目录
一、AWK
干什么用的?
使用起来有什么条件?
怎么使用?
二、sed
功能?
sed怎样读取数据?
怎样调用sed ?
三、sort
功能是什么?
命令有哪些?
本文只讲解了一些简略的知识框架,如需详细学习,附录几本参考书籍,百度网盘自行下载:
链接:https://pan.baidu.com/s/1uqBeL7FF0GiG4EzmWk90sg?pwd=3905
提取码:3905
一、AWK
引言:如果要格式化报文或从一个大的文本文件中抽取数据包,那么awk可以完成这些任务。
干什么用的?
awk是shell过滤工具,之所以要在shell中使用awk是因为awk本身是学习的好例子,但结合与其他工具诸如grep和sed,将会使shell编程更加容易。
简言之,功能就是过滤和提取,通过对源文件读取内容,然后进行过滤,提取用户感兴趣的字段
使用起来有什么条件?
源文件必须满足如下条件才可被awk过滤和提取内容:
源文件中内容要满足每个都有分隔符,且是相同的分隔符。
如:1.2 2.3 3.4这就满足条件,分隔符为' . '
怎么使用?
有三种方式调用AWK。
第一种是命令行方式:
awk [-F field-separator] 'commands' input-file(s)- commands是真正的awk命令
- -F. 分隔符。因为 a w k使用空格作为缺省的域分隔符,因此如果 要浏览域间有空格的文本,不必指定这个选项,但如果要浏览诸如 p a s s w d文件,此文件各域 以冒号作为分隔符,则必须指明 - F选项.
第二种方法是将所有awk命令插入一个文件,并使 awk程序可执行,然后用awk命令解释 器作为脚本的首行,以便通过键入脚本名称来调用它。
第三种方式是将所有的awk命令插入一个单独文件,然后调用:
awk -f awk-script-file input-files(s)-f 选项指明在文件 awk _script _ file中的awk脚本,input _ file( s )是使用awk进行浏览的文件名。
示例:
获源文件中的整数部分,通过下面圈红的命令实现,其中print:打印 ,'{}' awk的命令,file是源文件,‘>’ 是重定向,新创建newfile文件将内容输入到该文件内,如果不写就是打印到屏幕上。而$1就是文件的第一列。
若要获取小数部分,通过$2得到:


获取下面标红的第一行
可以用管道grep结合awk进行筛选,其中间隔符是空格,因此直接不写.F,-v 取反 不要XXX的意思。
或者用这种方式,第1列必须是ubantu,对其筛选,$0是打印一整行,然后筛选第8行是sleep,进行如下筛选也可以:


二、sed
功能?
简言之就是对文件进行读取数据和编辑
sed怎样读取数据?
sed从文件的一个文本行或从标准输入的几种格式中读取数据,将之拷贝到一个编辑缓冲区,然后读命令行或脚本的第一条命令,并使用这些命令查找模式或定位行号编辑它。重复此过程直到命令结束。
修改的是拷贝,源文件未发生变化
怎样调用sed ?
调用sed有三种方式:
- 在命令行键入命令;
- 将sed命令插入脚本文件,然后调用sed;
- 将sed命令插入脚本文件,并使sed脚本可执行。
使用sed命令行格式为:
sed [选项] sed命令 输入文件在命令行使用sed命令时,实际命令要加单引号。sed也允许加双引号。
使用sed脚本文件,格式为:
sed [选项] -f sed脚本文件 输入文件 要使用第一行具有s e d命令解释器的s e d脚本文件,其格式为:
sed 脚本文件 [选项] 输入文件 不管是使用shell命令行方式或脚本文件方式,如果没有指定输入文件,sed从标准输入中接受输入,一般是键盘或重定向结果。
sed选项如下:
- n 不打印;sed不写编辑行到标准输出,缺省为打印所有行(编辑和未编辑)。
- p命令可以 用来打印编辑行。
- c 下一命令是编辑命令。使用多项编辑时加入此选项。如果只用到一条sed命令, 此选项无用,但指定它也没有关系。
- f 如果正在调用sed脚本文件,使用此选项。此选项通知sed一个脚本文件支持所有的sed命令,例如:sed -f myscript.sed input_file,这里myscript.sed即为支持sed命令的文件。
基本sed编辑命令如下:


示例:
在第二行内添加3.3
附加数据:附加到第二行后面
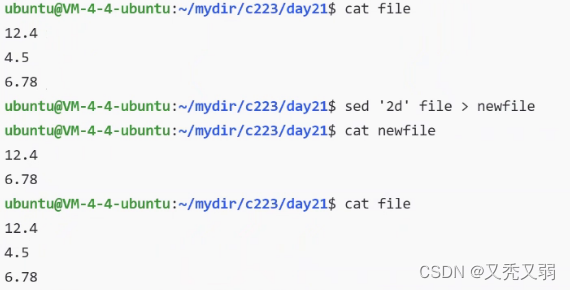
删除第二行
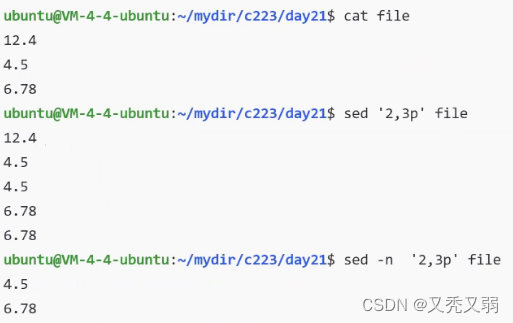
打印第二行、第三行,加上-n是不对源文件进行打印


三、sort
功能是什么?
sort命令将许多不同的域按不同的列顺序分类。
命令有哪些?
sort -cmu -o output_file [other options] +pos1 +pos2 input_files- -c 测试文件是否已经分类
- -m 合并两个分类文件
- -u 删除所有复制行
- -o 存储sort结果的输出文件名
- - o选项保存分类结果,然而也可以使用重定向方法保存。
- 其他选项:
- -b 使用域进行分类时,忽略第一个空格
- -n 指定分类是域上的数字分类
- -t 域分隔符;用非空格或t a b键分隔域
- -r 对分类次序或比较求逆
- +n n为域号。使用此域号开始分类。 n n为域号。在分类比较时忽略此域,一般与 + n一起使用。 post1 传递到m,n。m为域号,n为开始分类字符数;例如 4,6意即以第5域分类,从第7 个字符开始。
最基本的sort方式为sort filename,按第一域进行分类(分类键 0)。实际上读文件时sort操作将行中各域进行比较,如下所示:

sort分类求逆
如果要逆向sort结果,使用- r选项。在通读大的注册文件时,使用逆向sort很方便。
唯一性分类
有时,原文件中有重复行,这时可以使用 - u选项进行唯一性(不重复)分类以去除重复行。对带重复行的文件使用- u选项去除重复行,不必加其他选项,sort会自动处理。
如下所示,对文件逆序+去重: