–0724
还有几分钟,把burpsuite安装一下
—0804
hh当然,和室友聊天去啦hhh
java目录下找不到jdk,环境变量没法配emm,重新装一下。
emm原来这个文件夹是在安装时自己创建的

啊啊啊,我是猪emm
javasuite闪退是因为环境变量没配好~我还把新版本的java卸了,下了旧版本的,为此还注册了oracle。
具体可能通过javac测试环境变量是否配好了。
成功啦
–0858emm已经一个小时啦,快去看代码!!!
一、debug AttacKG
大概用两个小时,弄清model具体内容,也就是读论文中不明晰的地方
居然找不到昨天写的文档了emmm
还好问题不大,在代码里写了很多注释,直接看代码也ok
(一)techniqueTemplateGeneration
1、re.sub用法
这篇比较清楚
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eik5j1EL-1669259809812)(E:\stup\Typora\pics\image-20221124091942991.png)]](https://img-blog.csdnimg.cn/b2de200f405447029fb0c96c4b466ecf.png)
https://www.cnblogs.com/z-x-y/p/9633212.html
2、examples是什么呢
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IxZHgFVC-1669259809813)(E:\stup\Typora\pics\image-20221124092625974.png)]](https://img-blog.csdnimg.cn/b561fdb8743f46e7972b5e5d2ecdf536.png)
需要看一下这个文件的来源,没找到,感觉是自己pick的初始technique
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LZgn1cXm-1669259809814)(E:\stup\Typora\pics\image-20221124092745939.png)]](https://img-blog.csdnimg.cn/35d766443c5043e7bf792900b7d9cb7f.png)
3、template
后期画整体图的时候,部分注释又有更新。
但是还是不太明晰instance在这里是什么意思
(1)template结构定义.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MpNVhwOW-1669259809814)(E:\stup\Typora\pics\image-20221124094711525.png)]
(2)update_template更新模板
def update_template(self, attack_graph: AttackGraph):
logging.info("---technique template: Update template!---")
# 总实例数+1
self.total_instance_count += 1
sample_node_template_node_dict = {}
# node matching
# 查看sample图中的node,进行匹配与更新
for node in attack_graph.attackgraph_nx.nodes:
max_similarity_score = 0
most_similar_node_index = -1
node_index = 0
# 遍历template中的technique_node技术结点
for template_node in self.technique_node_list:
# 对每一个新的节点node,与原有图中节点template_node进行相似度比对,找到相似度最大的,记录索引和分之
similarity_score = template_node.get_similarity(attack_graph.attackNode_dict[node])
if similarity_score > max_similarity_score:
max_similarity_score = similarity_score
most_similar_node_index = node_index
node_index += 1
# whether node in new sample is aligned with exist template node
# 如果新的node的相似度分数大于THRESHOLD,则将其加入sample_node_template_dict(单独针对每个新的template为update template创立)
# 并用该节点将与其最相似的老节点更新
# 具体similar算法,和更新方法?
if max_similarity_score > self.NODE_SIMILAR_ACCEPT_THRESHOLD:
sample_node_template_node_dict[node] = most_similar_node_index
self.technique_node_list[most_similar_node_index].update_with(attack_graph.attackNode_dict[node])
else:
# 如果不大于,则直接加入technique_node_list,作为新的节点
tn = TemplateNode(attack_graph.attackNode_dict[node])
self.technique_node_list.append(tn)
# 设置index
sample_node_template_node_dict[node] = len(self.technique_node_list) - 1
instance = []
# 查看sample图中的edge,进行匹配与更新
for edge in attack_graph.attackgraph_nx.edges:
# 得到现在图里面的边,后面做的是结点index的转换(由原来图,换位现在结点匹配更新后新生成的图的index)
technique_template_edge = (sample_node_template_node_dict[edge[0]], sample_node_template_node_dict[edge[1]])
# 查看原来的template是否包含该边
if technique_template_edge in self.technique_edge_dict.keys():
self.technique_edge_dict[technique_template_edge] += 1
else:
self.technique_edge_dict[technique_template_edge] = 1
# 将边加入到instance中,所以instance就是现有边的集合
instance.append(technique_template_edge)
# 统计现有边的情况,记入technique_instance_dict,初始化时和原有edge_list相同,不知后续有什么变化?
instance = tuple(instance)
if instance in self.technique_instance_dict.keys():
self.technique_instance_dict[instance] += 1
else:
self.technique_instance_dict[instance] = 1
(4)结点相似性对比函数 get_similarity
def get_similarity(self, node: AttackGraphNode) -> float: # Todo
similarity = 0.0
if self.type == node.type:
# 如果结点type相同,则加0.4分
similarity += 0.4
# 对比ioc和nlp(实体名称)部分的相似度,取最大值
similarity += max(get_stringSet_similarity(self.ioc, node.ioc), get_stringSet_similarity(self.nlp, node.nlp))
return similarity
具体看下get_stringSet_similarity
def get_stringSet_similarity(set_m: Set[str], set_n: Set[str]) -> float:
max_similarity = 0.0
for m in set_m:
for n in set_n:
# 对比每个元素的相似度,找到最大的
similarity = get_string_similarity(m, n)
max_similarity = max_similarity if max_similarity > similarity else similarity
return max_similarity
再看下get_string_similarity
好可爱,作者fu了一篇博客https://blog.csdn.net/dcrmg/article/details/79228589
用的是python-Levenshtein
def get_string_similarity(a: str, b: str) -> float:
# 计算莱文斯坦比
similarity_score = Levenshtein.ratio(a, b)
return similarity_score
(5)更新结点列表方法update_with
def update_with(self, attack_node: AttackGraphNode) -> TemplateNode:
# instance数量加1,即该node又多融合了一个Instance
self.instance_count += 1
# 融合结点
self.merge_node(attack_node)
return self
查看merge_node
def merge_node(self, node: AttackGraphNode):
# 字典取并集
self.nlp |= node.nlp
self.ioc |= node.ioc
node.nlp = self.nlp
node.ioc = self.ioc
(6)总结
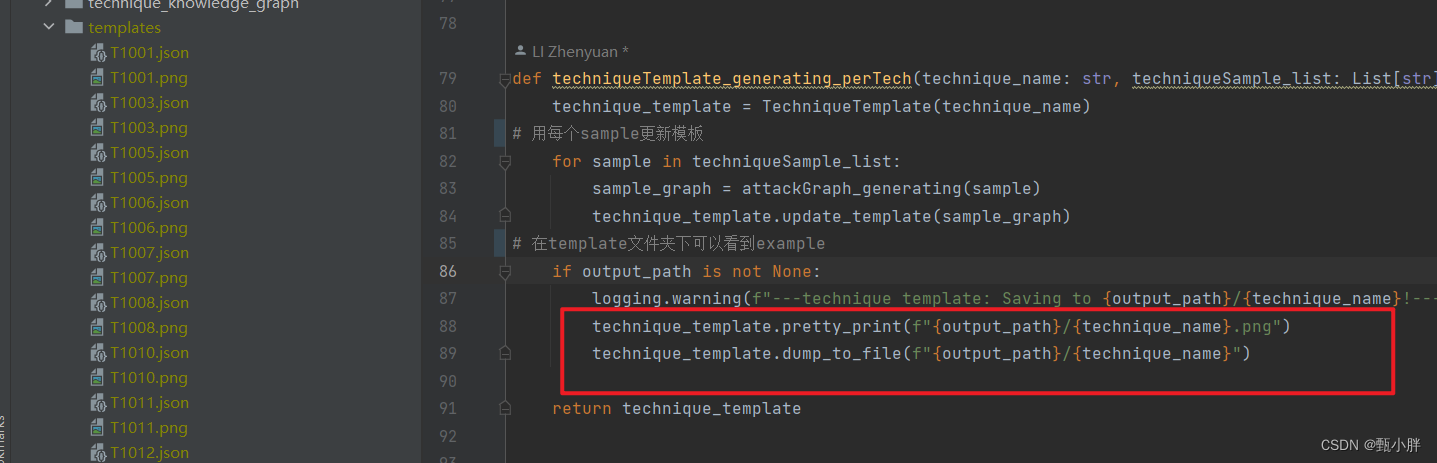
(n)templates文件夹下可以看到examples
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i8yh3SBK-1669259809814)(E:\stup\Typora\pics\image-20221124094359514.png)]](https://img-blog.csdnimg.cn/82a880e324944b18875d45447fbf53c1.png)
----1355继续看代码叭~再用一个小时,看下technique-identification
(二)technique-identification
—1616看了一下午,终于好像,看明白了一点点subgraph_alignment,不容易欸!!!但是这复杂度也太高了叭!!!
(二)techniqueIdentification
# 输入:报告、挑选的techniques、模板地址、输出地址
#输出:technique+对应子图+对应分数
#功能:发现文本里的technique
# 这个之后怎么处理呢?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xni7mlRP-1669281196328)(E:\stup\Typora\pics\image-20221124171217888.png)]](https://img-blog.csdnimg.cn/c4524c8f4e994750a895f0aa20c2dfa9.png)
1、输入
(1)picked_techniques
这里可以很清楚的看到【12:18】,就是编号T1234。
name = “/techniques/T1041”
print(name[12:18])
T1041
picked_techniques_name_dict = {"/techniques/T1566/001": "Phishing",
"/techniques/T1566/002": "Phishing",
"/techniques/T1566/003": "Phishing",
"/techniques/T1195/001": "Supply Chain Compromise",
"/techniques/T1195/002": "Supply Chain Compromise",
"/techniques/T1059/001": "Command and Scripting Interpreter",
"/techniques/T1059/003": "Command and Scripting Interpreter",
"/techniques/T1059/005": "Command and Scripting Interpreter",
"/techniques/T1059/007": "Command and Scripting Interpreter",
"/techniques/T1559/001": "Inter-Process Communication",
"/techniques/T1204/001": "User Execution: Malicious Link",
"/techniques/T1204/002": "User Execution: Malicious File",
"/techniques/T1053/005": "Scheduled Task/Job",
"/techniques/T1037/001": "Boot or Logon Initialization Scripts",
"/techniques/T1547/001": "Boot or Logon Autostart Execution",
"/techniques/T1547/002": "Boot or Logon Autostart Execution",
"/techniques/T1112": "Modify Registry",
"/techniques/T1012": "Query Registry",
"/techniques/T1218/005": "Signed Binary Proxy Execution: Mshta",
"/techniques/T1218/010": "Signed Binary Proxy Execution: REgsvr32",
"/techniques/T1218/011": "Signed Binary Proxy Execution: Rundll32",
"/techniques/T1078/001": "Valid Accounts",
"/techniques/T1518/001": "Software Discovery",
"/techniques/T1083": "File and Directory Discovery",
"/techniques/T1057": "Process Discovery",
"/techniques/T1497/001": "Virtualization/Sandbox Evasion",
"/techniques/T1560/001": "Archive Collected Data",
"/techniques/T1123": "Audio Capture",
"/techniques/T1119": "Automated Collection",
"/techniques/T1041": "Exfiltration Over C2 Channel"}
picked_techniques = set([technique_name[12:18] for technique_name in picked_techniques_name_dict.keys()])
2、technique_identifying()
# 先对文本进行分析
ag = attackGraph_generating(text)
# 如果没有模板的话,就根据technique_list生成模板;如果有的话,就直接load
if template_path == "":
tt_list = techniqueTemplate_generating(technique_list=technique_list)
else:
tt_list = load_techniqueTemplate_fromFils(template_path)
#
attackMatcher = technique_identifying_forAttackGraph(ag, tt_list, output_file)
return attackMatcher
3、technique_identifying_forAttackGraph
def technique_identifying_forAttackGraph(graph: AttackGraph, template_list: List[TechniqueTemplate], output_file: str) -> AttackMatcher:
# 对整个有关report_text的图进行AttackMatcher实例化,用该对象的方法,对report进行match
attackMatcher = AttackMatcher(graph)
for template in template_list:
# 遍历templist,对每个template进行TechniqueIdentifier实例化,该对象可记录matching record。
#之后,将该technique_identifier加入到attackMatcher
attackMatcher.add_technique_identifier(TechniqueIdentifier(template))
attackMatcher.attack_matching()
attackMatcher.print_match_result()
# 感觉没有生成
attackMatcher.to_json_file(output_file + "_techniques.json")
return attackMatcher
4、 attack_matching
def attack_matching(self):
# subgraph_list = nx.strongly_connected_components(self.attack_graph_nx)
# 将attack_graph变成无向图后,找到所有连通子图
subgraph_list = nx.connected_components(self.attack_graph_nx.to_undirected())
for subgraph in subgraph_list:
logging.debug("---Get subgraph: %s---" % subgraph)
# matching_result = []
for technique_identifier in self.technique_identifier_list:
# technique和子图对齐
technique_identifier.subgraph_alignment(subgraph, self.attack_graph)
# for node in subgraph:
# # Try to find a match in technique_identifier_list
# for technique_identifier in self.technique_identifier_list:
# technique_identifier.node_alignment(node, nx_graph)
# for edge in subgraph.edges():
# for technique_identifier in self.technique_identifier_list:
# technique_identifier.edge_alignment(edge, nx_graph)
# find the most match technique
for technique_identifier in self.technique_identifier_list:
node_alignment_score = technique_identifier.get_graph_alignment_score() #/ self.normalized_factor
if technique_identifier.technique_template.technique_name not in self.technique_matching_score.keys():
self.technique_matching_score[technique_identifier.technique_template.technique_name] = node_alignment_score
self.technique_matching_subgraph[technique_identifier.technique_template.technique_name] = subgraph
self.technique_matching_record[technique_identifier.technique_template.technique_name] = technique_identifier.node_match_record
elif self.technique_matching_score[technique_identifier.technique_template.technique_name] < node_alignment_score:
self.technique_matching_score[technique_identifier.technique_template.technique_name] = node_alignment_score
self.technique_matching_subgraph[technique_identifier.technique_template.technique_name] = subgraph
self.technique_matching_record[technique_identifier.technique_template.technique_name] = technique_identifier.node_match_record
# matching_result.append((technique_identifier.technique_template, node_alignment_score))
logging.debug("---S3.2: matching result %s\n=====\n%s - %f!---" % (technique_identifier.technique_template.technique_name, subgraph, node_alignment_score))
(1)subgraph_alignment()!!!
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yIdfzlTn-1669281196328)(E:\stup\Typora\pics\image-20221124171245152.png)]](https://img-blog.csdnimg.cn/29a926d076a042f3b17438431fbf200f.png)
def subgraph_alignment(self, subgraph: set, attack_graph: AttackGraph):
self.node_match_record = {}
# 对于子图里的每个结点,和template中的结点做对齐
for node in subgraph:
self.node_alignment(attack_graph.attackNode_dict[node])
k_list = []
v_list = []
# k为template中technique的index;v为攻击点和对应分数
for k, v in self.node_match_record.items():
k_list.append(k)
# v = [(attack_node, node_similarity_score),...,(attack_node, node_similarity_score)]
if v is None:
v_list.append([''])
else:
v_list.append(v)
self.node_match_record = {}
best_match_score = 0
best_match_record = {}
# *:将列表拆成两个独立参数,然后进行组合
for item in itertools.product(*v_list):
# 对于每一组template_like_attack_nodes,如果第i个template结点对应的为空,则为none;不然,则为其对应的attack_nodes
for i in range(0, len(k_list)):
if item[i] == '':
self.node_match_record[k_list[i]] = None
else:
self.node_match_record[k_list[i]] = item[i]
# node_match_record:【node_index, node_node_similarity】
# 对于technique模板中的边,分别计算在此组attack——nodes下的分值
for template_edge, instance_count in self.technique_template.technique_edge_dict.items():
source_index = template_edge[0]
sink_index = template_edge[1]
# No matched node for edge
# 异常处理:如果起点或终点在node_match_record中不存在——没有对应的template点,其边记录为0,出现异常也记为0
try:
if self.node_match_record[source_index] is None or self.node_match_record[sink_index] is None:
self.edge_match_record[template_edge] = 0.0
continue
except:
self.edge_match_record[template_edge] = 0.0
continue
source_node = self.node_match_record[source_index][0]
sink_node = self.node_match_record[sink_index][0]
if source_node == sink_node:
distance = 1
else:
try:
# 找两点之间最短路径,如果有错误,就将边之间的分值记为0.
distance = nx.shortest_path_length(attack_graph.attackgraph_nx, source_node, sink_node)
except:
self.edge_match_record[template_edge] = 0.0
continue
source_node_matching_score = self.node_match_record[source_index][1]
sink_node_matching_score = self.node_match_record[sink_index][1]
# 边匹配计算分数=结点分数相乘后开方,除以结点之间距离
edge_matching_score = math.sqrt(source_node_matching_score * sink_node_matching_score) / distance
self.edge_match_record[template_edge] = edge_matching_score
match_score = self.get_graph_alignment_score()
if match_score > best_match_score:
best_match_score = match_score
best_match_record = self.node_match_record
self.node_match_record = best_match_record
(2)get_graph_alignment_score
def get_graph_alignment_score(self):
return self.get_node_alignment_score() + self.get_edge_alignment_score()
(3) get_node_alignment_score
node_alignment_score = 0.0
if self.node_match_record is None:
return 0
index = 0
for node_index, node_node_similarity in self.node_match_record.items():
if self.technique_template.technique_node_list[node_index].type == "actor":
continue
if node_node_similarity is not None:
# ToDo: Need to select the larger similarity score
# 攻击结点和模板节点的相似度*模板结点出现的次数
node_alignment_score += node_node_similarity[1] * self.technique_template.technique_node_list[node_index].instance_count # math.sqrt
index += 1
node_alignment_score /= (self.technique_template.node_normalization + 1)
return node_alignment_score
(4)好像没看到edge,明天看!get_edge_alignment_score
def get_edge_alignment_score(self):
edge_alignment_score = 0.0
for edge, edge_similarity in self.edge_match_record.items():
edge_alignment_score += edge_similarity * (self.technique_template.technique_edge_dict[edge])
edge_alignment_score /= (self.technique_template.edge_normalization + 1)
return edge_alignment_score
-----2018洗完澡,做完核酸,收到了零食!!!开心!!
然后和舍友聊天到现在嘿嘿(讲座也没听,打算看看论文啦!!)
二、读论文RAGA: Relation-aware Graph Attention Networks for Global Entity Alignment
emmm宿舍成感情茶话会了hhhh
好啦,和爸爸妈妈打电话~彻底废了









![[附源码]java毕业设计疫情背景下叮当买菜管理系统](https://img-blog.csdnimg.cn/5b87443ef4104e4a889f3f2f6d135ac9.png)