数据挖掘,计算机网络、操作系统刷题笔记53
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
与此同时,既然要考网警之数据分析应用岗,那必然要考数据挖掘基础知识,今天开始咱们就对数据挖掘方面的东西好生讲讲
刷题系列文章
【1】Oracle数据库:刷题错题本,数据库的各种概念
【2】操作系统,计算机网络,数据库刷题笔记2
【3】数据库、计算机网络,操作系统刷题笔记3
【4】数据库、计算机网络,操作系统刷题笔记4
【5】数据库、计算机网络,操作系统刷题笔记5
【6】数据库、计算机网络,操作系统刷题笔记6
【7】数据库、计算机网络,操作系统刷题笔记7
【8】数据库、计算机网络,操作系统刷题笔记8
【9】操作系统,计算机网络,数据库刷题笔记9
【10】操作系统,计算机网络,数据库刷题笔记10
【11】操作系统,计算机网络,数据库刷题笔记11
【12】操作系统,计算机网络,数据库刷题笔记12
【13】操作系统,计算机网络,数据库刷题笔记13
【14】操作系统,计算机网络,数据库刷题笔记14
【15】计算机网络、操作系统刷题笔记15
【16】数据库,计算机网络、操作系统刷题笔记16
【17】数据库,计算机网络、操作系统刷题笔记17
【18】数据库,计算机网络、操作系统刷题笔记18
【19】数据库,计算机网络、操作系统刷题笔记19
【20】数据库,计算机网络、操作系统刷题笔记20
【21】数据库,计算机网络、操作系统刷题笔记21
【22】数据库,计算机网络、操作系统刷题笔记22
【23】数据库,计算机网络、操作系统刷题笔记23
【24】数据库,计算机网络、操作系统刷题笔记24
【25】数据库,计算机网络、操作系统刷题笔记25
【26】数据库,计算机网络、操作系统刷题笔记26
【27】数据库,计算机网络、操作系统刷题笔记27
【28】数据库,计算机网络、操作系统刷题笔记28
【29】数据库,计算机网络、操作系统刷题笔记29
【30】数据库,计算机网络、操作系统刷题笔记30
【31】数据库,计算机网络、操作系统刷题笔记31
【32】数据库,计算机网络、操作系统刷题笔记32
【33】数据库,计算机网络、操作系统刷题笔记33
【34】数据库,计算机网络、操作系统刷题笔记34
【35】数据挖掘,计算机网络、操作系统刷题笔记35
【36】数据挖掘,计算机网络、操作系统刷题笔记36
【37】数据挖掘,计算机网络、操作系统刷题笔记37
【38】数据挖掘,计算机网络、操作系统刷题笔记38
【39】数据挖掘,计算机网络、操作系统刷题笔记39
【40】数据挖掘,计算机网络、操作系统刷题笔记40
【41】数据挖掘,计算机网络、操作系统刷题笔记41
【42】数据挖掘,计算机网络、操作系统刷题笔记42
【43】数据挖掘,计算机网络、操作系统刷题笔记43
【44】数据挖掘,计算机网络、操作系统刷题笔记44
【45】数据挖掘,计算机网络、操作系统刷题笔记45
【46】数据挖掘,计算机网络、操作系统刷题笔记46
【47】数据挖掘,计算机网络、操作系统刷题笔记47
【48】数据挖掘,计算机网络、操作系统刷题笔记48
【49】数据挖掘,计算机网络、操作系统刷题笔记49
【50】数据挖掘,计算机网络、操作系统刷题笔记50
【51】数据挖掘,计算机网络、操作系统刷题笔记51
【52】数据挖掘,计算机网络、操作系统刷题笔记52
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记53
- @[TOC](文章目录)
- 数据挖掘分析应用:DBSCAN聚类算法
- 基于层次的聚类算法
- 图分裂聚类算法
- 以太网交换机中的 端口/MAC 地址映射表()
- 使用 ping 命令 ping 另一台主机,就算收到正确的应答,也不能说明()
- 对于 ICMP 协议的功能,说法正确的是( )
- 当个人计算机以拨号方式接入Internet时,必须使用的设备是()。
- 如果系统只有用户态线程,则线程对操作系统是不可见的,操作系统只能调度进程;
- A的运行效率应该也是和C选项差不多的意思,使用虚拟内存,需要额外的进行地址映射等操作,程序的运行效率降低
- 以下哪些进程状态转换是正确的
- 是未开启分页机制的CPU访问存储器内信息时所用的地址。
- 现代操作系统的基本特征是()。
- 总结
文章目录
- 数据挖掘,计算机网络、操作系统刷题笔记53
- @[TOC](文章目录)
- 数据挖掘分析应用:DBSCAN聚类算法
- 基于层次的聚类算法
- 图分裂聚类算法
- 以太网交换机中的 端口/MAC 地址映射表()
- 使用 ping 命令 ping 另一台主机,就算收到正确的应答,也不能说明()
- 对于 ICMP 协议的功能,说法正确的是( )
- 当个人计算机以拨号方式接入Internet时,必须使用的设备是()。
- 如果系统只有用户态线程,则线程对操作系统是不可见的,操作系统只能调度进程;
- A的运行效率应该也是和C选项差不多的意思,使用虚拟内存,需要额外的进行地址映射等操作,程序的运行效率降低
- 以下哪些进程状态转换是正确的
- 是未开启分页机制的CPU访问存储器内信息时所用的地址。
- 现代操作系统的基本特征是()。
- 总结
数据挖掘分析应用:DBSCAN聚类算法
切割的聚类,假设是中心存在的
这个基于密度的聚类,区域内的密度高,才行
E领域,你这讲画个图啊???




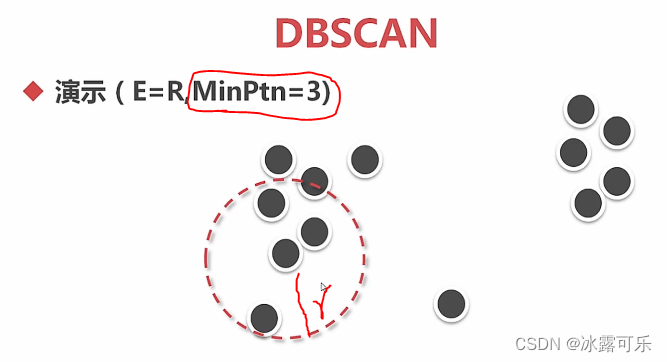
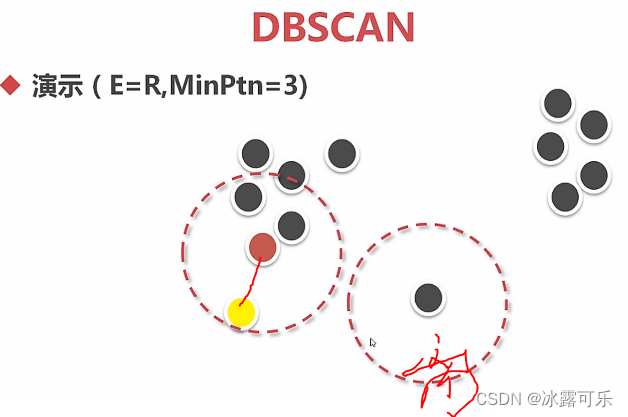
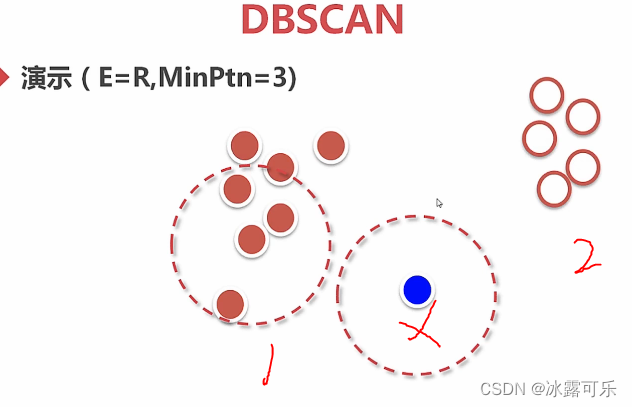
这也太笼统了,但是模型都有的,这都是现成的代码

代码玩
聚类半天,很骚啊
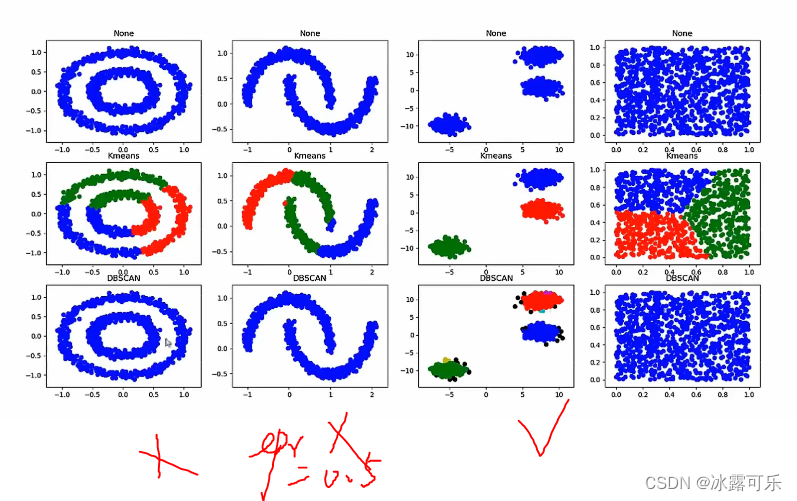
e领域半径太大不可
调整小的e领域,如果类别过多,颜色就没法搞
尺度可以考虑放小,让blobs数据集变回小间距数据
blobs = make_blobs(n_samples=n_samples, random_state=8, center_box=(-1,1), cluster_std=0.1) # 避免位置变化,范围
然后咱们利用基于密度的聚类
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles, make_blobs, make_moons
from sklearn.cluster import KMeans, DBSCAN
def kmeans():
n_samples = 1000 # 生成样本的个数
circles = make_circles(n_samples=n_samples, factor=0.5, noise=0.05) # factor俩圆之间的间距
moons = make_moons(n_samples=n_samples, noise=0.05)
blobs = make_blobs(n_samples=n_samples, random_state=8, center_box=(-1, 1), cluster_std=0.1) # 避免位置变化,范围
random_data = np.random.rand(n_samples, 2), None # 标注不使用
# print(circles) # 样本点和标注,标注不需要
colors = "bgrcmyk"
data = [circles, moons, blobs, random_data] # 四个数据集
# 模型——随意添加
models = [("None", None), ("Kmeans", KMeans(n_clusters=3)),
("DBSCAN", DBSCAN(min_samples=3, eps=0.2)) ]
# n分2类
f = plt.figure() # 给不同模型下,不同数据集的聚类情况画图
for index, clt in enumerate(models):
clt_name, clt_entity = clt # 前面是名字,后面是模型的实体
for i, dataset in enumerate(data):
X, Y = dataset # 生成好的数据集,后面标注不用
if not clt_entity:
clt_res = [0 for item in range(len(X))] # 数据中第一部分的维度
else:
# 有实体——拿着模型聚类去
clt_entity.fit(X) # 拟合
clt_res = clt_entity.labels_.astype(np.int) # 聚类之后,有自己的标签哦,拿出去展示,不同色
# 然后拿着结果作图去
f.add_subplot(len(models), len(data), index*len(data)+i+1) # 不同模型,多个数据
[plt.scatter(X[p, 0], X[p, 1], edgecolors=colors[clt_res[p]]) for p in range(len(X))]
# 每个数据都画出来
plt.show()
if __name__ == '__main__':
kmeans()
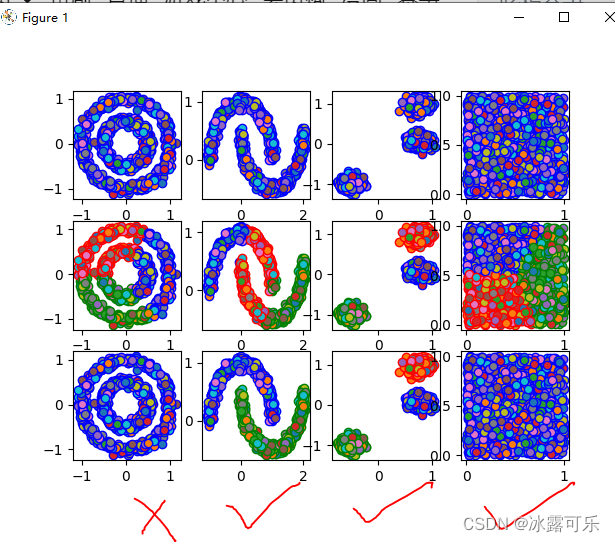
把半径再调整为0.1
这次OK了
美滋滋
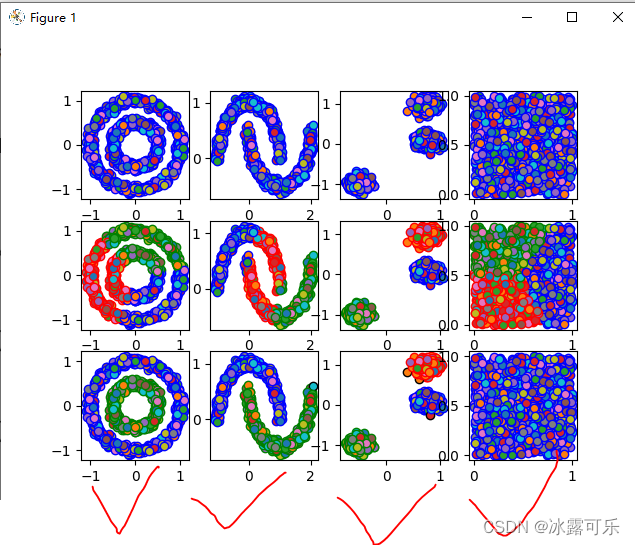
基于层次的聚类算法
相近的互联
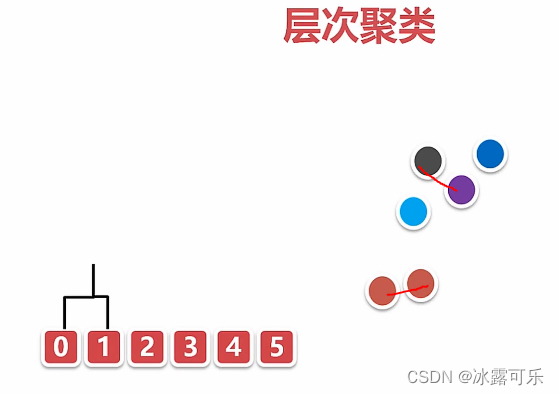
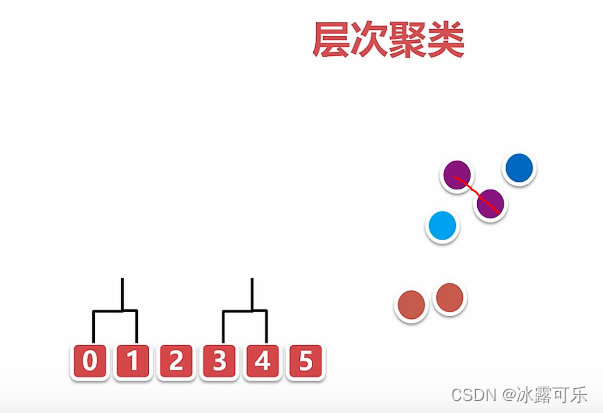
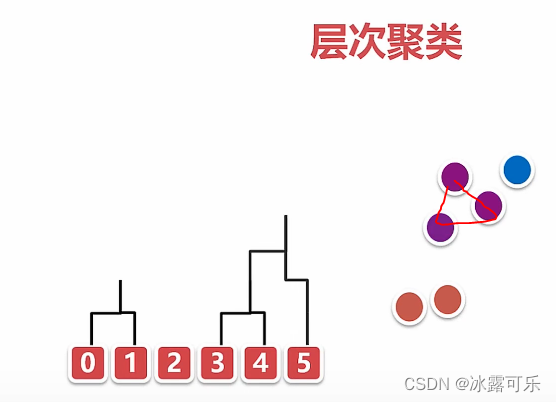
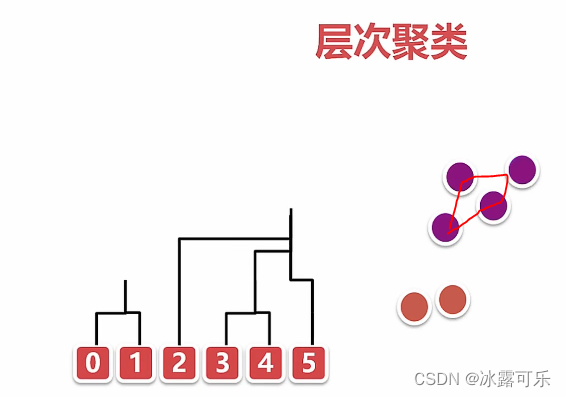
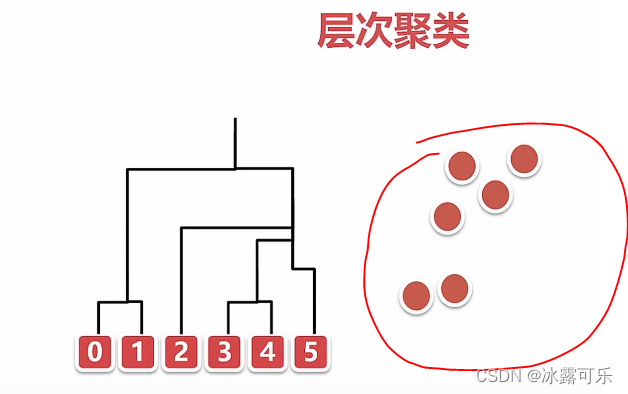
那簇与簇之间的距离
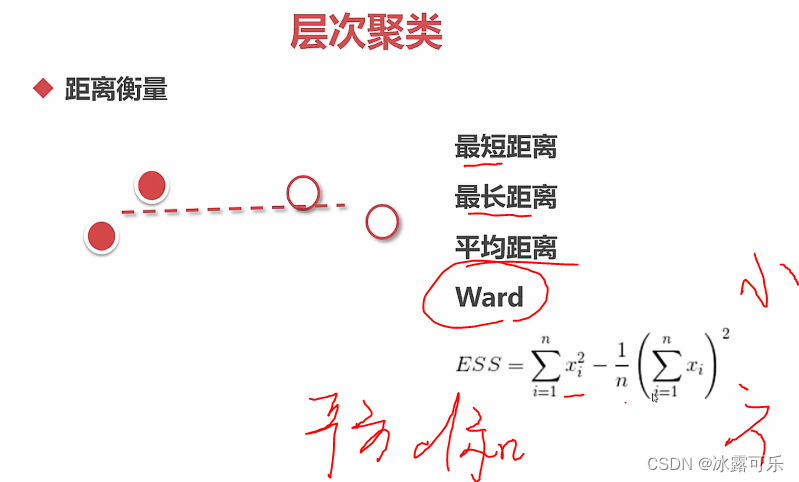

代码撸起来

complete是最大距离
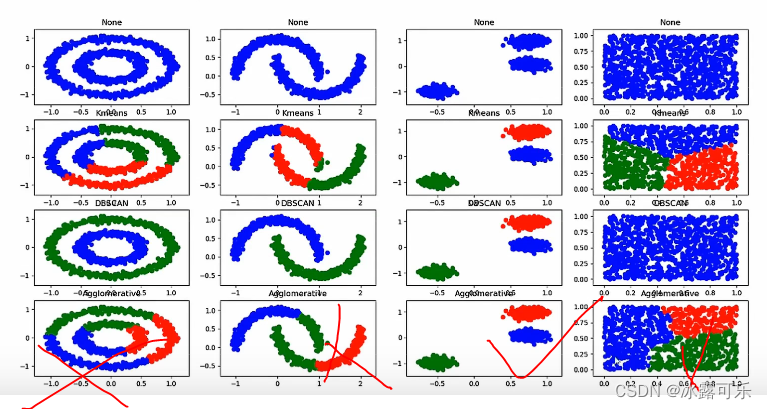
层次聚类不适合基于密度的聚类
离散的群落可能也gg
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles, make_blobs, make_moons
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
def kmeans():
n_samples = 1000 # 生成样本的个数
circles = make_circles(n_samples=n_samples, factor=0.5, noise=0.05) # factor俩圆之间的间距
moons = make_moons(n_samples=n_samples, noise=0.05)
blobs = make_blobs(n_samples=n_samples, random_state=8, center_box=(-1, 1), cluster_std=0.1) # 避免位置变化,范围
random_data = np.random.rand(n_samples, 2), None # 标注不使用
# print(circles) # 样本点和标注,标注不需要
colors = "bgrcmyk"
data = [circles, moons, blobs, random_data] # 四个数据集
# 模型——随意添加
models = [("None", None), ("Kmeans", KMeans(n_clusters=3)),
("DBSCAN", DBSCAN(min_samples=3, eps=0.1)) ,
("CengCi", AgglomerativeClustering(n_clusters=3, linkage="ward")) ]
# n分2类
f = plt.figure() # 给不同模型下,不同数据集的聚类情况画图
for index, clt in enumerate(models):
clt_name, clt_entity = clt # 前面是名字,后面是模型的实体
for i, dataset in enumerate(data):
X, Y = dataset # 生成好的数据集,后面标注不用
if not clt_entity:
clt_res = [0 for item in range(len(X))] # 数据中第一部分的维度
else:
# 有实体——拿着模型聚类去
clt_entity.fit(X) # 拟合
clt_res = clt_entity.labels_.astype(np.int) # 聚类之后,有自己的标签哦,拿出去展示,不同色
# 然后拿着结果作图去
f.add_subplot(len(models), len(data), index*len(data)+i+1) # 不同模型,多个数据
[plt.scatter(X[p, 0], X[p, 1], edgecolors=colors[clt_res[p]]) for p in range(len(X))]
# 每个数据都画出来
plt.show()
if __name__ == '__main__':
kmeans()
图分裂聚类算法
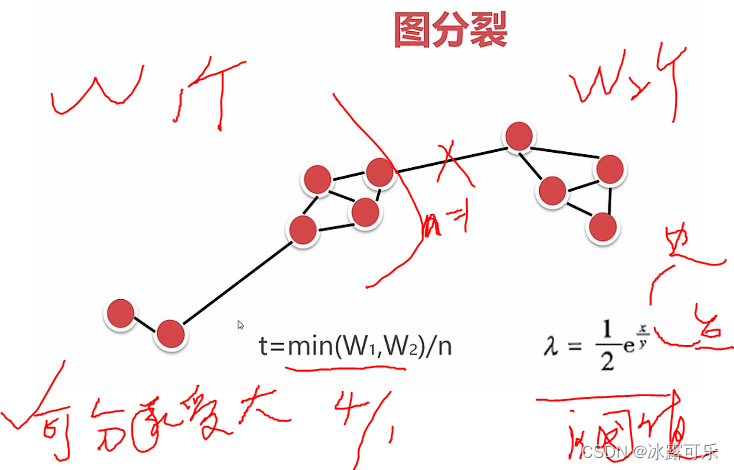
x条最大连通图的边
y个点
t=4
阈值是1.83
切
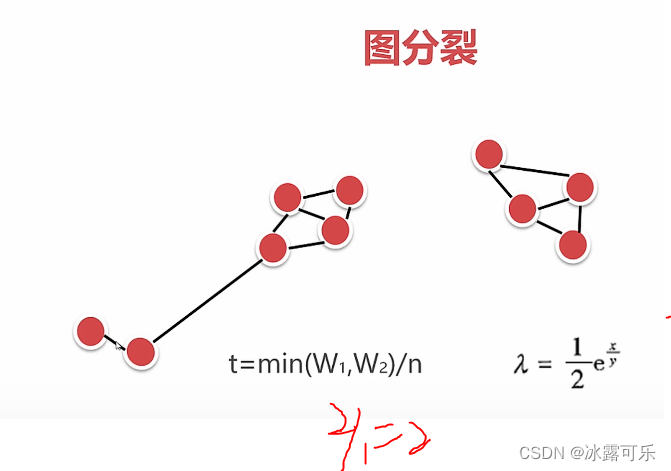
t=2,阈值1.60,切

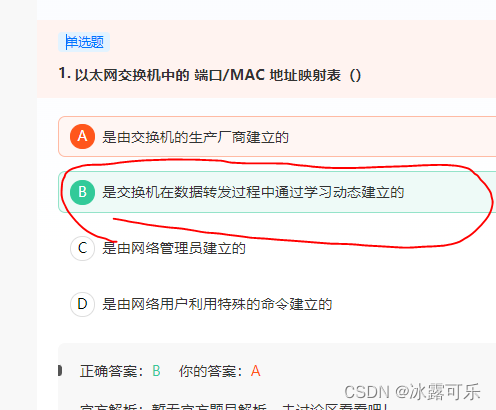
以太网交换机中的 端口/MAC 地址映射表()
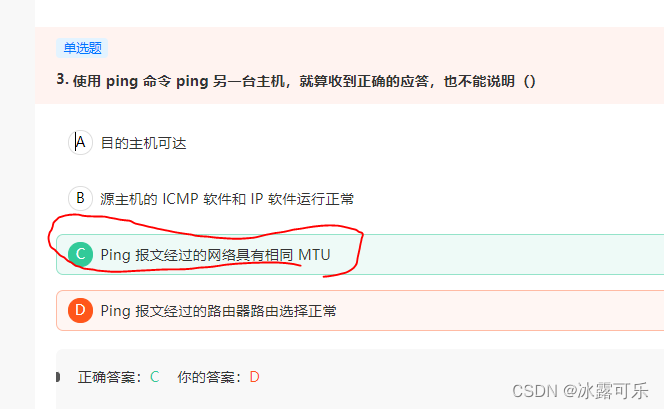
使用 ping 命令 ping 另一台主机,就算收到正确的应答,也不能说明()
对于 ICMP 协议的功能,说法正确的是( )

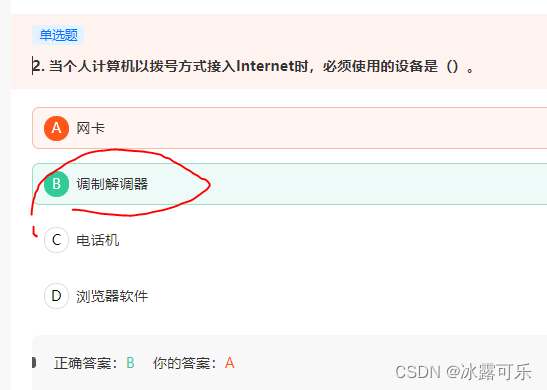
当个人计算机以拨号方式接入Internet时,必须使用的设备是()。
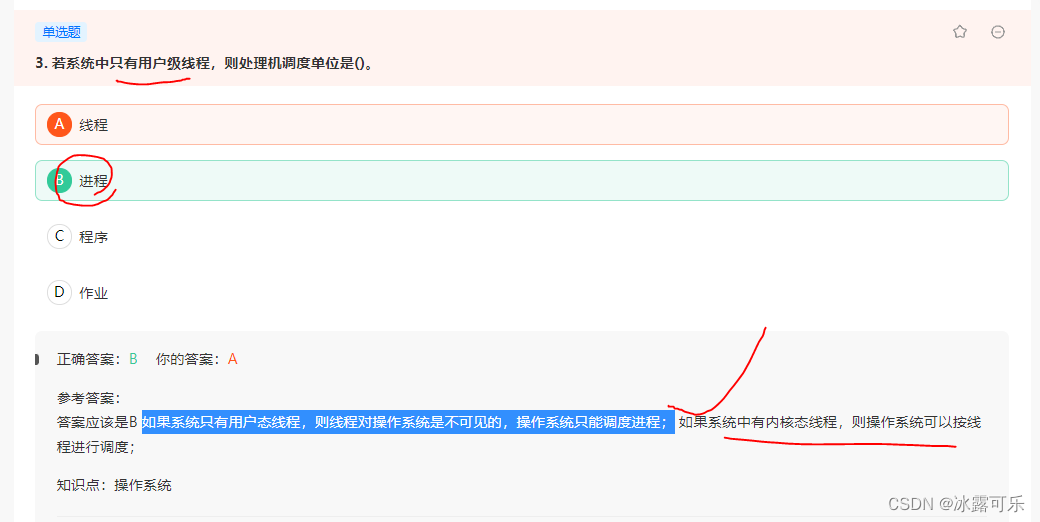
如果系统只有用户态线程,则线程对操作系统是不可见的,操作系统只能调度进程;
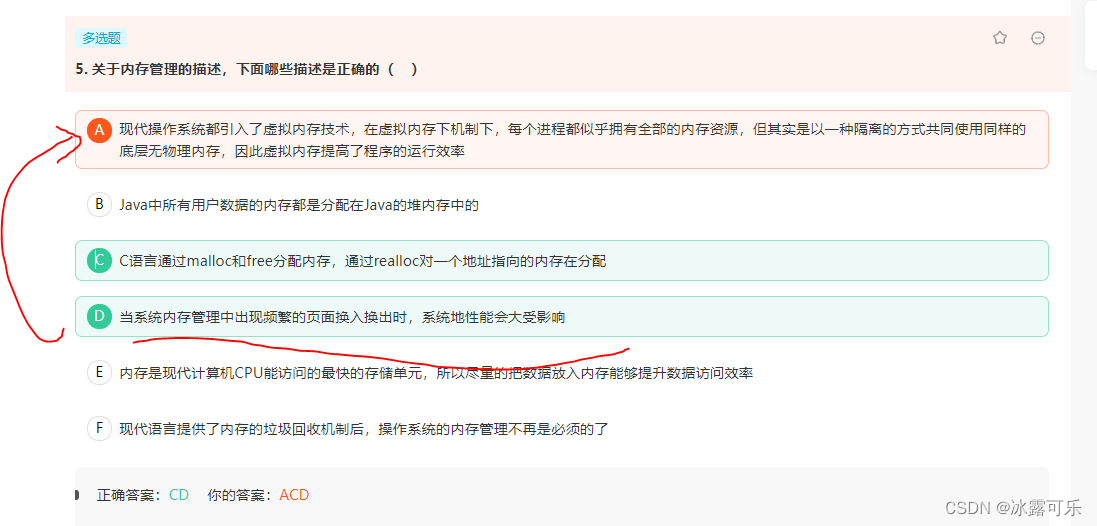
A的运行效率应该也是和C选项差不多的意思,使用虚拟内存,需要额外的进行地址映射等操作,程序的运行效率降低
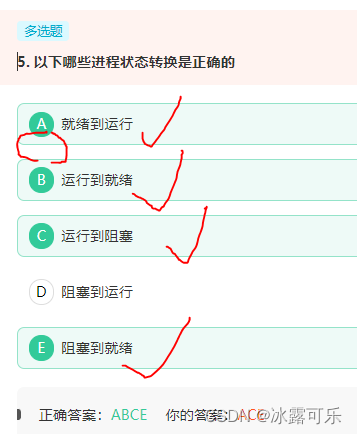
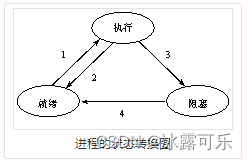
以下哪些进程状态转换是正确的
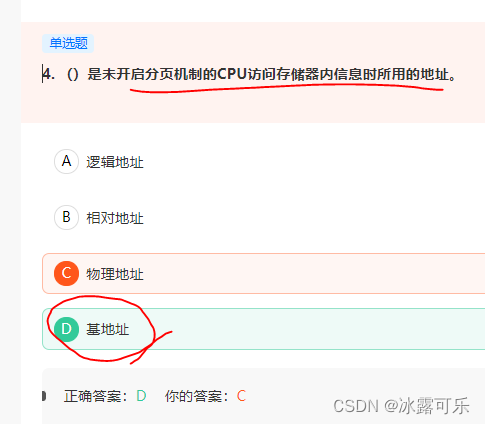
是未开启分页机制的CPU访问存储器内信息时所用的地址。
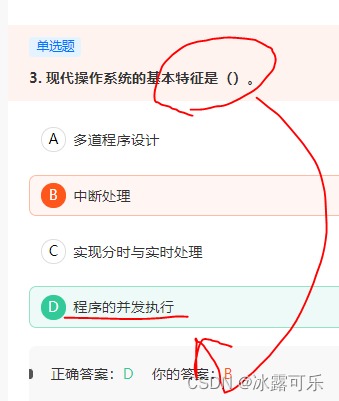
现代操作系统的基本特征是()。
总结
提示:重要经验:
1)
2)学好oracle,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。