第一张图transfomer模型图,第二张图是是以各个功能模块的形式来呈现transformer的。
在这里我们来讲transformer的几个关键技术:
1.encoder部分的位置嵌入
2.encoder部分的多头注意力机制
3.残差连接
4.LayerNormalization
5.decoder部分的多头注意力的使用
6.sequence mask和padding mask
7.训练小技巧
目录
1.encoder部分的位置嵌入
2.encoder部分的多头注意力机制
3.残差连接
4.LayerNormalization
5.decoder部分的多头注意力的使用
6.sequence mask和padding mask
7.训练小技巧
1.encoder部分的位置嵌入
由于transformer模型没有循环神经网络的迭代操作,所以我们必须提供每个字的位置信息给transformer,才能识别出语言中的顺序关系。这篇论文使用sin和cos函数的线性变换来提供给模型的位置信息。

其中pos指的是句子中字的位置,取值范围是[0,max sequence length),i指的是词向量的维度,如果i是偶数用的就是sin函数 ,i如果是奇数用的就是cos函数。每一个位置在embedding dimension维度上都会得到不同周期的sin和cos函数的取值组合,从而产生独一的纹理位置信息,模型从而学到位置之间的依赖关系和自然语言的时序特性。
我们拿例子举例,我们看看输入why do we work?的位置信息怎么编码的?

可视化一下,最后得到这样的效果:

所以,会得到why do we work这四个词的位置信息,然后embedding矩阵和位置矩阵的加和作为带有位置信息的新X,Xembedding_pos.

在这里记录一个问题,为啥要用sin cos这种方式编码呢?
答:作者这里这么设计的原因是考虑到NLP任务中,除了单词的绝对位置,单词的相对位置也非常重要,根据公式sin(α+β)=sinαcosβ+cosαsinβ以及cos(α+β)=cosαcosβ-sinαsinβ,这表明位置k+p的位置向量可以表示为位置k的特征向量的线性变换,为模型捕捉单词之间的相对位置提供了非常大的便利。
2.encoder部分的多头注意力机制
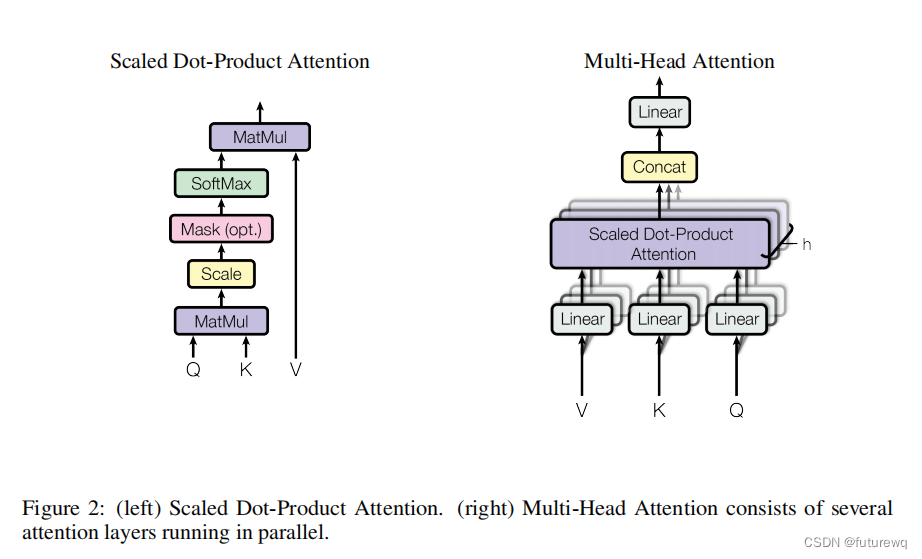
论文中的多头注意力机制示意图。其中多头是可以并行计算的。
这一步是为了学到多重语意含义的表达,进行多头注意力机制的运算。
每一个字经过映射之后都会对应一个R矩阵,这个R矩阵就是表示这个字与其他字之间某个角度上的关联性信息,这叫做单头注意力机制。
每个字经过多头注意力机制之后会得到一个R矩阵,这个R矩阵表示这个字与其他字在N个角度上(比如指代,状态...)的一个关联信息,这个角度就是用多个头的注意力矩阵体现的。这就是每个字多重语义的含义。
我们的目标是把我们的输入Xembedding_pos通过多头注意力机制先得到Z。然后Z通过前馈神经网络得到R。这个R矩阵表示这个字与其他字在N个角度(比如指代,状态...)上的一个关联信息.
先看下怎么得到这个Z:

其中WQ,WK,WV是可学习矩阵。Q表示query, K表示Key,V表示Value。之所以引入这三个矩阵,是借鉴了搜素查询的思想,比如我们有一些信息是键值对(key->value)的形式存到了数据库,(5G->华为,4G->诺基亚) ,比如我们输入的Query是5G,那么去搜素的时候,会对于一下Query和Key,把与Query最相似的那个Key对应的值返回给我们。这里是同样的思想,我们最后想要的Attention,就是V的一个线性组合,只不过根据Q和K的相似性加了一个权重并softmax一下。
我们用一个head具体来看下。

Q1和K1的相似度是用点击来衡量的,两个向量越相似,它们的点积就越大,反之就越小。
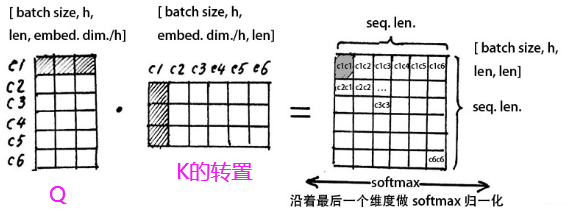
从每行来看,这样就可以得到 ,每个字和其他字的相似度,可以表示这个字和哪几个字更加相关。这个矩阵就是head1角度的注意力矩阵。
这里还有个问题需要好好关注,就是为啥QK^T要除以.
答:假设,这两个都是服从标准正态,那么E(XY)=E(X)E(Y)=0*0,方差:
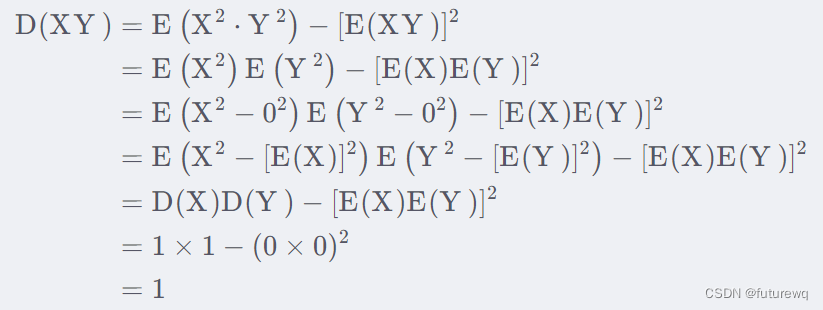
这样就会发现,qi,ki相乘依然是服从0-1的正态分布,那么dk个相加,根据
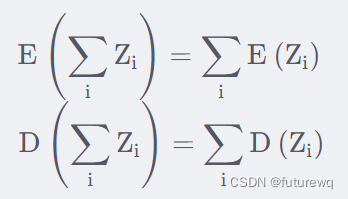
就能得到的均值是0,方差是dk.方差越大也就说明,点积的数量级越大(以越大的概率取大值)。那么一个自然的做法就是把方差稳定到1,做法就是将点积除以
。此时:
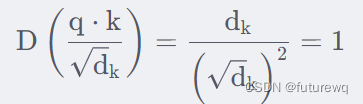
将方差控制到1,就能有效地防止梯度消失问题了,那么这个是为什么呢?先画出softmax图像来看看:这里假设输入时x=[a,2a,3a],看看随着a的增大,softmax图像的变化:

可以看到,数量级对softmax得到的分布影响非常大。在数量级较大时,softmax将几乎全部的概率分布都分配给了最大值对应的标签。而看这个图像的梯度,在输入值很大的时候,会发现导数几乎为0.
然后对每一行使用softmax归一化变成某个字与其他字的注意力的概率分布(使每一个字跟其他所有字的权重的和为1)
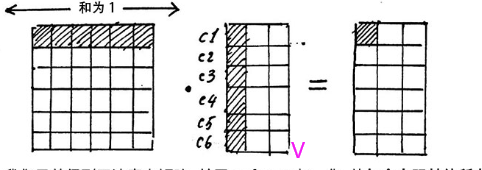
注意力矩阵中的每行,都依次点乘V的列,矩阵V的每一行代表着每一个字向量的数学表达,这样操作,得到的正是注意力权重进行数学表达的加权线性组合,从而使每个字向量都含有当前句子的所有字向量的信息。这样就得到了新的X_attention.
用这个加上之前的Xembedding_pos得到残差连接,训练的时候可以使得梯度直接走捷径反传到最初层,不易消失。另外,残差还有个好处就是能够保留原始的一些信息。
再经过一个LayerNormalization操作就可以得到Z。
所以多头注意力机制细节总结起来就是下面这个图了:
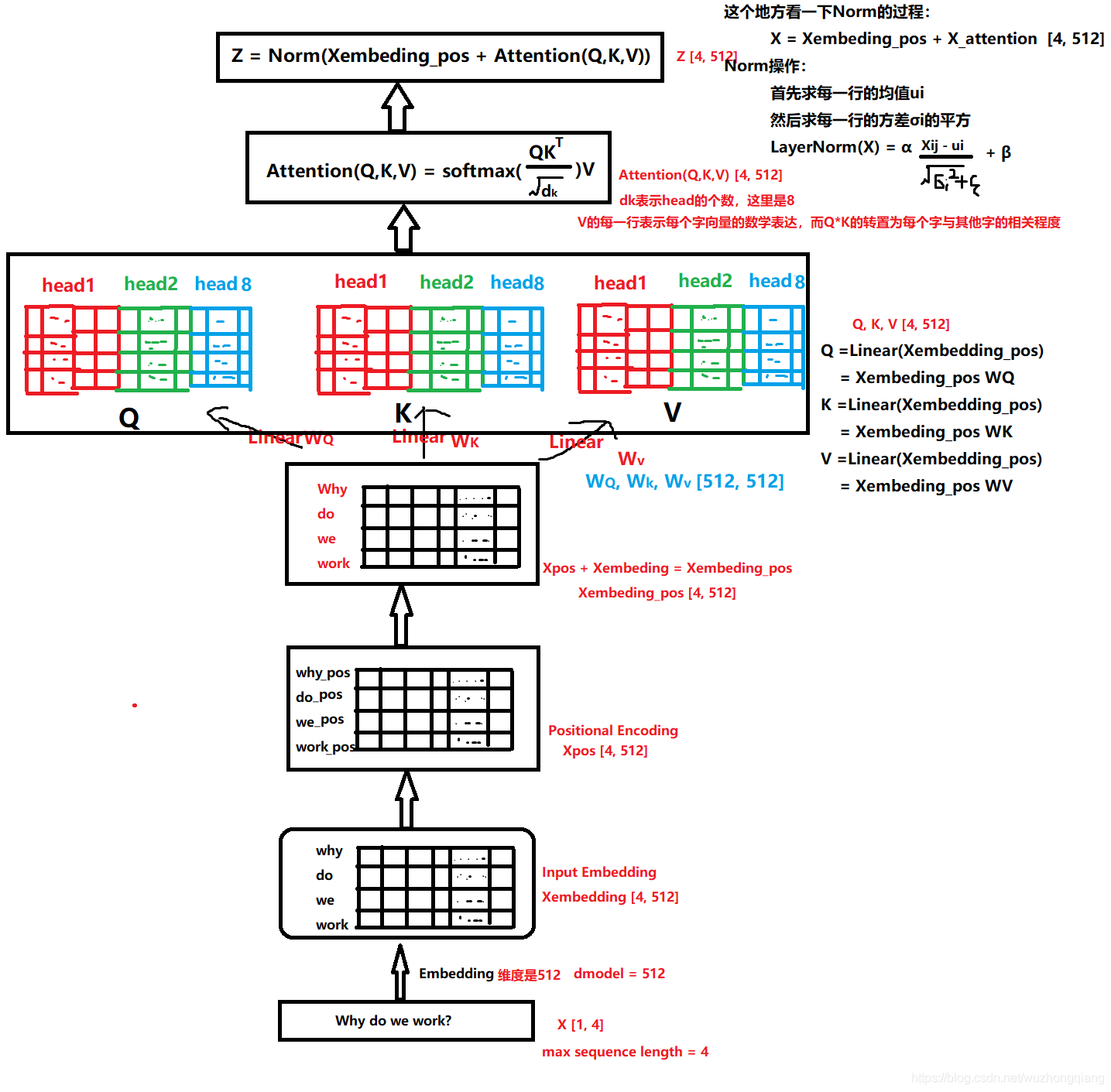
注意,这个图里面有个地方表达错了,dk不是注意力的头数,而是拼接起来的那个最终维度,另外就是,这里多个头时直接拼接的。
剩下就是全连接层,这里就不提了。多头注意力机制就讲完了。
我们在这里穿插总结下。
所以一个Transformer编码块做的事情如下:

下面看看Transformer Encoder的整体的计算过程:


3.残差连接
encoder里面经过注意力矩阵加权之后的V,再加上Xembedding_pos做了残差连接,在之后的运算里,每经过一个模块的运算,都要把运算之前的值和运算之后的值相加,从而得到残差连接,训练的时候可以使梯度直接走捷径反传到最初始层,梯度不易消失,还能保留原始输入的一些信息。
4.LayerNormalization
这个上面的2部分已经提到了,这里详细说一下。LayerNormalization的作用是把神经网络中隐藏层归一化为标准正态分布,以起到加快训练速度,加速收敛的作用:

然后用每一行的每一个元素减去这行的均值,再除以这行的标准差,从而得到归一化后的数值,时为了防止除0;之后引入两个可训练参数α,β来弥补归一化的过程中损失掉的信息。注意⊙表示元素相乘而不是点积,我们一般初始化α为全1,而β为全0.
在这里记录一个问题,比较下LayerNormalization和BatchNormalization,以及为什么这里没有用batchnormalization。
答:batchnormalization不同的时前者时以行为单位(每一行减去每一行的均值然后除以每一行的标准差),后者是一个Batch为单位(每一个元素减去batch的均值然后除以batch的标准差)。来个图感受下:

这里可以这样考虑,从样本角度的合理性,就是每个句子毕竟差距还是蛮大的,既然是融合全局信息,并归一化,最好还是各个句子归一化自己的。
5.decoder部分的多头注意力的使用

这张图就说明了decoder中其中一个多头注意力机制(最上面图2中的encoder-decoder attention模块)的使用,它使用了来自编码块的输出的注意力向量集M,还使用了前面decoder前面部分的输出字信息。
所以多头注意力机制总共在transfomer的三个地方使用了(以图2中的模块名来说):
第一个就是encoder中的self-attention,学习多重语义信息
第二个就是decoder中的encoder-decoder attention,它使用来自encoder顶层的输出注意力向量集和前面decoder输出的序列信息学习多重语义信息
第三个就是decoder的self-attention,是第二个的一部分输入数据。
6.sequence mask和padding mask
我们在编码块肯定不止一个句子,如果有多句话的话,句子的长度是不一样的,而我们的seqlen肯定是以最长的那个为标准,不够长的句子一般用0补充道最大长度,这个过程叫做padding.

但这时进行softmax的时候就会出现问题,回顾softman函数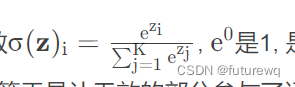
是有值的,这样的话softma中被padding的部分就参与了运算,就等于是让无效的部分参与了运算,会产生很大隐患,这时候就需要做一个mask让这些无效区域不参与运算,我们一般给无效区域加一个很大负数的偏置,也就是:

经过上式的masking我们使无效区域经过softmax计算之后还几乎为0,这样就避免了无效区域参与计算。这就是padding mask, 这种mask在scaled dot-product attention里面都需要用到。实现的时候,padding mask实际上是一个张量,每个值都是Boolean,值为false的地方就是我们要进行处理的地方(加负无穷) 。
transformer里面还有一种mask,叫做sequence mask,它只存在于decoder部分。我们来看看
解码器中的自注意力层的模式与编码器不同:在解码器中,自注意力层只被允许处理输出序列中更靠前的那些位置。在softmax步骤前,它会把后面的位置给隐掉,这里才是正规的mask操作,这个mask操作的目的是不能让当前位置的词看到它之后的,只能看到它以及它之前的,具体实现的时候:

那么为什么sequence mask要这么做呢?这里如果不用sequence mask的话,相当于我预测当前输出的时候,是结合了所有的信息,也就是看到了后面的词语信息。比如我爱中国。在输出爱的时候,如果不mask,会用到中国的信息。但是,我们做预测的时候,预测当前输出,是看不到后面句子的,所以如果训练的时候不mask,就会导致训练和预测出现了一个gap,所以这个sequence mask是必要的。
7.训练小技巧
这里有两个训练小技巧,也值得关注下。
1.LabelSmoothing(regularization)

就是我们准备真实标签的时候,最好也不要完全标成非0即1的这种情况,而是用一种概率的方式标记我们的答案。这是一种规范化的方式。比如

我们最后不要标成这种形式,而是比如positon #1这个,我们虽然想让机器输出I,我们可以I对应的位置是0.9,剩下的0.1其他五个地方平分,即

2.Noam Learning Rate Schedule
这是一种非常重要的方式,如果不用这种学习率的话,可能训练不出一个好的transformer.
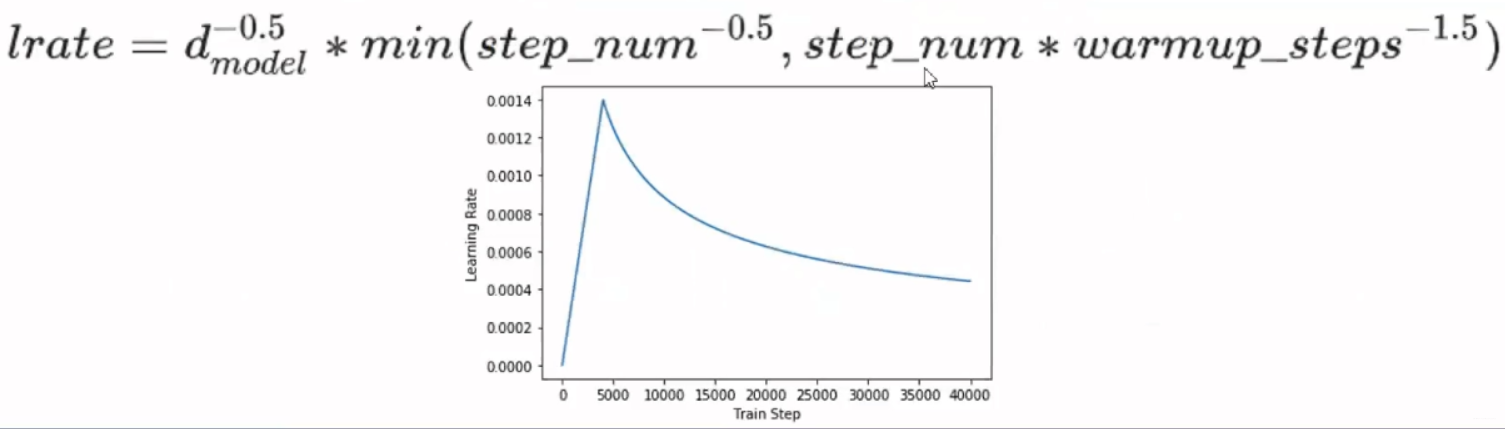
就是先让学习率线性增长到某个最大的值,然后再按指数的方式衰减。相当于先有一个热启动阶段,先让学习率线性增大,到一定的程度,再开启冷启动阶段,或者叫学习率衰减的方式。这个方式对于训练transformer来说,是一个比较重要的策略。
这里记录了一些问题,还有很多问题,以及更加完全的transformer模型的理解,可以看下面的博客。
https://zhongqiang.blog.csdn.net/article/details/104414239