Java线程池参数调优
- 前言
- 线程池常见误解
- ■ 必须用线程池 不能直接new线程
- ■ 7参数的生效顺序
- 结论
- Java线程池参数调优
- ■ 网上流传的线程数计算公式
- ■ 调整生产消费平衡
- 疑问① 能否直接设置大量线程数
- 疑问② 这个核心数最好吗
- ■ 经典案例-业务请求第三方接口
- ■ 反思过去配置的线程池
- 结论
- ■ 让线程榨干CPU
- **大总结*
- 最后
前言
On a scale of one to 10, how happy are you as a couple?
从1分到10分你们会给彼此之间的感情打几分?
Eight.
8分
这是电影《史密斯夫妇》中史密斯夫妇互相打分台词。
大多数开发例如我,和多线程的关系就像史密斯夫妇一样,一直过着平淡无奇的生活,同床共枕却不曾知根知底,只有哪天炸雷,捅破了真实身份,才会刺激起来,最终真正理解相爱。
我通过观察任务管理器、资源监视器,用极端的Java程序来调试Java线程池。
线程池常见误解
■ 必须用线程池 不能直接new线程
无论社交平台还是IT论坛经常看到有两种极端。
一种通常是新手转行,真实项目少,迷信八股——哎呀,不能直接new Thread。诶,阿里巴巴手册说了禁用三方法,必须手配7参数。
另一种通常是老油条,一直做低并发项目,就会大意——我偏偏就new Thread,公司都黄几个了项目都没炸,怎么不能用。就算出了问题,我已经在下下家了。
不做极端,应当真正理解3方法7参数4拒绝策略,因地制宜。
■ 7参数的生效顺序
其中最重要的是7参数。
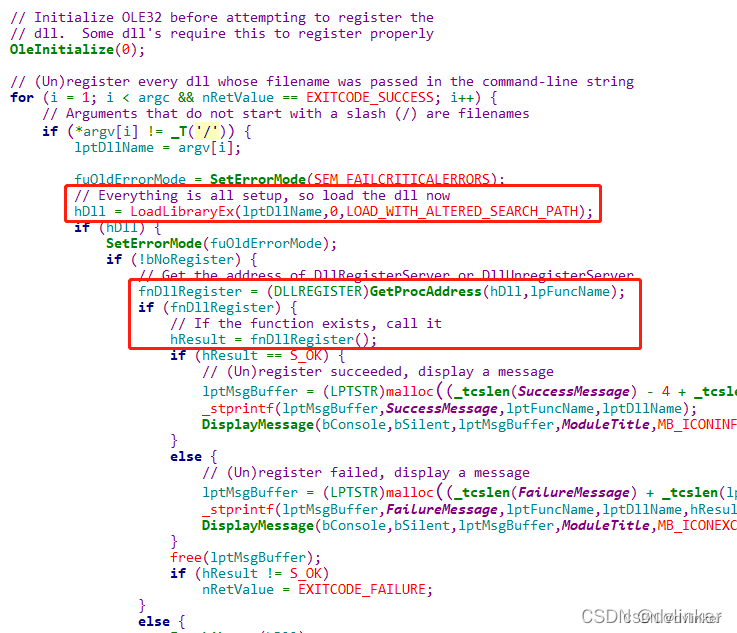
由于corePoolSize, maximumPoolSize相邻,曾误认为超过核心线程数,它们唯一区别是空闲keepAliveTime(unit)会销毁。错!这样就会无法理解阻塞队列workQueue和maximumPoolSize设计的美感。
corePoolSize就会马上启用maximumPoolSize的线程
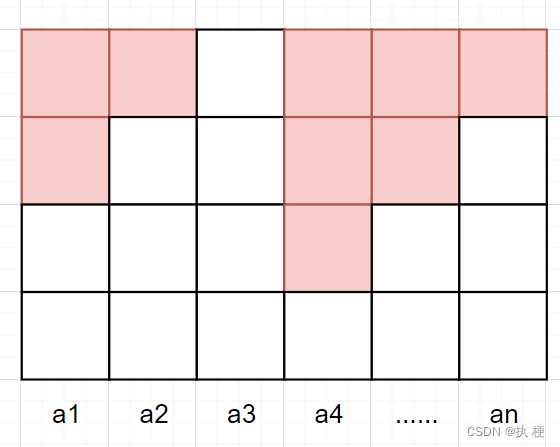
盗个图

一图简单明了,超出核心线程处理先存入队列,队列满了才加线程数,再处理不来才拒绝。
代码测试
首先是一个计时器,类似这种就应该直接new Thread,不必复杂化。
然后设定一个核心线程为1,队列为6,最大线程3(备用线程2个)的线程池,
每100毫秒提交一个运行1秒的任务,执行20次。然后休眠一段时间以上重复操作。
static void cpu() throws InterruptedException {
new Thread(()->{
for (int i = 0; i < 9999; i++) {
System.err.println("计时:" + i + "===========================================");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
BlockingQueue workQueue = new ArrayBlockingQueue<Thread>(6);
ExecutorService executorService = new ThreadPoolExecutor(1, 3, 10000,
TimeUnit.MILLISECONDS, workQueue, new ThreadPoolExecutor.AbortPolicy());
for (int i = 1; i <= 20; i++) {
int finalI = i;
try {
executorService.execute(() -> {
System.err.println("【队列:" + workQueue.size() + "】[执行任务" + finalI + "] " + Thread.currentThread());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.err.println("【队列:" + workQueue.size() + "】[任务" + i + "]加入线程池");
} catch (RejectedExecutionException e) {
System.err.println("抛弃任务:"+ finalI);
}
Thread.sleep(100);
}
Thread.sleep(4880);
for (int i = 21; i <= 40; i++) {
int finalI = i;
try {
executorService.execute(() -> {
System.err.println("【队列:" + workQueue.size() + "】[执行任务" + finalI + "] " + Thread.currentThread());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.err.println("【队列:" + workQueue.size() + "】[任务" + i + "]加入线程池");
} catch (RejectedExecutionException e) {
System.err.println("抛弃任务:"+ finalI);
}
Thread.sleep(100);
}
}
执行结果
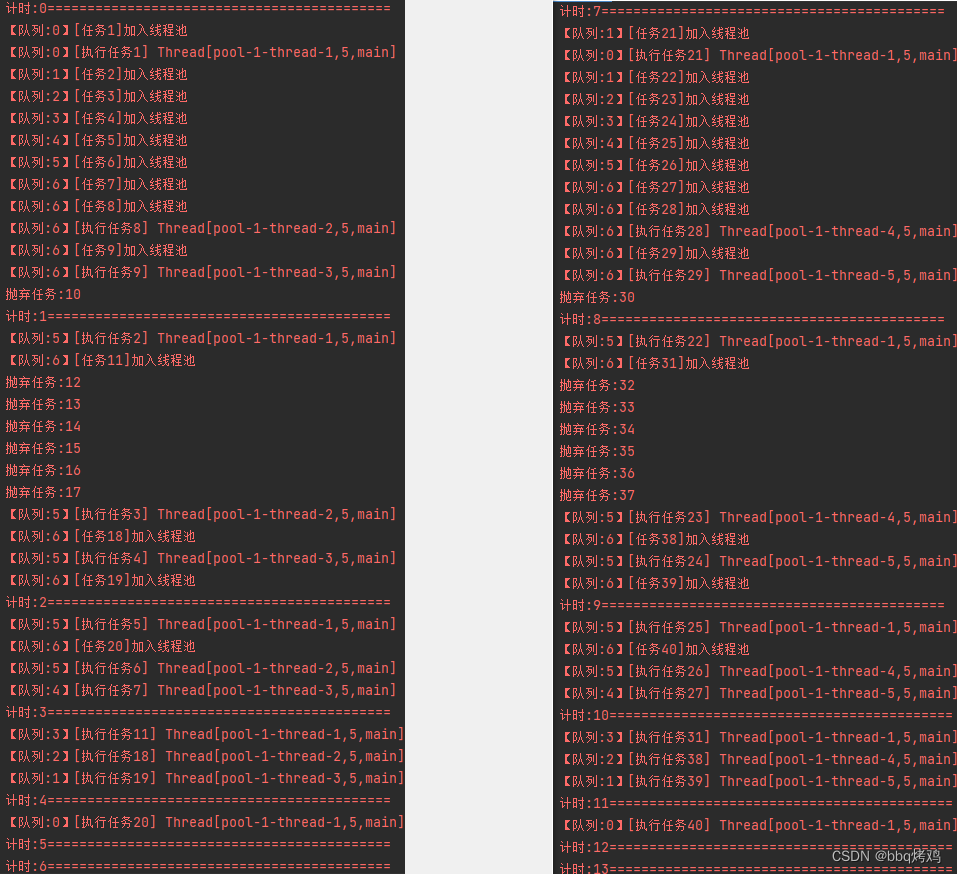
现象
先核心线程执行任务1,任务2 ~ 7排队(满6个),开启备用线程处理任务8 ~ 9,都满了,抛弃任务10。
核心线程空闲了——执行队列任务2,队列空一个——任务11排队,抛弃任务12~17,备用线程空闲了——处理队列任务3 ~ 4,任务18 ~ 19排队。
隔了几秒后重复结果大致相同,不过备用线程已被销毁换了新的。
如果keepAliveTime改大,结果不同,备用线程会继续工作。
结论
打个比喻,银行固定corePoolSize个柜台处理业务,处理不过来就排队,排队将要排到门外(满workQueue),新来的人排不了队,直接进去触发新的柜台,直到满maximumPoolSize个柜台,再超出的人就handler方式拒绝了,新柜台一起处理排队的人直到队列空了,再等待keepAliveTime (unit)才销毁。
也就是说new Thread也是有简单应用场景的。而创建线程池可以管理线程,复用线程,还能控制线程数量,当积压过多时启用备用线程但不超过设定。
Java线程池参数调优
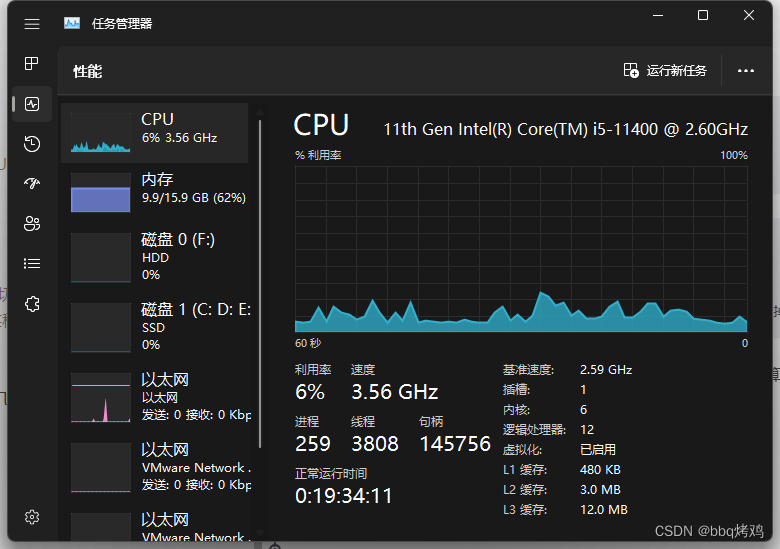
CPU配置
i5-11400 6核12线程
■ 网上流传的线程数计算公式
无脑套用你就会发现很荒谬。
【IO密集型】
算法① CPU核心数 * 2
【CPU密集型】
算法② Cpu核心数+1
主要消耗 CPU 资源,避免内核态和用户态频繁来回切换,
+1是因为当下很多 CPU 支持超线程技术和线程出于某种原因阻塞或者挂掉可以进行补位
【混合型】
算法③ (线程等待时间与线程CPU时间之比 + 1)* CPU数目*CPU 使用率
上文案例线程中只有Thread.sleep,cpu运算几乎没有,当作io密集型。
用算法① 6*2=12
测试代码
稍作修改,阻塞队列改为无界,也就是说后面几个参数都无用了,线程数为12。模拟一个为期10s、QPS为100的并发,
static void cpu2() throws InterruptedException {
...// 如上计时器引入
BlockingQueue workQueue = new LinkedBlockingQueue <Thread>();
ExecutorService executorService = new ThreadPoolExecutor(12, 1000000, 10000,
TimeUnit.MILLISECONDS, workQueue, new ThreadPoolExecutor.AbortPolicy());
for (int i = 1; i <= 1000; i++) {
int finalI = i;
executorService.execute(() -> {
System.err.println("【队列:" + workQueue.size() + "】[执行任务" + finalI + "] " + Thread.currentThread());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
//System.err.println("【队列:" + workQueue.size() + "】[任务" + i + "]加入线程池");
Thread.sleep(10);
}
}
执行结果
消费跟不上生产,队列越来越大,直到不生产队列才开始慢慢降下来。
后面的任务延时太久才执行,而CPU却毫无压力,显然这个算法是在扯淡,就算换成真正的IO操作,瓶颈也在IO关CPU啥事,大概率是在流传中慢慢被曲解了用法,详看下文。
■ 调整生产消费平衡
上面的结果给了我们启发,不耗CPU就该多建立线程去处理任务,否则会任务堆积,导致任务不及时处理,不进队列是最理想的效果。
生产QPS为100,任务平均执行时间为1s,也就是说1s内我们必须处理100任务,需要(算法100*1S)=100,,直接调100,几乎不进队列了,意味着生产即消费。
然后就跟调超频一样再往下压榨,发现65才是最低平衡点。
数不对,找了一番后发现提交线程也是要耗时的,不可忽略,循环1000大约需要15 ~ 16s完成,也就是QPS非100,而是1000/15~16≈65,这下对了,算法无误。
初得结论?
【非CPU密集型】?
算法④ QPS*任务平均执行时间
疑问① 能否直接设置大量线程数
调整代码,循环改久,延时尽可能去掉,模拟最大的QPS。
QPS越高线程数得越多,那我摊牌了,直接核心线程设置1000000,免去计算。
结果很糟糕,不一会儿就黑屏了,动弹不得,后台音乐还播放着。
然后重启电脑设置40000,检测到全部进程都终止了。但是不太对,窗口几乎都还在,不慌,点击菜单监视器停止再开启,正常了,原来最先奔溃的是监视。
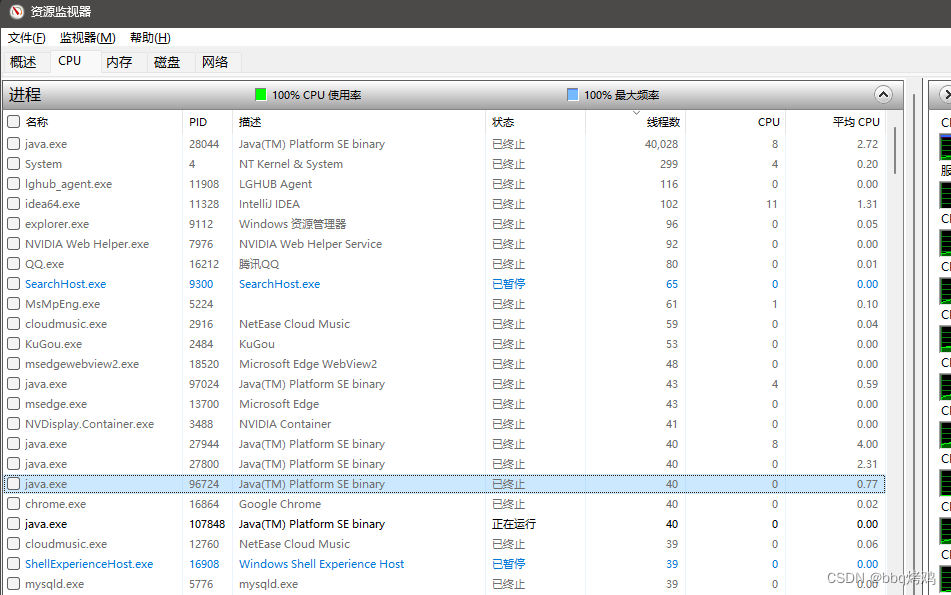
然后再调高,跑20w。发现内存不断飙高,直到顶峰,开始消耗虚拟内存。
真相大白了,系统崩溃是内存问题,老问题了,以前写的这篇文章详细记载了。
winserver物理内存使用不到一半就频繁爆内存
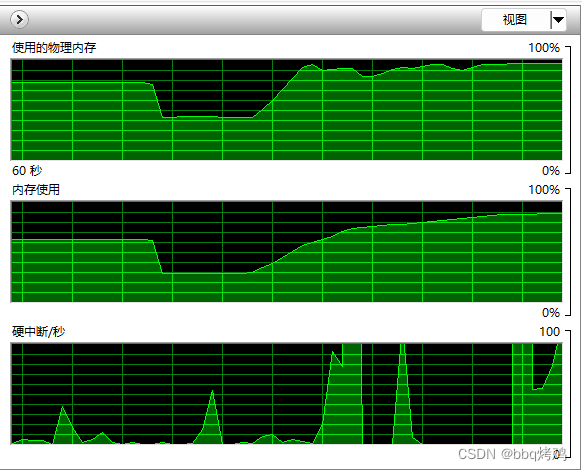
所以得在线程数量尽可能低的前提下去保障处理效率。线程多了,上下文切换损耗你说看不见,那线程占用内存是可见的吧。
疑问② 这个核心数最好吗
答案是否定。因为Demo任务内容为睡眠操作非真正io。
如果代码改为io操作,比如任务为移动4K小文件,文件为23MB小文件,磁盘读30MB/s,写100MB/s,移动耗时大概1s等同于睡眠时间。
那一个线程就把磁盘都占用满了,第2个线程可能是耗时翻倍。这种情况下,设置如上面65的线程核心数有什么用?没有用,3个线程都嫌多。
当然,上面的传输也是极端IO现象,大多数情况IO仅占用操作一部分,并且单文件移动不好跑满磁盘,4k文件才容易跑满磁盘。
再得结论?
【非CPU密集型、非IO密集】
算法④ QPS*任务平均执行时间
【 IO密集型】
没有算法,取决于IO瓶颈
■ 经典案例-业务请求第三方接口
任务中进行了http同步请求,阻塞接受结果进行业务处理。
这是后端开发最常见的多线程运用场景。
例如腾讯api给你限制了100QPS,接口耗时30ms,1000/30 * n = 100(1000ms除以耗时计算单线程QPS,n个线程达到100QPS),理想平均并发=100*30/1000=3并发即可。
假如接口耗时10ms 理想平均并发=100*10/1000 = 1并发。
假如接口不限流,那你直接打满并发就行了,忽略带宽并发无上限,上限取决于网络io,比如我曾经做过调用AI接口传参图片Base64编码,这个网络IO就非常大,没达到限流QPS标准就请求不动了,还会影响其它接口的网络IO请求。
极端下你的业务总耗时等同于第三方接口请求耗时也是30ms。那你撑死也就100QPS,并发也是3,线程数为3即可。
如果是非纯IO,还掺杂其它类似sleep非cpu、非io操作,接口总耗时1s。那又回到了之前那个算法,需要100个线程,也就是线程数范围在3 ~ 100 区间。
可靠结论?
【非CPU密集型、非IO密集】
算法非常复杂,没有定式
受限于IO瓶颈、你的业务耗时( 算法④ 任务QPS*任务平均执行时间(可以配置尽量大的线程数)),根据木桶理论找最短板得出你请求的瓶颈【IO密集型】
没有算法, 取决于IO瓶颈。
比如第三方请求,受限于网络IO,第三方限流。
■ 反思过去配置的线程池
那我曾经配过这么一个线程池,业务中存在调用第三方接口上传图片Base64,图片一般为100KB偏下,那这台服务器的上传带宽仅为10M,也就是大约1.25Mb/s,那么大约每秒只能上传15张照片。客户端先请求业务接口,业务接口负载调用这个服务,分发的QPS大约为10,某秒极端可能卡到100个请求,那我无脑改大了核心线程数量,数量直接配60,让它积压,确实整体也没啥大问题,当然并发到来时,接口变成非即时,卡顿,这个无碍,并发不是平均的,一会儿就消费下来了,可以接受延时结果。
统计稳定期间接口平均响应时间(每10分钟)大概在0.6s,算法④ 计算10*0.6=6,也就是说,平时只需要6个核心线程就可以处理响应。如何处理请求曲线突刺?要么牺牲些许即时丢入队列,要么缩短平均的计时单位。例如平均每5s作为平均值,然后取每分钟12个平均值中最大的平均值,这个平均值肯定偏大,然后再取小时中这个值的众数或平均数作为平均值,越稳定的请求越接近6,很有可能是7或8。
那最大TPS受限于前面说的网络IO-图片上传,同理也可能是16~17TPS。
可得出一个看似完美的配置 corePoolSize = 7 maximumPoolSize = 16
仅仅这么做,问题可大了,虽然处理上限是16TPS,但是这么设定的话,当并发到来时,工作队列设定太大,难以触发备用线程,导致处理慢,工作队列设定太小,默认拒绝策略,单位时间超出的请求将会被抛弃(我们是接受一定时间内的非即时处理的)。
下策 唯一的不抛弃拒绝策略是CallerRunsPolicy,但是都抛给了主线程不就又回到了不安全线程案例。
中策 16作为核心线程数,采取无界队列,线程不饱和,利用率低,会有更多传说中的内核态和用户态切换损耗,没达到完美,但是接受处理是最快的,并发超出时,全部任务会相对延迟了,这个不太好。
上策 采取双队列。从源头就限流16,多出来的存入MQ,理想情况下不会抛弃任务。
另一种是最好的,默认拒绝策略,从抛出异常这里拉入MQ,然后异步重新消费。
显然,我配置的60个线程大大超出了线程数瓶颈,更多的是把休眠中线程当成一种存储任务的道具。放开线程数量省去计算瓶颈还能避免任务丢失,这是非常多老油条常犯的错误,能跑就行,甚至会说这点损耗对系统毫无影响。
结论
【纯IO密集型】
算法⑤ 取决于IO瓶颈。
比如磁盘IO瓶颈、
第三方请求,受限于网络IO,第三方限流。【非CPU密集型、非IO密集】
算法非常复杂,没有定式,
算法④ 任务QPS*任务平均执行时间(每小时的[每分钟的(平均每5s)的最大值]的平均值)
这个公式是业务耗时推导出来的并发数,根据木桶理论找最短板得出你的请求瓶颈,有可能受限于IO,也有可能受限于CPU,还有可能受限于内存。
也就是说,可以利用算法④去求得业务的平均并发数作为核心线程数,算法⑤ IO瓶颈或CPU瓶颈(一般会预留点不会压榨到百分百)得出的并发数作为最大线程数,采用默认拒绝策略,无法处理的拉入MQ,允许延迟则重新消费,不允许延迟则备份入库作为记录,可以做类似这种的可靠消费补偿。
■ 让线程榨干CPU
单线程能把多核CPU跑满吗?
答案是不能。
1、空循环占用CPU吗?
2、单线程最多跑满多核CPU的多少?
3、单线程能否跑满多核CPU的单核?
4、需要几个线程跑满多核CPU?
抱着疑问写下代码
代码
模拟CPU空转
static void cpu4() {
int core = 1;
for (int i = 1; i <= core; i++) {
int finalI = i;
new Thread(()->{
System.err.println(finalI +" "+ Thread.currentThread());
while (true) {
}
}).start();
}
}
观察任务管理器,1线程-20% || 2线程-46% || 3线程-46% || 4线程-59% || 5线程-73%|| 6线程-87%
值大概在这附件上下浮动,7线程稳定百分百cpu。
观察资源监视器,单线程占用CPU是会平摊到12个虚拟线程上面的,毫无规律。

得出答案
1、空循环占用CPU。
2、单线程最多跑满n核CPU的100/n%,但永远达不到
3、单线程无法接近跑满多核CPU的单核,因为它会由多核cpu轮番跑,不会仅占用一个cpu核心。
4、需要n+1线程跑满n核CPU
这里得出,算法②CPU核心数+1 存在一定道理。但是这是求——跑满CPU的最佳线程数的算法,不是常规线程池配置的算法,显然算法③也是针对CPU的算法。
经典现象
如果写过辅助脚本、宏之类的话,会对CPU空转代码造成的负面影响非常熟悉。比如滥用循环监控某个值,明显感觉到电脑开始卡顿,然后在循环中加入sleep(1)之类的,卡顿消失。
也就是说算法②③适用于全力让CPU攻破某个运算,比如类似GPU挖矿,不然肯定影响系统的其它操作。
*大总结
Java多线程的应用的是分使用场景的。
分类
① 简单异步
② 被动干活 — 银行柜台 (任务自动送上门,匹配上强度就行,不出意外就能领工资)
开发者作为万恶的资本家,就是计算平时需要的最少员工,峰流所需的临时工,只要员工挂不了,就聘请最少的员工干活。反正平时流量也就那些,多请员工只会浪费开出的工资,还会让员工摸鱼。【例 大厂留一定的精英作为核心线程,干不过来了就招些外包,闲了就遣散外包】
③ 主动找活干 — 挖矿 (多劳多得,往死里干,钱越多)
开发者作为矿老板,矿场里的花嫁越大声,别墅越大,不要顾虑其它,争分夺秒的挖。
【例 外包公司来了个大项目,所有项目组全部过来干这个,晚上通宵加班不死就给加班费】
用法
① 直接new Thread
② 常见于服务端。算法④求得平时流量所需核心线程数。阻塞队列不用配置太大,能稳住低频率的小并发突刺就行。最大线程数的计算需要考虑多方面,CPU瓶颈(算法②③)、IO瓶颈、内存瓶颈、甚至GPU瓶颈、第三方限制等,根据木桶理论找出短板,求得系统能稳定运行前提的最大TPS,根据这个TPS由算法④求得系统能稳定运行的最大线程数,然后采用默认阻塞队列,捕获异常,抛弃的任务丢入分布式MQ做业务补偿或者抛弃日志等。
补充
1、求得的最大线程数不可能小于核心线程数,如果出现这种情况说明系统无法撑住常规流量,该升级配置或者负载均衡了。
2、备用线程空闲线程存活时间配置比较容易忽略,并发一般不是一直并发,偶尔可能也会停个10来秒,那这个备用线程空闲线程存活时间就一定得大于十来秒。
3、简单说就是统计TPS配置核心线程数(跟流量相关),压力测试配置最大线程数(跟配置相关)。
③ 常见于客户端。全力解决问题,不留一点余粮,只求速度,例如解压、挖矿、跑AI、解密。算法②③是这个场景下针对CPU的最佳线程数算法。
算法② Cpu核心数+1
算法③ (线程等待时间与线程CPU时间之比 + 1)* CPU数目*CPU 使用率
算法④ 任务QPS *任务平均执行时间(每小时的[每分钟的(平均每5s)的最大值]的平均值)
最后
线程池的参数可不是随便配置。一般人配线程池仅仅是为了防止突发大量线程崩溃系统,配小了又影响处理效率,直接配大参数,往往系统一卡顿再改大,美名其曰调优。不细究可能无所谓,深入了解后才明白配好线程池参数不仅能解决这些问题,还能节约资源,提高效率。开发对多线程的认知一定得是大结局的史密斯夫妇一样,万不可糊糊涂涂过日子。