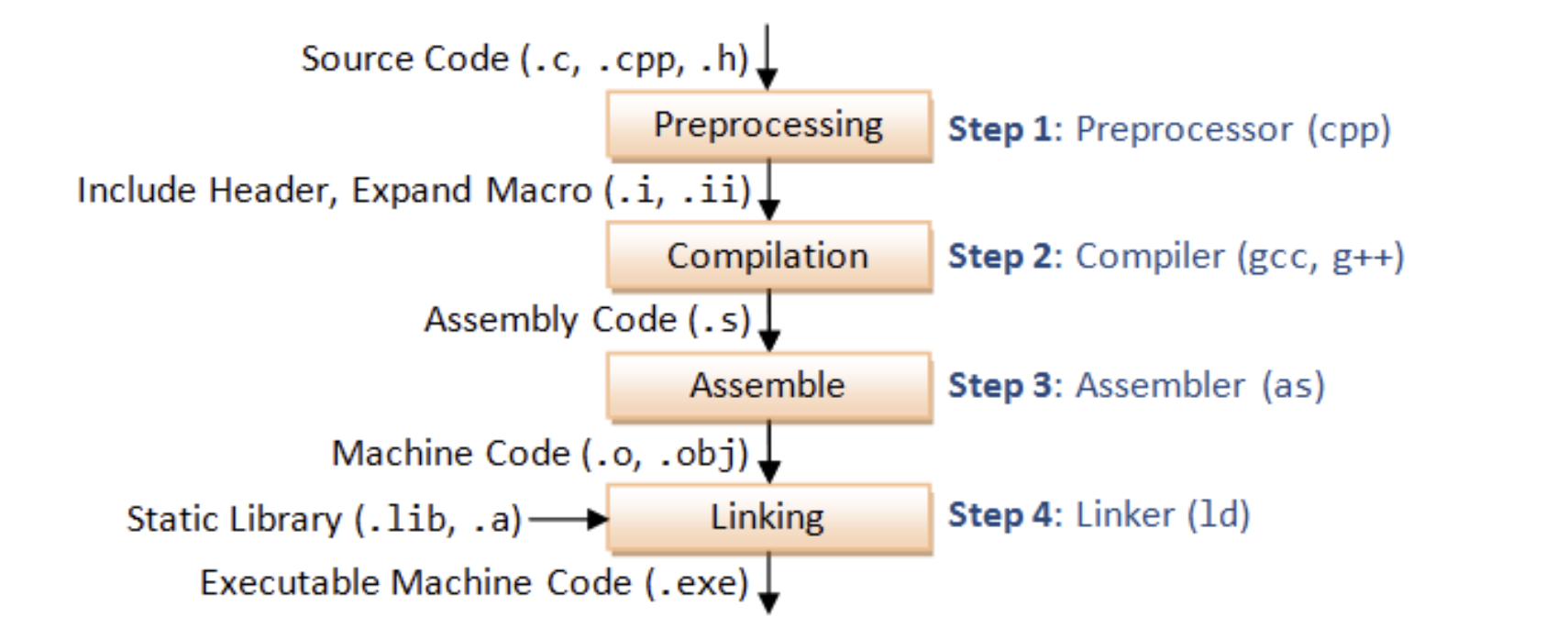
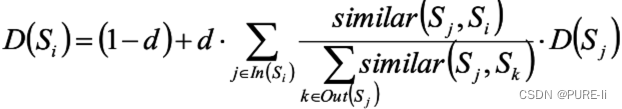大型语言模型 (LLM) 通过利用思维链 (CoT) 提示生成中间推理链作为推断答案的基本原理,在复杂推理上表现出了令人印象深刻的性能。 然而现有的 CoT 研究主要集中在语言模态上。 我们提出 Multimodal-CoT(多模态思维链推理模型),它将语言(文本)和视觉(图像)模态结合到一个两阶段框架中,该框架将基本原理生成和答案推理分开。 通过这种方式,答案推理可以利用基于多模态信息的更好的生成原理。 使用 Multimodal-CoT,作者提出的模型在 对ScienceQA 数据集进行评估,结果显示在少于 10 亿个参数下比之前 LLM(GPT-3.5)高出 16 个百分点(75.17%→91.68% )的准确率。
论文地址:https://arxiv.org/abs/2302.00923
代码地址:https://github.com/amazon-science/mm-cot
本文研究在小于 10 亿参数的情况下就产生了性能提升,是如何做到的呢?简单来讲,本文提出了包含视觉特征的 Multimodal-CoT,通过这一范式(Multimodal-CoT)来寻找多模态中的 CoT 推理。
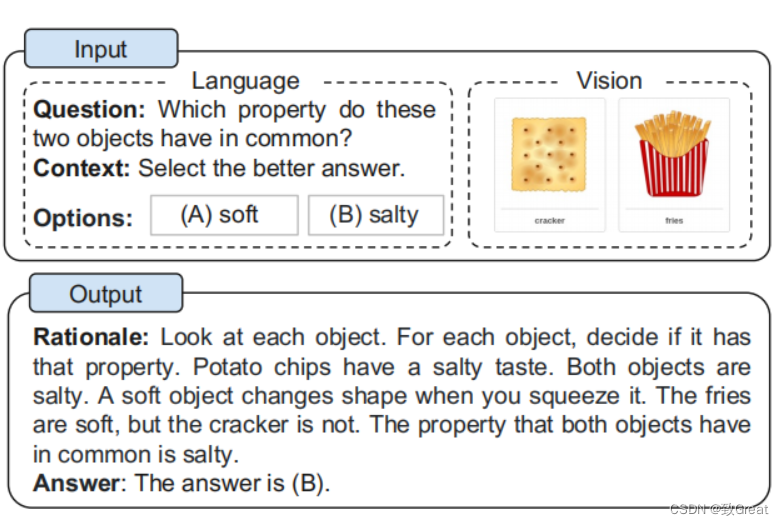
1 什么是COT
COT全称为Chain-of-Thought,定义是在应对推理任务时,在给出最终答案之前所产生的中间推理步骤,载体是一系列的短句子 。简单来说,思维链是一种离散式提示学习,更具体地,大模型下的上下文学习(即不进行训练,将例子添加到当前样本输入的前面,让模型一次输入这些文本进行输出完成任务),相比于之前传统的上下文学习,即通过x1,y1,x2,y2,…x_test作为输入来让大模型补全输出y_test,思维链多了中间的一些闲言碎语絮絮叨叨,以下面这张图为例子:

上图展示了在 CoT 诞生之前是怎样使用标准的 prompting 方法来求解推理任务的。首先这是一个少样本学习的方法,需要给出一些问题和答案的样例,然后拼接这正想要求解的问题,最后再拼接一个字符串“A:”之后输入到大语言模型中,让大语言模型进行续写。大语言模型会在所提供的问题和答案的样例中学习如何求解,结果发现很容易出错,也就是上面提到的大语言模型在推理任务上很容易遇到瓶颈
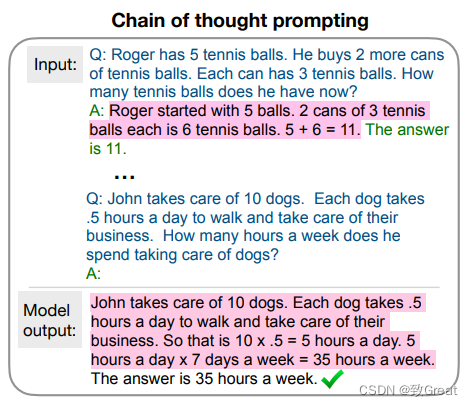
上图展示了 CoT 的做法,CoT 与 Standard prompting 唯一的区别就是,CoT 在样例中在给出问题的同时,不仅给出了答案,在答案之前还给出了人为写的中间推理步骤。在把问题、中间推理步骤和答案的若干样例拼接上所想要求解的问题和字符串“A”,再输入到语言模型之后,语言模型会自动地先续写中间推理步骤,有了这些推理步骤之后,它就会更容易地给出正确答案,也就是能够更好地解决推理这类的问题
2 研究背景
2.1 使用LLM进行CoT推理
最近,CoT 已被广泛用于激发多步LLM 的推理能力。具体来说,CoT 技术鼓励 LLM 生成用于解决问题的中间推理链,主要技术有Zero-SHot-CoT、Few-Shot-CoT、Manual-CoT、Auto-CoT
优化推理演示
Few-Shot-CoT的性能比较依赖于演示的质量,使用不同人员编写的演示例子在符号推理任务中产生的准确性浮动比较大。除了手工制作演示之外,最近的研究还研究了调整演示选择过程的方法,比如Auto-CoT。除此之外,还有作者提出了基于复杂性的语言模型中的强化学习(RL)和多模态思维链推理策略,已经获得有效的论证,比如GPT-3.5。
优化推理链
优化推理链的一个常用的方法是问题分解,有人提出了最小到最大的提示,将复杂问题分解为子问题,然后依次解决这些子问题。因此,对先前解决的子问题的答案有助于解决一个给定的子问题。
2.2 通过微调模型引出CoT推理
最近的一个兴趣是通过微调语言模型来引出CoT推理。在一个带有CoT注释的大规模数据集上对Encoder-Decoder结构的T5模型进行了微调。然而,当使用CoT来推断答案时,可以观察到性能的急剧下降,即在答案(推理)之前生成推理链,相反,CoT只被用作答案之后的解释。后续有人通过对一个更大的教师模型产生的思维链输出的学生模型来微调知识蒸馏,该方法在算术、常识和符号推理任务方面都表现出了性能的提高。具体论文和代码可以查阅《Large Language Models Are Reasoning Teachers》:
论文链接:https://arxiv.org/pdf/2212.10071.pdf
项目地址:https://github.com/itsnamgyu/reasoning-teacher
3 多模态CoT的挑战
现有研究表明,CoT推理能力可能以一定规模出现在语言模型中,例如超过1000亿个参数。然而,在1b模型中引出这种推理能力仍然是一个未解决的挑战,更不用说在多模态场景中了。本篇论文工作的重点是1b模型,因为它们可以用消费者级gpu(例如,32G内存)进行微调和部署。在本节中,作者进行了一些列实验,研究了为什么1b模型在CoT推理中失败,并研究如何设计一个有效的方法来克服挑战。
3.1 CoT的作用
首先,作者在ScienceQA基准测试上微调了CoT推理的纯文本基线,采用UnifiedQABase作为文本主体模型。3我们的任务被建模为一个文本生成问题,其中模型将文本信息作为输入,并生成由基本原理和答案组成的输出序列。如图1所示的一个示例,该模型将问题文本(Q)、上下文文本©和多个选项(M)的标记串联起来作为输入。
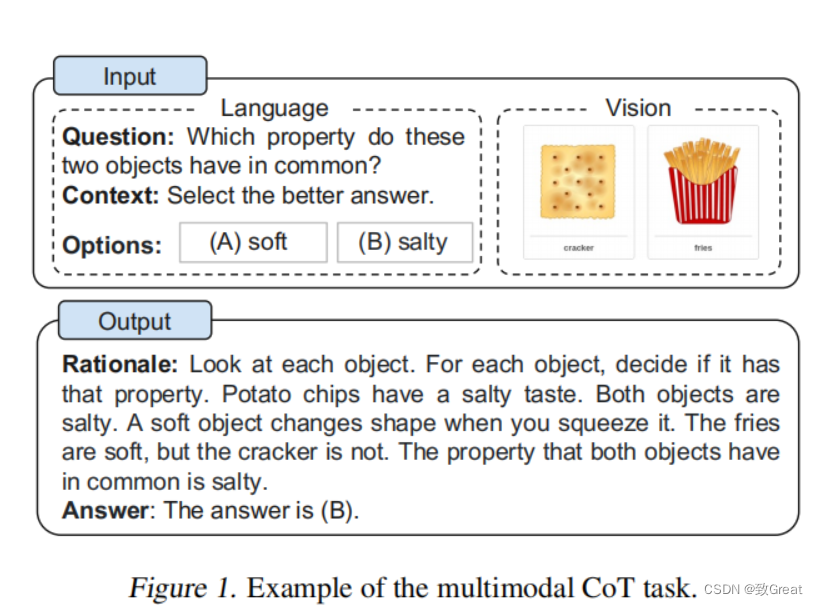
为了研究CoT的影响,我们将其性能与三种变量进行了比较: (i)直接预测答案(QCM→A)(无CoT);(ii)推理+预测答案(QCM→RA);(iii)预测答案+解释(QCM→AR)。

令人惊讶的是,我们观察到,如果模型在答案之前预测原因或者原理(QCM→RA),准确率下降↓了12.54%(80.40%→67.86%)。结果表明,这些理论原理不一定有助于预测正确的答案。在其他研究中也观察到类似的现象,其中合理的原因可能是模型在获得所需的答案之前超过了最大长度限制,或提前停止生成预测。然而,我们发现生成的输出(RA)的最大长度总是小于400个字符,这低于语言模型的长度限制(即UnifiedQABase中的512个)。因此,它值得更深入地研究为什么这些理论原理会影响答案推理效果。
3.2 模型被“幻觉”推理误导
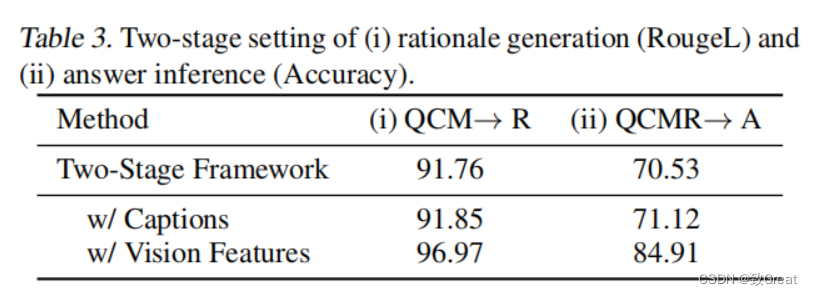
为了深入研究推理如何影响答案预测,我们将CoT问题分为两个阶段,推理生成和答案预测。我们计算出了推理生成和答案预测的RougeL分数和准确性。表3显示了基于两阶段框架的结果。虽然两阶段基线模型获得了91.76的RougeL分数,但答案推理精度仅为70.53%。与表2中的QCM→A(80.40%)相比,结果显示,在两阶段框架中生成的基本原理并没有提高答案的准确性。
然后,我们随机抽样50个错误案例,发现该模型倾向于产生误导答案推断的幻觉理由。如图2所示,

模型(左部分)产生幻觉,“一个磁铁的南极最靠近另一块磁铁的南极”。我们发现,这些错误在错误情况中发生的比例为64%

3.3 多模态有助于实现有效的基本推理
我们推测,这种幻觉推理现象是由于缺乏必要的来执行有效的多模态cot的视觉环境。为了注入视觉信息,一种简单的方法是将成对的图像转换为标题然后在两个阶段的输入中附加标题。然而,如表3所示,使用标题只能产生边际的性能提高(↑0.59%)。然后,我们通过将视觉特征合并到语言模型中来探索一种高级技术。具体地说,我们将成对的图像输入DETR模型来提取视觉特征。
然后我们在输入解码器之前 将视觉特征和语言表示融合。有趣的是,有了视觉特征,理论基础生成的RougeL得分已经提高到96.97%(QCM→R),这相应地有助于更好的回答准确率达到84.91%(QCMR→A)。有了这些有效的理由,幻觉现象就得到了缓解,其中62.5%的幻觉错误已经被纠正所示,视觉特征确实有利于产生有效的理由,并有助于准确的答案推断。由于表3中的两阶段方法(QCMR→A)比表2中的所有单阶段方法都有更好的性能,因此我们在多模态-cot框架中选择了双阶段方法。
4 多模态COT
总的来说,我们需要一个可以生成文本特征和视觉特征并利用它们生成文本响应的模型。又已知文本和视觉特征之间存在的某种交互,本质上是某种共同注意力机制,这有助于封装两种模态中存在的信息,这就让借鉴思路成为了可能。为了完成所有这些,作者选择了 T5 模型,它具有编码器 - 解码器架构,并且如上所述,DETR 模型用于生成视觉特征。
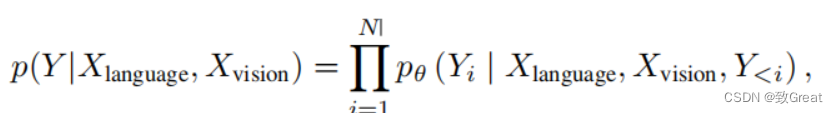
class T5ForMultimodalGeneration(T5ForConditionalGeneration):
_keys_to_ignore_on_load_missing = [
r"encoder.embed_tokens.weight",
r"decoder.embed_tokens.weight",
r"lm_head.weight",
]
_keys_to_ignore_on_load_unexpected = [
r"decoder.block.0.layer.1.EncDecAttention.relative_attention_bias.weight",
]
def __init__(self, config: T5Config, patch_size, padding_idx, save_dir):
super().__init__(config)
self.model_dim = config.d_model
self.padding_idx = padding_idx
self.out = open(os.path.join(save_dir, 'gate.txt'), 'w')
self.shared = nn.Embedding(config.vocab_size, config.d_model)
self.patch_num, self.patch_dim = patch_size
self.image_dense = nn.Linear(self.patch_dim, config.d_model)
self.mha_layer = torch.nn.MultiheadAttention(embed_dim=config.hidden_size, kdim=config.hidden_size, vdim=config.hidden_size, num_heads=1, batch_first=True)
self.gate_dense = nn.Linear(2*config.hidden_size, config.hidden_size)
self.sigmoid = nn.Sigmoid()
encoder_config = copy.deepcopy(config)
encoder_config.is_decoder = False
encoder_config.use_cache = False
encoder_config.is_encoder_decoder = False
self.encoder = T5Stack(encoder_config, self.shared)
decoder_config = copy.deepcopy(config)
decoder_config.is_decoder = True
decoder_config.is_encoder_decoder = False
decoder_config.num_layers = config.num_decoder_layers
self.decoder = T5Stack(decoder_config, self.shared)
self.lm_head = nn.Linear(config.d_model, config.vocab_size, bias=False)
# Initialize weights and apply final processing
self.post_init()
# Model parallel
self.model_parallel = False
self.device_map = None
4.1 编码器
模型F (X)同时接受语言和视觉输入,并通过以下功能得到文本表示
H
l
a
n
g
u
a
g
e
H_{language}
Hlanguage和图像特征
H
v
i
s
i
o
n
H_{vision}
Hvision:

T5 模型的编码器负责生成文本特征,但 T5 模型的解码器并没有利用编码器产生的文本特征,而是使用作者提出的共同注意式交互层(co-attention-styled interaction layer)的输出。
拆解来看,假设 H l a n g u a g e H_{language} Hlanguage是 T5 编码器的输出。 X v i s i o n X_{vision} Xvision 是 DETR 的输出。第一步是确保视觉特征和文本特征具有相同的隐藏大小,以便我们可以使用注意力层。
4.2 交互层
在获得语言和视觉表示后,我们使用单头注意网络将文本字符与图像像素相关联,其中查询(Q)、键(K)和值(V)为
H
l
a
n
g
u
a
g
e
H_{language}
Hlanguage,
X
v
i
s
i
o
n
X_{vision}
Xvision 和
X
v
i
s
i
o
n
X_{vision}
Xvision ,其中注意力输出
H
v
i
s
i
o
n
a
t
t
n
∈
R
n
∗
d
H^{attn}_{vision} \in R^{n*d}
Hvisionattn∈Rn∗d被定义为:

然后,我们应用门控融合机制如去融合文本和视觉特征
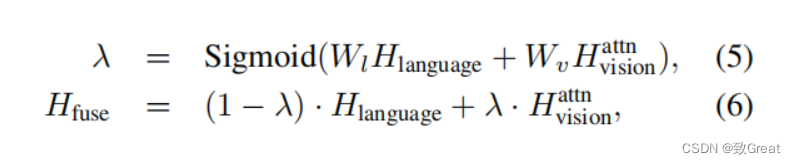
hidden_states = encoder_outputs[0]
image_embedding = self.image_dense(image_ids)
image_att, _ = self.mha_layer(hidden_states, image_embedding, image_embedding)
merge = torch.cat([hidden_states, image_att], dim=-1)
gate = self.sigmoid(self.gate_dense(merge))
hidden_states = (1 - gate) * hidden_states + gate *
4.3 解码层
最后,解码器将融合的输出
H
f
u
s
e
H_{fuse}
Hfuse输入transformers,预测目标Y。算法1显示了多模态COT的完整过程。

5 实验结果
作者使用 UnifiedQA 模型的权重作为 T5 模型的初始化点,并在 ScienceQA 数据集上对其进行微调。他们观察到他们的 Multimodal CoT 方法优于所有以前的基准,包括 GPT-3.5。有趣的地方在于,即使只有 2.23 亿个参数的基本模型也优于 GPT-3.5 和其他 Visual QA 模型!这突出了拥有多模态架构的力量。
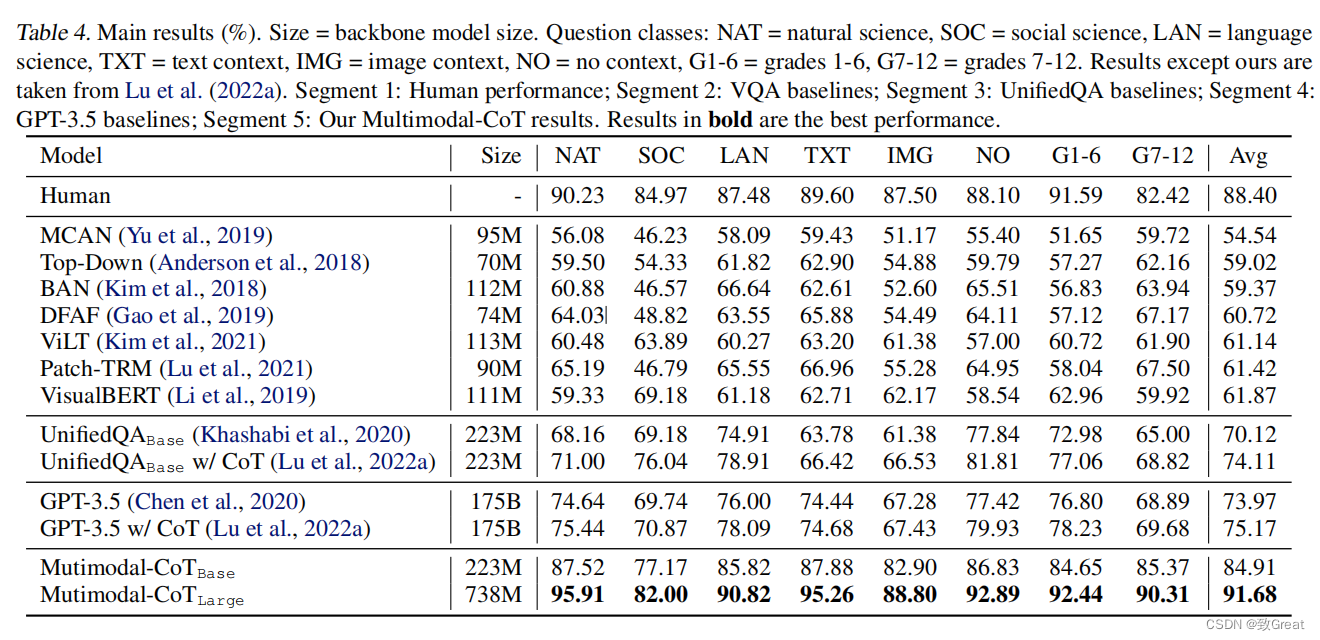
作者还展示了他们的两阶段方法优于单阶段方法。

6 实验结论
文本深刻研究了多模态CoT的问题,提出了多模态cot,它将语言和视觉模式整合到一个两阶段的框架中,将基本推理生成和答案预测分开,因此答案推理可以利用从多模态信息中更好地生成的基本推理。通过多模态cot,结果表明该方法在ScienceQA基准上的准确率超过GPT-3.5 有16个百分点。
这篇论文带来的最大收获是多模态特征在解决具有视觉和文本特征的问题时是多么强大。
- 作者展示了利用视觉特征,即使是小型语言模型(LM)也可以产生有意义的思维链 / 推理,而幻觉要少得多,这揭示了视觉模型在发展基于思维链的学习技术中可以发挥的作用。
- 从实验中,我们看到以几百万个参数为代价添加视觉特征的方式,比将纯文本模型扩展到数十亿个参数能带来更大的价值。
参考资料
- 超越GPT 3.5的小模型来了!
- Chain of Thought论文、代码和资源【论文精读】 - 哔哩哔哩
- 思维链(Chain-of-thoughts)作为提示 - 知乎<
- Chain of Thought 开山之作论文详解 - 知乎
- 思维链微调Fine-tune-CoT方法:大型语言模型教小模型一步一步推理 - 智源社区
- 有了Fine-tune-CoT方法,小模型也能做推理,完美逆袭大模型 - 智源社区
- 首个标注详细解释的多模态科学问答数据集,深度学习模型推理有了思维链-51CTO.COM
- 上海交大&亚马逊|语言模型的多模态思想链推理 - 智源社区