Hive的定义:
基于Hadoop的数据仓库解决方案将结构化的数据文件映射为数据库表
提供类sql的查询语言HQL (Hive Query Language)
Hive让更多的人使用hadoop
Hive的运行机制
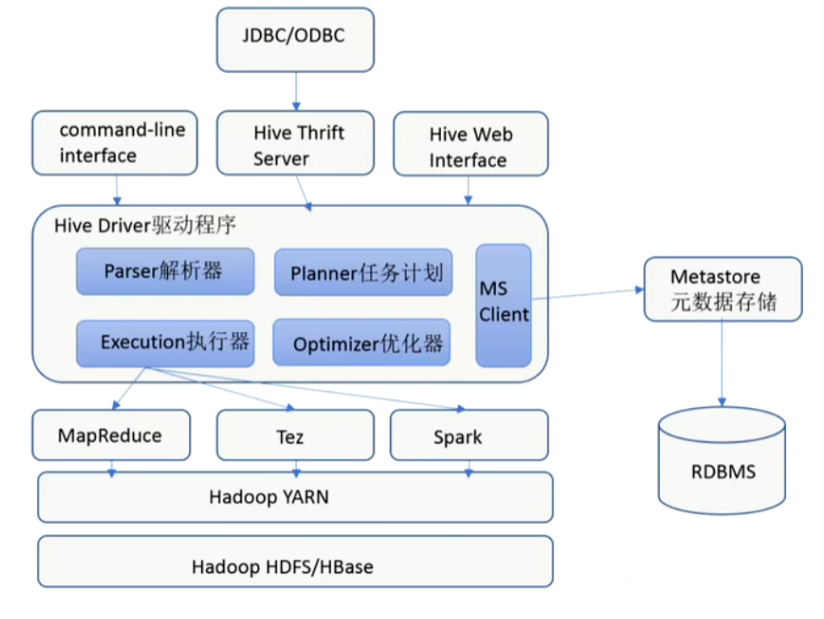
Hive 通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的 Driver,
结合元数据(MetaStore),将这些指令翻译成 MapReduce,提交到 Hadoop 中执行,最后,将
执行返回的结果输出到用户交互接口。

Hive环境搭建:
安装jdk、hadoop、mysql (元数据管理使用)
Hive组件:
开启hive的两种方式:
第一种:本地登陆
[root@siwen ~]# start-all.sh
[root@siwen ~]# jps
[root@siwen ~]# hive ----直接hive
hive (default)> exit; ------退出hive
第二种:远程登陆
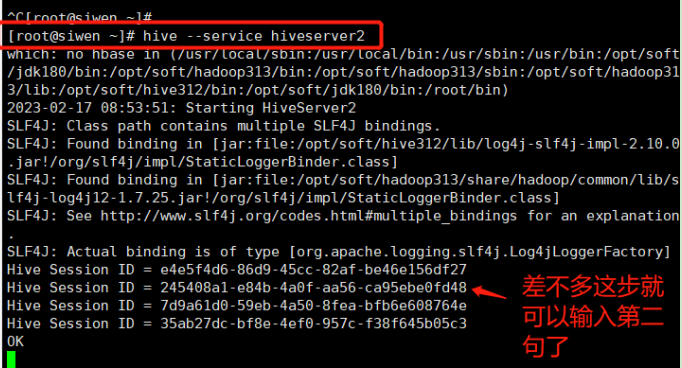
[root@siwen ~]# hive --service hiveserver2 开启成功后再进行下一步
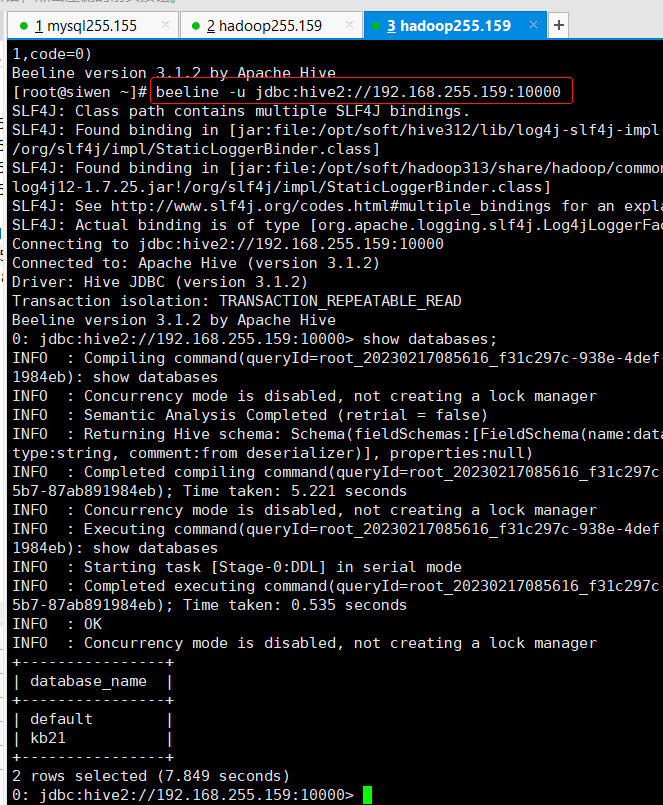
[root@siwen ~]# beeline -u jdbc:hive2://192.168.255.159:10000
注:
[root@siwen stufile]nohup hiveserver2 1>/dev/null 2>&1 & 此语句表示把反馈的信息放到一个黑洞里面,不再提示,这样就不用占着两个窗口了




![[数据结构]:13-插入排序(顺序表指针实现形式)(C语言实现)](https://img-blog.csdnimg.cn/326b864d645e49419a6daeef37135d44.png)




![MySQL全解[集群篇]](https://img-blog.csdnimg.cn/b468ed13db7f417ca41ca1d4888c24f3.png)
