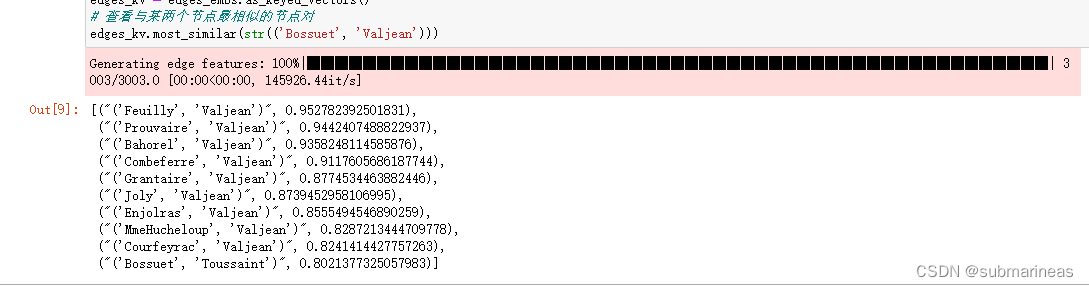
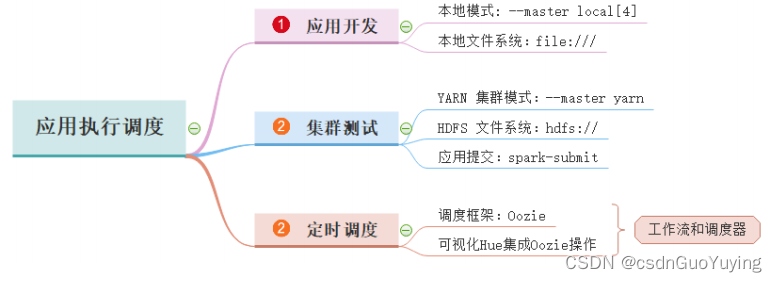
第四章 应用执行调度
前面已经完成【广告数据ETL】和【业务报表分析】,在IDEA中使用本地模式LocalMode开发,从本地文件系统LocalFS加载数据,接下来打包发到测试集群环境测试,并且使用Oozie调度执行。
4.1 应用打包
在集群环境运行开发Spark Application,首先要打成jar,直接使用Maven插件即可。
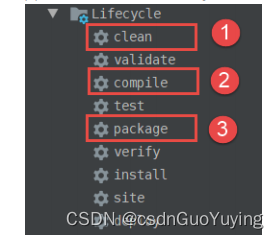
首先第一步①【清除classes文件】,然后第二步②【编译源文件】,最后第三步③【class文件打成jar包】,将其重命名为【spark-ads_2.11-1.0.0.jar】,修改jar包中【config.properties】中内容:
# local mode
app.is.local=false
app.spark.master=local[4]
# 广告业务数据存储路径
datas.path=hdfs://node1.itcast.cn:8020/spark/dataset/pmt.json
# 字典数据
ipdata.region.path=hdfs://node1.itcast.cn:8020/spark/dataset/ip2region.db
通过spark-submit中–master指定应用运行模式,将【广告业务数据】和【IP地址解析字典数据】上传到HDFS目录【/spark/dataset】中,命令如下:
# 创建目录
hdfs dfs -mkdir -p /spark/dataset/
# 先上传【广告业务数据】、【字典数据】至虚拟机/root/submit-ads-app
mkdir -p /root/submit-ads-app
## rz 上传
# 上传数据
hdfs dfs -put /root/submit-ads-app/pmt.json /spark/dataset/
hdfs dfs -put /root/submit-ads-app/ip2region.db /spark/dataset/
启动Hue服务,登录WEB系统,查看文件:
同时将打成应用jar包【spark-ads_2.11-1.0.0.jar】上传到HDFS目录【/spark/apps】,命令如下:
# 上传应用jar至虚拟机/root/submit-ads-app
mkdir -p /root/submit-ads-app
## rz 上传
# 上传jar包至/spark/apps
hdfs dfs -put /root/submit-ads-app/spark-ads_2.11-1.0.0.jar /spark/apps/
登录Hue Web 系统,查看jar包:
此外,应用程序依赖于第三方包:MySQL驱动包、Config解析包和IP地址解析包:
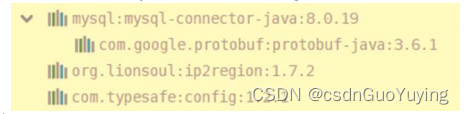
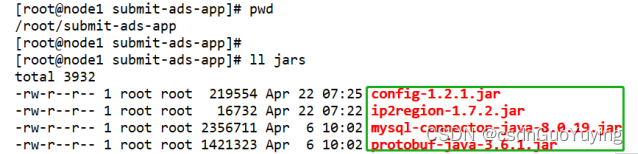
需要将其拷贝上传至【虚拟机目录/root/submit-ads-app/jars】项目:
在使用spark-submit提交应用【ETL应用】或【Report应用】运行时,需要使用【–jars】指定应用依赖的jar包,发送到Driver和Executor,以便Task运行时可以找到。
4.2 集群提交运行
使用spark-submit提交应用执行,如下案例所示:
$SPARK_HOME/bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
具体说明,查看官方文档:http://spark.apache.org/docs/2.4.5/submitting-applications.html#
对上述开发的两个Spark 应用分别提交运行:
第一个:广告数据ETL处理应用(ads_etl)
- 应用运行主类:cn.itcast.spark.etl.PmtEtlRunner
- 依赖第三方jar包:config-1.2.1.jar、ip2region-1.7.2.jar
第二个:广告数据报表Report统计应用(ads_report)
- 应用运行主类:cn.itcast.spark.report.PmtReportRunner
- 依赖第三方jar包:config-1.2.1.jar、mysql-connector-java-8.0.19.jar、protobuf-java-3.6.1.jar
删除数据
在提交应用执行之前,需要将Hive 表中对应分区数据和MySQL表中报表数据删除。
1)、删除【Hive Table 分区数据】
-- 显示分区
SHOW PARTITIONS itcast_ads.pmt_ads_info ;
-- 删除分区表数据
ALTER TABLE itcast_ads.pmt_ads_info DROP IF EXISTS PARTITION (date_str='2020-04-23');
2)、删除【MySQL Table报表数据】
-- 删除表中数据
TRUNCATE TABLE itcast_ads_report.region_stat_analysis ;
TRUNCATE TABLE itcast_ads_report.ads_region_analysis ;
本地模式提交
先使用spark-submit提交【ETL应用】和【Report应用】,以本地模式LocalMode运行,查看Hive Table和MySQL Table数据是否OK。
- ETL应用运行(ads_elt)提交应用命令
SPARK_HOME=/export/server/spark
EXTERNAL_JARS=/root/submit-ads-app/jars
${SPARK_HOME}/bin/spark-submit \
--master local[2] \
--conf "spark.sql.shuffle.partitions=2" \
--class cn.itcast.spark.etl.PmtEtlRunner \
--jars ${EXTERNAL_JARS}/ip2region-1.7.2.jar,${EXTERNAL_JARS}/config-1.2.1.jar \
hdfs://node1.itcast.cn:8020/spark/apps/spark-ads_2.11-1.0.0.jar
- 报表Report应用运行(ads_report)提交应用命令
SPARK_HOME=/export/server/spark
EXTERNAL_JARS=/root/submit-ads-app/jars
${SPARK_HOME}/bin/spark-submit \
--master local[2] \
--conf spark.sql.shuffle.partitions=2 \
--class cn.itcast.spark.report.PmtReportRunner \
--jars ${EXTERNAL_JARS}/mysql-connector-java-8.0.19.jar,${EXTERNAL_JARS}/protobuf-java-3.6.1.jar,${EX
TERNAL_JARS}/config-1.2.1.jar \
hdfs://node1.itcast.cn:8020/spark/apps/spark-ads_2.11-1.0.0.jar
集群模式提交
当本地模式LocalMode应用提交运行没有问题时,启动YARN集群,使用spark-submit提交【ETL应用】和【Report应用】,以YARN Client和Cluaster不同部署模式运行,查看Hive Table和MySQL Table数据是否OK。
- ETL应用运行(ads_elt)提交应用命令,DeployMode为client
SPARK_HOME=/export/server/spark
EXTERNAL_JARS=/root/submit-ads-app/jars
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--queue default \
--conf spark.sql.shuffle.partitions=2 \
--class cn.itcast.spark.etl.PmtEtlRunner \
--jars ${EXTERNAL_JARS}/ip2region-1.7.2.jar,${EXTERNAL_JARS}/config-1.2.1.jar \
hdfs://node1.itcast.cn:8020/spark/apps/spark-ads_2.11-1.0.0.jar
- 报表Report应用运行(ads_report)提交应用命令,DeployMode为cluster
SPARK_HOME=/export/server/spark
EXTERNAL_JARS=/root/submit-ads-app/jars
${SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--queue default \
--conf spark.sql.shuffle.partitions=2 \
--class cn.itcast.spark.report.PmtReportRunner \
--jars ${EXTERNAL_JARS}/mysql-connector-java-8.0.19.jar,${EXTERNAL_JARS}/protobuf-java-3.6.1.jar,${EX
TERNAL_JARS}/config-1.2.1.jar \
hdfs://node1.itcast.cn:8020/spark/apps/spark-ads_2.11-1.0.0.jar
由于从HDFS上加载数据,封装到DataFrame中,默认的分区数目等于block 数目,所以每个Task处理数据最大量为128MB,无需设置并行度,但是要是从HBase表或者Elasticsearch索引加载数据,需要考虑分区数目(并行度spark.default.parallelism)。