2.1 爬虫的实现原理
不同类型的爬虫,具体的实现原理也不尽相同,但是这些爬虫之间存在许多共性。下面我将以通用爬虫与聚焦爬虫为例,具体来讲解爬虫是如何来运作的。
通用爬虫的工作原理
通用爬虫是一个自动提取网页的程序,能够从Internet上下载网页,是大多的搜索引擎的重要组成部分。
通用爬虫从一个或若干个初始的URL开始,获取初始网页上的URL,再爬去网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统程序的停止条件。
通用爬虫从互联网中收集网页、采集信息,这些网页信息用于为搜索引擎提供支持,它决定着整个引擎系统是否丰富,是否能够及时更新,因此设计出来的爬虫性能的优劣将直接影响着搜索引擎的搜索效果。
但是,用于搜索引擎的的通用爬虫其爬行的行为需要符合一定的规则,遵循一些命令或者文件的内容,如标出nofollow的链接,或者rebots的协议。(关于rebots协议的详细将会,在后面介绍)。
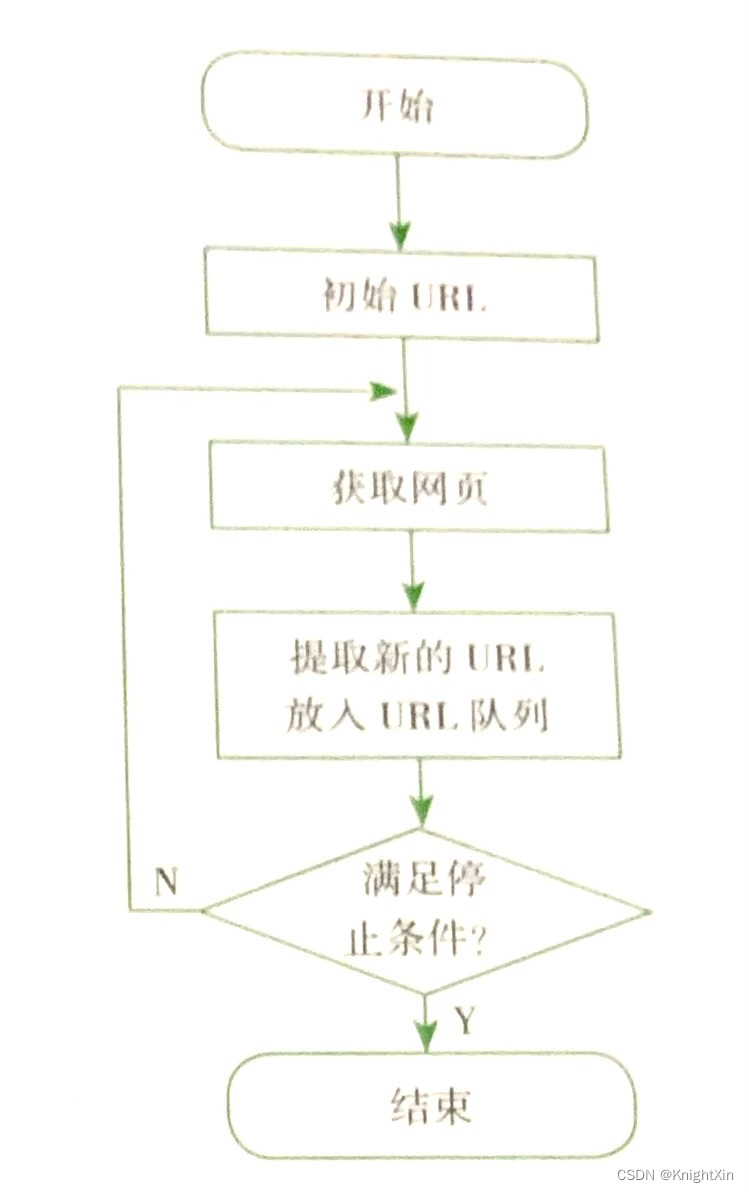
聚焦爬虫工作原理
与通用爬虫相比,聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法进行过滤与主题无关的链接,来保留需要的链接,并对其进行爬取。然后他将根据一定的搜索策略,从队列中选择要爬取的网页URL,并不断重复上述的过程,知道达到系统的某一条件时停止。
相对于通用网络爬虫,聚焦爬虫还需要解决3个主要的问题。
- 对爬