文章目录
- Transformer
- 前言
- 网络结构图:
- Encoder
- Input Embedding
- Positional Encoder
- self-attention
- Padding mask
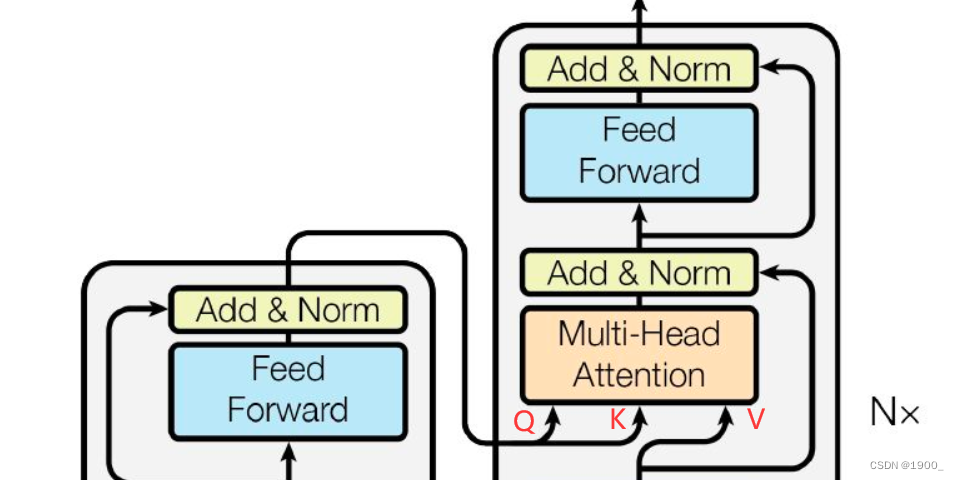
- Add & Norm
- Feed Forward
- Decoder
- input
- masked Multi-Head Attention
- test时的Decoder
- 预测
Transformer
前言
Transformer最初是用于nlp领域的翻译任务。
出自谷歌2017年发表的论文Attention Is All You Need
当然现在已经应用于各类任务了,在CV领域也表现非常出色。本文是自己的学习笔记,因为我主要是看图像方面的,所以中间有些关于nlp的一些特殊知识没有详细说,如有兴趣,请自行查阅。
参考链接:
台大李宏毅自注意力机制和Transformer详解
李沐老师讲解Transformer
自注意力机制讲解
Transformer详解
Transformer 详解
详解Transformer (Attention Is All You Need)
Transformer模型详解(图解最完整版)
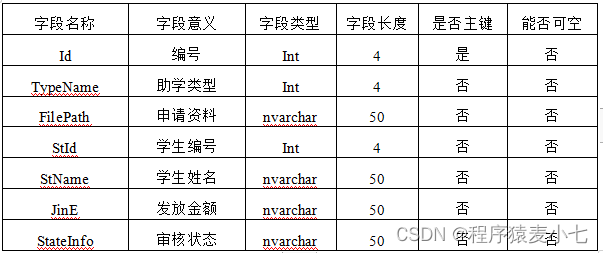
网络结构图:
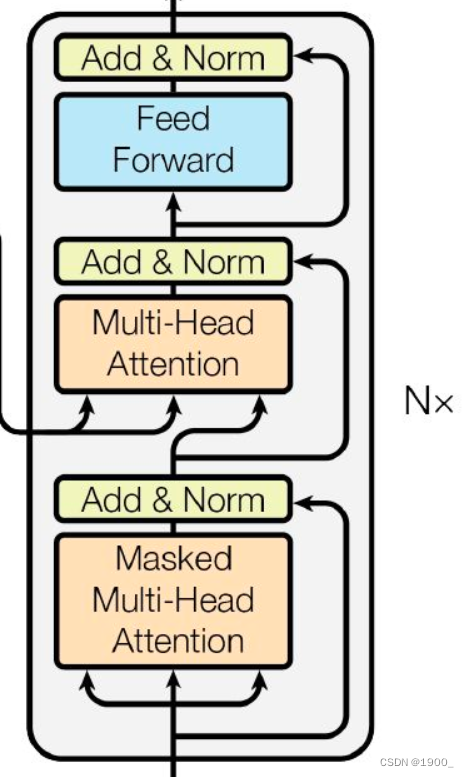
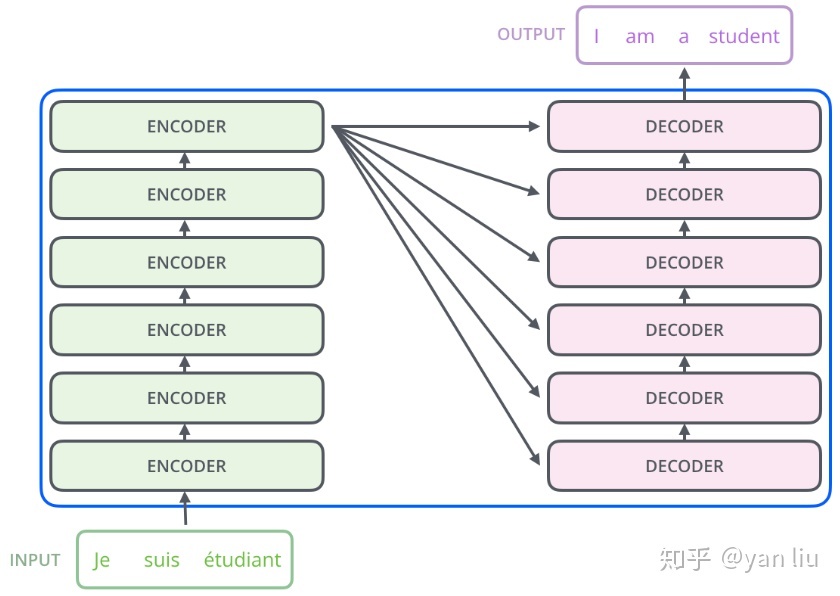
这个结构图很清晰,左边是编码器,右边是解码器。
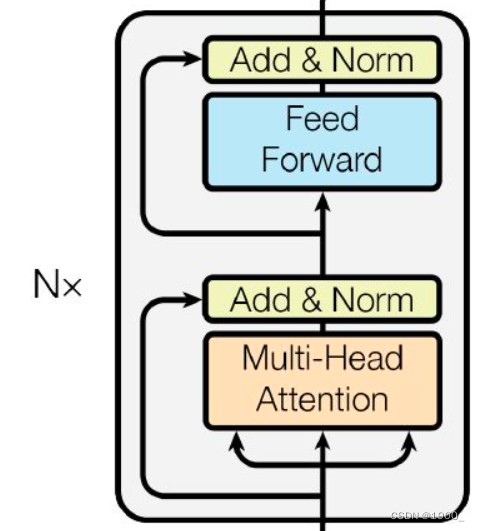
编码器:由N=6个相同的层堆叠而成。每层有两个子层。第一层是一个multi-head self-attention机制,第二层是一个简单的、按位置排列的全连接前馈网络。两个子层都采用了一个residual(残差)连接,然后进行层的归一化。也就是说,每个子层的输出是LayerNorm(x + Sublayer(x)),其中Sublayer(x)是由子层本身的输出。
解码器:解码器也是由N=6个相同层的堆栈组成。注意,解码器也是有输入的,解码器的输入先经过一个masked multi-head self-attention,然后是残差和layerNorm,然后再与编码器的输出一起送入一个与编码器一样的结构。重复6次。最后经过线性层和softmax输出结果。
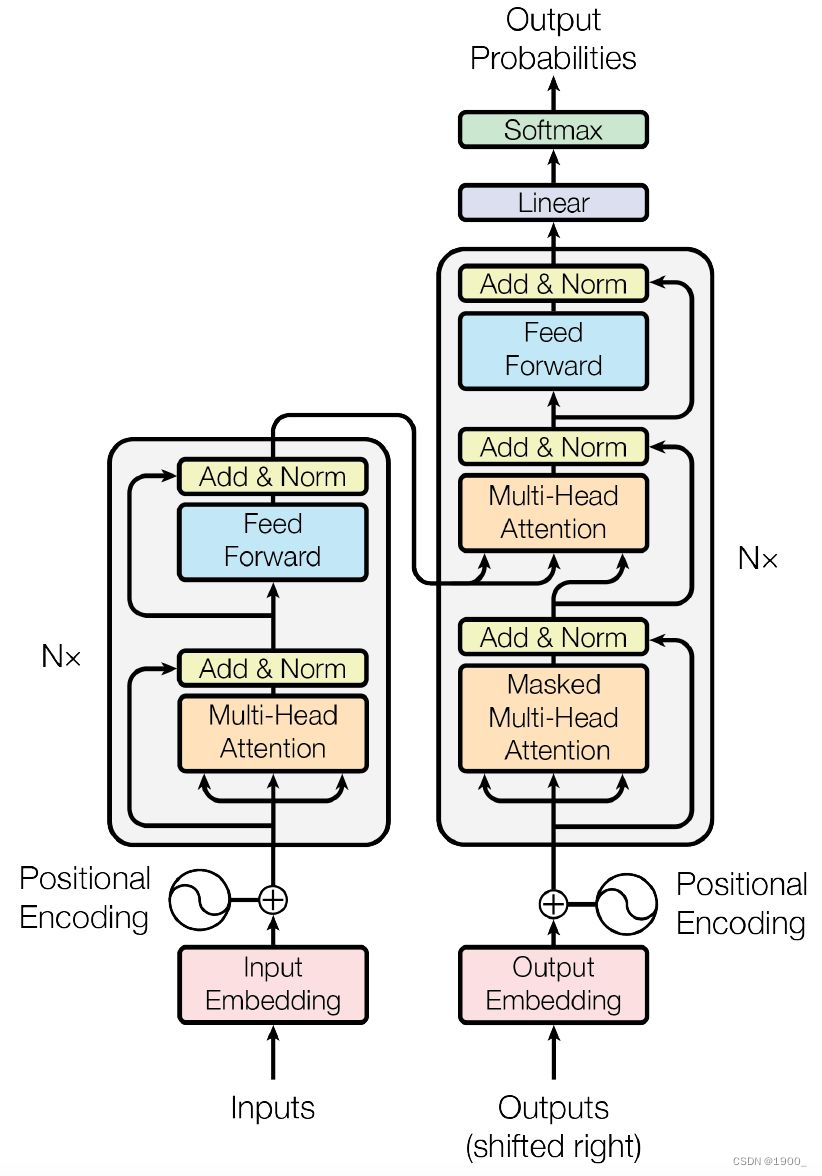
我们一步一步的看,先说左边的编码器。
Encoder
Input Embedding
首先说input输入,既然是做翻译任务那么输入自然是一个句子,比如I love you
那么这个肯定不能直接输入进去,计算机也不认识啊,一般我们都需要转化为方便计算机处理的形式。在图像领域,我们会把图像处理为[B,C,H,W]的矩阵交给计算机处理,那么nlp领域也是一样,我们可以采用一种方法讲单词转化为向量:One-hot 独热码
非常简单,就是假设词汇表一共只有五个单词,那我就用一个长度=5的向量,第一个单词就是{10000},第二个{01000},以此类推,如图所示。如果字典一共有五千个词汇,那么编码得到的向量长度就是5000。
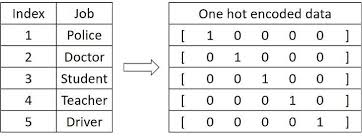
但是这种方法很显然不好,它很稀疏(有效信息太少),而且很长(太长了计算量太大了)。
更重要的是这种编码方式完全无法体现出来词汇之间的关系,比如“香蕉”和“西瓜”,都是水果,他们是有联系的,但是这种编码方式忽略了关系,只与他们在词汇表的位置有关。
那么有另外一个方法叫做word Embedding,他会给每一个词汇对应一个向量,并且这个向量是包含语义的信息的。
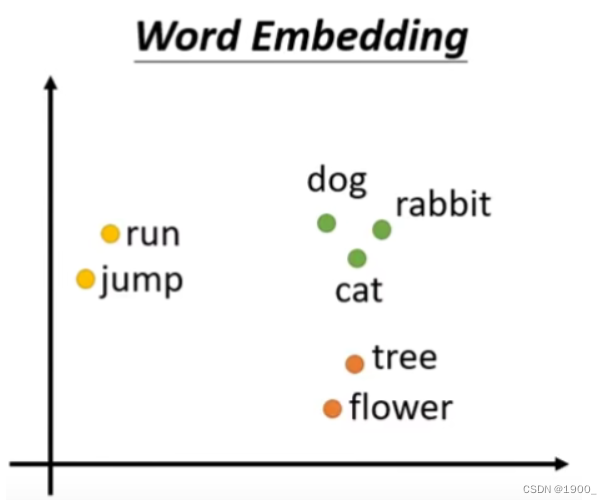
至于word Embedding是怎么做的,这里不说了,感兴趣的自己搜索看下,我主要是做图像的。
我们只要知道,Transformer的第一步Input Embedding就是将输入的词汇,编码成了一个一个的向量(长度为512)。
Positional Encoder
转化为词向量后还需要给每个词向量添加位置编码positional encoding。因为位置是有用的,同样一个单词放在句首和放在句中,可能会有不同的词性,会有不同的意思,所以位置信息我们也需要。
如何获得位置编码?论文中使用正余弦位置编码来为每个词计算位置向量。位置编码通过使用不同频率的正弦、余弦函数生成,生成的向量长度与词向量长度一致(待会要相加)。
正余弦位置编码计算公式如下,至于为什么这样设计,可以看其他的讲解文章Transformer 中的 Positional Encoding
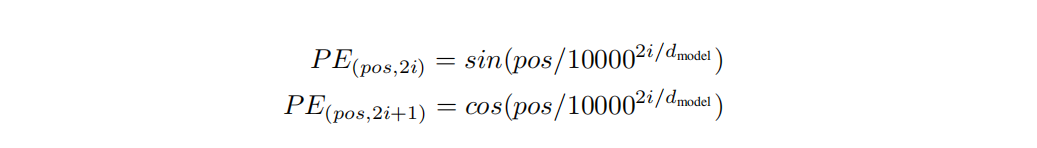
经过这个我们可以得到位置编码,再和前面得到的词向量做加法,就得到了我们处理好的输入。
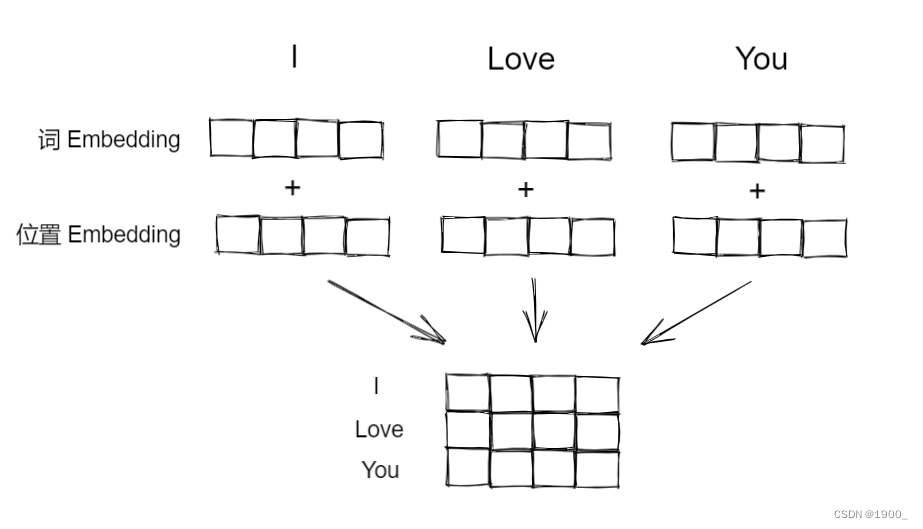
假设输入的是I Love You,那么最后这个输入的尺寸就是[3,512]
接下来才开始进入真正的编码器部分。
self-attention
Transformer就是基于自注意力的
关于self-attention,可以看我在另一篇博客中的介绍:自注意力机制
这里就简单说下:
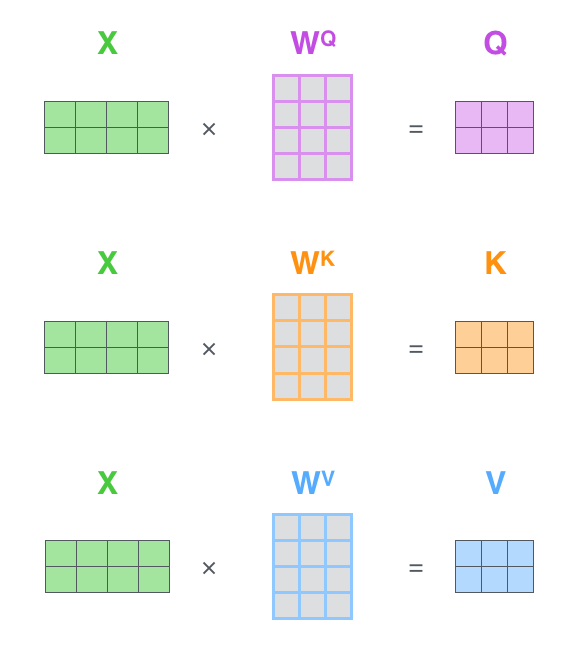
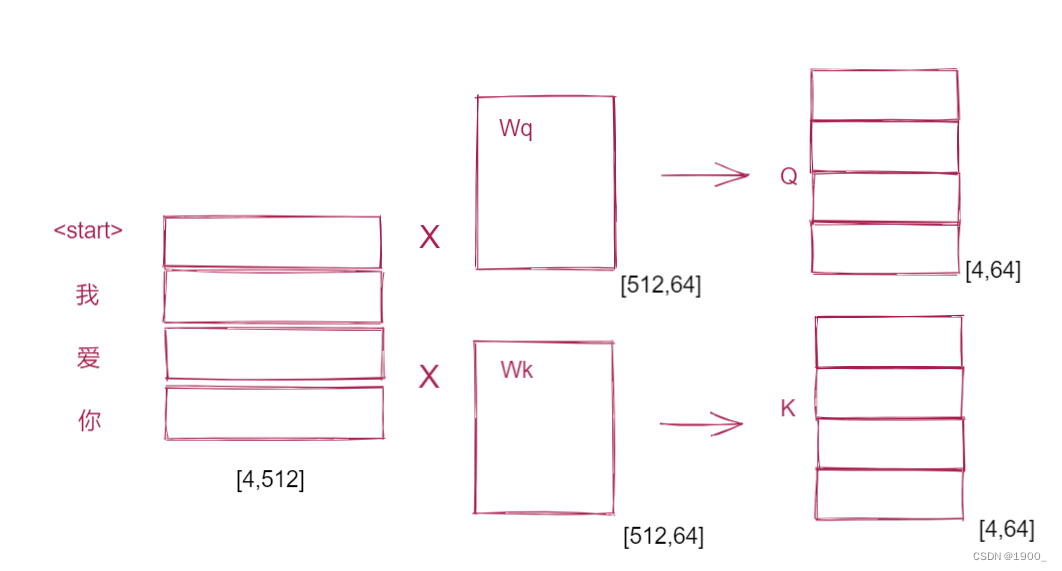
简单来说就是输入的向量x,分别与三个矩阵相乘得到 Q , K , V Q,K,V Q,K,V,也就是query,key,value
这里x的大小是[2,512], W Q W^Q WQ的大小是[512,64],所以得到的结果是[2,64],如果输入是三个单词,那就是[3,64]
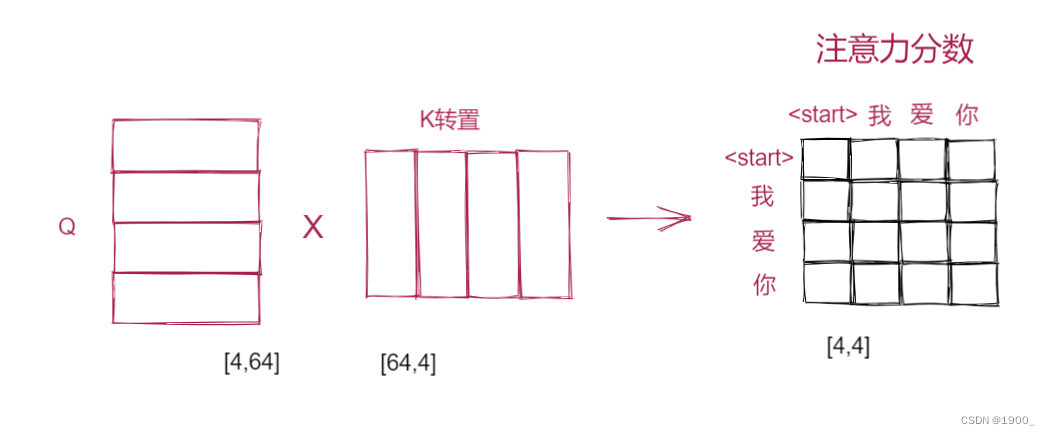
然后Q和 K T K^T KT相乘得到注意力分数,再做一个softmax映射,然后再与V相乘,就得到了自注意力的输出。
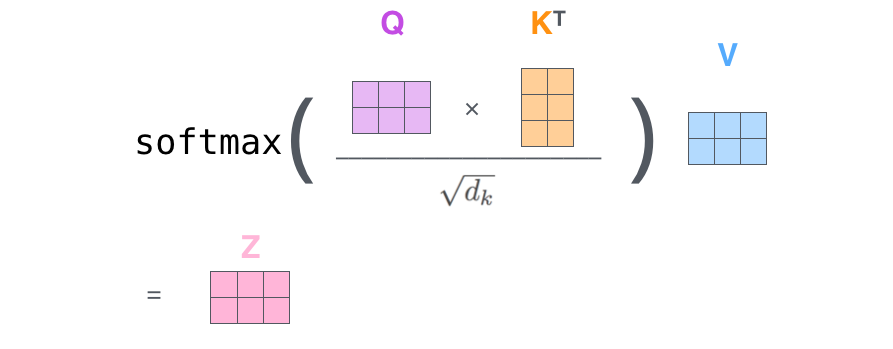
这里为什么要除以一个根号下dk(dk就是K的维度,也就是64),是因为公式中计算矩阵Q和K每一行向量的内积,为了防止内积过大,因此除以向量维度的平方根。
这里注意,我们假设输入的尺寸是[3,512],计算得到的Q,K,V都是同样的尺寸[3,64],然后Q乘以
K
T
K^T
KT就得到[3,3]大小,再乘以V:[3,64],最终得到的结果是[3,64]大小。
这个V其实就相当于,输入向量本身,注意力分数就是考虑了全部的相关性,V与注意力分数相乘,就是相当于输入序列考虑了所有的单词,然后进行有侧重的调整。
这就是自注意力机制,那么多头自注意力机制就是使用多组Q,K,V,来得到多个结果,最后拼接在一起。
假设我们用8个头,那么就会得到8个[3,64]的矩阵,cat在一起就是[3,64*8]=[3,512]大小。

但是我们还是需要[3,64]的大小,所以将这个结果再乘以一个权重矩阵[512,64]的,就能变回原来的大小了。
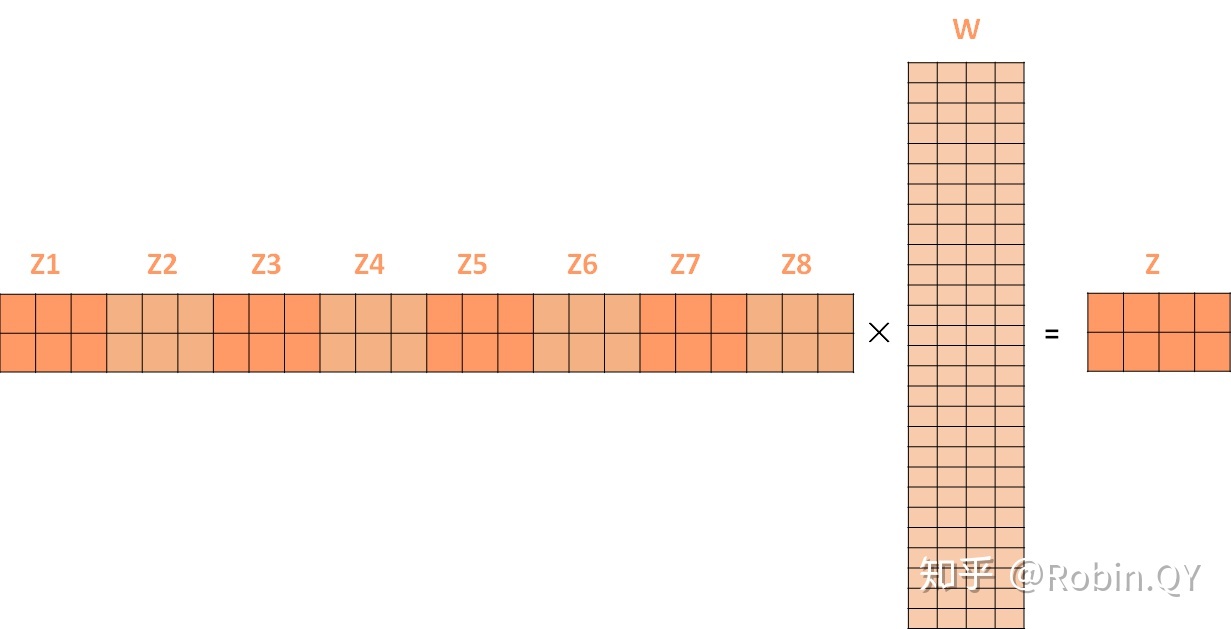
最终的Z就作为后面模块的输入。
Padding mask
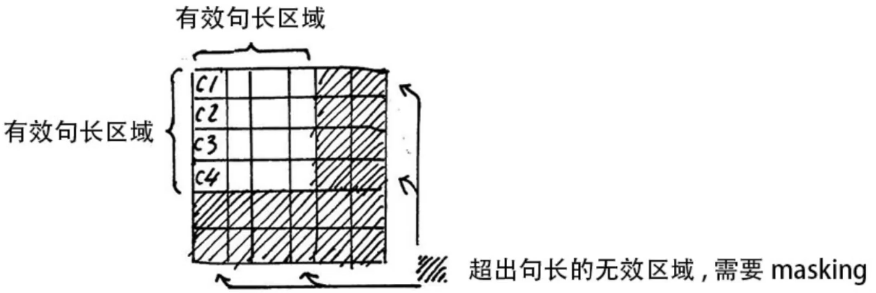
这里强调一个东西Padding mask
我们的输入数据是一个单词序列。那么每个单词被编码后,得到的是不同长度的词向量。
有的长,有的短,这个时候我们就会做补齐操作,一般是填充0。0乘以其他数字也是0,所以我们经过自注意力得到的结果里面也有很多0,然后在我们进行softmax的时候就有问题了。softmax是指数运算, e 0 = 1 e^0=1 e0=1是有值的,所以这些填充的0会影响到计算结果。
这就相当于让无效的部分参与了运算。因此需要做一个 mask 操作,让这些无效的区域不参与运算,一般是给无效区域加一个很大的负数偏置,趋近于 − ∞ -∞ −∞,这样的话再做softmax,他就会趋近于0,就不会影响到结果。
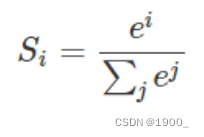
这个就叫做padding mask。具体的做法就是我们有一个mask矩阵,不需要mask的位置是False,需要mask的位置是True,然后在我们计算出注意力分数之后,对已经计算好的scores,按照mask矩阵,填-1e9。下一步计算softmax的时候,被设置成-1e9的数对应的值~0,被忽视。
Add & Norm
经过自注意力机制之后呢,图上写着Add & Norm
Add的意思就是一个残差连接,
Norm 的意思是归一化,但是这里要注意,这里不是我们图像里面常用的Batch Normalization(BN)
Batch Normalization的目的是使我们的一批(Batch)feature map满足均值为0,方差为1的分布规律。
BN对整个Batch进行操作,就是对每一列进行操作。啥意思呢,假设batchsize=3,有三行数据,分别是身高,体重,年龄。
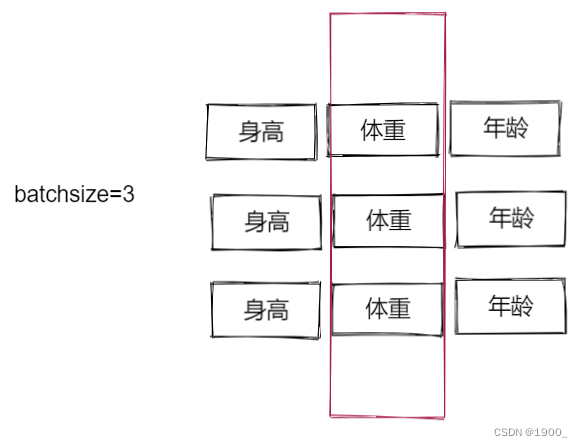
BN是对每一列做归一化,使其满足均值为0,方差为1的分布规律
而Layer Normalization(LN)则是对每一行进行归一化。
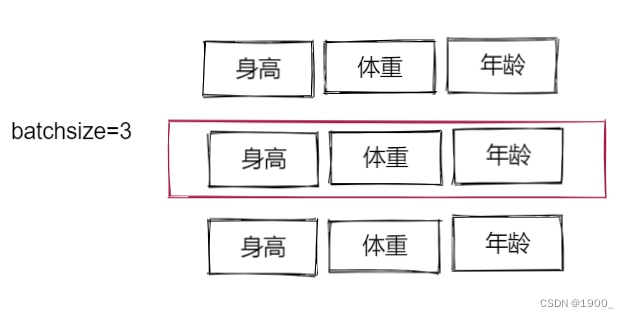
这里看起来不太合理,对每一行进行归一化就乱了。但是nlp领域很适合LN。
因为我们每一行是一句话,所以对每一行做归一化是合理的,相反对每一列做归一化是不合理的。
这里我解释的不一定对,大家可以搜一些别的资料看看。反正这个就是做归一化的。
公式表示如下:

Feed Forward
这里比较简单,就是一个两层的神经网络,先线性变换,过一个ReLU,然后再线性变换即可。
公式表示如下:
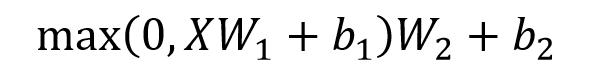
X是输入,Feed Forward 最终得到的输出矩阵的维度与X一致。
W1和W2的大小取反即可。假设输入X大小是[3,64],那么W1取[64,1024],W2取 [1024,64]。
(3,64)x(64,1024)x(1024,64)=(3,64)大小不变。
FeedForward的作用是:通过线性变换,先将数据映射到高纬度的空间再映射到低纬度的空间,提取了更深层次的特征。
FeedForward完了之后再经过一个Add&Norm,得到一个[3,64]的大小
至此Encoder部分就结束了
将输出再作为输入,将此部分重复N次。
Decoder
input
翻译是一个seq2seq的任务,输入三个单词我们并不知道要翻译出来几个单词,这些是不确定的。
所以我们需要让网络知道在哪里结束,所以我们翻译我爱你的时候
Encoder的输入是我爱你
Decoder的输入是<start>我爱你
Decoder的输出是I love you <end>
首先说Decoder的输入,有两种输入,一种是训练时候的输入,一种是预测时候的输入。
- 训练的时候:输入为Ground Truth,也就是不管输出是什么,会将正确答案当做输入,这种模式叫做teacher-forcing。
- 预测的时候:预测的时候没有正确答案,那么我们的输入是已有的预测,具体来说就是先输入一个
<start>然后过一遍decoder,让网络预测出I,然后将<start> I当作输入,再过一遍decoder,以此类推,最终翻译出整个句子。所以,这里我们可以看出来,预测的时候Decoder并不是并行的,而是串行的,需要一个单词一个单词去预测。
Decoder这边的输入,同样的经过位置编码,相加之后,输入进去。
同样的Decoder的输入也不是等长的,所以我们Decoder部分也需要一个Padding mask。
接下来才是Decoder核心的部分。
masked Multi-Head Attention
首先是一个masked Multi-Head Attention
可以看到,这里和Encoder里面的自注意力不一样,加了个mask,为什么加了个mask呢。
我们首先来看下,Decoder部分输入句子我爱你,经过编码送入自注意力中,如下图所示
Q和K的转置相乘就是注意力分数,然后会做一个softmax。在做softmax之前,要注意,最后这个[4,4]的矩阵,第一行代表的就是第一个词语<start>与整个句子四个词语分别计算得到的相关性。第二行同理。
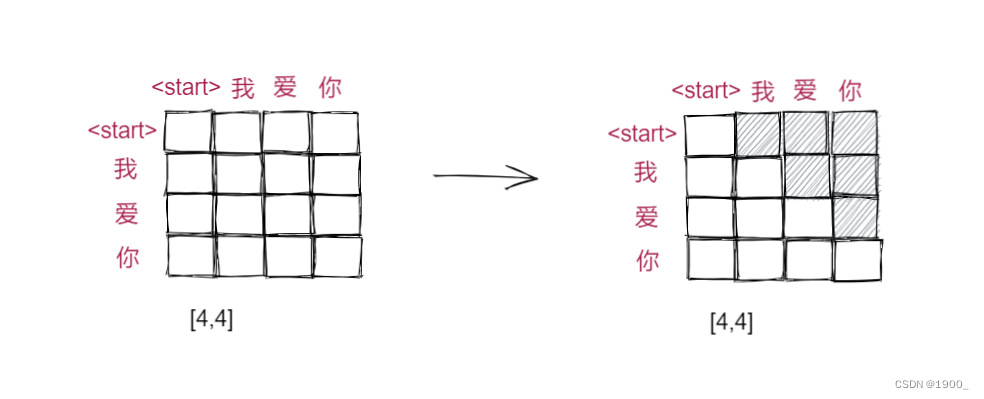
但是有一个问题,我们现在是在训练,我们自然掌握了Ground Truth,但是我们实际预测的时候,没有标准答案,实际的预测是我们把<start>输入进去,然后网络预测出I,然后将<start> I当作输入,再过一遍decoder,以此类推,最终翻译出整个句子。那我们训练的时候怎么做到这一点呢?
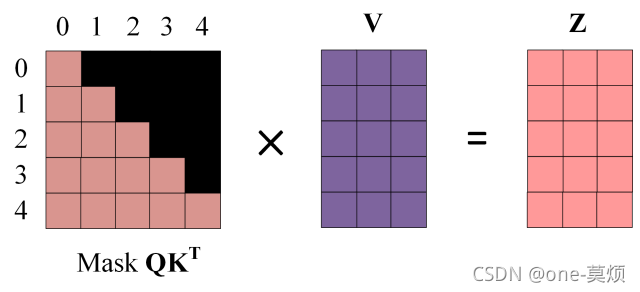
这就是用到sequence mask了,在softmask之前,用一个掩码矩阵,右上角全部是一个负的极大值,左下角为0,与注意力分数的矩阵相加,就可以保留下来左下角的数据了。经过softmax,右上角的数据都会被处理为0。

这个操作的意义就在于,经过这个操作,第一行<start>,只能看到它跟自己的注意力分数(相关度),而第二行我字,可以看到他与<start>和我的注意力分数,同理,第三行能看到前三个的,每一个单词都只能考虑他以及他之前的单词。这是符合预测的,因为第一个单词进来的时候,是不应该看到之后的单词的,实际中我们做预测的时候也确实是这么做的。所以训练的时候使用masked多头自注意力。
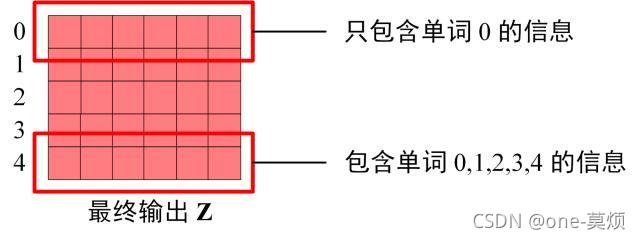
将这个mask后的注意力分数,经过softmax,在与V相乘,就得到自注意力的输出Z,这个Z的第一行Z1只包含第一个单词的信息,第二行只包含前两个单词的信息,以此类推。多个头,就得到了多个Z。
多头的结果cat起来,经过一个线性层,改变尺寸,使尺寸与出入同样大小。
然后经过Add&Norm,这就和Encoder那里一样。这样,解码器的第一部分就完成了。
解码器的第二部分,没有什么新的东西,主要就是,将编码器的输出,计算得到Q和K,然后将解码器第一部分的输出,计算得到V,拿这个Q,K,V去参与自注意力运算,最后再过一个Add&Norm,然后再过一个Feed Forward,再过一个Add&Norm。就结束,这就是整个Decoder的内容。将这部分也重复N次。
编码器和解码器都会重复N次,但是解码器中使用的编码器的结果,都是最后一次编码器给出的。他们的关系是这样的
test时的Decoder
上面说的是训练时候的decoder,实际测试的时候,比如我们输入我爱你,让网络翻译。
实际的流程是我爱你被输入到Encoder中,最顶层的Eecoder输出一个结果,然后Decoder中输入<start>,经过Decoder输出I,然后再将<start>和I一同输入Decoder,用结果的最后一个维度来预测love
预测
Decoder完了之后,就是最后一部分,预测单词
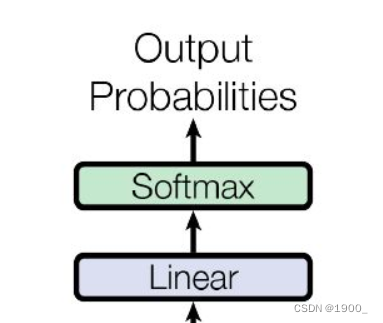
Decoder的输出,会经过一个线性层,在经过一个softmax,输出概率来预测单词。
比如,最后得到的矩阵是[4,512],那么第一行中512个元素的概率,最大的那个假设是25,那么说明预测的第一个单词就是对应的词汇表25位置上的单词。
因为 Mask 的存在,使得单词 0 的输出 Z0 只包含单词 0 的信息
Softmax 根据输出矩阵的每一行预测下一个单词
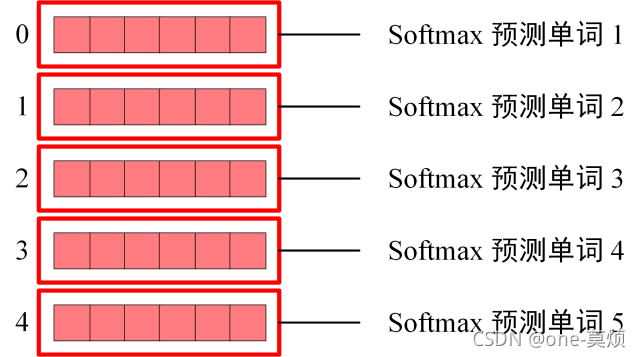
这也使得我们训练的时候,Decoder可以并行,我们一次就可以预测所有的单词。
我们可以直接使用最后一行的预测结果,与真实值做loss计算。