参考资料
- https://amazon-dynamodb-labs.workshop.aws/
- https://docs.amazonaws.cn/amazondynamodb/latest/developerguide/Introduction.html
dynamodb的工作原理
核心概念
table、item和attributes是dynamodb的核心组件,可以分别对应关系型数据库中的表,行和列
-
table包含多个item,item是一组attributes,dynamodb没有item的数量的限制
-
item包括attributes,例如People 表中的一个
item包含名为 PersonID、LastName、FirstName 等的属性 -
ddb的表没有固定结构,不需要预先定义,每个项目都能够拥有自己的独特属性
-
ddb最多支持高达 32 级深度的嵌套属性
dynamodb的服务配额
读写方面(指定的吞吐量是ddb可以交付的最大容量)
- RCU,读取容量单位,4KB 及以下,每秒一次强一致性读取(4KB),或每秒两次最终一致性读取(8KB)
- WCU,写入容量单位,1KB 及以下,每秒一次写入(10个2KB需要20个WCU)
表的限制
- 表大小没有限制;表的数量限制为每账号每region2500个;每个查询和扫描的大小为1MB
索引和键
- LSI,5个;GSI,每个表20个;投影SI,最多 100 个
item大小最大为400KB
主键和二级索引
分区键和排序键,分区键就是主键,排序键是索引键,通过哈希函数对数据进行分区(具有相同分区键的项目存储在互相紧邻的物理位置)。和mysql函数的逻辑类似,dynamodb中的每个分区默认按照排序键进行排序。复合主键唯一即可
二级索引为数据的查询提供了另一个子树
参考《mysql是怎样运行的?》索引章节内容,聚簇索引通过b+树的方式实现了数据的快速检索
页按照主键大小顺序排列,每个页内的记录也按照主键的大小顺序排列
二级索引和聚簇索引的逻辑类似,但是每个页中不再是完整的用户数据,而是索引键+主键的组合,查询的路径变成了二级索引->主键->数据页。联合索引即多个列组成的索引,本质上还是个二级索引
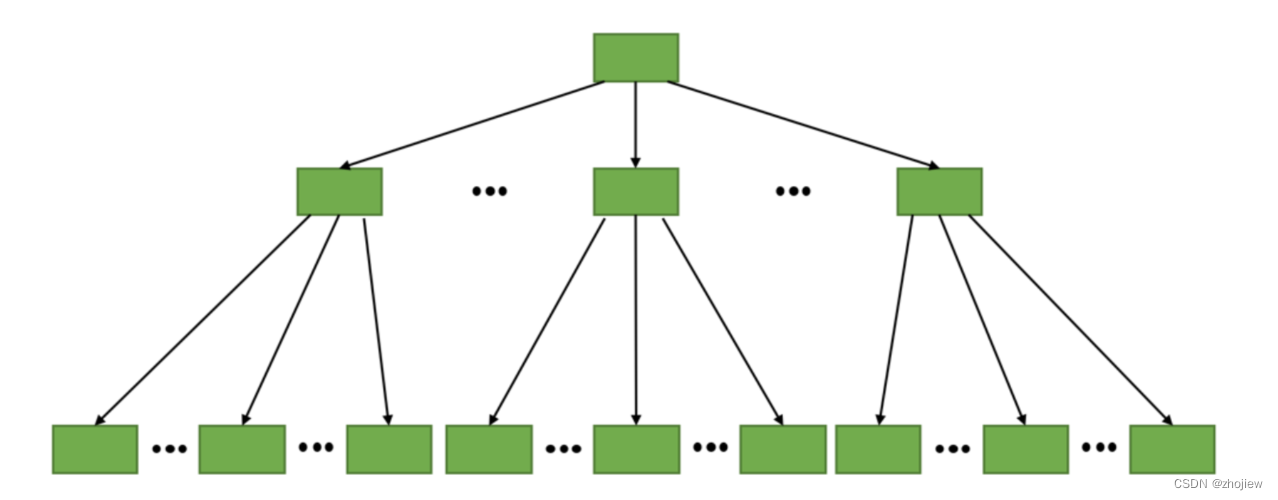
dynamodb的索引可以和mysql的索引进行类比
-
全局二级索引,实际上是个联合索引,并且联合索引的内容可以和基表中的分区和排序键不一致
-
本地二级索引,也是个联合索引,但是分区键必须相同,排序键可以不同
注意:每个索引属于一个表,dynamodb在基表的项目进行增删改的时候自动维护索引,存在一定的性能损耗
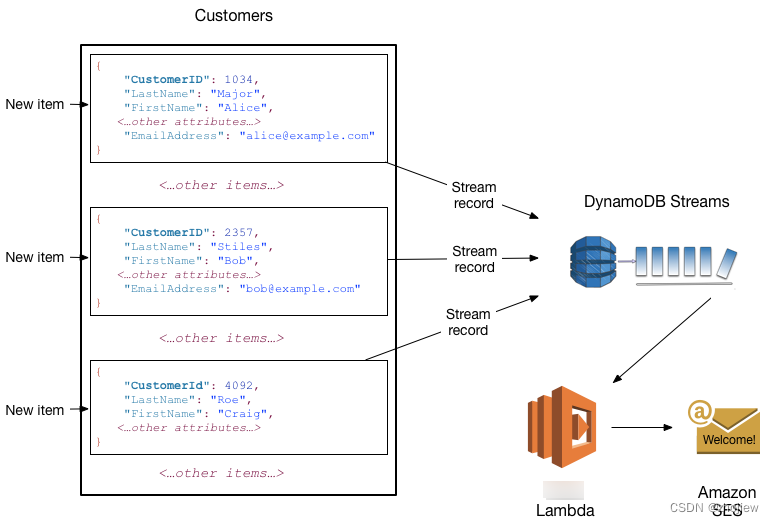
dynamodb启用流时,当对item出现增删改事件是,stream会写入流记录(表名,事件时间戳,元数据),保留24小时后自动删除
典型用法是将dynamodb stream和lambda函数结合,捕获感兴趣的事件并触发对应行为
dynamodb的api操作(DDL和DML)
https://docs.amazonaws.cn/amazondynamodb/latest/developerguide/HowItWorks.API.html
总体的操作可以分为
- 管理层面
- 数据平面,即crud操作,可以使用partiql或标准api,支持事务操作
创建删除表
aws dynamodb list-tables
aws dynamodb put-item --table-name Music --item "{\"Artist\": {\"S\": \"No One You Know\"}, \"SongTitle\": {\"S\": \"Call Me Today\"}, \"AlbumTitle\": {\"S\": \"Somewhat Famous\"}, \"Awards\": {\"N\": \"1\"}}"
aws dynamodb delete-table --table-name Music
增删改查
aws dynamodb put-item --table-name Music --item file://item.json
aws dynamodb get-item --table-name Music --item file://item.json
aws dynamodb delete-item --table-name Music --key file://key.json
查询表
aws dynamodb query --table-name Music --key-condition-expression "ArtistName=:Artist and SongName=:Songtitle"
一致性问题
dynamodb 是region隔离的,数据在多可用区中存储,写入数据持久化后,短时间内(1s)最终在所有存储未知保持一致
dynamodb支持最终一致性和强一致性读取
- 最终一致性,当前读数据可能不是最新的
- 强一致性读取,无论何时都读取最新写入的数据,有局限性
- GSI不支持
- 相比最终一致性有更高的吞吐量,但是会收到延迟和终端的影响(500错误)
- 更高的延迟(leader未找到最新数据时)
默认使用最终一致性读取,使用ConsistentRead 将api调用指定为强一致性读取
读写容量问题
dynamodb支持两个读写容量模式处理表操作
- 按需模式
- 预置模式(默认)
读写容量模式在创建表时设置,也可以之后进行修改