四年一度的世界杯已正式拉开战幕,各小组比赛正如火如荼地进行中。在这样一场球迷的盛宴中,不如让 Towhee 带你「以文搜球」,一览绿茵场上足球战将们的风采吧~
「以文搜球」是跨模态图文检索的一部分,如今最热门的跨模态图文检索模型莫过于 CLIP,关于模型的原理详解和相关使用教程,推荐参考从零到一,教你搭建从零到一,教你搭建「以文搜图」搜索服务系列文章。
世界杯是一场全球的盛宴,这里有来自不同地区、使用着不同语言的朋友们。那我们在“搜球”的时候如何能支持其他语言的文本,比如中文?甚至同时支持多种语言的「以文搜球」呢?
中文版搜球
如果观察目前主流的图文跨模态模型,我们会发现它们的架构基本都包含了文本编码器和视觉编码器,分别用于提取文本和图片的特征。那么面对不同语言的文本,模型只需要使用不同的文本数据训练文本编码器,使其适配对应的视觉编码器,就能让文本和图片向量映射到相同的特征空间。
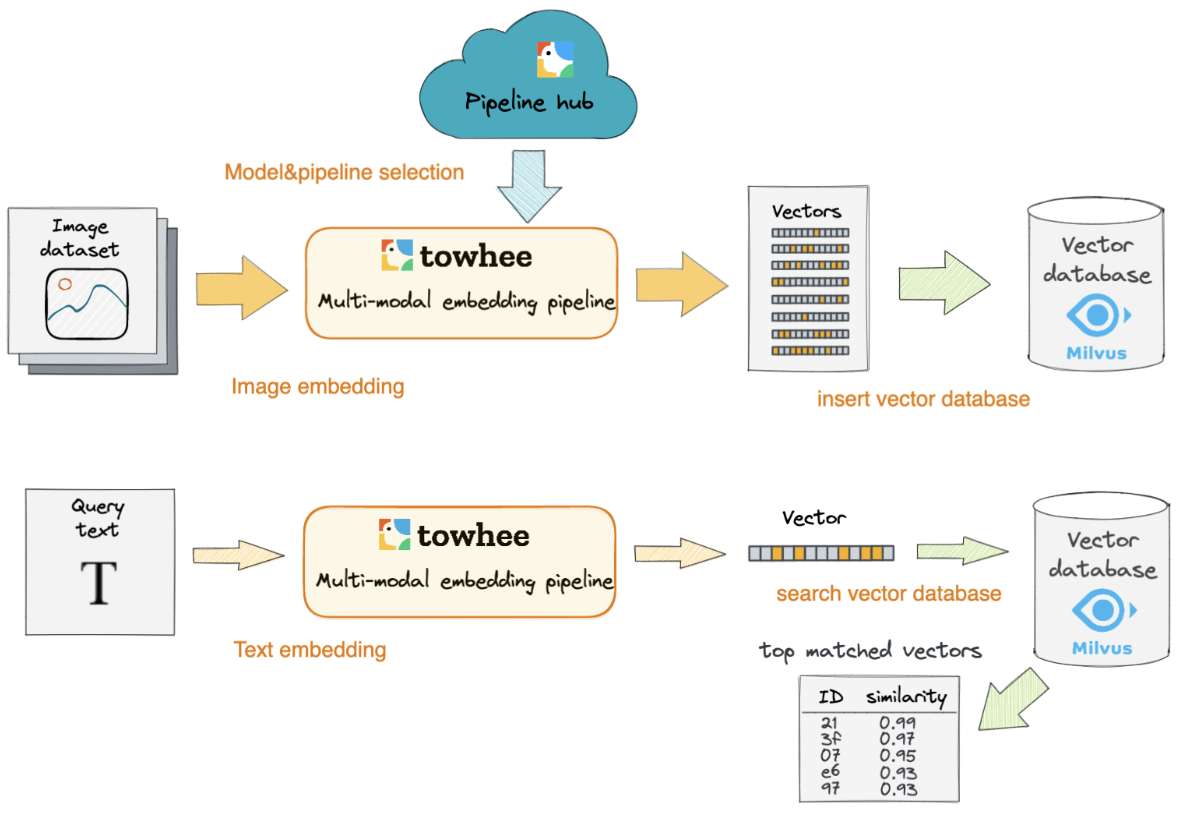
为了方便用户使用,Towhee 用更加友好的 Python 接口包装了一些预训练模型。用户可以根据目标任务直接选择不同算子提取图片与文本向量,其中支持了中文输入。这里我们以算子 image_text_embedding.taiyi 为例,用 10 张图片搭建一个简单的「以文搜图」服务。

-
数据:10 张图片来自图像数据集 ImageNet 中的“soccer_ball”类别,包括了足球相关的图片。
-
特征提取:image_text_embedding.taiyi 能够将中文或图片转换成向量,使用同一个模型生成的向量拥有同样的特征空间。
-
向量数据库:这里搭建的「以文搜图」系统使用了 Milvus 实现向量存储与检索,包括匹配对应的图片路径。
1. 准备工作
为了之后的向量存储和检索,我们需要事先启动 Milvus 服务,具体教程可以参考 Milvus 官网文档。此外,我们还需要安装相关的 Python 依赖,包括 Towhee 和 Pymilvus(注意根据自己的环境安装其他所需要的依赖包)。
python -m pip install towhee pymilvus
最后,我们需要准备一个 Milvus 集合,用于之后的向量存储和检索。在创建集合的时候,你可以根据自己的需求配置不同的参数。下面是用 Python 创建 Milvus 集合的代码示例,该集合配置如下:
-
集合名:唯一且不重复,用于指定集合
- 数据表格:
-
id:主键,由系统自动生成唯一且不重复的整数(无需插入) -
embedding:图片向量,由 512 维浮点数组成 -
path:图片路径,由字段组成
-
-
索引:基于
embedding列数据创建 IVF_FLAT 索引(参数"nlist":2048),同时选择 IP 内积 衡量向量之间的相似度(距离越大表示越相似)
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
HOST = 'localhost'
PORT = '19530'
COLLECTION_NAME = 'text_image_search'
INDEX_TYPE = 'IVF_FLAT'
METRIC_TYPE = 'IP'
DIM = 512
TOPK = 3
def create_milvus(exist_ok=False):
try:
connections.connect(host=HOST, port=PORT)
except Exception:
raise RunTimeError(f'Fail to connect Milvus with {HOST}:{PORT}')
if utility.has_collection:
collection = Collection(COLLECTION_NAME)
if exist_ok:
print(f'Using existed collection: {COLLECTION_NAME}.')
return collection
else:
print('Deleting previous collection...')
collection.drop()
# Create collection
print('Creating collection...')
fields = [
FieldSchema(name='id', dtype=DataType.INT64, description='embedding ids', is_primary=True, auto_id=True),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, description='image embeddings', dim=DIM),
FieldSchema(name='path', dtype=DataType.VARCHAR, description='image path', max_length=500)
]
schema = CollectionSchema(fields=fields, description='text image search')
collection = Collection(name=COLLECTION_NAME, schema=schema)
# Create index
print('Creating index...')
index_params = {
'metric_type': METRIC_TYPE,
'index_type': INDEX_TYPE,
'params':{"nlist":2048}
}
collection.create_index(field_name='embedding', index_params=index_params)
print(f'Milvus collection is ready: {COLLECTION_NAME} ({INDEX_TYPE}, {METRIC_TYPE}).')
return collection
collection = create_collection()

2. 插入数据
当准备工作完成后,我们可以利用 Towhee 接口 实现一下流程:
-
根据图片路径读取并解码图片
-
利用预训练模型生成图片向量
-
将向量与对应的图片路径插入事先准备好的 Milvus 集合
import towhee
# Insert
insert = (
towhee.glob['path']('path/to/soccer_ball/*.JPEG')
.image_decode['path', 'image']()
.image_text_embedding.taiyi['image', 'vec'](
model_name='taiyi-clip-roberta-102m-chinese',
modality='image')
.ann_insert.milvus[('vec', 'path'), 'milvus_res'](
uri=f'tcp://{HOST}:{PORT}/{COLLECTION_NAME}')
# .select['path', 'image', 'milvus_res']()
# .show()
)
print(f'Total vectors in collection: {collection.num_entities}')
至此我们已经成功将 10 张样本图片对应的向量和路径存入数据库,一个可供「以文搜图」的系统就搭建好了。
3. 检索测试
接下来,让我们简单地用中文查询进行检索测试:
import towhee
query = (
towhee.dc['text'](['输入查询语句'])
.image_text_embedding.taiyi['text', 'vec'](
model_name='taiyi-clip-roberta-102m-chinese',
modality='text')
.ann_search.milvus['vec', 'milvus_res'](
uri=f'tcp://{HOST}:{PORT}/{COLLECTION_NAME}',
metric_type=METRIC_TYPE,
limit=TOPK,
output_fields=['path'])
.flatten('milvus_res')
.runas_op['milvus_res', ('image_path', 'score')](lambda x: (x.path, x.score))
.image_decode['image_path', 'image']()
.select['text', 'image', 'score']()
.show()
)
通过查询“小孩玩足球”、“小男孩玩足球”、“小男孩抱着足球”,我们对比前三名的搜索结果可以观察到该系统成功实现了文本描述与图片内容的匹配。当文本描述出图片之间的差别时,相似度之间的差异会变得更加明显。



多语言版搜球
对比英文版本的「以文搜图」,我们可以发现其实只需要替换向量化的算子就能够实现中文查询。同理可见,如果有一个算子使用了支持多种语言的预训练模型,我们就可以搭建一个同时支持多种语言查询的「以文搜图」服务。
下面就是这样一个例子,同时也展示了如何在 Towhee 流水线中使用自定义算子。该自定义算子使用了 towhee.models.clip 中一个支持多语言文本的预训练模型 ‘clip_vit_b32’,能够将不同语言的文本与图像匹配。
-
自定义算子:
from towhee.models.clip import create_model
from torchvision import transforms
from PIL import Image
import numpy()
model = create_model('clip_vit_b32', pretrained=True, device='cpu')
def encode_text(x):
features = model.encode_text(x, multilingual=True).squeeze(0).detach().cpu().numpy()
return features
def encode_image(x):
tfms = transforms.Compose([
transforms.Resize(224, interpolation=transforms.InterpolationMode.BICUBIC),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
(0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
])
img = Image.open(x)
x = tfms(img).unsqueeze(0)
features = model.encode_image(x).squeeze(0).detach().cpu().numpy()
return features
-
插入数据:
import towhee
# Insert
insert = (
towhee.glob['path']('path/to/soccer_ball/*.JPEG')
.runas_op['path', 'vec'](func=encode_image)
.ann_insert.milvus[('vec', 'path'), 'milvus_res'](uri=f'tcp://{HOST}:{PORT}/{COLLECTION_NAME}')
.select['path', 'milvus_res']()
.show()
)
print(f'Total vectors in collection: {collection.num_entities}')
-
文本查询:
import towhee
query = (
towhee.dc['text'](['输入查询语句'])
.runas_op['text', 'vec'](func=encode_text)
.ann_search.milvus['vec', 'milvus_res'](
uri=f'tcp://{HOST}:{PORT}/{COLLECTION_NAME}',
metric_type=METRIC_TYPE,
limit=TOPK,
output_fields=['path'])
.flatten('milvus_res')
.runas_op['milvus_res', ('image_path', 'score')](lambda x: (x.path, x.score))
.image_decode['image_path', 'image']()
.select['text', 'image', 'score']()
.show()
)




分别查询中文、英文、西班牙语、法语的“小男孩玩足球”,我们可以获得几乎相同的查询结果。
通过本文,我们学习了如何用 Towhee 搭建一个简单的「以文搜球」系统,成功地支持了中文等多种语言的输入。还不快快试着搭建一个「搜球」系统吗?
如果需要应用到实际业务,大家可以用更多的方法优化模型、优化系统,比如用业务数据微调模型、加速推理服务、实现并列运行、加入异常处理机制等。