离线数仓-7-数据仓库开发DIM层设计要点-每日全量表同步
- 离线数仓-7-数据仓库开发DIM层设计要点-每日全量表同步
- 1.DIM层 维度模型 设计要点
- 1. 维度表的相关设计
- 2.维度表 设计要点
- 2.DIM层 各维度表分析
- 1.商品维度表
- 1.商品维度表 前期梳理
- 2.商品维度表 DDL表设计分析
- 3.商品维度表 加载数据分析
- 1.从ods层与商品维度相关的表 load到商品维度表中
- 1.首先书写子查询:与商品维度相关联的ods层表格
- 2.将子查询拼装在一起,横着join,竖着union
- 3.最终整合完毕 商品维度表 结构如下,并进行数据装载
- 2.优惠券维度表
- 1.优惠券维度表 前期梳理
- 2.优惠券维度表 DDL表设计分析
- 3.优惠券维度表 加载数据分析
- 3.活动维度表
- 1.活动维度表 前期梳理
- 2.活动维度表 DDL表设计分析
- 3.活动维度表 加载数据分析
- 4.地区维度表
- 1.地区维度表 前期梳理
- 2.地区维度表 DDL表设计分析
- 3.地区维度表 加载数据分析
- 5.日期维度表
- 1.日期维度表 前期梳理
- 2.日期维度表 DDL表设计分析
- 3.日期维度表 加载数据分析
离线数仓-7-数据仓库开发DIM层设计要点-每日全量表同步
1.DIM层 维度模型 设计要点
1. 维度表的相关设计
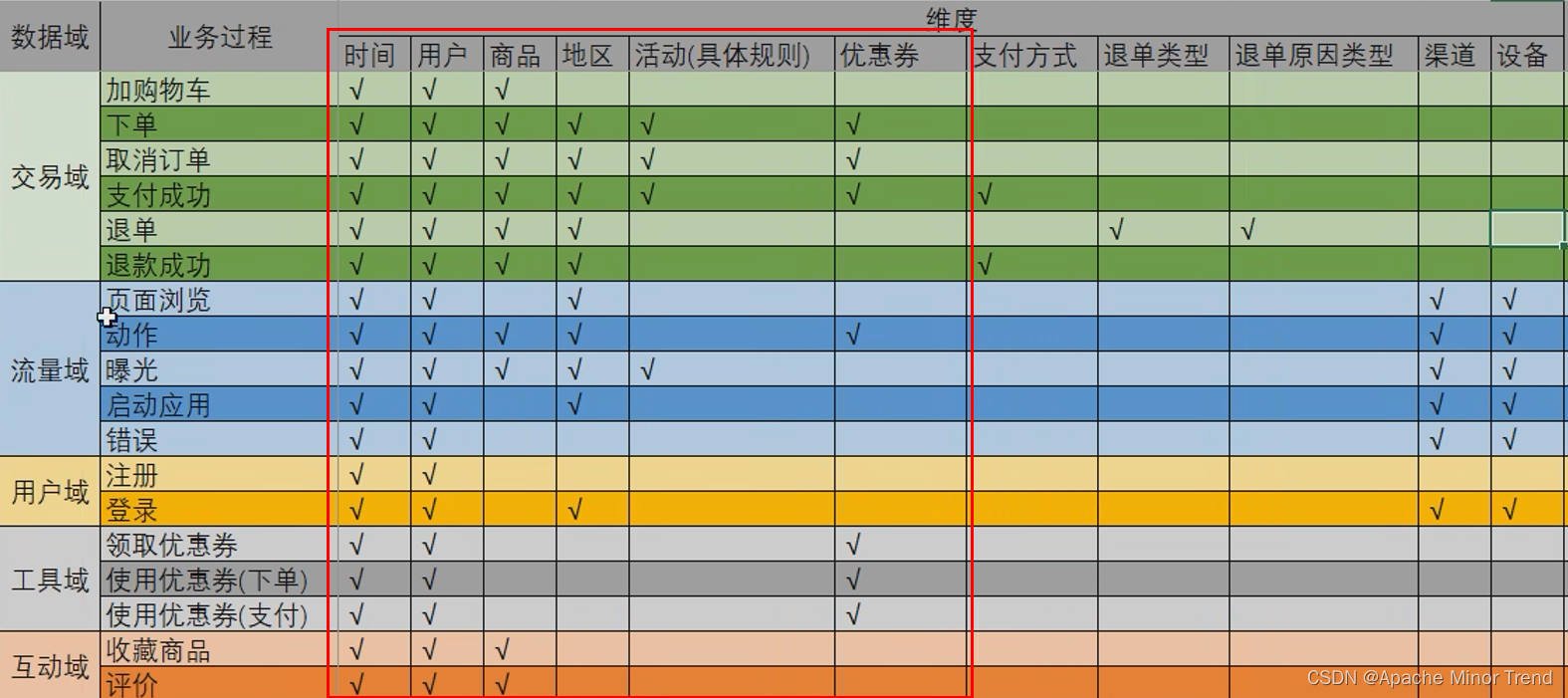
- 有些维度信息,进行了维度退化
- 1.此维度信息对应的维度字段太少
- 2.本身维度信息和业务过程都在一条数据里面,没必要进行拆分
- 最后整合完此项目后,维度表只有6张,分别是:时间、用户、商品、地区、活动、优惠券 ,其他维度都进行了维度退化,方便数据使用。
2.维度表 设计要点
- (1)DIM层的设计依据是维度建模理论,该层存储维度模型的维度表。
- (2)DIM层的数据存储格式为orc列式存储+snappy压缩。
- DIM层主要是做快速查询用的,所以需要选型列式存储+快速压缩的这种组合(orc列式存储+sanppy压缩)
- (3)DIM层表名的命名规范为dim_表名_全量表或者拉链表标识(full/zip)
2.DIM层 各维度表分析
1.商品维度表
1.商品维度表 前期梳理
- 确定ods层与商品相关的表格有哪些,这里其实就是最开始进行的业务梳理,关联出来的表格维度信息,梳理完成后,该项目与商品维度相关的表格有如下这些:
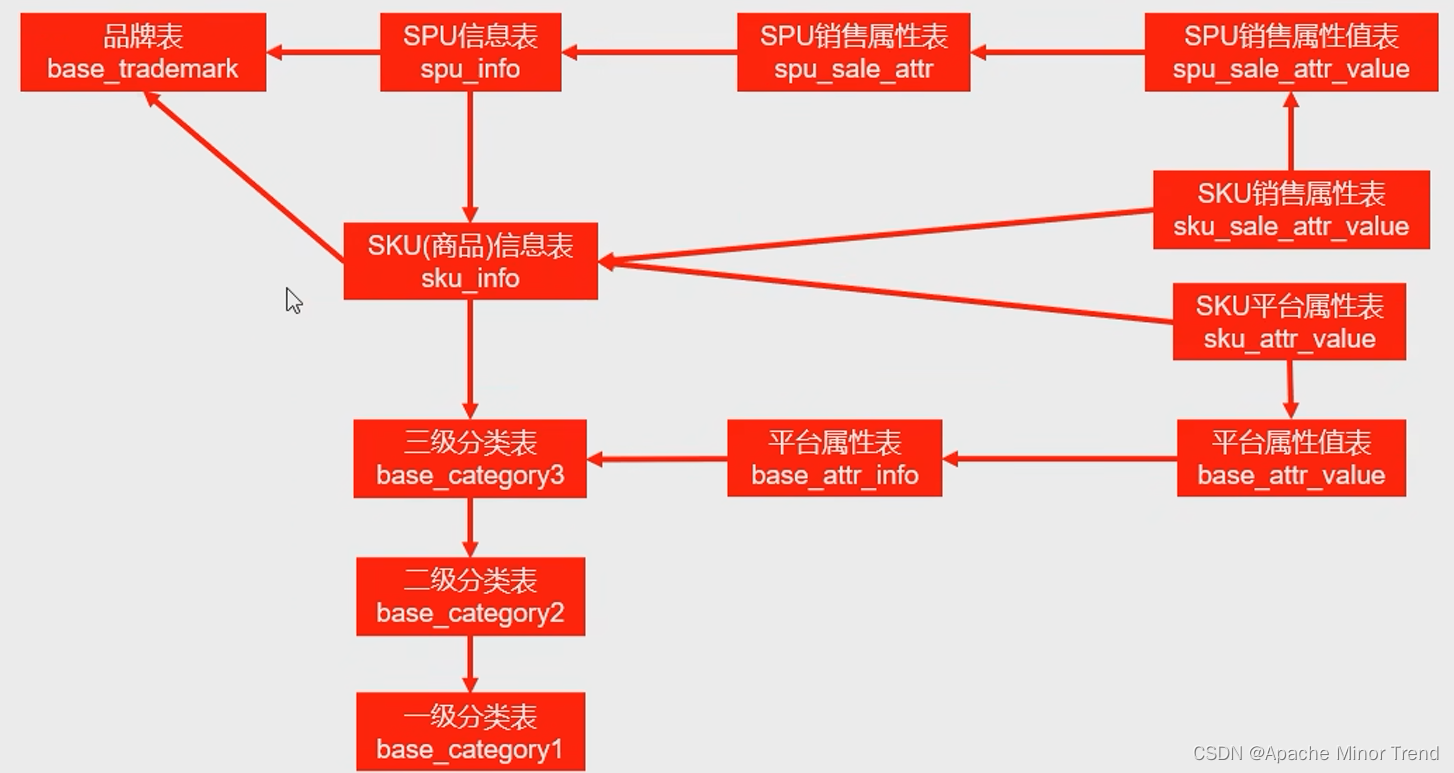
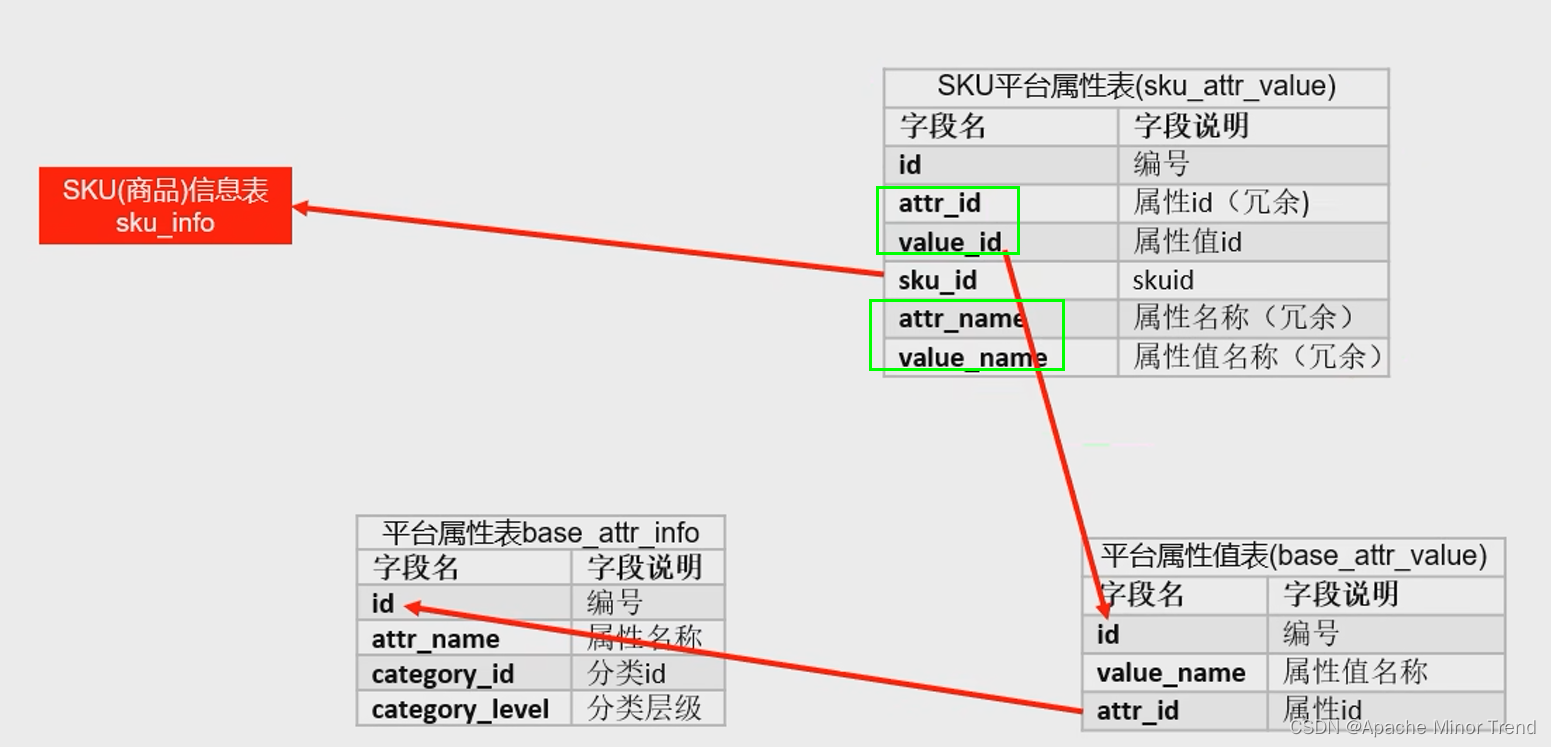
- sku与平台属性值之间是多对多的关系,所以建议这中间需要增加一个表格,进行关联这两部分的数据。
- 平台属性表和平台属性值表 之间是一对多的关系,通常遇见这样的问题,需要在多的这一侧表格中,添加1列为1对应的表格的id字段即可实现。
- 基于以上的ods层表格,需要确认哪些字段可以被DIM层使用,即确认哪些字段被使用。
- 需要认真分析业务数据库中与之关联的所有表格,如果某张表做了其他表格的冗余操作,即该张表格能查询出来与之关联的其他表格的关键字段id,属性等信息,那么可以直接使用这张表信息,进行ods层同步即可,其他表格不需要进行ods层同步,该项目举例如下。
- SKU平台属性表中,做了字段的冗余设计,可以从此表中获取到平台属性值表和平台属性表的关键信息,这样就不需要在同步下面两张表到ods层,从而减少了工作量。
2.商品维度表 DDL表设计分析
- 牵扯到一个字段有多值属性的情况:使用结构体数组来存储。
- 商品维度表DDL结构如下:
DROP TABLE IF EXISTS dim_sku_full;
CREATE EXTERNAL TABLE dim_sku_full
(
`id` STRING COMMENT 'sku_id',
`price` DECIMAL(16, 2) COMMENT '商品价格',
`sku_name` STRING COMMENT '商品名称',
`sku_desc` STRING COMMENT '商品描述',
`weight` DECIMAL(16, 2) COMMENT '重量',
`is_sale` BOOLEAN COMMENT '是否在售',
`spu_id` STRING COMMENT 'spu编号',
`spu_name` STRING COMMENT 'spu名称',
`category3_id` STRING COMMENT '三级分类id',
`category3_name` STRING COMMENT '三级分类名称',
`category2_id` STRING COMMENT '二级分类id',
`category2_name` STRING COMMENT '二级分类名称',
`category1_id` STRING COMMENT '一级分类id',
`category1_name` STRING COMMENT '一级分类名称',
`tm_id` STRING COMMENT '品牌id',
`tm_name` STRING COMMENT '品牌名称',
`sku_attr_values` ARRAY<STRUCT<attr_id :STRING,value_id :STRING,attr_name :STRING,value_name:STRING>> COMMENT '平台属性',
`sku_sale_attr_values` ARRAY<STRUCT<sale_attr_id :STRING,sale_attr_value_id :STRING,sale_attr_name :STRING,sale_attr_value_name:STRING>> COMMENT '销售属性',
`create_time` STRING COMMENT '创建时间'
) COMMENT '商品维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_sku_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
3.商品维度表 加载数据分析
1.从ods层与商品维度相关的表 load到商品维度表中
1.首先书写子查询:与商品维度相关联的ods层表格
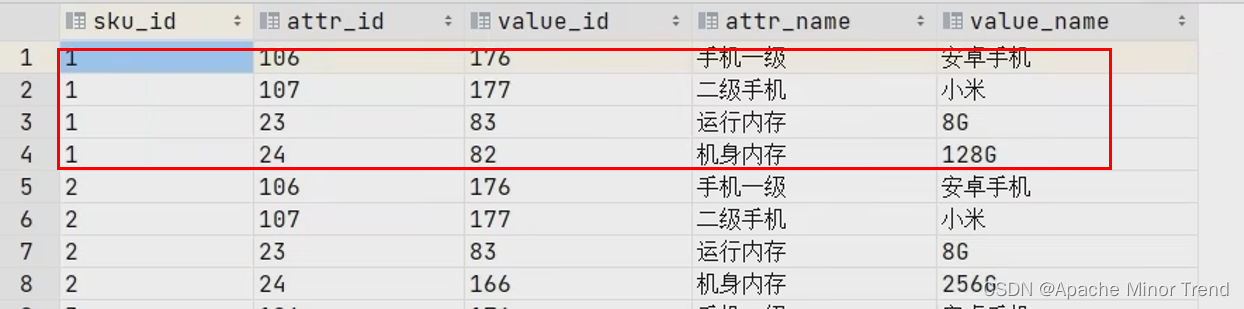
- 通过sql,构造复杂结构体数组
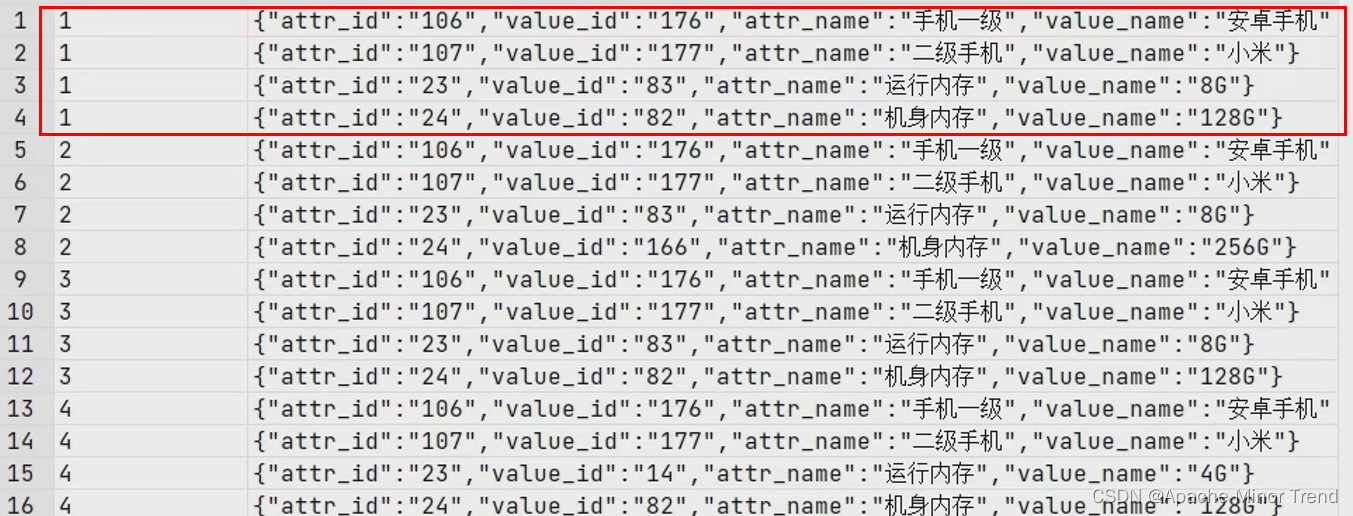
- 原始sql查询出来数据是如下的情况(
select
sku_id,
attr_id,
value_id,
attr_name,
value_name
from ods_sku_attr_value_full
where dt = ‘2020-06-14’
):
- 构造复杂结构体数组,需要注意:struct结构体里面的字段名需要跟商品维度表的字段名保持一致;
- 第一步,构造非分组结构体,查询结果如下:
select
sku_id,
named_struct(“attr_id”,attr_id,“value_id”,value_id,“attr_name”,attr_name,“value_name”,value_name)
from ods_sku_attr_value_full
where dt = ‘2020-06-14’
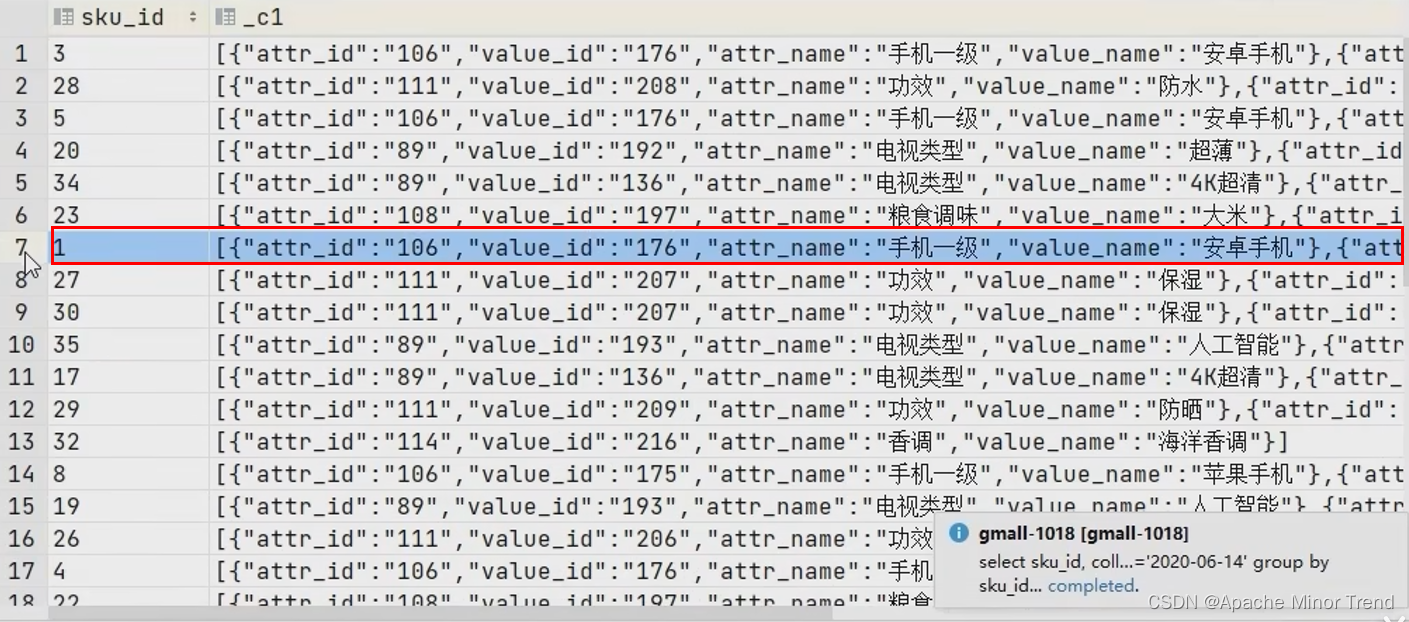
- 第二步,聚合sku_id,然后使用函数 collect_set()获取结构体聚合结果。
select
sku_id,
collect_set(named_struct(“attr_id”,attr_id,“value_id”,value_id,“attr_name”,attr_name,“value_name”,value_name))
from ods_sku_attr_value_full
where dt = ‘2020-06-14’
group by sku_id;
- 第一步,构造非分组结构体,查询结果如下:
- 原始sql查询出来数据是如下的情况(
2.将子查询拼装在一起,横着join,竖着union
- CTE:公共表表达式:声明一次子表,可以在后面使用多次,具体语法:
with
别名a as (子查询),
别名b as (子查询) ,
…
select * from 别名a join 别名b on 别名a.id = 别名b.id
3.最终整合完毕 商品维度表 结构如下,并进行数据装载
- 使用insert overwriter 而不使用insert into 的目的:保证数据的幂等性 (1的N次方 都是1),避免因为环境问题重跑脚本造成的数据不一致问题出现。
with
sku as
(
select
id,
price,
sku_name,
sku_desc,
weight,
is_sale,
spu_id,
category3_id,
tm_id,
create_time
from ods_sku_info_full
where dt='2020-06-14'
),
spu as
(
select
id,
spu_name
from ods_spu_info_full
where dt='2020-06-14'
),
c3 as
(
select
id,
name,
category2_id
from ods_base_category3_full
where dt='2020-06-14'
),
c2 as
(
select
id,
name,
category1_id
from ods_base_category2_full
where dt='2020-06-14'
),
c1 as
(
select
id,
name
from ods_base_category1_full
where dt='2020-06-14'
),
tm as
(
select
id,
tm_name
from ods_base_trademark_full
where dt='2020-06-14'
),
attr as
(
select
sku_id,
collect_set(named_struct('attr_id',attr_id,'value_id',value_id,'attr_name',attr_name,'value_name',value_name)) attrs
from ods_sku_attr_value_full
where dt='2020-06-14'
group by sku_id
),
sale_attr as
(
select
sku_id,
collect_set(named_struct('sale_attr_id',sale_attr_id,'sale_attr_value_id',sale_attr_value_id,'sale_attr_name',sale_attr_name,'sale_attr_value_name',sale_attr_value_name)) sale_attrs
from ods_sku_sale_attr_value_full
where dt='2020-06-14'
group by sku_id
)
-- 进行数据装载
insert overwrite table dim_sku_full partition(dt='2020-06-14')
select
sku.id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.is_sale,
sku.spu_id,
spu.spu_name,
sku.category3_id,
c3.name,
c3.category2_id,
c2.name,
c2.category1_id,
c1.name,
sku.tm_id,
tm.tm_name,
attr.attrs,
sale_attr.sale_attrs,
sku.create_time
from sku
left join spu on sku.spu_id=spu.id
left join c3 on sku.category3_id=c3.id
left join c2 on c3.category2_id=c2.id
left join c1 on c2.category1_id=c1.id
left join tm on sku.tm_id=tm.id
left join attr on sku.id=attr.sku_id
left join sale_attr on sku.id=sale_attr.sku_id;
2.优惠券维度表
1.优惠券维度表 前期梳理
- 确定维度属性的三个要求:
- 1.尽可能生成丰富的维度属性
- 2.尽可能不使用编码,而是用明确的文字说明,一般可以编码与文字共存,也就是说,如果数据中有编码与码表对应的,直接将码表中的文字获取出来,编码跟对应的文字都保留即可。
- 3.尽量沉淀出通用的维度属性。
- 关于优惠券维度表:
- 需要将“优惠范围类型编码”和“优惠范围类型名称”全部整合到优惠券维度表中
- 需要将“购物券类型编码”和“购物券类型名称” 全部整合到优惠券维度表中
- 需要沉淀出“优惠规则:满xxx元减xxx元,满xxx件打xxx折”
2.优惠券维度表 DDL表设计分析
- 优惠券维度表DDL结构如下:
DROP TABLE IF EXISTS dim_coupon_full;
CREATE EXTERNAL TABLE dim_coupon_full
(
`id` STRING COMMENT '购物券编号',
`coupon_name` STRING COMMENT '购物券名称',
`coupon_type_code` STRING COMMENT '购物券类型编码',
`coupon_type_name` STRING COMMENT '购物券类型名称',
`condition_amount` DECIMAL(16, 2) COMMENT '满额数',
`condition_num` BIGINT COMMENT '满件数',
`activity_id` STRING COMMENT '活动编号',
`benefit_amount` DECIMAL(16, 2) COMMENT '减金额',
`benefit_discount` DECIMAL(16, 2) COMMENT '折扣',
`benefit_rule` STRING COMMENT '优惠规则:满元*减*元,满*件打*折',
`create_time` STRING COMMENT '创建时间',
`range_type_code` STRING COMMENT '优惠范围类型编码',
`range_type_name` STRING COMMENT '优惠范围类型名称',
`limit_num` BIGINT COMMENT '最多领取次数',
`taken_count` BIGINT COMMENT '已领取次数',
`start_time` STRING COMMENT '可以领取的开始日期',
`end_time` STRING COMMENT '可以领取的结束日期',
`operate_time` STRING COMMENT '修改时间',
`expire_time` STRING COMMENT '过期时间'
) COMMENT '优惠券维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_coupon_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
3.优惠券维度表 加载数据分析
- sql中字符串拼接
case coupon_type
when '3201' then concat("满",condition_amount,"元减",benefit_amount,"元")
when '3201' then concat("满",condition_num,"件打",(1-benefit_discount)*10,"折")
when '3201' then concat("减",condition_amount,"元")
end benefit_rule
- 最终装载数据的sql:
insert overwrite table dim_coupon_full partition(dt='2020-06-14')
select
id,
coupon_name,
coupon_type,
coupon_dic.dic_name,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
case coupon_type
when '3201' then concat('满',condition_amount,'元减',benefit_amount,'元')
when '3202' then concat('满',condition_num,'件打',10*(1-benefit_discount),'折')
when '3203' then concat('减',benefit_amount,'元')
end benefit_rule,
create_time,
range_type,
range_dic.dic_name,
limit_num,
taken_count,
start_time,
end_time,
operate_time,
expire_time
from
(
select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
limit_num,
taken_count,
start_time,
end_time,
operate_time,
expire_time
from ods_coupon_info_full
where dt='2020-06-14'
)ci
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code='32'
)coupon_dic
on ci.coupon_type=coupon_dic.dic_code
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code='33'
)range_dic
on ci.range_type=range_dic.dic_code;
- 使用cet语法,实现一次子查询的方式,需要创建别名的别名,要不然sql不认识是哪个表格,会报错。
with
ci as (
select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
limit_num,
taken_count,
start_time,
end_time,
operate_time,
expire_time
from ods_coupon_info_full
where dt='2020-06-14'
)
dic as (
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
)
select
id,
coupon_name,
coupon_type,
dic_1.dic_name,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
case coupon_type
when '3201' then concat('满',condition_amount,'元减',benefit_amount,'元')
when '3202' then concat('满',condition_num,'件打',10*(1-benefit_discount),'折')
when '3203' then concat('减',benefit_amount,'元')
end benefit_rule,
create_time,
range_type,
dic_2.dic_name,
limit_num,
taken_count,
start_time,
end_time,
operate_time,
expire_time
from ci
left join dic dic_1 on ci.coupon_type = dic_1.dic_code
left join dic dic_2 on ci.range_type = dic_2.dic_code;
- 如果删除hive上的外部表,重新创建外部表之后,查询没有数据,是因为没有分区信息导致;
- 需要执行修复此表元数据的命令:msck repair table ods_log_inc; msck:meta store consistency check;
- 然后再查看分区:show partitions ods_log_inc ;分区就回复了。
3.活动维度表
1.活动维度表 前期梳理
- 确定与活动相关的主维表和相关维表
- 1.获取活动相关表格如下:
- ods_active_info_full
- ods_active_rule_full
- 2.分析与之关联的每个表格中的具体字段,抽离出来“活动维度表”所需字段
- 3.确定这些表格中,谁是主维表。粒度小的是主维表,规则表rule较info表粒度更小,所以此表作为主维表。
- 4.主维表确定以后,主维表对应的一行代表什么信息,同理维度表一行就代表什么信息。此处,规则rule表最为主维表,rule表中一行代表一条规则,那么活动维度表,一行也代表一条规则。
- 1.获取活动相关表格如下:
2.活动维度表 DDL表设计分析
- 活动维度表DDL如下:
DROP TABLE IF EXISTS dim_activity_full;
CREATE EXTERNAL TABLE dim_activity_full
(
`activity_rule_id` STRING COMMENT '活动规则ID',
`activity_id` STRING COMMENT '活动ID',
`activity_name` STRING COMMENT '活动名称',
`activity_type_code` STRING COMMENT '活动类型编码',
`activity_type_name` STRING COMMENT '活动类型名称',
`activity_desc` STRING COMMENT '活动描述',
`start_time` STRING COMMENT '开始时间',
`end_time` STRING COMMENT '结束时间',
`create_time` STRING COMMENT '创建时间',
`condition_amount` DECIMAL(16, 2) COMMENT '满减金额',
`condition_num` BIGINT COMMENT '满减件数',
`benefit_amount` DECIMAL(16, 2) COMMENT '优惠金额',
`benefit_discount` DECIMAL(16, 2) COMMENT '优惠折扣',
`benefit_rule` STRING COMMENT '优惠规则',
`benefit_level` STRING COMMENT '优惠级别'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_activity_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
3.活动维度表 加载数据分析
-
full类型的“每日全量快照表”,每天都需要装载一次,需要书写脚本,每天凌晨装载一次前一天的数据到full表中即可。
-
维度表,都是获取ods层与之相关的表格的当天的分区,然后汇总录入维度表
-
加载ods层数据到活动维度表的具体sql:
insert overwrite table dim_activity_full partition(dt='2020-06-14')
select
rule.id,
info.id,
activity_name,
rule.activity_type,
dic.dic_name,
activity_desc,
start_time,
end_time,
create_time,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
case rule.activity_type
when '3101' then concat('满',condition_amount,'元减',benefit_amount,'元')
when '3102' then concat('满',condition_num,'件打',10*(1-benefit_discount),'折')
when '3103' then concat('打',10*(1-benefit_discount),'折')
end benefit_rule,
benefit_level
from
(
select
id,
activity_id,
activity_type,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
benefit_level
from ods_activity_rule_full
where dt='2020-06-14'
)rule
left join
(
select
id,
activity_name,
activity_type,
activity_desc,
start_time,
end_time,
create_time
from ods_activity_info_full
where dt='2020-06-14'
)info
on rule.activity_id=info.id
left join
(
select
dic_code,
dic_name
from ods_base_dic_full
where dt='2020-06-14'
and parent_code='31'
)dic
on rule.activity_type=dic.dic_code;
4.地区维度表
1.地区维度表 前期梳理
- 1.与地区相关的ods层表格有哪些
- ods_base_province_full
- ods_base_region_full
- 2.分析这些表格中字段,汇总字段
- 地区中存在国际以及国内相关的系统化编码规则:area_code,iso_code,iso_3166_2
- 3.确定主维表与相关维表
- 4.表格之间进行关联
2.地区维度表 DDL表设计分析
DROP TABLE IF EXISTS dim_province_full;
CREATE EXTERNAL TABLE dim_province_full
(
`id` STRING COMMENT 'id',
`province_name` STRING COMMENT '省市名称',
`area_code` STRING COMMENT '地区编码',
`iso_code` STRING COMMENT '旧版ISO-3166-2编码,供可视化使用',
`iso_3166_2` STRING COMMENT '新版IOS-3166-2编码,供可视化使用',
`region_id` STRING COMMENT '地区id',
`region_name` STRING COMMENT '地区名称'
) COMMENT '地区维度表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_province_full/'
TBLPROPERTIES ('orc.compress' = 'snappy');
3.地区维度表 加载数据分析
insert overwrite table dim_province_full partition(dt='2020-06-14')
select
province.id,
province.name,
province.area_code,
province.iso_code,
province.iso_3166_2,
region_id,
region_name
from
(
select
id,
name,
region_id,
area_code,
iso_code,
iso_3166_2
from ods_base_province_full
where dt='2020-06-14'
)province
left join
(
select
id,
region_name
from ods_base_region_full
where dt='2020-06-14'
)region
on province.region_id=region.id;
5.日期维度表
1.日期维度表 前期梳理
- 前面四张表都是从ods层“每日全量快照表”中抽离出来的,但是日期维度表不是这样的
- 具体流程梳理:
- 日期维度表 从业务系统中进行分析表格的时候,搜寻不到主维表以及相关维表,所以日期维度表 数据都不来自于业务系统,日期维度表 数据 跟业务系统 没有关系。
- 日期维度表:
- 每行数据 通常与 数仓中计算周期有关,计算周期可能为:天、小时,所以每行数据代表的数据跟计算周期相关联。
- 列数据,通常存储跟日期相关联的时间维度属性,该天所属的年、月、周几、几季度等维度
2.日期维度表 DDL表设计分析
- 日期维度表 不需要分区,分区也没有意义
DROP TABLE IF EXISTS dim_date;
CREATE EXTERNAL TABLE dim_date
(
`date_id` STRING COMMENT '日期ID',
`week_id` STRING COMMENT '周ID,一年中的第几周',
`week_day` STRING COMMENT '周几',
`day` STRING COMMENT '每月的第几天',
`month` STRING COMMENT '一年中的第几月',
`quarter` STRING COMMENT '一年中的第几季度',
`year` STRING COMMENT '年份',
`is_workday` STRING COMMENT '是否是工作日',
`holiday_id` STRING COMMENT '节假日'
) COMMENT '时间维度表'
STORED AS ORC
LOCATION '/warehouse/gmall/dim/dim_date/'
TBLPROPERTIES ('orc.compress' = 'snappy');
3.日期维度表 加载数据分析
- 日期维度表数据,来自于哪里?
- 手动写入,批量导入,一次导入一年即可。节假日每年可能会发生变化,所以只能每年倒一次即可。
- 怎样实现批量导入一年数据到日期维度表?
- 本地程序处理,处理完毕生成文本文件,获取节假日以及非节假日是哪些
- 由于是txt文件,首先创建hive临时表,数据格式规定为txt格式,然后日期维度表 加载临时表里面的数据即可。
- 临时表sql如下:
DROP TABLE IF EXISTS tmp_dim_date_info;
CREATE EXTERNAL TABLE tmp_dim_date_info (
`date_id` STRING COMMENT '日',
`week_id` STRING COMMENT '周ID',
`week_day` STRING COMMENT '周几',
`day` STRING COMMENT '每月的第几天',
`month` STRING COMMENT '第几月',
`quarter` STRING COMMENT '第几季度',
`year` STRING COMMENT '年',
`is_workday` STRING COMMENT '是否是工作日',
`holiday_id` STRING COMMENT '节假日'
) COMMENT '时间维度表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/warehouse/gmall/tmp/tmp_dim_date_info/';
- 同步数据到日期维度表
insert overwrite table dim_date select * from tmp_dim_date_info;