用Numba:一行代码将Python程序运行速度提升100倍
在《用PyPy加速Python程序》中我们看到,PyPy通过JIT技术可以将Python的运行速度平均提高3-4倍。但即便是提升后,Python的执行速度依然无法与C/C++/Rust同日而语。并且PyPy对Python程序的优化对开发者来说完全是个黑盒,我们不能指定优化的部分,更不知道PyPy优化了哪里。Numba可以一定程度上解决了PyPy的上述问题。按照Numba的说法,经过Numba优化过的数值算法,其运行速度媲美C和Fortran。今天我们就来看一下如何用一行代码将Python的性能提升至C语言的水平。

文章目录
- 什么是Numba
- 安装Numba
- Numba初体验
- Numba加速原理
- 使用案例
- 案例1:计算$\pi$
- 案例2:寻找最近点
- 总结
什么是Numba
Numba是一款可以将python函数编译为机器代码的JIT编译器,由Anaconda公司主导开发,可以对Python原生代码进行CPU和GPU加速。Numba非常擅长加速数值运算,它对Numpy支持得非常好,Numpy经过Numba加速后的速度接近C和Fortran。
Numba采用装饰器让Python可调用对象获得CPU或GPU优化。装饰器是一个函数,它以另一个函数为输入,对其进行修改,并将优化后的函数返回给用户。装饰器减少了编程时间,增加了Python的可扩展性。
当使用Numba装饰器调用Python函数时,Numba使用行业标准LLVM编译器库将Python代码转换为针对环境自动优化的机器码。Numba为各种CPU和GPU配置提供了几种快速并行化Python代码的选项,有时只需一个命令,就能实现Python的并行化运行。当与NumPy一起使用时,Numba为不同的数组数据类型和布局生成专用代码,进一步优化性能。
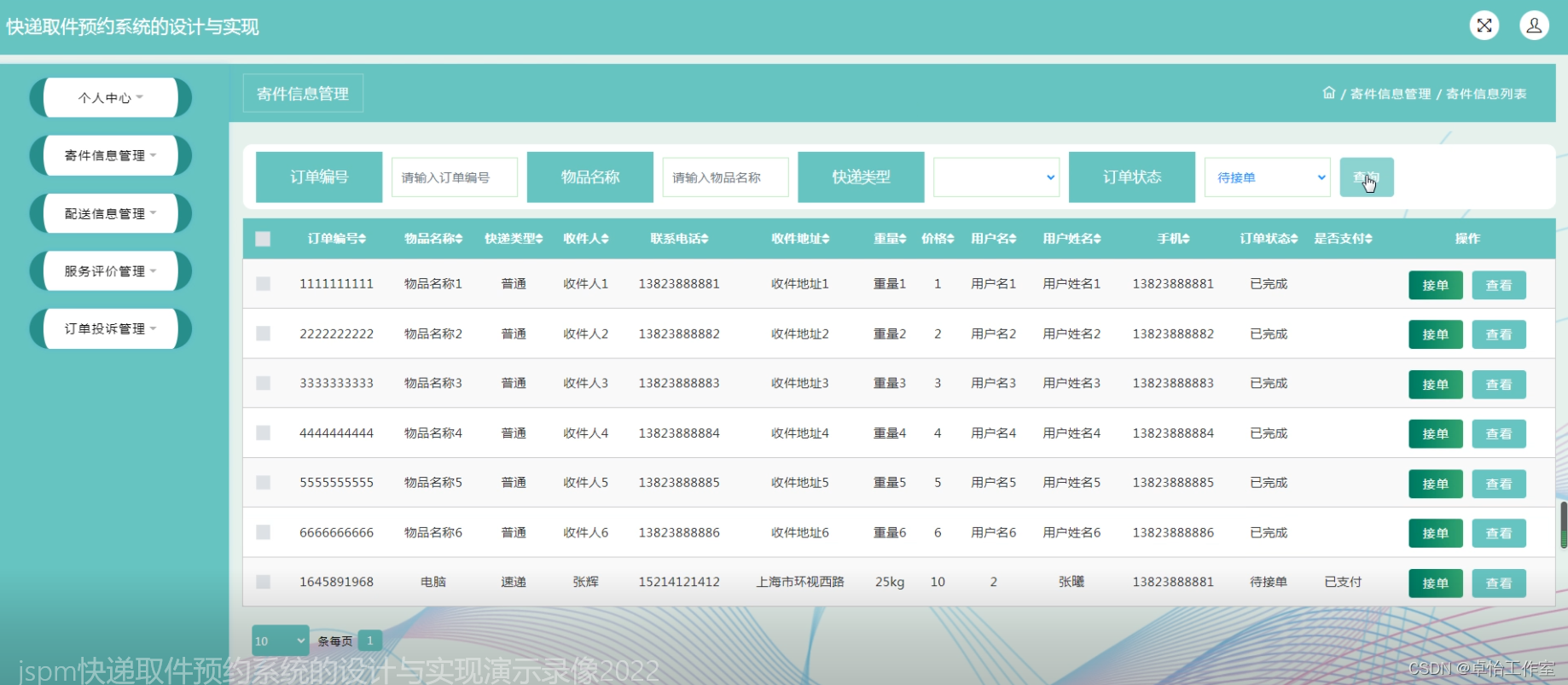
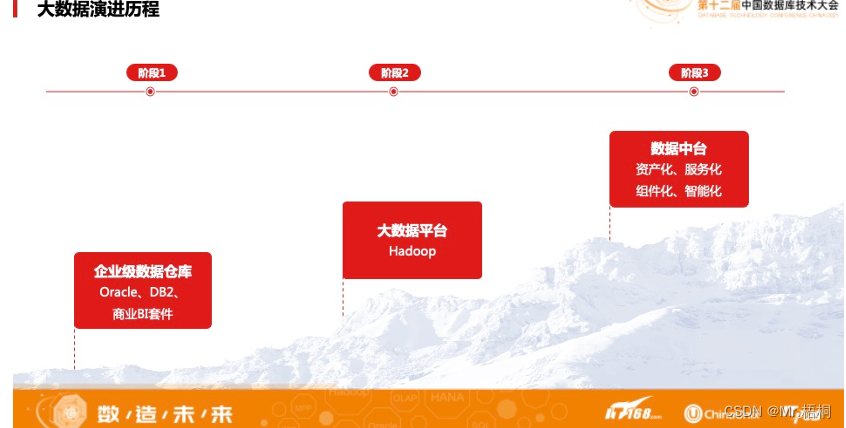
下图是Numba与纯Python和C语言的性能比较,

通过上图我们可以清晰地看到,Numba的性能随着数据量的增加,性能非常接近(甚至略好于)C语言的性能,比Python快至少2个数量级。
安装Numba
Numba的安装非常简单,你可以用pip或conda直接安装:
$ pip install numba
$ conda install numba
安装成功后,我们可以尝试引入Numba,输出Numba的版本:
import numba
print("Numba Version : {}".format(numba.__version__))
# Out: Numba Version : 0.54.1
能看到输出Numba版本号就表示Numba安装成功了。
Numba初体验
安装好Numba后,我们先来体验一下Numba到底有多强。
我们先写一个比较耗时的函数,这个函数接收一个列表,计算列表中数据的标准差:
import math
def std(xs):
# 计算均值
mean = 0
for x in xs:
mean += x
mean /= len(xs)
# 计算方差
ms = 0
for x in xs:
ms += (x-mean)**2
variance = ms / len(xs)
# 转成标准差
std = math.sqrt(variance)
return std
上面的代码用了两次循环,第一次计算均值,第二次计算方差。很明显上面函数的时间复杂度为 O ( 2 n ) O(2n) O(2n),随着输入列表数据的增长,算法时间会呈线性增长。下面我们用高斯分布( N ( 0 , 1 ) N(0, 1) N(0,1))随机生成1000万数据,测试一下这个方法的执行时间。
import numpy as np
a = np.random.normal(0, 1, 10000000)
我们用%timeit命令调用std()函数,看一下执行时间:
%timeit std(a)

从数据可见,std(a)用时4.81秒。
我们看一下Numba优化后的结果。我们首先从Numba中引入njit装饰器,然后用njit”装饰“一下我们前面的std()函数,得到一个新的函数,我们将其命名为c_std。
from numba import njit
c_std = njit(std)
接着,同样方法,用%timeit命令调用c_std(),看一下Numba优化后的执行速度:
%timeit c_std(a)

上面的输出显示c_std(a)仅用时31.4ms,跟std(a)相比,Numba优化过后的速度提升了150倍!
上面的std()计算标准差的函数只是个示例,实际开发中我们不会自己写这么低效的算法,而是直接用Numpy的std()函数。我们可以比较一下Numba优化过的c_std()函数跟Numpy的std()函数的速度:
%timeit a.std()

从上面输出可见,Numpy的std()函数用时75.9ms,是Numba用时的2倍多。
上面这个示例,相信大家已经直观的感受到Numba性能加速的威力。经过Numba优化的代码,不但比纯Python有100倍以上的加速,甚至比用C扩展的Numpy还要快2倍。
Numba加速原理
为什么Numba能将Python提速这么多?这要从Numba的加速原理说起。我们在《用PyPy加速Python程序》中我们讲到了JIT编译。JIT技术通过在运行时将Python字节码进一步编译为机器码来对Python程序进行加速,其工作原理如下图:

Numba做的工作主要在JIT编译器这一步。其实PyPy也是在这一步对Python程度提供JIT编译,但Numba的JIT与PyPy比有4点显著的不同:
- PyPy是全局优化,Numba是局部优化。这意味着用PyPy你需要替换整个Python环境,而Numba不需要,只需要明确要优化的函数即可;
- PyPy的优化是黑箱,我们不知道PyPy何时优化了何处;而Numba是我们明确指定要有优化哪里,开发者可以更加有的放矢地进行优化;
- Numba背后使用的是LLVM,LLVM是一个针对LLVM Intermediate Representation(IR,中间语言)的跨平台优化编译器,它编译速度快、占用内存小,且对代码的优化程度很高;
- Numba支持硬件加速。
下图显示了Numba的工作流程:

Numba首先会对Python字节码进行分析,将其转化成Numba中间语言。由于Python是动态语言,而LLVM需要明确变量的数据类型,所以Numba会对代码中变量的数据类型进行推断,然后更新Numba中间语言,加入数据类型。接着将Numba中间语言转换成更底层的LLVM中间语言,LLVM中间语言经过LLVM编译器的编译优化后得到机器码。
上图除了LLVM,还有NVVM。NVVM建立在LLVN基础之上,用于优化GPU运算。所以Numba不但支持CPU运算加速,还支持GPU加速。
使用案例
让我们看多几个Numba的使用案例。
案例1:计算 π \pi π
数学上我们有很多种方法可以估算 π \pi π的值,其中最优雅的当数蒙特卡罗模拟。
假设我们有一个边长 L = 2 L=2 L=2的正方形,其中心点位于坐标原点上。以原点为圆心, R = 1 R=1 R=1为半径做正方形的内切圆,如下图所示:

圆的面积与正方形的面积的比值为
r
=
S
圆
S
方
=
π
R
2
L
2
=
π
4
r = \frac{S_圆}{S_方} = \frac{\pi R^2}{L^2} = \frac{\pi}{4}
r=S方S圆=L2πR2=4π
即
π
=
4
r
\pi = 4r
π=4r。所以只要我们能估计出正方形和其内切圆的面积之比,就能计算出
π
\pi
π的值。
注意,这里我们不能用圆的面积公式来求圆的面积,因为我们不知道 π \pi π是多少。这里我们就可以用蒙特卡罗模拟的思想,在正方形区域内随机生成大量的点,看多少点落在圆内( x 2 + y 2 ≤ 1 x^2+y^2 \le 1 x2+y2≤1),用落在圆内点的数量除以生成的点的总数即可得到圆形与正方形的面积比。
很明显,随着点数的增加,这个比例会越来越精确。我们可以编写代码测试一下:
import random
def pi(npoints):
n_in_circle = 0
for i in range(npoints):
x = random.random()
y = random.random()
if (x**2+y**2 < 1):
n_in_circle += 1
return 4*n_in_circle / npoints
npoints = [10, 100, 10000, 1000000]
for number in npoints:
print(pi(number))
Out: 3.6
3.44
3.176
3.142104
从输出我们可以看到,随着点数的增多,对 π \pi π的估算越精确。但即便到了100万个点,其精度依然只能做到小数点后2位。如果我们需要更高的精度,这个所需的点会更多。
我们看一下如果模拟1000万个点,上面的代码需要运行多久?
%timeit print(pi(10000000))

从输出看,迭代了7轮,平均运行时间6.18秒。上面的算法时间复杂度为 O ( n ) O(n) O(n),如果我们要测试1亿个点,那就要1分钟。这个时间就太久了。我们看看Numba会将这个函数优化到多快。
这次我们不用njit()包裹,给大家演示一下用装饰器语法来加速。其实很简单,就是在pi()函数前加上@njit
@njit
def pi(npoints):
n_in_circle = 0
for i in range(npoints):
x = random.random()
y = random.random()
if (x**2+y**2 < 1):
n_in_circle += 1
return 4*n_in_circle / npoints
我们再次测试一下经过Numba优化后的速度:
%timeit print(pi(10000000))

从输出可以看到,经Numba加速后只需要205毫秒,提升了30倍!
案例2:寻找最近点
Numba对Numpy的支持非常友好。很多时候,对于数组操作Numpy都能很快的处理,但如果要实现一个复杂的算法,里面很多运算不都是数组或向量运算,此时我们就可以将Numpy和Numba混用,得到更高的性能。我们来看个例子:
import math
def closest(points):
mindist2 = 999999.
mdp1, mdp2 = None, None
for i in range(len(points)):
p1 = points[i]
x1, y1 = p1
for j in range(i + 1, len(points)):
p2 = points[j]
x2, y2 = p2
dist2 = (x1 - x2) ** 2 + (y1 - y2) ** 2
if dist2 < mindist2:
mindist2 = dist2
mdp1, mdp2 = p1, p2
return mdp1, mdp2, math.sqrt(mindist2)
上面的代码用于寻找一组点中距离最近的两个点。从代码上我们能看到这里使用了双重循环,所以其时间复杂度为 O ( n 2 ) O(n^2) O(n2)。这真的不是一个高效的算法,但是个很好的性能测试例子。
我们用正态分布随机生成1000个点,看一下执行速度:
points = np.random.uniform((-1,-1), (1,1), (1000,2))
%timeit closest(points)

输出显示,1000个点需要1.05秒。
我们再来看一下Numba优化后的效果。在closest()函数前加入@njit,
@njit
def closest(points):
mindist2 = 999999.
mdp1, mdp2 = None, None
for i in range(len(points)):
p1 = points[i]
x1, y1 = p1
for j in range(i + 1, len(points)):
p2 = points[j]
x2, y2 = p2
dist2 = (x1 - x2) ** 2 + (y1 - y2) ** 2
if dist2 < mindist2:
mindist2 = dist2
mdp1, mdp2 = p1, p2
return mdp1, mdp2, math.sqrt(mindist2)
然后再次运行测试
points = np.random.uniform((-1,-1), (1,1), (1000,2))
%timeit closest(points)

从输出看只需要8.59ms,比未加速版本快了120倍!
总结
通过上面的示例,大家应该充分感受到了Numba的威力,总结起来Numba有如下优势:
- 简单–仅需一行代码就能得到百倍速度提升;
- 神速–性能提升非常明显,对于时间复杂度在 O ( n ) O(n) O(n)以上的代码,基本都能有100倍的提升;
- 兼容–很好得兼容Numpy等科学计算库;
- 特别适合科学计算场景