ThreadPoolExecutor是JDK提供的在java.util.concurrent包中的一个用于创建线程池的工具类。
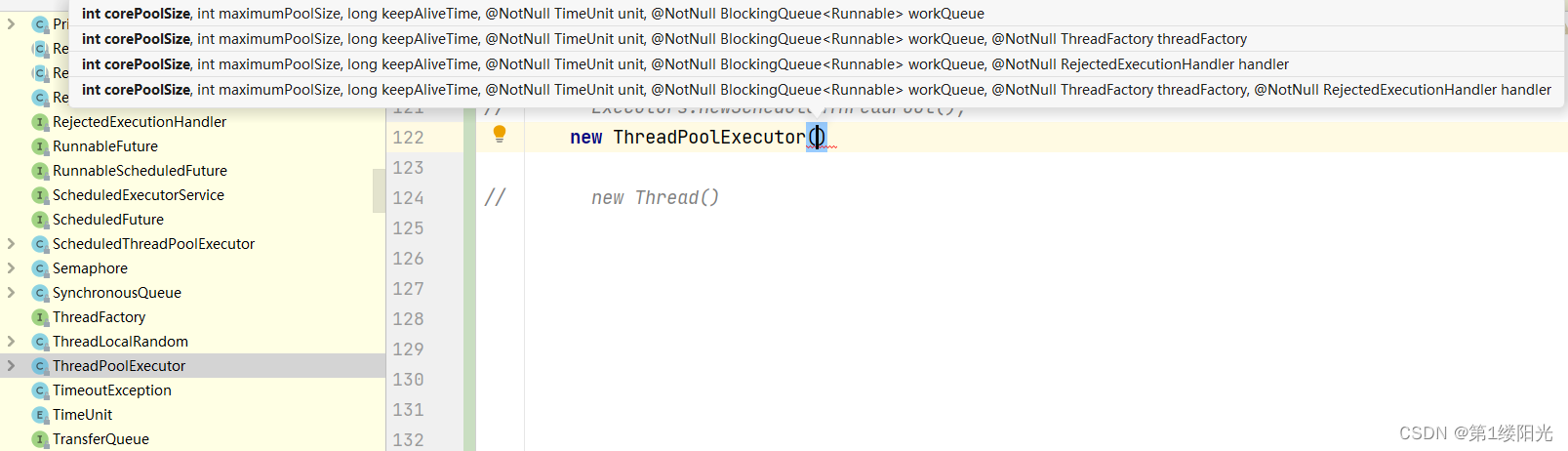
一、ThreadPoolExecutor的7个参数
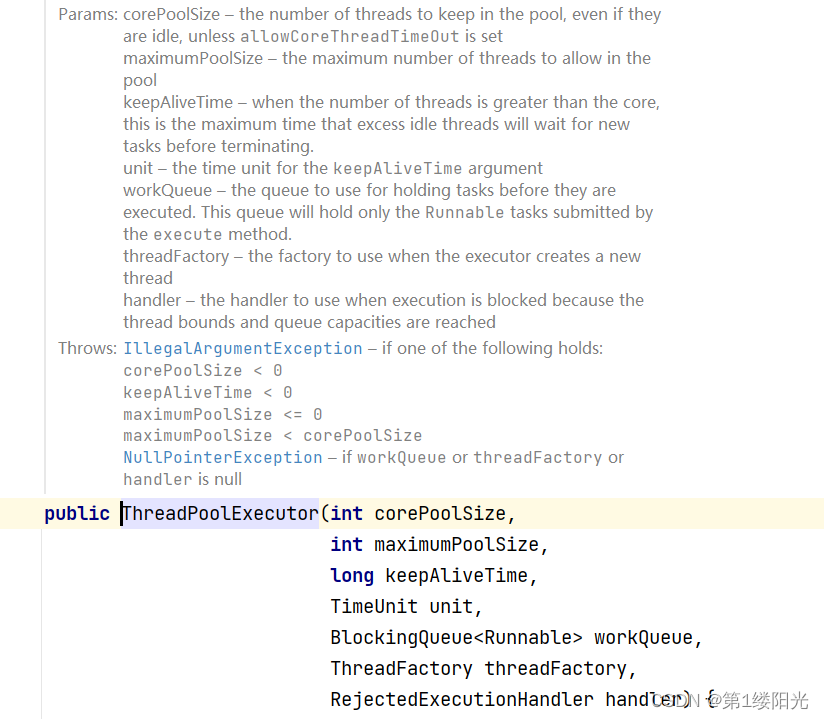
- corePoolSize:核心线程数,线程池中保留的最小的线程数量,即使它们是空闲的也不会被销毁,除非allowCoreThreadTimeOut被设置为true;
- maximumPoolSize:最大线程数,线程池中可以创建的最大线程数量;
- keepAliveTime:空闲线程存活时间,当线程数大于核心时,这是多余的空闲线程在终止前等待新任务的最大时间;
- unit:keepAliveTime参数的时间单位;
枚举类TimeUnit:
- NANOSECONDS:纳秒
- MICROSECONDS:微妙
- MILLISECONDS:毫秒
- SECONDS:秒
- MINUTES:分钟
- HOURS:小时
- DAYS:天
- WorkQueue:工作队列,用于保存待执行任务的队列,这个队列将只保存execute方法提交的可运行任务
JDK提供的四种工作队列:
- ArrayBlockingQueue:基于数组的有界阻塞队列,按FIFO排序,新任务进来后会放到队尾;
- LinkedBlockingQueue:基于链表的可选的无界阻塞队列(最大容量为Integer.MAX,可设定长度),按FIFO排序;
- SynchronousQueue:不缓存任务的阻塞队列,新任务进来时不会缓存,而是直接被调度执行该任务,如果没有可用线程,则创建新线程,如果线程数量达到maxPoolSize,则执行拒绝策略;
- PriorityBlockingQueue:具有优先级的无界阻塞队列。

有界队列:可防止资源耗尽问题,当线程池中线程数量达到corePoolSize后,再有新任务进来,则会讲任务放入该队列尾部等待被调度,如果队列已满,则创建一个新线程,如果线程数量的达到maxPoolSize,则执行拒绝策略;
无界队列:当线程池中线程数达到corePoolSize后,再有新任务进来会一直存入该队列,不会创建线程,所以线程数量永远不会达到maxPoolSize,此时maxPoolSize不起作用。
- threadFactory:线程工厂,创建新线程时要使用的工厂,该工厂可以用来设定线程名、是否为daemon线程等;
- handler:拒绝策略,当达到线程池中的线程数量达到最大线程数,并且工作队列中的任务已达到最大容量,再有新任务提交进来而阻塞执行时要使用的处理程序。
拒绝策略:
AbortPolicy:ThreadPoolExecutor的默认处理方式,直接抛出RejectedExecutionException异常;
DiscardPolicy:不处理直接丢弃任务,不会给任何通知;
DiscardOldestPolicy:丢弃队列中最早未处理的任务,即是丢弃队列头部的一个任务;
CallerRunsPolicy:在当前调用者的线程中运行任务,即是谁提交的任务由它自己去处理。

二、从源码分析线程池执行流程
1、线程池中主要成员变量

- ctl:初始化了线程池的状态和线程数量,初始状态为RUNNING并且线程数量为0;这里一个Integer既包含了状态也包含了数量,其中int类型一共32位
- 高3位标识状态
- 低29位标识数量
- ctlOf(),395行,用来更新线程状态和数量
- COUNT_BITS:线程数量的最大取值长度为29,所以线程数量最多为2^29-1
- CAPACITY:线程池容量,=(1<<COUNT_BINTS)-1
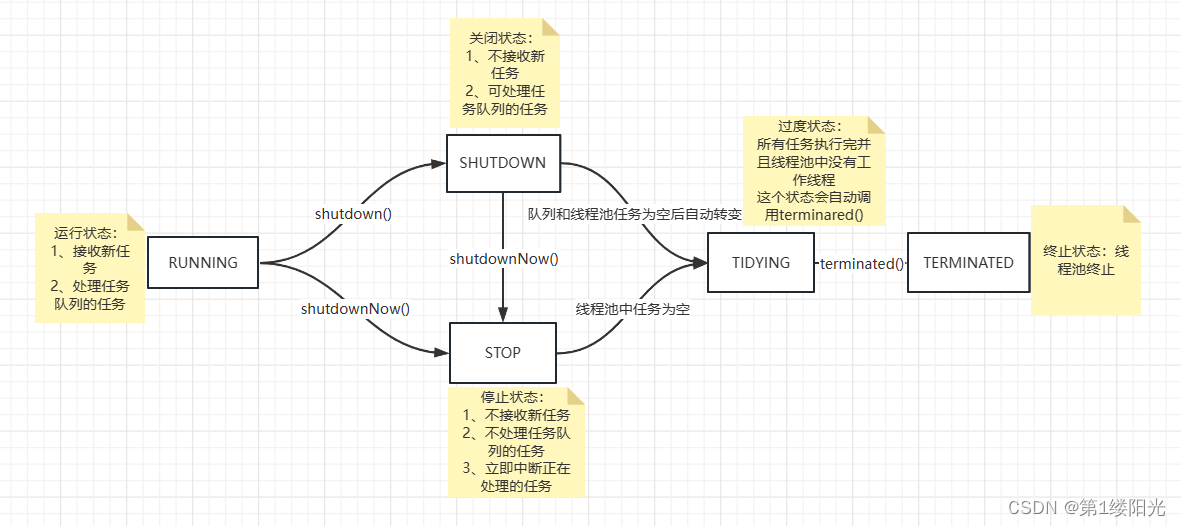
- RUNNING、SHUTDOWN、STOP、TIDYING、TERMINATED:ctl高三位表示的线程池的五种状态
线程池状态转换图:
- runStateOf(int c):通过传入的c,获取最高三位的值,拿到线程池状态码
- workerCountOf(int c):获取当前线程数量,拿到现有线程数量
2、线程池的execute()方法执行过程
众所周知,我们需要调用线程池的execute()并传入线程,以能在将来某个时间执行传入的任务;所以,首先执行的是execute方法。


1343-1344:健壮性判断,传入的要执行的任务不能为空;
1365:获取ctl的具体值,包括线程池的状态和线程数量;
1366-1370:判断工作线程数是否少于核心线程数,如果少于,说明未达到核心线程数,则创建新的线程;
1367:如果创建成功,execute()方法结束;否则重新获取ctl的值:
如果工作线程不少于核心线程数(说明线程数已达到核心线程数)或工作线程少于核心线程数但新线程创建失败,则:
1371-1379:如果线程池为RUNNING状态,同时能成功将任务添加到任务队列中
1372:重新获取ctl的值
1373-1374:再次判断线程池状态是否为RUNNING,如果非RUNNING就执行remove将该任务从阻塞队列中删除
1374:根据拒绝策略执行拒绝任务,execute()结束
1375-1376:如果线程池状态不为RUNNING,判断工作线程数,如果工作线程数为0说明任务队列中有任务,但没有线程在执行任务,此时创建一个线程;
1378-1379:如果线程池状态不为RUNNING或状态为RUNNING但不能入队列,就创建线程数,如果创建失败则根据策略拒绝任务,execute()结束。
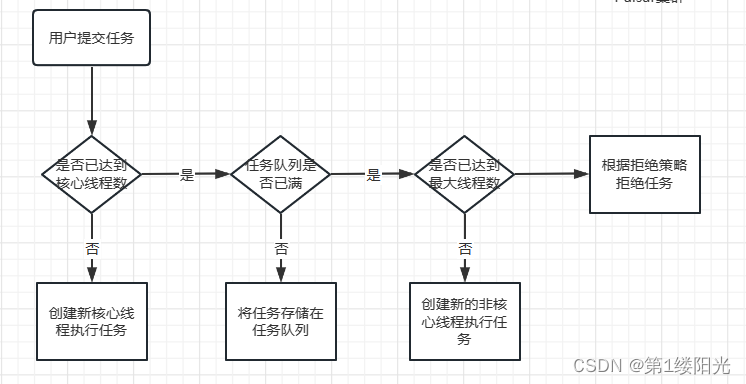
调用线程池execute()方法添加一个任务时,总结:
如果有空闲线程,使用空闲线程直接执行该任务;
如果没有空闲线程,且当前运行的线程数少于corePoolSize,则创建新的核心线程执行该任务;
如果没有空闲线程,且当前线程数等于corePoolSize,同时任务队列未满,则将任务放入任务队列等候;
如果没有空闲线程,且任务队列已满,同时线程池中的线程数小于maxinumPoolSize,则创建新的线程执行任务;
如果没有空闲线程,且任务队列已满,同时线程池中的线程数等于maxinumPoolSize,则根据拒绝策略拒绝新的任务。
3、线程池addWorker方法执行的流程
private boolean addWorker(Runnable firstTask, boolean core) {
// for循环的标志
retry:
for (; ; ) {
int c = ctl.get();
int rs = runStateOf(c);
// 查看是否可以不去构建新的工作线程:如果线程池状态不是RUNNING并且线程池状态不是SHUTDOWN、任务不为空、工作队列为null,就不用去创建新线程了
if (rs >= SHUTDOWN // 如果线程状态不是RUNNING
&&
!(rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty()))
// 线程不是SHUTDOWN状态(那也就是STOP,TIDYING,TERMINATED三者之一)
// 任务不为空 -> 这里对应上述的addWorker(null,false)
// 工作队列为null
// 这时直接return false,不去构建新的工作线程
return false;
for (; ; ) {
// 获取工作线程数
int wc = workerCountOf(c);
if (wc >= CAPACITY || // 如果工作线程大于最大线程容量
wc >= (core ? corePoolSize : maximumPoolSize)) // 或者当前线程数达到核心/最大线程数的要求
return false; // 直接结束,添加Worker失败。
if (compareAndIncrementWorkerCount(c)) // 以CAS的方式添加线程
break retry; // 如果成功,跳出最外层循环
c = ctl.get(); // 再次读取ctl的值
if (runStateOf(c) != rs) // 如果运行状态不等于最开始查询到的rs,那就从头循环一波。
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// 开始添加工作线程
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask); // 构建Worker对象传入任务
final Thread t = w.thread; // 将worker线程取出
if (t != null) {
// 拿到全局锁,避免我在添加任务时,其他线程干掉线程池,因为干掉线程池需要获取到这个锁
final ReentrantLock mainLock = this.mainLock;
// 加锁
mainLock.lock();
try {
// 获取线程池状态
int rs = runStateOf(ctl.get());
// 两种情况允许添加工作线程
if (rs < SHUTDOWN || // 判断线程池是否是RUNNING状态
(rs == SHUTDOWN && firstTask == null)) { // 如果线程池状态为SHUTDOWN并且任务为空
if (t.isAlive()) // 如果线程正在运行,直接抛出异常
throw new IllegalThreadStateException();
// 添加任务线程到workers中
workers.add(w);
// 获取任务线程个数
int s = workers.size();
// 如果任务线程大于记录的当前出现过的最大线程数,替换一下。
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true; // 任务添加的标识设置为true
}
} finally {
mainLock.unlock(); //任务添加成功,退出锁资源
}
if (workerAdded) { // 如果添加成功
t.start(); // 启动线程
workerStarted = true; // 标识启动标识为true
}
}
} finally {
if (!workerStarted) // 如果线程启动失败
addWorkerFailed(w); // 移除掉刚刚添加的任务
}
return workerStarted;
}
————摘自郑金维老师的讲解