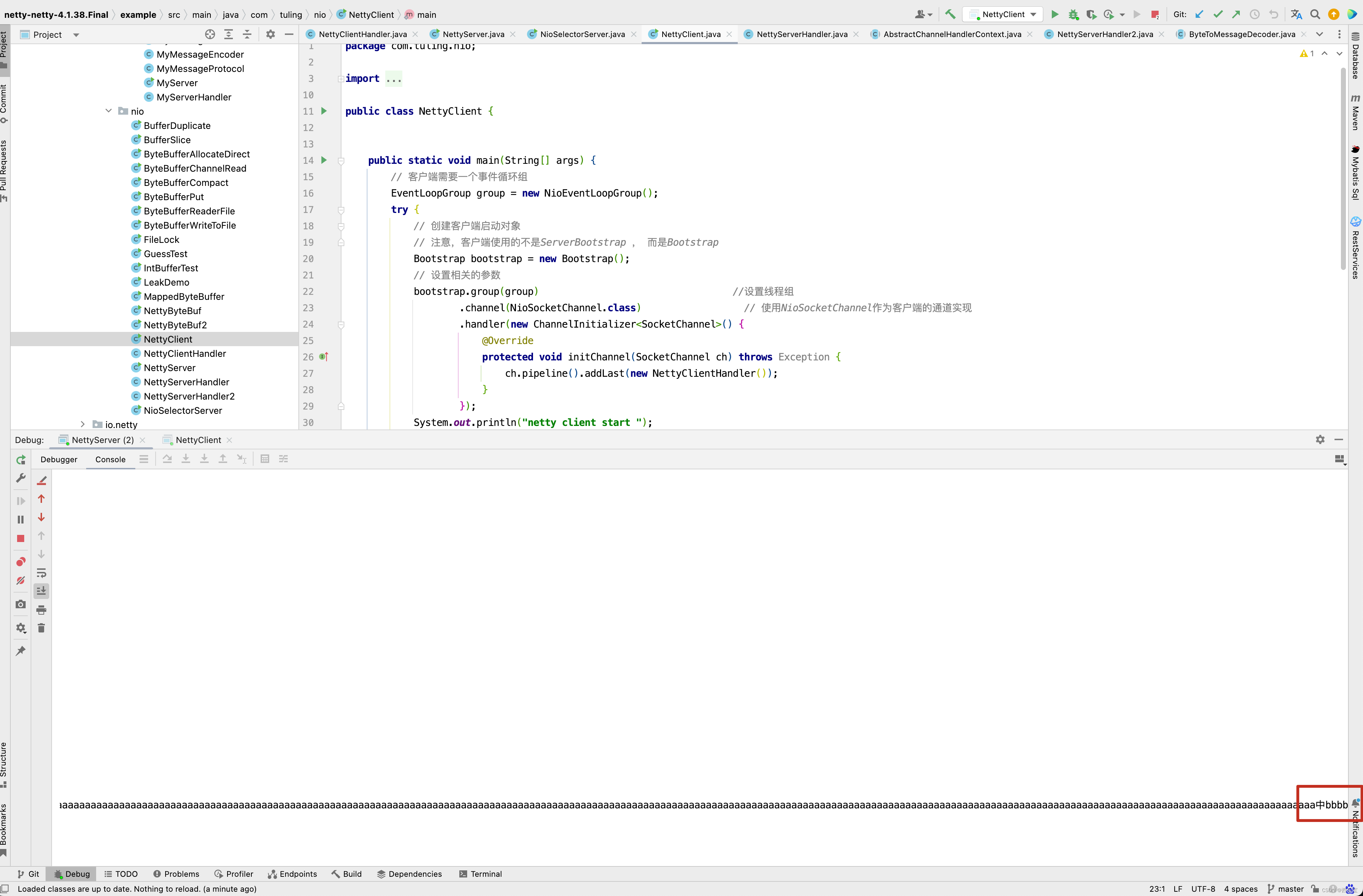
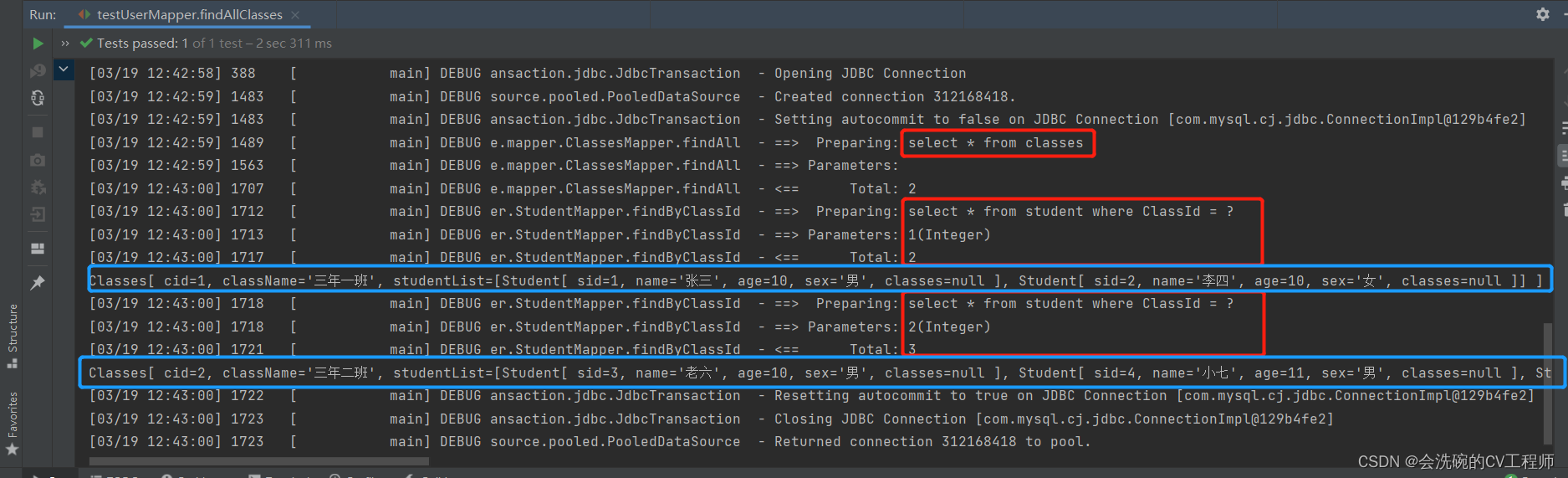
在NettyClientHandler的channelActive()方法中,先for循环写了1023个字节, 然后写了一个"中" 字,utf-8编码一个中文占3个字节,再写了4个"bbbb",因此最终写入到ByteBuf中是1030个字节 。
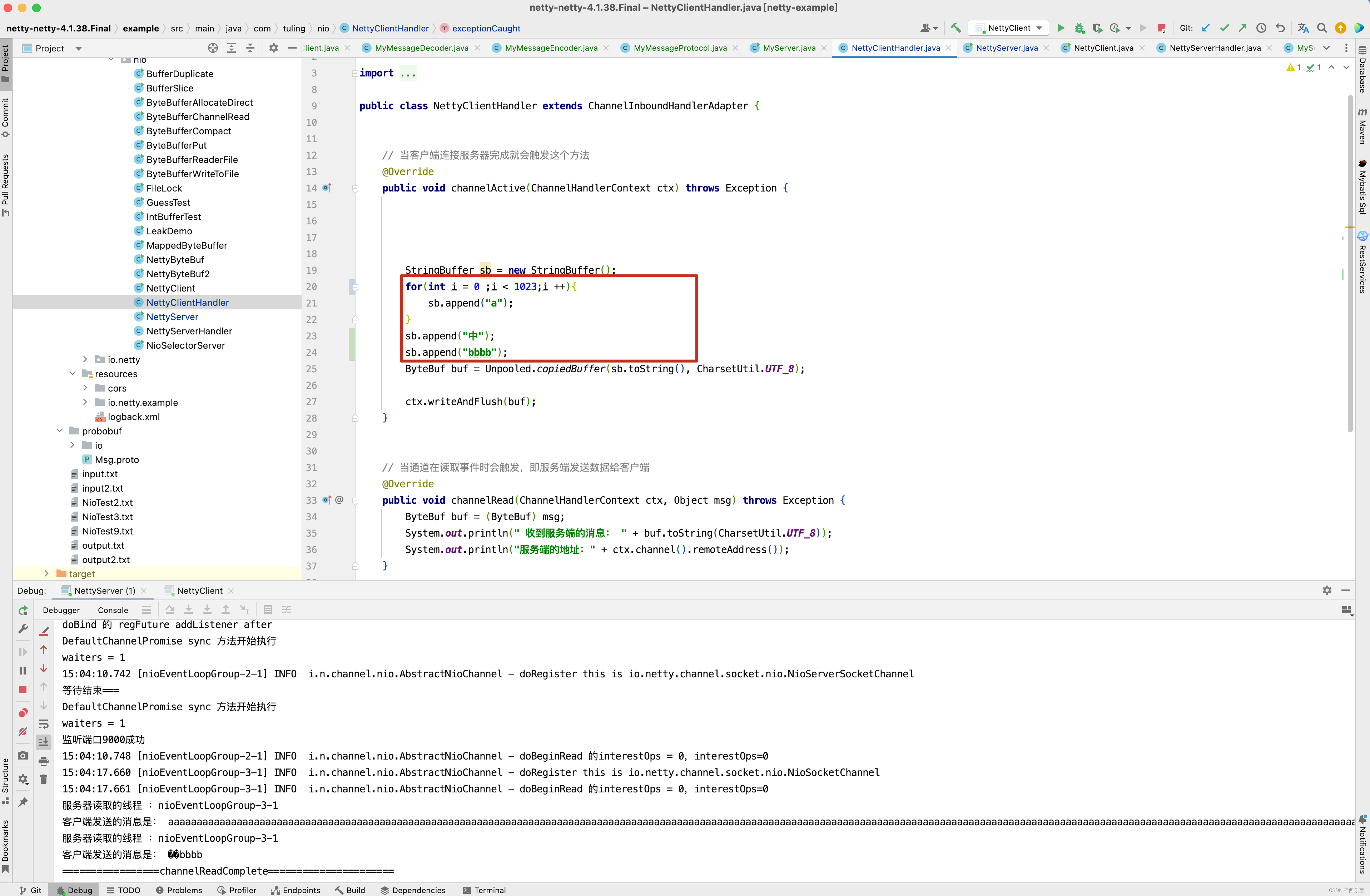
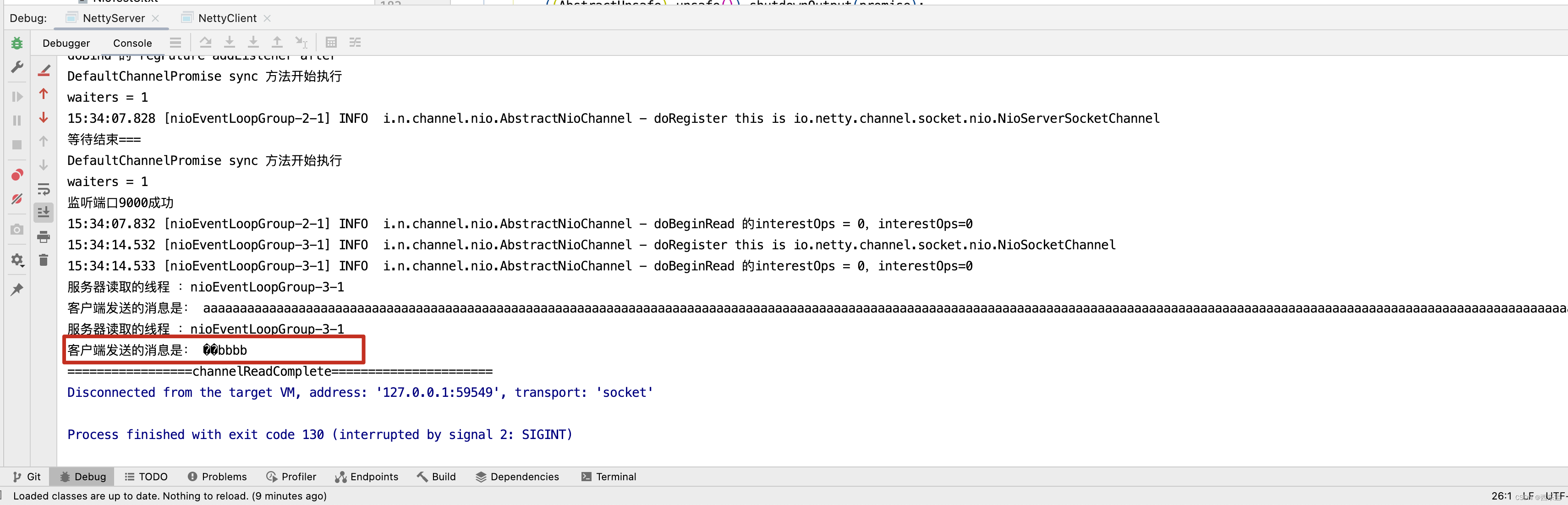
我们之前也分析过,第一次读取时,ByteBuf默认容量为1024,因此在NioSocketChannel的read()方法中,while()循环中会循环两遍。 如下图所示 。
而刚好在ByteBuf的[1024,1025,1026]这三个字节中被"中"的中字占用,因此ByteBuf取0~1023个字节时,“中”字被截断了 。
最终在服务端代码中打印了两次ByteBuf字符串信息,发现打印的信息中文乱码。
这个问题怎样解决呢?
解决方案一
如果说 Netty 默认提供了一个可变的缓冲区大小分配方案,那么我们可不可以改变这个策略呢?从AdaptiveRecvByteBufAllocator开始向上找到根类型,可以最终找到 RecvByteBufAllocator 接口上,查看这个接口的子类,应该会有其他缓冲区大小分配方案。
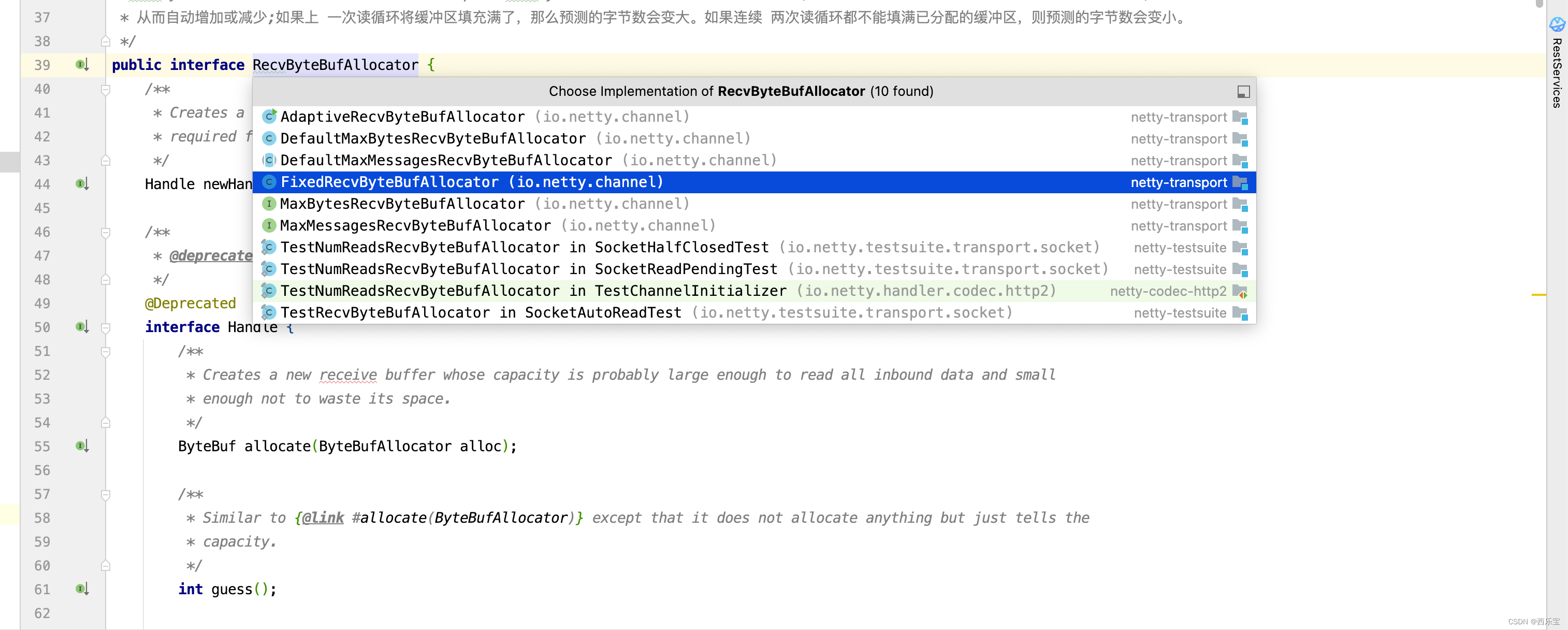
这里有一个固定的接收数组空间分配器,现在只要想办法把默认的 AdaptiveRecvByteBufAllocator换成 FixedRecvByteBufAllocator 就可以解决问题了。
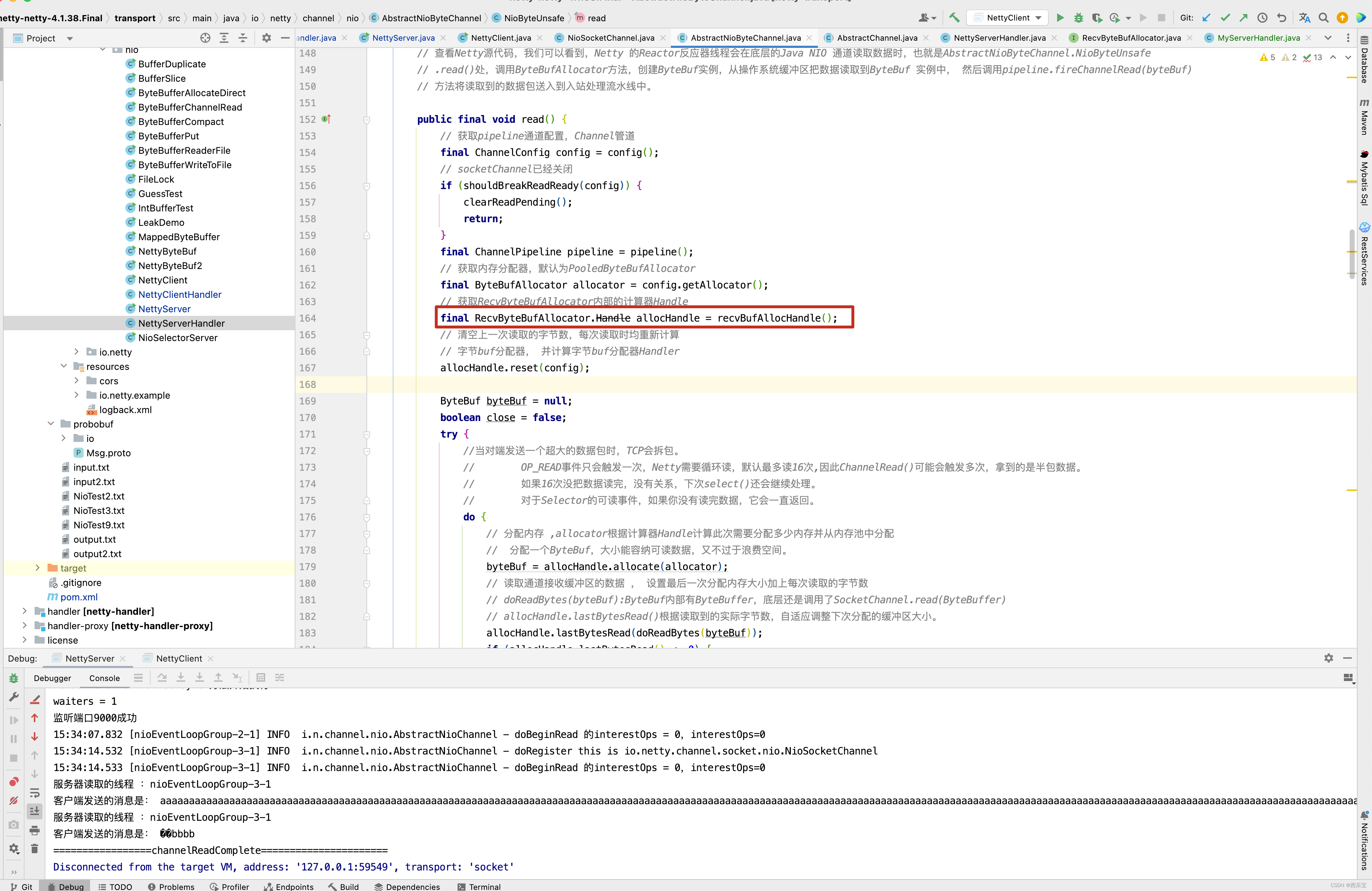
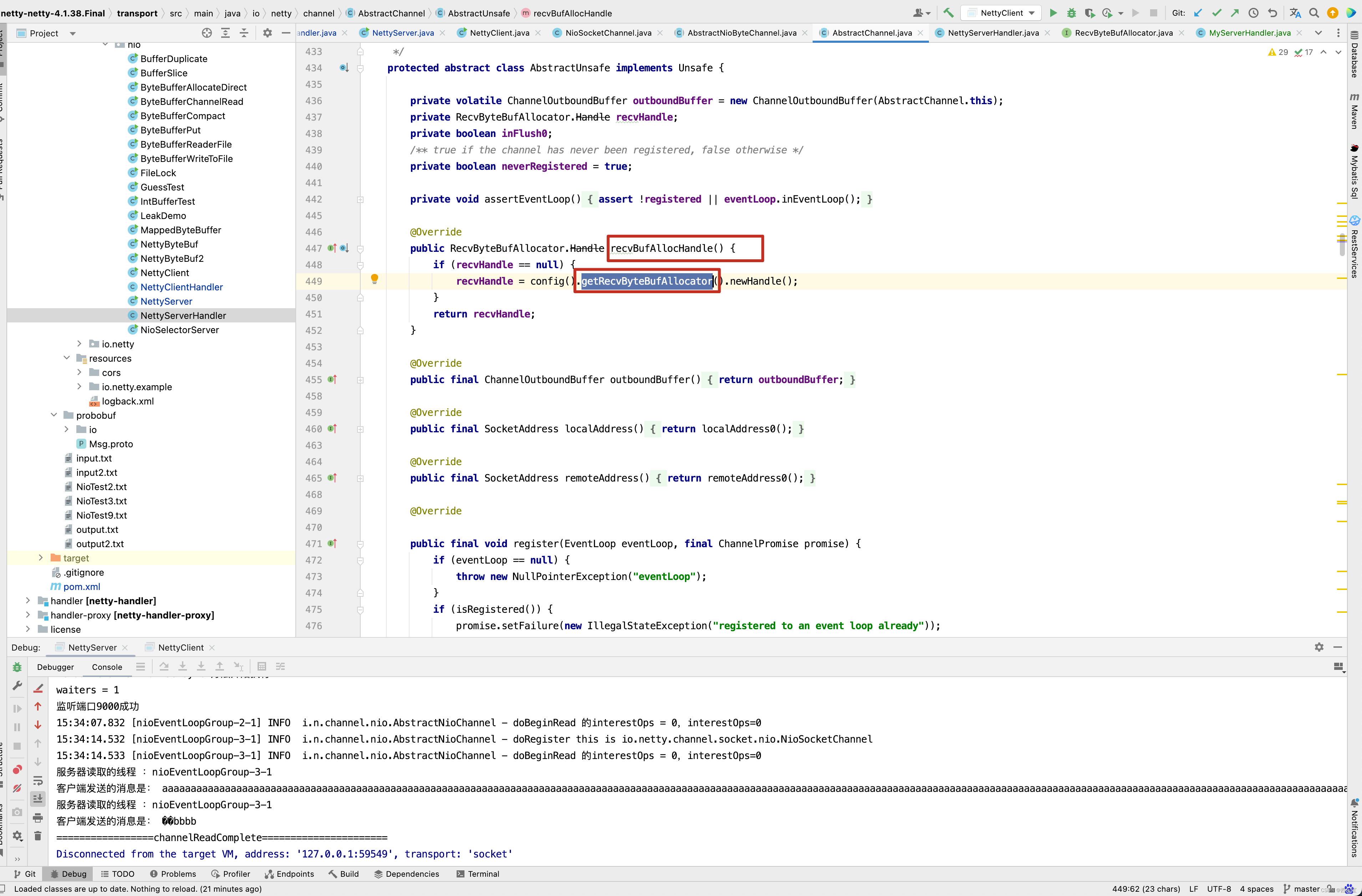
首先调用 config方法,然后调用getRecvByteBufAllocator来创建这个allocHandle。既然有getRecvByteBufAllocator()方法,那肯定有setRecvByteBufAllocator()方法。
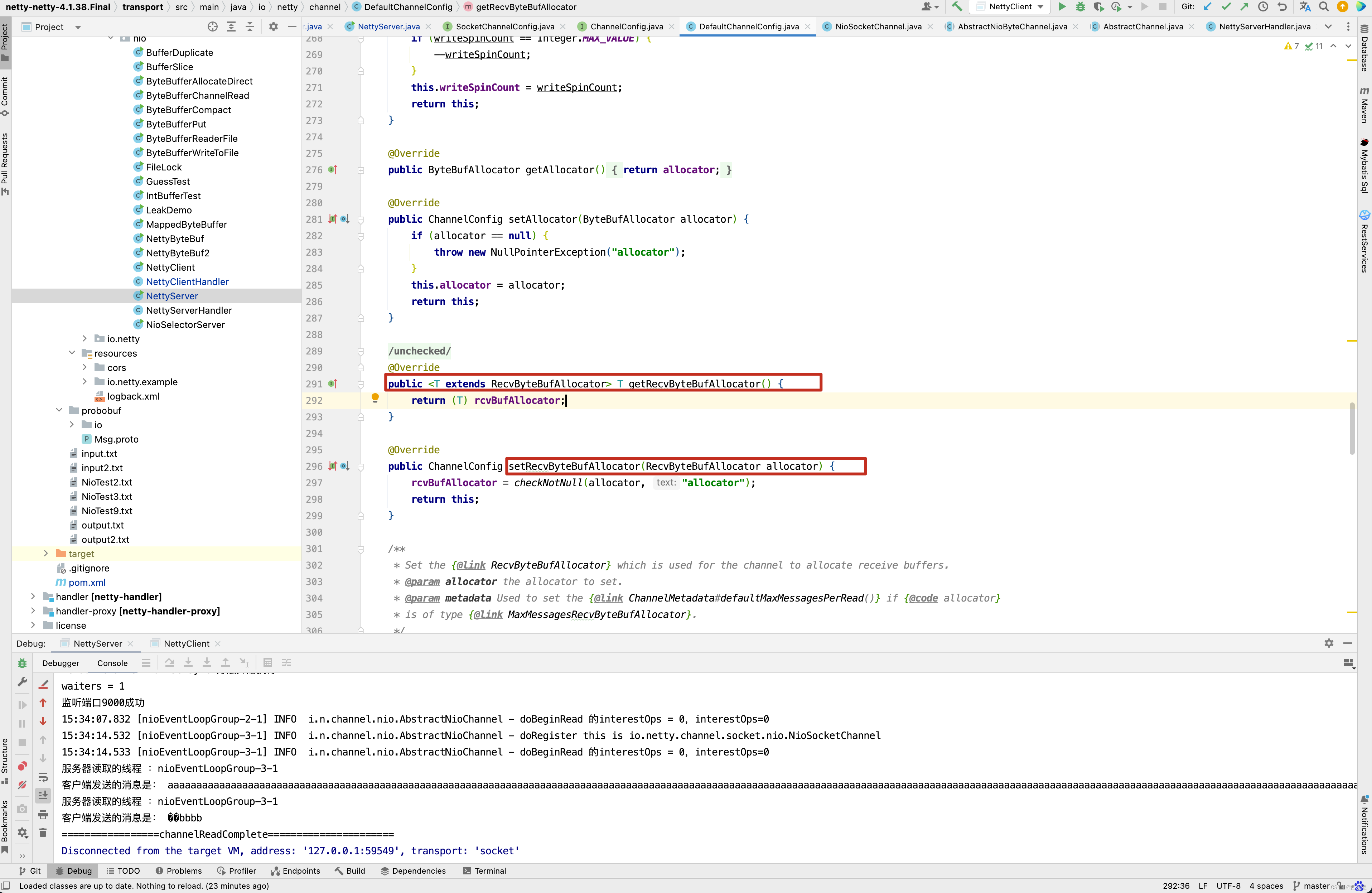
因此只需要调用config()的setRecvByteBufAllocator()方法即可。
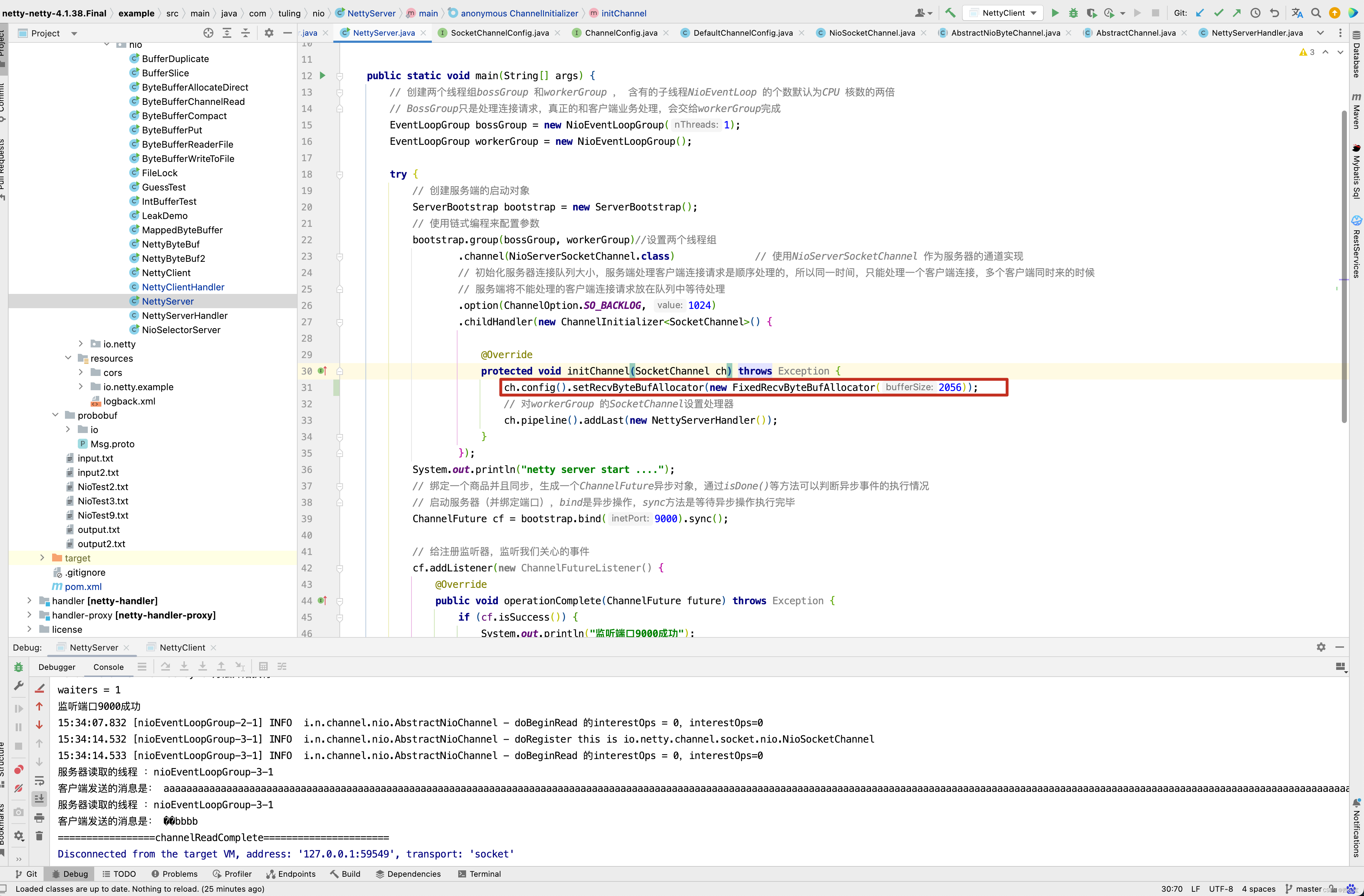 ByteBuf一次就打印完了,并没有出现中文乱码。
ByteBuf一次就打印完了,并没有出现中文乱码。

对于这个问题, 还有另外一种解决方案。
方案二
客户端代码修改
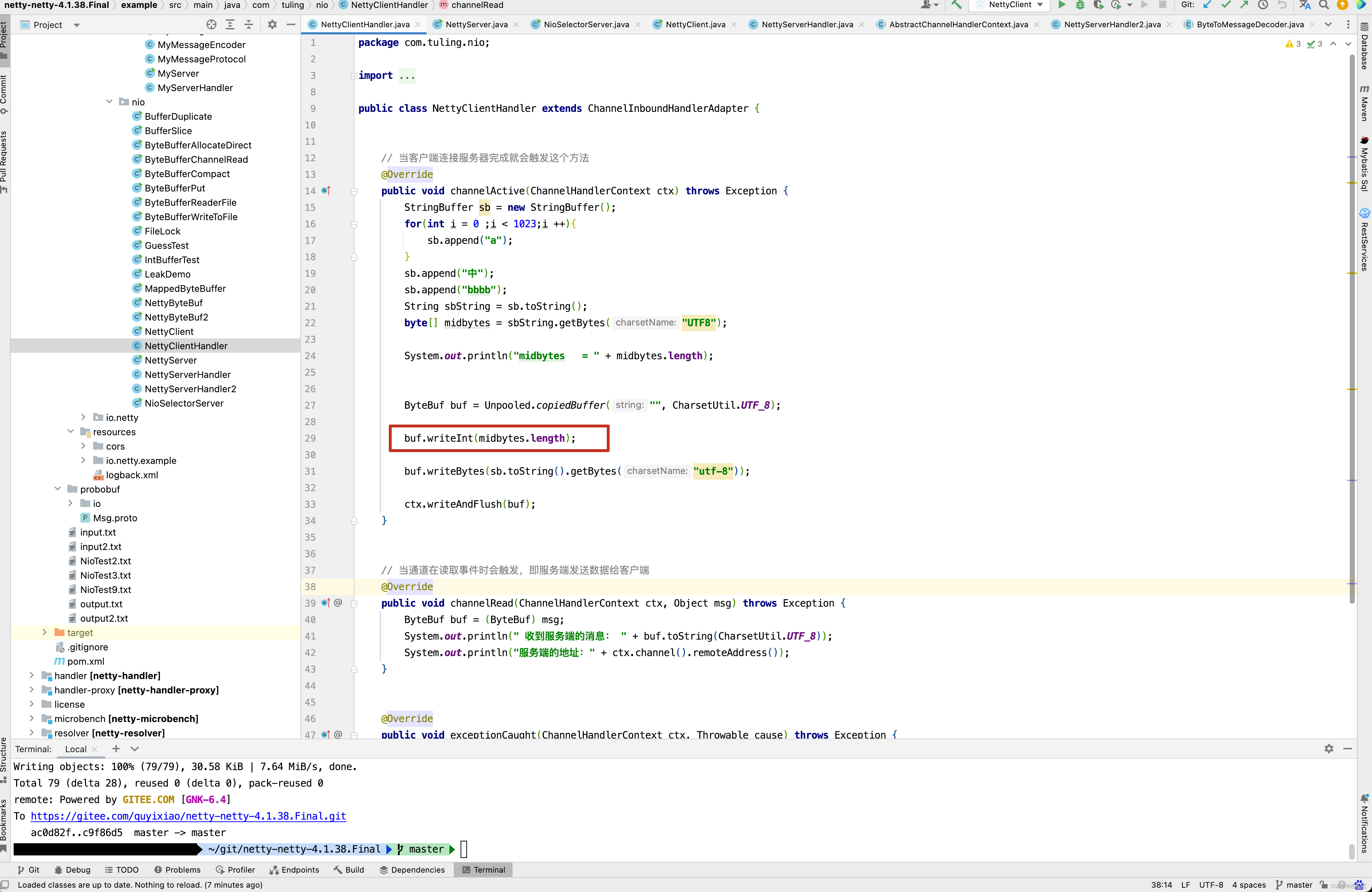
在内容前面添加内容的长度 。
在initChannel()方法中添加ch.pipeline().addLast(new NettyServerHandler2()) 一行代码。
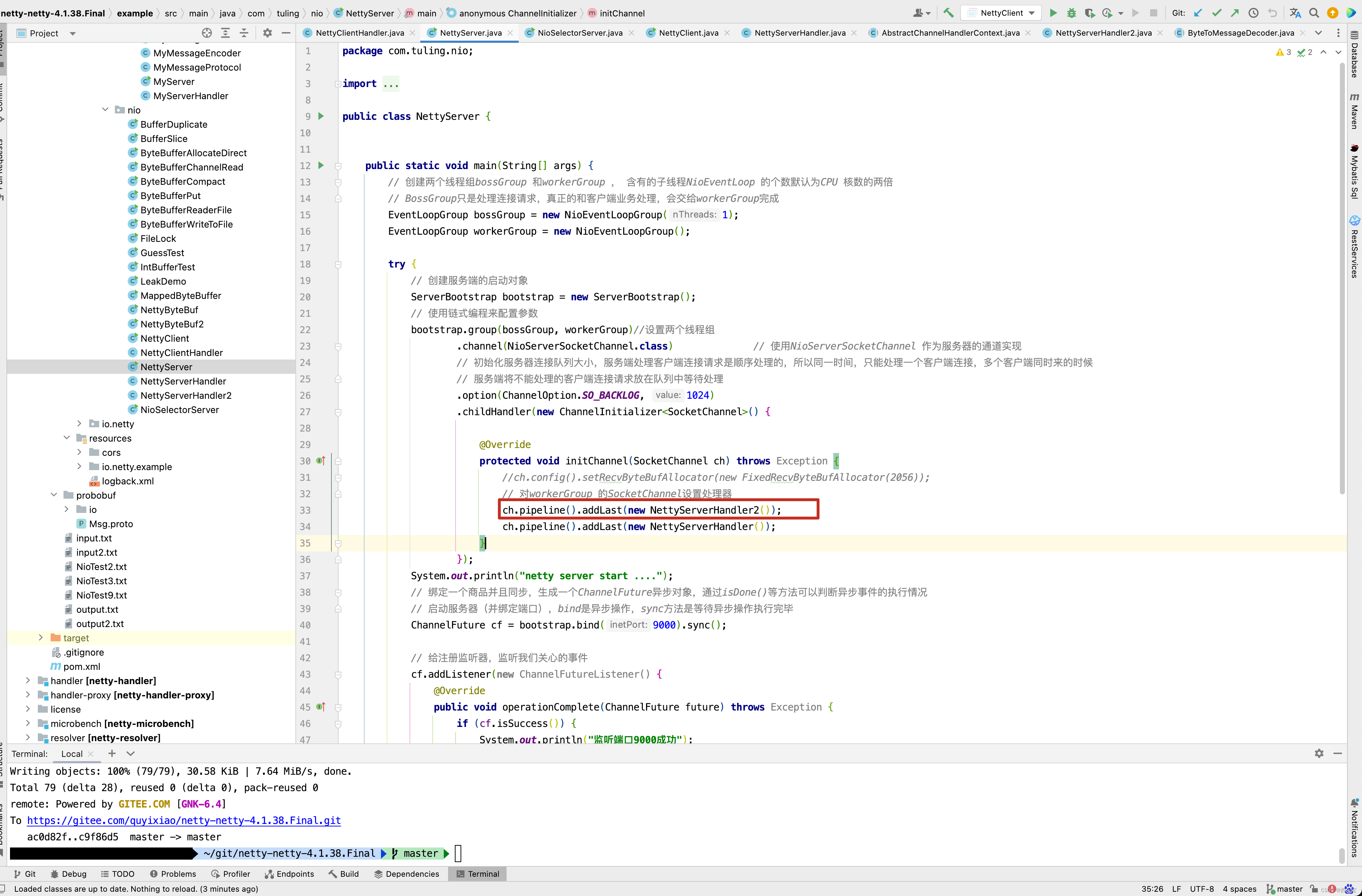
的具体代码如下
public class NettyServerHandler2 extends ByteToMessageDecoder {
private int alreadyReadLength ;
private int sumByteLength ;
private ByteBuf buf ;
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
System.out.println("NettyServerHandler2 invoke");
if (sumByteLength == 0) {
sumByteLength = in.readInt();
buf = Unpooled.copiedBuffer("", CharsetUtil.UTF_8);
}
int readableBytes = in.readableBytes();
alreadyReadLength += readableBytes;
byte[] data = new byte[readableBytes];
in.readBytes(data);
buf.writeBytes(data);
if (alreadyReadLength == sumByteLength) {
sumByteLength = 0;
byte[] outData = new byte[buf.readableBytes()];
buf.readBytes(outData);
out.add(new String(outData,"utf-8"));
buf.release();
buf = null;
}
}
}
写一个Handler继承ByteToMessageDecoder,而在这个类的内部定义了三个属性,alreadyReadLength记录已经读取的字节数, sumByteLength本次客户端发送过来的总字节数, buf 临时存储客户端传递过来的字节,当alreadyReadLength和sumByteLength相等时,则表示字节已经读取完全 。 此时可以将数据写回到out中。因此NettyServerHandler2的主要作用就是合并客户端传递过来的字节,从而避免客户端数据还没有读取完就时行业务处理。
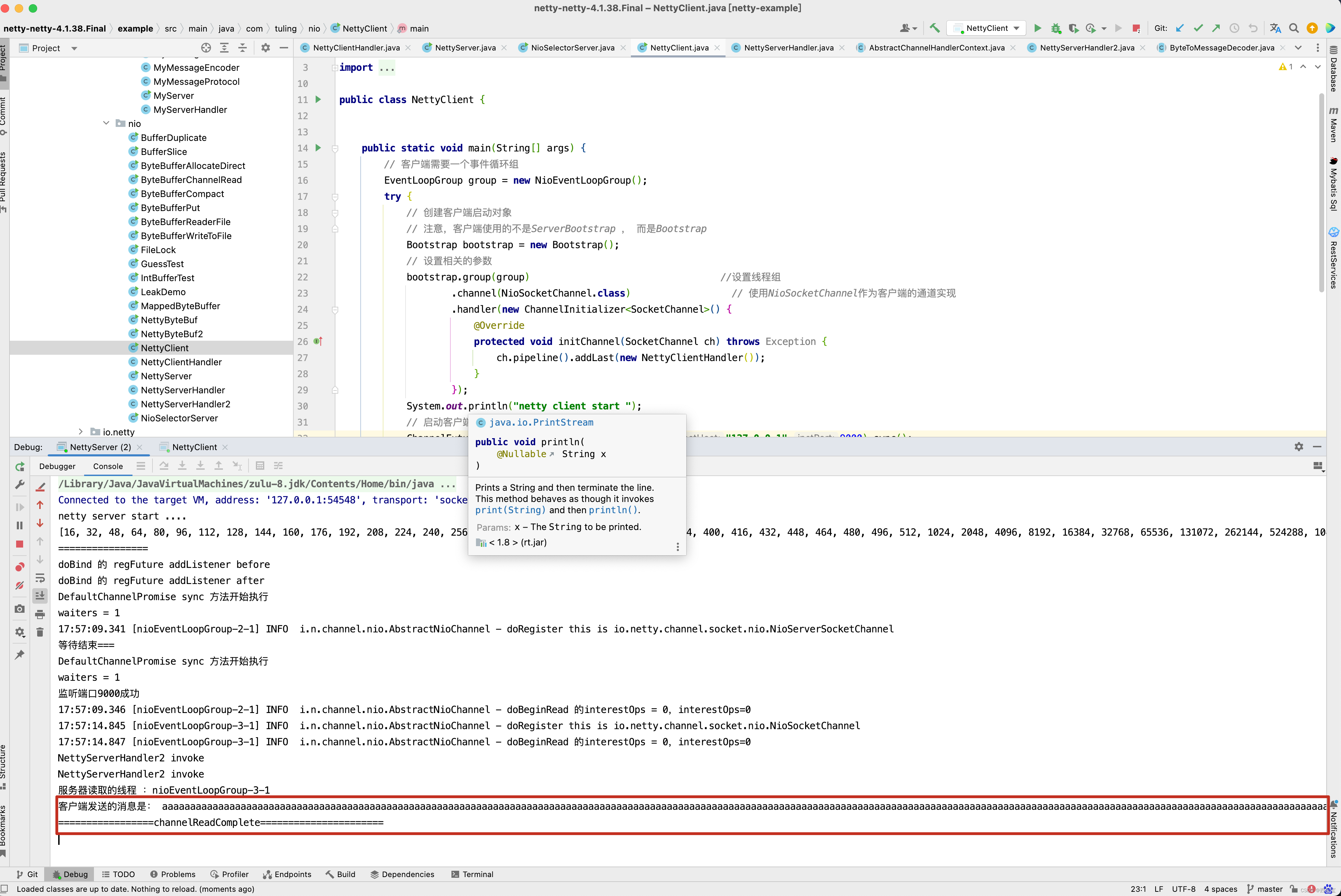
没有出现乱码问题了,个人觉得第二种方案比第一种方案更加好,因为在第一种方案中调用了ch.config().setRecvByteBufAllocator(new FixedRecvByteBufAllocator(2056)) 方法,指定了RecvByteBufAllocator 为FixedRecvByteBufAllocator,并且初始化ByteBuf的容量为2056,如果此次用户发送的byte长度是1030,这是已知的,如果用户第一次请求的字节长度是3000,是不是又要修改FixedRecvByteBufAllocator中的bufferSize的值为3000,又要重启Netty服务器,显然不适用于生产环境 。 而第二种方案基本上适用于所有的情况 ,当然啦,第二种情况在NettyServerHandler2定义了三个局部变量alreadyReadLength,sumByteLength,buf 那会不会存在并发问题呢? 这个不得而知,因为我自己对Netty也是在不断的学习中 ,具体的情况,我会在下一篇博客去求证,但这里也给我们提供了一种解决问题的思路,希望给读者有借鉴意义 。
第三种解决方案
当然对于之前提到问题,还有第三种解决方案,我们利用LengthFieldBasedFrameDecoder来解决 。
- 在NettyServer中, 在ChannelInitializer的initChannel方法中添加自定义handler NettyServerHandler2 ,这个类继承LengthFieldBasedFrameDecoder实现了decode()方法 。
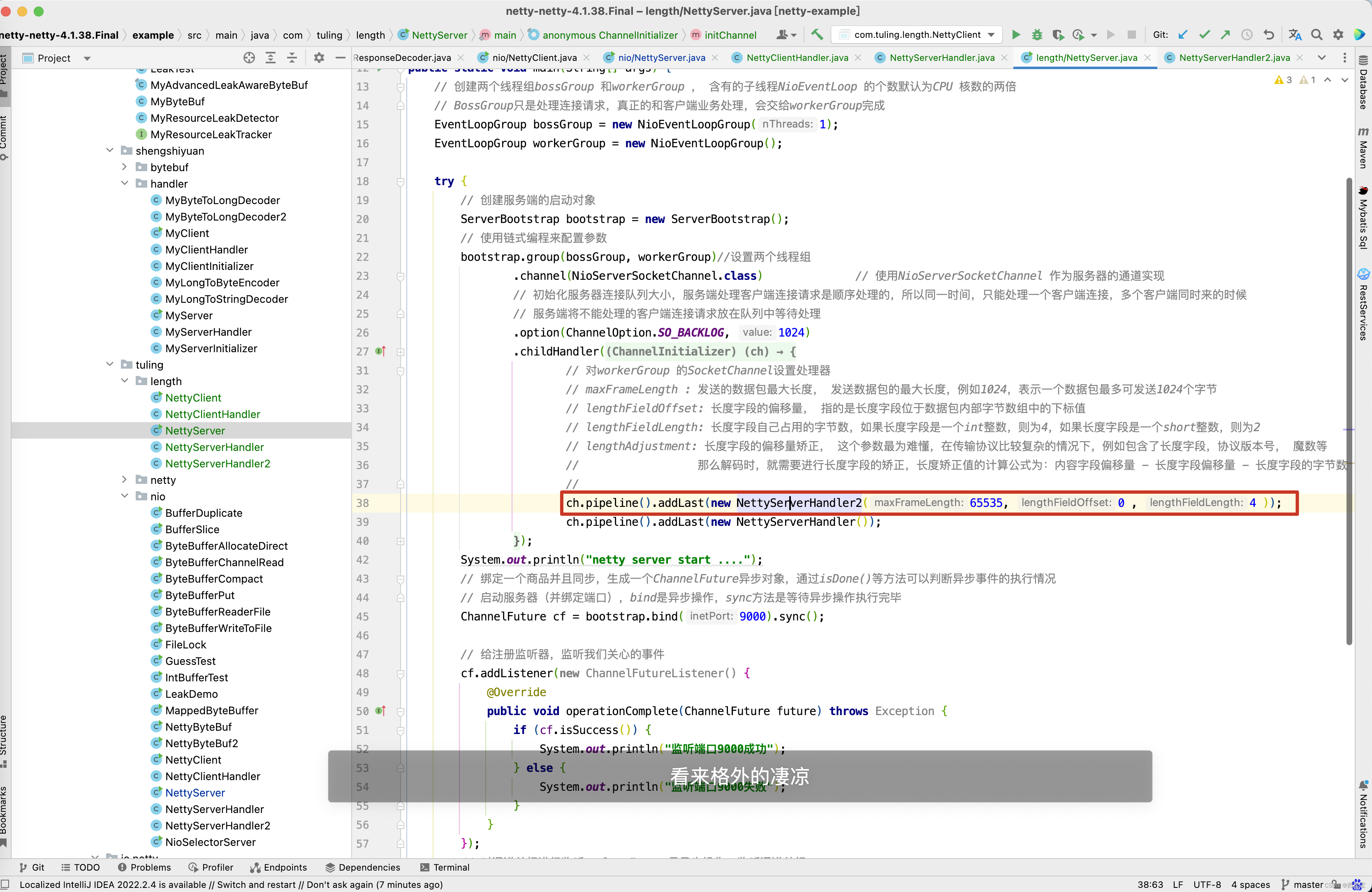
在NettyServerHandler2的构造方法中传递了3个参数,这3个参数的含义为
- maxFrameLength : 发送的数据包最大长度, 发送数据包的最大长度,例如1024,表示一个数据包最多可发送1024个字节
- lengthFieldOffset: 长度字段的偏移量, 指的是长度字段位于数据包内部字节数组中的下标值
- engthFieldLength: 长度字段自己占用的字节数,如果长度字段是一个int整数,则为4,如果长度字段是一个short整数,则为2
- lengthAdjustment: 长度字段的偏移量矫正, 这个参数最为难懂,在传输协议比较复杂的情况下,例如包含了长度字段,协议版本号, 魔数等
那么解码时,就需要进行长度字段的矫正,长度矫正值的计算公式为:内容字段偏移量 - 长度字段偏移量 - 长度字段的字节数
- 写一个NettyServerHandler2继承LengthFieldBasedFrameDecoder类
public class NettyServerHandler2 extends LengthFieldBasedFrameDecoder {
public NettyServerHandler2(int maxFrameLength, int lengthFieldOffset, int lengthFieldLength) {
super(maxFrameLength, lengthFieldOffset, lengthFieldLength);
}
@Override
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
in = (ByteBuf) super.decode(ctx,in);
if(in == null){
return null;
}
if(in.readableBytes()<4){
throw new Exception("字节数不足");
}
//读取length字段
int length = in.readInt();
if(in.readableBytes()!=length){
throw new Exception("标记的长度不符合实际长度");
}
//content内容
byte []bytes = new byte[length];
in.readBytes(bytes);
return new String(bytes,"UTF-8");
}
}
到这里这篇博客就告一段落,下一篇博客见。
本文对应github地址为
https://gitee.com/quyixiao/netty-netty-4.1.38.Final.git





![[Netty源码] ByteBufAllocator内存管理器相关问题 (十一)](https://img-blog.csdnimg.cn/b8146c9d0f284aa68618e3deb89c4290.png)